
Abstract
This paper presents a novel supervised dimensionality reduction approach for facial feature extraction called (2D)2LDALPP. The proposed (2D)2LDALPP method effectively combines alternative 2DLDA with alternative 2DLPP. The feature extraction is split into two steps: firstly, the column directional information is extracted by applying alternative 2DLDA; secondly, the feature matrix is inversed and alternative 2DLPP is used to extract the row directional information. The advantage of the method lies in the compression of the facial image in two different directions and the fact that the dimension of the feature matrix is low. At the same time, because 2DLDA is a supervised learning method, the proposed method not only preserves the manifold structure of the samples but also contains the label information of the classes. Experimental results on the Feret, ORL, and Yale databases show that the proposed method is effective.
1. Introduction
Feature extraction is the key problem of face recognition, and the extraction of effective and stable features is a current research hot spot. Principal Component Analysis (PCA) [1] and Linear Discriminant Analysis (LDA) [2] are the two best-known methods, which have been developed along with many other outstanding approaches. The objective of PCA is to seek a set of mutually orthogonal basis functions that capture the directions of maximum variance in the data. LDA aims to find an optimal projection space that maximizes the ratio of between-class scatter matrices and within-class scatter matrices of the training samples. LDA is a supervised learning method and thus is suitable for the classification task. However, LDA used in face recognition will confront a small sample size problem (SSS) due to the larger size of the vector and the relatively small number of training samples. To overcome this problem, the Fisherface method first projects the samples into the PCA space so that the within-class scatter matrix is non-singular. Many studies have indicated that face images possibly reside in a low dimensional, non-linear sub-manifold embedded in the original high dimensional data space. This discovery has inspired many to propose the use of many manifold learning methods in face recognition. He [3] proposed a Locality Preserving Projection (LPP) called the Laplacianfaces method, which finds an embedding that preserves the local structure of the image space. Being similar to LDA, LPP also confronts the SSS if it is used directly for the face recognition task, so Laplacianfaces extracts the low-dimensional features of the image by first projecting the samples into PCA space.
PCA, LDA and LPP are 1D linear projecting methods. The common disadvantage of these methods is that an image must be presented as a vector, which not only causes the SSS but also the loss of the structure information residing in the 2D image. To address this problem, two techniques are introduced to improve efficiency. One is a kernel technique, which has been reported in [4], [5],[6] and [7]. The other is a 2D linear projecting method. Yang [8] developed the Two-Dimensional Principal Component Analysis (2DPCA) method; Li [9] developed the Two-Dimensional Linear Discriminant Analysis (2DLDA) method, and Hu [10] proposed the Two-Dimensional Locality Preserving Projection (2DLPP) method. 2D techniques compute eigenvectors of the so-called image covariance matrix directly, without matrix-to-vector conversion, making 2D techniques more efficient than 1Dversions.
The feature of 2D techniques is the matrix, and the dimension is much greater than 1D techniques, where the feature is the vector. At the same time, 2DPCA, 2DLDA and 2DLPP extract the feature of the image in the row (or column) direction only, so the information of the row (or column) direction is not correlative, but the information of the column (or row) is still correlative. Certain methods are proposed to deal with this issue. The first method is the so-called two-directional two-dimensional method, in which 2D techniques are carried out twice. Zhang [11] proposed Two-Directional Two-Dimensional Principal Component Analysis ((2D)2PCA); S. Noushath [12] developed Two-Directional Two-Dimensional Linear Discriminant Analysis ((2D)2LDA), and Guo [13] proposed Two-Directional Two-Dimensional Locality Preserving Projection ((2D)2LPP). Two-directional two-dimensional methods extract features from both the row direction and the column direction, and the dimension of the feature matrix is much less than in the two-dimensional techniques. As mentioned above, (2D)2PCA and (2D)2LPP are unsupervised learning methods which are not suitable for classification tasks such as face recognition. (2D)2LDA is a supervised learning method, but some research indicates that it is ambiguous on computing because there are different ways to construct the covariance matrix in the(2D)2LDA approach. The second type of method pays attention to the algorithm itself, which tries to amend 2D techniques by combining other optimal methods such as [14] and [15]. These methods improve the performance of recognition by adding optimal methods to 2D techniques; at the same time, the design of algorithm complexity is also improved. Recently, some methods that hybridize different feature extraction techniques have become popular. These methods combine more than two kinds of feature extraction techniques to enhance the recognition accuracy on the ORL,Yale and other famous databases, as reported in [16] and [17]. Qi [18] proposed another two-direction two dimensional method called (2D)2PCALDA, which combines 2DPCA and 2DLDA. It is reported that the performance of (2D)2PCALDA is better than (2D)2PCA and (2D)2LDA on the ORL and Yale databases.
The main disadvantage of two-directional two-dimensional compression methods is that the information of the feature matrix presentsonly a single feature. For example, (2D)2LPP preserves the local structure of the training samples without including the label information of the classes. By contrast, (2D)2LDA is a supervised learning method which contains the label information of the classes but loses the local structure of the training samples. Inspired by (2D)2PCALDA, in this paper we propose a similar method called (2D)2LDALPP. The feature matrix can be obtained by projecting an image into the column-directional alternative 2DLDA and the row-directional alternative 2DLPP sequentially. The experiment's results on subsets of the Feret, ORL and Yale databases show that the proposed method is effective. In the field of face recognition, there are always controversies about the competence of 2D subspace analysis methods. Wang [19] compared 2DPCA and 2DLDA on the ORL and Cas-peal databases. Rao[20] discussed the performance of some kinds of subspace analysis methods in five noise conditions. Lu [21] investigated dimensionality reduction approaches for direct feature extraction from tensor data. However, there are still no certain conclusions about this issue. In this paper, we also focus on the performance of present two-directional two-dimensional methods, which have been reported in [11],[12],[13] and [18], as well as our proposed method. We compare the recognition accuracy and computing complexity and discuss the advantages and disadvantages of these methods.
The rest of this paper is organized as follows. Section 2 briefly reviews alternative 2DLDA and 2DLPP methods; in Section 3,the idea of the proposed method is described; the experimental results and analysis are presented in Section 4, and the conclusion is given in Section 5.
2. Overview of alternative 2DLDA and 2DLPP approaches
2.1 Alternative2DLDA
Suppose {Xij} are the training images, which contain c classes, and ith class ωi has Ni training samples, the total training samples are N = Σci=1 Ni. The ith class jth sample is denoted by m × nmatrix Xij. The between-class scatter matrix Sb, within-class scatter matrix Sw and total class scatter St, are defined as follows[9]:

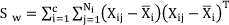

In Eqs.(1), (2) and (3), X̄ and X̄i denote the mean of all samples and the mean of the ith class samples, respectively. The approach of alternative 2DLDA attempts to seek a set of projecting vectors Ad = (ai,a2,…,ad) that best discriminates different face classes by maximizing the criterion function J(a) of alternative 2DLDA as

The vector aopt, which maximizes the function J(a), is called the optimal discriminant vector. The physical interpretation of maximization J(a) is that the ratio of between-class scatter matrix Sb,, and within-class scatter matrix Sw is maximal. That is, in this projecting direction, the samples of different class are more scattered and the samples of the same class are closer. Introducing Lagrange multiplier method, maximizing function J(a) is equal to the computed maximum value of function f:

Let ∂f/∂ai = 0, the objective function can be reduced to an eigen equation:

Obviously, if Sw is non-singular, the optimal vector of 2DLDA is the eigenvector corresponding to the maximal eigenvalue of structure Sw−1Sb. Generally, it is not enough to have only one optimal projection vector, so the discriminant vector Ad is composed of the orthogonal eigenvectors a1,a2,…,ad of Sw−1Sb corresponding to the first d largest eigenvalues. The feature matrix of Xij is Yij = ATdXij by projecting Xij into the subspace Ad, and the size of Yij is d × n.
2.2 2DLPP
Given N training samples, the objective function of 2DLPP [10] is defined as:

where ‖.‖ means L2 norm. Let Xi denote the ith sample, and Yi denote the feature matrix of Xi. Wij is the similarity of sample Xi and Xj, which can be defined as
The physical interpretation of minimizing J is that if Xi and Xj are close, the feature matrix Yi and Yj are also close. In this case, the samples in the low-dimensional space preserve the local manifold structure in the high dimensional space.
With the constraint

Introducing the Lagrange multiplier method, minimizing function J is equal to the solution of the eigenproblem of function as follows:

whereX = [X1X2 …XN] is an m × Nn matrix which consists of all the training samples. D is a diagonal matrix defined as Dii = Σi Wij, and the entries of D is the column (or row) sum of W. L is Laplacian's matrix, defined as L = D – W. In is an identity matrix of n order, and operator ⊗ is the Kronecher product of the matrix. Vector a is the eigenvector of Eq. (9), corresponding to the smallest eigenvalue. If the d smallest eigenvalues of Eq. (9) are λ1 < λ2 < … < λd, and its corresponding eigenvectors a1, a2,…,ad consist of the projecting matrix Ad = [al a2 … ad], the feature matrix of sample Xi is

