
Abstract
This paper proposes a target tracking method called Incremental Self-Updating Visual Tracking for robot platforms. Our tracker treats the tracking problem as a binary classification: the target and the background. The greyscale, HOG and LBP features are used in this work to represent the target and are integrated into a particle filter framework. To track the target over long time sequences, the tracker has to update its model to follow the most recent target. In order to deal with the problems of calculation waste and lack of model-updating strategy with the traditional methods, an intelligent and effective online self-updating strategy is devised to choose the optimal update opportunity. The strategy of updating the appearance model can be achieved based on the change in the discriminative capability between the current frame and the previous updated frame. By adjusting the update step adaptively, severe waste of calculation time for needless updates can be avoided while keeping the stability of the model. Moreover, the appearance model can be kept away from serious drift problems when the target undergoes temporary occlusion. The experimental results show that the proposed tracker can achieve robust and efficient performance in several benchmark-challenging video sequences with various complex environment changes in posture, scale, illumination and occlusion.
Keywords
Introduction
Visual tracking [1] [2] is one of the most important tasks in many applications of robots, such as vehicle tracking and control [3], military reconnaissance [4], security surveillance [5], non-rigid target tracking [6], and investigation of robotics [7]. The main challenges related to visual tracking include scale and posture variation of the object, illumination change, complex and clutter-like background, motion or viewpoint of the camera [8] and occlusion, inevitably causing large appearance variation. All these difficulties cause a target to change in a video sequence. This problem can be overcome if the target model can be appropriately updated during tracking. Many methods have been proposed to achieve stable model updating, such as that based on subspace learning, the most representative methods of subspace learning to model target appearance is PCA subspace algorithm [9]. Inspired by this idea, an incremental 2D-PCA is proposed in [10] to significantly reduce the computational cost of 2D image signal; also, an incremental linear discriminant analysis (ILDA) is proposed in [11] to separate target samples and background samples. For the mixture model, the most popular method is to integrate a Gaussian mixture model into an online expectation maximization (EM) framework to handle target appearance variations during tracking [12]. Online boosting-based work was proposed for feature selection and successfully applied for target tracking in [13]. This method was also applied to classify pixels belonging to foreground or background.
All the above methods focus on representing the adaptive appearance model. Unfortunately, a significant problem is neglected, i.e., how to select the optimal update opportunity, which directly influences the accuracy and efficiency of the appearance model update [14]. Almost all state-of-the-art tracking approaches, based on incremental adaptive appearance model, rigidly employ a mechanism that updates the appearance model in every frame or in a fixed step (e.g., every five frames). However, this kind of updating strategy lacks adaptability because the appropriate update time is hard to determine. The long-step updating strategy cannot keep up with the changes of the target; the short-step updating strategy is vulnerable to the drifting problem, and is more time-consuming. There are several complicated situations that should be considered for model updating: 1) the model should be updated when the background or the target encounters significant changes in video sequences, 2) the model should not be updated frequently if the model maintains stable adaptability, in order to be less time-consuming, 3) the model should not be updated if severe occlusion occurs to avoid the problem of model drifting. Therefore, neither a short-step nor a long-step fixed updating strategy can guarantee the validity of the model update, which may degrade the model or cause fast drift over time.
The key to selecting a suitable update opportunity for the model is to measure the adaptability of the current model during tracking. The model should be updated whenever adaptability is lost. Otherwise, the tracker should skip the updating procedure. A self-updating strategy is proposed in this paper, based on the measuring adaptability of the appearance model. Since model updating is used for tracking the target, i.e., to distinguish the target and the background, the adaptability of the appearance model should be measured by using the discriminative capability changes, Dfc, to determine whether the current model needs to be updated or not. Compared with the fixed-step update strategy, our self-updating mechanism can capture the optimal update opportunity and eliminate the majority of unnecessary updates during tracking. To achieve the above goals, an Incremental Self-Updating Visual Tracking (ISUVT) method is proposed to validate the effectiveness of our proposed updating mechanism. In the ISUVT tracker, three features (Greyscale, Histogram of Gradient (HOG) and Local Binary Pattern (LBP)) are used to represent the targets. A particle filter is adopted as a search mechanism, which predicts the target state in the next frame based on the recent target state. Furthermore, three Incremental FDA (IFLDA) classifiers are trained online with the ISUVT tracker by sampling target data and background data for each of the three features. According to the trained classifiers, the current target can be located by selecting the most similar particle. Using the pre-trained classifiers to classify target samples and background samples in the current frame, the discriminant capability of each feature is obtained. Whether the current sub-model should be updated is determined by the change of discriminant capability between the current frame and the previous updated frame. If updating is indeed required, the tracker will repeat the IFLDA training by sampling current data until the best target model is obtained. The framework of the proposed ISUVT tracker is illustrated in Fig. 1.

