
Abstract
This paper presents a vision based pose estimation system using knowledge based approach for human-robot symbiosis. The system is based on visual information of the face by connected component analysis of the skin color segmentation of images in HSV color model and is commenced with the face recognition and pose classification scheme using subspace PCA based pattern-matching strategies. With the knowledge of the known user's profile, face poses are then classified by multilayer perceptron. Based on the frame-based knowledge representation approach, face poses are being interpreted using the Software Platform for Agent and Knowledge (SPAK) management. On face pose recognition, robot is then instructed to perform some specific tasks by issuing pose commands. Experimental results demonstrate that the subspace method is better than that of the standard PCA method for face pose classification. The system has been demonstrated with the implementation of the algorithm to interact with an entertainment robot named, AIBO for human-robot symbiotic relationship.
1. Introduction
The meaning of the word ‘symbiosis’ as defined in the American heritage dictionary is “A close prolonged association among two or more different organisms of different species that may but does not necessarily benefit each member” ( The American Heritage Dictionary, 2006 ). Recently, this biological term has been used to describe similar relationships among broader range of entities (Ueno, H., 2002).
As robots increase in capabilities and are able to perform more human-like complicated tasks in an autonomous manner, we need to think about the interactions that human will have with robots. There are several ways to communicate with human beings and intelligent machines (e.g. robot, vehicle, etc.) such as text commands, speech commands, gesture commands, eye tracking commands, and so on. Text command based approaches are more rigid but it is not natural compared to visual perception of human-robot communications. Although the verbal command based human–robot interaction systems have been used based on few keywords (such as walk, turn left, turn right, stop walking, move right, etc.), but nevertheless, have been found with many difficulties to generalize human speeches. This paper proposes a facial pose recognition based human–robot nonverbal interaction system to communicate with robots more likely to human. Attention is focused on vision based face recognition and then to interact with robot using pose commands of the known user.
A fair amount of research works have been published in literature on face pose based human-robot interaction. Two approaches are commonly used to interpret the face pose for human machine interaction. One is gloved based approach (Sturman, D.J., & Zetler, D., 1994) that requires wearing of cumbersome contact devices and generally carrying a load of cables that connect the device to a computer. Another approach is vision based technique that does not require wearing any of contact devices with human body part, but uses a set of video cameras and computer vision techniques to interpret poses (Vladimir, I.P., Sharma, R., & Huang, T.S., 1997). Face pose recognition based on vision technology has been emerging with the rapid development of computer hardware of vision system in recent years and in future will dominate in Human-Computer and Human-Robot Interactions. The poses are being modeled by relating the appearance of any face to the appearance of the set of predefined, template poses. S. Waldherr et al. proposed a gesture-based interface for human and service robot interaction. They combined template-based approach and neural network based approaches for tracking a person and recognizing gestures involving arm motion (Waldherr, S., Romero, R., Sebastian, T., 2000). Watanabe et al used eigenspaces from multi-input image sequences for recognizing gesture. Single eigenspaces are used for different poses and only two directions are considered in their method (Watanabe, T. & Yachida, M., 1998). Chao proposed a hand gesture recognition for human-machine interface of robot teleoperation using edge features matching (Chao, H., 2003). Rigoll et al. used HMM-based approach for real-time gesture recognition. In that work features are extracted from the differences between two consecutive images and considered that the target image is always in the center of the input images (Rigoll, G., Kosmala, A. & Eickeler, S., 1997). But practically it is difficult to maintain such condition. Utsumi et al. detected predefined hand pose using hand shape model and tracked hand or face using extracted color and motion. Multiple cameras are used for data acquisition to reduce occlusion problem in their system. But in this process there incurs complexity in computations (Utsumi, A., Tetsutani, N. & Seiji I., 2002). In our previous work (Bhuiyan, M.A., Ampornaramveth, V., Muto, S., & Ueno, H. 2004), we detected and tracked face and eye for human robot interaction. However, all of the above papers did not consider knowledge-based approach to interpret facial pose for person- specific human-robot interaction.
