
Abstract
Understanding human activity is a crucial aspect of developing intelligent robots, particularly in the domain of human-robot collaboration. Nevertheless, existing systems encounter challenges such as over-segmentation, attributed to errors in the up-sampling process of the decoder. In response, we introduce a promising solution: the Temporal Fusion Graph Convolutional Network. This innovative approach aims to rectify the inadequate boundary estimation of individual actions within an activity stream and mitigate the issue of over-segmentation in the temporal dimension. Moreover, systems leveraging human activity recognition frameworks for decision-making necessitate more than just the identification of actions. They require a confidence value indicative of the certainty regarding the correspondence between observations and training examples. This is crucial to prevent overly confident responses to unforeseen scenarios that were not part of the training data and may have resulted in mismatches due to weak similarity measures within the system. To address this, we propose the incorporation of a Spectral Normalized Residual connection aimed at enhancing efficient estimation of novelty in observations. This innovative approach ensures the preservation of input distance within the feature space by imposing constraints on the maximum gradients of weight updates. By limiting these gradients, we promote a more robust handling of novel situations, thereby mitigating the risks associated with overconfidence. Our methodology involves the use of a Gaussian process to quantify the distance in feature space. The final model is evaluated on two challenging public datasets in the field of human-object interaction recognition, that is, Bimanual Actions and IKEA Assembly datasets, and outperforms popular existing methods in terms of action recognition and segmentation accuracy as well as out-of-distribution detection.
Keywords
1. Introduction
Understanding Human-Object Interactions plays an important role in intelligent systems, especially for robots to learn from demonstrations and collaborate with humans, which requires not only recognizing and segmenting interaction relations per frame but also quantifying prediction uncertainty.
The quality of an action recognition system relies on the identification of cues that define the label of an action, as well as the spatial-temporal relations that define the boundaries between consecutive actions in a task. In our previous work (Xing and Burschka, 2022b), we formulated representations for activities within spatio-temporal graphs. These graphs feature human skeleton joints and the central points of bounding boxes encapsulating objects as graph nodes, where graph edges signify the dynamic relationships between these nodes. Sub-activities are recognized and segmented frame-wise by analyzing the dynamic connections between graph nodes. In that work, we have proven that the attention-based Graph Convolutional Network (GCN) is one of the most promising solutions to process dynamic HOI graph relations. It adaptively updates the correlations between nodes through an attention mechanism, and iteratively parses features in spatial and temporal dimensions. In conjunction with a temporal pyramid pooling (TPP) decoder, the processed graph features underwent further upsampling to revert to the original temporal scale. Subsequently, the resultant graph sequences were classified and segmented frame by frame. However, directly interpolating temporal pooling features diminishes the smoothness and accuracy of segmentation. Overcoming segmentation inaccuracies and over-segmentation in the temporal dimension remains challenging for researchers. Building upon prior successful methodologies, the present work adopts the encoder-decoder framework, and leverages attention-based graph convolutional networks to analyze dynamic graph features, with a specific focus on mitigating the over-segmentation issue.
In order to improve the HOI segmentation performance, we propose a novel Temporal Fusion Graph Convolutional Network (TFGCN), which consists of an attention-based graph convolutional encoder and a newly designed temporal fusion (TF) decoder. The new decoder extracts global features through multiple parallel temporal-pyramid-pooling blocks and enriches temporal features by fusing high-dimensional features from the encoder to processed low-dimensional features. The experimental results on public datasets show better performance in terms of recognition accuracy and preventing boundary shifts and over-segmentation. However, learning-based models are commonly overconfident in wrong predictions, while real scenarios have many unexpected situations, such as noise and unknown data. These factors increase the risk and difficulty of the application. Therefore, the detection of novel human actions is necessary for the implementation of our model.
Multi-object tracking algorithms give inspiration on how to solve the problem, which typically assigns IDs based on the distance between representation features and the existing feature space (Wojke and Bewley, 2018). In other words, it requires the model to be distance-aware in the representation space (Liu et al., 2020a), as expressed as follows:
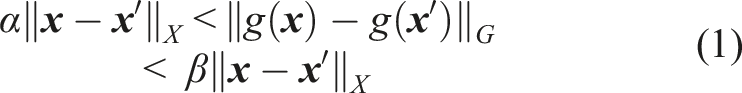
Traditional cascaded convolutional networks provide an upper bound for the hidden representation space distance through normalization and activation functions (Ruan et al., 2018). However, they suffer from the problem of exploding and vanishing gradients.
Residual connections show the ability to compensate for the gradient problems (Veit et al., 2016), but lead to a higher bound range and indistinguishable features in the representation space for OOD detection. In order to preserve the meaningful isometric property in our deterministic model, we introduce a Spectral Normalized Residual (SN-Res) connection, which places an upper Lipschitz constraint on the residual flow. We form an Uncertainty Quantified Temporal Fusion Graph Convolution Network (UQ-TFGCN) with this novel construction, in which the hidden representation space is restricted to a reasonable region. The final labels of the unknown data, along with their similarity to known data, are predicted using maximum likelihood estimation within a Gaussian Process (GP) kernel.
Overall, the technical contributions of the paper are: • we propose a Temporal Fusion Graph Convolution Network (TFGCN) that utilizes a novel temporal feature fusion decoder to enhance the capabilities of Graph Convolutional Networks (GCNs) to understand human-object interaction; • We find that residual connections prove advantageous in maintaining input distances within a familiar space, and we enhance the capability to detect out-of-distribution instances by incorporating spectral normalization of residual connections. We investigate the impact of the spectral normalization coefficient on the accuracy and out-of-distribution detection performance. • we evaluate our model on two challenging, public HOI datasets. Compared to other current action recognition and segmentation approaches, our model achieves the best performance on both datasets in terms of accuracy and uncertainty estimation.
2. Related work
Graph convolutional networks have evolved rapidly in recent years in the field of understanding human activities. The following section briefly introduces the most relevant graph convolutional networks, human-object-interaction understanding methods, and uncertainty quantification methods. Certain sections on graph convolutional networks and human-object interaction understanding are adapted from our prior work (Xing and Burschka, 2022b).
2.1. Graph convolution networks
Recently, Graph Convolution Networks (GCNs) have been successfully implemented in the field of human action recognition with structured representations.
The GCNs can be categorized into two classes: spatial and spectral. The spatial GCNs operate the graph convolutional kernels directly on spatial graph nodes and their neighborhoods. Yan et al. (2018) proposed a Spatial-Temporal Graph Convolutional Network (ST-GCN), which extracts spatial features from the skeleton joints and their naturally connected neighbors and temporal features from the same joints in consecutive frames. Shi et al. (2019) introduced a two-stream adaptive Graph Convolutional Network (2s-AGCN) based on ST-GCN, which adopted an initial attention mechanism in spatial layers to adaptively update the adjacency matrix for multi-input streams (skeleton joints and bones). Chen et al. (2021) proposed a Channel-wise Topology Refinement Graph Convolution Network (CTR-GCN) that refines a spatial attention mechanism on channel dimension to efficiently learn dynamical features in different channels. Xing and Burschka (2022a) introduced a hybrid attention-based graph convolutional network (HA-GCN), which mixes two attention mechanisms to enrich graph features from different input streams. Ling et al. (2023) introduced a bi-stream (joint and bone) spatial graph convolutional network to detect eye contact for conveying information and intent in wild environments.
The spectral GCNs consider the graph convolution in the form of spectral analysis (Li et al., 2016). Henaff et al. (2015) developed a spectral network incorporating with graph neural network for the general classification task. Kipf and Welling (2017) extends the spectral convolutional network further in the field of semi-supervised learning on graph-structured data.
This work follows the spatial GCNs adopts the aforementioned methods one by one and compares their performance with different encoder-decoder setups.
2.2. Understanding of human-object-interaction
The understanding of Human-Object-Interaction (HOI) plays a pivotal role in understanding human activities, which involves the segmentation and recognition of sub-activities frame-wise through the analysis of interactive relations between human and objects.
Feichtenhofer et al. (2016) introduced a two-stream 2D CNN that utilizes features from both appearances in still images and stacks of optical flow. Carreira and Zisserman (2017) proposed a two-stream inflated 3D CNN (I3D) that improves the ability of 2D CNNs in extracting spatial-temporal features.
With the successful applications of Graph Neural Networks (GCNs) in action recognition, many recent works represent human and objects as nodes in a graph and extract their relation features by GCNs. Dreher et al. (2019) presented a graph network that uses three multi-layer perceptron (MLP) blocks to update nodes, edges, and aggregation features from the graph representation of HOI. The authors also published their HOI dataset, namely, the Bimanual Actions dataset. Asynchronous-Sparse Interaction Graph Networks (ASSIGN) Morais et al. (2021) is another attempt at the HOI recognition and segmentation task. It used a recurrent graph network that automatically detects the structure of interaction events associated with entities of a sequence of interactions, which are defined as human and objects in a scene. More recently, Xing and Burschka (2022b) proposed a Pyramid Graph Convolutional Network (PGCN) that adaptively updates the human-object relations by attention mask and upsamples the HOI features to the original time scale by a novel temporal pyramid pooling (TPP) decoder. However, directly interpolating temporal pooling features reduces the smoothness and accuracy of segmentation. Lagamtzis et al. (2023) exploited spatial and temporal hand-object relations by leveraging an encoder-decoder framework with graph neural networks. The network can recognize the hand action label and forecast the next motion by a multi-layer perceptron module. However, the authors represented human appearance features by a single graph node, which weakens the performance of action recognition. Tran et al. (2023) modeled human-object interactions through a long-term activity route (persistent process) and short-term sub-actions (transient processes). Instead of recognizing action labels, authors focus on the 2D/3D trajectory prediction of the whole activity. Besides single-person action recognition, multi-person involved HOI understanding is another important task. To address the occlusion issue in multi-person actions, Qiao et al. (2022) combined both visual and geometry HOI features together and processed features through a Two-level Geometric feature-informed Graph Convolutional Network (2G-GCN). Reily et al. (2022) represented individual actions as graph nodes, interactions between people as graph edges, and finally extracted team intentions from graph features.
Most existing recurrent networks exhibit commendable real-time performance yet are hindered by limited short-term memory. The encoder-decoder structure provides a promising solution for this problem by facilitating a comprehensive fieldview. Compared with multi-person intent recognition, single-person action recognition is a more fundamental and challenging task. Motivated by the successful implementation of the temporal pooling decoder, this study adopts the encoder-decoder structure to enhance the performance of single-performer action understanding. The approach involves extracting global features by the temporal pooling module and fusing condensed features into the temporally pooled features.