Since Ad is an m × d matrix, the size of Y is d × n.
3. The proposed approach
3.1 Alternative 2DLPP approach
The essence of 2DLPP is the row-based LPP, which regards the row of images as a single sample for extracting the feature by carrying out LPP. A natural extension is to regard the column of images as a single sample for carrying out LPP. This method is named alternative 2DLPP. Obviously 2DLPP compresses the image in the row direction, while alternative 2DLPP does the same in the column direction.
Suppose the training set X = [X1X2 … XN] has N training samples. The size of Xi is m × n. The main idea of alternative 2DLPP is to seek a column vector bi of n order to obtain the row vector Yi of m order by linear transformation Yi = Xibi. Generally, it is not enough to select only one projecting vector, so the projecting subspace Br is composed of r eigenvectors b1,b2,…,br. The feature matrix of Xi is Yi = XiBr in the subspace Br, and the size of Yi is m × r.
Similarly, we can generalize an eigenproblem to obtain b, as shown in Eq. (11):

where X = [X1TX2T …XNT]T is an Nm × n matrix. D is a diagonal matrix defined as Dii =ΣjWij. Imis an identity matrix of m order, and operator ⊗ is the Kronecher product of matrix. Vector b is the eigenvector of Eq. (11) corresponding to the smallest eigenvalue. If the r smallest eigenvalues of Eq. (9) are λ1 < λ2 < … < λr, its corresponding eigenvectors b1,…,br consist of the projecting matrix B = [b1,b2, …, br]
3.2 (2D)2LDALPP
Suppose we have obtained the projection matrix Ad(as in Section 2.1) and Br (as in Section 3.1), projecting the m × n image Xij into Ad and Br sequentially to yield a d by d × r feature matrix Yij.

We called algorithm (12) (2D)2LDALPP. The size of Yij is d × r, due to d « m and r « n, so the dimension of the image is compressed significantly.
From formula (12) we can see that the main idea of (2D)2LDALPP is that the original image Xij is projected into the alternative 2DLDA subspace to extract the vertical direction feature ATdXij; ATdXij is then transposed to yield (ATdXij)T, and alternative 2DLPP is utilized to extract the horizontal direction feature. Thus, the feature matrix Yij contains both the vertical direction feature and the horizontal direction feature of the original sample image. Obviously, the vertical direction feature represents the discriminant information and the horizontal direction feature preserves the manifold structure of the sample. Because 2DLDA is a supervised learning method, (2D)2LDALPP contains the class label of training samples, which is the reason that the recognition performance of (2D)2LDALPP is better than (2D)2LPPand (2D)2LDA.
Given the test sample XT, Eq. (12) is used to obtain the feature matrix Y; a nearest neighbour is then used for classification. Here the distance between the two feature matrices Y and Yij is defined by

where‖Y-Yij‖ denotes the Euclidean distance between the two feature matrices Y and Yij. Suppose {Xij} is the training set which contain c classesω1,ω2…ωc; Xij denotes the ith class the jth sample. If d(Y,Ykj) = mini d(Y,Yij) and Ykj ∈ ωk, the resulting decision is Y ∈ ωk. The framework of (2D)2LDALPP is illustrated in Fig. 1.

The Framework of (2D)2LDALPP
To summarize the preceding description, the (2D)2LDALPP algorithm is as follows:
3.3 Algorithm analysis
The separability of extraction features is the important factor in evaluating the performance of the algorithm. Next, we use experimental methods to determine the separability of five existing two-directional two-dimensional methods.
We select the first to fifth individuals in Yale B [22]. Each individual has 64 samples. Fig. 2 shows samples of the database in the five two-directional two-dimensional subspaces. Figs. 2 (a), (b), (c), (d) and (e) represent the separability of (2D)2PCA, (2D)2LDA, (2D)2LPP, (2D)2PCALDA and (2D)2LDALPP, respectively. The figures, from left to right, are the scatter diagrams of each method in terms of the first and second projected vectors, the first and third projected vectors, and the first and fourth projected vectors. It is clear from Fig. 2 that (2D)2LDALPP has significantly higher separability than the other four methods for classifying the samples in the database, because the classes in (2D)2LDALPP have larger between-class distance and smaller within-class scatter. At the same time, it seems that (2D)2LPP is better than the last three methods:we believe the key factor is possibly that it preserves the manifold structure of the sample when the data is projected from high dimensional space to low dimensional space.