This paper explores a face pose estimation system for person-specific human-robot interaction (HRI) through a knowledge-based approach. Fig. 1 shows an overall architecture of the system. The image analysis and recognition system integrates the detection of human faces in complex backgrounds and recognition of the face pose using PCA. The system is commenced with the extraction of largest connected skin like region from the input images by skin color segmentation. Segmented blocks are then normalized and passed through the PCA based face recognition system. During face recognition, class and sub-class hierarchies are used to support small rotation and orientation variations. Here subspace means separate eigenspaces for different facial images. Changes in illumination usually causes large change in the appearance of a face. In this paper, we propose a novel method for face recognition under arbitrary illumination by using rms scaling and histogram equalization representation. Attempts were taken to address image variation produced by changing in illumination and pose. The pose classification is achieved by employing a multilayer perceptron with backpropagation algorithm. If the segmented block matches with the predefined pose at a particular image frame then corresponding pose command is issued. Pose commands are being transferred to the robot through TCP/IP protocol. Based on the frame-based knowledge representation approach the pose based person-specific human-robot interaction is modeled. The knowledge based protocol organizes the overall system knowledge for decisions making and coordinates the operations of other components using frame-based approach. Based on the information in the connected agents (like face and pose classification outputs), it processes the facts and activates the corresponding frame and carries out the user's predefined actions. Pose commands and robot actions are interpreted in voice so that the human can hear which pose he/she made and which action is being accomplished by the robot. As an application of this method, the system has been implemented in real time mode using the Sony entertainment robot AIBO: such as to recognize human, greeting and mimic with human by poses, greeting, singing, dancing, and so on. Experimental results suggest that the proposed approach provides a faster representation and achieves lower error rates in face recognition.
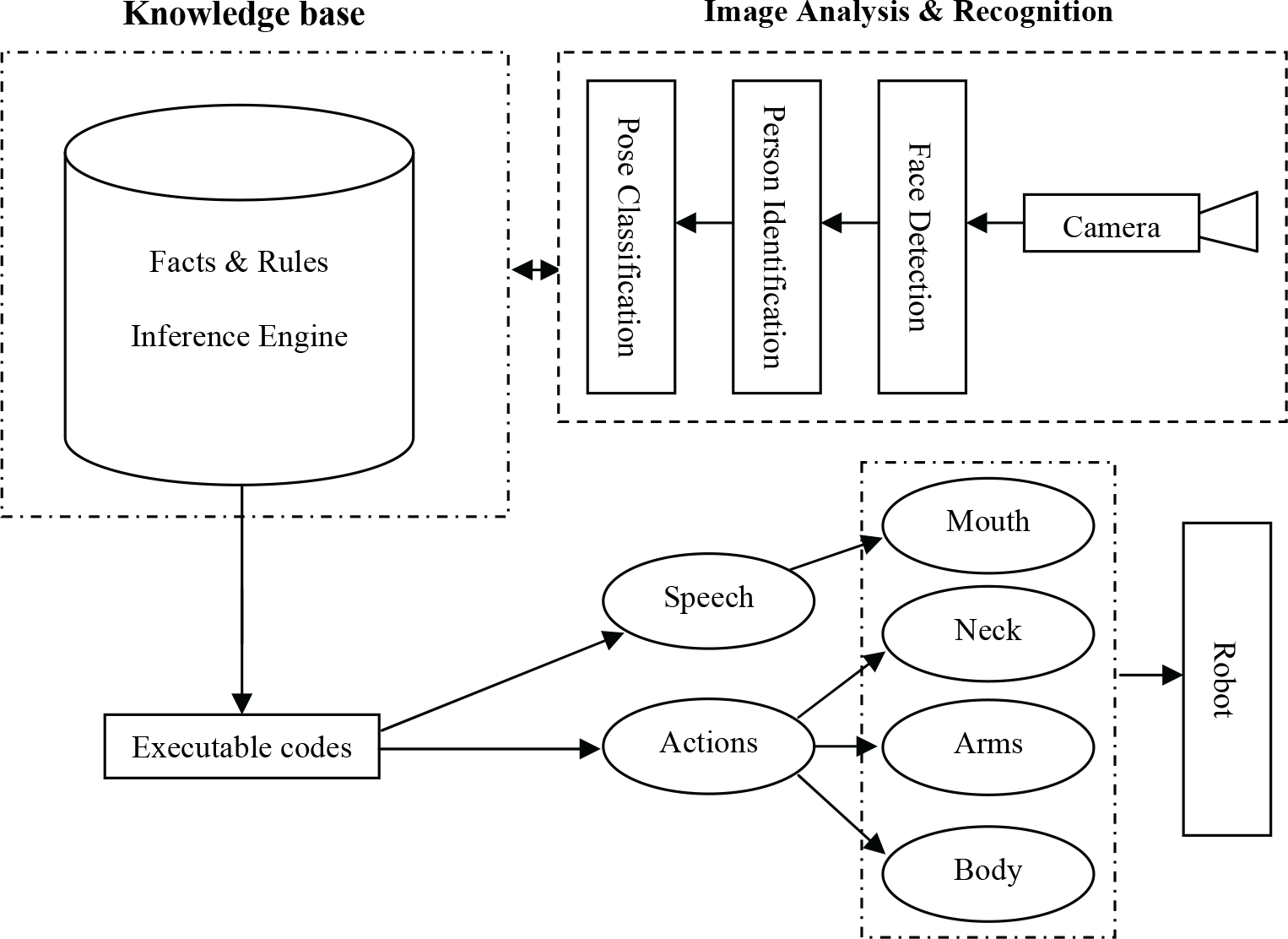
Overall architecture of the face gesture based human-robot symbiosis system
The remainder of this paper is organized as follows. In Section 2, the idea of the proposed method and its feature extraction phase are described. Skin color segmentation and Face detection are described in Section 3. Section 4 describes subspace PCA techniques for face recognition. Section 5 describes the pose classification phase. Section 6 describes the knowledge base interface. In Section 7, experimental results are presented for the image database to demonstrate the effectiveness and robustness of the method. Finally, overall conclusions are presented in Section 8.
2. System Description & Feature Extraction
The face pose recognition and robot interaction system includes three phases: (i) the feature extraction phase (for face detection), (ii) face recognition phase (for person identification), and (ii) pose classification and robot control phase (for human-robot interface), as shown in Fig. 2. The feature extraction phase is commenced with an image processing technique, which involves an algorithm to detect and isolate the facial area in an image. For this, video color images are converted from RGB to HSV color model. After applying the skin color segmentation process, binary image is obtained from which largest connected component is being analyzed for face detection. On finding the facial area, the image is used for PCA analysis with those of the gray scale images kept into image database. Finally, in the classification stage, a 3-layer perceptron is used with backpropagation algorithm to classify different poses occurring in the image sequences. This network identifies the specific pose for different persons and issues commands to the robot for specific actions.

