
Abstract
The focus of this research is to introduce the concept of combined intelligent control (CIC) as an effective architecture for decision-making and control of intelligent agents and multi-robot sets. Basically, the CIC is a combination of various architectures and methods from fields such as artificial intelligence, Distributed Artificial Intelligence (DAI), control and biological computing. Although any intelligent architecture may be very effective for some specific applications, it could be less for others. Therefore, CIC combines and arranges them in a way that the strengths of any approach cover the weaknesses of others. In this paper first, we introduce some intelligent architectures from a new aspect. Afterward, we offer the CIC by combining them. CIC has been executed in a multi-agent set. In this set, robots must cooperate to perform some various tasks in a complex and nondeterministic environment with a low sensory feedback and relationship. In order to investigate, improve, and correct the combined intelligent control method, simulation software has been designed which will be presented and considered. To show the ability of the CIC algorithm as a distributed architecture, a central algorithm is designed and compared with the CIC.
Introduction
Artificial intelligence started as a field whose goal was to replicate human level intelligence in a machine (Rodney Brooks, 1987) [12] and the development of rational agents, i.e. agents capable of performing useful actions given its world perception and knowledge, has been a major concern since the beginning of Computer Science research (F.R. Meneguzzi & A.F. Zorzo& M.d. Costa, 2004) [3]. Multiple cooperating robots hold the promise of improved performance and increased fault tolerance for large-scale problems. Multi-robot cooperation, however, is a complex problem (Maja J. Matari& Gaurav S. Sukhatme, 2003) [5]. Increasing efficiency is one of the key reasons for deploying teams of robots instead of single robots (D. Fox & K. Konoligey, B. Limketkai& D. Schulzz, 2003) [1] that distributed artificial intelligence helps us to improve multi-robot sets (Jun Ota, 2006) [4]. Several approaches are introduced since now to attain efficient intelligent architectures (Shu-Hsien Liao, 2005). The focus of this research is to introduce the concept of combined intelligent control (CIC) as an effective architecture for decision-making and control of intelligent agents and robots. The idea of combined intelligent control has been motivated by biological structures, especially human beings. In a biological structure, different organs can create a set of behaviors and actions through the application of their own abilities and specifications (Michael A. Arbib, 2003) [7]. Finally, they produce the eligible decision, which is distributed, complete and intelligent. Basically, the CIC is a combination of various architectures and methods from fields such as artificial intelligence, DAI, control and biological computing. Although any intelligent architecture may be very effective for some specific applications, it could be less for others. There are some structural discrepancies among much intelligent architecture, necessitating a thoughtful procedure for their interconnection to yield a good result. The aim is to arrange them in a way that the strengths of any approach cover the weaknesses of others. In this paper first, we introduce some intelligent architecture from a new aspect. Afterward, we offer CIC by combining them. An effective artificial intelligence engine, i.e. the CIC should support agents that are reactive, context specific, flexible, realistic, and easy to develop (Sascha Stoeter, Paul Rybski, Kristen N. Stubbs, Colin P. McMullen, 2002).
