
Abstract
A deep understanding of human activity is key to successful human-robot interaction (HRI). The translation of sensed human behavioural signals/cues and context descriptors into an encoded human activity remains a challenge because of the complex nature of human actions. In this paper, we propose a multilayer framework for the understanding of human activity to be implemented in a mobile robot. It consists of a perception layer which exploits a D-RGB-based skeleton tracking output used to simulate a physical model of virtual human dynamics in order to compensate for the inaccuracy and inconsistency of the raw data. A multi-support vector machine (MSVM) model trained with features describing the human motor coordination through temporal segments in combination with environment descriptors (object affordance) is used to recognize each sub-activity (classification layer). The interpretation of sequences of classified elementary actions is based on discrete hidden Markov models (DHMMs) (interpretation layer). The framework assessment was performed on the Cornell Activity Dataset (CAD-120) [1].
The performances of our method are comparable with those presented in [2] and clearly show the relevance of this model-based approach.
Introduction
Social robots must be able to interact effectively with humans, to understand their needs, to interpret their orders, and to predict their intentions. These challenging tasks can obviously benefit from body language, which comprises a very important aspect of communication. For successful HRI, the robot must be able to translate the sensed human behavioural signals/cues and context descriptors into an encoded behaviour. The question concerns how to map information made available from uncertain and scarce data, often coming from simple sources into natural human activities. The difficulty of this mapping process stems from the diversity and complexity of human activities. Even the simplest tasks can be performed with both interpersonal and intrapersonal variability. In addition, human activity is rarely atomic: usually, a set of behaviours are performed in parallel (gestures, speech, posture, etc.). Therefore, human activity is not easily codified into machine-programmable constructs.
In the past, object detection and activity recognition have been dealt with separately. Recent works (e.g., ([3, 4, 5]) have shown that combined models are mutually beneficial. In particular, the improvement of the recognition rate obtained by Paker's method suggests that combining human body poses and objects' trajectories is an effective strategy for human activity recognition. This idea is supported also by cognitive psychological studies: it is closely related to the “predictive coding” hypothesis from ideomotor theory [5]. The principle of the “ideomotor” argues that, during the execution of a particular action, a motor model (a reduced-order model) is automatically associated with the input of the perception, representing the perceptual effects of the action on the environment [6]. This event-coding theory suggests that the human brain continuously generates expectations regarding sensory inputs from motor activities. In this context, human actions are goal-directed movements that lead to intended effects in the environment [7]. It seems plausible to assume that activity recognition can benefit from knowing what object a person is using, but even more from how the object is being used, which is the affordance of the object. The concept of affordance is an ecological approach to perception proposed by Gibson in 1979 [8]. With this concept, Gibson offers a new approach to a knotty problem in perception theory: accounting for meaning in perceptual experience. The exploration of the implicit assumptions of the object-affordance context conducted by Heft [9] has revealed the intentional character of perception. This result is completely consistent with the idea of goal-directed movements for intended effects in an environment as proposed by ideomotor theory.
In this paper, we present a multilayer reasoning system for human activity recognition. Each activity is modelled as a sequence of elementary task-oriented actions or sub-activities that change over the course of performing an action. Human movements and the environment are observed (perception layer); the coordination of the human body across temporal segments in combination with environment descriptors (object affordance) is used to model and recognize each sub-activity (classification layer). Eventually, the sequence of classified elementary actions is analysed to interpret and understand the activity (interpretation layer). The perception layer is based on the D-RGB modality to sense the environment and the body-skeleton in a markerless way (we use the Cornell Activity Dataset (CAD-120) data [1]). The serious inaccuracy of the skeleton detection algorithm is tackled and properly fixed by animating it using the Kinect to output a physical model of the observed human body on the dynamic simulator XDE. The virtual human model [9] and control [10] implemented in the simulator filters input data by imposing the satisfaction of kinematics and dynamics body constraints as well as Newton motion laws and biomechanical principles in human motions. For the classification of the elementary actions, we propose the use of SVM, which is especially popular (and not only within visual pattern recognition). In particular, we chose a MSVM with a Gaussian radial basis function (RBF) kernel. The features used for the classification are both the spatiotemporal parameters extracted from the limbs' coordination directly observed and filtered from the virtual mannequin dynamic model, and the information about object affordance (provided from the dataset labels). The interpretation layer consists of understanding the activity by considering the sequences of sub-activities – or elementary actions – executed by the person. For this purpose, we propose the use of DHMM models with a maximum likelihood parameter estimated using the Baum-Welch algorithm. Our method achieves a precision of P=0.81 for elementary actions' classification and P=0.82 for activities' interpretation. In summary, our contribution in this paper is threefold:
We provide a method for the reconstruction of human body motor activities under kinematics constraints and for the extrapolation of a dynamically consistent configuration of the lower limbs, solely based on noisy data coming from capture motions of the upper-body. This method is very powerful, since it allows for activity analysis in real-life environments where occlusions of the lower-body are particularly problematic. We suggest a combination of spatiotemporal parameters for the description of body motion coordination. This combination is very effective because the classifier performed well by using a vector of features of small dimensions (Ψi ∈ ℝ25 versus Ψi ∈ ℝ201, as in [2]). We propose a method to understand human activity by analysing the sequence of atomic actions and which has shown good results even though it was learnt on only a few persons and tested on not seen before persons.
Related work
