
Abstract
With the rapid development of computers and the increasing, mass use of high-tech mobile devices, vision-based face recognition has advanced significantly. However, it is hard to conclude that the performance of computers surpasses that of humans, as humans have generally exhibited better performance in challenging situations involving occlusion or variations. Motivated by the recognition method of humans who utilize both holistic and local features, we present a computationally efficient hybrid face recognition method that employs dual-stage holistic and local feature-based recognition algorithms. In the first coarse recognition stage, the proposed algorithm utilizes Principal Component Analysis (PCA) to identify a test image. The recognition ends at this stage if the confidence level of the result turns out to be reliable. Otherwise, the algorithm uses this result for filtering out top candidate images with a high degree of similarity, and passes them to the next fine recognition stage where Gabor filters are employed. As is well known, recognizing a face image with Gabor filters is a computationally heavy task. The contribution of our work is in proposing a flexible dual-stage algorithm that enables fast, hybrid face recognition. Experimental tests were performed with the Extended Yale Face Database B to verify the effectiveness and validity of the research, and we obtained better recognition results under illumination variations not only in terms of computation time but also in terms of the recognition rate in comparison to PCA- and Gabor wavelet-based recognition algorithms.
Introduction
Face recognition has received significant attention due to its wide range of applications. The application of face recognition have been expanded recently, not only to the public sector, such as security, surveillance and access control for offices, but also to personal devices such as digital cameras, service robots, smartphones and laptops. Numerous studies on face recognition have been reported, but the recognition performance of practical face recognition systems is largely influenced by variations in illumination conditions, viewing direction or poses, facial expression, aging and disguises [1, 2]. It is still regarded as a challenging task because of unresolved issues caused by these issues.
The existing face recognition algorithms are generally classified into three categories according to the type of features used:
Holistic methods: These methods represent the whole facial region as a high-dimensional vector that is used as an input to a classifier. Local methods: These methods extract local features from facial regions, such as the eyes, nose, mouth and cheeks, and then use these features to classify a face. Hybrid methods: In these methods, both the holistic and local features are used to recognize a face. Zhao et al. [1] have claimed that “…one can argue that these methods could potentially offer the better of the two types of methods.”
Face recognition based on the Eigenspace algorithm [3–6] - one of the holistic methods - was introduced in 1991 and achieved more noticeable recognition performance than other available algorithms at the time. As a result, holistic methods have received much attention and have been researched actively up to the present day. First and foremost, the characteristic aspect of the facial representation used in these holistic methods is that it contains overall information for a face, since the entire facial region is represented as a high-dimensional vector. This naturally leads to the fact that it holds the global characteristics of a face, such as the shape of the face and relationships among the facial components [7]. Principal Component Analysis (PCA), Linear Discriminant Analysis (LDA), and Independent Component Analysis (ICA) are well-known, popular and successful holistic methods. PCA is an effective feature extraction method in pattern recognition. It utilizes a set of the most expressive feature vectors, which maximizes the variances of the features [2, 4]. LDA uses the class information of features and finds a set of the most discriminating feature vectors that minimizes within-class scatter while maximizing between-class scatter [8]. ICA finds statistically-independent basis vectors and minimizes both second-order and higher-order dependencies in the input images [9].
Before holistic algorithms were developed in 1990s, local methods had been actively studied, employing features extracted from local facial regions [10, 11]. Recently, local methods came into focus again, partly due to their robustness against occlusion and variations in facial expressions. Local methods have two advantages compared to holistic methods [12, 13]. First, a face can be represented as a set of feature vectors extracted from local regions, resulting in lower-dimensional vectors. Thus, the “curse of dimensionality” problem could be alleviated. Second, local features might be useful when some part of the face is occluded. Bruneli and Possio [14] compared two classes of local methods - geometrical feature-based methods and template-based methods - in which the result showed that the template-based approach saw better performance. Ahonen et al. [15] applied a texture descriptor, called a ‘Local Binary Pattern’ (LBP), for face recognition. An LBP operator is applied to the face image, and then the output is partitioned into sub-regions. Histograms of the sub-regions are utilized for face recognition.
