
Abstract
Programming robots by human demonstration is an intuitive approach, especially by gestures. Because robot pick-and-place tasks are widely used in industrial factories, this paper proposes a framework to learn robot pick-and-place tasks by understanding human hand gestures. The proposed framework is composed of the module of gesture recognition and the module of robot behaviour control. For the module of gesture recognition, transport empty (TE), transport loaded (TL), grasp (G), and release (RL) from Gilbreth's therbligs are the hand gestures to be recognized. A convolution neural network (CNN) is adopted to recognize these gestures from a camera image. To achieve the robust performance, the skin model by a Gaussian mixture model (GMM) is used to filter out non-skin colours of an image, and the calibration of position and orientation is applied to obtain the neutral hand pose before the training and testing of the CNN. For the module of robot behaviour control, the corresponding robot motion primitives to TE, TL, G, and RL, respectively, are implemented in the robot. To manage the primitives in the robot system, a behaviour-based programming platform based on the Extensible Agent Behavior Specification Language (XABSL) is adopted. Because the XABSL provides the flexibility and re-usability of the robot primitives, the hand motion sequence from the module of gesture recognition can be easily used in the XABSL programming platform to implement the robot pick-and-place tasks. The experimental evaluation of seven subjects performing seven hand gestures showed that the average recognition rate was 95.96%. Moreover, by the XABSL programming platform, the experiment showed the cube-stacking task was easily programmed by human demonstration.
Keywords
1. Introduction
Human-Robot interaction (HRI) has emerged as a crucial, interdisciplinary research topic which has many promising applications [1]. Sato et al. [2] showed that understanding human intention through human behaviours is an essential function for a robot because about 35% of the information is delivered to a listener's side by means of language and about 65% is obtained by nonverbal communication. Compared to previous work using verbal commands in human-robot interaction [3], understanding human hand gestures provides a novel, natural method to program robots. This task, however, is full of challenges because essential hand features and learning algorithms are severely influenced by hand shape and environmental conditions such as lighting. To implement a good hand gesture recognition system, a large training database is usually required and various gestures should be modelled. In addition, the recognized human hand gesture should be interpreted by a robot system to manipulate objects and interact with an environment. In other words, the robot should achieve the task goal according to the stimulus conditions and action priorities of the plan understood from the human hand gestures. In this paper, we develop a human gesture recognition system based on a convolution neural network (CNN). Without much effort on modelling gestures, an image of a hand is simply fed to the CNN. The second challenging problem is to manage the input and output resources of the robot system. This work develops a behaviour-based robot system to plan the task demonstrated by a human hand. To the robot system, the recognized gesture commands are regarded as high-level task sequence inputs. Once the human hand motion is understood by the gesture recognition system, the robot task sequence is generated for the behaviour-based robot system to execute the task. Figure 1 illustrates the proposed idea that enables a robot to understand human hand gestures and learn pick-and-place tasks.