There is a substantial literature focusing on human action recognition. Most of these works (e.g., [10,11,12]) consider detecting actions at a “sub-activity” level (e.g., walking, jumping and running), while others focus on high-level activity recognition, such as [13] and [2]. A large number of methods rely on the observation of body pose trajectories by using either motion capture or visual techniques in highly constrained settings. Some of these works exploit optical flow measurements from videos [14], others use motion history images to represent actions [15]. Ramanan [16] has approached activity recognition by first tracking humans in the sequence and then comparing the human body configurations with an annotated motion library. Blank [17] proposed a representation of actions as space-time shapes that can be recognized by extracting space-time features from a sequence of images. In [18], the authors used a dynamic time warp to analyse the stretching of trajectories in space and time. Rao and Shah [19] proposed a method to transform a trajectory into a sequence of signed dynamic instants that allows a view-invariant representation. These types of methods are particularly effective for the classification of activities characterized by distinctive poses (e.g., performing gestures, running and jumping), but they cannot be used to distinguish actions that have similar body pose trajectories.
Another approach consists of extracting space-time interest points in videos. Laptev [20] proposed a space-time interest point detector inspired by the notion of an interest point operator presented in [21]. The approach involves the detection of local structures where the image has significant variation in both spatial and temporal dimensions. This method has the limitation of not producing enough stable interest points for the characterization of complex sequences. Another method based on interest points was proposed by Ke [22]: interest points detected over motion vectors (optical flow) are employed as features for activity recognition with a discriminative cascade classifier. Niebles [23] proposed an unsupervised learning method for human activity recognition based on latent topic models, such as a probabilistic latent semantic analysis (PLSA) model and latent Dirichlet allocation (LDA).
Due to the computational time involved and the inaccuracy of the pose detectors in video, recent systems for activity recognition are grounded on a feature-based approach. Dollár et al. [24] used a bag-of-words approach over visual spatiotemporal words. In [25, 26], general methodologies are proposed to capture the spatial and temporal distribution of these words. Using a similar approach, Hamid et al. [27] investigated activity sequences in terms of their constituent sub-sequences, called “event n-grams”. The authors proposed a computational framework that exploits this representation to discover various activities taking place in an environment. These methods have been proven to be quite effective in the recognition of activities with prominent physical cues, but they are not suitable for the recognition fine motion, like slight limb movements. Other authors have proposed methods based on the combination of body pose and image features. For instance, Karlinsky [28] used detected body parts to find relevant visual features, while Yao and Fei-Fei [4] clustered pose models that interact with objects to classify actions. Both of these methods are restricted to still images. Recently, with the arrival of inexpensive D-RGB sensors, some authors began considering the depth information of images or videos for human activity recognition ([29, 30, 31,32, 31]). Zhang and Parker, in [32], have proposed the use of 4D local spatiotemporal features and a LDA classifier to identify six human actions, such as lifting, removing and waving, etc., from a sequence of D-RGB images. However, they only address the detection of actions at the sub-activity level. In [31], the authors proposed a hierarchical maximum entropy Markov model to detect activities from D-RGB videos and using only human pose information for detecting activities (they also constrained the number of sub-activities in each activity). Paker et al. [33] have proposed a framework that combines pose-based and feature-based action recognition methods. The system uses a human pose tracker that requires a one-time calibration phase to record a depth image of the scene for background subtraction. This requirement makes this method unsuitable for implementation on a mobile robot. However, the improvement of the recognition rate obtained by Paker's method suggests that combining human body poses and objects' trajectories is an effective strategy for human activity recognition. The great importance of contextual understanding for human activity recognition has been proven in a rigorous fashion by Koppula et al. in [2]. The authors clearly showed how knowledge about an object's affordance and position with respect to the human body entail a considerable improvement of the activity recognition system that they proposed. This idea is closely related to the “predictive coding” hypothesis from ideomotor theory [5]. For a detailed review of video-based human activity recognition, we refer the reader to [34].
Motivation
The great interest in the analysis of human activities in everyday-life contexts has been encouraged by a broad range of applications in many areas, such as advanced user interfaces, disease diagnosis and, more generally, the understanding of human behaviour. Stimulating the activity of individuals or observing them performing tasks over the course of daily life recommends the design and development of mobile autonomous robots able to search and detect humans, to appropriately interact with them, and to collect data useful for the analysis of their behaviour. The main abilities that this kind of robot has to satisfy are to detect, localize and track humans and analyse their activities. These capabilities are particularly challenging in real-life situations, especially when using only embedded sensors. An autonomous mobile platform provides, in this context, real added value since it allows for the maximization of the observability of a person's activities without limiting that person's movements. The use of a mobile robot with embedded sensors to detect and track human activities gives rise to the possibility of controlling the conditions of information retrieval in complex and cluttered environments, of focusing resources, and of reducing the risk of occlusion and measurement noise. This allows for an in-depth analysis in non-controlled environmental conditions, without any environmental equipment required. In a previous work [35], we presented a framework combining a multimodal human detector based on sensors embedded in a mobile robot, and a decisional engine exploiting fuzzy logic mechanisms to enable the robot to track humans, maximizing observability and confronting losses of detection. The idea that motivated this work was to exploit the ability of the robot to track humans and maximize the observability of their movements in order to understand their behaviour. In the following sections, we present a new method to achieve the challenging task of human activity recognition. Here, the assessment of this method is performed on data collected with a fixed Kinect sensor [1], but the same results could be obtained with data collected from a Kinect embedded on the robot while tracking the person as introduced in [35].
Dataset
The CAD-120 dataset comprises video sequences of four individuals performing 10 daily activities which are recorded using the Microsoft Kinect sensor. Each video comes with RGB images, depth images and a tracked skeleton. The latter is detected using OpenNi's skeleton tracker [36] in the Nite 1.3 software package. Figure 1 shows some examples of the recorded activities. For more details about this dataset, we refer the reader to [1]. Table 1 specifies the set of sub-activities involved in each activity (the grey cells indicate that the sub-activity is executed during that activity). Note that some activities consist of the same sub-activities, though they are executed in a different order.