Basic flow of the proposed tracking approach
The rest of the paper is organized as follows: Section 2 briefly introduces the feature representation of the target. Section 3 deals with the proposed self-updating strategy and Section 4 shows the implementation of the ISUVT algorithm in detail. The experimental results of the tracker are presented in Section 5, followed by a conclusion in Section 6.
The basic component of a visual tracking system is target representation. However, ultimately no feature is suitable for all tracking conditions. Therefore, multiple features should be extracted for tracking the target in the whole sequence. In this work, three features are extracted to form the adaptive model: Greyscale, HOG (Histogram of Gradient) and LBP (Local Binary Pattern). Since ISUVT adopts a particle filter as the search mechanism – i.e., the tracker detects the target state from all of the candidate particles in the current frame according to the prior state – every particle corresponds to a candidate image region. In other words, the tracker extracts Greyscale, HOG and LBP features for every particle. These three features can be used to measure the similarity of every particle with the target particle of the previous frame. The most similar particle will be chosen for locating the target in the current frame.
Greyscale is the basic feature of an image. Many existing trackers use it for target representation; however, the Greyscale feature is vulnerable to illumination changes and noisy data. In this paper, we combine the Greyscale feature with HOG and LBP to form a robust feature representation. HOG [15] is a widely used gradient-based feature and is considered to be one of the best feature descriptors to describe a target's edges and shapes. To accelerate the calculation of HOG, we employ an integral histogram [16]. LBP is a powerful feature for texture classification; it has been determined that LBP and HOG features can better detect humans in conditions of partial occlusion [17]. These three features should form a stable representation. Figure 2 gives visual examples of these three features.

Three kinds of feature representation of the target
Since it is very hard to track a target for a long time using a fixed-appearance model, the target model must be able to self-update. In this section, we will elaborate our self-updating strategy in detail. The tracking procedure can be divided into two stages: observation and updating. At the observation stage, our tracker samples data randomly and extracts features of each sampled data. At the updating stage, the Dfc value between the current frame and the last updated frame is calculated to determine whether the current model should be updated. Part A below shows how IFLDA (Incremental Fisher Linear Discriminant Analysis) is used in ISUVT. Part B introduces the observation stages. In Part C the discriminant capability of the appearance model is evaluated, and the updating strategy is discussed in Part D. The optimal updating occasion will be analysed in practice in order to derive our self-updating strategy.
Feature classification by FLDA
Many discriminant classifiers have been used for binary classification in visual tracking applications, including SVM and Fisher Linear Discriminant Analysis (FLDA). Since the efficacy of Fisher Linear Discriminant Analysis in visual tracking has been demonstrated in [11] and [18], this classifier is employed in our ISUVT tracker. The aim of traditional FLDA in target tracking is to find an optimal discriminative generative model that can be used to separate the target samples from the background samples and seek a linear transformation matrix,