Among various local feature representations, Gabor wavelets have been recognized as one of the most successful local feature extraction methods due to their robustness against distortions caused by variations in illumination, scale, translation and rotation [16, 17]. Many approaches based on Gabor wavelets have been proposed for face recognition, such as Dynamic Link Architecture (DLA) [18], Elastic Bunch Graph Matching (EBGM) [19], Gabor-Fisher Classifier (GFC) [20], Fusion of Multiresolution Gabor Features [21], and Local Gabor Binary Pattern Histogram Sequence (LGBPHS) [22]. DLA and EGBM are face representation methods using elastic graph matching. DLA represents a face using a rectangular graph with local features extracted at deformable nodes using Gabor wavelets. Wiskott et al. [19] have expanded DLA to EGBM, employing an object-adapted graph and node, which refer to a specific facial landmark. Liu et al. [20] applied the enhanced Fisher linear discriminant model (EFM) to the Gabor feature vector for face recognition and showed that its result outperformed both PCA and LDA. Xu et al. [21] proposed a matching-score level with two fusion methods which obtains good performance on Gabor Features. LGBPHS describes a face by combining the LBP operator and the Gabor wavelet transforms.
With the hybrid methods, both holistic and local features are used to enhance the recognition performance by preserving their strengths and averting any weaknesses. Pentland et al. [23] applied the concept of eigenfaces to some facial components, such as the eyes, nose and mouth, which correspondingly produces ‘eigeneyes’, an ‘eigennose' and an ‘eigenmouth’. The work of Lanitis et al. [24] presents a flexible appearance model-based face recognition method which uses statistical shape information, an Active Shape Model (ASM) and grey-level information; both are constructed using PCA.
Both holistic and local features have their own merits in face recognition. Holistic features contain a statistical summary of the spatial layout properties, giving the global contours and textures of the image. On the other hand, local features may provide detailed regional properties. According to a psychological study of the brain's cognitive mechanisms underlying human scene recognition researched by Oliva and Torralba [25], both features are used in the human perception process, but they play different roles. The global precedent hypothesis [26] claims that holistic features are processed before analysing local features in human perception mechanisms. Holistic features contain a statistical summary of the spatial layout properties of a face, giving the coarse and global contours and textures of it. On the other hand, local features are known to provide a detailed local description.
In a previous study, we experimentally showed that the ground truth image - corresponding to a test image -tends to exist in the upper part when sorted by similarities [27]. In this paper, we propose a hybrid face recognition algorithm in which PCA is used in the first stage and LGBPHS - one of local methods - is used in the second stage.
The rest of this paper is organized as follows: related works concerning LGBPHS are described in the next section. In Section 3, the suggested hybrid method is described, along with the principles of its modules. Section 4 presents experimental results to verify the efficiency and advantages of our proposal. Conclusions are provided in the final section.
Local Gabor Binary Pattern Histogram Sequence (LGBPHS)
In this section, we introduce - briefly - the LGBPHS, proposed by Zhang et al. [22], a non-statistical-based face recognition approach which combines Gabor wavelets and LBP in enhancing the representational power of the spatial histogram. Gabor wavelet-based face representation has demonstrated its robustness against variations, such as illumination, scale, translation and rotation. LGBPHS employs Gabor Wavelets and LBPs to convert a face image into a sequence of histograms. An LGBPHS operator consists of the following three steps.
First, an original face image is convolved with Gabor filters to obtain the image, called a ‘Gabor Wavelet Representation’ (GWR) [22]. The GWR is obtained as follows:

where f(·) denotes the image, * denotes the convolution operator, and φ denotes the Gabor filter with a frequency v ∊ {0, …, 4} and orientation μ ∊ {0, …, 7}.
We use 40 Gabor filters with five frequencies and eight orientations, as shown in Eq. (1).
Second, we apply an LBP operator to the magnitude part of the GWR to obtain a Local Gabor Binary Pattern (LGBP) image. The LBP is an operator which moves a 3×3 window in an image to extract the structural features which are known to be robust to the illumination and noise variations [15]. The LBP is defined as below:

where Γ(X) is the bit string representing the structural feature at a point X, ⊗ is a concatenation operation, W is a 3×3 window, Ī(W) is a mean intensity value of pixels in W, p is a pixel in W, I(p) is an intensity value of p, and ζ (Ī(W), I(p)) is a comparison operation that returns 1 if Ī(W) < I(p) and 0 otherwise. A typical example of an LBP operation is shown in Figure 1. The LBP exhibits relatively good performance in face detection and recognition, while its operation is simple [15, 28].

