
Abstract
This paper proposes a novel Neural-Immunology/Memory Network to address the problem of motion control for flapping-wing Micro Aerial Vehicles (MAVs). This network is inspired by the human memory system as well as the immune system, and it is effective in attenuating the system errors and other lumped system uncertainties. In contrast to most existing Neural Networks, the convergence of this proposed Neural-Immunology/Memory Network can be theoretically proven. Both analyses and simulations that are based on different immune factors show that the proposed control method is effective in dealing with external disturbances, system nonlinearities, uncertainties and parameter variations.
1. Introduction
The development of flapping-wing MAVs has been spearheaded by the demand of developing autonomous, lightweight, small-scale flying machines that are appropriate for a variety of missions, including reconnaissance over land, in buildings and tunnels, and other confined spaces. Of particular interest is the ability of these vehicles to operate in the urban environment and perch on buildings to provide situational awareness to military combatants.
There are numerous examples of highly successful flapping fliers existing in nature that could provide us with another perspective in designing MAVs. During the past few years, a number of flapping mechanisms have been developed and demonstrated in a limited fashion - for example, Aerovironment's Microbat and University of California (UC) Berkeley's Micromechanical flying insect [1], [2].
In consideration of the similarities [3] between the characteristics of numerous flapping fliers existing in nature and the requirements of future flapping MAVs, perhaps that which best demonstrates the characteristics we wish to employ in an agile MAV is the hummingbird, as shown in Fig. 1. The hummingbird species's size range and seepd range are similar to thoseof MAV-class vehicles [4–7]. Wing lengths range from about 33 mm to 135 mm and wind-tunnel tests have revealed their maximum flight speeds to be as high as 27 mph. This study explores the vibratory flapping dynamics inspired by the biomechanical system of hummingbirds. In particular, we are interested in the motion of the wing mounted on a MAV.

Hummingbirds and Flapping-wing MAVs
Note that micro air vehicles operate in a very sensitive Reynolds number regime in which many complex flow phenomena take place within the boundary layer. Due to the lack of knowledge about the fundamental flow physics within this regime, many dynamic effects might not be reflected with the current flapping wing model, which could causes failures during practical implementation [8, 9]. To neutralize any such conflict, a novel Neural-Immunology/Memory Network is proposed in this work.
Neural network-based (NN-based) control has been widely applied in various systems - see, for instance, [10–18]; however, most NN-based control algorithms confront one or some of the following issues: 1) A large amount of training data is needed to pre-construct the network, and although many improved NNs are able to update themselves online, their accuracy heavily relies upon the selected training data. 2) There is no existing theory to regulate how to build a NN, such as how many layers there should be or what kind of base function should be used. As a matter of fact, constructing a NN is always time consuming and empirical. 3) A practical NN contains large quantities of neurons, which brings with it a heavy computational burden and requires a great deal of memory space. 4) Usually, network reconstruction is a necessity when the system dynamics change, even very slightly. 5) There is no theoretical proof to guarantee the stability of the control system.
In the most recent decade, researchers turned to biological systems to look for inspiration [19–22] in order to overcome the deficiencies of traditional NN approaches. In this paper, inspired by the human memory system and the immune system, we propose a Neural-Immunology/Memory Network (NIMN), in which the aforementioned disadvantages is associated with most NN-based control methods. In this work, the Neural-Memory Network [23] [24] is presented first as a foundation, and then the superior NIMN is elaborated as we introduce the so-called ‘immune selection factor’.
More specifically, NIMN is very easy to construct - it does not rely upon a precise system model and it demands less computation Energy compared with most other methods. It is able to learn from both past experience and current observed information to improve its performance. Moreover, there is no need for network reconstruction or consistent weights to update even if the system's dynamics change significantly. These features have been verified via both theoretical analysis and simulation study.
2. Neural-Memory Network
A. Fundamentals
Human memory is one of the most intriguing biological phenomena in nature [25] [26]; it is what makes possible so many of our complex cognitive functions, including communicating and learning.
There are close links between learning and memory. The existence of memory depends upon previous learning, and learning can most clearly be demonstrated by good performance on a memory test. Learning and memory involve three stages (see Fig. 2):

Human memory/learning system
B. Analogies between a Human Memory System and a Neural-Memory Network
The proposed Neural-Memory Network (NMN) simulates the mechanisms and procedures of the Human Memory System (HMS) described above. The analogies between HMS and NMN are presented in Table 1.
Analogies between HMS and NMN
C. Neural-Memory Network Structure
Considering an arbitrary system with the following system dynamics:

where f(.) and g(.) are two nonlinear functions, Δf represents uncertainties in this system and u is the control signal. Defining a symbol e = x – x* to denote the control error, where x* represents the desired state, a 1st-order Neural-Memory Network is depicted as in Fig. 3.