The CIC has been executed in a multi-agent set. In this set, robots must cooperate to perform some various tasks in a complex and nondeterministic environment with a low sensory feedback and relationship. In order to investigate, improve, and correct the combined intelligent control method, simulation software has been designed which will be presented and considered. To compare the advantages and disadvantages of the CIC, a central decision maker is designed and utilized too.
Combined intelligent control
The CIC combines different methods and architectures in intelligence, distributed intelligence and control areas to reach a high level of intelligence by emphasizing their strengths and eliminating the weaknesses of each architecture. Natural environments are dynamic, nondeterministic and complex and if agents want to be efficient, they must have a high level of intelligence same as any natural creature. A robot must have the special abilities to do different goals and tasks and the CIC tries to provide these abilities. The CIC is a distributed structure. Thus, it can provide some abilities such as unlimited development, high fault tolerance, cooperation, ability to do various tasks, needless of accurate modeling of environment and other agents, making global decisions by local information.
Problem definition
Recently there have been a number of proposals for the use of artificial evolution as a radically new approach to the development of control systems for autonomous robots (Jun Ota, 2006), (P. Husbands & I. Harvey & D. Cliff & G. Miller, 1997) [11]. Coordinating the motion of multiple mobile robots is one of the fundamental problems in robotics. Here we introduce a common example to test our idea. An unspecified number of robots with different abilities are selected to perform tasks such as moving and arranging objects. The robot environment is dynamic and nondeterministic and the position of agents, robots, obstacles and goals change. Some of the tasks can not be done by one robot and a group of robots should cooperate together to do them. Each robot recognizes and decides about cooperation with other robots. It is possible for robots to fail. Other robots must support the failed robot and do its task. Robots decide distributively, i.e. each robot has the ability to make decisions to select tasks, goals, movements or to cooperate with other robots according to its perception. Thus, there is not any unique central decision to command robots.
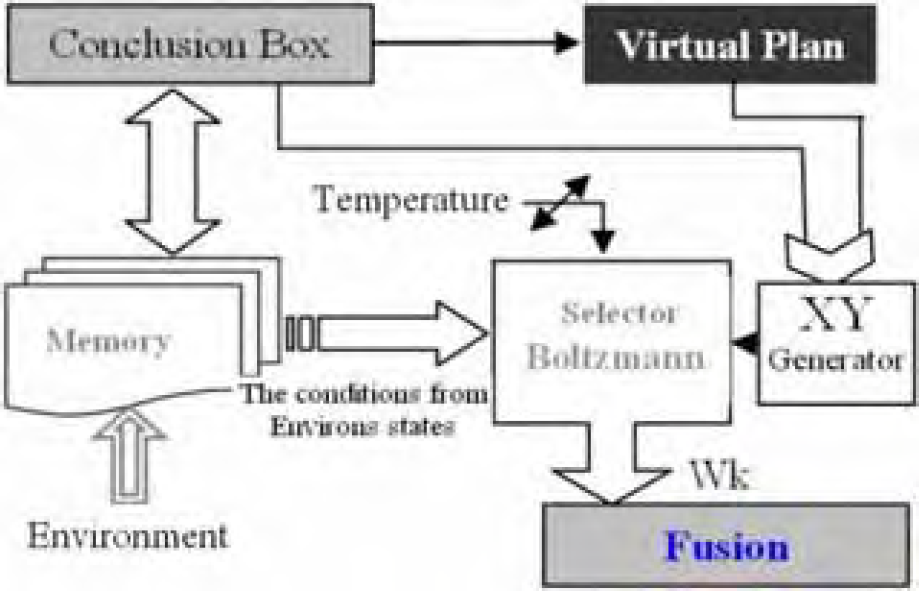
General operation
The schematic of CIC operation is shown in Fig. 1. Each robot has this structure in its mind. In the cooperation part, robots select their tasks with the use of market mechanism method. In this method, robots attempt to increase their profit and decrease expenses. The profit of each robot is defined in accordance to collective tasks. Cooperating or not cooperating with other robots would be clarified in this part. After determining the task, the estimator will guess the geographical position of the goal according to experience and logical rules. The different parts such as subsumption (leaning on behaviorist opinion), learning (leaning on Q-table), history box (leaning on memory) and mental input (leaning on logical rules and virtual plan) propose movements with different weights. The fusion part should make the final decision due to its inputs from other parts. A genetic-neural network algorithm can improve the operation of this part. If a group of robots cooperates, one of them will be selected as the leader and others should follow it. The leader robot is selected due to its expertness. The expertness criterion is determined by BDI-Based 3 part. If a robot has more knowledge and more ability, it has higher expertness and so the robot can select better actions and earn more profit. Thus, it can suggest more profit to other robots and other robots will select it as their leader. All robots during their movements analyze and learn their environment; therefore, the general operation of the collection will be improved.