2.3. Uncertainty quantification
Most existing learning-based classification methods have high accuracy in in-distribution datasets, but suffer from overconfidence in wrong predictions and barely detect out-of-distribution samples. Many promising works train Bayesian neural networks to approximate uncertainty(Alex Kendall and Cipolla, 2017; Blundell et al., 2015), but it is difficult to converge in a large range of data. Lakshminarayanan et al. (2017) introduced a method that estimates the prediction uncertainty by ensembling predictions from multiple models. Gal and Ghahramani (2016) proposed Monte Carlo Dropout (MC-Dropout) to approximate the Bayesian probability. Due to their reliability, these two methods are usually considered as baselines for uncertainty quantification, although they are time-consuming.
Recently, deterministic network uncertainty quantification (DUQ) methods have been proposed to efficiently estimate the prediction uncertainty in a single forward pass. The key factor is distance awareness in the representation space. Miyato et al. (2018) introduced Spectral Normalization to regulate weight update gradients in a generative network. Van Amersfoort et al. (2020) adopted two sides Lipschitz constraints to enforce the gradient smoothness and sensitivity to meaningful changes. Following the two sides Lipschitz constraints, Liu et al. (2020a) utilized the spectral normalized kernel instead of normal convolutional kernels on the mainstream to constrain the weight update max gradient and guarantee distance awareness in feature space. However, general Spectral Normalization models exhibit a substantial number of trainable parameters and necessitate considerable computational resources.
In this study, we observe that the residual connection contributes to maintaining input distance within proximity and has fewer trainable parameters compared to the mainstream. However, it results in an elevation of the Lipschitz bounds. To enhance the efficacy of distance awareness in the feature space, we employ Spectral Normalization on the residual connections (SN-Res). Additional empirical evidence supporting this observation is provided in the experiment section.
To measure the uncertainty, the Gaussian Process has been widely implemented. Liu et al. (2020a) approximated the Gaussian Process prior distribution by a learnable neural kernel and further obtained the likelihood per the Laplace approximation. Although it improved the efficiency of the computation of likelihood, but damaged the accuracy of the likelihood. Li et al. (2021) improved the flash radiography reconstruction by removing the outliers with high uncertainty, which is estimated by the Gaussian probability density function with mean zero and a measured covariance matrix. Su et al. (2023) utilized a multivariate Gaussian distribution to estimate the uncertainty of each corner of predicted bounding boxes in a LiDAR point cloud, and improved the performance of object detection for autonomous vehicles.
Inspired by these previous works, we follow the uncertainty quantification techniques for deterministic networks and utilize the multivariate Gaussian distribution to model the uncertainty and measure it through its likelihood.
3. Uncertainty quantified temporal-fusion graph convolutional network
In this section, we introduce an Uncertainty Quantified Temporal Fusion Graph Convolutional Network (UQ-TFGCN) with Spectral Normalized Residual connection, which balances the distance-preserving ability in representation space and high-accuracy performance.
3.1. Temporal-fusion graph convolutional network
The basic idea of temporal fusion graph convolutional network is inspired by image segmentation approaches, which predict the semantic meaning of each pixel unit by extracting global spatial features and mapping it to the corresponding spatial position. In contrast, we feed the graph representations of HOI instead of images into the network, since the graph representation is insensitive to the background and appearance noise. Our temporal fusion graph convolutional network processes the graph features not only in the spatial dimension but also in the temporal dimension. These features are compressed into a low temporal dimensional space by the encoder and upsampled to the original temporal dimension by the decoder.
3.1.1. Graph construction
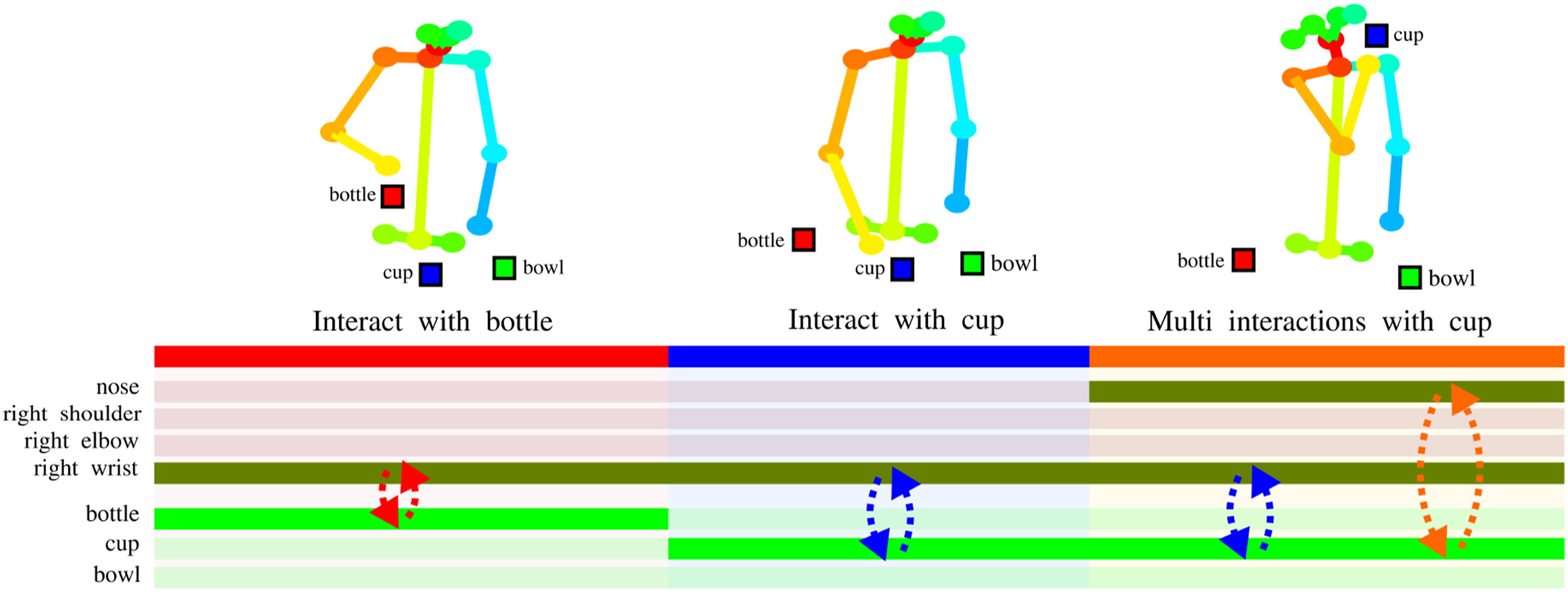
In this work, we focus on the interaction between a single-performer and multiple objects. Most of the human body can be conceptualized as an articulated system with joint nodes connected by bones, and most objects can be represented by central points. Therefore, the human-object-interaction (HOI) scenario can be reduced to a graph with nodes and edges, as shown in Figure 1(a). In an HOI graph, each node has three types of edges, namely, inward, outward, and self-connecting edges (Shi et al., 2019). The edges of human skeleton are defined by the pose estimation model, which is with inward connections from each joint to adjacent joints that are closer to the center of the body (neck), and outward connections in reverse, as shown in Figure 1(b). However, object-related connections (human-objects and objects-objects) are challenging due to the dynamic nature of the scene. As illustrated in Figure 2, dynamic relationships are evident in the process of drinking. The pertinent targets, including objects and skeleton joints, are highlighted along the time axis to depict sub-actions. Specifically, the right wrist node sequentially interacts with the bottle and cup node. In the final phase of the action, the cup node concurrently engages with both the right wrist and nose. Traditional spatial graphs are predefined based on prior knowledge, which barely accommodates these dynamic relationships. Hence, in this work, we employ a spatial attention mechanism in the encoder to adaptively update dynamic edges. Simplify the human-object-interaction into a graph representation from the work (Xing and Burschka, 2022b): (a) spatial graph with nodes (blue) and edges (orange) for an example in the Bimanual Actions dataset (Dreher et al., 2019); (b) initial inwards adjacent matrix with skeleton inward edges (orange block), empty human-objects (red blocks) and objects-objects edges (blue block). Dynamic relations (depicted by dashed arrows) exist between the body parts and objects involved in the action of drinking, with the human represented by a skeleton and objects represented by square boxes. The highlighted time bar signifies active participation in the interaction by either objects or skeleton joints.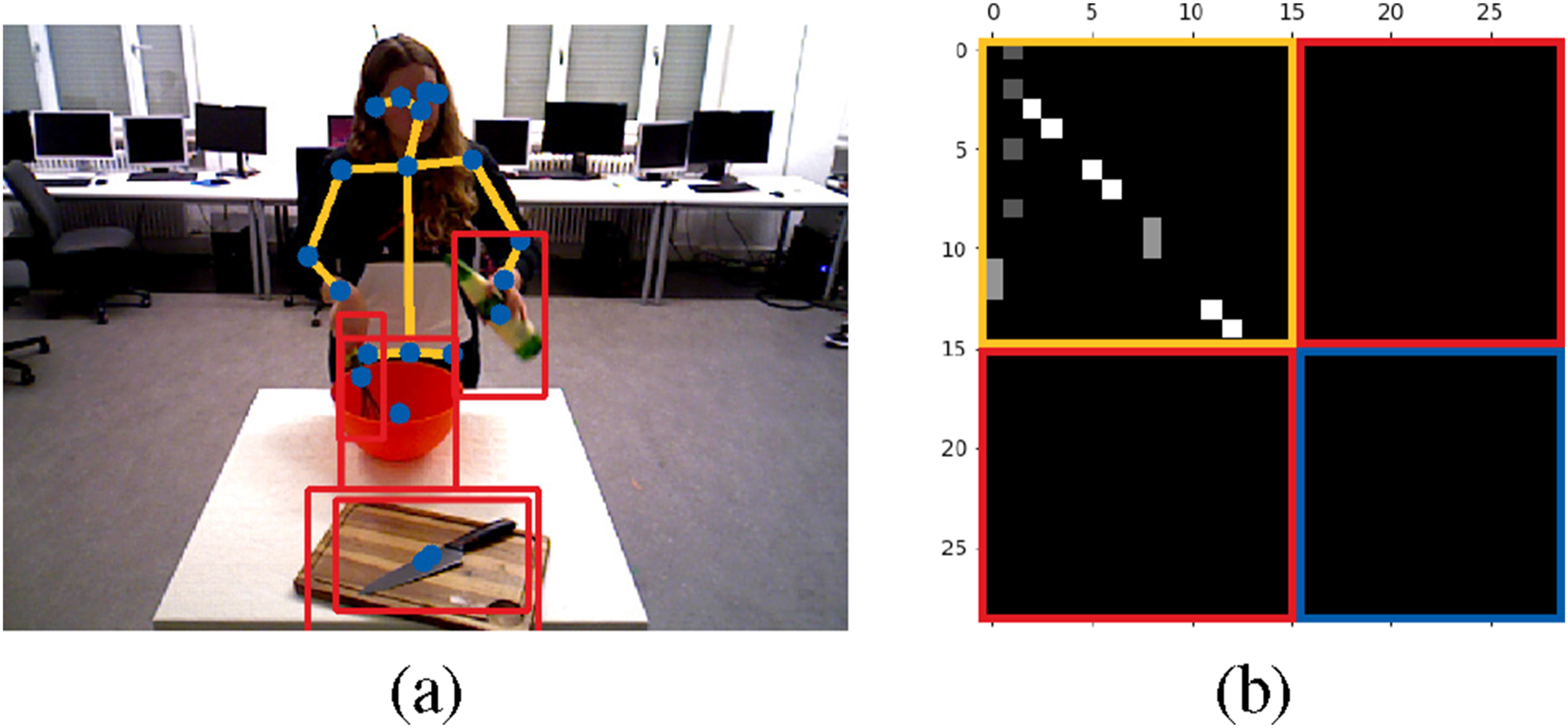