1st-order Neural-Memory Network
This 1st-order Network includes four types of neurons. These are past experience neurons, objective neurons, feedback neurons and observation neurons, whereby w1, w2, w3 and w4 represent their respective weights and k is the step counter. Note that observation neurons are not necessarily required.
An mth-order Neural-Memory Network is illustrated in Fig. 4, in which m denotes m steps backwards.
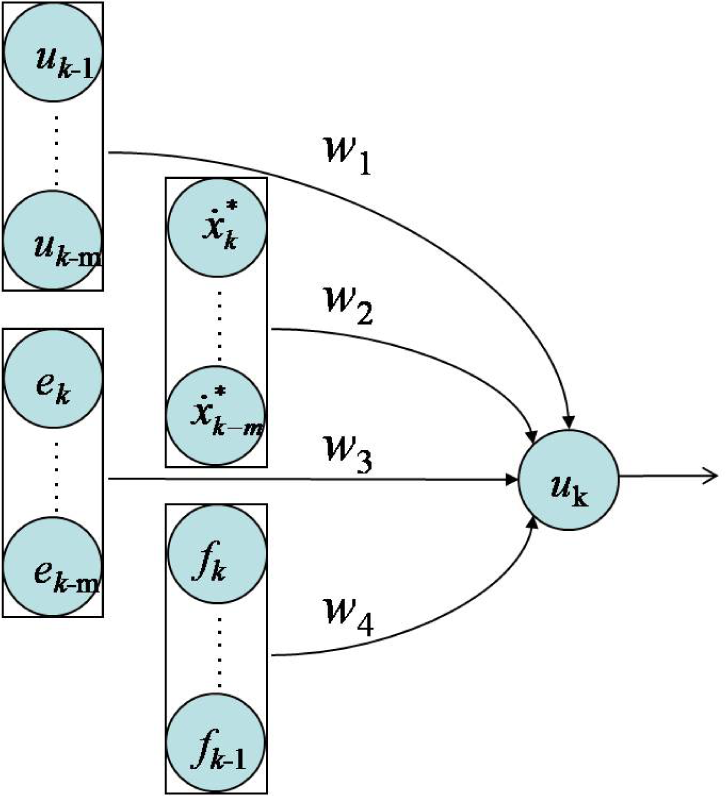
mth-order Neural-Memory Network
D. Stability Analysis
In this section, the theoretical analysis for the system's stability is given. However, and for simplicity, only the proof for the 1st -order network's stability is detailed step-by-step.
According to the network structure depicted in Fig. 3, we have:

The weights for the 1st-order are chosen as:




Please refer to our previous work for the details of the weight settings [23]. Therefore, using the Euler approximation, we get:


With(7) minusing (8), uk being defined in (2), and weights given in (3) to (6). It can be readily shown that:
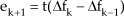
Therefore:

where:

donates the maximum variation rate of the disturbances and uncertainties Δf, which is assumed to be bounded due to the fact that in general such variation cannot be infinitely fast, otherwise no control strategy is able to work.
As a result, and because the sampling interval t is a very small number, any tracking error is confined within a narrow envelop defined by t2c0. The observation neurons, F, are not necessarily required for the same reason, namely that it is not possible that f be able to change infinitely quickly.
A similar analysis can be made for the higher-order case. Presumably, a higher-order Neural-Memory Network leads to better control precision because more of the earlier (longer-term) memory is incorporated within the control scheme, though more computations are involved.
Refer to Table 2 for the weights of higher-order Neural-Memory Networks.
Higher-order weights