Example of an LBP operation
Third, an LGBP image is partitioned into 15×15 pixel-sized sub-regions, whereby histograms of the sub-regions are obtained afterward. A 15×15 sub-region is selected because it provides an efficient recognition rate after having experimented with various alternative sizes of sub-regions, such as 5×5, 21×20, and 35×40. The reason why we divide the GBP images is that the dimension of the LGBP can be reduced by partitioning the entire face image into small local regions while detailed local information is preserved. Original facial images of 105×120 pixels are used throughout this paper. The number of histograms per image is 2,240, as it is obtained after the multiplication of 40 (the number of Gabor filters) by 56 (the number of sub-regions).
We compare the histograms obtained from the above procedure - LGBPHS - to measure the similarity between two facial images. The similarity between the histograms of a test image and a training image is measured by employing the Bhattacharyya distance shown below:

where H1 and H2 are histograms, N is the total number of histogram bins, and
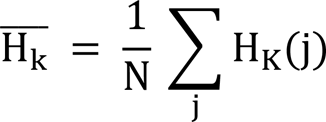
The Bhattacharyya distance becomes 0 when two histograms are exactly the same, and it grows to 1 as the dissimilarity level is increased. Thus, one may select the training image which has the lowest Bhattacharyya distance value as the matching facial image according to the LGBPHS procedure.
We propose a hybrid classifier for face recognition, utilizing the advantages of both holistic and local features. The classifier, called ‘Dual-stage of PCA and LGBPHS’ (DPL), consists of two stages in a serial order. Figure 2 shows the flowchart of the classifier. In the first stage, PCA-based coarse recognition is performed, where the distances between a test image and the training images are used to measure the confidence level [27]. The confidence level measurement is performed as follows. Training images are sorted in ascending order according to their distance values between a test image and the training images. The ith sorted image is called rank i. If the ranks of 1, 2 and 3 belong to the same person or the identity of rank 1 exists three or more times among ranks 2 to 6, then it passes the confidence test. This specific test rule has been obtained from a number of experiments on PCA-based face recognition conducted in our previous work [27].

Flowchart for the proposed DPL algorithm
When the confidence level is reliable enough (i.e., if it passes the confidence test), the recognition procedure is finished at the first stage. Otherwise, the second stage is initiated. In the second stage, the classifier reduces the number of candidate training images by selecting only the upper n training images after sorting them in ascending order according to their distance values between a test image and the training images. The retained n images are used for the second stage using the LGBPHS approach introduced in Section 2. In Section 4, we show the recognition rates with the corresponding computation times when we select the upper six and upper 25 training images. As the number of candidate images increases, we expect a lower probability of false rejection, but a higher computational load is unavoidable. We call the proposed dual-stage algorithm ‘DPL6’ and ‘DPL25’ according to the number of candidate images supplied to the second stage.
In the experiment, we compared the cases of DPL6 and DPL25 to show the trade-off between the number of retained images and computational load. The main advantage of this coarse-to-fine strategy is the computational load reduction; only a small number of training images are retained from the former stage. This strategy is more efficient when the latter stage uses computationally heavy methods, like Gabor filtering.
The coarse-to-fine face recognition strategy has already been studied in other research [29, 30], but the criteria for the selecting the candidate images for the second stage was not clearly specified. We extend our previous work [27] to show the experimental grounds for the criteria. More importantly, the proposed recognition approach has a flexible structure that enables the finishing of the recognition procedure at the first stage using PCA. In experiments, the proposed approach showed higher recognition rates and required less time for computation under illumination variations than the PCA- and Gabor filter-based recognition algorithms.
