
Abstract
Detecting and tracking people is a key capability for robots that operate in populated environments. In this paper, we used a multiple sensor fusion approach that combines three kinds of sensors in order to detect people using RGB-D vision, lasers and a thermal sensor mounted on a mobile platform. The Kinect sensor offers a rich data set at a significantly low cost, however, there are some limitations to its use in a mobile platform, mainly that the Kinect algorithms for people detection rely on images captured by a static camera. To cope with these limitations, this work is based on the combination of the Kinect and a Hokuyo laser and a thermopile array sensor. A real-time particle filter system merges the information provided by the sensors and calculates the position of the target, using probabilistic leg and thermal patterns, image features and optical flow to this end. Experimental results carried out with a mobile platform in a Science museum have shown that the combination of different sensory cues increases the reliability of the people following system.
1. Introduction
Developing robots able to collaborate with humans in real-world domains such as material transport, rescue, health care, manufacturing, etc. poses numerous advantages. A requirement to achieve this objective is to develop the robot ability to accurately and robustly detect and track human partners in order to generate the proper behaviour. This research deals with the issues related to developing a reliable “person following” behaviour that allows the robot to accompany a human. Once the target person is detected, the robot attempts to drive directly toward the person's location. To this aim our approach is to endow the robot with multimodal perception that enables it to fuse information from multiple sensors, assimilate these multimodal data in real time and then respond at the timescale of the interaction.
The primary requirement of this research has been to investigate the realization of a human tracking system based on low-cost sensing devices. Recently, research on sensing components and software led by Microsoft has provided useful results for extracting the human pose and kinematics [1]. The Kinect motion sensor device offers visual and depth data at a significantly low cost. While the Kinect is a great innovation for robotics, it has some limitations. First, the depth map is only valid for objects that are further than 80cm away from the sensing device. A recent study [2] about the resolution of the Kinect proves that for mapping applications the object must be in the range of 1-3 m in other to reduce the effect of noise and low resolution. Second, the Kinect uses an IR projector with an IR camera, which means that sunlight could have a negative effect, taking into account that the sun emits in the IR spectrum. Third, the Kinect relies on algorithms for detection of human activities captured by a static camera. In mobile robot applications the sensor configuration is embedded into the robot, which is usually moving. As a consequence, the robot is expected to deal with environments that are highly dynamic, cluttered and frequently subject to illumination changes.
To cope with this, our work is based on the hypothesis that the combination of multiple sensors, a Kinect, a thermopile array sensor (Heimann HTPA thermal sensor) and a Hokuyo Laser can significantly improve the robustness of human detection. Thermal vision helps to overcome some of the problems related to colour vision sensors, since humans have a distinctive thermal profile compared to non-living objects (therefore human pictures are not considered as positive) and there are no major differences in appearance between different people in a thermal image. Another advantage is that the sensor data does not depend on light conditions so people can also be detected in complete darkness. As a drawback, some phantom detections near heat sources such as industrial machines or radiators may appear. Therefore, it is a promising research direction to combine the advantages of different sensing sources because each modality has complementary benefits and drawbacks as it has been shown in other works, [3], [4], [5], [6] and [7].
We have experimented in a Science museum with different elements exposed and people moving around and strong illumination changes due to weather conditions.
The rest of the paper is organized as follows: In Section II related work in the area of human tracking is presented. We concentrate mainly on work done using multiple sensor fusion for people tracking. Section III describes the proposed approach and Section IV the experimental setup. Section V shows experimental results and Section VI shows conclusions and future work.
2. Related work
People detection and tracking systems have been studied extensively due to the increasing demand of advanced robots that must integrate natural Human-Robot Interaction capabilities in order to perform some specific tasks for humans or in collaboration with them. As a complete review on people detection is beyond the scope of this work (an extensive work can be found in [8] and [9]) we focus on most related work.
To our knowledge, two approaches are commonly used for detecting people using a mobile robot. The first includes vision-based techniques and the second approach combines vision with other modalities, normally range sensors, such as laser scanners or sonar like in [10], [11]. Recent computer vision literature is rich in people detection approaches in colour images. Most approaches focus on a particular feature: the face [12]; [13], the head, [14], the upper body or the torso, [15], the entire body, [16], just the legs, [17], or multimodal approaches that integrate motion information [3]. All methods for detecting and tracking people in colour images on a moving platform face similar problems and their performance depends heavily on the current light conditions, viewing angle, distance to persons and variability of appearance of people in the image.
Apart from cameras, the most common devices used for people tracking are laser sensors. One of the most popular approaches in this context is to extract the legs' position by detecting moving blobs that appear as local minima in the range image. [18] presents a system for detecting legs and following a person with only laser readings. A probabilistic model of a leg shape is implemented, along with a Kalman filter for robust tracking. [19] addresses the problem of detecting people using multiple layers of 2D laser range scans. Other implementations such as [20] also use a combination of face and laser-based leg detection.
Most existing combined vision-thermal-based methods, [4], [5], [6], [7], concern non-mobile applications in video monitoring applications and especially for pedestrian detection where the pose of the camera is fixed. Another approach, [21], shows the advantages of using thermal images for face detection. They suggest that the fusion of both visible and thermal-based face recognition methodologies yields better overall performance.
However, to the author's knowledge, there is little published work on using thermal sensor information to detect humans using mobile robots. The main reason for the limited number of applications using thermal vision so far is probably the relatively high price of this kind of sensor. [22] shows the use of thermal sensors and grey scale images to detect people in a mobile robot. A drawback of most of these approaches is the sequential integration of sensory cues. People are detected by thermal information only and are subsequently verified by visual or auditory cues.
3. Proposed approach
We propose a multimodal approach, which is characterized by parallel processing and filtering of sensory cues, as is shown in Figure 1. Since our algorithm is intended to run in a robot, our implementation is based on the ROS system [23].