The schematic of Combined Intelligent Control (CIC)
A fundamental problem in business-to-business exchanges, here selection tasks by robots, is the efficient design of mechanisms to promote cooperation and coordination of various self-interested agents (D.J. Wu & Yanjun Sun, 2002) [2]. If there is a few number of robots and ability of each agent is defined completely and there is not any related problem among the agents, it is ideal to use a central decision maker to divide the tasks and to define cooperation among the agents. In case of increasing the number of agents, due to the localization of information, central decision maker will lose decisiveness. A distributed architecture, i.e. Market Mechanism, in cooperation box, using economic rules solves this problem. Other robots and the weights of bodies require inputs to this part. The outputs are cooperation or not cooperation decision with other robots or giving cooperation requests to other robots. Outwardly, the result is increase in personal profit. But generally, tasks were done in the least amount of time and energy. Marketing rules consist of:
Agents obtain money for performing tasks proportional to weight, importance and priority. Thus, robots would attempt to move maximum weight in the least amount of time to win maximum profit. Robots pay expenses for energy and deterioration in accordance with the movements it performs. Therefore, to obtain more profit, the robot must optimize its movements. Collective profit is described as the accomplishment of all tasks in minimum time and expenses, i.e. less energy consumption, less movements and less deterioration. Robots make transactions to cooperate in heavy tasks. A leader robot is selected based on expertness to divide the profit among all other robots. If an agent or some agents are destructed, more money would be paid to other robots for doing their task. So the tasks of failed robots would be performed by others.
The first priority in task selection belongs to common tasks that are suggested by other robots. It guarantees cooperation among robots to perform heavy tasks. This selection follows this algorithm:


In these formula B is the robot's profit, K is the robot's profit coefficient, F is the expense, W is the priority of task, A is robot's ability and T is probable selected tasks. Parameter i determines the decision maker robot and j determines other robots.
The second priority belongs to tasks that are performed alone by the robot:

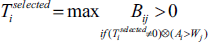
And in the third priority, the case of not selecting personal or collective task, the robot suggests cooperation with other robots:

Where b is the suggestion from agent i to agent j. A task is not performed only when it is beyond the agents' capabilities. Fig. 2 shows a schematic of operation of market mechanism part.

A schematic of the operation of Market Mechanism part
When two or more robots try to do a task, one of them accepts the responsibility of leading the others. In fact, the leader offers demands to the other robots and other robots analyze the profit of cooperation and decide to cooperate. Leader costs to attract the cooperation of the robots. After doing the task, the leader gains the profit of the task. The leader selects the actions and in cooperation mode, other robots receive location of leader and track it.
Subsumption as a behaviorist architecture includes behavior control layers that are designed from bottom up (Patrick A.M. Ehlert, 1999) [10]. At first, the zero layer, containing lower level behaviors, is designed and then the higher level behaviors will be added to reach the appropriate behavior in the collection. The main task of subsumption architecture in the robot is to make the appropriate movement decision. Behaviors consist of: the motion toward the guessed goal, cooperation behavior
4
, escaping from obstacles and anti crash behaviors, gripping behavior and anti-woozy behavior. Fig. 3 shows a schematic of the relations among the behaviors. Each behavior makes an output according to its operation and sensory feedback. Each behavior can affect the lower behaviors in two ways: Suppress and Inhibit. Due to the reciprocal influence of behaviors, a general behavior appears in output of subsumption part and enters the fusion part. If we consider x and y
5
as the moving dimensions, the motion toward the goal behavior for each moving dimension will be:


Relations between behaviors in behavior box
In this formula, Δx and Δy determine the velocity in the direction of x and y. k is the expertise coefficient that is determined according to the frequency changes of environment and robot's knowledge about its environment. More robot knowledge will result in higher expertise coefficient, which leads to bigger steps for robot in movement.
Escaping from obstacles
6
and anti crash behaviors are followed by this algorithm:
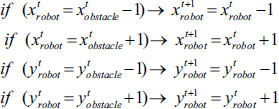
This relation states that when a robot reaches close to an obstacle or other robots, it moves in the opposite direction. In such conditions, weight of behaviorist part has its maximum value. Robot avoids all of obstacles and robots except its collaborating robots.
Sometimes robots falter in dead-zones and they can not make any decision to unfetter themselves. The anti-woozy behavior produces a random and nervous action. Such action may be able to transfer the robot from the dead-zone to new states.

The anti-woozy signal will be active if robot moves in the limited area far from the goal frequently.
The required logical rules could be added without limitation in this section. These rules could be developed according to the requirements. Some examples of usable logical rules include:
A close look at human behaviors shows us the following logical rules: “There is a much lower probability for an action to be selected in the next stage if it causes a repetitive state. The probability of selecting such an action depends on the knowledge of the agent”. According to the above rule, the History Box must determine the appropriate movement by taking into account the record of all past movements. The probability is determined either by a neural network learning algorithm or by hand, in the Fusion Part. History box has two essential parts (Fig. 4):
According the empirical results, it is suggested that B and C be 0.01 and 50 respectively. In addition, degree of temperature, that defines movement history dependency, should be taken 0.1. To distinguish between movement choices and different histories, parameters are needed to be defined in a specified range. A parameter in fusion part will improve the optimization. If robots are in a state where the only possible movement is return to the previous state, it is most probably a closed path that robot can't pass through it (Fig. 5). Therefore, it is presented as a closed path.
That is to say, if robot moves from block St to St+1 and the only possible movement from there is to move back to block St, the St+1 is a closed path. This rule can be generalized to a long path and therefore in this case robot will be able to learn a longer closed path. In dynamic environments, robot just can have a surmise about closed path. But in static environments, if all of the blocks are reviewed once, robot will be able to recognize all possible closed paths exactly. However, the environment is not completely known for robots to build a complete map from it due to uncertainty, but leaning on limited information gained from environment, robot can build a virtual map of the environment (Fig.6 (b) & (c)). The appropriate decision can be made using different methods such as fluid flow idea. The best instantaneous path can be guessed with use of stream function ψ. If robot was assumed as source, goal as a sink and other robots and objects as obstacle, by having ψ optimal path can be found instantaneously. Thanks to the inherent dynamic property of the robots and obstacles, the generated paths must be updated dynamically. Sometimes robots falter in the ⊂ shape (U-turn) obstacle. Robot can understand it if its movements were repeated frequently. In this situation, robot increases the exploration radius (Fig.10). Robot can detect only one block around itself. Obstacles are dynamic and it is possible for an obstacle in vicinity of the robot, to run over it. So if the robot detects any occupied block around itself, the robot moves in the opposite direction
7
. This will result in an invariable distance of one block between the robot and obstacles.

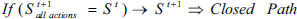
A schematic of interaction between the mental input, virtual plan and history parts

Robot has visited all the blocks of closed path part and has recognized this path is closed

(a-Left) In the static environment if robot visits all blocks, it can recognize the optimal path. (b-Right) In the dynamic environment or when robot has not met all blocks, it can suggest many paths with a lower reliability.
One of the most important capabilities of intelligent creatures is their ability in learning. Learning causes the intelligent creatures to recognize environment during their life and perceive the rules of environment to achieve a better operation and adapt themselves with dynamic and nondeterministic environments (Richard S. Sutton& Andrew G. Barto, 1998) [14]. In the above collection, there are two kinds of learning: The first is related to finding and improving the estimation parameters in fusion parts that are followed by neural network algorithm. The second is to learn and recognize the robots' area and it is followed by Q-Learning technique.

