
Abstract
This paper presents the development of fuzzy-appearance manifold and fuzzy-nearest distance calculation in the eigenspace domain for pose estimation of degraded face images. In order to obtain a robust pose estimation system which can deal with the fuzziness of face data caused by statistical errors, we proposed the fuzzy-vector representation in eigenspace domain of the face images. Using fuzzy-vector representations, all of the crisp vectors of face data in the eigenspace domain are firstly transformed into fuzzy-vectors as fuzzy-points. Next, the fuzzy-appearance manifold is constructed from all the available fuzzy-points and the fuzzy-nearest distance calculation is proposed as the classifier of the pose estimation system. The pose estimation of an unknown face image is performed by firstly being projected onto the eigenspace domain then transformed to become an unknown fuzzy-point, and its fuzzy-distance with all of the available fuzzy-points in the fuzzy-appearance manifold will be calculated. The fuzzy-point in the manifold which has the nearest distance to that unknown fuzzy-point will be determined as the pose position of the unknown face image. In the experiment, face images with various quality degradation effects were used. The results show that the system could maintain high recognition rates for estimating the pose position of the degraded face images.
1. Introduction
The face recognition problem is very challenging in the development of humanoid robots. It is well-known that the performance of an automatic face recognition system (AFR) decreases significantly when large pose variations are present in the input space [1]. Therefore, various attempts should be made to handle this issue. Automatic face recognition (AFR) has been traditionally associated with the fields of computer science and pattern recognition. Since AFR is considered to be a natural, non-intimidating identification method [2, 3], it has the potential to be the leading biometric technology that can also be applied directly into robotic applications. Unfortunately, it is also one of the most difficult pattern recognition problems.
So far, all existing solutions provide only partial, and usually unsatisfactory, answers to the market needs [4]. There are also other problems in its applications, i.e., when the enrolled individual (the probe) does not wish to cooperate in the process of recognition, which is inevitably desirable in the 3D face recognition system. In the context of face recognition, it is common to distinguish between the problem of verification and that of recognition. In the first case, the probe claims an identity of a person whose template is stored in the database (gallery). We refer to the data used for specific recognition task as a template. The face recognition algorithms are developed by comparing the incoming face image and verify the equivalence with that of in a given template. Such a set up of one-to-one matching can occur when biometric technology is used to secure transactions such as in automatic teller machines. In this verification case, the user is usually assumed to be collaborative by giving a sign as a clue.
The second case is more difficult. Recognition implies that the probe subject should be compared with all the templates stored in the gallery database. The face recognition algorithm should then match a given face image with one of the individuals in the database, or one-to-many matching problem. In this case, no collaboration by the users can be assumed, and if one intentionally wished not to be recognized, one can deceive the AFR system at the current technological level. Three-dimensional face recognition is a relatively recent trend that in some sense breaks the long-term tradition of mimicking the human visual recognition system. Trying to use 3D information, i.e., pose estimation as part of the 3D AFR system, has become an emerging research direction in the hope of making face recognition more accurate and robust, especially for non-collaborative users.
In this paper, we would like to address the problem on estimating the pose of the incoming 3D face image as the required information for recognizing a 3D face in our system. The developed pose estimation system is consists of two subsystems, i.e., eigenspace-feature extraction subsystem and fuzzy-feature pose classification subsystems. In the eigenspace-feature extraction subsystem, a crisp vector as the representation of a face image is projected into the eigenspace domain for dimensionality reduction of the input space. In the fuzzy-feature pose classification, a fuzzy-appearance manifold is proposed, in which an interpolation line is constructed by passing through numerous fuzzy-points that represent the learning images in a fuzzy-feature space. For estimating the pose position of the unknown data test, we also proposed a fuzzy-nearest distance calculation method that will be explained later. The robustness of the pose estimation system is experimentally tested to 3D face images with various degradation effects.
The remainder of this paper is organized as follows. Section 2 describes the related research on the crisp-appearance manifold method and its application as a pose estimation system. Section 3 presents the construction of a fuzzy-vector from the learning images and the construction of the fuzzy-appearance manifold. This section also presents the description of the fuzzy-nearest distance calculation method which acts as a classifier in the proposed pose estimation system. Section 4 illustrates and discusses the performance evaluation of the system in estimating the pose position of the degraded 3D face images, and finally, Section 5 presents our conclusion.
2. Related Studies: Crisp-Appearance Manifold