Face recognition and robot interaction
A. Feature extraction phase
The feature extraction phase includes image normalization, illumination and contrast equalization, histogram equalization, filtering, and skin color segmentation.
A.1. Image Normalization
Images of faces are resized to 60×60, by default uses nearest neighbor interpolation to determine the values of pixels in the output image but other interpolation methods can be specified. This research uses a lowpass filter before interpolation to reduce aliasing.
A.2. Illumination and contrast Equalization
Contrast is a measure of the human visual system sensitivity. Although the role of contrast is significant in visual processing of computer displays, in almost all of the past literature address the face recognition process in different lighting conditions with different illumination and contrast. To achieve an efficient and psychologically-meaningful representation, experiments were conducted in two phase: (i) all images with same illumination and rms contrast and (ii) images with different illumination.
The rms (root mean square) contrast metric, which is equivalent to the standard deviation of luminance, is given by (Peli, E., 1990):

where x
i
is a normalized gray-level value such that 0 < x
i
< 1 and x̄ is the mean normalized gray level:

with this definition, images of different human faces have the same contrast if their rms contrast is equal. The rms contrast does not depend on spatial frequency contrast of the image or the sptial distribution of contrast in the image. All images are maintained with the same luminance and same rms contrast using the following equation:

where α is the contrast and β is the brightness to be increased or decreased from the original image f to the new image g. The illumination and rms contrast equalization process is illustrated in Fig. 3.

Illumination and rms contrast equalization
A.3. Histogram Equalization
The face images may be of poor contrast because of the limitations of the lighting conditions. So histogram equalization is used to compensate for the lighting conditions and improve the contrast of the image.
A.4. Filtering
Images are sometimes corrupted by various sources of noise. The fine details of the image represent high frequencies, which mix up with those of noise. When low-pass filtering is used, some details in the image may be erased as well. In this experiment, Prewitt filtering is used to suppress the noise.
3. Skin Color Segmentation & Face Detection
Skin color segmentation is based on visual information of the human skin colors from the image sequences. This research uses HSV color space for skin color segmentation. The reason behind this choice is two folds: (i) Since the hue components of the HSV color space agrees better with human chromatic perception, the hue value has been employed to describe the colors of images, (ii) Application of the hue components, instead of all the R,G,B colors, obviously reduces a large amount of computational cost. Therefore, the dominant and perceptually relevant skin colors extracted in RGB space from images, are converted into the HSV space. Images are being searched in HSV space depending on the amount of color content of these dominant colors, that is, whether the skin color value is substantially present in an image or not.
In the HSV color model a color is described by three attributes hue, saturation and value. Hue is the attribute of visual sensation that corresponds to color perception associated with the dominant colors, saturation implies the relative purity of the color content and value measures the brightness of a color. The HSV space classifies similar colors under similar hue orientations. The conversion from RGB to HSV is given by the equations (Androutsos, D., Plataniotis K.N. & Venetsanopoulos, A.N., 1999):

ranging [0,2π], where H = H1 if B ≤ G; otherwise H = 360° − H1;

where R,G,B are the red, green, and blue component values which exist in the range [0,255].
Let a color image