In this case, the ɛ-Greedy method for the choice of movement and Greedy method for learning are used. S is the beginning area and E is the ending area that robot must travel. A new dimension is added to the formula. By using this idea, robots learn environment according to their position of goals. It is necessary for the robot since the starting and ending of goals differ. Equation 12 determines the probability of selecting each action:

By using the batch-updating technique and TD (λ)
8
, robots can increase convergence rate in learning. But practical experiences show that sometimes robot can not find the optimal path by this idea. For example if robot reaches a goal by pacing a non-optimal path, batch-updating or TD (λ) causes most of the blocks in path to partake in final prize. Thus, selecting this path is of higher probability in the next step. The best suggestion is that robots utilize their Q-Table when their expertness would be enough. Expertness would be determined by BDI algorithm
9
.
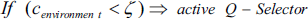
Cenvironment and ζ are determined by BDI-Box and show the environment's complexity and the robots' expertness. Robots must accomplish some tasks in different positions. Each robot divides environment into six areas. Related to the start and end of the path, the robot updates and uses one of their Q-Tables that contains knowledge about these areas. For increase of the convergence of learning rate, robots utilize cooperative learning (M. Nili Ahmadabadi& M.R. Barouni Ebrahimi& E. Nakan, 2003). Robots share their Q-Table with each other and each robot can update its Q-Table by using other robots' data. Robots can earn very good results by using Cooperative learning. By simulation software and after 200 cycles and comparing results, we conclude that the convergence of learning rate increases by about n0,672 times where n is the number of robots. (Fig. 7)

The array Q (st, at, Startarea, Endarea) in cooperation learning: Robots share their Q-Tables to increase the convergence rate.
Choosing the goal and cooperation situation is done in market mechanism part. The movement decisions are made according to the different environment's conditions in various parts such as subsumption, mental input, history box and Q-table. Due to different abilities of each part, decisions could be contradictory. For example, the learning algorithm may make a movement decision in accordance with its Q-table and the mental input part guesses that the path is closed and suggests a different movement. All decisions are transferred to the fusion part and the final decision will be made in this part. The final decision is a result of comparing all of the suggestions from other parts by a certain weight. It means that any part specifies a unique happening probability for all possible movements. Fusion part multiplies a coefficient factor in the happening probability and adds them up for any movement state. The best movement is determined as the output from the fusion part by using ɛ-Greedy method according to the total importance of happening probability.

In this formula, n is the number of total possible movements and ɛ is a parameter that determines the intensity of exploration. Normal values of ɛ have been considered 0.1. The values of weights (Wij) have an important role in optimization of the collection's operation. A neural-network algorithm can determine the values of these weights. The used method is MLP with BP learning technique. For a good convergence rate, we should appropriate suitable initial values to weights in the fusion. These initial values are specified by genetic algorithm from other robots that have enough expertness. These values will be optimized after the beginning of the robot's operation by neural network algorithm 10 . Fig. 8 shows the various sections of fusion part.

Structure of fusion part: Wij have an important role in finding the optimal path.
The simulation software is designed in Visual C#.Net 2005 interface to show the operation of the collection and defects of the CIC architecture. To show the ability of the CIC algorithm as a distributed architecture, a central argorithm is designed and compared with the CIC.
Central architecture: The central architecture (CA) uses the normal and conventional ways to make decision. The central architecture is a computer that takes all data from the robots and the environment without any limitation of communications. The CA produces a variety of virtual decisions for agents based on some simple logic laws and after that simulates the decisions in virtual environment. The CA analyses all the data and results and dictates commands to the robots after comparing results and selecting the best of them. For dynamic and nondeterministic environment, the algorithm updates decisions in each cycle. Some of the laws in the CA are as follow:
The best selection is the one that produces minimum movements for robots. Any crash with obstacles or other robots is unacceptable. Some tasks could be done by more than one robot, …
We can simulate both central and distributed architectures, CIC, in the simulator and compare their results. In this simulator, we can determine the number of robots and tasks by variety of abilities and properties independently. In addition, we can select some dynamic or static obstacles by deterministic or nondeterministic motions. All the abovementioned parameters are optional and the user can change them.