Proposed idea of understanding human hand gestures and learning pick-and-place tasks
The novelty of our research is to propose a robot task-learning system which has a front-end CNN-based gesture recognition system and a back-end behaviour-based robot programming platform to deal with pick-and-place tasks. We propose a computational approach based on CNN to recognize human hand gestures without using complicated algorithms to extract hand features such as hand contour and curvature. Through the convolution and sub-sampling layers of a CNN, invariant features are allowed with little dislocation. To reduce the effect of various hand poses on recognition accuracy, the principal axis of the hand is found to calibrate the image in this work. Calibrated images are advantageous to a CNN to learn and recognize gestures correctly. In addition, the light condition affects the skin colour, resulting in the recognition rate being severely degraded. To solve this problem, we adopt a Gaussian mixture model (GMM) to derive the robust skin model. In a continuous hand motion, because transitive gestures may be ambiguous for the CNN to recognize, we apply forward-and-backward search rules on their adjacent frames which have the most similar images to them. The rules correct the misrecognized transitive gestures without changing the semantic meaning of the continuous motion.
In the proposed robot system, sensor inputs and action outputs are encapsulated in the form of behaviours to react to or interact with an environment. Basic skills for pick-and-place tasks such as Gilbreth's transport empty (TE), grasp (G), transport loaded (TL), release (R), and search (SH) [4] are initially created. The planner of behaviours is generated by the front-end gesture recognition system and described by the Extensible Agent Behavior Specification Language (XABSL) [5] to maintain the multi-tazsking performance in the robot system. The XABSL programming platform handles the multi-tasking scheduling to process images from cameras and robot encoders, and command the robot to behave under proper conditions. The advantages of the XABSL programming platform are: first, a task is implemented by a hierarchical state machine of robot behaviours and planned by an option graph in the XABSL. Second, behaviours are reusable and modular for pick-and-place tasks.
In the following sections, Section II presents the brief review of the related research. Section III introduces the proposed framework with a CNN-based gesture recognition system followed by a behaviour-based robot programming platform being described in detail. In Section IV, experimental evaluations are provided, and lastly concluding remarks are summarized in Section V.
2. Review of related research
2.1 Programming by demonstration
Programming by demonstration (PbD) [6] is an alternative HRI methodology to program robots without programming expertise. The method of PbD is implemented by understanding human motion and implementing a corresponding robot motion to accomplish tasks. Most of the previous PbD work represented human demonstration by motion trajectories and made robots replay these encoded trajectories. The human motion trajectories could be joint, Cartesian, and force trajectories [7]. Human motion was modelled as a cyclic motion [8], discrete motion [9], or a combination of cyclic and discrete motion [10]. Since these demonstrated trajectories had high dimensionality, local [11] and global [12] transformation methods were adopted to reduce the dimensionality. To abstract human motion, motor primitives were used in PbD. They could be perceptual-motor primitives [13], movement primitives [14], or control modules [15]. Simply speaking, these primitives encoded the mapping relationship between sensory stimuli and action responses and were treated as the building blocks for robots to accomplish tasks. The main advantage of using motor primitives to program a robot is that motor primitives are reusable to facilitate robot programming.
For a robot, pick-and-place motions are commonly used in a variety of robot manipulative tasks. In [16], a 6D-tracker was placed on a human demonstrator and used to capture motion trajectories. The velocity profile of the trajectories was analysed to decompose a pick-and-place task into task primitives. These task primitives were basic movements such as MoveZ (move along the z-axis) and MoveJ (move to the position using joint interpolation). In [17], they taught a robot low-level action primitives by kinaesthetic teaching and developed a graphical interface to plan these primitives to accomplish a behaviour. For example, a pick-and-place behaviour was implemented by primitives such as Input, MoveArm, Close/Open, and Gripper Output. Zoliner et al. [18] proposed a hierarchical task representation to describe manipulation problems such as pick-and-place tasks, device handling, and tool handling. A task was implemented by elementary operators and the knowledge was extracted from human demonstration. Previous work had their own motor primitives which were customized to specific manipulative tasks. Much work focused on analysing human motion data and mapping it to the customized primitives. However, human motion was high dimensional and changeable, making a robot difficult to duplicate the same robot motion by primitives. Thus, human demonstration should be understood by a robot during PbD including the purpose of action and the type of action.
In this paper, a set of basic skills should be created for pick-and-place tasks. Before that, it is necessary to clarify the commonalities and differences between a skill and a task. Friedrich and Kaiser [19] stated that acquisition a new program schemata on task level is ‘learning of a sequence of elementary skills including proper application conditions'. Voyles and Khosla [20] assumed that ‘a set of robotic skills that approximate the set of primitives that a human uses to perform a task from the particular application domain’. Nicolescu [21] considered ‘a task to be an activity involving the coordination of an existing set of skills in order to achieve a given set of goals’. Aramaki et al. [22] considered that a task sequence is defined by concatenation of skills. Gilbreth [4] investigated 18 types of elemental motions (so-called therbligs) to represent human motion used in a workspace. Any human motion in a workspace could be represented by these 18 therbligs. In this paper, the therbligs, transport empty (TE), grasp (G), transport loaded (TL), release (R), and search (SH) are used to understand human demonstration of pick-and-place tasks. Accordingly, a set of robot basic skills are created to achieve the pick-and-place tasks.
2.2 Hand gesture recognition
Hand gesture recognition has been a promising topic and applied to many practical applications [23]. For example, hand gesture is observed and recognized by surveillance cameras to prevent criminal behaviour [24]. Hand gesture recognition has also been investigated by a variety of studies [25], such as sign language recognition [26], lie detection [27], and robot control [28]. Gesture is a body language that humans use to express emotion and thoughts. The varied gestures of the five fingers and palm may have their physical meanings. Hand gesture recognition is a complicated process including feature extraction and gesture modelling and learning. Scale-invariant feature transform (SIFT) has been used to extract hand features from images [29]. The image features were represented in the form of vectors to describe the hand shape. Central moments were used by [30, 31] to represent the hand shape because they were invariant to translation and scaling and physically meaningful. They were used to describe the inclination, displacement of the centre, and stretch of a hand. Hand contour was usually adopted as the feature in gesture recognition. Huang [32] used the Fourier descriptors to describe the hand contour and applied the Hausdorff distance to measure the similarity between two hand shapes. McEiroy and Wilson [33] used the Fourier Descriptor coefficients to describe the hand shape and then applied the neural network on the coefficients to classify the different hand shapes. Tantachun et al. [34] considered that the biometrics such as fingerprints and hand geometry could be extracted from the Eigenface method [35, 36]. Al-Jarrah [37] and Holden [38] plotted the hand contour in the polar coordinate by measuring the distance from the hand centre to the edge. In previous work on gesture modelling, Hidden Markov Model (HMM) was used to a real-time semantic level American Sign Language recognition system [39]. A gesture also can be modelled as a HMM state sequence. In [40], they adopted a Finite State Machine (FSM) model to recognize human gestures. In [41], Time Delay Neural Network (TDNN) was used to match motion trajectories and train gesture models.
To recognize gestures in a continuous motion, Jo el al. [42] used a FSM to deal with a task-level recognition problem where a task was represented in a state transition diagram and every state represented a possible gesture. Some researchers used a rule-based method for gesture recognition. Culter and Turk [43] designed a set of rules to recognize waving, jumping, and marching gestures. In recent years, deep learning is widely applied to many applications. Especially, CNN is a proper method for image-based learning. For example, [44] used a CNN to implement recognize open and closed hands.
3. Framework of the robot task-learning system
The flowchart of the proposed robot task-learning system is shown in Fig. 2. The figure shows that the system is composed of a gesture recognition system and a behaviour-based robot programming platform. The proposed system aims at understanding human hand gestures and learning to accomplish a pick-and-place task in the same manner.
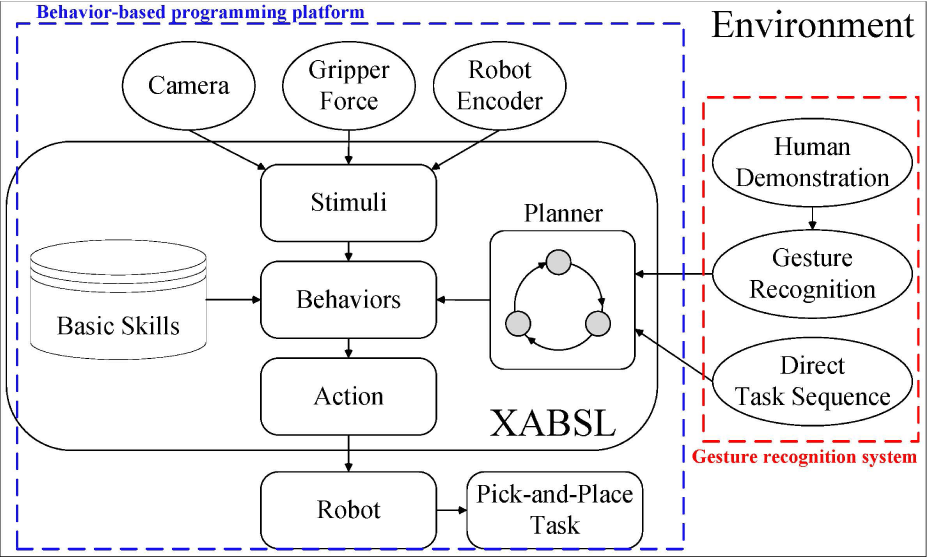
Framework of the proposed robot task-learning system
For the gesture recognition system, human hand motion and the environmental conditions are captured by a camera and then the captured images are processed to generate a sequence of gestures and position changes of objects. For the behaviour-based robot programming platform, it consists of basic skills and a planner. Every skill is treated as a behaviour that is activated by stimuli from camera images, force sensor, or robot encoders. The planner is described by the XABSL syntax to implement the sequence and the stimulated conditions of behaviours. The XABSL programming platform maintains the multi-tasking schedule among behaviours. Thus, any sequence of gestures understood from human demonstration can be implemented by the XABSL programming platform. The details of the gesture recognition system and the behaviour-based robot programming platform are described as follows.
3.1 Gesture recognition system
Figure 3 shows the flowchart of the gesture recognition stystem. From an image input, the hand is extracted by skin it colour segmentation. The skin model is trained by a Gaussian mixture model to classify the skin colour and non-skin colour. After that, the calibration of the hand position and orientation is used to translate and rotate the hand image to the neutral pose. The calibrated image is fed to the CNN to train or test the network. For continuous hand motion post-processing is used to filter out the noise of the results from the CNN. Each block of the flowchart is described as follows.