3.1.2. Encoder
As shown in Figure 3(a), the core theory of attention mechanism is updating the predefined adjacent matrix by adding global correlations—the attention map that can generally be calculated in the following way: Structure of the Spatial-Temporal Graph Convolutional block. (a) A spatial graph convolutional layer with the attention map 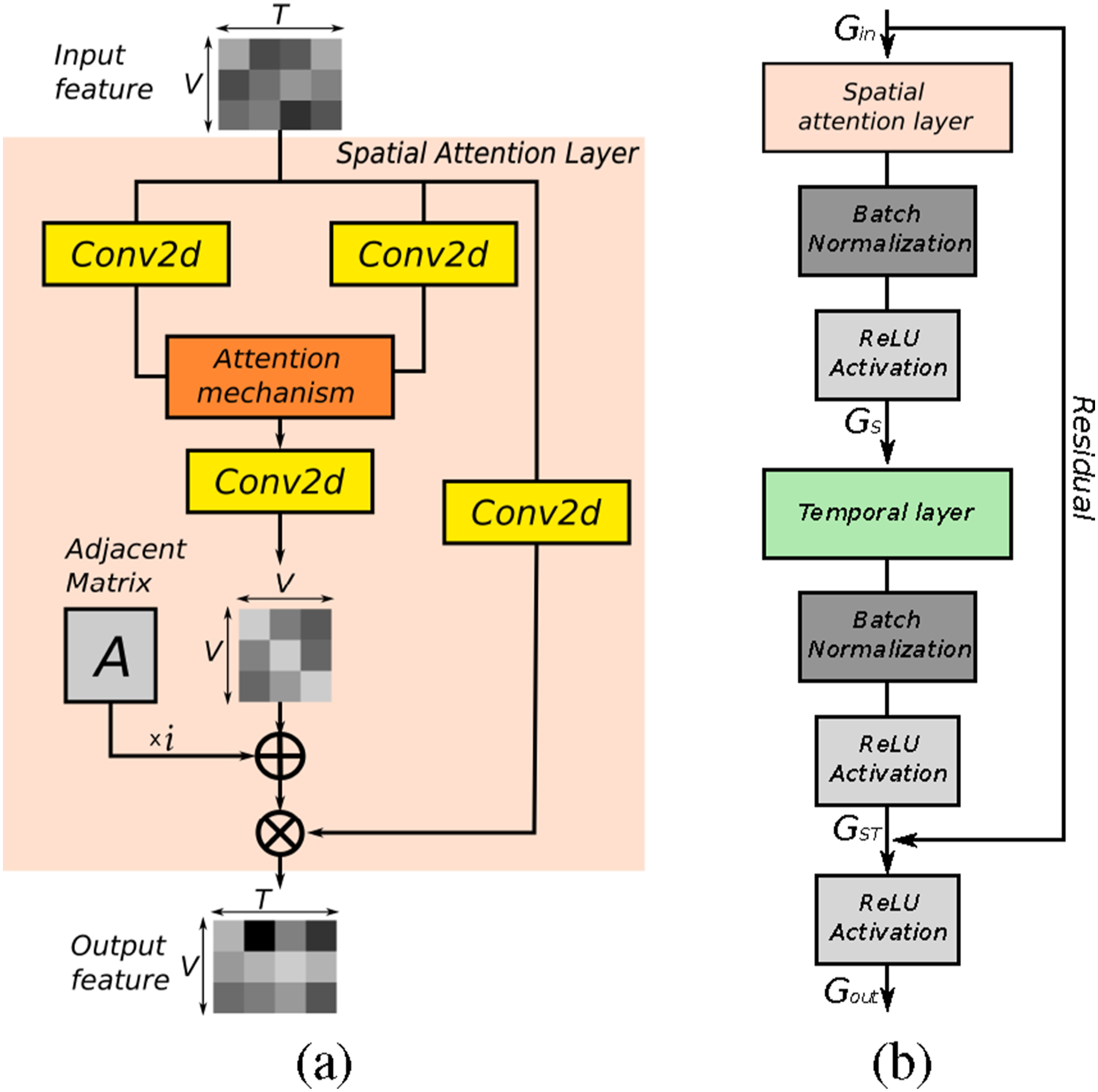
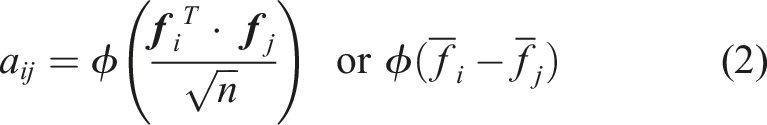
Given an input graph
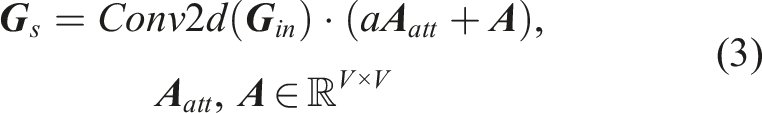
The spatial graph feature is further processed by a temporal graph convolutional layer to obtain the spatio-temporal processed feature map
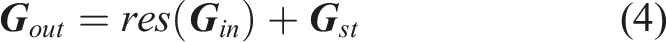
To achieve the best performance, we compare the effect using several popular existing attention-based graph convolutional networks as encoders. The ST-GCN (Yan et al., 2018) is implemented as a baseline without an attention mechanism. The AGCN (Shi et al., 2019) is a variant of ST-GCN that adds a product attention mechanism to the spatial graph convolution layer. The encoder of PGCN (Xing and Burschka, 2022b) passes the attention map through an additional 1D convolutional layer to adjust its weights. The CTR-GCN (Chen et al., 2021) refines the spatial attention mechanism in channel dimension to learn different dynamical features in each channel. The HA-GCN (Xing and Burschka, 2022a) proposes a hybrid attention mechanism that mixes product and subtract attention maps together to enrich the dynamic features of different input streams. In the temporal dimension, the ST-GCN, AGCN, and PGCN process features by a single 2D convolutional kernel, while HA-GCN and CTR-GCN employ multi-scale temporal convolutional kernel introduced in the work (Liu et al., 2020b).
The encoder is formed by concatenating 10 aforementioned basic spatial-temporal graph convolutional blocks with different channel sizes.
3.1.3. Decoder
In order to upsample the condensed features back to the original time scale and predict action labels for each frame, we propose a novel temporal feature fusion decoder. As shown in Figure 4, the decoder feature map is subscribed separately by two blocks, namely, temporal feature extractor and feature fusion. The temporal feature extractor further compresses and extracts temporal features through three serial linear bottleneck layers (Sandler et al., 2018) and four parallel temporal pyramid average pooling (Xing and Burschka, 2022b) blocks. The four averaged feature outputs are concatenated, passed through a 2D convolutional kernel, and merged with a temporal residual connection. In the feature fusion block, the condensed feature is upsampled to the original time scale through one interpolate module. A depth-wise separable convolutional (DS Conv) (Chollet, 2017) and 2D convolutional layers are employed to process the interpolated features. In the residual branch, the encoded condensed features are firstly processed by a 2D convolutional kernel and interpolated to the same size as in the main branch. The residual connection brings original high-dimensional features into the mainstream and fuses them with the low-dimensional features, which contributes to the performance accuracy. Framework of temporal fusion decoder including three blocks: temporal feature extractor, feature fusion, and classifier. The “Concate” block concatenates all feature maps from temporal pyramid pooling (TPP) layers into one. “DS Conv” represents a depth-wise 2D convolutional layer.
Furthermore, since the structure has good compatibility, we switch the proposed decoder with two existing upsampling methods, that is, Fast-FCN (Wu et al., 2019) and Temporal-Pyramid-Pooling (TPP) (Xing and Burschka, 2022b). The Fast-FCN was originally introduced to solve the task of image segmentation and achieved promising results by jointly upsampling three processed feature maps from different depths of the encoder. To make the model suitable for action segmentation tasks, we convert the joint upsampling module to upsampling only on the time axis. The TPP is another recent decoder, which added four parallel temporal pyramid pooling modules after a joint upsampling block. By utilizing dilated convolutional kernels with different scales, the TPP has a wide range of respective fields and achieves promising performance in action segmentation.
In the classifier, the fused features are first compressed in the spatial dimension by two depth-wise separable kernels and then mapped to the class space in the channel dimension.
3.2. Distance-aware feature space by spectral normalized residual connection
The residual connections improve the prediction performance by collapsing the features. However, in doing so, the distance in representation space is blurred, and the ability to detect out-of-distribution is further impaired. Hence, we propose a Spectral Normalized Residual connection to replace the traditional residual connection in the graph convolutional models, in which the mainstream has cascaded layers.