Since the target and background samples are separated in transformation space, we estimate the similarity in transformation space instead of feature space. However, if the target appearance is changed, the transformation space may lose its discriminant capability for target samples and background samples. In this case, the transformation matrix
In this work, target tracking is achieved by using a particle filter. The tracking process is governed by the observation model of the particle filter framework, as is well known. We shall therefore introduce the observation model adopted by our tracker first. The variable

where σ is a constant and DIFFi is defined as
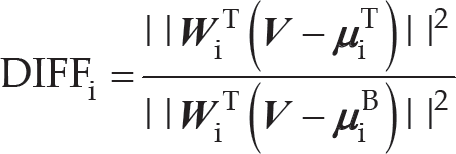
where i represents the ith feature and
The equation = DIFFi (d1i, d2i, · dk1) denotes the distance ratio of drawn particles between the target class and the background class. When d k i is smaller than 1, the kth particle is closer to the state of the target, which is classified into the target class while the opposite is classified into the background class.
After the previous observation step, the drawn particles are classified into two classes. In the likelihood maps, the particles are divided into two classes:

Particles that are far away from the classification boundary will make a greater contribution to estimating the final tracking result and evaluating the discriminative capability of the appearance model, while particles near by the boundary cannot be selected for this task. In order to eliminate the influence of trivial DIFFi value and highlight the discriminative capability, DIFFi is stretched:

To judge class separability of the target and the background, class variance is defined as:
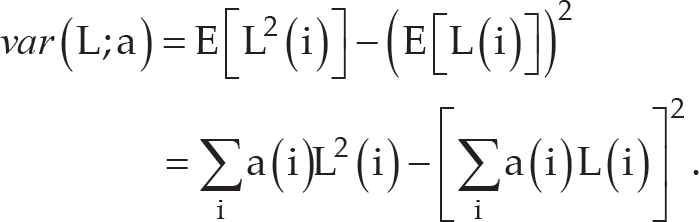
where a(i) denotes the probability density function of the various distribution.
The Variance Ratio (VR) of the target and the background is then calculated by using the new distribution of the particle likelihood maps and the discriminative capability maps, and the appearance model D i can be obtained as:

where p and q denote the distribution of the target class and the background class, respectively, in likelihood map Li. A high value of Di indicates that particles of both the target class and the background class are tightly clustered, respectively (low intra-class variance), so that the two classes are well separated from each other (high inter-class variance); this means that the appearance model is more able to discriminate between the target and the surrounding background.
Since ISUVT extracts three features for target representation, our tracker can adaptively choose the optimal feature and allocate online a different weight to every feature for fusion in each frame, according to the change in the target and the surrounding background. Only a feature with high discriminative capability can make a significant contribution to the final tracking result. The tracking performance depends on how distinguishable the target is from its background. The greatest weight should be assigned to the feature with the greatest ability to discriminate between the target and surrounding background. A fusion strategy for the multiple features is employed here based on the Variance Ratio method [19] [20].
The weight w i is approximated using the normalized VR.
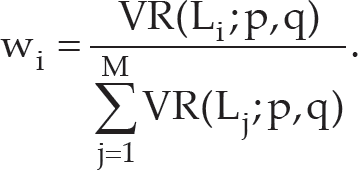
To compute the final state P(