Flowchart of the proposed human gesture recognition system
3.1.1 Human demonstration
One of the salient features of the proposed robot task-learninR g o is t that th2 e in1 p 4, u Vt to the robot system is by means of human demonstration. In other words, a human can use gestures captured by a camera to command the robot to perform a pick-and-place task. Currently, the proposed system uses Gilbreth's therbligs such as TE (transport empty), TL, G, and R to understand human motion. Figure 4 shows that the human demonstrates a cube-stacking task and the robot learns to understand the demonstration and re-perform the task.

(a) A human demonstrates a cube-stacking task. (b) The robot re-performs the same task.
3.1.2 Skin model for colour segmentation
In a vision system, the light condition is an important factor to affect the system performance. Using colour thresholds to classify skin and non-skin colours is common in conventional approaches, but colour thresholds are not enough to describe the statistical properties of skin colour under various light conditions. Even though the YCbCr colour space that is less sensitive to the light condition than the RGB colour space is used, the result is still defective. For example, the pixel value (B) of a binarized image is determined by the YCbCr threshold and described as

Figure 5 shows the YCbCr image and its binarized image by the threshold in Eq. (1). From Fig. 5(b), some pixels on the ring and little fingers are classified as non-skin pixels. In this paper, we use a GMM to solve this problem. A GMM is represented by K Gaussian components as

Image binarization using a threshold in Eq. (1). (a) YCbCr image; (b) binarized image.

where P(k) is the prior probability (π) and P(x | k) is the conditional probability formulated as a Gaussian distribution with the mean (μ) and covariance (Σ). Thus, {π k , μ k , Σ k } k are optimized by the expectation-maximization (EM) algorithm and used to express P(x) by Eq. (2). The detailed steps of GMM were described in [45]. In GMM training, we divide the workspace into 15 cells. For every section, we sample the colour within the yellow area around the centre of the hand. Figure 6 shows that the workspace is divided into 15 cells in which the skin colours are sampled for GMM training data. The greater number of cells indicates that the more skin colour data are sampled for the GMM to obtain the colour distribution of hand skin in the environment wherever the light condition is various. Thus, the number 15 is chosen according to the lighting condition of the experimental environment.

GMM training. (a) Workspace is divided into 15 cells; (b) Skin colour within the yellow area of the hand is sampled for every section.
For an extreme case, we put a light source on the upper-right corner (see Fig. 7). Figure 8 compares the results between a threshold and a GMM. The result in Figure 8(c) is obviously superior to the one in Figure 8(b).