Researchers take many different approaches to recognize 3D face images using pose information. Earlier methods focused on constructing invariant features [5], synthesizing a prototypical frontal view [6], or classify pose problems [7]. Pose estimation is important when view-based classifiers are trained to recognize a subset of views, since head pose is closely related to human intention and behaviour [8, 9]. Lowe [8] introduced the notion that a partial match of image to model features yields constraints on the position in the image of other features of the model due to rigidity constraints. This was generalized by Gaston et al. [9] and Grimson et al. [10] using the term interpretation tree. A Local Gabor Binary Patterns LGBP method for estimating head pose estimation has been proposed by Ma et al. [11]. Following the popular eigenface approach which was proposed by Turk and Pentland [12], many techniques have been extended to explore recognition in eigenspace.
Generally, the appearance-based approaches deal with a set of learning images taken at predetermined pose positions with various capturing conditions. Since these images are usually high-dimensional images, they cannot be applied directly for reasons of efficiency. Hence, a transformation to the eigenspace domain, in which its dimensionality is much lower than in the original image-space, is usually utilized. A Principal Component Analysis PCA is an efficient transformation procedure to represent a collection by mapping the original n-dimensional space onto a k-dimensional feature subspace where normally k<n.
Recently, researchers improved the previous eigenspace model with the use of an appearance manifold in eigenspace to deal with the pose-invariant problem, or even for estimating the pose position of images. Addressing various problems, many types of appearance manifolds have been developed, such as the crisp-appearance manifold in [13, 14] which could handle pose and illumination variations; the appearance manifold with probabilistic techniques [15, 16] for handling various facial changes; the layer-transparent manifold in [17] for recognizing occluded objects, etc.
In the crisp-appearance manifold, after transforming the learning images onto eigenspace, the manifold of the face is constructed by interpolating the mean vector of the training as the crisp-points. Practically, the manifold can be constructed simply by applying an interpolation method between training images in two consecutive poses (crisp-points), i.e., linear or quadratic (spline) interpolation technique. However, this crisp-appearance manifold approach only works well when the input images have no degraded effects. Unfortunately, this assumption is not realistic in real-world applications. Some degradation effects usually occur and contaminate the original images during the capturing process, hence relying on a crisp-appearance manifold to handle this problem is not sufficient.
3. Fuzzy-Appearance Manifold and Fuzzy-Nearest Distance Calculation
This section describes the process of constructing the fuzzy-appearance manifold of all data in the gallery by firstly transforming them into fuzzy-vectors in a fuzzy-feature space. As in real applications of the pose estimation system, variations in camera-captured images usually occurred naturally. Those variations might occurred during the capturing process, for example, the changing appearance of image due to illumination conditions, noise and degrading images due to data communication procedures.
In a conventional pose estimation system, an image is represented in an array of crisp vectors. Previously, however, results on pose estimations with crisp vector representation for 3D face images showed that the recognition rate of the crisp-appearance manifold system is very low, i.e., about 30% on average [18]. To increase the recognition capability of this system, we proposed a fuzzy-vector representation instead of a crisp vector representation.
As stated earlier, the 3D pose estimation system consists of an eigenspace-feature extraction subsystem and a fuzzy-feature pose classification subsystem. This fuzzy-feature pose classification subsystem can be divided further into two parts, i.e., the construction of the fuzzy-appearance manifold and the fuzzy-nearest distance calculation method. In this section we will explain the construction of the fuzzy-appearance manifold model and the fuzzy-nearest distance calculation. The basic idea of constructing the fuzzy-appearance manifold model is accomplished through two steps, i.e., the construction of fuzzy points from 3D face images, and the construction of a fuzzy-appearance manifold that connects all the available fuzzy points. As the developed pose estimation system used the fuzzy-vector calculation technique, the images that will be used to estimate pose position should also be represented in the fuzzy-number and fuzzy-vector instead of the crisp-number and crisp-vector.
4. Construction Process of Fuzzy-Vector Representation for 3D Face Images
Suppose the learning data of a single 3D image in the learning stage is designated as a single crisp-vector x̄ k the eigenspace domain. For the purpose of fuzzification, the data images of a person taken with different expressions and illumination conditions in a single pose position are grouped into one set of crisp-vectors. For each of these crisp-vectors data sets, we calculate the minimum value (l), the average value (c) and the maximum value (r) at each dimension. Then, using those values, a fuzzy-vector of an image in each pose position can be determined as a normalized triangular fuzzy-vector x̄ k , with the average value determined as the centre position, the minimum value as the left position and the maximum value as the right position.
Let vector
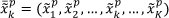
where k =1,2,…, K the number of the eigen vector in the eigenspace domain and p = 1,2,…, P the pose position of the image. The fuzzy-number x̄pk can be expressed by