where n indicates the number of pixels with a hue value H(C R ,C G ,C B ) = i and M × N is the total number of image locations. A typical face image and the construction of its hue histogram is illustrated in Fig. 4. The overview of this color histogram based face detection process is shown in Fig. 5.
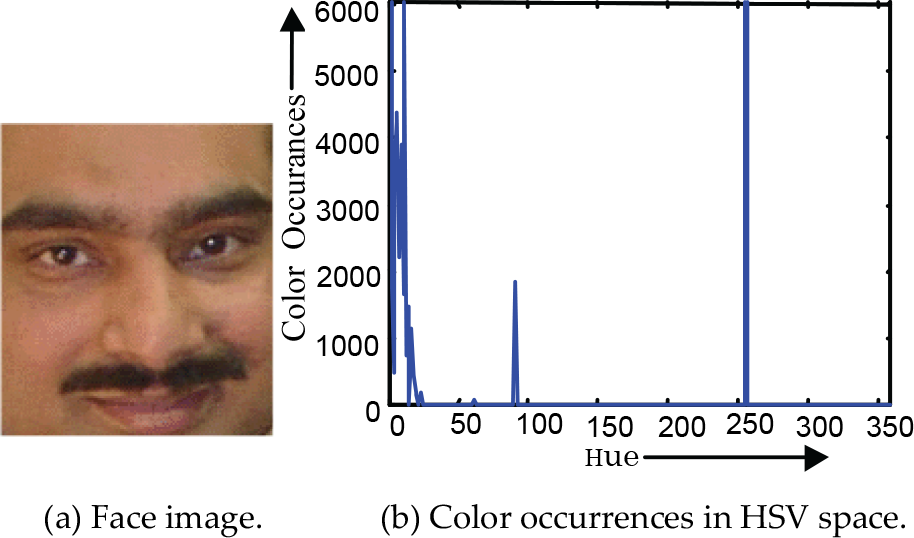
Hue histogram of a face image

Block diagram of the face detection method
Eqn. (4), within a certain threshold, determines whether a facial part exist in an image or not. Since the skin-colors are clustered in color space and differ from person to person and of different races, the threshold value is determined from the hue histogram of the respective image. In this experiment, the hue components have been chosen as: 0° < h face < 40° for the segmentation of skin-like regions. The detection of face region boundaries by such a hue segmentation process is shown in Fig. 6.

Largest area estimation using hue segmentation. (a) A face image (b) Skin color segmentation (c) Largest connected area (d) Cropped Image
The exact location of the face is then determined from the image for pixels with largest connected region of skin-colored pixels. The connected components are being determined by applying a region-growing algorithm at a coarse resolution of the segmented image. In this experiment, 8-pixel neighborhood connectivity is employed. In order to remove the false regions from the isolated blocks, smaller connected regions are assigned by the values of the background pixels. After thresholding the image may be encountered by some holes in the face skin region. In order to remove the false regions, the face region is subjected to morphological dilation operation with a 3×3 structuring element several times followed by the same number of erosion operations using the same structuring element. The dilation operation is used to fill the holes and the erosion operations are performed on the dilation results to restore the shape of the face. If the person puts on a dress with color that is similar to skin color then segmentation output quality is very poor. Even if the person wears T-shirt then it needs to separate hand from face. This system, therefore, considers that the person would wear full shirt with non-skin color and the background would not be any skin color.
Once the face is found in an image (assuming the largest connected area), it then justified by using ellipse-fitting (Bhuiyan, M.A., Ampornaramveth, V., Muto, S. & Ueno H., 2000). The gravity center of the face is then computed as follows.
If the gray level at each point (x, y) of the face area F of an image is considered as the “mass” of (x, y), we can define the center of gravity of that component, as well as the moment of inertia about specified points or lines. The pq-th moment of area F about the origin (0,0) is given by:

where (x, y) are the coordinates of the pixel included in area E. The 0-th moment m00 represents the area F and the center of gravity of F is the point (x̄, ȳ) whose coordinates are given by:
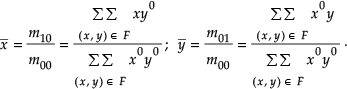
On finding the gravity center of the largest connected area, the camera is zoom-up in such a way that centering on that gravity center, a rectangular area of size 60×60 is cropped. Normalization is performed to scale the image to match with the size of the training image. The precise face position, represented by the top left and bottom right points, [x1, y1], [x2, y2], is localized from the image as follows.
The face area is bounded by a rectangular box using height and width information of the segment (M1 × N1) and is scaled to be square image with 50 × 50). Suppose, if there is a segment of rectangle P[(x
l
, y
l
) − (x
h
, y
h
)], we sample it to rectangle Q[(0,0) − (50,50)] using following expression (Hasanuzzaman, M., Zhang, T., Ampornaramveth, V., Bhuiyan, M.A., Shirai, Y. & Ueno, H., 2004a),
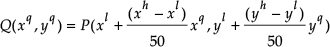
These images are converted as gray images and used as training or test images. The output of the normalization algorithm looks like the training image as shown in Fig. 6(d). This gray scale image is used for recognizing in PCA analysis with those of the gray scale images kept into image database (the selected skin-like regions are normalized as training images size in order to match with them). Later, the face poses are recognized according to the matching results of the images at particular frame.
4. Face Recognition using Subspace PCA
The Principal Component Analysis (PCA) based approach has been used to recognize gesture from an unknown input image. To achieve better accuracy, this system uses subspace method or separate eigenspaces for different poses classification instead of normal PCA (Moghaddam, B. & Pentland, A. (1997). This subspace method (Hasanuzzaman, M., Zhang, T., Ampornaramveth, V., Bhuiyan, M.A., Shirai, Y. & Ueno, H., 2004a) offers an economical representation and very fast classification for vectors with a high number of components as only the statistically most relevant features of a class are retained in the subspace representation. The main idea of subspace method is similar to PCA that is to find the vectors that best account for the distribution of target images within the entire image space. In the traditional PCA eigenvectors are calculated from training images that include all the poses or classes whereas in the subspace method training images are grouped for different poses separately and the test image is projected on each subspace separately. This approach of face pose recognition includes the following operations:
Generate a set of face poses corresponding to training images T i j (M × M), where i=1,2 …., N is the number of training images of j-th class.
Compute eigenvectors u n j for each group (Pentland, A. 2000) and choose k number of eigenvectors (u k j ) corresponding to the highest eigen values to form PCA. These vectors represent the subspace of that pose group images.
Compute corresponding distribution in k-dimensional weight space for the known subclass images by projecting them onto the subspaces of the corresponding group and determine weight vectors (Ω
c
j
):