Approach combining three input clues from RGB-D sensor, laser and thermal sensor using a particle filter approach.
The People tracking system is based on a Hokuyo laser sensor, a HTPA thermal sensor developed by Heimann and a Kinect sensor, mounted on a RMP Segway mobile platform, which are shown in Figure 2. Each sensor provides input to three detection units: Leg detection, Vest Detection and Thermal Detection explained later in this section. The Detection units feed target candidates to the Particle filter where the information is fused. The Best candidate from all the particles is then selected to set the position to be reached by the robot in order to follow the target person.
The HTPA allows the measurement of the temperature distribution of the environment, where very high resolutions are not necessary, such as person detection, surveillance of temperature critical surfaces, hotspot or fire detection, energy management and security applications. The thermopile array can detect infrared radiation; we convert this information into an image where each pixel corresponds to a temperature value. The sensor only offers a 32×31 image that allows a rough resolution of the environment temperature. The benefits of this technology are very small power consumption, as well as the high sensitivity of the system.
Kinect provides depth data that we transform into depth images, it uses near infrared light to illuminate the subject and the sensor chip measures the disparity between the information received by the two IR sensors. It provides a 640×480 distance (depth) map in real time (30fps). In addition to the depth sensor, the Kinect also provides a traditional 640×480 RGB image.
The scanning laser range finder chosen for the leg and obstacles detection tasks is a Hokuyo UTM-30LX. This laser provides a measuring area of 270 angular degrees, from 0.1 to 30m in depth and an angular resolution of 0.25 (1080 readings per scan).

The used robotic platform: a Segway RMP 200 provided with the Kinect, a Hokuyo laser and the thermal sensor
2.1 Leg detection
The proposed Leg Detection makes use of the probabilistic leg pattern presented in previous works [18]. The proposed system has implemented a leg model as a sequence of max >min > max > min > max given the laser readings (as in [3]), see Figure 3. Based on the five points shown in the figure (Pa, Pb, Pc, Pd and Pe) different measures are defined, such as the distance between the legs and the distance between the legs and the background.