Considering a traditional residual connection using one convolutional kernel, where r(

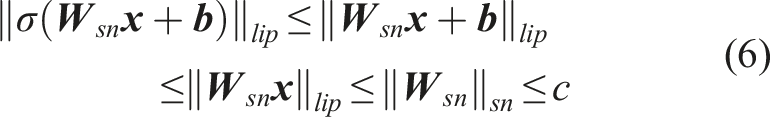
3.3. Feature space distance measurement using Gaussian process
By implementing the aforementioned model, we get a distance-aware feature space. We collect the high-dimensional feature of all known data (trainset) output by the second separable kernel in the classier as shown in Figure 5, and fit a multivariate normal distribution per class to quantify the prediction distance in the feature space, as follows: The Gaussian Process (GP) kernel collects high-dimensional features from the network before the predictor and gives predictions with probabilities.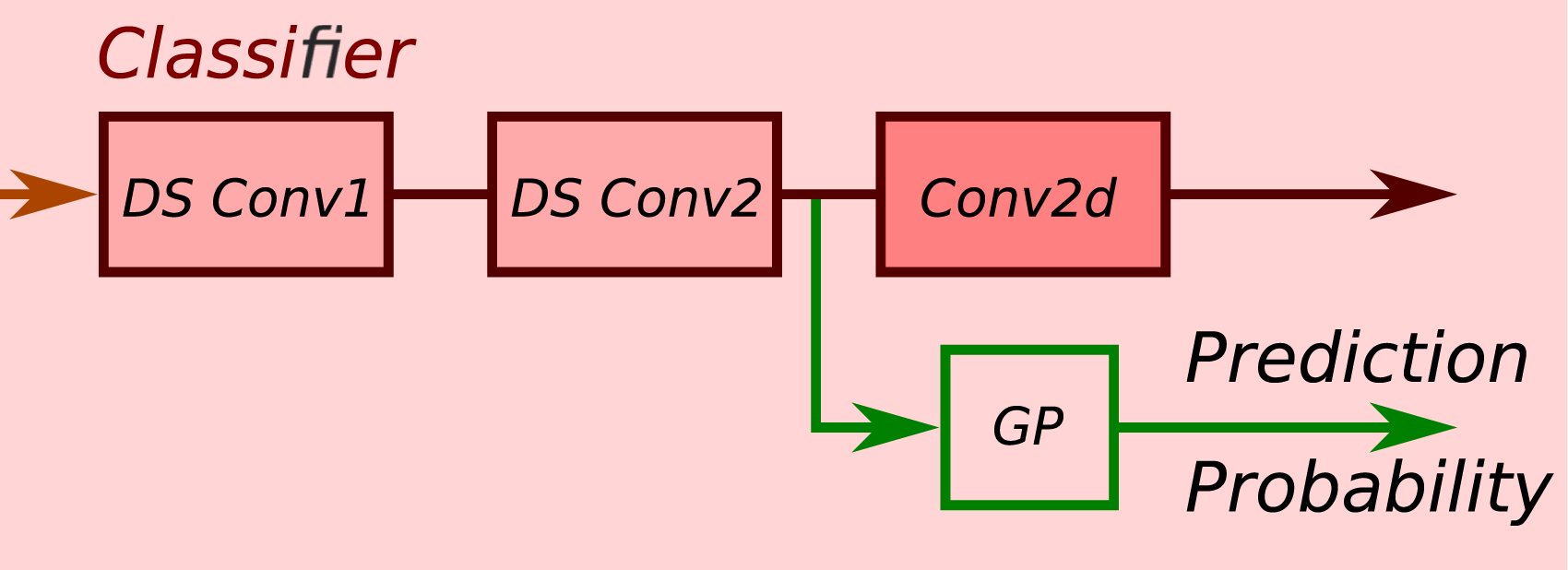
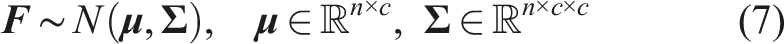
In the evaluation phase, we calculate the marginal likelihood of the unknown feature representation
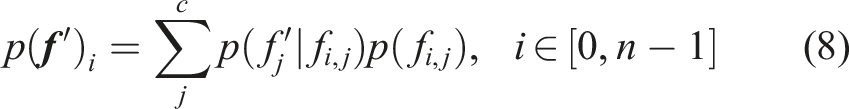
In comparison, we utilize several existing measuring modules: the exponentiated distance (Van Amersfoort et al., 2020) and Laplace-approximated neural Gaussian process (Liu et al., 2020a).
4. Evaluations and results
To evaluate the performance of the proposed UQ-TFGCN model, we experiment on two public challenging human-object interaction datasets: Bimanual Actions dataset (Dreher et al., 2019) and IKEA Assembly dataset (Ben-Shabat et al., 2021). A detailed ablation study is performed on the Bimanual Actions dataset (Dreher et al., 2019) to examine the contributions of the proposed model components. Then, the final model is evaluated on both datasets and the results are compared with other state-of-the-art methods.
All experiments are conducted on the PyTorch deep learning framework with a single NVIDIA-2080ti GPU. The stochastic gradient descent (SGD) with Nesterov momentum (0.9) is selected as the optimization strategy. A 16 batch size is used in the training process, and a 1 batch size is applied for testing each entire record. Cross-entropy is adopted as the loss function for the backpropagation. The weight decay is set to 0.0002.
4.1. Evaluation metrics
Top 1 accuracy, F1-macro (weighted) score, and macro-recall are selected to evaluate the performance of recognition accuracy. F1@k is used to compare the performance of action segmentation, and k is set to 10%, 25%, 50%, same as in the work (Xing and Burschka, 2022b). The area under the receiver operating characteristic (AUROC) and the area under the precision-recall curve (AUPRC) metrics are chosen to measure the performance of out-of-distribution (OOD) detection. Since the softmax output loses the true feature distance by normalization, we use Gaussian lop probability values of the multivariate model as the measurement score for AUROC and AUPRC. As recommended in the work (Nixon et al., 2019), static calibration error (SCE), adaptive calibration error (ACE), and thresholded adaptive calibration error (TACE) are adopted to measure the calibration error, where the threshold is set as 0.01. The popular expected calibration error (ECE) is additionally compared, although it is designed for binary classification methods.
4.2. Human-object interactions dataset
Bimanual actions dataset (BimActs)
Dreher et al. (2019) was built for human-object interaction detection in daily life environments, which has in total 540 recordings (∼2.30h). Frame-wise predictions of 6 subjects (3D skeletons) and 12 objects (3D bounding boxes) are provided. An evaluation benchmark is recommended by the authors: leave-one-subject-out cross-validation that contains records from one subject for validation and the rest subjects for training. To evaluate distance-aware performance, we create Noisy BimActs as noisy out-of-distribution (OOD), which are with the same number of frames as the original data, but with 50% impulse noise and empty data, respectively. In our experiments, we split each training record into small segments of 120 frames every 10 frames. In the test phase, the entire record of test data is fed into the model without any preprocessing. It should be noted that all noise is introduced at the node level. Thus, 50% empty data indicates that half of the nodes (including skeleton joints and objects) are not detected.
IKEA assembly dataset (IKEA ASM)
Ben-Shabat et al. (2021) is another challenging and complex human-object interaction dataset, which contains 16,764 assembly actions in 32 categories (∼35.27h). 2D skeletons and 2D object bounding boxes are provided for each frame. The authors proposed a cross-environment benchmark, in which the test environments (117 scans) do not appear in the trainset (254 scans) and vice-versa. To evaluate the performance on unknown out-of-distribution detection, we regard the testset of IKEA ASM as a completely out-of-distribution (OOD) to the model trained on the BimActs dataset. The preprocessing of train data is similar to the BimActs dataset but with a segment length of 500 frames per 100 frame gap.
For both the BimActs (Dreher et al., 2019) and IKEA Assembly datasets (Ben-Shabat et al., 2021), The original 3D/2D skeleton and object position data are concatenated along the node dimension. It results in a tensor of shape B × C × T × V, where B denotes the batch size, C represents the number of channels, T corresponds to the number of frames, and V indicates the number of nodes. Before being fed into the model, the data undergoes preprocessing that involves the application of controlled noise in rotation, translation, and scaling. Specifically, rotational noise was introduced by perturbing the data within a range of [−10°, 10°] around the z-axis. Translational adjustments were applied within a range of [−0.2, 0.2] meters or pixels along the x and y axes, and scaling variations were implemented by applying a multiplicative factor between [0.9, 1.1] on both the x and y axes. Note that all x, y, and z axes are in camera or image coordinates.
4.3. Ablation studies
Ablation study of introduced modules in the decoder on the bimanual actions dataset (Dreher et al., 2019).
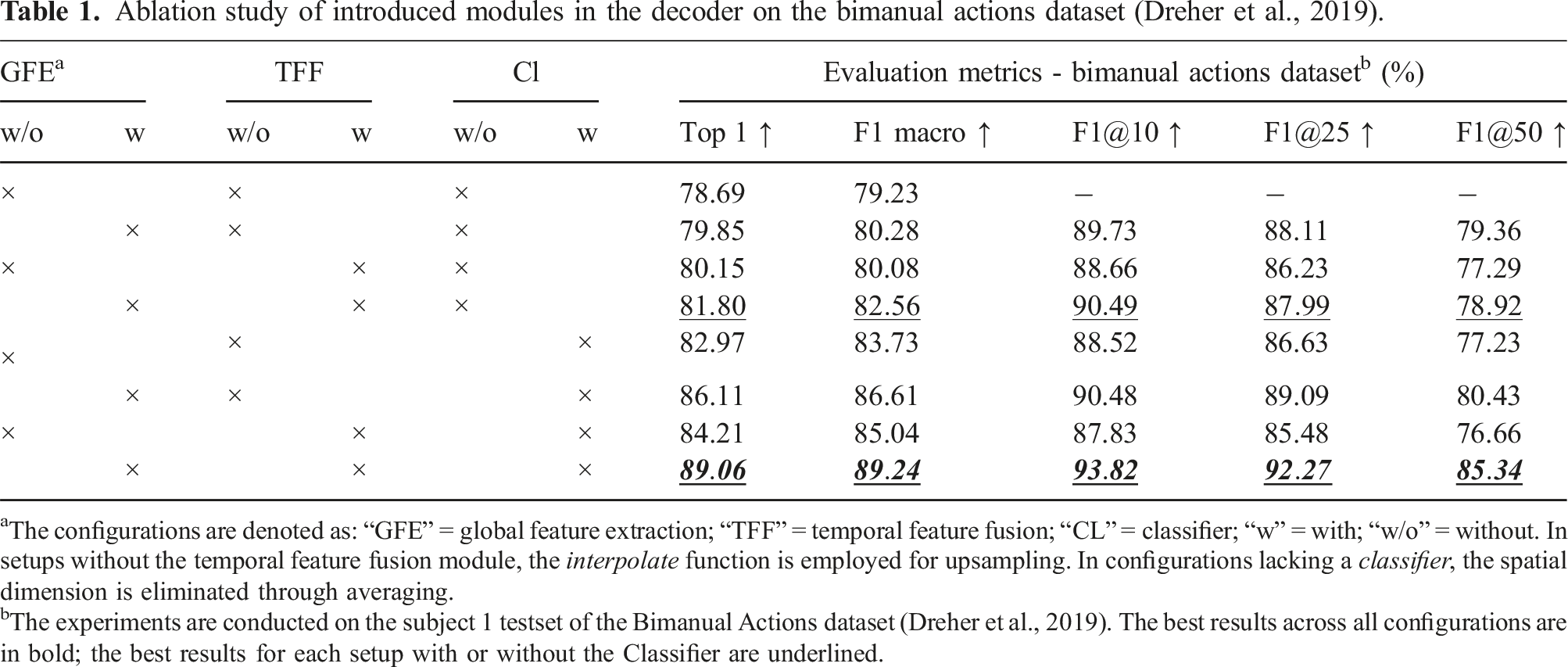
aThe configurations are denoted as: “GFE” = global feature extraction; “TFF” = temporal feature fusion; “CL” = classifier; “w” = with; “w/o” = without. In setups without the temporal feature fusion module, the interpolate function is employed for upsampling. In configurations lacking a classifier, the spatial dimension is eliminated through averaging.
bThe experiments are conducted on the subject 1 testset of the Bimanual Actions dataset (Dreher et al., 2019). The best results across all configurations are in bold; the best results for each setup with or without the Classifier are underlined.
