
Abstract
In this study, the use of alternative acoustic sensors in human-robot communication is investigated. In particular, a Non-Audible Murmur (NAM) microphone was applied in tele-operating the Geminoid HI-1 robot in noisy environments. The current study introduces the methodology and the results of speech intelligibility subjective tests when a NAM microphone was used in comparison with using a standard microphone. The results show the advantage of using a NAM microphone when the operation takes place in adverse environmental conditions. In addition, the effect of Geminoid's lip movements on speech intelligibility is also investigated. Subjective speech intelligibility tests show that the operator's speech can be perceived with higher intelligibility scores when the operator's audio speech is perceived along with the lip movements of robots.
1. Introduction
To date, many studies have addressed the problem of human-robot interaction [1]. Components or modalities such as speech, gestures, gaze and others have been used in order to facilitate a natural human-robot interaction. Particular efforts have been focused on designing and developing human-like robots [2]. The Geminoid HI-1 robot, which was developed at the ATR, Intelligent Robotics and Communication Laboratories, Japan [3, 4], is a tele-operated anthropomorphic robot designed to be a duplicate of an existing person. Since speech is the most natural modality for human-human communication, in human-Geminoid interaction speech communication also plays an important role. In addition to audio speech, communication is also performed by the lip movements of Geminoid.
In this study, the results of subjective speech intelligibility tests conducted to evaluate the importance and the effect of Geminoid's lip movements on speech intelligibility are reported. Several subjects have been employed in order to evaluate the intelligibility of speech perceived during interaction, and under clean and noisy conditions.
Moreover, in this study the use of alternative acoustic sensors is also investigated. In particular, speech uttered by an operator while using a NAM microphone to tele-operate Geminoid was subjectively evaluated and compared with speech uttered while using a standard microphone.
2. The Geminoid HI-1 tele-operated android
Figure 1a and Figure 1b show the Geminoid HI-1 robot with its master person. Geminoid HI-1 is a duplicate of its creator. A Geminoid is an android, designed to look exactly like a real human. Its name originates from the Latin word “geminus” meaning twin, and “oides” meaning similarity. Anthropomorphic robots such as Geminoid are designed to be very similar to real humans with features such as artificial skin and hair, and are controlled through a computer system that replicates the facial movements of the operator in the robot. Humanoid robots belong to another robot family, which includes robots designed for human-robot interaction. Humanoid robots, however, do not have the appearance of real humans.

(a) and (b): The Geminoid HI-1 (left) and its master person (right).
In Geminoid HI-1, the robotic element has an identical structure to previous androids [5]. Efforts have been focused on designing a robot to be a copy of the master person. Silicone skin was moulded by a cast taken from the original person; shape adjustments and skin textures were painted manually based on MRI scans and photographs. Fifty pneumatic actuators drive the robot to generate smooth and quiet movements. The 50 actuators were determined to effectively show the movements necessary for human interaction, and also express the master's personality traits. Thirteen actuators are embedded in the face, 15 in the torso, and the remaining 22 move the arms and legs.
3. Non-Audible Murmur (NAM)
Non-Audible Murmur (NAM) refers to a very softly uttered speech received through the body tissue. A special acoustic sensor (i.e., the NAM microphone) is attached behind the talker's ear. This receives very soft sounds that are inaudible to other listeners who are in close proximity to the talker.
The first NAM microphone was based on stethoscopes used by medical doctors to examine patients, and was called the stethoscopic microphone [6]. Stethoscopic microphones were used by the first author for the automatic recognition of NAM speech [7]. The silicon NAM microphone is a more advanced version of the NAM microphone [8]. The silicon NAM microphone is a highly sensitive microphone wrapped in silicon; silicon is used because its impedance is similar to that of human skin. Silicon NAM microphones have been employed for automatic recognition of NAM speech as well as for NAM-to-speech conversion [9]. Similar approaches have been introduced for speech enhancement or speech recognition [10].
The speech received by a NAM microphone has different spectral characteristics in comparison to normal speech. In particular, the NAM speech shows limited high-frequency contents because of body transmission. Frequency components above the 3500–4000 Hz range are not included in NAM speech. The NAM microphone can also be used to receive audible speech directly from the body [Body Transmitted Ordinary Speech (BTOS)]. This enables automatic speech recognition in a conventional way while taking advantage of the robustness of NAM against noise. Figure 2 shows the spectrogram of an audible utterance received by a close-talking microphone and Figure 3 shows the spectrogram of the same utterance received by a NAM microphone. As is shown in the figure, only low frequency components are included in the NAM speech.