4. Application to Micro Aerial Vehicles
A. System Dynamics
Based upon a study of the skeletal structure of hummingbirds and the existing literature [25], [26], an artificial vibratory flapping system - as shown in Fig. 5 - is developed to describe the wing flapping motion.
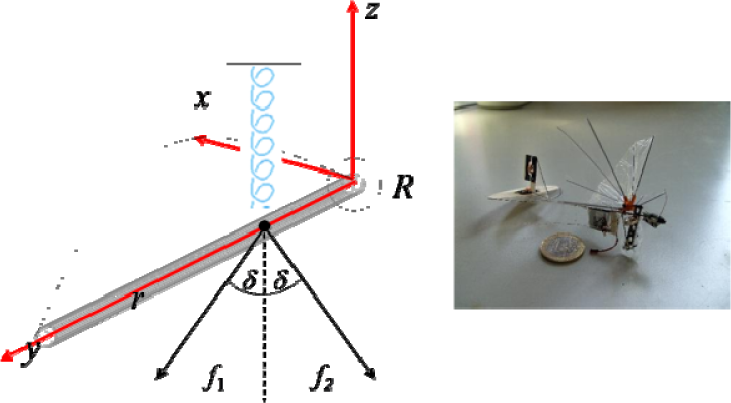
Schematic representation of the vibratory flapping system
Two reference frames consisting of a body-fixed axis {e1, e2, e3} and a wing-fixed axis {x, y, z}, are defined, both having their origin at the shoulder joint. An ideal column with a length l and a radius r is used to represent the humerus. Located at distance l1 from the shoulder joint, a pair of exogenous forces is introduced to represent the depressor muscle, whereby each of f1 and f2 composes an opposite angle δ to z axis. At the same location, a vertical spring with a stiffness k donating the elevator muscle is placed, the justification for representing this muscle with a single spring is that this muscle travels around and over the top of the coracoid, reversing direction and attaching to the sternum; therefore, this constrains the line of action of the elevator muscle in passing through a point at the top of the coracoid, just like the force generated by the spring.
The flapping motion dynamics is thus given as:


where

and C = diag(c1 c2). v is the free stream speed; therefore, G[F1 F2]T, Nkl12 and vC[p q]T correspondingly denote moments due to actuating forces, restoring forces and damping forces. Δb represents the model constructing error and J is the moment of inertia. [p q]T represents the angular velocity of the wing-fixed frame with respect to the body-fixed frame, and Φ and θ are Euler angles respectively referred to as flapping and folding motions. Y is the transformation matrix.
B. Neural-Memory Network Control Design
To derive the control input for the flapping motion, the system dynamics is rewritten as follows:
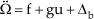
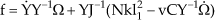

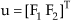
where Ω = [Φ θ]T, u = [F1 F2]T. Moreover, note that because neither of the Euler angles Φ nor θ could physically reach ±π/2, matrix G and Y are always invertible.
Defining symbol s = ė + βe, where β >0, it is easy to prove that s converges to zero as e goes to zero. Using the 1st-order Neural-Memory Network, it is easily shown that:

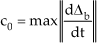
For the same token, s is bounded and therefore e is bounded within a narrow envelop.
C. Simulation Verifications
To verify the effectiveness of the Neural-Memory Network, numerical simulations on flapping wing motion control are conducted using the first-order network. The parameters used for simulation are chosen as: t = 0.01s, k = 10N/m, v = 10m/s, δ = 40°, C = diag(0.1, 0.06) and the uncertainty Δb = [10sin(t)+5 15cos(4t) – 8]T, which is time varying constantly.
Two types of motion are simulated.
[1] High speed cruising
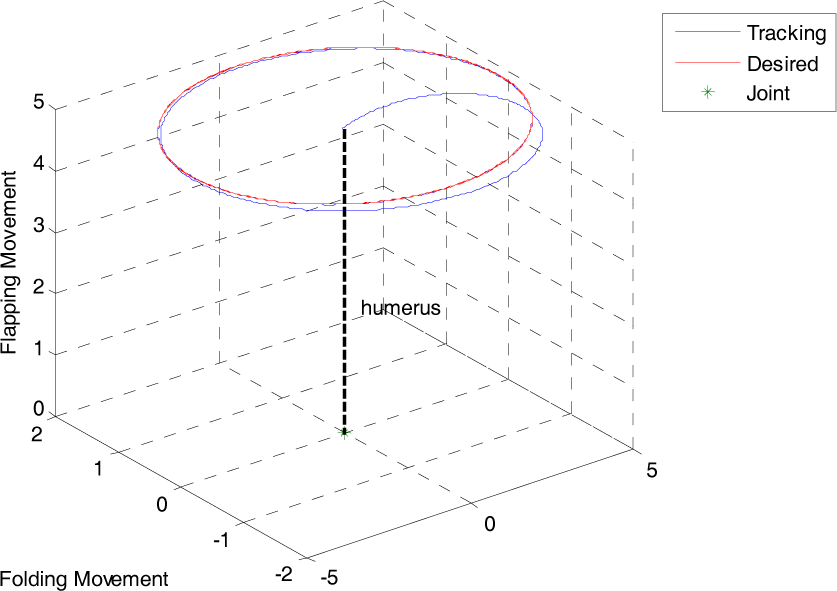
In this mode, the hummingbird swings both of its wings along a pair of elliptic trajectories, as shown in Fig. 6. Fig. 7 compares the desired wing-tip trajectory and the tracking trajectory using the 1st-order Neural-Memory Network. The control output u is shown in Figure 8.

A forwarding hummingbird's wingtip motion

Simulated wingtip movement trajectories
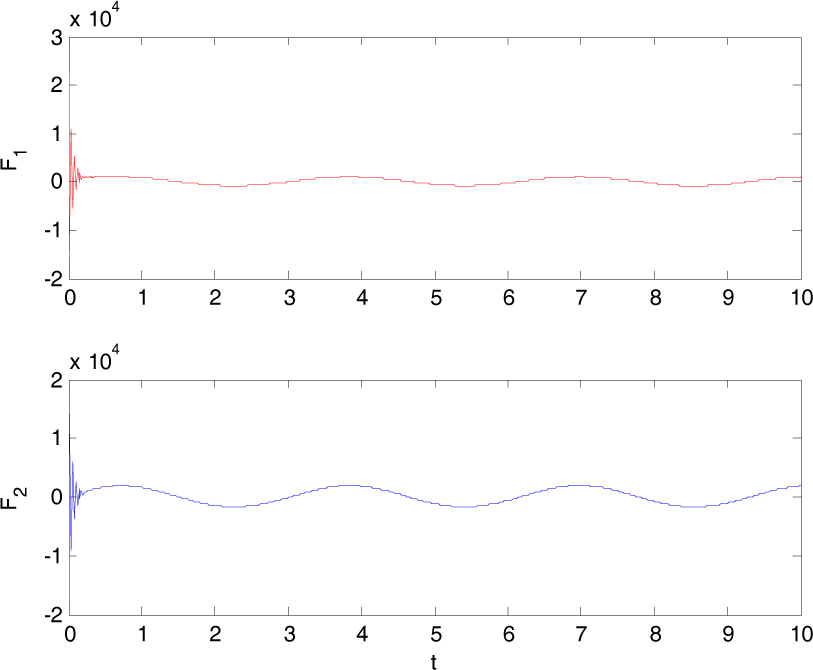
Control outputs
[2] Reverse.
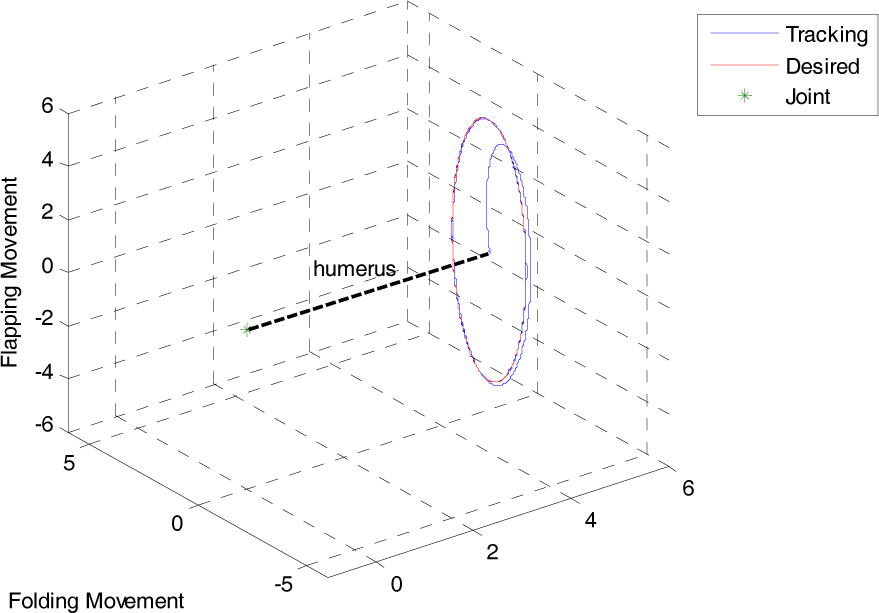
When the hummingbird is flying backwards, its wingtip trajectory yields a pair of ellipses on top of its body, as shown in Fig. 9. The trajectory tracking performance is illustrated in Figure 10. Moreover, the angle tracking and control action are shown in Fig. 11.
A Hummingbird flying backwards
Wingtip trajectories for a reversing motion