Comparison of encoder-decoder setups on the bimanual actions dataset (Dreher et al., 2019). a
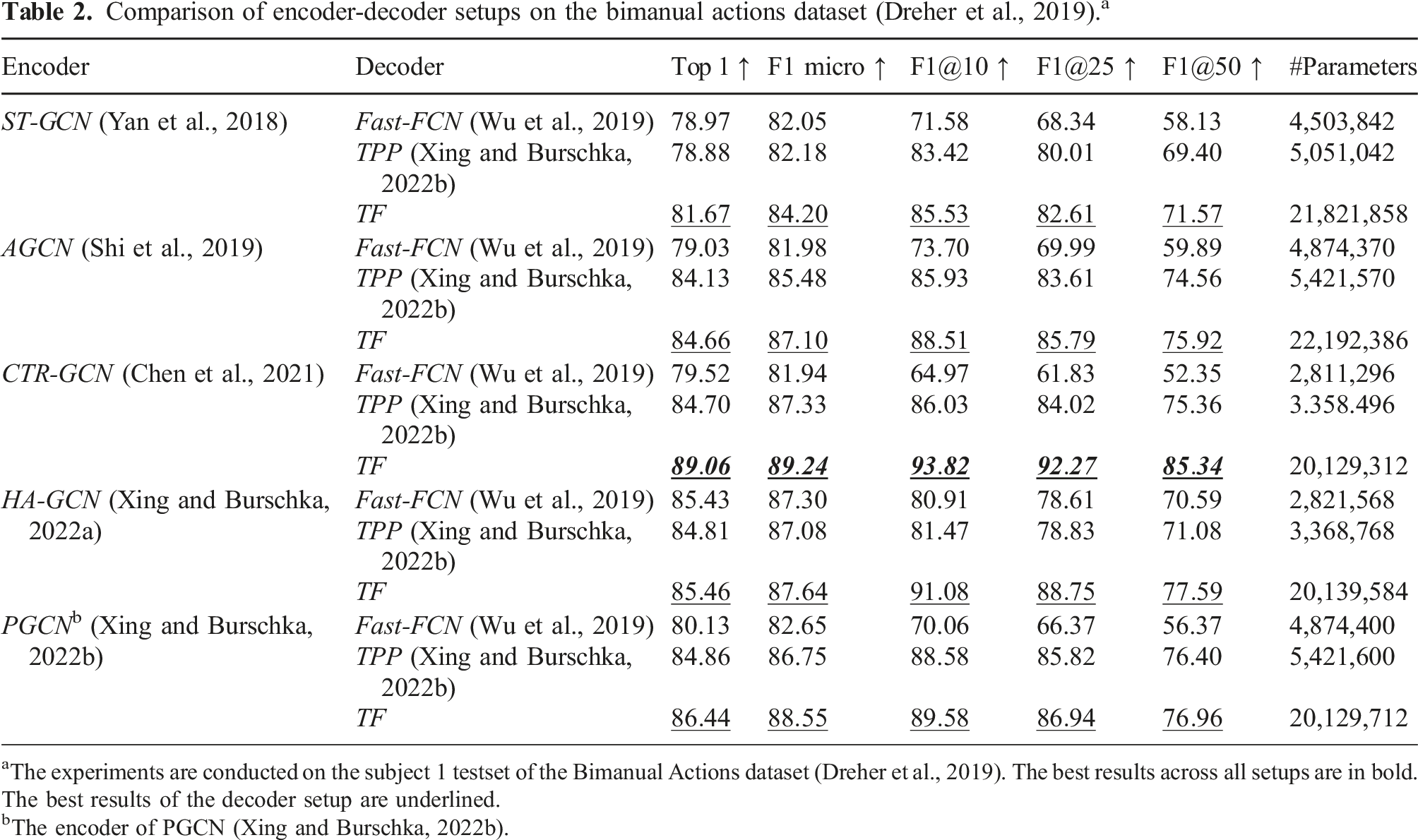
aThe experiments are conducted on the subject 1 testset of the Bimanual Actions dataset (Dreher et al., 2019). The best results across all setups are in bold. The best results of the decoder setup are underlined.
bThe encoder of PGCN (Xing and Burschka, 2022b).
The normalized confusion matrices for the top prediction from the final model are presented in Figure 6. The principal challenge lies in accurately predicting actions such as approach, lift, retreat, and place, particularly when these actions involve interactions with diverse objects. This difficulty is amplified by the use of unstable object detection methods. Furthermore, the actions of approach and retreat typically occur instantaneously, occasionally taking place within 5 frames. Another notable observation is the misclassification of “hold,” while the actual action is “cut.” The misclassification is caused by the utilization of “wrist” joints to represent “hands.” This results in a limited resolution of motion detection and a potential misconception of the action as “hold.” These challenges could be mitigated through the implementation of stable object detection and human pose estimation methods, as well as additional hand pose estimation techniques. Nonetheless, rather than developing perfect algorithms for object detection, human pose estimation, and hand pose estimation, our primary concern revolves around the capability of the feature map to represent the input noise (input distance), and how to quantify the prediction uncertainty. Normalized confusion matrix for frame-wise prediction of accumulative classification correctness over the subject 1 testset on the Bimanual Actions dataset (Dreher et al., 2019).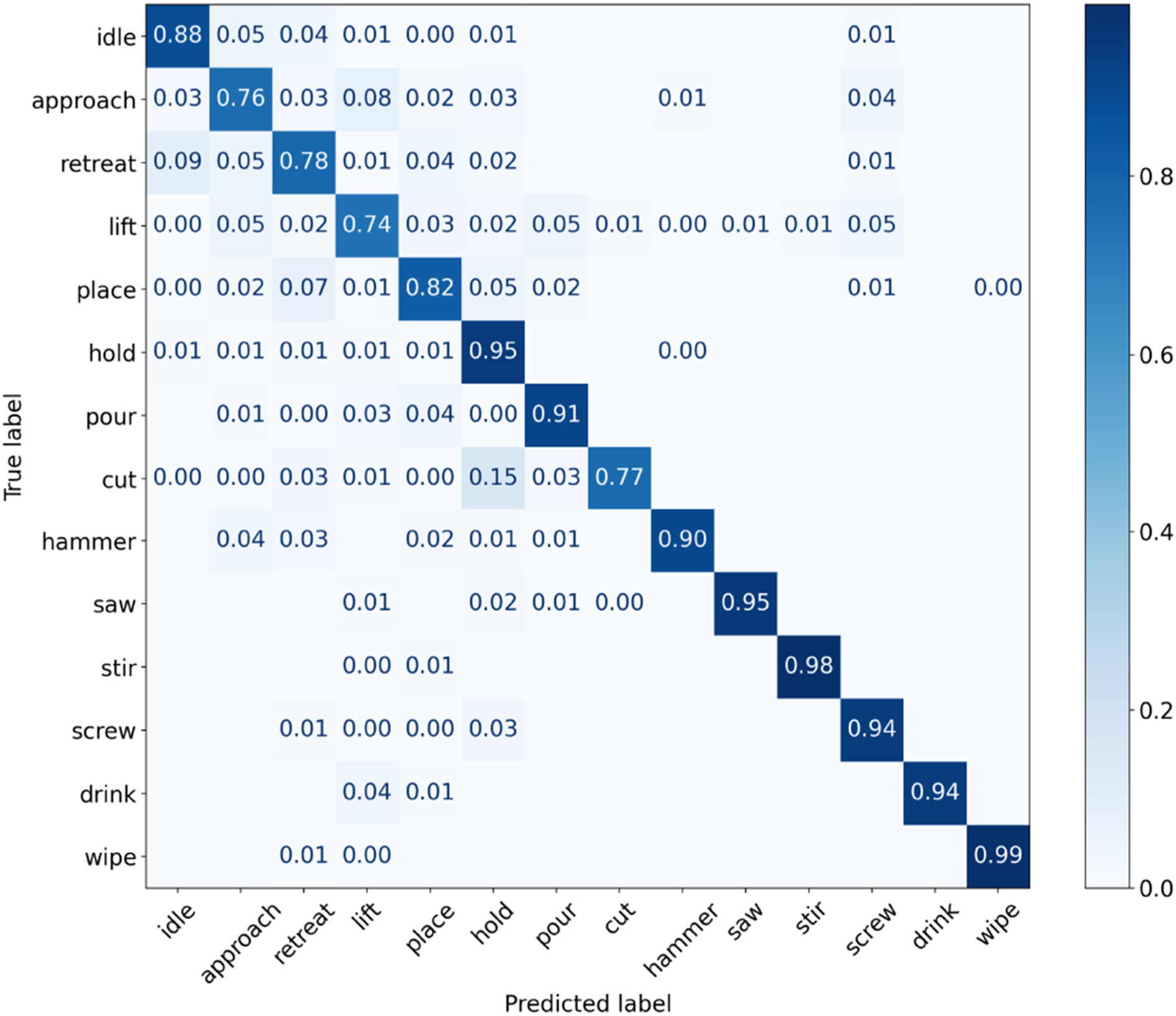
Ablation study of the spectral normalized residual connection and the Gaussian process on the bimanual actions dataset (Dreher et al., 2019).