Spectrogram of an audible utterance received by a close-talking microphone.

Spectrogram of an audible utterance received by a NAM microphone.
Previously, the first author of the current paper reported experiments for NAM speech automatic recognition that produced very promising results. A word accuracy of 93.9% was achieved for a 20k Japanese vocabulary dictation task when a small amount of training data from a single speaker was used [7]. The HMM distances of NAM sounds in comparison with the HMM distances of normal speech were also investigated, which indicated distance reduction with regard to NAM sounds [11].
In this study, a new version of a NAM microphone is used to receive audible speech through the body tissue (i.e., BTOS) at the operator's side. The study aims at investigating the use of NAM microphones in Geminoid-human interaction under noisy conditions. However, very often Geminoid or similar robots are operated in noisy environments, such as conferences, malls, etc. Since NAM microphones show increased robustness against noise, using a NAM microphone instead of a standard microphone in operating Geminoid might be advantageous in adverse environmental conditions.
Figure 4 shows the old and the new versions of the NAM microphone. As is shown, the new version of NAM microphone is smaller than the previous one, and can be attached to the talker more easily. The new version is made by a special material and – to some extent – can be attached to the talker without using any supporting device.

Old version (left) and new version (right) of NAM microphone.
4. Diagnostic Rhyme Test
Speech can be evaluated based on intelligibility, naturalness and suitability for a specific application. Speech intelligibility is a measure of how well speech can be understood, and is different from speech naturalness. Depending on the application, intelligibility or naturalness appear to be the most important factor. For instance, in reading machines for the blind, speech intelligibility with high scores is more important than speech naturalness. In contrast, other applications (e.g., multimedia applications) require speech with high rates of naturalness.
Speech intelligibility can be evaluated subjectively or objectively. In the case of subjective evaluation, speech intelligibility is measured by subjective listening tests based on human perceptions. The response sets are usually syllables, words or sentences. The test sets usually focus on consonants, because consonants play a more important role in speech understanding than vowels.
Among other subjective tests, Diagnostic Rhyme Test (DRT) is very widely used to evaluate speech intelligibility. In this case, a set of word pairs is used to test speech intelligibility. A pair consists of two words which differ by a single phonetic characteristic in the initial consonant. Specifically, voicing, nasality, sustension, sibilation, graveness and compactness phonetic characteristics are evaluated by DRT.
In this study, the Japanese Diagnostic Rhyme Test (JDRT) was used to evaluate speech intelligibility [12]. JDRT consists of 60 word pairs, which evaluate the six phonetic characteristics (i.e., 10 word pairs for each characteristic). Table 1 shows the description of the JDRT.
Description of the JDRT

5. Controlling the lip movements of geminoid
Several approaches have been proposed for converting speech or text to lip motion. When text or phonetic transcriptions are available, methods like concatenation, trajectory generation or dominance functions (which are linear combinations of trajectories selected according to a phonetic transcription) can be applied [13, 14]. Lip motion generation methods based only on audio can roughly be categorized into phone-based methods or direct audio-visual conversion.
Phone-based methods model the audio-visual data using different phone models, mostly artificial neural networks (ANN) and hidden Markov models (HMM) [15]. However, in a tele-operated system, an online conversion of audio to lip motion is required, so that text-based methods or phone-based models are not appropriate.
Direct audio-visual conversion, without using phone models, have been recently shown to be more effective than HMM-based phone models [16, 17]. For example, in [17], these two approaches are directly compared and it was shown that the ANN-based method was judged significantly better than the HMM method. An explanation for that is because ANN-based approaches typically work on a frame-wise basis, and can offer closer, more direct synchronization with the acoustic signal than HMM, in which the mapping is mediated through longer phone-size units.
Another class of direct audio-visual conversion methods uses Gaussian Mixture Models (GMM) [18]. In that study, a maximum likelihood estimation of the visual parameter trajectories is adopted using an audio-visual joint GMM, and a minimum converted trajectory error approach is proposed for refining the converted visual parameters.
Finally, another approach of direct audio-visual conversion is based on formants (resonances of the vocal tract) [19]. Although most approaches use Mel-Frequency Cepstral Coefficients (MFCC) as acoustic parameters, the interpretation of their values with regard to phonetic contents are not straight as the formant frequencies. Further, all MFCC-based methods require construction of models prior to their use. Thus, in the present work, we adopt a formant-based lip motion generation method.
The proposed method operates in real time and is divided in two parts; one is the operator side, while the other is the robot side [20, 21]. In the operator side, formant extraction is firstly conducted on the input speech signal. Then, the origin of the coordinates of the formant space given by the first and second formants (F1 and F2) are translated to the centre of the vowel space of the speaker (adjusted by a graphic user interface), for accounting for differences in the vowel space depending on the speaker's features, such as gender, age and height. A rotation of 25 degrees is realized on the new coordinates, so that the F1 axis has better matching with the lip height. Although lip width can also be estimated from the normalized vowel space, only lip height is controlled in the present work due to the physical limitations of the robot. The estimated lip height is then converted to the actuator commands by a linear scaling. Audio packets and actuator commands are sent to a remote robot in intervals of 20 ms. Figure 5 shows the procedure of lip generation in the operator side.