Simulation software
The user can change the exploration coefficient and environment's complexity or destroy any agent or robot to show the fault-tolerance capability. The robots or agents are equipped by the CIC architecture. Robots only know their abilities and they don't have any information about the environment, tasks or the number and abilities of other robots. They obtain this information during the activity. User can eliminate some of the CIC's parts and see the results of their corresponding effect.
Simulation shows the benefit of each robot and a normalized factor that is named efficiency factor. Robots must pay expense for any movement or decision they make. When robot considers a bid from other robots, suggests cooperation to other robots, or analyzes the movement decisions, its fund decreases. The robot earns benefit, if it cooperates with the leader robot or transfer tasks to the goal position. The benefits are calculated by these formulas:

Where f is the initial finances of the robot and WC is the total weights that robot has carried out and v is the priority factor. If a task has large priority factor, robots try to carry it out faster, because they earn more profit. So we can allocate a large amount of v for important tasks. E is the expense that robot must pay. For more benefit, robots must try to carry out tasks in the least amount of time, movement, communication and calculation. This formula is used for calculating the efficiency η for each robot:



In this formula ηaverage is general efficiency of collection and enormal IS the normalized error. The enormal is usable when an optimal path is founded. If robot is obsolete, it can't have much activity, because the probability of its failure is higher. So the tendency of the robot to perform tasks will be lower. The ψ coefficient can identify the tendency of the robot for doing tasks. Efficiency would be shown for each robot in the simulation software.
A summary of results will be presented
11
After using the simulation software and comparing and analyzing the results. Simulation software helps us to compare results in both central and CIC architectures. In addition, user can toggle on or off any internal part and consider their operation alone or along with other robots. These results can be generalized in the real set.
The behavior-based part can make suitable reactive decision such as escape from dynamic obstacles and crash avoidance with other robots. But it is necessary for other parts of the CIC to be involved in getting around obstacles. For example, robot cannot pass by the U-turn obstacles without using the logic box. The logic box, especially history-box, has a high efficiency for passing obstacles when the robot falters in complex obstacles (Fig. 10). The market-mechanism part performs well for division of tasks among robots (Fig. 11). Each robot by use of the marketing rules in the market-mechanism part can decide to cooperate too. Virtual plan in the logical part helps increase the rate of convergence in finding the optimal path after increasing the expertness. When the number of robots and tasks increases, not only the performance of collection does not decrease, but also efficiency increases, and it is one of the most important CIC's abilities. It seems that it is one of the inherent properties of the distributed architecture such as CIC. In the especial case with 3 robots and 9 tasks, we added further robots. Fig.12 shows that the average efficiency of the central decision maker decreases, but it increases in case of the CIC. So the CIC can perform well in extending collection. After expertness of the robot reaches a satisfactory level, learning part can ameliorate robot's movements. Commonly learning part may decrease efficiency in environments with high frequency of changes. Thus robots must not use it initially (Fig. 13). In addition, testing the CIC algorithm shows that the fault-tolerance is very high. For example, if any robot or agent fails on its task, other robots accelerate to cooperate and help the failed robot to accomplish its task. This ability helps the collection to solve the communication shortcoming among agents too
12
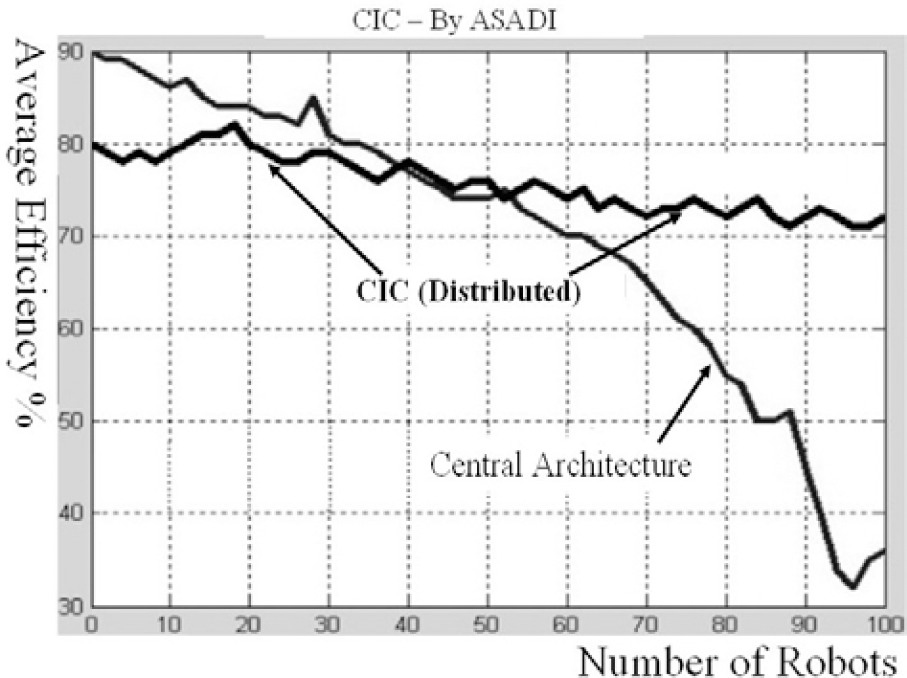
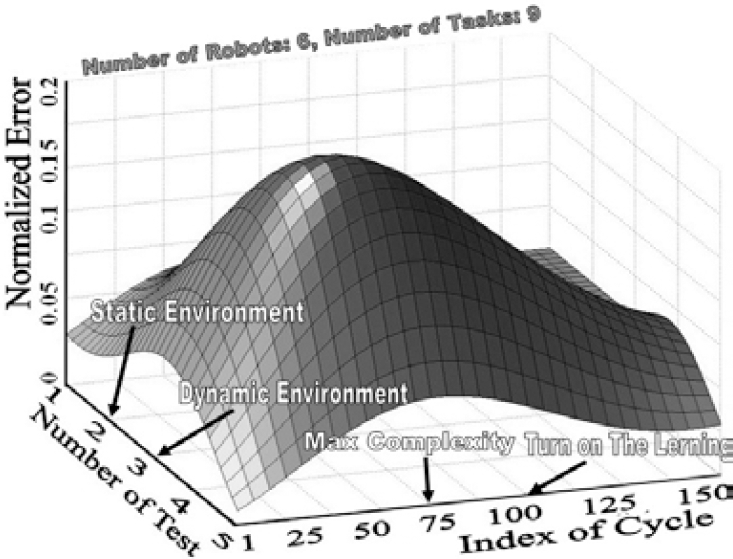
. Generally, unlike the central architecture, if complexity increases in CIC, general efficiency will decrease a little (Fig. 14). Complexity is a function of dynamics, number of robots and tasks, limitation of communications and possible faults. One of the most important parts is fusion that has an acceptable performance. But if the weights were refined, for example using artificial neural network or genetic algorithm, the performance will increase. We do not use neural network and genetic algorithm here, because most of the time results were not acceptable. We extracted some results from NN and GA and selected better ones manually. Besides, computations in the CIC are much less than that of central architecture (Fig. 15). Although the CIC is designed for dynamic and nondeterministic situation, it performs well in static and certain environments. In the static and deterministic situations, the central part, by complete sensory feedback, suggests the optimal paths. So it's possible to compare the CIC performance by optimal answers. Fig. 16 shows the normalized error of a collection. Learning decreases the normalized error after many cycles. To consider the effect of each part in the CIC, as seen in Fig. 17 and 18, each part of the CIC was turned off separately. The tests were repeated in variety of conditions and outcomes were recorded. It can be seen, if behavior-based box is inactivated, the average efficiency of the collection decreases too much. The order of importance of the CIC parts are behavior-based part, Logic-part (especially history-box) and learning part respectively.