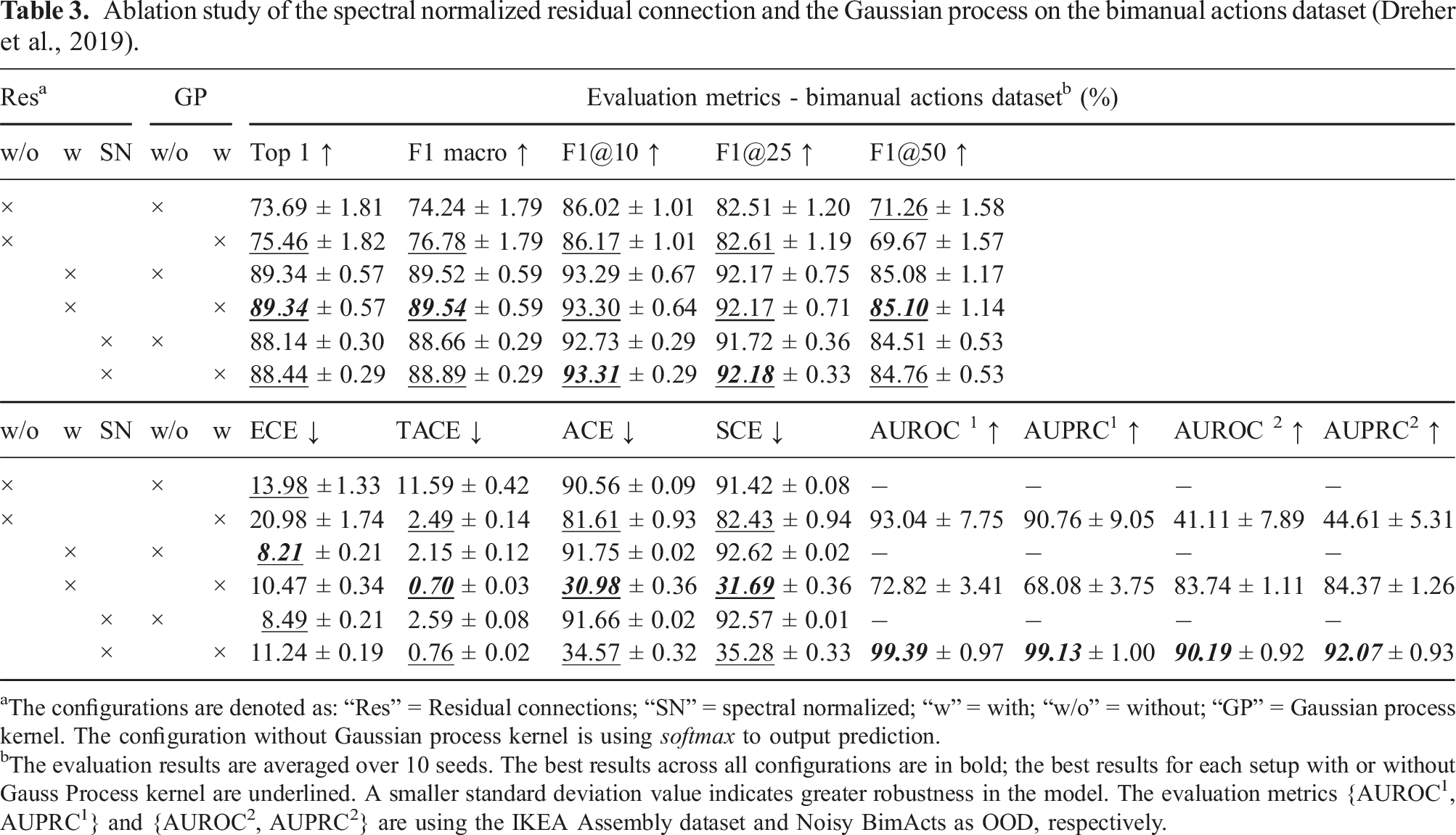
aThe configurations are denoted as: “Res” = Residual connections; “SN” = spectral normalized; “w” = with; “w/o” = without; “GP” = Gaussian process kernel. The configuration without Gaussian process kernel is using softmax to output prediction.
bThe evaluation results are averaged over 10 seeds. The best results across all configurations are in bold; the best results for each setup with or without Gauss Process kernel are underlined. A smaller standard deviation value indicates greater robustness in the model. The evaluation metrics {AUROC1, AUPRC1} and {AUROC2, AUPRC2} are using the IKEA Assembly dataset and Noisy BimActs as OOD, respectively.
The results in Table 3 confirm that the residual connection is of high significance for accurate predictions and accuracy-related performance, such as F1 macro and F1@k. Moreover, the results of the variance demonstrate that the residual connections increase the model stability. However, another remarkable observation is that adding residual connections leads to a smaller feature space distance (AUROC1 and AUPRC1) between the Bimanual Actions testset (in-distribution) and the IKEA testset (out-of-distribution), and a larger feature space distance between the noisy Bimanual Actions (Noisy BimActs) testset and the original testset. The observations confirm that the residual connections shift the bi-Lipschitz bounds to a higher range, which leads to a higher distance to meaningful changes in the input manifold but lower sensitivity to out-of-distribution. Note that, we consider the noisy BimActs to have meaningful changes in the input manifold since it holds 50% of the original data.
The Spectral Normalized Residual connections set a maximum constraint on the upper Lipschitz bound, which enhances the OOD detection while maintaining sensitivity to changes in the manifold. The results can also be observed in Figure 7, where the feature space density is represented in the Gaussian log-probability space. However, it is clear that spectral normalization is a trade-off between preserving feature space distance and high accuracy. In Table 3, the accuracy performance of the spectral normalized model is 1% lower than the model with normal residual connections, while its AUROC and AUPRC achieve the best result. The log-probability distribution of feature space on the Bimanual Actions dataset (Dreher et al., 2019), noisy Bimanual Actions dataset, and the IKEA ASM (Ben-Shabat et al., 2021) datasets.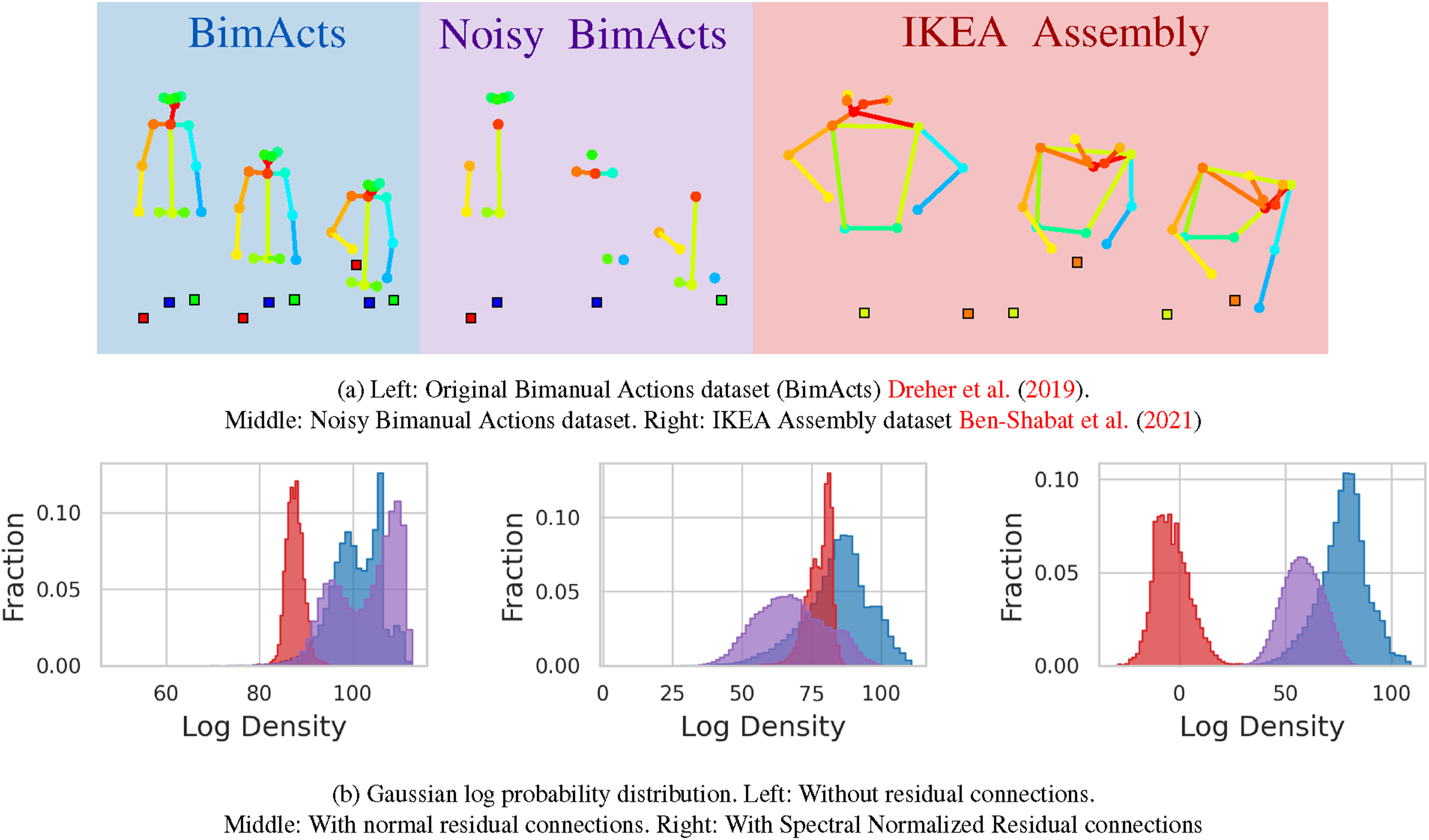
Comparison of coefficient values in spectral normalization function on the bimanual actions dataset (Dreher et al., 2019).
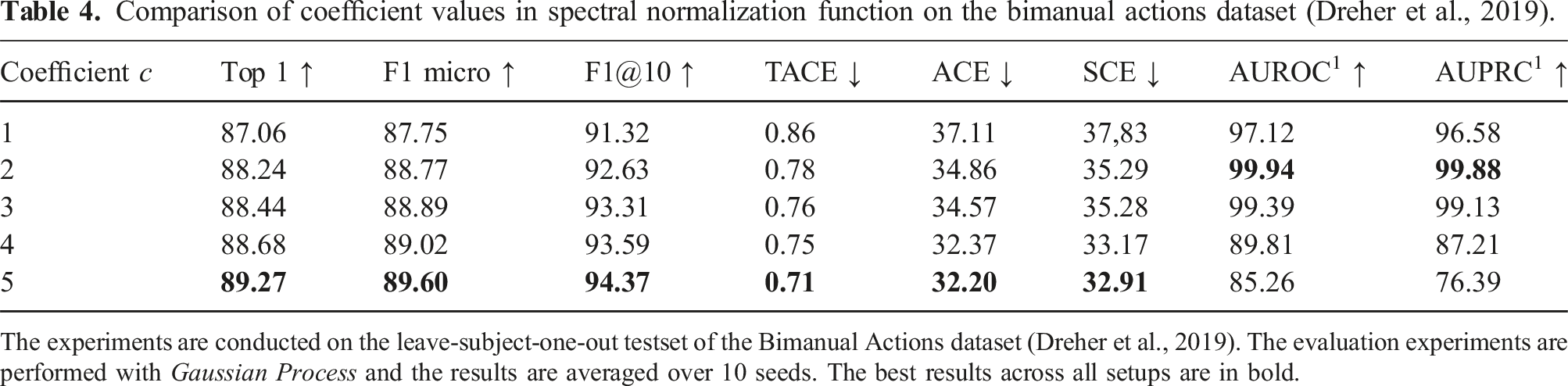
The experiments are conducted on the leave-subject-one-out testset of the Bimanual Actions dataset (Dreher et al., 2019). The evaluation experiments are performed with Gaussian Process and the results are averaged over 10 seeds. The best results across all setups are in bold.