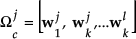
where average image of j-th class
Treat segmented region as individual input image and transform each into eigen-image component and calculate a set of weight vectors (Ω j ) by projecting the input image onto each of the eigen images as Eqns. (10) and (11).
Determine if the pose of the image based on the minimum Euclidean distance among weight vectors,


If min(ε i ) is lower than predefined threshold and closer to any sub class, then the corresponding subclass is identified.
If any segment is face then classify the pattern whether it is known or unknown person.
For exact matching ε c should be zero but for practical purposes we have used a threshold value through experiment, considering optimal separation among the sub classes. In this experiment, the PCA output has been combined for segmented images of a particular frame to recognize pose (Hasanuzzaman, M., Zhang, T., Ampornaramveth, V., Bhuiyan, M.A., Shirai, Y. & Ueno, H., 2004b). Face poses are being classified depending on five orientations the face, such as: (i) left-sided face (90°), (ii) left-sided face (45°), (iii) frontal face, (iv) right-sided face (45°), (v) right sided face (90°). Similarly considering for top aligned face and bottom aligned face with these five orientations, a total of 15 poses are defined as P i ,(i = [1,15]). Pose commands are then generated to interact with robot using TCP/IP protocol.
5. Pose Classification Phase
The pose classification phase includes neural network training for the recognition of pose patterns of the face image. This system is based on supervised learning in which the learning rule is provided with the set of example face patterns (the training set). The multi-layer perceptron, as shown in Fig. 7, with backpropagation algorithm (Negnevitsky, M. 2002) has been employed for this purpose. The number of nodes in the input layer is equal to the dimension of the feature vector and the number of nodes in the output layer equals the number of poses the neural network is required to recognize. The network recognizes a feature vector as belonging to class m if the output of the m-th node is greater than that of the other nodes in the output layer.

Network architecture of BPNN
During training, the weight and biases of the network are iteratively adjusted to minimize the network performance. The default performance function, for back propagation neural networks, is the mean square error (MSE), which is defined as the average squared error between the networks outputs and target outputs. The number of epochs for this experiment was 10,000 and the error margin was 0.01. The back-propagation training algorithm is illustrated in a flowchart as shown in Fig. 8.