where L i denotes the particle likelihood map generated by the ith feature from previously extracted features, and the adaptive weight factor of this likelihood map is represented as W i .
Once one feature fails, it will be distributed as a very small weight. Therefore, it cannot seriously influence the tracker. Because the weights of likelihood maps are adjusted in every frame, the tracker can adaptively choose online the best feature for tracking. When dealing with significant challenges such as variation of posture, scale and illumination, the tracker is more robust and accurate than other methods.
During tracking, the model needs to be updated incrementally using the new data obtained in order to efficiently adapt to the changes in various environments. However, most existing algorithms employ a rigid update mechanism with a fixed-step of frames; thus, they cannot capture the optimal occasion to update the appearance model. In this paper, we propose a smart self-updating strategy, which can evaluate the stability of the appearance model and the change in the tracking environment based on the change in the discriminative capability of the appearance model.
The demands for selecting the optimal update time will be analysed first. The appearance model is more robust and accurate when it can exactly distinguish the target from the background. When the model loses this discriminative capability, the tracking performance drops. When the tracker encounters a significant environmental change for the first time (e.g., illumination changes from bright to dark), the discriminative capability of the model inevitably declines in the current frame, because the model lacks prior information on the current situation. Therefore, the model should be updated when it degrades to a certain level.
Considering another situation, when the tracking condition gradually reverts to the previous state (e.g., illumination changes back to bright condition), the discriminative capability will rise in the current frame, because the appearance model still retains classification ability in the restored state, based on the prior information training from previous frames. In this case, the increase in discriminative capability shows that the target itself is more distinguishable from the background in this frame, and the tracker should collect positive and negative samples to strengthen the stability of the model. Moreover, when occlusion or accidental error occurs, the classification is not reliable, and all the prediction locations of the target might be classified into the background class, which will lead to dramatic change in discriminative capability. Because this change would greatly exceed the normal range, the occlusion or obvious error can be detected during tracking, thus firmly avoiding updating in the current frame.
As discussed above, the optimal update time and the change in the tracking surroundings can be captured by evaluating the change in the discriminative capability of the appearance model between the current frame and the last updated frame.
In the proposed self-updating strategy, the discriminative capability of the appearance model is the result of the fusion of the discriminative capabilities of multiple independent sub-models; the discriminative capability Do resulting from the fusion can be expressed via weighting the discriminative capability Di of each independent sub-model with the normalized weight.
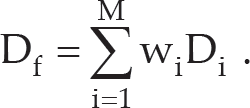
The extent of change between the current frame and the last updated frame is defined as:
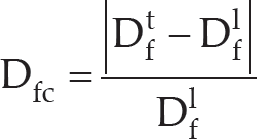
where Dtf and Dlf represent the discriminative capability of the appearance model in the current frame and the last updated frame, respectively. During tracking, the tracker evaluates Dfc after finding the target location in every frame to determine whether the model should be updated.
Once the condition τu ≥ Dfc ≥ τo is satisfied, with τu and τo being default thresholds, the ability to separate the target from the background changes within a predetermined range and the appearance model should be updated. Occlusion or accidental error could occur when Dfc > τo, and the tracker should firmly avoid updating in such a scenario. When Dfc < τu, although a change is present, the appearance model is still stable enough to separate the target and background accurately. Therefore, updating can also be avoided to improve efficiency. By adopting the self-updating strategy, the tracker can intelligently capture the optimal update opportunity, which is beneficial for improving efficiency and avoiding the serious drift caused by wrong updating.
If Dfc satisfies certain complex conditions, as mentioned above, the tracker needs to update the appearance model. It is not necessary to repeat the retraining, calculating the inter-class scatter matrix
In this section we will describe aspects of our ISUVT tracker in more detail, including particle-filter framework, multiple-feature representation, evaluation of discriminative capability and updating appearance model. The basic flow of the proposed ISUVT tracker is illustrated in Figure 3.