Logic box increases the exploration radius, so robot can maneuver some complex obstacles
Market Mechanism as a distributed architecture in CIC has better efficiency than a central decision maker when the number of robots increases

The efficiency increases by extending the collection in the CIC.

These figures show two collections of multi-robots. Both of the collections emphasize that the learning does not have a good result in environments with high frequency of changes. For solving this problem, Action selection by learning-Box was turned off till BDI-box turns it on.

Average efficiency decreases in CIC less than the central decision maker when complexity increases
Learning can decrease the normalized error in static or dynamic environment with low frequency of changes.
Computation in the CIC is less than the central architecture.

By combining some algorithms, we obtain a more efficient algorithm. In this figure, we can see the effect of each algorithm in the CIC.
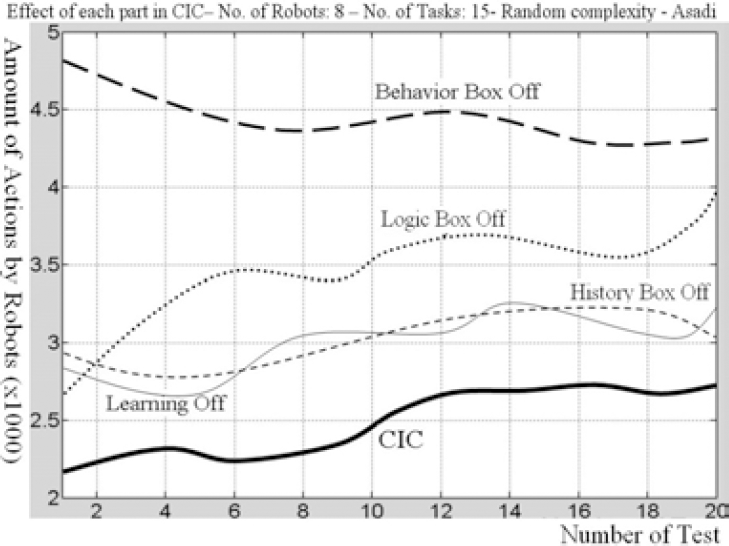
When we turn off each of the CIC's components, robots must take more actions to do tasks. So we can consider the effect of each algorithm.
Other advantages can be seen in the simulation software.
The results show that the CIC has satisfactory performance and high level of intelligence for decision making in multi-robots collaborations in complex and nondeterministic environments. In static environment, a central architecture has a better performance than a distributed architecture. But when the complexity of environment increases, the CIC as a distributed architecture can perform better than a central architecture. In the CIC, fault tolerance is high and the unlimited expanding of the set is possible and simple.
Footnotes
1
We added some limitations to robots, especially in sensory feedback and communication, to show up the ability of the CIC to make better use of data.
2
In the simulation software robots move on the area with 100 rows and 200 columns.
3
Belief-Desire-Intention
4
The cooperation signal comes from market mechanism part.
5
Robots move in a grid word. In real word we can decrease the dimention of grids. So equation 6 and ![]() can use in real word too.
can use in real word too.
6
All of the obstacles and robots except collaborating robots are assumed obstacles.
7
We assume robots are very simple and the CIC can make decision by limited information. In real environment, we can add other sensors such as vision to qualify operation.
8
In the TD (λ) method e starts big and consequently should be ecreased as the agent learns.
9
BDI (Belief-Desire-Intention) algorithm for determining the expertness is considered in other paper.
10
Details of operation of fusion part in optimization of Wij by using neural network and genetic algorithm will be presented in the other paper. For the first time we used guesstimated values manually.
11
Some conclusions can not be represented graphically or textually and can be observed in practice (i.e. in software simulation)
12
In the simulation software, operator can destroy each robot and see the consequent result.