Distribution of some samples using the two features in two-directional two-dimensional subspace
The five methods we discussed above can be classified into two types: the single feature extraction type and the hybrid feature extraction type. (2D)2PCA,(2D)2LDA and(2D)2LPP belong to the first type, while (2D)2PCALDA and (2D)2LDALPP belong to the second type. The proposed method (2D)2LDALPP has two advantages. Firstly, comparing with (2D)2PCA,(2D)2LDA and (2D)2LPP, (2D)2LDALPP extracts the vertical feature of images by using alternative 2DLDA, and the horizontal feature by using alternative 2DLPP. Such hybrid feature is suitable for feature representation, which is used to improve recognition performance [23]. Secondly, the difference between (2D)2PCALDA and (2D)2LDALPP is that the latter replaces 2DPCA by using 2DLPP to extract the row-directional feature of images. From Fig.2, we can see that (2D)2LDALPP performs better than (2D)2PCALDA The main reason is as follows. 2DPCA is the 2D version of the PCA approach, which aims at preserving the global structure of the data. On the other hand, 2DLPP is the 2D version of LPP, which aims at preserving the local structure of original data by explicitly considering the manifold structure. The basis function obtained by LPP is the eigenvectors of the local covariance matrix [24]. It is commonly recognized that the intrinsic feature of face images possibly resides in a low-dimensional sub-manifold embedded in the original high-dimensional data space [10] [16] [17] and [18]. Therefore, the feature extracted by 2DLPP can be used to represent the sub-manifold embedded in the high-dimension space to improve the recognition performance.
3.4(2D)2LPPLDA
It should be noted that an alternative way to combine 2DLDA and 2DLPP is to extract the vertical feature of images by using 2DLPP and the horizontal feature by using 2DLDA. That is, first the column directional information is extracted by applying 2DLPP, then the feature matrix is inversed and 2DLDA is used to extract the row-directional information, which can be called the (2D)2LPPLDA approach. Compared with (2D)2LPPLDA, (2D)2LDALPP has the advantage in computational complexity. If the size of the training sample is m × n,d1,d2 and N are the number of the row-projected vectors, the number of the column-projected vectors, and the training number, respectively. The training complexity of (2D)2LDALPPis O(n2d1 + m2d2 + nd1N2), while that of (2D)2LDALPP is O(n2d1 + m2d2 + nmN2). Since d2 « m, it is obvious that the complexity of the (2D)2LPPLDA is much larger than that of (2D)2LDALPP, so we select the (2D)2LDALPP as our proposed method to compare other existing two-directional two-dimensional methods.
4. Experimental results and analysis
In this section, the proposed method (2D)2LDALPP is used for face recognition and tested on three well-known databases: Feret [25], ORL [26] and Yale [2]. Feret and Yale are used to test the performance of the face recognition methods in conditions of varied facial expressions and illuminations. The ORL database is used to examine the performance of the methods under the condition of minor variations of scaling rotation. We compare (2D)2LDALPP with (2D)2PCA, (2D)2LDA, (2D)2LPP and (2D)2PCALDA for their recognition accuracy and computing time. For (2D)2LPP and (2D)2LDALPP, if samples Xi and Xjare connected (Xi and Xj are in the same class), we use
We choose a subset of the Feret database consisting of 432 images from 72 individuals; each individual has set images, including a front image and its variations in facial expression and illumination. For the purpose of computation efficiency, the facial portion of each original image is cropped and resized to 56 × 48using nearest-neighbour interpolation. There are 40 different people in the ORL database and 10 different images of each person, making 400 images in total, and the size of each image is 112 × 92. All pictures are taken at different times, from different angles, with different facial expression (closed or open eyes, smiling or non-smiling surprised, annoyed, angry, excited) and with different facial details (with or without glasses, with or without beard, different hairstyle). The facial portion of each original image is cropped and resized to 56 × 48 using nearest-neighbour interpolation. The Yale database contains 165 greyscale images of 15 individuals, each of which has 11 different images showing various facial expressions in a range of lighting conditions. The facial portion of each original image is cropped and resized to 50 × 50 using nearest-neighbour interpolation from the original size of 320 × 243.
We conduct the experiments from three aspects. Firstly, we aim at examining the relationship between the recognition accuracy and the feature dimension, especially the low dimension of the feature matrix. Secondly, we consider the recognition accuracy corresponding to the training number. Finally, we compare the running time of these five methods and discuss their complexity.
4.1 Results on variety of feature dimensions
The relationship between the recognition performance and the feature dimension, especially in the lower dimension, is a crucial issue in face recognition systems. Due to the fact that face recognition systems are generally off-line, the feature dimension plays an important role in keeping the system in real-time. The lower the feature dimension, the faster the face recognition system. In this experiment, we try to find the effect of low dimension on face recognition performance.
The experimental database is split into two parts: one part is the training set, and the other is the testing set. On the Feret database, we randomly select two images per individual for the training samples, and the last four images are used as testing samples. Thus, the training set consists of 144 samples and the testing set consists of 288 samples. On the ORL database, six images per individual are used as training samples and the remaining four images are used as testing samples. The training set consists of 240 samples and the testing set consists of 120 samples. On the Yale database, six training samples per individual are selected randomly for training samples, and the last five images per individual are used as testing samples. The training set consists of 90 samples and the testing set consists of 75 samples.
In order to evaluate the recognition accuracy corresponding to the number of projected vectors, a classification experiment is conducted under a series of different dimensions. The size of the feature matrix is d × d (d is the number of the projected vector: its value is from 1 to 7) for (2D)2LDALPP, (2D)2PCA, (2D)2LDA, (2D)2LPP and (2D)2PCALDA Fig. 3(a) illustrates the recognition accuracy curves versus the number of projected vectors on the Feret database. From Fig.3(a), it can be seen that the recognition accuracy of (2D)2LDALPP, (2D)2PCALDA, (2D)2LDA increases rapidly with the number of projected vectors. When d>3, the recognition accuracy of (2D)2LDALPP, (2D)2PCALDA, (2D)2LDA is higher than (2D)2PCAand (2D)2LPP. The recognition accuracy approaches the best results at 78.13%, 49.65%, 73.26%, 55.78% and 77.78% at the dimensions of 6, 7, 7, (2D)2LPP,and (2D)2PCALDA, respectively.