Basic flow of the proposed tracking approach
As the last section showed, the main tracking procedure can be divided into the observation stage and the updating stage.
At the particle observation stage, suppose that we know the target state of the last frame or initial state. Our tracker randomly selects positive and negative samples from the target class and background class respectively to train the IFLDA classifier online. Then, our tracker estimates the similarity, called DIFF, between each particle and the target of the last frame, and generates the likelihood maps of the current frame. The DIFF will also be used in the updating stage since it decides our model's adaptability during tracking.
At the updating stage, we firstly evaluate the likelihood maps using DIFF at the particle observation stage. According to the likelihood maps, the tracker will detect the best candidate particle as the current target state. Then, by calculating the discriminant capability in the current frame we obtain the discriminant capability of the current frame. Finally, we can obtain Dfc from the current frame and last updated one. Our tracker can easily determine whether it needs to be updated or not based on the Dfc value. If necessary, our model will be updated by retraining the IFLDA classifier online using the recent data.
When our model extends to multi-feature representation, we will add feature fusion strategy in generating the likelihood maps and calculating the discriminant capability. In fact, each fusion weight assigned to generate the likelihood maps and to calculate the discriminant capability is a coefficient obtained by normalized Variance Ratio.
In this section, we design a two-part experiment to demonstrate the efficiency and robustness of the proposed method. Firstly, the proposed self-updating strategy is compared with the fixed-steps updating strategy. Secondly, the tracking performance of ISUVT is compared with the state-of-the-art tracker Incremental Visual Tracking (IVT) [9]. IVT is used for adjusting the appearance model automatically based on Incremental Principal Component Analysis – widely accepted to be a robust tracking method.
The number of particles in IVT is set to 600, and every image patch is resized to 32×32 in [9]. To significantly diminish the calculation cost and demonstrate the validity of the proposed self-updating strategy, the number of particles and the size of each image patch is reduced to 300 and 16×16, respectively, in both of the tested algorithms in this paper; other parameters of IVT remain at the default values provided by the authors. Furthermore, the two thresholds τu and τo used at the self-updating stage are set as 0.3 and 0.7, empirically based on our trial and error experiments. If we set τu too small and τo too large, the tracker will be sensitive to subtle changes and update its model frequently. On the other hand, if we set the two thresholds too close to each other (i.e., large value of τu and small value of τo), the tracker will be unable to update its model. All the parameters of the two algorithms are kept constant during the experiments.
To show the robustness of the proposed method for dealing with different situations, the datasets used in our work are video sequences challenging the current benchmark, involving temporary occlusion, variation in posture, scale, illumination, and complex background. For all these sequences, the ground truths are manually labelled. Except “Tank” and “Fighter” which are captured by our research group, all the other video sequences are downloaded from [21].
Self-updating vs. fixed-steps updating
In this section we will compare our ISUVT with the fixed-step updating strategy adopted by Incremental Visual Tracking (IVT) in four aspects, as mentioned below.
Dealing with severe occlusion with minor tracking error
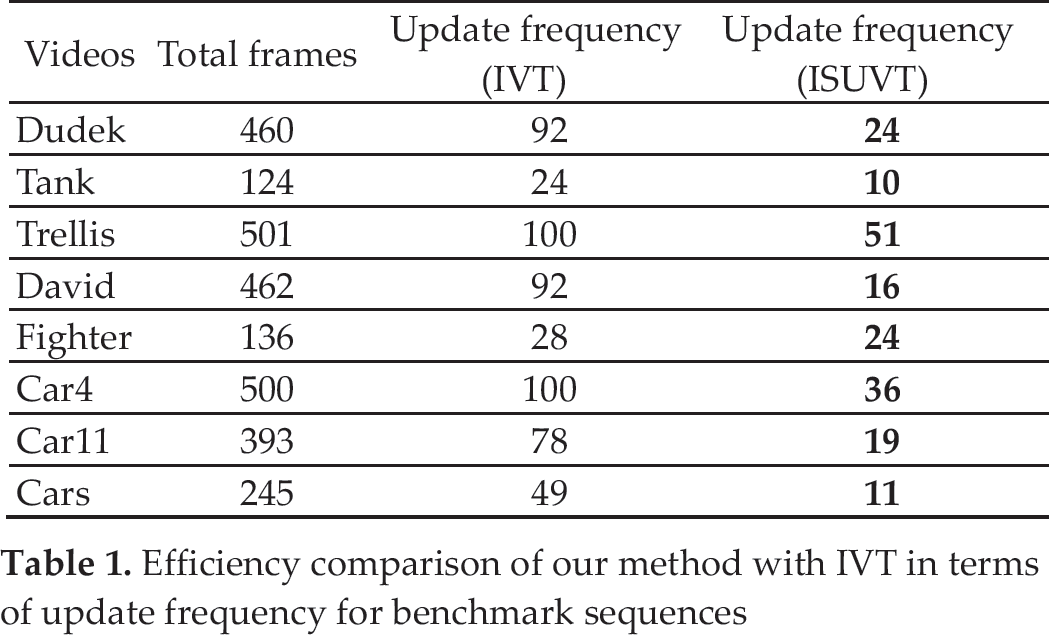
The “Tank” video sequences contain a moving tank with full occlusion caused by flame and smoke after it fires. It can be clearly seen from Fig. 4 that the tank undergoes full occlusion during frame 44 to frame 60, so that the Dfc curve faces dramatic changes in these frames. In this period, IVT updates three times, in frames 45, 50 and 55, respectively, since IVT updates its model every five frames. As a result, as shown in Fig. 5, IVT loses its target with large tracking error. However, ISUVT maintains tracking performance with minor tracking error. Using two thresholds [τu, τo] in the updating stage, our tracker can detect effective or poor updating opportunities, as shown in Fig. 3.