with xpkl the left part fuzziness as the minimum value, xpkc the centre-peak position as the average value and xpkr the right part fuzziness as the maximum value of x̄pk. Please note that these values are calculated based on 80 images, taken from 20 persons with four different expressions.
In its application, suppose an image of a probe person with unknown expression and under uncontrolled illumination condition is already projected onto the eigenspace domain, as a crisp-vector ȳ
k
and fetched to the system for estimating its pose position. Please note that the index x is for the input vector on the training stage, while the index y is for input vector on the application stage. This crisp-vector ȳ
k
shall be firstly transformed into a triangular fuzzy-vector
5. Construction Process of Fuzzy-Appearance Manifold in Fuzzy-Feature Space
Suppose a set of crisp-vectors in the eigenspace domain x̄
k
is already transformed into its fuzzy-vector
Linear Interpolation Fuzzy-manifold: linear interpolation is the most simple interpolation method, yet it produces reliable results in some experiments. Suppose we have two fuzzy-points

with t a constant increment for a linear interpolation curve.
Quadratic (Bezier Spline) Interpolation Fuzzy-manifold: Bezier curves were first publicized in 1962 by the French engineer Pierre Bezier. Bezier curves have many variations, depending on the number of the used control point. In this paper, we adopted the Bezier spline (quadratic line) interpolation method, due to its simplicity and lower computational cost.
The construction of the quadratic (Bezier spline) fuzzy-manifold can be explained as follows. Suppose we have three fuzzy-points
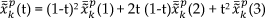
with t a constant increment which determines how far
6. Fuzzy-vector Nearest-Distance Calculation
Suppose we have already constructed the fuzzy-appearance manifolds using both the fuzzy-linear and the fuzzy-quadratic (spline) interpolation methods. Suppose there is an unknown-pose image of a person with unknown expression and illumination conditions, which have been transformed from an original crisp-vector ȳ
k
into a triangular fuzzy-vector
Let

with fuzzy-number ȳ k which can be expressed by:

where ykl the left part fuzziness, ykc the centre-peak position and ykr the right part fuzziness of y˜k. Suppose
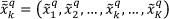
with q = 1,2,…, Q the number of the fuzzy reference points in the manifold is greater than p = 1,2,…, P, the number of the fuzzy reference points in the learning stage. The interval of the fuzzy-points in the fuzzy-appearance manifold could be determined as needed, and in our case a 10 interval is used, so that the number of the reference points Q is 180, while P = 7 in the Data Set 1 and P = 13 in the Data Set 2. The triangular fuzzy-number x˜kK can also be expressed as:

To determine the pose estimation of an unknown ȳ
k
crisp-vector that is already projected onto the eigenspace domain, the ȳ
k
is firstly transformed into a fuzzy-vector
The subtraction between two fuzzy-points, i.e.,

with crisp number zqk which can be expressed by:

The fuzzy-distance between the two fuzzy-points is then a scalar crisp-value

The illustration of the fuzzy-distance calculation can be seen in Figure 1.
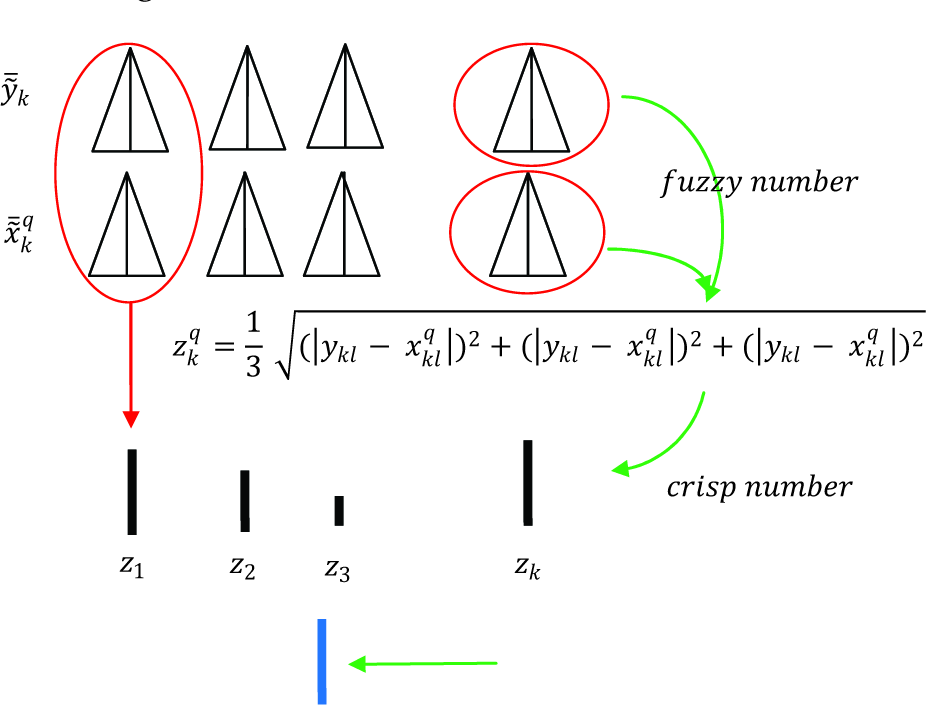
Distance calculation of the fuzzy-point
7. Experimental Set-Up and Its Results
To evaluate the performance of our developed methods, we have tested our system on estimating the 3D face images using the University of Indonesia Computational Intelligence Lab (UICIL) database. The database contains images of 20 Indonesian persons with 26 horizontal-pose positions (−900 to +900 with 50 interval) with four different expressions (neutral, angry, laugh and smile). The images were reduced to a 30 pixels × 30 pixels with greyscale colour type. Samples of 3D face images we used in the experiments are presented in Figure 2.

Example of the learning images used in the experiments

Example of the degraded testing images (a) original (b) Gaussian noise addition (c) Poisson noise addition (d) salt and pepper noise addition and (e) speckle noise addition
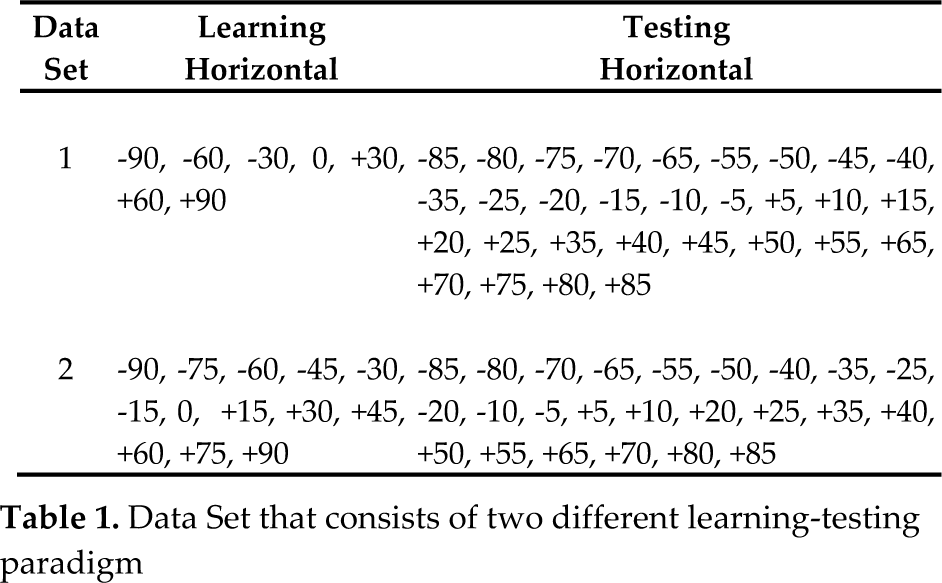
In the overall experiments, the construction of the fuzzy-appearance manifold in the learning process was accomplished using face images without noise addition, while the testing images were the images which have been contaminated with noise distortions. The training/testing paradigms in the experiments are shown in Table 1. The fuzzy-appearance manifold based on Dataset 1, was developed using 7 fuzzy-points, with training/testing paradigm of 19%:81%, while for Dataset 2 the fuzzy-appearance manifold was constructed based on 13 fuzzy-points, with training/testing paradigm of 35%:65%, respectively. Please note that the additional fuzzy-points were generated at each 10, so that the total number of the fuzzy-points was up to 180.
Data Set that consists of two different learning-testing paradigm
The results of the experiments are shown in Table 2 and Table 3, respectively. It should be noted that the error tolerance for horizontal pose estimation is 20, meaning that if the system estimated that the unknown pose is 170, for example, since we have no such pose position, then it is determined to be 150 in accordance with the real pose in the database. Table 2 shows the recognition rates and its comparison for both the fuzzy-appearance manifold and the crisp-appearance manifold using Dataset 1. While Table 3 shows the recognition rates for experiments using Dataset 2.
Recognition rates comparison of fuzzy-appearance manifold and crisp-appearance manifold for Dataset 1