4.4. Comparison with state-of-the-art
Comparison of cross-validation results with state-of-the-art methods on the bimanual actions dataset (Dreher et al., 2019). a
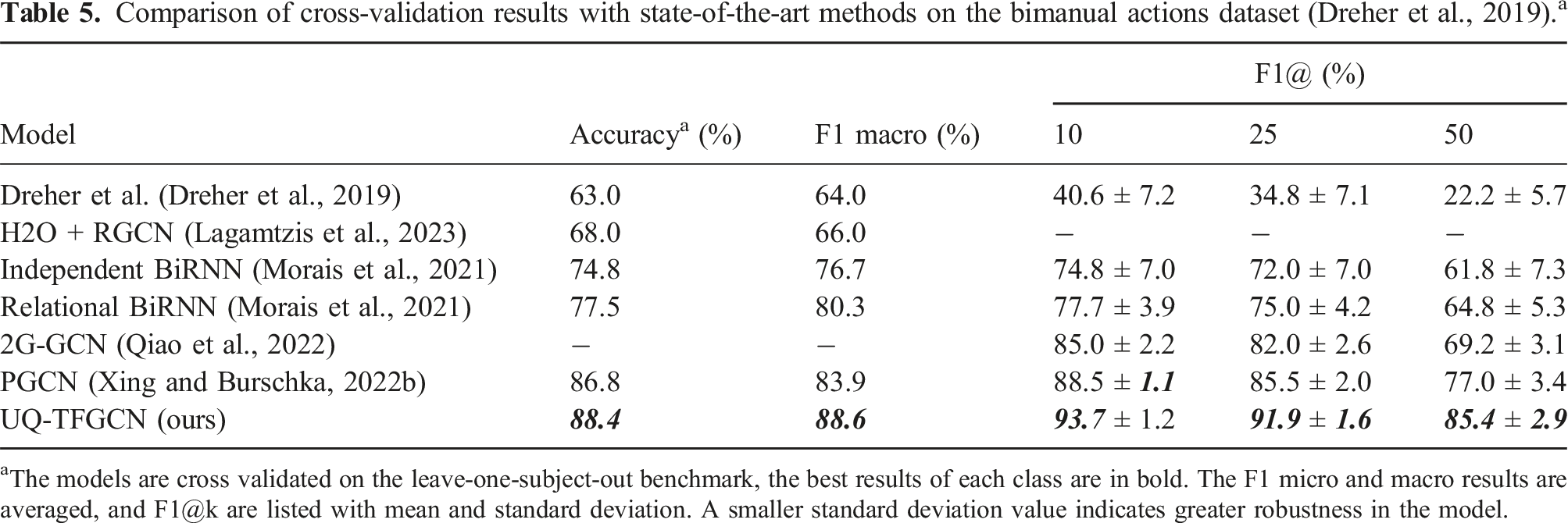
aThe models are cross validated on the leave-one-subject-out benchmark, the best results of each class are in bold. The F1 micro and macro results are averaged, and F1@k are listed with mean and standard deviation. A smaller standard deviation value indicates greater robustness in the model.
Action recognition and segmentation results in terms of top-1 accuracy, macro-recall, and F1@k on the IKEA assembly dataset (Ben-Shabat et al., 2021).
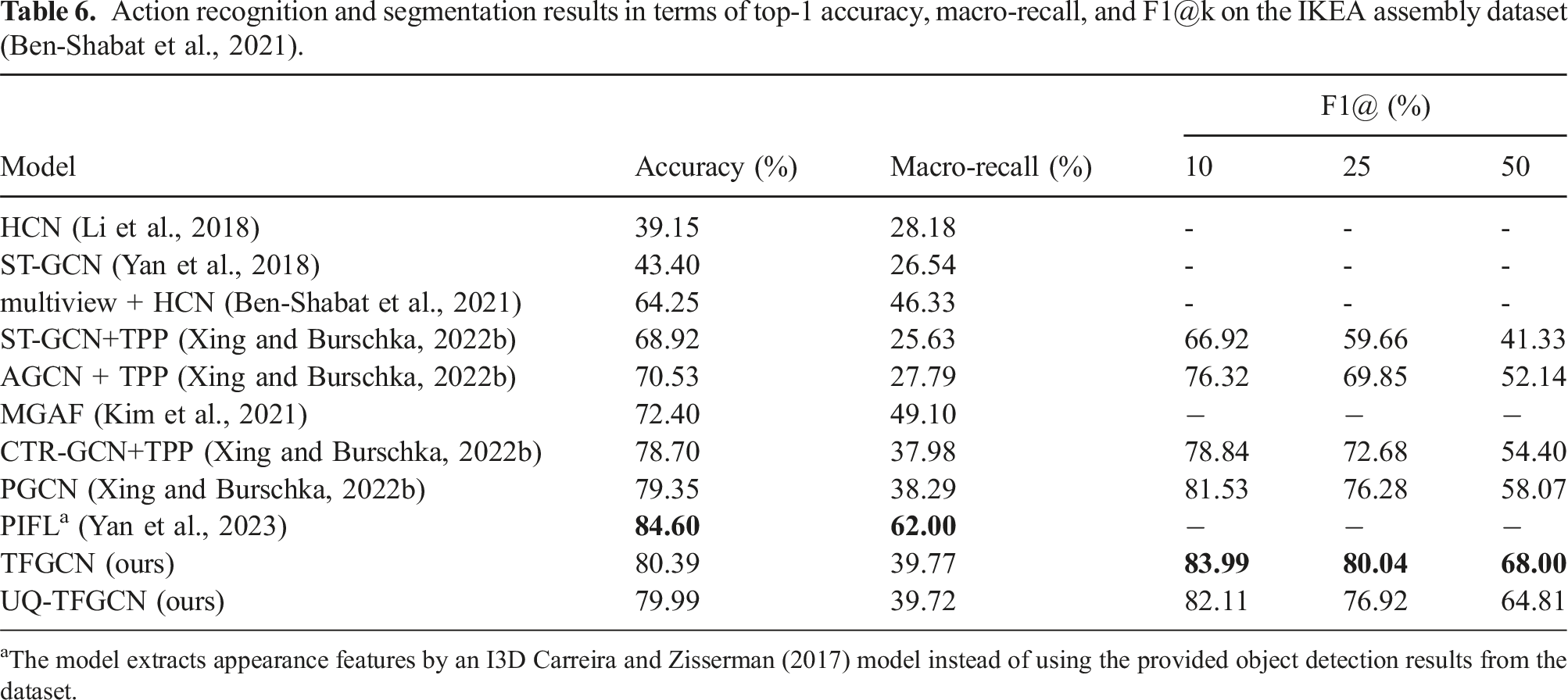
aThe model extracts appearance features by an I3D Carreira and Zisserman (2017) model instead of using the provided object detection results from the dataset.
From Table 5, it is easy to see that our model achieves the best performance across all of the metrics on the Bimanual Actions dataset (Dreher et al., 2019). Especially, the proposed Uncertainty Quantified Temporal Fused Graph Convolutional Network (UQ-TFGCN) significantly improves the performance in terms of average F1@k score (by 6.2%, 6.4%, and 8.4%) compared to the PGCN, which confirms its efficiency for action recognition and segmentation. Furthermore, the standard deviation in F1@k for our results is the smallest, indicating that the model exhibits high robustness.
The experimental results in Table 6 demonstrate that the proposed TFGCN outperforms the state-of-the-art methods in terms of f1@k segmentation score. While the PIFL (Yan et al., 2023) achieves superior performance on the IKEA Assembly dataset, it is unfair to directly compare it with other methods. This discrepancy arises from the fact that PIFL extracts appearance features using an I3D model, as opposed to utilizing the provided object detection results from the dataset. On the other hand, this underscores the significance of comprehensive instance information in the context of action determination. Another remarkable observation is that replacing the normal residual connection with Spectral Normalized Residual connections in UQ-TFGCN leads to a drop in accuracy and f1 score performance, which reaffirms the disruption of spectral normalization. The advantage of Spectral Normalized Residual connections cannot be demonstrated in these two experiments, because most existing recognition and segmentation models ignore the measure of feature distance.
Uncertainty quantification performance on the bimanual actions dataset a (Dreher et al., 2019).
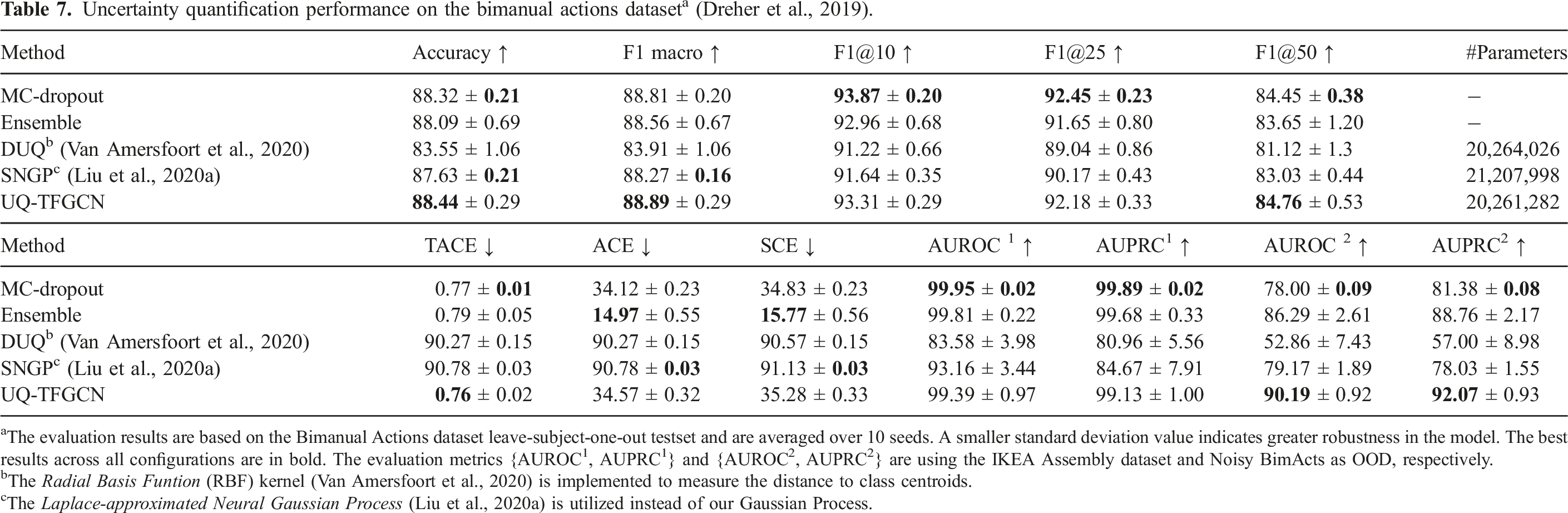
aThe evaluation results are based on the Bimanual Actions dataset leave-subject-one-out testset and are averaged over 10 seeds. A smaller standard deviation value indicates greater robustness in the model. The best results across all configurations are in bold. The evaluation metrics {AUROC1, AUPRC1} and {AUROC2, AUPRC2} are using the IKEA Assembly dataset and Noisy BimActs as OOD, respectively.
bThe Radial Basis Funtion (RBF) kernel (Van Amersfoort et al., 2020) is implemented to measure the distance to class centroids.
cThe Laplace-approximated Neural Gaussian Process (Liu et al., 2020a) is utilized instead of our Gaussian Process.