The Dfc curves with corresponding video frames of “Tank”, ISUVT (green dot), and IVT (red dot)

Tracking results of “Tank” sequence
To estimate the tracking performance for a target whose appearance model changes slowly, two sequences (“Dudek” and “Car4”) are selected in our experiments. The tracking results show that minor errors are put out by the ISUVT tracker with less updating time than IVT, which adopts the fixed-steps updating strategy.
The target tracked in the “Car4” sequence is a moving car that undergoes large illumination and scale changes. The tracking results are presented in Fig. 6. The IVT tracker gradually drifts away after a heavy illumination change under a bridge in frame 190. The ISUVT tracker, however, can track the target quite well. From the curve shown in Fig. 8, ISUVT can choose the optimal update time around frames 56, 190, 235 and 304 in this sequence. According to the result show in Table I, ISUVT updates 51 times while IVT updates 100 times in total.

Tracking results of the Car4″ sequence: ISUVT (green dot), IVT (red dot)

Tracking results of the “Dudek” sequence: ISUVT (green dot), IVT (red dot)
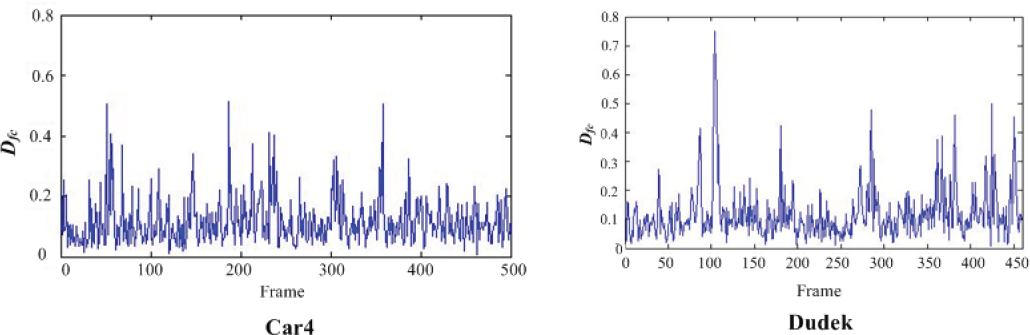
Dfc curve of “Car4” and “Dudek”
In the “Dudek” sequences, the target is a moving face that undergoes temporary occlusion and large changes in motion and lighting. The tracking results are presented in Fig. 7. From the Dfc curve shown in Fig. 8, it can be seen that ISUVT updates in several frames of the sequence, including frames 85 (face moving), 185 (taking off glasses), 277 (smiling), and between frames 350 and 450 (large motion and lighting changes). When temporary occlusion takes place, there is a dramatic change in Dfc that is beyond the set range, so the proposed appearance model holds stable without being updated. The tracking objects in the above-mentioned video change slowly, but IVT loses the target gradually while ISUVT holds it in a stable way. Figure 9 shows the tracking errors of IVT and ISUVT in these two video sequences. The ISUVT updates 24 times while the IVT tracker updates 92 times (as shown in Table 1).

Tracking error in “Car4” and “Dudek”
Efficiency comparison of our method with IVT in terms of update frequency for benchmark sequences
The target tracked in the “Fighter” sequence is a flying fighter jet that undergoes severe scale changes and changes in position and rotation due to motion. From Table I we can see that IVT updates 28 times while ISUVT updates 24 times. Although both trackers can track the target successfully, the ISUVT tracker is more accurate in both scale and location tracking, especially in the period where the target shrinks to a very small size. From the Dfc curves, we can clearly see that in the first half of the sequences, ISUVT seeks fewer updating occasions compared with IVT, since the appearance of the target changes slowly. On the other hand, in the second half of the sequences, ISUVT increases its updating frequency according to Dfc changes, while IVT remains the same. As a result, ISUVT is able to follow changes in the fighter, as Fig. 10 and Fig. 11 show.