Leg pattern based on the work of Belloto et al. [3].
2.2 Vest detection
As stated above, RGB-D images are used to track the target and add information to the particle filter. The position of the target will be estimated by Vest Detection and this information will be provided by means of the distance from the robot's centre, the angle from the robot's front direction and its height. Taking into account the proposed particle filter's structure, only the information on the angle and distance will be used in further steps of the proposed approach. The next paragraphs will give details about Vest Detection.
The vest detection method is intended to be used with a person that is wearing an emergency vest. The foreseen applications for the people following behaviour implemented by the robot are mainly related with robots supporting emergency personnel, in rescue activities for instance. In this method an RGB filter is applied in order to focus the attention towards the emergency vest's yellow colour, obtaining a binary image where the white pixels correspond to the target colour. After that, the binary image is filtered by erasing first the very small white areas and then applying morphological dilation and erosion operations (the result is shown in Figure 4 (a)). If there is more than one white region in the resulting image, the one with the bigger area is selected. The chosen area is used to extract some image features (corners with big Eigenvalues) to be tracked in the received images (see Figure 4 (b)). The optical flow is calculated for the detected corners using the Lucas-Kanade [24] method. In each frame, after calculating the optical flow, the centroid of the corners will be extracted, this being the target's estimated position.

Binary image original with features Emergency vest detection
To increase the reliability of the tracking avoiding errors, especially when the target turns or changes its perspective, the image features are recalculated each time the distance between them changes or some points disappear.
2.3 Thermal detection
People present a thermal profile different from their surrounding environment. The temperature detected in the pixel corresponding to a person is usually around 37 degrees Celsius, with a slight tendency to be slightly lower, due to the presence of hair or clothes over the skin.
We implement a procedure that, given a thermal image, computes a vector of 32 floating point numbers. The nth element of this vector corresponds to the estimation of the probability a person is in column n (a column of 31 elements).
This computation is performed in three steps:
First of all, a likelihood of corresponding to a person is assigned to every thermopile pixel. This likelihood is computed under the assumption that the temperature of a person is normally distributed with mean μ and standard deviation σ. To compute the mean and the standard deviation we have taken several thermal images of people standing in front of the sensor and the pixels corresponding to those images have been taken into account to compute the parameters. Several values have been tested and values of mean = 36 andstandard deviation = 2 have been used with good experimental results.
Then smoothing of the likelihood matrix is performed by convolution with a Gaussian kernel with a width of five pixels [25].
And finally the maximum of column n is assigned to the nth element of the aforementioned likelihood vector.
2.4 Fusion using particle filter
Once the Leg Detection, Vest Detection and Thermal Detection are defined, it is necessary to merge and fuse this information to perform complete person tracking. To this end a Sequential Importance Resampling (SIR) [26] particle filter is proposed, as it fits in this kind of nonlinear and non-Gaussian problem.
Focusing on the posed problem, the state in time t will be defined as a pair of x and y positions, X(t)=[x(t), y(t)]. As it is not possible to model the target's movement pattern a priori, the state transition is defined as
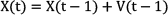
where X(t-1) is the previous state vector and V(t-1) is the process noise.
The observation, on the other hand, is defined by the information provided by Leg Detection, Vest Detection and Thermal Detection. So based on those three information sources each particle will be defined by a leg likelihood, a vest likelihood and a thermal likelihood.
Finally the tracking procedure of the particle filter is done as shown in Figure 5.

People following algorithm using particle filter.
2.4.1 Leg Likelihood
As discussed above, the Leg Detection based on previous work [3] will analyse each laser reading set and will provide an array of possible leg angles and depths with a likelihood above a given threshold. To calculate the leg likelihood for each state or particle the nearest possible leg is detected from the information provided by the Leg Detection Unit. Based on this leg position the leg likelihood is calculated as
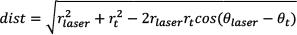

where dist is the radial distance between the particle and the legs detected by the laser scan and Pleg is calculated as the multiplication of the likelihood of the leg pattern described in Section 2.1 and an exponential function, returning smaller values as the distance increases.
2.4.2 Vest Likelihood
The information provided by the Vest Detection is also used to compute the camera likelihood. This likelihood is calculated using the angle estimated by means of the image features and optical flow. The probability is calculated as:


where dist is the distance between a particle's angle and the detected feature's central position and Pvest is calculated as an exponential function.
2.4.3 Thermal Likelihood
The thermal likelihood is calculated using the information provided by Thermal detection. To that end, for each particle the nearest value of the evidence array that exceeds a certain threshold is detected and, based on this angle, the likelihood is calculated as