Lip motion generation in the operator side.
On the robot side, the audio packets and the lip motion actuator commands are received. Then the actuator commands are sent to the robot for moving the lip actuators and a delay is controlled for playing the received audio packets, in order to synchronize the two streams. Figure 6 illustrates the lip motion generation on the robot side.

Lip motion generation on the robot side.
6. Methods
6.1 System Architecture and Description
In the current study, two experiments are described. In the first experiment, the effectiveness of lip motion generation based on the proposed method was evaluated. The authors were interested in investigating whether speech intelligibility is improved when the speech of an operator – in clean and noisy environments – is perceived along with the lip motions of a robot. In this experiment, a standard microphone was used to transmit the operator's voice. The operator was located in a different room to the robot, and office noise was present at a level of 35 dB(A). On the robot side, the listeners evaluated the uttered speech under four conditions; clean/noise conditions, with/without lip motions.
In the second experiment, the authors were interested in investigating whether when using a NAM microphone in the operator's side under noisy conditions, speech can be perceived with higher intelligibility compared with using a standard microphone. Very often, however, the operator has to tele-operate a robot in a noisy environment (e.g., mall, conference centre, etc.). In such cases, it might be beneficial to use a body-conducted microphone (e.g., NAM microphone), which shows higher robustness against noise compared with a standard microphone. In this experiment, audible speech was used. The operator's speech was transmitted to the robot side along with robot's lip motions. The listeners have to evaluate the operator's speech intelligibility when using a NAM microphone and when using a standard microphone by listening to the uttered speech and also by watching the lip motions of the robot. For reference a SONY ECM-C10 microphone was used. In the case of 70 dB(A) noise, the resulting signal-to-noise ratio (SNR) at the NAM microphone was 20 dB and using the standard microphone it was 5.9 dB. When noise at the 80 dB(A) level was present, the resulting SNR at the NAM microphone was 12.2 dB and at the standard microphone it was 2.9 dB.
6.2 Procedure for evaluation of Geminoid's lip movements
The experiments were conducted in the Geminoid's room, in a reverberant environment with 38 dB(A) background noise. The environment was chosen to be as similar as possible to the environment where human-Geminoid interaction occurs.
For this subjective evaluation, ten subjects (i.e., six males and four females) were employed. The subjects were normal-hearing, undergraduate students, and were paid to participate in the experiments. Their age was between 20 and 24 years old. Before the experiments, they had not met the Geminoid robot in real life.
The subjects were seated in front of Geminoid at a distance of about 1.5m. They were also instructed to watch the Geminoid's lips/face while listening to a word. The stimulus consisted of the 120 words of the JDRT, which were pre-recorded and played back one by one during the experiment. Each subject was provided with a list, which included the correct uttered word and its pair in the JDRT. The subjects were instructed to definitely choose one of the two written words. For example, if the uttered word was zai, the subjects had to choose between zai and sai.
The experiment consisted of four sessions. Specifically, speech intelligibility was evaluated under the following conditions: speech with lip movements, speech without lip movements, speech with lip movements and background babble noise at a level of 70 dB(A) played back through a loud speaker in the subject's area, and speech without lip movements with the same babble noise in the subject's area. The order of the four sessions was randomly selected in order to avoid the subjects memorizing the correct words.