A light source on the upper-right side

Image binarization using a threshold in Eq. (1) and GMM. (a) Original RGB image; (b) binarized image by a threshold; (c) binarized image by GMM.
3.2 Calibration of hand position and orientation
To obtain better recognition results, the hand images should be calibrated by their position and orientation. Once the binarized image is derived, we calculate the hand centre (x̄ȳ) as follows
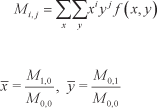
where x and y are the coordinates of the skin pixel whose pixel value f (x,y) is set as 1, and vice versa.
For orientation, we use moment invariants to find the principal axis of the hand [30]. The angle of orientation is expressed as

As (x̄ȳ) and θ are calculated, they are used to translate and rotate the image to the neutral pose.
3.2.1 Gesture recognition by a convolution neural network
To recognize human gestures, we adopt a CNN as the approach to classify the seven types of human hand gestures. The CNN is a type of feed-forward neural network. Small overlapped portions of an original image are represented by neurons in a layer of the network so that the image features are allowed to be translated. The pixels in the convolutional layer use the same weight to save memory size and improve efficiency. Compared to previous technologies using complicated image feature extraction, the CNN provides a robust and systematic methodology to classify the type of hand gestures. Figure 9 shows the architecture of the CNN where there are eight layers, denoted as I1, C2, S3, C4, S5, N6, H7, and O8 in sequence [46]. I1 is the input layer, C2 and C4 are the convolution layers, S3 and S5 are the sub-sampling layers, N6 is the input layer of a feed-forward neural network, H7 is the hidden layer of the neural network, and O8 is the output layer of the neural network. C2, S3, C4, and S5 are interleaved and S5 is connected with N6 of the feed-forward neural network. The input of I1 is an 28×28-pixel image. By applying six 5×5-pixel convolution patches on I1, six 24×24-pixel feature maps are generated in C2. Then, each feature map in C2 is taken by 2×2-pixel sub-sampling, resulting in six 12×12-pixel feature maps in S3. Again, applying 12 5×5-pixel convolution patches on the six feature maps in S3 generates 12 8×8-pixel feature maps in C4. Finally, 2×2-pixel sub-sampling is applied to the feature maps in C4 to generate 12 4×4-pixel feature maps in S5. The 12 4×4-pixel feature maps are expanded and concatenated in terms of a 192×1 vector as N6. These 192 neurons of N6 are fully connected with the 192 neurons of H7. Last, N7 is also fully connected to the seven neurons of O8. For the implementation, the steps were described in [46].

Architecture of the CNN
3.2.2 Post-processing in continuous motion
Since there are transitive hand gestures in a continuous hand motion, they become uncertain for the trained CNN. We design rules to post-process the gesture type of the transitive image frames. The rules are as follows
Using the rules, the transitive gestures are assigned to the certain gesture type in the closest preceding or successive frame.
4. Behaviour-based robot programming platform
4.1 Basic skills
As mentioned in Section II, Gilbreth's 18 therbligs are used to analyse human demonstration. Accordingly, we create a corresponding set of robot basic skills such as TE, TL, G, R, SH, and search precisely (SHP) to accomplish pick-and-place tasks. Once human demonstration is recognized as a sequence of therbligs, the plan of scheduling the robot basic skills is directly synthesized for the robot to accomplish the same task. Table 1 shows the robot basic skills and their descriptions.
Basic skills for pick-and-place tasks