Since noise is unavoidable in real scenarios, OOD detection on noisy datasets reveals some practical benefits of preserving distance in feature space. Three common noises in the real world are selected for comparison, namely, impulse noise, Gaussian noise, and Poisson noise. The corresponding results of different noise intensities are demonstrated in Figure 8. Since each noise has its different intensity scale, we choose three increasing unit intensities for different noises. For the impulse noise, it set 10% of testset to zeros by increasing one unit intensity. For the Gaussian noise, the increasing unit intensity is set as 0.1 variance of testset. For the Poisson noise, it is 1000 mm expected values and variance. As shown in Figure 8, our model consistently maintains the highest AUROC in Gaussian and Impulse noise and achieves performance close to the MC-Dropout method in Poisson noise. The results demonstrate that our model is robust in preserving feature space distances under different noise conditions. Comparison of AUROC with increasing noise intensity in the Bimanual Actions Dataset (Dreher et al., 2019) over different uncertainty quantification methods: Ensemble, MC-Dropout, SNGP, and ours. (a) Impulse noise, (b) Gaussian noise, (c) Poisson noise.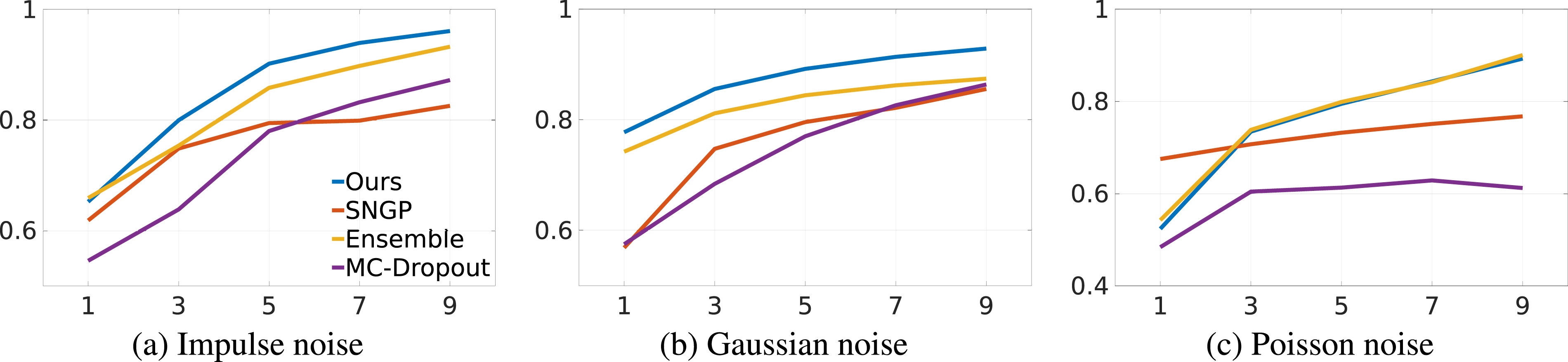
4.5. Qualitative results
We present the detailed outputs with the probability of our model and related methods on examples from Bimanual Action (Dreher et al., 2019) dataset. Figure 9 shows an example of the left-hand actions in the sawing activity. A remarkable achievement of our model is precise predictions of the end and the start of segments, which recognize correctly the start and end frame index of retreat in the example. It demonstrates that our model significantly improves the ability to prevent shift- and over-segmentation. Our model also achieves higher accuracy in action recognition compared to other methods. In the example, both ASSIGN (Morais et al., 2021) and PGCN (Xing and Burschka, 2022b) predict a wrong place action, and only our model successfully predicts a hold action consistent with ground-truth. Another impressive achievement is that, in addition to the prediction of the action label, our model also outputs the predicted probability. As shown in the bottom of Figure 9, the probability represents the similarity between the current feature and known features from trainset, which makes the model’s predictions more interpretable. Wrong predictions usually occur at the junction of two sub-actions, where the probability is low, because the features at this time are far away from the distribution centers of both actions. Predictions with low probabilities in a continuous action mean that the input has some noise, for example, wrong object detection. In the example, we select three representative frames in a continuous hold action, that is, predictions with high (black), medium (gray), and low (white) probabilities. At the position with high probability, the input has a precise location and correct label of objects, while at medium and low probability places, either objects are mislabeled or missing. Qualitative results for action recognition and segmentation of the left hand in an example of sawing a wooden wedge from the Bimanual Actions dataset (Dreher et al., 2019). Distinct actions are distinguished using various colors. The probability, generated by our UQ-TFGCN model, is visually represented in a grayscale bar, where brighter grayscale values correspond to lower predicted probabilities.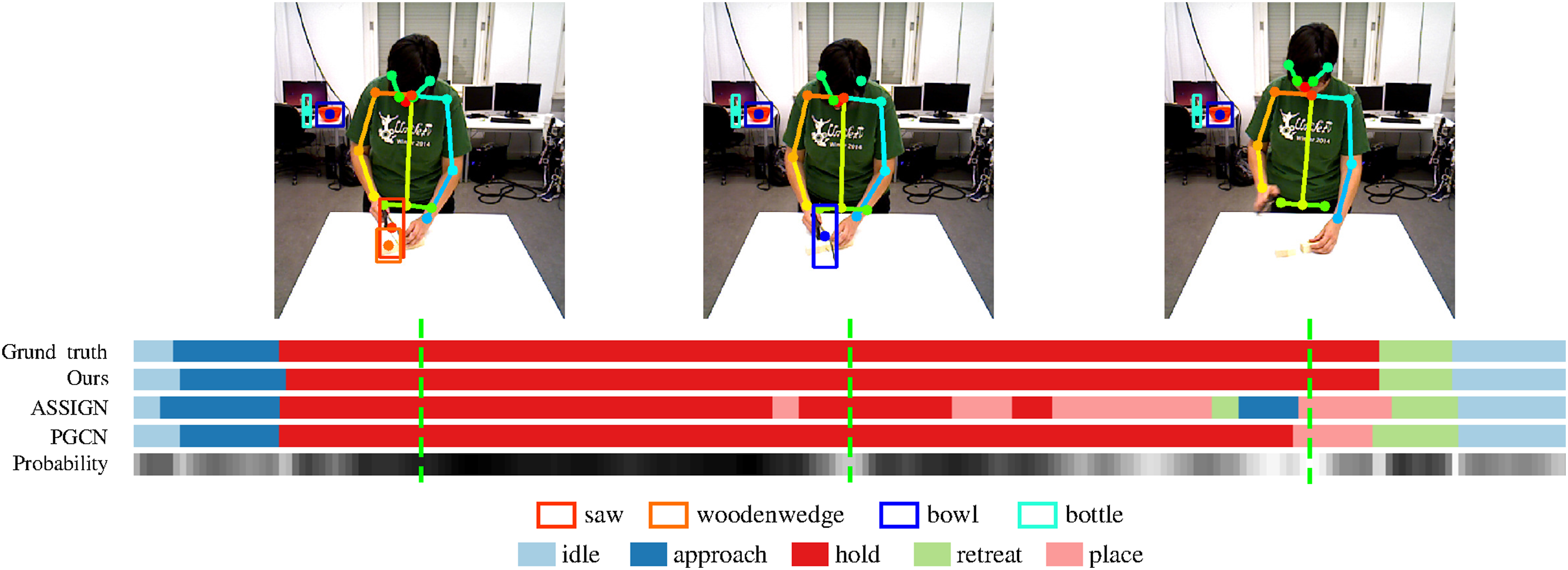
Another qualitative result of a complex assembly side table task from the IKEA Assembly dataset (Ben-Shabat et al., 2021) is demonstrated in Figure 10. It can be seen that the proposed temporal fusion (TF) decoder has a better performance in preventing shift- and over-segmentation compared with Fast-FCN (Wu et al., 2019) and temporal pyramid pooling (TPP) (Xing and Burschka, 2022b) decoders. Qualitative uncertainty estimation and activity segmentation results of assembly side table example from the IKEA Assembly dataset (Ben-Shabat et al., 2021). Distinct actions are distinguished using various colors. A brighter grayscale value indicates a lower predicted probability.
5. Conclusions
We introduced a method to compute prediction uncertainty and preserve input distance in Human Action Recognition frameworks through a novel Uncertainty Quantified Temporal Fusion Graph Convolutional Network (UQ-TFGCN) for recognizing and segmenting Human-Object interaction sequences. The network consists of an attention-based graph convolutional network as an encoder and a temporal fusion module as a decoder. One novelty is the modification of the decoder to reduce errors in the upsampling of features to prevent over-segmentation and to improve the detection of action class transitions. The new decoder leads to an increased number of parameters that increase the computational requirements. The resulting inference still allows online segmentation of actions on standard desktop hardware. Additionally, Spectral Normalized Residual connection helps to maintain meaningful isometric properties. At the same time, it harms the accuracy of the network. The accuracy level can be held at an acceptable level through parameter tuning trade-off between accuracy and feature space distance of the Spectral Normalized Residual.
Experiments on public datasets demonstrate that the proposed temporal fusion decoder has significantly improved the model performance on human-object interaction recognition and segmentation, but it leads to a larger computation complexity as mentioned above. Experimental analysis on noise and out-of-distribution data detection proves that the proposed Spectral Normalized Residual connection is beneficial to preserve the input distance in the feature space, and contributes to estimating the uncertainty. The examination of parameter quantities provides compelling evidence supporting the efficiency of the proposed SN-res method. Results on public HOI datasets with two different data formats (2D and 3D) show that our model has a general capability that can be implemented on other structural-represented domains.
The study shows that the action recognition and segmentation capabilities of our model can be of high relevance for various use cases that require an understanding of human behavior, for example, learning from demonstration and human-robot collaboration. Furthermore, the safety of collaborations between humans and robots can also be improved through an additional uncertainty output. Knowledge of the limitations of the acquired knowledge is only the first step. Active learning of new knowledge is the next natural step for an intelligent system. Therefore, we plan to extend the capabilities of our model to active learning based on novelty detection results.
Supplemental Material
Supplemental Material - Understanding human activity with uncertainty measure for novelty in graph convolutional networks
Supplemental Material for Understanding human activity with uncertainty measure for novelty in graph convolutional networks by Hao Xing and Darius Burschka in The International Journal of Robotics Research.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Lighthouse Initiative Geriatronics under grant no. 5140951.
Supplemental Material
Supplemental material for this article is available online.
Appendix
Considering a graph convolutional layer g(
Additional residual connections shift the range to a higher value as follows:
The upper bound can be easily obtained by
From equation (12), it can be seen that the upper bound of the residual stream shifts the feature space distance to a higher range when β r > β m . In fact, the mainstream produces fine feature maps through several cascaded layers, while the residual outputs coarse features, which means that the Lipschitz upper bound of the feature space distance in the residual connection is larger than that of the mainstream, that is, β r > β m . Note that when β r ≤ β m , the feature space distance automatically satisfies the constraint, since −β m ≤ β r − β m ≤ 0 and 0 ≤ ‖g2 − g1‖. Hence, constraining the Lipschitz upper bound of residual connections is crucial to preserve distance in the representation space.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.