6.3 Procedure for evaluation of NAM microphone
Intelligibility of speech received by a NAM microphone and speech received by a standard microphone were evaluated in noisy conditions. This experiment corresponds to the case when the operator is located in a noisy environment and uses a NAM microphone to tele-operate Geminoid.
In this experiment, the uttered words for intelligibility evaluation included noise. To simulate this situation, babble noises at the levels of 70 dB(A) and 80 dB(A) were played back through a loud speaker, and were recorded simultaneously by a NAM and a standard microphone. The recorded noises were then superimposed onto the clean words to simulate the noisy stimuli.
For this evaluation, four subjects were used (i.e., two males and two females). The subjects were students and employees working in the laboratory. All of them were normal-hearing. While listening the stimulus, the subjects were instructed to watch the Geminoid's lips/face movements. The same word lists as those employed in the previous experiments were used.
7. Results
7.1 The effect of lip movements on speech intelligibility
Figure 7 shows the results obtained in the experiments. The results show that the lip movements of Geminoid have an effect on perceptual scores in both clean and noisy environments. The highest overall score was achieved when speech intelligibility was evaluated in a clean environment with lip movements. In this case, the evaluation score was 92.2%. The second highest score was obtained when the evaluation was performed in a clean environment, but without lip movements. In this case, the score was 87.5%. When the speech was evaluated in a noisy environment with lip movements, the score was 82.2%. Finally, in the case of evaluation in a noisy environment without lip movements the score was as low as 79.7%.
Evaluation of speech intelligibility with respect to Geminoid's lip movements.
The results clearly show that when interacting with Geminoid in both clean and noisy environments, the operator's clean speech can be better understood when also watching Geminoid's face and lip movements. This phenomenon is very similar to the one appearing in human-human communication. Since speech includes both audio and visual modalities, audiovisual speech perception results in higher speech intelligibility rates.
7.2 Speech intelligibility using NAM and desktop microphones
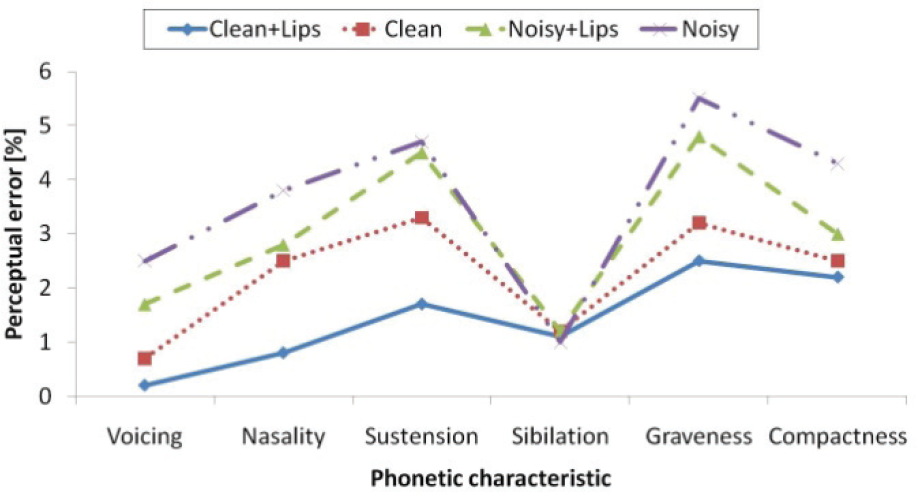
Figure 8 shows the results when noisy stimulus of 70 dB(A) was used. The results show that in the case of sustension, sibilation and compactness phonetic characteristics, lower error rates were obtained when using a standard microphone. In all the other cases, the NAM microphone achieved lower error rates. The differences in the error rates might be explained by the limited frequency band of the NAM microphone. When, however, the uttered word has an initial consonant with rich information in the higher frequency band, this word may be confused resulting in lower intelligibility scores. The overall perceptual score was 79.2% when using the standard microphone and 77.7% when the NAM microphone was used. The scores are closely comparable, and the difference was statistically not significant.

Evaluation of speech intelligibility with noisy stimuli [70 dB (A)].
Figure 9 shows the results when a noisy stimulus of 80 dB(A) was used. As is shown, when using a NAM microphone significantly lower error rates were obtained in most of the cases. Only in the cases of sustension and sibilation did the desktop microphone performed slightly better. The overall intelligibility score for the standard microphone was 63.5% and for the NAM microphone 72.4%. The difference in intelligibility scores was statistically significant.