Examples of recorded activities from the CAD-120 dataset [1]
Activities (rows) and sub-activities (columns) in the dataset CAD-120

The spatiotemporal structure of an activity is formalized defining a digraph with four types of node, as shown in Figure 2. The spatiotemporal nodes (s-t) describe the evolution of the body posture (the body coordination) resulting from the analysis of the XDE output, as explained in session 6.1. The oa nodes represent the information about object affordance at each frame. The sa and A nodes are, respectively, the sub-activities and the activities. We modelled each activity as a sequence of elementary task-oriented actions or sub-activities that change over the course of performing that action. The sequence of sub-activities in time is used to recognize the current activity. The coordination of the human body across temporal segments in combination with environment descriptors (object affordance), is used to model and recognize each sub-activity. Note that the objects' trajectories are not used in the model (as proposed in [2]). This is to prevent the dependence of the model upon the object tracking, which is usually highly inaccurate due to occlusions during manipulation tasks. For example, if the recognition of the drinking elementary action relies upon information about the glass's trajectory, the risk of failure is high because of the high probability that the glass may cease to be detected when it is held by the hand. If, instead, we only need to know that the person is manipulating a glass, which has drinkable affordance, the risk of misclassification is much lower. However, the modularity of the model allows us to extend the number of features used for the classification (for instance, by taking into account object trajectories, gaze direction, audio information, and so on).