Recognition performance of different approaches with varying dimension of feature matrices of the Feret, ORL and Yale face databases
Fig. 3(b) reports the results on the ORL database. Fig.3(b) shows that, on this database, (2D)2LDALPP, (2D)2PCA, and (2D)2LPP are superior to (2D)2LDA and (2D)2PCALDA when d<4, but the performance of all methods seem to be closer to one another when d>4. The top recognition accuracies of (2D)2LDALPP, (2D)2PCA, (2D)2LDA, (2D)2LPP,and(2D)2PCALDAare 98.75%, 97.5%, 98.75%, 99.38% and 97.5%, when the dimension of the feature vectors are 5, 7, 7, 6 and 7, respectively
Fig. 3(c) illustrates the results on the Yale database. (2D)2LDALPP, (2D)2PCA, and (2D)2LPP are superior to (2D)2LDA and(2D)2PCALDA when d<4, but the performance of all methods seems to be close when d>4. The recognition accuracy approaches the best results at 89.17%, 80%, 77.5%, 80% and 74.17% at the dimensions of 7, 6, 5, 6 and 6 for (2D)2LDALPP, (2D)2PCA, (2D)2LDA, (2D)2LPP,and (2D)2PCALDA, respectively.
It can be observed from the results that, on different databases, the recognition performance varies from method to method when the number of projected vectors is relatively smaller. On the Feret database, (2D)2LDALPP,(2D)2LDA and (2D)2PCALDA out-perform (2D)2LPP and (2D)2PCA, but on the ORL and Yale databases, it seems that (2D)2LDALPP, (2D)2LPP and (2D)2PCA are superior to (2D)2LDA and (2D)2PCALDA. In our opinion, the reason for this is the size of class in the training set. The bigger the class, the more suitable it is for the supervised learning method. In our experiment, the class of the Feret database is 72, the largest, so the supervised learning methods (2D)2LDALPP,(2D)2LDA and (2D)2PCALDA show better performances than the unsupervised learning methods (2D)2LPP and (2D)2PCA On the other hand, the classes of ORL and Yale are relatively smaller, and (2D)2LPP and (2D)2PCA are more accurate than (2D)2LDA and (2D)2PCALDA It seems that an unsupervised method is more powerful than a supervised learning method. (2D)2LDALPP also achieves satisfactory performance on these databases, and we believe this is because 2DLPP is included in the algorithm. According to the above analysis, (2D)2LDALPP combines the main features of 2DLDA and 2DLPP, which endows it with powerful and robust ability to extract the more significant features from the training samples. Of course, the constraint of the conclusion is the smaller dimension of the feature matrix.
4.2 Results on variation in training number
In 4.1 we have discussed the relationship between recognition performance and the low feature dimension in order to acquire more detailed results about the recognition performance. In this experiment, we compare the performance of the proposed method (2D)2LDALPP with four other methods for varying numbers of training samples. A random subset with l(=2,3,4,5) samples per individual on the Feret database is taken with labels to form the training set. The rest of the database is used as the testing set. The performance of (2D)2LDALPP is compared with that of (2D)2PCA, (2D)2LDA, (2D)2LPP, and (2D)2PCALDA The top recognition accuracies are shown in Table 1. The values in parentheses denote the dimension of the feature matrix for the top recognition accuracy.
Comparison of different approaches in terms of top recognition accuracy (%) on FERET database
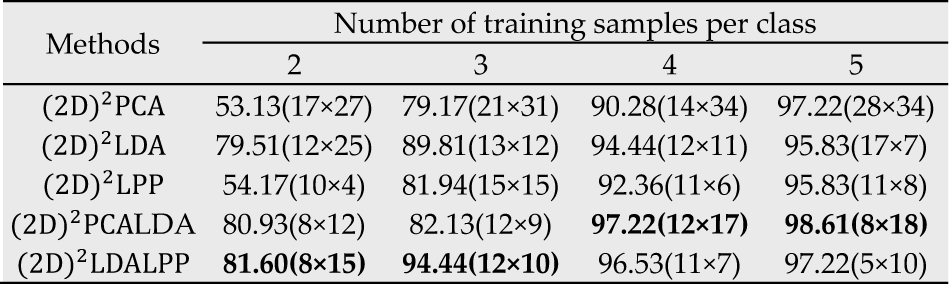