Flow chart for training BPNN
6. Knowledge-Based Interface
The system first detects human face using skin color segmentation and then face poses are classified depending on the knowledge stored in the knowledgebase. On face pose classification, the static poses are recognized using frame-based approach. Known poses are defined as frames in the knowledge base. When the required combination of the pose components are found the corresponding pose frames are activated. Dynamic poses are recognized by considering the transitions of the face poses in a sequence of time steps. After the pose is recognized, the interaction between human and robot is determined by the knowledge modeled as frame hierarchy in the knowledgebase management system SPAK. SPAK works as a knowledge and data management system, communication channel, intelligent scheduler, and so on.
6.1 Knowledge Model for Pose-based HRI
Knowledge is the perception about and understanding of a subject or a domain. This research approaches knowledge representation using frame-based approach. A frame is a data-structure for representing a stereotype situation (Minisky, M. 1974). Attached to each frame there are several kinds of information about a particular object or concept it describes, such as frame name, a set of attributes called slots with values (optionally filled with default values). Using frames and their slots a knowledge base for gesture-based human-robot interaction can be developed. Fig. 9 illustrates the frame hierarchy of this knowledge model organized by IS-A relation. The IS-A relation implies that there is a class and sub-class relation between the upper frame and the lower frame. The class frames are created for user, robot, behavior (robot action), gesture and pose. The User frame includes child (instance) frames of known users (instance frames “Alan”, “Tanvir”, “Rina”, …), pose frame includes all the predefined poses (instance frames “Top Aligned Left-sided Face 45”, “Normal Aligned Right-sided Face 90”, “Bottom Aligned Right-sided Face 45”, …) as child frames, robot frame includes the robot (instance frame “Aibo”) that are used by the users, and the behavior frame includes all the robot actions (instance frames “Walk”, “TurnLeft”, “TurnRight”, “Dance”, …) as child frames.
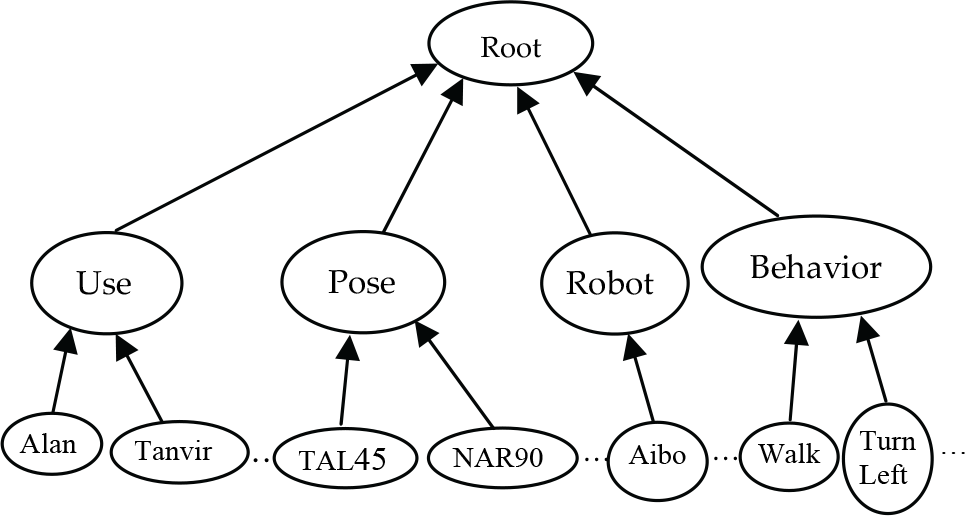
Frame hierarchy for pose based human-robot interaction
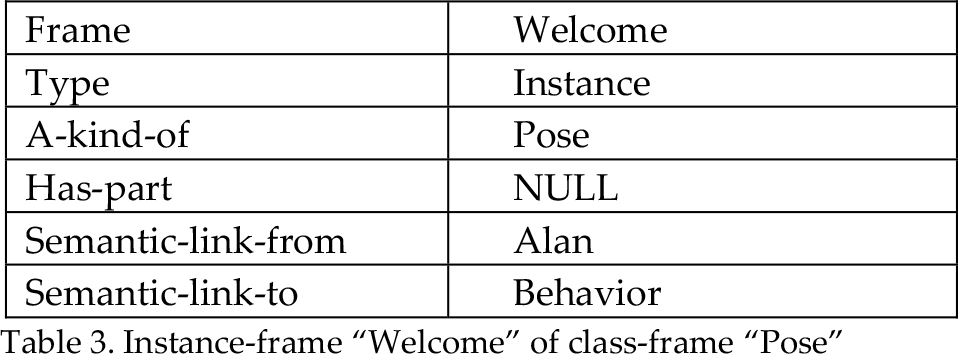
Table 1 illustrates the instance frame “Alan” of the class frame “User” and he has semantic link from the robot Aibo and to Behavior “Welcome”. In this frame-based model, several robots can be used and according to user selection the corresponding robot will be activated. Table 2 shows an example instance frame “Aibo” of the class frame “Robot” and that one is semantically linked to the user “Alan”. Table 3 shows the example components of an instance frame “Welcome” of the class frame “Pose”. This frame has three slots for the gesture components. If Normal Aligned Right-sided Face 90 is found in the particular image frame then Pose frame “Welcome” will be activated. Similarly, the new users, new poses, and new robot actions can be added by activating the corresponding frames in the knowledge base using the SPAK knowledge Editor.
Instance frame “Alan” of class frame “User”

Instance frame “Aibo” of class frame “Robot”