4.1.1 Sensors
For each basic skill, it serves as a behaviour that has the stimuli as the pre-conditions to activate itself to act properly. Stimuli in the proposed system come from the cameras, force sensor, and robot encoder. In the system, two cameras are used: camera 1 is hung on the top of the workspace and camera 2 is an eye-on-hand camera. Camera 1 and camera 2 are used for basic skills SH and SHP, respectively because camera 1 is far from an object and the acquired object location is less precise; however, camera 2 is close to an object and is used to acquire a more precise object location.
4.1.2 Planner
The planner is the key block in the proposed system. Particularly, the plan for managing behaviours is easily described by the XABSL platform [5]. The XABSL representation to describe the execution plan of behaviours is an option graph that is simply a diagram of hierarchical state machines. Option graphs allow users to simply plan the execution sequence of behaviours. In the proposed system, options are planned to manage basic skills to accomplish pick-and-place tasks. A basic skill is described by a simplest option that has inputs (stimuli), outputs (action), and decision. Thus, the basic skills presented in Table 1 are implemented by options. Figure 10 shows the XABSL syntax of TE and the option graph to execute the sequence of TL, G, and R.
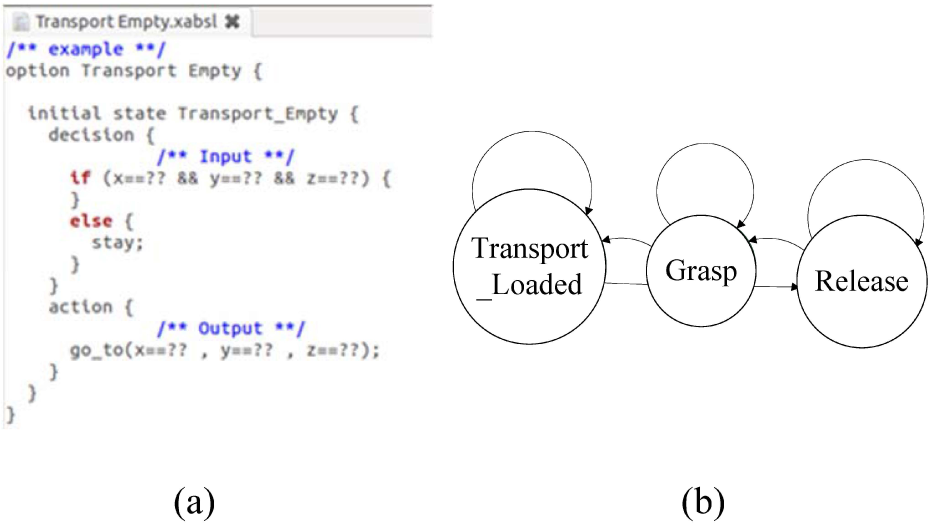
(a) XABSL syntax of TE. (b) Option graph to execute the sequence of TL, G, and R.
To illustrate the XABSL platform for pick-and-place tasks, the cube-stacking task is implemented. The task is to stack cubes in an order of blue, red, and green. The XABSL needs to plan a sequence of basic skills to stack cubes. Figure 11 shows the option graph of the task. In the option graph, the sequence of picking the red cube is described as: SH searches the red cube using camera 1, TE moves the robot over the red cube, SHP searches the red cube again using camera 2 to acquire a more accurate location, TE moves the robot to the red cube, and G grasps the red cube. The sequences of picking and placing the red and blue cubes follow the same scheduling logic.
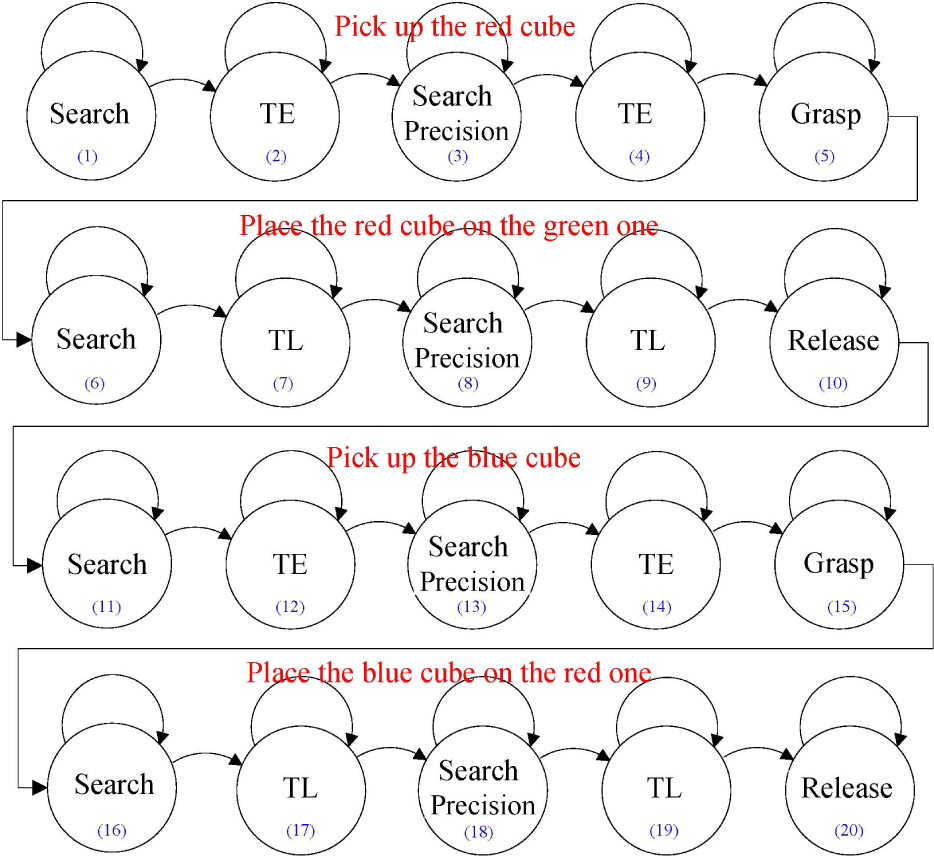
Option graph to perform cube stacking in blue, red, and green order
5. Experimental evaluation
5.1 Validation of GMM
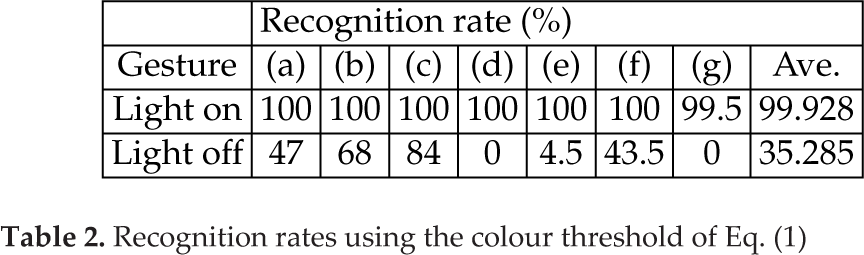
In the experiment, the GMM for modelling the skin colour was validated. Figure 12 shows the testing environment with light on/off. For either lighting condition, 600 training and 200 testing images of a gesture type were chosen to test the GMM. Figure 13 shows the seven gesture types that were tested in the experiment. Tables 2 and 3 show the recognition rates by the threshold of Eq. (1) and GMM of Eq. (2), respectively. Obviously, when the light was off, the result of the threshold was degraded.
Recognition rates using the colour threshold of Eq. (1)
Recognition rates using the GMM of Eq. (2)


Testing environment for GMM. (a) Light on; (b) Light off.