Control outputs for reversing motion
In order to further test the robustness of the proposed Neural-Memory Network, a 30% random variation is added to the free stream speed by the equation:

where rand is a function generating a random number from 0 to 1. In addition, a more complicated motion - hovering - is simulated. The corresponding simulation results are shown in Figs. 12 and 13. Note that the proposed Neural-Memory Network still works well, whereas most existing control strategies would fail in such a complicated environment.

A hovering hummingbird

Wingtip trajectories for a hovering motion
From the simulation results above, it is clearly seen that the tracking performances in either scenario (constant free stream and random free stream) are fairly good. However, the control output magnitudes are relatively large at the beginning of every simulation and so this phenomenon is understandable because little experience has been gained at that point, and hence the Neural-Memory Network is relatively immature. In order to overcome this problem, the Neural-Immunology/Memory Network has been developed, which will be addressed in the next section.
5. Neural-immunology/memory network
A. Immunology Inspiration
The human immune system is a dynamic and intelligent system [27–29]. Once one kind of antigen invades our body, a general immune response is initiated by the immune system. After the invading antigen gets acquainted, a more specific immune response begins to work against the antigen.
The human immune system works on two levels with the general goal of pathogen control: a general response mechanism, called ‘innate immunity’ that does not directly respond to any specific pathogen, and a specific, antibody-mediated response mechanism called ‘acquired immunity’.
At the beginning, and because of the lack of knowledge about the antigen, the immune system selects a sort of universal antibody to take effect (innate immunity). After the antigen becomes better understood, a much more matching and effective kind of antibody is activated to fight (acquired immunity).
B. Neural-Immunology/Memory Network Structure
The overall immune system is similar to a complicated and intelligent network, which dynamically adjusts its neuron (antibody) weights to react to the antigens.
Therefore, a novel neural-immunology/memory network is constructed, as follows [30, 31]:

where u is the overall network output, and ui and ua stand for the innate response and the acquired response respectively. σ is a function adjusting the engagement of each response, which is called the ‘immune selection factor’. Fig. 14 illustrates the structure of the neural-immunology/memory network. Note that σ, the immune factor, ranges from 0 to 1, and normally grows form 0 to 1. Similar to the immune system, this network works on two levels as well. When a little experience is gained, ui dominates, but as experience accumulates, the acquired response, ua, phases in.

Neural-Immunology/Memory Network Structure
C. Immune Factors
In the simulation, innate response network is chosen as ui = -ke, which is a traditional proportional control approach. The acquired response ua is the Neural-Memory Network. However, the question of how to choose an appropriate immune selection factor is an issue. In this paper, two candidates are presented and discussed.
1. Hard Switch

This means that at the beginning, only ui works and, after a certain period, u2 replaces u1 completely and suddenly. Fig. 15 illustrates a hard switch function.