where dist is the distance between the particle and the person detected by the thermal sensor and Ptherm is calculated as the multiplication of the likelihood of the thermal profile of the person and an exponential function.
2.4.4 Final Likelihood
Once the likelihoods are calculated, the final likelihood of a state given an observation is calculated as
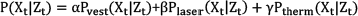
where Pvest(Xt|Zt)), Plaser(Xt|Zt) and Ptherm(Xt|Zt) are the likelihoods calculated from the information provided by Leg Detection, Vest Detection and Thermal Detection respectively and α, β and γ are coefficients to weight the three likelihoods. The addition of these coefficients allows more importance to be given to one of the information sources if desired. During the evaluation process a set of values are tested in order to obtain a good performance.
3. Experimental evaluation
In this section, we discuss the experimental evaluation of our approach. This section describes the tests that have been carried out in order to assess the performance of the different feature detectors considered, with regard to the task described in the previous sections.
We quantitatively evaluate our algorithm using data collected with a mobile robot moving in a Science museum.
During the experiments, the robot was remotely controlled. We asked different people to walk naturally in front of the robot. We collected two sets of data (320×240 RGB-D image+284 laser+32×31 thermal) at a frequency of 4Hz in different areas of the museum. The fist dataset contains 2862 data and the second dataset 2300 images.
Figure 6 shows some images taken by the robot. As it can be seen, lighting conditions affect to the image treatment, as there are crystal corridors in the museum (Figure 6 (a) and Figure 6 (b)). In addition there are some aesthetic elements that are detected as people, such as the big figure in the door in Figure 6 (c).

Eureka! Science Museum
For all the datasets, we hand-annotated the position of the people to be tracked, selecting the centre of the vest as a target point. From the depth images we consider a bound of 20 pixels in order to extract the distance from the robot. The annotation is provided for four images per second. The picture in the right corner of Figure 6 (d) shows a people following sequence where the annotated position is represented.
In order to establish the relative position between the target person and the robot a three-dimensional cylindrical coordinate system is defined, taking into account the posed problem and the available sensors as shown. Each target's position will be defined with three values (ρ,φ,z) where ρ represents the Euclidean distance from the robot's centre, φ represents the angle from the robot's front direction and z is the height as shown in Figure 7. Taking into account that the robot's movement type is restricted to a plane, it was decided to leave out the z-axis in this step of the experiment as it does not add any information to the tracking process.