Seven gesture types to be recognized
5.2 Gesture recognition
In this paper, seven gesture types (see Fig. 13) were chosen for recognition. The images were taken by a XBOX Kinect camera that was set up right above the hand. The image size is 200×200 pixels. First, each image was converted to the YCbCr colour space and the background was removed by the GMM. After the image was down-sized and its background was removed, it became an 28×28-pixel grey-scale or binarized image (see Fig. 14) for saving the computational time in the CNN. For each gesture type, we took 600 and 200 images from a subject to train and test, respectively, the CNN. To validate the proposed method, we used four-fold cross-validation. Tables 4 and 6 show the recognition rates of the seven gesture types using their binarized and grey-scale images, respectively when the background was removed. From the results, it was obvious that the recognition rates were high for gesture types (a)-(f). However, the recognition rate of gesture (g) was poor using the binarized images. Instead, using the grey-scale images, the recognition rate of gesture (g) was improved. The reason was that the binarized images were similar among gesture types (d), (e), and (g), but their grey-scale images had more image details such as the finger positions. Figure 15 shows the binarized and grey-scale images of gesture types (d), (e), and (g). Tables 5 and 6 compare the recognition rates of the grey-scale images with/without the background, respectively. Obviously, even though the images were grey-scale, the recognition rate without a background was superior to the one with a background.
Recognition rates of the seven gesture types using their binarized images when the background was removed

Recognition rates of the seven gesture types using their grey-scale images when the background was not removed

Recognition rates of the seven gesture types using their grey-scale images when the background was removed


Images after the original images were down-sized and the background was removed

Binarized and grey-scale images of gestures (d), (e), and (g)
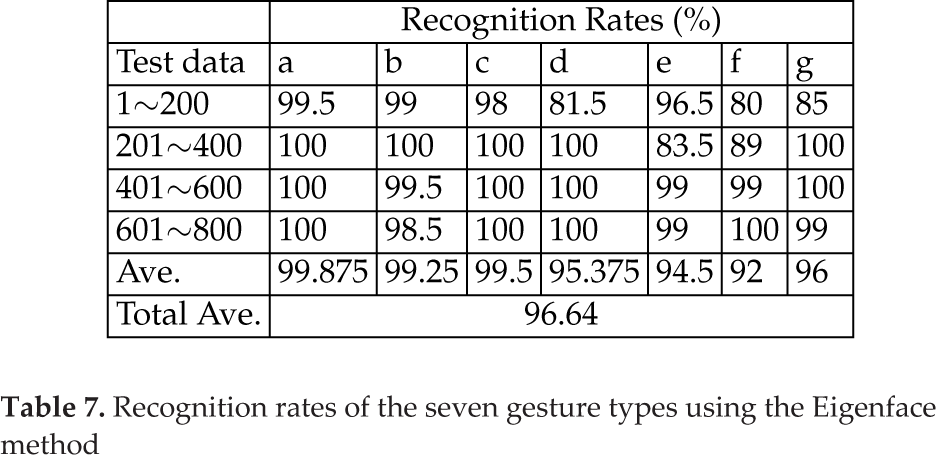
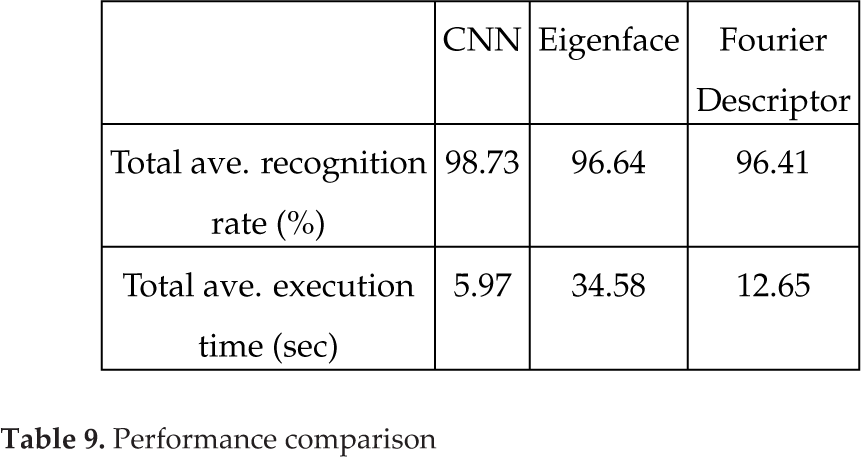
To address the contribution of the proposed method, the two image recognition methods, Eigenface [35, 36] and Fourier Descriptor[33], were adopted to compare with the proposed CNN method using the same training and testing data set. For the Eigenface method, 3×3 Eigenface images were chosen. Tables 7 and 8 show the recognition rates of the seven gesture types using the Eigenface and Fourier Descriptor methods, respectively. Table 9 shows the performance comparison among the CNN, Eigenface, and Fourier Descriptor methods. The CNN method was superior to the other two methods in the total average recognition rate. The average execution time for 200 testing images was 5.97 seconds by the CNN method and much faster than 12.65 seconds by the Fourier Descriptor method and 34.58 seconds by the Eigenface method.
Recognition rates of the seven gesture types using the Eigenface method
Recognition rates of the seven gesture types using the Fourier Descriptor method