It is clear from Table 1 that the top recognition accuracy of (2D)2LDALPP is the highest with 2 or 3 training samples per class. The recognition accuracies are 81.6% and 94.44% respectively. When the number of training samples per classis 4 and 5, the top recognition accuracy of (2D)2PCALDA is the highest, 97.22% and 98.61% respectively. On the Feret database, we see that none of the methods achieves top recognition accuracy on all the training samples per class. For example, when the number of training samples per class is 2, the recognition accuracy of (2D)2LDALPP is the highest, (2D)2PCALDA is second, and both of them are higher than the last three methods;however, when the number of training samples per class is 3, the recognition accuracy of (2D)2PCALDA is the highest and (2D)2LDALPP is the second highest.
The attainment count of top recognition accuracy for the five methods on the Feret database is shown in Table 2. Both (2D)2LDALPP and (2D)2PCALDA attain top recognition accuracy twice;(2D)2PCA attains top recognition accuracy once, and neither of the other two methods attains top recognition accuracy. As mentioned above, in regard to recognition accuracy, the performance of (2D)2LDALPP and (2D)2PCALDA is superior to the other three methods on this database. In this experiment, the Feret database is used to test the performance of the face recognition methods in conditions of varied facial expressions and illuminations, so the conclusion is that (2D)2LDALPP and (2D)2PCALDA are more adaptive to a variety of facial expressions and illuminations. Comparing (2D)2LDALPP with (2D)2PCALDA, the former is better when the training number is less, but when the number increases, the latter begins to improve. There are two general characteristics of (2D)2LDALPP and (2D)2PCALDA: both of them are hybrids of two different subspace methods and the supervised learning method.
Comparison of different approaches in terms of top recognition accuracy counts on three databases
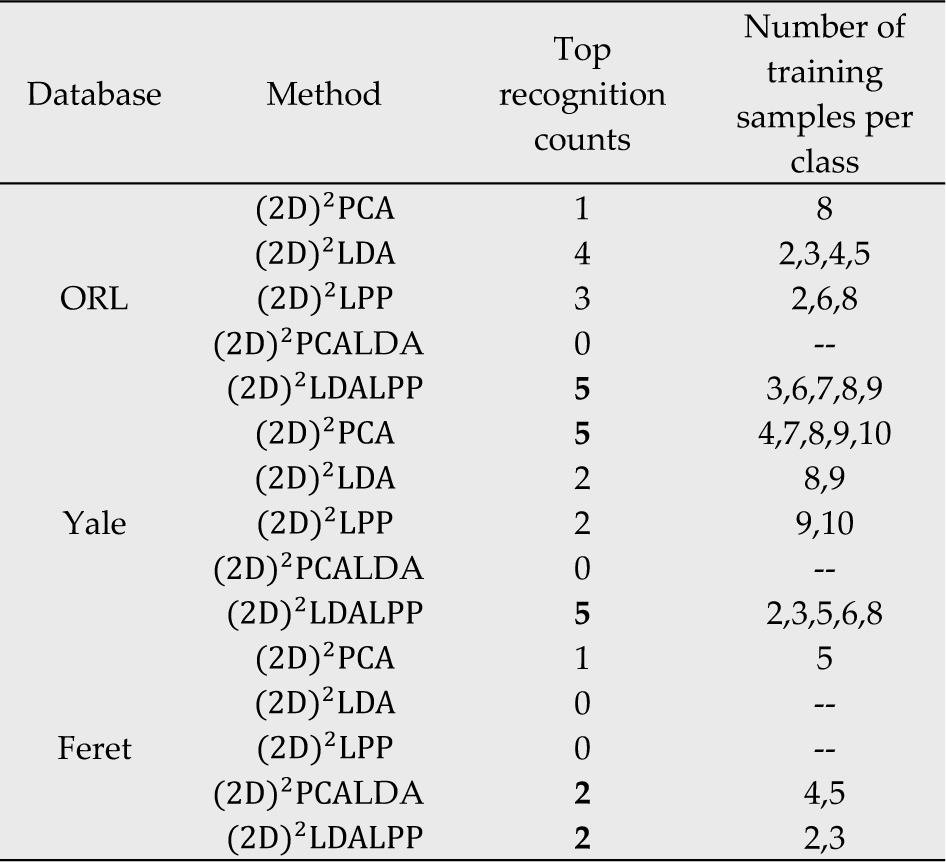
On the ORL database, a random subset with l(=2,3,4,5,6,7,8,9) samples per individual is taken with labels to form the training set. The rest of the database is used as the testing set. The top recognition accuracies are shown in Table 3. From the experiments, the conditions of recognition performance are complicated. The method which attains the top recognition accuracy is different with different numbers of training samples per class. It is found that none of the methods can attain top recognition accuracy all the time. From the statistical data in Table 2, (2D)2LDALPP attains top recognition accuracy five times, with 3,6,7,8 and 9 training samples per class. (2D)2LDA attains top recognition accuracy four times, with 2,3,4 and 5 training samples per class. (2D)2LPP and (2D)2PCA attain top recognition accuracy three times and once respectively. (2D)2PCALDA does not attain top recognition accuracy on this database. Because the ORL database is used to examine the performance of the methods under the condition of minor variations of scaling, rotation, our conclusion is that (2D)2LDALPP is quite adaptive in this condition, while (2D)2PCALDA is the weakest. On this database, the methods containing 2DPCA perform less well than the methods containing 2DLDA and 2DLPP.
Comparison of different approaches in terms of top recognition accuracy (%) on ORL database