Recognition rates comparison of fuzzy-appearance manifold and crisp-appearance manifold for Dataset 2

As can be clearly seen in Table 2 and also in Table 3, the recognition rates using the fuzzy-appearance manifold with linear interpolation are always higher than that of the quadratic method. The possible reason for this is because the fuzzy manifold with linear interpolation is interpolated in a more continuous form, since it is constructed based on two fuzzy-points. Meanwhile, in the quadratic interpolation method, the fuzzy-manifold is constructed based on three fuzzy-points, which sometimes missed the second fuzzy-point while making a continuous line between those three consecutive fuzzy-points. Concerning the addition of various forms of noises into the testing images, the recognition rates of the fuzzy-manifold were not decreased, showing that the fuzzy-appearance manifold is robust to noise disturbances. Meanwhile, the recognition rate of the crisp-appearance manifold was very low, almost around 30%. Even though the recognition rates were not decreased also with the noise additions to the testing images, the truth decision was very low in order to draw a direct very low for having a direct conclusion about this phenomenon.
It can also clearly be seen in Table 3 that increasing the number of known fuzzy-points P, as experimentally
conducted using Dataset 2, increased the recognition rates of the system. Moreover, with the same phenomena using Dataset 1, the fuzzy-appearance manifold using linear interpolation method shows a higher recognition rate compared with that of the quadratic interpolation.
8. Conclusion
We have developed a method for constructing a fuzzy-appearance manifold using line interpolation and quadratic interpolation methods in a fuzzy-vector representation. This fuzzy-manifold interpolates the fuzzy-vectors of 3D face images in the fuzzy-feature space, and used this for estimating the pose position of the incoming 3D face images with unknown pose and unknown persons. We have also developed a fuzzy-nearest distance calculation method to determine the pose position of those incoming images.
We have tested our algorithms using two datasets with various numbers of training and testing percentages. It is shown in the experimental results that the proposed algorithms show high recognition accuracies for estimating poses of 3D face images, even for face images of unknown pose positions of unknown persons. It is clearly shown that the fuzzy-manifolds using the linear interpolation methods outperformed the fuzzy-manifolds with the Bezier spline method in all aspects of experimental datasets. It is also shown that our proposed methods have high recognition capabilities for estimating pose positions of 3D images with various degradation effects. The results show that the addition of various types of noises into the face images did not decrease the recognition rates of the system.
Footnotes
9. Acknowledgement
This research is funded by Ministry of National Education and Culture of Indonesia, through International Publication and Research Collaboration Programme. The first author would like to extend his gratitude to University of Indonesia Research Programme for funding the equipment and for providing other funds used during the research activities.