Face Database
All the experiments in this study were carried out on the database of 2,432 images of 38 individuals from the Extended Yale Face Database B [31, 32]. There are 64 images for each individual. However, since 18 images of the 2,432 were known to be corrupted during the image acquisition step, we actually used 2,414 images for this paper. All the images used in this experiment are frontal faces under varying illumination conditions from the database. The database is divided into five subsets, named ‘Subsets 1 to 5’, according to the ranges of the angles between the light source direction and the camera axis, as shown in Figure 3. Examples images of the database are given in Figure 4. The number of images in each subset is given in Table 1.
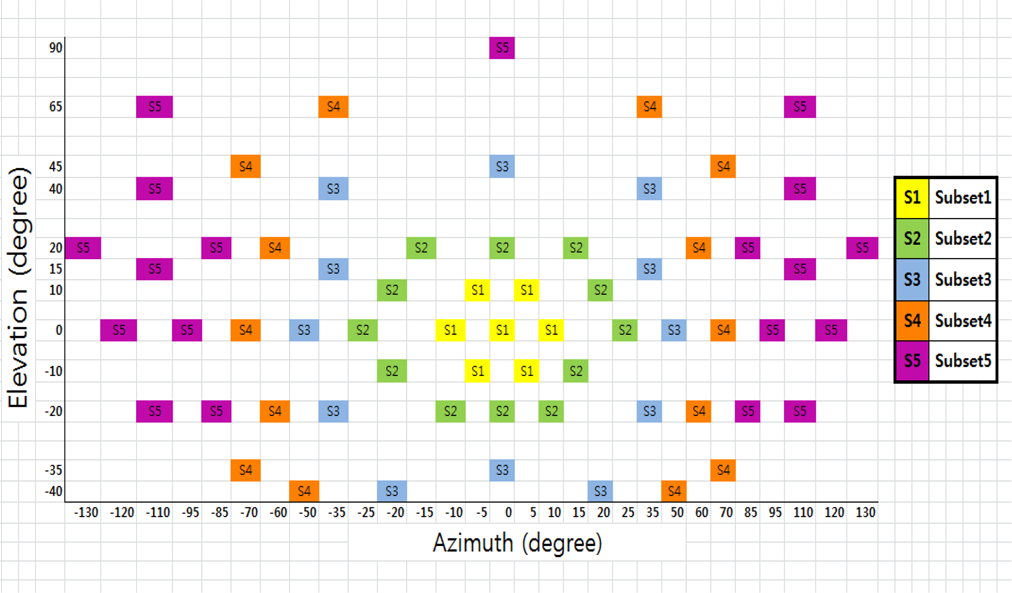
The angles between the light source and the camera axis

Example images of an individual in each subset
Number of images in each subset

Subset 1 is used as a training set, as it is the set where illumination variation effects are negligible. Subsets 2 to 4 are used for testing different illumination conditions. Subset 5 is excluded from the experiment because the illumination conditions are so severe that some images are difficult to recognize even to the naked eye.
All the images in Subsets 1 to 4 are manually aligned, cropped and then resized to 105×120 pixels. We pre-processed the images with a LBP to compensate for the illumination variations.
We performed PCA-based face recognition separately in order to compare with the results from the proposed DPL algorithm. Employing the training set and test image described in 4.1, we obtained the results as shown in Table 2. It shows the cumulative match score at rank 1. As expected, when there is little change in illumination, as in Subsets 2 and 3, the recognition rates at rank 1 are perfect. However, it shows 95% in the case of Subset 4, as the illumination conditions worsen.
Recognition rate of the PCA method

Recognition rate of the PCA method
Figure 5 shows the cumulative match characteristic (CMC for Subset 4. We used the cosine Mahalanobis (COM distance to calculate the distance between the test image and the training images. The COM distance is a unitless measure and descriptive statistic that provides a relative measure of a data point's distance (residual) from a common point. It shows that the cumulative match score is about 0.98 at rank 6. This implies that the probability that the identity of a test image exists among ranks 1 to 6 is 98%. Therefore, the proposed DPL algorithm uses only six of 263 training images when it performs the LGBPHS based second recognition stage to save computation time while allowing 2% error. We also tested with the upper 25 training images in the experiment with a 0.005% error.