On the Yale database, a random subset with l(=2,3,4,5,6,7,8,9) samples per individual is taken with labels to form the training set. The rest of the database is used as the testing set. Table 4 shows the experimental results. It is found that none of the methods achieve top recognition accuracy all the time on this database; however, we can see from Table 2 that (2D)2LDALPP,(2D)2PCALDA and (2D)2PCA attain top recognition accuracy five times, and (2D)2LDA and (2D)2LPP three times and twice respectively. In this experiment, we aim to test the performance of the face recognition methods under conditions of varied facial expressions and illuminations. It can be easily ascertained that (2D)2LDALPP and (2D)2PCA obtain better recognition accuracy compared to the other three methods. Compared with (2D)2PCA, (2D)2LDALPP attains the top recognition accuracy with relatively small training samples per class, which is very common in real face recognition systems. Something else that should be mentioned is that the performance of (2D)2PCA is quite different on the Yale database than on the Feret database. Although the aim with both these databases is to test performance in conditions of varied facial expressions and illuminations, it is revealed that (2D)2PCA is not stable on the Feret database, although it is possibly suitable for varying facial expressions and illuminations.
Comparison of different approaches in terms of top recognition accuracy (%) on Yale database

If we look at the top recognition accuracy together with the three databases, (2D)2LDALPP achieves it 12 times, (2D)2PCA seven times, (2D)2LDA six times, (2D)2LPP five times, while (2D)2PCALDA only reaches it twice. It is obvious that (2D)2LDALPP performs more effectively for face recognition. From the experiments above, we can conclude that, from the point of view of recognition accuracy,(2D)2LDALPP is the best option, having attained the greatest top recognition accuracy on three experimental databases. (2D)2PCALDA shows good performance on Feret but is not stable because of its weakness on the ORL and Yale databases. It does not adapt to the variety of scaling and rotation. It should be noted that (2D)2LDALPP shows superior performance with small training samples and low-dimensional features, and it is feasible in actual application.
4.3 Results on running time
The running times are also compared when the five methods attain top recognition accuracy on the Feret, ORL and Yale databases. The results are shown in Table 5. In this experiment, we select a training number of 6 per class in the ORL and Yale databases, and 2 per class in the Feret database. For each method, we calculate the training time and testing time, and they are displayed in the fourth and fifth columns of Table 5; the total time is the training time plus testing time. In Table 5, the test times of the five methods on each database are similar, while the training times are quite different. It is well known that the decisive factor of testing time is the size of the feature matrix. Because the sizes of the feature matrices are close, the testing times among them is quite similar. The most different training time is that of (2D)2LPP, which is far greater than that of the other methods.
Comparison of different approaches in terms of running time on three databases
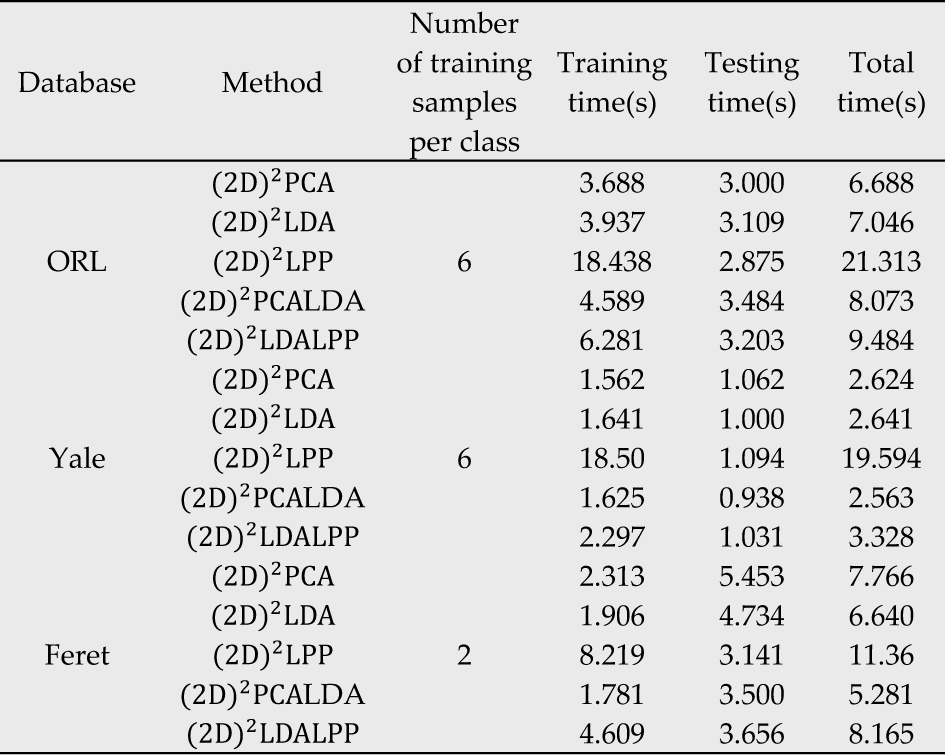
The results can be explained by the complexity of the methods. If the size of the training sample is m × n,d1,d2 and N are the number of the row-projected vectors, the number of the column-projected vectors, and the training number, respectively. The training complexity of (2D)2PCA, (2D)2LDA and (2D)2PCALDA is O(n2d1 + m2d2). The training complexity of (2D)2LPPis O)(n2d1 + mnN2 + m2d2 + nd1N2). The training complexity of (2D)2LDALPPis O(n2d1 + m2d2 + nd1N2). It is obvious that mnN2 is the greatest part of O(n2d1 + mnN2 + m2d2 + nd1N2). We notice also that the training complexity of (2D)2LDALPP is precisely mnN2less than (2D)2LPP. Because m × n is the size of original training sample, it is too big to compute mnN2 directly. For this reason, on a large database it is very difficult to utilize (2D)2LPP directly. Although (2D)2LDALPP is also involved in computing 2DLPP, due to the fact that it firstly utilizes 2DLDA, and reduces the dimension of the image dramatically, the computed matrix is much smaller than (2D)2LPP. As a result, the training time is also less than the latter. Compared with(2D)2PCA, (2D)2LDA and (2D)2PCALDA, the training complexity of (2D)2LDALPP is more than nd1N2. The training time of (2D)2LDALPP is still more than these three methods, and future research should focus on this issue.