Digraph representing the different nodes and their relationships for the proposed framework (s-ti = spatiotemporal parameters in frame i, oai = object affordance in frame i, sai = sub-activity classified in frame i, and Aj= activity j, with j = 1,…,10)
Perception
Human behaviour
By the term behaviour we refer to the range of human mannerisms while executing an action, including body movements and posture, gaze direction, facial expressions, voice, and so on. In the presented system, the perception of human behaviour is limited to the analysis of body posture and motion. In most of the literature, the perception of whole-body kinematics is based on accurate motion capture technologies, such as wearable sensors, markers and instrumented platforms. In order to make our system compatible with real-life applications, we cannot use such systems (i.e., which entail limitations in body movement and in the work space, and which require a long setup time). For this reason, we chose to test our system on a dataset of data collected with a marker less approach designed to capture, in real-time, multi-segmental human motion by using a Kinect sensor and the Nite 1.3 software package. The serious inaccuracy of the sensor and the skeleton detection algorithm [37] (especially in the case of large occlusions of some parts of the body which often occur in real-world activity analysis) is confronted and properly fixed by animating using the skeleton tracking output as a physical model of the observed human body on the dynamic simulator XDE, a simulation framework developed by CEA-LIST [38]. It provides a dynamic virtual human model which consists of 20 joints and 45 degrees of freedom (DoF). Each DoF is a hinge joint controlled by an independent actuator producing a torque. In this software, the anthropomorphic model is rescaled automatically to match the height and weight of the subject's morphology. The use of a model-based approach with the simulator filters the input data by forcing the respect of the kinematics constraints [35]. A model-based approach is employed to replay the captured kinematics data in a kinematically- and dynamically-consistent manner, in order to extract accurate kinematics indicators from the human motion and to align the perceived movements with physical constraints acting on the human body. Additional indicators related to dynamic information (such as joint torques, contact forces, the position of the centre of pressure) can be extracted from the simulation and used for the classification presented in Section 6.2. This replay is divided into two successive steps, with an initial kinematic filter followed by a dynamic simulation of the model. Since the segments of the skeleton from OpenNI have no constant lengths, the joint data must first be filtered in order to be consistent with the kinematics of the human model, thus respecting the joint limits, collisions and other kinematics constraints [35]. An exclusively kinematic simulation is performed with the human model, tracking the joint positions in space from the skeleton data through proportional-derivative coupling between selected segments of the model and the captured points. From a set of nj measured-joint Cartesian positions
The dynamics simulator is coupled to a whole-body controller [39] to compute the optimal joint torques τ*, allowing for the tracking of the filtered body segment positions and orientations. These torques are computed so that,