Tracking results for the “Fighter” sequence: ISUVT (green dot), IVT (red dot)
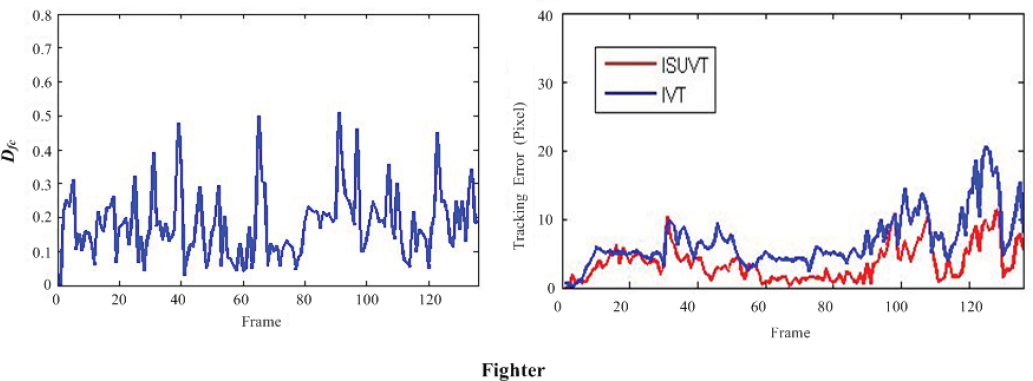
Dfc curves (Left) and tracking errors (Right) in “Fighter” sequence
To compare the efficiency of the two trackers, we list the number of corresponding updates in every tested sequence in Table.1. The IVT tracker updates the appearance model every five frames. Compared with the IVT tracker, the proposed method is more efficient and obtains more precise results with lower update frequency.
Tracking the target in a challenging environment
The first part of the experiment has shown that our proposed self-updating strategy is superior to the fix-steps updating strategy. In the second part we also have estimated the robustness of ISUVT through several video sequences challenging the benchmark with various disturbing factors such as illumination changes, posture changes, scale changes and complex background.
Illumination, posture and scale-changing environment
The target tracked in the “Trellis” sequences is a man walking by a trellis covered by vines. As shown in Fig. 12, the IVT tracker and the proposed tracker are both robust when the lighting conditions vary drastically; however, IVT fails completely when the man also shows severe posture changes in frame 340. From the D fc curve (shown in Fig.14) we can see that the ISUVT tracker updates frequently during the period when the target undergoes both illumination and posture change, which guarantees the robustness of the appearance model.

Tracking results for “Trellis” sequences: ISUVT (green dot window), IVT (red dot window)
The target tracked in the “David” sequences is a moving face undergoing illumination, posture, and scale changes. The tracking results are shown in Fig. 13. Although both trackers track the target successfully, the ISUVT tracker is more stable than IVT, which is especially clear in frame 173. The ISUVT tracker is more stable and robust under the challenging conditions. The D fc curve is presented in Fig. 14.

Tracking results for “David” sequences: ISUVT (green dot), IVT (red dot)

Dfc curves for “Trellis” and “David” sequences
The target tracked in the “Car11” sequence is a moving vehicle driven in a very dark outdoor environment. From the tracking results shown in Fig. 15, it is obvious that the IVT tracker faces a drifting problem from frame 208. Although IVT can roughly detect the position of the target over the whole sequence, these results are not as accurate as those delivered by ISUVT. The Dfc curve of this sequence is presented in Fig. 17. The ISUVT is more efficient when carrying out the updating procedure, with updates occurring in almost the last part of the sequence when the background becomes more complex, which effectively prevents drifting of the appearance model.

Tracking results for “Car11” sequence: ISUVT (green dot), IVT (red dot)
In the “Car” sequence, a moving car is experiencing interference with very similar targets in a low-constrast environment. The tracking results are presented in Fig. 16. The IVT tracker exhibits unstable behaviour in frames 132 and 147, when the target is close to a tree and a similar car, respectively. Tracking performance of the ISUVT tracker stays very good throughout the sequence. The corresponding Dfc curve is presented in Fig. 17.