5. Conclusion
Dimension reduction is the key problem in face recognition systems. Extracting stable and reliable features for improving recognition accuracy is an important task. Two-dimensional subspace methods can extract the features by keeping the structure of the face image. Two-directional methods can extract features from both the row and column of the image; thus, two-directional two-dimensional methods have become popular in face recognition. In this paper, an efficient two-directionaltwo-dimensional feature extraction method for face recognition called (2D)2LDALPP is proposed. The difference between the proposed method and 2DLPP and 2DLDA is that the former works on both the row direction and column direction of the image, whereas the latter two methods work only in one direction. Compared with (2D)2LDA and (2D)2LPP, the proposed method not only preserves the modified structure of the samples but also contains the label information of the classes, meaning the proposed method is a supervised method and has fewer dimensions of feature matrix. Experimental results show that the performance of the proposed method is effective. Another contribution of this paper is its comparison of the existing two-directional two-dimensional feature extraction methods, and the analysis of their adaptability on the Feret, ORL and Yale databases.
From the experiments, we can draw a number of conclusions:
The performance of differenttwo-directional two-dimensional methods is different according to the variation in training number. None of the methods is superior to other methods in all conditions. The (2D)2LDALPP method appears to be the best with the smaller dimension of the feature matrix. From a statistical standpoint, (2D)2LDALPP performs better than the other methods when the number of the training sample is varied. It is therefore credible that (2D)2LDALPP is more adaptable and robust against a variety of face images. Using hybrid features is an effective way to improve the performance of face recognition systems; however, the compatibility of the features is of primary importance. In our experiments, another hybrid method,(2D)2PCALDA, is not as stable as (2D)2LDALPP. From the experiments and analysis of the complexity of the methods, the running time of (2D)2LDALPP is less than (2D)2LPP but more than(2D)2PCA, (2D)2LDA and(2D)2PCALDA.
It should be noted that the disadvantage of the method is that the training time is longer than some two-directional two-dimensional methods. In our future work, we will study the use of techniques such as the block-wise method to try and solve this problem. Furthermore, the reason why five two-directional two-dimensional subspace analysis methods perform differently when the training number is varied needs to be explained in terms of theory.
Footnotes
6. Acknowledgments
This research was supported bythe National Natural Science Foundation of China (grant no. 51175389) and the Fundamental Research Funds for the Central Universities, China (grant no. 2011-VI-058).
7. Appendix
Notation table

| Notation | Explanation |
|---|---|
| PCA | Principal Component Analysis |
| LDA | Linear Discriminant Analysis |
| LPP | Locality Preserving Projection |
| 2DPCA | Two-Dimensional Principal Component Analysis |
| 2DLDA | Two-Dimensional Linear Discriminant Analysis |
| 2DLPP (2D)2PCA | Two-Dimensional Locality Preserving Projection Two-Directional Two-Dimensional Principal Component Analysis |
| (2D)2LDA | Two-Directional Linear Discriminant Analysis |
| (2D)2LPP | Two-Directional Locality Preserving Projection |
| (2D)2PCALDA | Two-Dimensional Principal Component Analysis plus Two-Dimensional Linear Discriminant Analysis |
| (2D)2PCALPP | Two-Dimensional Principal Component Analysis plus Two-Dimensional Locality Preserving Projection |
| (2D)2LDALPP | Two-Dimensional Linear Discriminant Analysis plus Two-Dimensional Locality Preserving Projection |