where S=S(τ, Wc) is the set of segment positions and orientations resulting from the current state of the model, the joint torques τ and the contact wrenches Wc. The objective q is a linear-quadratic setup for regularization purposes, favouring a reference-joint configuration, for example, and l is affine, essentially describing the dynamic constraints. Scalar weights wi define the relative priority between tracking tasks for the different body segments. The resulting optimal segments data
Two obstacles are yet to be overcome. First, as an example, despite the kinematic consistency between the various segments' positions and orientations Sk, the dynamics impose different constraints to be respected in order to maintain the balance of the model. The major consequence of these additional constraints is that the whole set Sk might not be feasible, and tracked targets
A second obstacle comes from occlusions and inaccuracies in the skeleton detection, as illustrated in Figure 3. Indeed, although the identification of upper-body segments has overall satisfactory robustness, the lower limbs are repeatedly misdetected and the detection of the contact state of the human with the ground is, moreover, virtually impossible without the use of force sensors at the feet level. As a result, a dynamically-consistent configuration of the lower-limbs must be extrapolated solely from the captured motion of the upper-body. This extrapolation is obtained by the setup of an automatic-walking controller [41], generating walking steps to maintain balance while achieving a desired motion for the centre of mass (CoM) of the model. The generated steps and the legs' configurations are dependent only upon the observed CoM and the body balance (they are completely independent from the observation). This is equivalent to assuming that information about the lower body collected by the observation is not considered at all (the high inaccuracy observed in real environmental applications motivated this choice). Based on a mixed-integer program, this predictive controller takes as input the desired displacement of the CoM of the human and the preferred position of the feet – if any – and gives as output the coherent legs movement. Although the generated steps are not directly related to the captured data, but only to the observed motion of the upper-body, it allows us to generate dynamically consistent motions for the whole-body in the case of missing data for the lower-limbs.

Comparison of kinematically and dynamically consistent motions. From left to right: RGB image (ground truth) with the inaccurate skeleton detected; simple kinematics replay (Sk); optimal segment data (S*).
The conjoint operation of the kinematics and dynamics filters allows us – as illustrated in Figure 3 – to conform measured data Sm to various constraints in order to obtain feasible motions S* with the utmost accuracy. The resulting dynamics simulation allows for the extraction of an additional dataset to obtain non-observable indicators.
The label indicating the object affordance related to the sub-activity comes with the used dataset. It is inferred by computing the relative kinematic features between the manipulated object and the human's skeletal joints. When the objects are not directly manipulated by the human, their affordance is gathered from the relative kinematic features (such as 'on top of and 'nearby') of other objects around them. For more details, we refer to [2].
Classification
This layer is used to recognize the sub-activities by classifying different features, such as human body posture and coordination, and contextual descriptors (i.e., object affordance). MSVMs are state-of-the art large-margin classifiers which have become very popular, especially – but not only – in visual pattern recognition. We implemented an MSVM based on the model proposed by Weston and Watkins [42]. This model consists of the generalization of the minimization quadratic problem defined for a binary classification MSVM (2),

Meanwhile, under the constraints (3) and (4),


where xi ∈ Rp, i=1,…, 1, are the training vectors (l is the number of training samples), w is the vector representing the hyperplane, C >0 is the user-specified misclassification penalty, ξi are the slack variables, y ∈ Rl is a vector such that yi ∈ {1,−1}, and b is the bias parameter.
For the k-class MSVM, the optimization problem (2) can be generalized by minimizing (5)

with the constraints (6) and (7)


As such, the resulting decision function is:

As the kernel function, we chose the Gaussian radial basis function kernel given in Equation 9 to interpret the nonlinear model as a linear model following a fixed nonlinear transformation that does not depend upon the sample of the data,
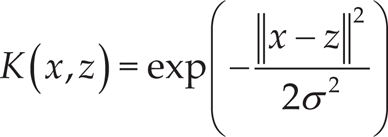
The model is trained until a predefined level of accuracy is reached in terms of the ratio value of the dual-objective function/upper-bound optimum. The value of the dual-objective function, α, is the solution of the dual problem obtained at some point in the training procedure. The upper bound, U(α), is computed by solving the primal problem with h = (wi · x) + bi,i = 1,…k as the function associated with the current α [43]. The results presented in this paper are found with an accuracy-level threshold equal to 95%. By increasing this value, the classification result can be more accurate, but the training step would require more time. In contrast, decreasing this value of the threshold entails the worst performances of the system but allows for the faster training of the model.
The proposed classification system is designed to recognize human mannerisms by analysing the movements' coordination, which refers to the relative timing of the motions made by different body segments [44]. The analysis of the body's coordination is used for medical assessment as well as in sports applications to increase the body performances. Several studies have investigated the coordination of the body segments by using kinematics variables for the motion. In [45], a plot of an angular time series of two joints, called sn angle-angle diagram, has been used for coordination assessment during locomotion. In [46], Hoy et al. described a chain-encoding technique originally presented in [47]. The technique used for coding the chain consists of a superimposed grid used to transform the angle-angle trajectory into digital values. In [48], the authors proposed the analysis of the relative motion – or coordination – between two segments by creating angle-angle plots coupling the proximal segment comprising the abscissa, and the distal segment comprising the ordinate. In [44], instead, the coordination between two body segments si and sj is defined as the time difference between corresponding key events ei and ej. However, in this case a specific movement is analysed (a baseball swing) and the key events are a priori well-defined (hip rotation, shoulder rotation and arm extension). We need to define a more generic system for body coordination analysis in order to be able to classify natural body movements during daily activities. In our classification system, the angular positions and velocities of the joints are used as descriptors (features) of the body coordination. In particular, for a given sub-activity node i, the vector of features Psi;i is computed using both the object affordance label and the human skeleton information obtained from replaying on XDE the skeleton movements tracked on the RGB-D video by the OpenNi algorithm. For the torso, the left shoulder, the left elbow, the left wrist, the right shoulder, the right elbow and the right wrist, we computed spatiotemporal parameters that describe the evolution of the posture and the coordination of the human body during the execution of a sub-activity. In particular, we considered two DoFs for the torso, three DoFs for each shoulder, and one DoF for the elbows and the wrists. As spatial parameters, the variation of the angular joint position of each joint mentioned above in a particular interval was analysed. We chose an interval of 30 frames that corresponds to the analysis of the joints' movements at around 0.9s. This interval has been chosen experimentally and has been proven to be particularly suitable for the frequency of the data collection of the considered database, as well as for the type of movements analysed. This parameter should be tailored to the sensor frequency and to the specific application (the kind of activity analysed). With the sliding windows method, the description of the angular position's evolution of the upper-body joints at each frame is obtained. Finally, the continuous parameters are discretized by assigning one of three possible values: 0 if the angular position is constant (the joint is not rotating), 1 if the angular value is increasing, and 2 if it is decreasing. We obtained a vector of spatial features ψi ∈ ℝ12 (according to the considered DoF). With the same approach, of staggering and discretization, the joints' velocities resulting from the dynamic simulation are used to compute temporal parameters. In this way, another vector of features, ψi ∈ ℝ12, which describes the discretized velocity directions of the joints in an interval of 0.9s is computed. By also considering the label indicating the object affordance from the database, we had in total a vector of features ψi ∈ ℝ25. In this way, we modelled the spatiotemporal coordination of the upper-body limbs during the execution of the sub-activity.
Temporal segmentation
The temporal segmentation consists of splitting the whole video of an activity into groups of frames representing the different sub-activities. This will group similar frames into one segment representing a sub-activity. In certain cases, when the features are additive, methods based on dynamic programming [11, 49] could be used to search for an optimal segmentation. This approach is not suitable for our application because the feature map that we consider is non-additive in nature. Furthermore, the complexity of human behaviour cannot be approximated with a linear dynamical system as in [50] because human activity is rarely atomic (different sub-activities can be performed simultaneously without any precise boundary between them) and interactions with objects are manifold. Our segmentation method consists of merging into one segment all the contiguous sub-activities classified as the same class. As explained above, for each frame i we compute the vector of features Ψi describing the body coordination in an interval of 30 frames (centred in frame i) and we run the MSVM described in Section 6.2. In this way, we associate with each frame one class of sub-activity (so far, our method is not suitable for simultaneous sub-activities' classification). The sub-activities classified as belonging to the same class are merged. Eventually, the outliers are removed from the sequence of sub-activities recognized frame-by-frame by the MSVM in order to decrease the isolated classification errors.
Interpretation
The interpretation layer is used to understand the human activity in question by considering the sequence of the classified elementary actions (sub-sequences). Not only is the order of elementary actions considered, but so too is their duration, which corresponds to taking into account the size of each segment. This approach requires the use of a statistical tool that is effective in modelling stochastic processes of generative sequences with discrete outputs. For this reason, we decided to model the sequences of sub-activities constituting the human activities by using DHMM. Given a set of N observations (classified sub-activities) O = (sa1,…,saN) (where each sal is the recognized class of sub-activities at around 0.9s such that it does not correspond to a whole segment) and the space of underlying states Z = 1,2,…,M (M=10, the number of activities from the dataset), the DHMM is trained in order to learn the parameters,
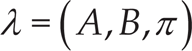
where π is the matrix of initial state probabilities, A is the state transition matrix and B is the observation probability matrix;