Tracking results for “Cars” sequence: ISUVT (green dot), IVT (red dot)

Dfc curves for “Car11” and “Cars” sequences
To quantitatively compare robustness and accuracy, the ground truth of the sequences was manually labelled. The evaluation of tracking errors is based on the relative position errors (in pixels) between the centre of the tracking result and that of the ground truth. The quantitative comparison results are shown in Fig. 18. Our method produces smaller tracking error for almost all sequences.
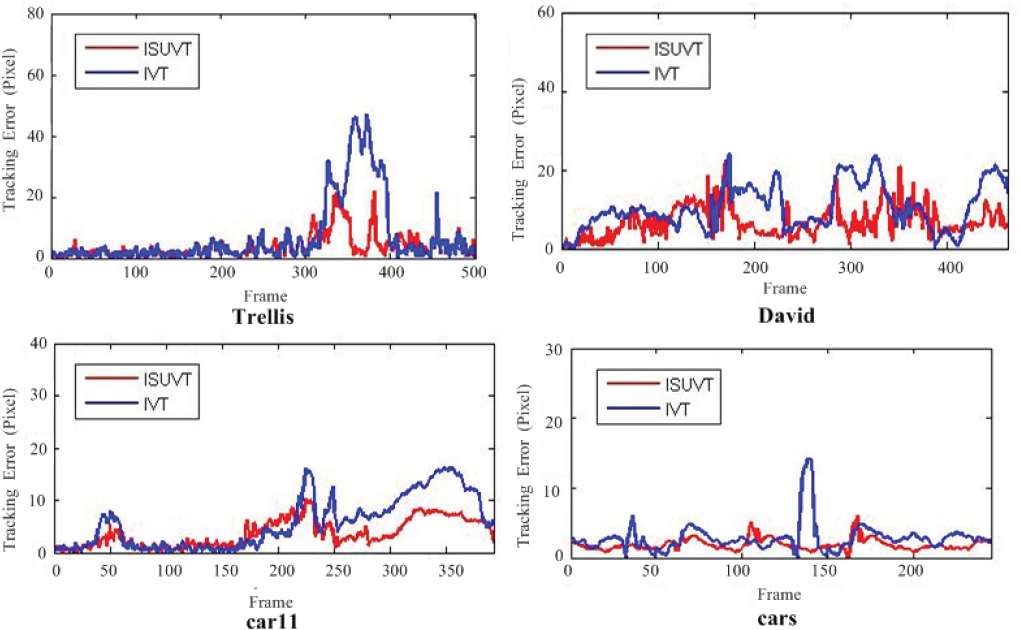
Quantitative comparison for benchmark sequences of ISUVT (red line) and IVT (blue line) in terms of position errors
This paper has proposed a robust and efficient online tracking algorithm and presented a smart self-updating strategy. Compared with the fixed-step updating strategy, self-updating can better detect optimal updating opportunities to solve the update efficiency and drifting problem. From experiments carried out in different challenging datasets, we can draw some conclusions:
The established self-updating mechanism can select the optimal update opportunity based on the change in the discriminative capability of the appearance model between the current frame and the last updated frame. In this way, the tracker is able not only to reduce unnecessary computation in updating when the appearance model is still stable, but also to keep the appearance model away from significant drift problems when the target undergoes temporary partial occlusion. The proposed tracker (ISUVT), which uses multiple features for target representation and adopts the self-updating strategy, can achieve higher efficiency and greater precision with minimal updating times compared to IVT.
In future work, we would attempt to introduce Multiple Instance Learning (MIL) into our method, which can solve the drifting problem and achieve better sampling performance for tracking tasks over long periods. The computing speed of the method could also be improved in order to integrate the proposed tracker into a robotic system.
Footnotes
7. Acknowledgements
This research was supported by the National Natural Science Foundation of China (No. 60802043, No. 61071137, No. 61271409), the National Basic Research Programme (also called 973 Programme, No. 2010CB327900), the China Postdoctoral Science Foundation (No. 2012M510768, No. 2013T60264) and the Natural Science Foundation of Hebei Province, China (No. F2013203364). The authors also thank Prof. David Ross for providing the code for the IVT tracker.