CMC of Subset 4
Table 2 shows that the images with greater illumination variations tend to have a lower recognition rate with the PCA algorithm, as expected. Overall, 24 images in Subse 4 failed with this algorithm.
In this section, we will show the results obtained after applying DPL-based face recognition to the identical training and test sets used in Section 4.2. Table 3 shows the number of successful and failed test images employing the second stage of DPL6 and an independent PCA. For Subsets 2 and 3, all images passed to the second stage in the DPL algorithm were also successful with the PCA algorithm. However, for Subset 4, only 148 out of 172 passed images were successful with the PCA algorithm, while 161 images out of 172 passed images were successful in the second stage of the DPL algorithm when we employed the upper six training images.
Number of successful/total test images at the second stage
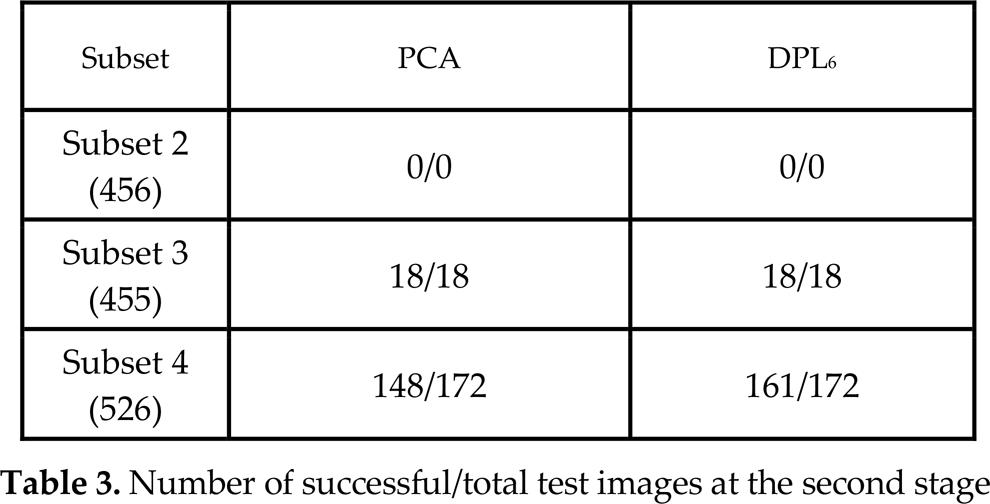
Number of successful/total test images at the second stage
Applying the confidence test given in Section 3, we observe that the failure rate increases as the illumination condition worsens, meaning that Subset 4 has the highest failure rate in the first stage. Among 1,437 test images, the identities of 1,247 images were determined at the first PCA-based stage, while 190 test images (18 from Subset 3 and 172 from Subset 4, as shown in Table 3) are passed to the second stage. Note that all 24 images that failed with the PCA algorithm for Subset 4 were passed to the second stage of the DPL, as shown for Subset 4 in Table 3, proving the effectiveness of the confidence test rule proposed in Section 3.
Table 4 shows the average recognition rate and average computation time of the proposed DPL algorithm compared with those of the PCA- and LGBPHS-based recognition algorithms. Both performances were measured for the 1,437 test images without consideration of their subsets. The experiments were performed on a PC with an Intel Core 2 Duo E7500 and 2GB RAM.