Performance comparison
To test the generality of the trained CNN model, 300 untrained images of each gesture type from three testers were tested where each tester provided 100 testing images. Table 10 shows the recognition rates of the results. From Table 10, we found that gesture types (d) and (e) from testers 2 and 3 were poor. Figure 16 shows the testing images of gesture types (d) and (e) from tester 2 and 3. Because the hand size of tester 2 was much smaller than that of the training images, gesture types (d) and (e) of tester 2 could not be recognized clearly. On the contrary, the hand size of tester 3 was much larger than that of the training images, resulting in failures in recognizing gesture types (d) and (e). Thus, we trained these 300 testing images and tested another 300 untrained images for both gesture types (d) and (e). After this, Table 11 shows the average recognition rates were improved above 90%. To validate the system with a large database, we both trained and tested 700 images from seven subjects for each gesture type where each subject provided both 100 training and testing images. Table 12 shows the recognition rates of the testing images of the seven gesture types. The results show that the average rate was 95.96%.
Recognition rates of the seven gesture types where the hand images of testers 1, 2, and 3 were untrained

Recognition rates of the seven gesture types where the hand images of testers 1, 2, and 3 were trained

Recognition rates of the seven gesture types from seven subjects


Gestures d and e from testers 2 and 3. (a) and (b) were gesture types d and e from tester2; (c) and (d) were gesture types d and e from tester3.
To test the pose calibration of the proposed method, the hand was continuously waving around ±90 o . The frame rate was 40. After the principal axis was calibrated, the hand was orientated to a neutral pose. Figure 17 shows the frames 1∼40 of a handwaving motion. The grey-scale and white images were before and after calibration, respectively. Apparently, the tilted hands were rotated to their neutral poses correctly.

Frames (a) 1∼20 and (b) 21∼40 of a handwaving motion
In addition, our experimental evaluation for a continuous motion was performed by the gestures shown in Fig. 18. The original result was incorrect in frames 2 and 21. For frame 2, the closest frame whose O8 value in the CNN was greater than 0.9 was frame 3. However, all the O8 values of frame 21 were less than 0.5. By applying the rule of the proposed post-processing, frame 2 was change from gesture type (d) to (e) and frame 21 was denoted as an undetermined frame.

Frames 1∼21 of a continuous motion
5.3 Spatial and temporal reasoning
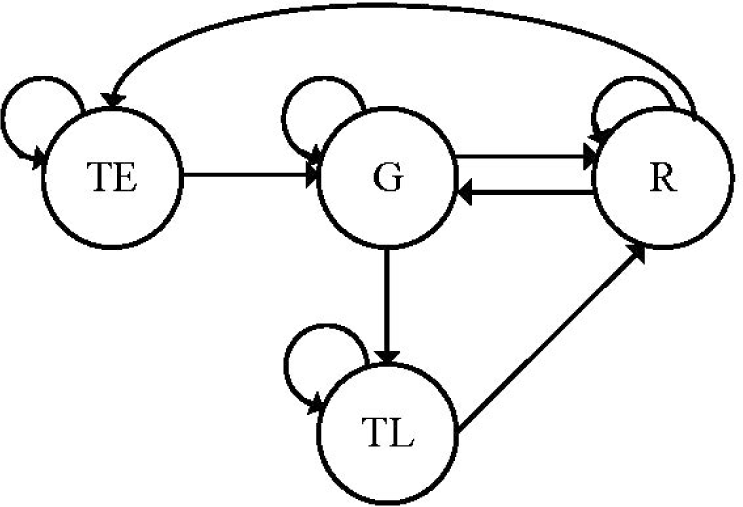
After the hand gesture was recognized, its corresponding robot basic skill such as TE, TL, G, or R was determined. However, for some gesture types, they corresponded to the different possible robot basic skills. For example, gesture type (a) could be a state of TE or R. To solve the problem, the spatial and temporal rules were applied to recognize the corresponding robot basic skills such as TE, TL, G, and R from human hand gestures. Table 13 and Fig. 19 show the spatial and temporal rules, respectively. From Table 13, the two spatial properties were used to determine the possible basic skills in the current gesture type. For example, when the hand position was near an object and the gesture type was (a), the corresponding robot basic skill was TE or R. After the possible gesture types were detected, they were fed to the temporal state machine to determine the exact corresponding robot basic skill. For example, in Fig. 19, when the current state was G and the possible gesture types TE/R were predicted from Table 13, the estimated next state was R instead of TE because G could not jump to TE.
Temporal rules
Spatial rules

5.4 Cube-stacking task
In the a cube-stacking task, a teacher demonstrated how to stack cubes. There were green, red and blue cubes on the desk. The teacher stacked these three cubes in any order and then the robot followed the same order to stack the cubes. Figures 20(a) to 20(k) show the teacher's demonstration to stack cubes. Figure 20(a) shows that the teacher performed TE to reach to the green cube. Figure 20(b) shows that G was performed to grasp the green cube.