A hard switch
For the purpose of clarity and concision, only a forward cruising motion is tested in this section. The tracking result is shown in Fig. 16 and the control outputs are depicted in Fig. 17.
Tracking trajectories of the hard switch
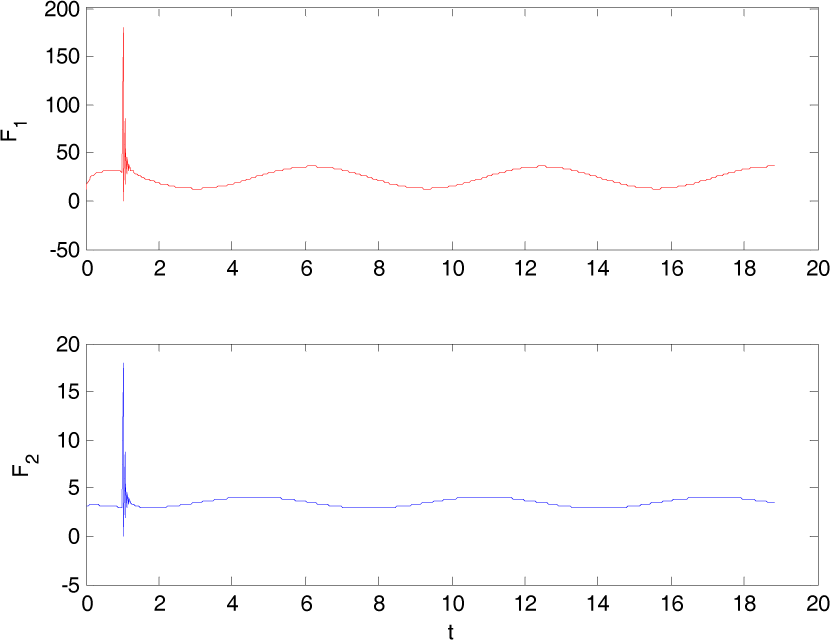
Network outputs under the hard switch
2. Self-adaptive Switch

Obviously, this immune selection factor incorporates control error and varies as the magnitude of e changes. When ‖e‖ is large, which means that the antigen is not well understood, the function value approaches 0 and therefore the innate response tends to function more; whereas when ‖e‖ is small, which means that learned experience is precise, the function value goes to 1 and thus the acquired response begins to work. Fig. 18 illustrates the tracking trajectories, Fig. 19 shows the network outputs and Fig. 20 gives the curve of σ.

Tracking trajectories of the self-adaptive switch

Control outputs of the self-adaptive switch

The working curve of the self-adaptive switch
6. Comparison and Analysis
In this section, the NIMN is compared with the NMN and a traditional BP-NN. All of these 3 approaches are applied to flapping control and the results are shown in table 3.
Comparison Results

Data training is time consuming and the selection of training data is very tricky. NIMN and NMN do not need any training data, but data training is essential to BP-NN. 500 sets of training data are applied to train the NN initially, but the control results are very unstable in using the trained BP-NN. Therefore, the number of training data is increased to 1,000 sets and then the NN begins to work properly.
The control energy is evaluated by ∫‖u‖dt. The control input magnitude of NMN is very high at the beginning, and hence the control energy that NMN needs is relatively high compared with that of both NIMN and BP-NN. Because no memory (experience) is gained for NMN at the beginning, so the control input varies drastically (a large magnitude) in searching for the balance point. However, the control energy that both NINM and BP-NN needs is low or medium because of the help of the “innate response” and the training data.
The control accuracy (evaluated by ∫‖e‖dt) of BP-NN is almost as good as the other two approaches, but only provided that the training data is sufficient and properly chosen. However, the time that BP-NN needs for one iteration is many times longer than that needed by either NIMN or NMN, as there are many neurons involved in BP-NN's computation.
7. Conclusions
In this paper, a novel Neural-Immunology/Memory Network is proposed. It is inspired by the memory system and the immune system.
The proposed Neural-Immunology/Memory Network overcame the shortages of the Neural-Memory Network. However, different immune selection factors resulted in different network outputs. It can be observed that with a more intelligent immune selection factor, the control outputs tended to be smoother.
This Neural Immunology/Memory Network is especially efficient and superior when it is applied to a system with lots of disturbances and uncertainties because of the fact that it requires little information about the disturbances and uncertainties and does not rely upon precise model dynamics.
Footnotes
8. Acknowledgments
This work is supported by the National Natural Science Foundation of PR China (grant No. 61105115)