Instance-frame “Welcome” of class-frame “Pose”
6.2 Human-Robot Interface using SPAK
SPAK has occupied a platform on which various software components for different robotic tasks are integrated over a networked environment. It co-ordinates the operation of these components by means of a frame-based knowledge modeling (Ampornaramveth, V., Kiatisevi, P., Ueno, H. (2004), (Hasanuzzaman, M., Zhang, T., Ampornaramveth, V., Bhuiyan, M.A., Shirai, Y. & Ueno, H. 2004b). This research combines vision and knowledge-based approaches for human-robot interaction so that user can define or edit robot behavior according to his/her desire. User can also define or edit the rules for pose recognition/interpretation in the knowledge database, which also contains information regarding user (profile) to improve reliability and robustness of image classification. Using information received from different agents, and based on the predefined frame knowledge hierarchy, the SPAK inference engine determines the actions to be taken and submit corresponding commands to the target robot control agents. The SPAK consists of a frame-based knowledge management system and a set of extensible autonomous software agents representing objects inside the environment and supporting human-robot interaction and collaborative operation with distributed working environment. SPAK consists of the following major components: GUI interface, Knowledge Base (KB), Network Gateway and Inference engine. SPAK allows TCP/IP based communication with other software components in the network and provides knowledge access and manipulation via TCP socket. Frame-based knowledge is entered into the SPAK with full slot information: attributes, conditions and actions. Based on information from remote software components (e.g. pose classification, face recognition, etc.), SPAK inference engine processes facts, instantiate frame instances and carries out the users predefined actions, as shown in Fig. 10 and Fig. 11.

SPAK knowledge Editor

Sample frame ‘face’ in SPAK knowledge Editor
7. Experimental Results & Performance
The performance and effectiveness of the face recognition method has been justified using different video images with various kinds of poses and issuing commands to the entertainment robot named “AIBO”. Experiments were carried out on a Pentium IV 1.2 GHz PC with 512 MB RAM. The system used 3CCD video camera and computer vision techniques. Each capture image was digitized to a matrix of 320×240 pixels with 24-bit color. The algorithm has been implemented using Visual C++. Face images were first analyzed to demonstrate the feasibility of the proposed method. When a complex image is subjected into the input, the face detection result highlights the facial part of the image. The system can also cope with the problem of faces wearing sunglasses. Images of different persons were taken at their own work places and at different environments both in sunny and cloudy weather conditions. Most of the images were taken using a digital camera, but some are from scanner, and some from video tapes recorded from different television channels. The algorithm is capable of detecting single face in an image. For multiple faces, that is, the image containing more segments of skin colored pixels, the system finds the dominant face only. It is possible to detect and exhibit more faces using genetic algorithm. Detection results for some of the images in different backgrounds, lighting conditions, expressions, including multiple faces, are shown in Fig. 12. A total of 410 images, including more than 80 different persons, were used to investigate the capacity of the proposed algorithm. Among them only 6 faces were found false. Experimental results demonstrate that the success rate of approximately 98.5% is achieved. The main reason behind the failure of those images in finding face regions is the substantially presence of pink, reddish or yellowish background regions in the image which are much larger than the true skin regions.

Face detection for the persons at their work places: left side images are original images, middle side images are color segmentation result and right side images are probable face locations
Face recognition was achieved using subspace PCA. Different eigenfaces of a typical user with different poses is shown in Fig. 13. Distribution of the feature vectors for different images are shown in Fig. 14. The negative values represent the magnitude of the features less than the reference values of the corresponding poses.

Eight eigenfaces for a typical user
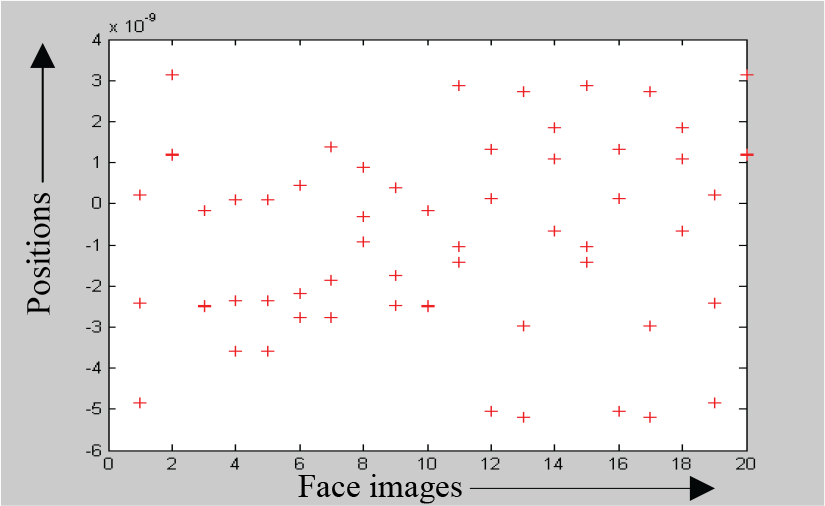
Distribution of the feature vectors of a typical user
For pose recognition, the training images were prepared first. All the training images were 50×50 grayscale images. For training, there were 100 images of face with a little bit rotation with different orientation for 15 different poses. The system was carried out for real time input images. In the case of no match, the system outputs “no matching found” message.
The Euclidean distance measure was used for different classes to select optimal threshold for issuing commands to the robots. The performance of the facial pose recognition system was evaluated by testing its ability to correctly classify different poses to their corresponding classes for both training and testing set of data. The data set used for training and testing the recognition system consists of the images for all of the poses used in the experiment. Ten samples for each pose were taken from 20 different volunteers. For each pose, 5 out of 10 samples were used for training purpose, while the remaining 5 poses were used for testing. The samples were taken from different distances by digital camera, and with different orientations. In this way, we were able to obtain a data set with cases that had different sizes and orientations, so we could examine the capabilities of the feature extraction scheme.
The recognition rate is defined as the ratio of the number of correctly classified samples to that of the total number of samples. Precision is defined as the degree of similarity among independent measurements of the same pose, without reference to the known value and is expressed as the inverse of the standard deviation. The precision and recognition rates of both subspace method and the PCA method have been analysed and the comparison results are shown graphically in Fig. 15 and Fig. 16, respectively. Performances for the poses at −90° and +90° look significantly different from others due to partial information processing at those poses.