(a) TE was performed to reach to the green cube; (b) G was executed to grasp the green cube; (c) TL was performed to transport the green cube; (d) the green cube was brought over the blue one; (e) R was performed to place the green cube on the blue one; (f) TE was performed; (g) reach to the red cube; (h) G was executed to grasp the red cube; (i) TL was performed to transport the red cube; (j) the red cube was brought over the green one; (k) R was performed to place the red cube on the green one
Figures 20(c) and 20(d) show that the teacher performed TL to transport the green cube and bring it over the blue one. Figure 20(e) shows that R was executed to place the green cube on the blue one. Figures 20(f) and 20(g) show that the teacher performed TE to move the red cube. Figure 20(h) shows that G was performed to grasp the red cube. Figures 20(i) and 20(j) show that the teacher performed TL to transport the red cube and bring it over the green one. Figure 20(k) shows that R was executed to place the red cube on the green one.
After the human demonstration, Figures 21(a) to 21(j) show that the cubes were stacked in the same order by the robot. After the therbligs of the human demonstration were recognized, the robot searched the red, green, and blue cubes and placed them in the same order. In this experiment, the motion primitives were performed as the following: SH (search the green cube), TE (move to the green cube), G (grasp the green cube), SH (search the blue cube), TL (transport the green cube), R (place the green cube on the blue one), SH (search the red cube), TE (move to the red cube), G (grasp the red cube), SH (search the green cube), TL (transport the red cube), and R (place the red cube on the green one). The motion sequence was automatically synthesized and implemented by the XABSL options. Particularly, the motion primitives SH (search) and SHP (search precisely) were inserted in the XABSL options because they were not observable in the human demonstration.

(a) Search for the green cube and reach it; (b) grasp the green cube; (c) search for the blue cube and transport the green one to the blue one; (d) reach to the blue cube; (e) place the green cube on the blue one; (f) search for the red cube and reach to it; (g) grasp the red cube; (h) search for the green cube and transport the red one to the green one; (i) reach to the green cube; (j) place the red cube on the green one
6. Concluding remarks and future work
We have introduced a novel robot task-learning system for pick-and-place tasks by understanding human hand gestures. To achieve a robust performance, the system is implemented in two subsystems: the hand gesture recognition system and the behaviour-based robot programming platform. To recognize human hand gestures, the proposed system adopts a CNN to learn seven types of gestures. The underlying idea is to use a CNN that we do not need gesture models and features (i.e., hand shape). Since the CNN learns the gestures by the convolution and subsampling of the images, the proposed system works on various types of gestures. In addition, the calibration on colour and hand pose is presented to achieve a robust recognition result. To consider the effect of the light condition, a GMM is used to model the skin colour. The moment invariants are used to find the principal hand axis for calibrating the hand pose to a neutral position.
After the gesture is recognized, the behaviour-based robot programming platform provides a direct approach to synthesize the task sequence of the human demonstration. The underlying idea is to use the XABSL options and basic skills such as TE, TL, G, and R to implement the demonstrated task sequence. Each skill serves as a behaviour that is activated by the stimuli from the images and robot encoders to perform the proper action.
In the experiments, the four-fold cross-validation was used to validate the system where 600 and 200 images from a subject were used to train and test the CNN, respectively and the results showed that the average recognition rate of the seven gesture types was around 98.73%. The CNN method outperformed the other two methods, Eigenface and Fourier Descriptor in the recognition rate. Particularly, the execution time of the CNN was much faster (5.73 sec) than the Eigenface (34.58 sec) and Fourier Descriptor (12.65 sec) in testing 200 images. In addition, the Eigenface method was vulnerable to the change of the lighting condition. The Fourier Descriptor that analysed the hand contour could not provide enough information to represent delicate gestures. On the contrary, the proposed method using the GMM and CNN was robust against the change of the lighting condition and provided the detailed features of gestures to achieve the better results. The proposed system also had the satisfactory result on the transitive gestures in a continuous motion using the proposed post-processing rules. The system implemented a cube-stacking task by the XABSL-based platform. From observing the human demonstration, the robot stacked the cubes in the same order.
The salience feature of the proposed system is to learn pick-and-place tasks by understanding human hand gestures. The success of the system is based on the marriage of the gesture recognition system and behaviour-based programming platform because the former provides high-level task sequence inputs to the latter to accomplish pick-and-place tasks from human demonstration.
The limitation of the CNN is that when an image has low image resolution and many details, it is hard to find the feature of the image by the CNN because the convolution and subsampling of CNN make the image blurred. Besides, in the proposed system, a gesture type does not uniquely correspond to a robot motion. For example, gesture types (a) and (c) can be a state of robot motion TE or R. In the proposed method, the spatial and temporal rules were adopted to determine the robot motion. Thus, another limitation is that using these simple rules is insufficient to deal with complex motions. The potential solution to this problem is to apply a systematic method such as HMM to infer the spatial and temporal relationship between gesture and motion.
The potential application of the system is a human-robot interface that allows human operators to program an industrial robot by demonstration. Human operators do not need any experience of robot programming but are able to command a robot to perform industrial tasks such as pick and place. Currently the proposed system has dealt with hand gestures instead of intentions to interpret human demonstration. In the future work, understanding human intentions to accomplish robot tasks would be an interesting research topic.
Footnotes
7. Acknowledgements
This work was supported in part by cooperated educational research, NTUT-MMH-102-02, from National Taipei University of Technology and Mackay Memorial Hospital, Taipei, Taiwan. Special thanks go to W. K. Chen, C. H. Cheng, and M. H. Hsu for preparing the experimental work.