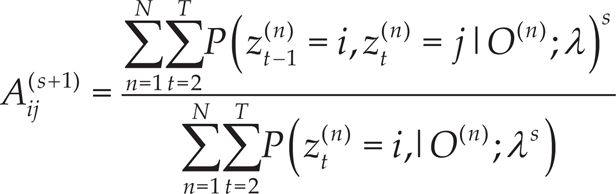

where I(sa) is an indicator function which is 1 if sa is true and 0 otherwise.
To classify a sequence of sub-activities into one of the M classes of activities, we trained up M DHMMs – one per class – and we computed the log-likelihood (Equation 14) that each model gives to the test sequence; the most likely model among the M trained is declared as the class to which the test sequence belongs.

Classification
We assessed the classification layer using four different groups of features by combining the features described in Section 6.2. The first group (G1) is composed of the sole object affordance labels; in the second group (G2), we included object affordance labels and the spatial parameters; the third group (G3) consists of object affordance labels and the temporal parameters; the last group (G4) includes all the features. To assess the performance of the classifier preventing the over-fitting problem in the training phase, we use the five-fold cross-validation method and then we compute the number of true positives (TPs), false positives (FPs), true negatives (TNs) and false negatives (FNs). These four parameters are used to compute the precision (TP/(TP+FP), recall (TP/(TP+FN)), specificity (TN/(FP+TN)) and accuracy ((TP+TN)/(TP+FP+TN+FN)) of the system for each class and for each group of features. Figure 4 shows the results taking into account the four groups of features. The classifier gave the best performances by taking into account all the features G4: precision (P = 0.8081), recall (R = 0.7008), accuracy (A = 0.9447) and specificity (S = 0.9633) (see Figure 4). This result shows the importance of the combination of both spatial and temporal parameters as descriptors of human body movements' coordination. The results of all four groups of features are detailed in Table 2.

Confusion matrices (top) and classification results (bottom) for each group of features (from the left: only object affordance labels G1, object affordance labels and spatial parameters G2/ object affordance labels and temporal parameters G3, all features G4)
Classification results

The sequences of classified sub-activities are the inputs of the temporal segmentation. Figure 5 shows three segmented activities with the respective gold standards and presenting a different level of recognition rate. The proposed method presents an average performance (in %) of 73, with an average error of 26.89 (SD=13.2).