Comparison between subpace and PCA in terms of precision

Comparison between subpace and PCA in terms of recognition rate
The training curve showing the gradual reduction in error as weights are modified over several epochs for backpropagation learning algorithm is shown in Fig. 17. The system has been implemented by gesture recognition program running in server PC. The PC has been considered as the server and the robot AIBO as a client. The communication link has been established through TCP/IP protocol. The human-robot interaction results with respect to different pose commands are described in Table 4.
Commands to control AIBO


Error versus iteration for training the BPNN
Dynamic gestures are recognized from the specific motion pattern or pose sequences in time steps and are defined using state transition diagram. This system recognizes two dynamic facial gestures considering the transition of the face poses in a sequence of time steps. If the human face shakes left to right or right to left, then it is recognized as “NO” gesture. If the human face shakes up and down or down and up, then it is recognized as “YES” gesture. This method uses a 3-layers queue (FIFO) that holds the last three results of the detected face poses. This method defines five specific face poses: frontal face (FF), right-rotated face (RF), left-rotated face (LF), up position face (UF) and down position face (DF). For every image frame, face pose is classified using subspace method. If pose is classified as predefined face pose then it is added to the 3-layer queue. If the classified pose value is same as previous frames then queue values will remain unchanged. From the combination of 3-layers queue values this method determine the gesture (Hasanuzzaman, M., Zhang, T., Ampornaramveth, V., Bhuiyan, M.A., Shirai, Y. & Ueno, H., 2004b). For example if the queues values are {DF, FF, UF} or {UF, FF, DF} pose sets then it is recognized as “YES” gesture. Similarly, if the queues values are {RF, NF, LF} or {LF, NF, RF} pose sets then it is recognized as “NO” gesture. If gesture is recognized then corresponding gesture frame will be activated. Fig. 18 shows example face sequences for dynamic gestures “YES” and “NO” and Fig. 19 shows the ‘move forward’ action of a robot as a consequence of the instruction ‘Top aligned normal face’.

Example of dynamic gesture sequences

Program interface for robot control
8. Conclusions
Face detection and facial pose recognition using machine vision techniques has many useful applications. Although human beings accomplish these tasks countless times a day, they are still very challenging for machine vision. Most of the researchers attack this kind of problem with face localization and feature selection with frontal view faces and without facial expression and normal lighting conditions although the variation between the images of the same face is too large due to facial expression, hair style, pose variation, lighting conditions, make-up, etc. In this paper, face detection has been implemented using skin color analysis. The effectiveness of the face detection algorithm has been tested both in simple and complex backgrounds for different types of face and non-face images of 320×240 resolution. The algorithm is capable of detecting the faces in the images with different backgrounds and lighting conditions. Our next approach is to extend the algorithm for overlapping faces in images and detect facial expressions and develop a gaze estimation algorithm that will be able to detect an eye in a face image and estimate the gaze direction. Our main target is to instruct operations to robots and make them understand the human's intentions and interests over facial expressions so that they would be capable of grasping with more intelligence while working cooperatively with human beings.
This research presents the development of a system for the recognition of face pose. A real time robot interaction system has been implemented. The work was accomplished by training a set of input data (feature vectors) corresponding to each face image pattern. Without the need of any gloves, images for different poses were captured by digital camera. The proposed system was able to reach a recognition rate of about 93.0% for training data and about 84% for testing data for static gestures. Dynamic poses are included in this system by tracing the transition of face poses with the classification of static poses. As an application of this system, the real-time human robot interaction system has been implemented using an entertainment robot AIBO.
The work presented in this research deals with static and dynamic poses. The system deals with images that have almost non-skin color background. Getting rid of this limitation will make the system more flexible and suitable for real life applications, as there is no control on the environment (i.e. background). Our next target is to make the system suitable for training the network to other types of images such as facial expression, eye tracking, head gesture and so on and make it applicable in real-time environment. Our main target is to establish a symbiotic society so that the robots can exchange their ideas and thoughts with human beings for the benefit of each other.
Footnotes
9. Acknowledgments
This research is supported by Economic & Social Research Council RES-000-22-1759.