Evaluation of speech intelligibility with noisy stimuli [80 dB (A)].
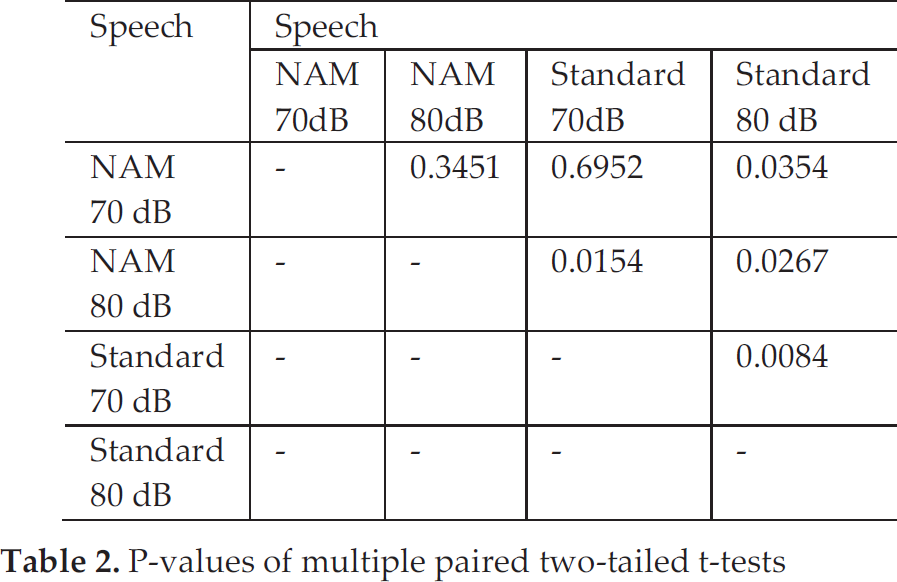
Table 2 shows the p-values of multiple paired two-tailed t-tests [22]. As is shown in the Table, in the case of NAM microphones, the difference between 70 dB(A) and 80 dB(A)noise levels was statistically not significant. This observation indicates that NAM microphones are more robust against noise compared to standard microphones. In the case of standard microphones, the difference between 70 dB(A) and 80 dB(A) noise levels was statistically significant.
P-values of multiple paired two-tailed t-tests
8. Discussion
This study reports the results of subjective speech intelligibility tests aiming at evaluating several aspects of human-robot interaction. Experiments were conducted to evaluate the effect of Geminoid's lip movements on speech intelligibility. The results obtained justify the effectiveness of Geminoid's lip movements while interacting with humans in both noisy and clean environments. In addition, the achieved results show the effectiveness of the method used to control the lip movements. It might be possible, however, that lower intelligibility scores are achieved if the speech was not accurately synchronized with lip motions, or if the lip motions were not accurately synthesized according to the uttered speech. This would result in an effect similar to the McGurk effect [23].
Anthropomorphic robots such as Geminoid HI-1 are designed and developed to interact with humans in different environments where noise might also be present. For more effective operation of Geminoid, the use of alternative acoustic sensors was also investigated in this study. Previously, the authors conducted experiments using a NAM microphone and demonstrated its robustness against noise. For this reason, the use of a NAM microphone by the operator was also investigated when Geminoid was tele-operated in noisy environments. The results obtained show that a NAM microphone might be very useful in very noisy environments.
The current study can be applied in situations when the operator is located in very noisy environment (e.g., malls, conference rooms), or when the robot is located in other noisy environments (e.g., train stations).
Although at this stage an automatic speech recognition module is not included in Geminoid, in the future we plan to investigate the possibility of decreasing the efforts of the operator by using automatic speech recognition while interacting with Geminoid. When the interaction takes place in adverse environments, users can use NAM microphones to operate the speech recognition engine.
9. Conclusions
In this study, the effect of Geminoid's lip movements on speech intelligibility was investigated by conducting subjective tests. The results showed that with lip movements, the intelligibility rates increase. This study also compares speech intelligibility using a NAM microphone and a standard microphone. The achieved results show the effectiveness of using a NAM microphone in adverse environmental conditions.
Footnotes
10. Acknowledgements
This work was partly supported by KAKENHI (21118003).