Example of segmentation for three different activities. In the first case (top), the accuracy is 97,3%, while in the second case (middle) it is 88,55% and in the last case (bottom) it is 69,17%.
The DHMM proposed for the interpretation layer was assessed with the following four different tests:
For each of the 10 activities, we trained a DHMM by using two samples of all the users and then we tested them by using the leftover sample. Reminder: the dataset contains samples of 10 activities played three times by four individuals (for each activity, there are 3 samples and in total there are 10 samples). For each of the 10 activities, we trained a DHMM by using one sample of all the users and then we tested it by using the two leftover samples. For each of the 10 activities, we trained a DHMM by using all the samples of three individuals and then we tested them by using all the samples of the leftover person (repeated for all individuals). For each of the 10 activities, we trained a DHMM by using all the samples of one person and then we tested them by using all the samples of the three leftover individuals (repeated for all individuals).
Tests 1 and 2 correspond to the assessment of the trained model with already seen test individuals, while Tests 3 and 4 present an approach not seen before.
Figure 6 shows the performances of the four tests, and the results are detailed in Table 3. The DHMMs that gave the best performances were those trained using all the samples of three individuals and then tested using all the samples of the leftover person (Test 3): precision (P = 0.8181), recall (R = 0.7583), accuracy (A = 0.9517) and specificity (S = 0.9731) (see Figure 6). This result was in a way expected because, in Test 3, the model is trained using more samples than is the case for the other tests (90 samples), followed by Test 1 (80 samples), then by Test 2 (40 samples), and eventually by Test 4 (30 samples). We can see that the performances obtained in Tests 3 and 1 are close because almost the same number of data are used for training. In this case, the factor already seen person (Tests 1 and 2) did not impact upon the performance. Instead, it seems that this factor significantly affected the results of Tests 2 and 4, in which the number of samples used for the learning is similar, while the performances of the case already seen are better than the case not seen before.

Confusion matrices (top) and interpretation results (bottom) for each test (from the left: Test 1, Test 2, Test 3, Test 4)
Interpretation Results

In this paper, we proposed a multilayer framework for the understanding of human daily activities in unconstrained situations. We modelled each activity as a sequence of elementary task-oriented actions or sub-activities that change over the course of performing the action in question. The proposed framework combines context descriptors (object affordance information) with the observed human body coordination (perception layer) in order to recognize the human's atomic actions or sub-activities (classification layer), and to eventually understand the general activities (interpretation layer). The perception layer exploits the D-RGB-based skeleton-tracking output to animate a physical model of the human body on a dynamic simulation (XDE) to compensate for the inaccuracy and inconsistency of the raw data. This approach allows for the optimization of the body motion reconstruction under kinematics constraints as well as for the extrapolation of a dynamically consistent configuration of the lower-limbs, solely from the captured motion of the upper-body. This is very useful for activity analysis in real-life environments where occlusions of the lower-body are particularly problematic. An MSVM model (classification layer) trained with features describing the coordination of the human body across temporal segments in combination with environment descriptors (object affordance) is used to recognize each sub-activity. The classifier was assessed using a five-fold cross-validation method, and it gave good performances in terms of precision (P = 0.81), recall (R = 0.7), accuracy (A = 0.944) and specificity (S = 0.96). To interpret the sequence of the elementary actions and understand the activity, we proposed the use of DHMM models, with the maximum likelihood parameter estimated using the Baum-Welch algorithm. The proposed DHMMs approach achieved P = 0.82, R = 0.76, A = 0.95 and S = 0.97. The framework assessment was performed on the Cornell Activity Dataset (CAD-120) [1]). The results obtained using our method are comparable with those obtained in [2], but it exploits a considerably reduced number of features for the classification (25 versus 201). This proves the relevance of the model-based approach used in conjunction the dynamic simulation, as well as the effectiveness of the combination of the selected features to describe the body coordination.
In the future, we intend to assess the proposed method for data collection by using a mobile platform while tracking the person as introduced in [35], with the aim verifying the hypothesis that better observability of the human increases the activity recognition rate.
Footnotes
9.
This article is a revised and expanded version of a paper entitled Body motion characterization for human-robot interaction presented at the IARP Conference on bio-inspired robotics, Frascati (Italy), May 14th–15th 2014 [![]() ]. We would like to thank Pauline Maurice and Sovannara Hak for their significant support for the XDE implementation.
]. We would like to thank Pauline Maurice and Sovannara Hak for their significant support for the XDE implementation.