Robot coordinate system
Figure 8 represent the range of data in the angle and depth used in the evaluation process.
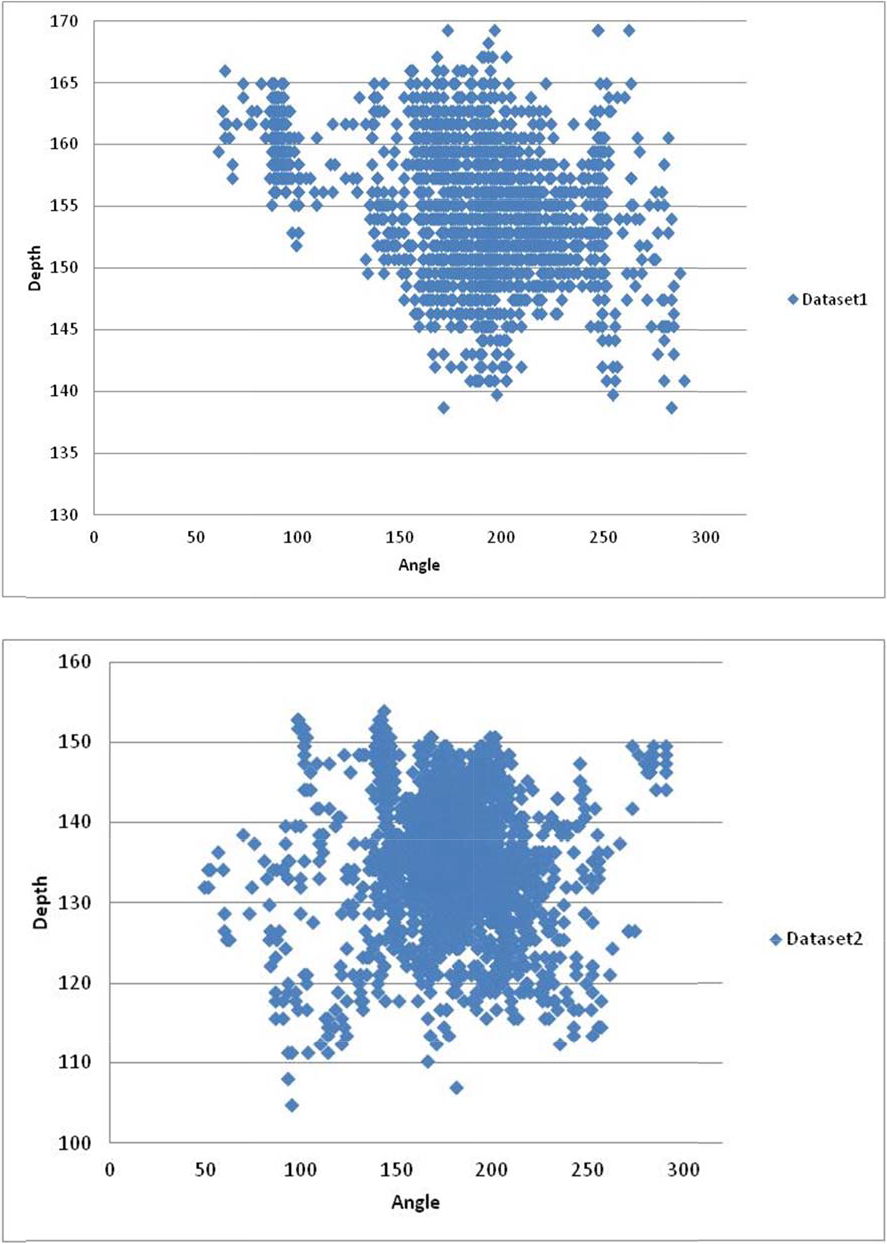
Annotated ground truth data for the two datasets used in the experiments (angle and depth position of the target person). The target persons are in an angle range of 50-320 pixels and a depth range of 100-200cm.
4. Experimental results
The performance of the people tracking system is evaluated in terms of error in the estimation, in distance and in angle, during person following tasks. Table 1 and Table 2 show a summary of the mean and standard deviation of errors obtained by the different tracking systems and the combination of them. The evaluation has been performed using the detectors individually: only Legdetection, only Vest detection, only Thermal detection and in combination of two giving the same weight to both detectors (vest and thermal, leg and thermal, leg and vest) and in combination of three with different weights. It should be noted that the fusion of the three sensor sources improves in both angle estimation and distance estimation; the results obtained by each estimator individually or in combination of two can be seen in Figure 9 and Figure 10. The Vest detector provides the best estimations individually as well as in combination with other sensors. For this reason in the final combination the Vest detector has a higher weight than the other sensors.

Mean errors in angle estimation for the different combinations used in the two datasets.

Mean errors in depth estimation for the different combinations used in the two datasets.
Results in term of error in angle (degrees). L refers to leg detection, V vest detection and T thermal detection. The number before the letter refers to the weight given to each detector.

Results in term of error in depth (m). L refers to leg detection, V vest detection and T thermal detection. The number before the letter refers to the weight given to each detector. The thermopile sensor is not used to estimate the position in depth of the tracked person.

Laser and thermal detection individually provide the worst results, as well as the combination of both. It seems that a thermal sensor in combination with the rest of the sensors deteriorates the estimations and in the case of the laser and vest combination the results are better than laser vest and thermal with the same weight. However, the final combination considering the thermal information with a weight of 0.15 improves the vest and laser combination.
For the results achieved in the working range (1 to 2m distance to the target) with the final combination of sensors it is clear that the best behaviour in general is obtained by the particle filter combining all the sensory cues.
5. Conclusions
In this paper, we have introduced a multimodal approach to detect and track people in indoor spaces from a mobile platform. This approach has been designed to manage three kinds of input images, colour, depth and temperature to detect people. As shown in the experimental evaluation, using complementary sensors and fusing their results using particle filtering results in robust and accurate person detection.
In the near future we aim:
To develop improved detectors combining/fusing visual cues using particle filter strategies, including face recognition and motion information, in order to track people gestures.
To improve the algorithm's parameter adjustment without hand tuning, using machine learning approaches.
To integrate with robot navigation planning ability to explicitly consider humans in the loop during robot movement.
To extend to other scenarios. This is a first implementation of a system that can be extended toward an outdoors scenario.
Footnotes
6. Acknowledgements
The work described in this paper was partially conducted within the ktBOT project and funded by KUTXA Obra Social.