Average recognition rates and average computation times
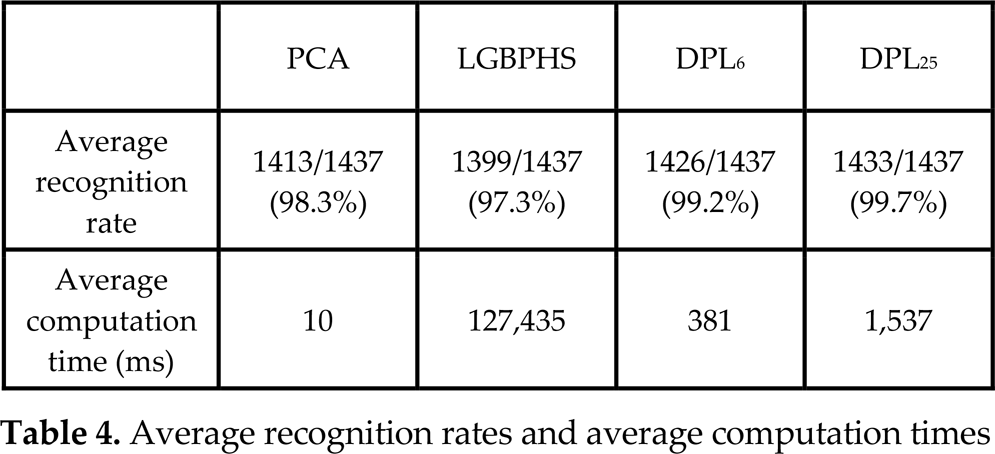
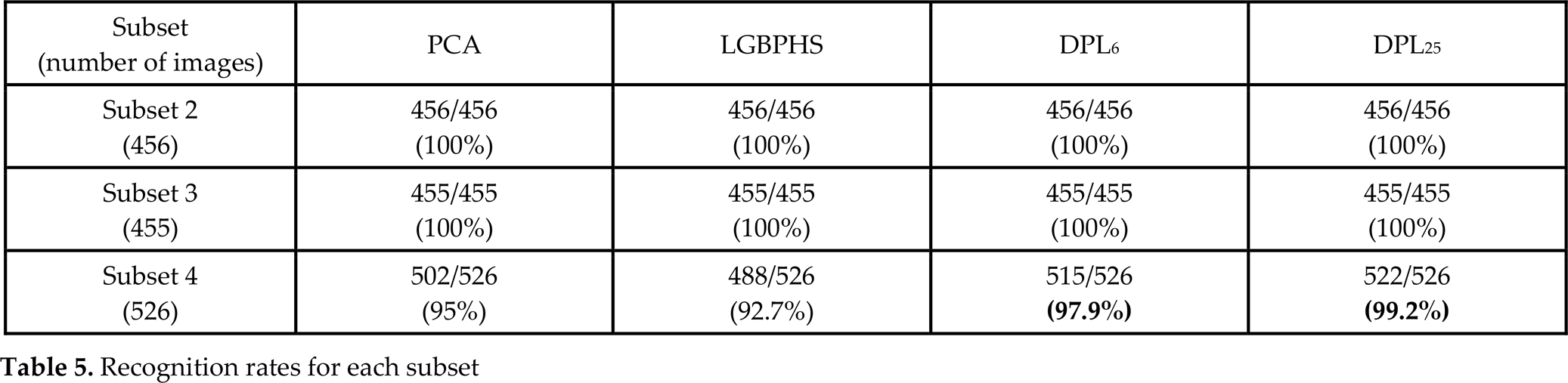
As shown in Table 4, the DPL algorithms give better recognition rates than PCA and LGBPHS. Moreover, the DPL consumes far less computation time than LGBPHS, so it might be used in real-time applications. This is achieved because 263 training images used in LGBPHS had been reduced to six or 25 with the DPL algorithm. Table 5 shows the recognition rate for each subset. For Subsets 2 and 3, the recognition rates for all the algorithms are perfect, as the illumination effect was negligible. However, the recognition rates for Subset 4 with PCA and LGBPHS are only 95% and 92.7%, respectively. These rates have been improved by DPL6 to 97.9% and by DPL25 to 99.2%. As the number of candidate faces is increased, the recognition rate is naturally improved. However, as shown in Table 4, the computation time for the upper 25 cases is increased compared with the upper six cases.
Recognition rates for each subset
This paper presented a hybrid face recognition method that employs dual-stage holistic- and local feature-based algorithms. The proposed DPL algorithm utilizes a PCA algorithm in the first stage and an LGBPHS in the second stage. The confidence test procedure was introduced to decide which test images were passed to the second stage for further classification.
By adopting the confidence test, we reduced the number of test images that were passed on to the more time consuming second stage. The average computation time per image was reduced, as it passed only the upper six or 25 training images when a test image failed the confidence test.
In the experiment, we also proved that the recognition rate has been improved in the proposed algorithm.
Footnotes
6.
This research was supported by the Technology Innovation Programme of the Knowledge Economy (No. 10041834) funded by the Ministry of Trade, Industry and Energy (MOTIE, Korea).