
Abstract
Finite-state transducers are frequently used for pronunciation lexicon representations in speech engines, in which memory and processing resources are scarce. This paper proposes two possibilities for further reducing the memory footprint of finite-state transducers representing pronunciation lexicons. First, different alignments of grapheme and allophone transcriptions are studied and a reduction in the number of states of up to 30% is reported. Second, a combination of grapheme-to-allophone rules with a finite-state transducer is proposed, which yields a 65% smaller finite-state transducer than conventional approaches.
1. Introduction
An ongoing challenge in human-robot interaction is to design efficient speech engines for natural human-robot communication [1, 2].
Consistent and accurate determination of word pronunciation is critical to the success of many speech technology applications. Most state-of-the-art speech engines performing automatic speech recognition (ASR) and text-to-speech synthesis (TTS) rely on lexicons, which contain pronunciation information for many words. To provide maximum coverage of the words, multiword expressions, or even phrases that commonly occur in a given application domain, application-specific words, or phrase pronunciations may be required, especially for application-specific proper nouns such as personal names or names of locations.
Pronunciation lexicons for speech engines contain grapheme and allophone transcription of lexical words. The “x-sampa-SI-reduced” phonetic alphabet, a subset of the X-SAMPA set as defined for Slovenian [3], is used in allophone transcriptions. An example of a pronunciation lexicon for a few Slovenian words is shown in Figure 1.

An excerpt from a Slovenian pronunciation lexicon
The storage and run-time processing of pronunciation lexicons is memory consuming, especially for highly inflected languages, where pronunciation lexicons typically contain over one million lexical items.
In some systems with limited memory resources—for example, in speech engines for embedded systems or multilingual speech engines used in spoken-oriented human-robot dialogue systems [4, 5]—using large pronunciation lexicons is not feasible [6]. In addition, the search time in such lexicons may be long if the lexicons are too large to be stored in the main memory or cache. Therefore, memory-efficient representations of pronunciation lexicons enabling fast lookup are mandatory in order to address these limitations. Another disadvantage of inefficient lexicon representation is the unnecessary use of system resources.
State-of-the-art pronunciation lexicon representation techniques used in speech engines are based on structures called finite-state automata (FSA) as in [7] and finite-state transducers (FSTs) [8, 9]; very similar structures are also called tries [10]. All these techniques with the exception of [8] focus on a compact and memory-efficient implementation of the FSA/FST/trie structure representing the pronunciation lexicon. On the other hand, the technique presented in [8] produces an FST with a very small number of states but a large number of transitions in comparison with other techniques, thus it is less appropriate for compact representation in systems with limited memory resources.
This paper discusses new possibilities for reducing the size of pronunciation lexicon representation using FSTs. We report the results of experimenting with different alignments of grapheme and allophone transcriptions of the lexical items, thus changing the FST input and output alphabet. In the second experiment we report encouraging results that were obtained by removing redundant information from the allophone transcription prior to building the FST. Both approaches directly change the resulting minimized and determinized FST, thus enabling further compression with other state-of-the-art techniques in the implementation phase [7].
2. FST representations of pronunciation lexicons
An FST differs from an FSA in that when it accepts a symbol it also outputs another symbol. In this way it can translate an input string into an output string. An example of an FST representing a simple pronunciation lexicon from Table 1 is shown in Figure 2.
Pronunciation lexicon with three lexical items


An FST representing a simple pronunciation lexicon from the example in Table 1. By convention, the states are represented as circles and marked with their unique number. The initial state is represented by a bold circle and final states by double circles. An input label i and an output label o are marked on the corresponding directed arc as i: o
An FST is defined as 6-tuple (Σ, Γ, Q, q0, F, δ), where:
Σ = finite, non empty set of input symbols Γ = finite, non empty set of output symbols Q = finite, non empty set of states q0 = initial state, q0 ∈ Q F = set of final states, F ⊆ Q δ = transition function, which can be represented with equation 1:

Every state has a finite number of transitions to other states. Every transition is labelled with an input and output symbol. At the beginning, the FST is in its initial state. For every symbol in the input string, the FST changes its state according to the transition function and emits an output symbol. If it moves to a final state when it accepts all the symbols of the input string, we say that it has accepted the input string. At that moment the output string, which is composed of all the emitted symbols, becomes valid.
Many efficient algorithms have been developed for FSTs [11], such as union, concatenation, intersection, determinization, minimization, and so on. When using minimization and determinization, the FST becomes a very convenient representation of pronunciation lexicons [12–14]. If one excludes all heteronyms (words with the same spelling but different pronunciations), all acyclic FSTs representing pronunciation lexicons can be determinized [15], and therefore acyclic FSTs are frequently used for pronunciation lexicon representations in speech engines. For representing heteronyms, p-subsequential FSTs can be used [16]. For deterministic FSTs, the existence of a minimal FST has been proven [17]. Hereinafter we denote a minimized and determinized FST as MDFST. Minimization of an FST transforms the FST into an equivalent FST with a minimal number of states. A MDFST also exhibits a minimal number of transitions [18]. The two deterministic FSTs are said to be equivalent if for every sequence of input symbols they generate the same sequence of output symbols.
Table 2 shows the reduction of the number of states by minimization and determinization for the SI-Pron Slovenian pronunciation dictionary containing 1,239,401 lexical items.
Comparison of the number of states and transitions of FST and MDFST representing the SI-Pron pronunciation lexicon
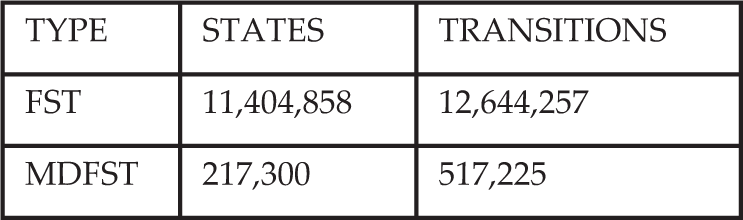
The FST in Figure 2 shows that there are three possible transitions from the initial state with the same input symbols. In a deterministic FST there is no state with more than one transition with the same input symbol. The advantage of a deterministic FST is lookup speed, which is linearly dependent only on the length of the input string and not dependent on the size of the FST.
In Figure 3 an equivalent FST to the one from Figure 2 is shown, which has been both determinized and minimized (MDFST).

Minimized and determinized FST from Figure 2: MDFST
3. Grapheme-to-allophone string alignment
When building an FST from a pronunciation lexicon, it is necessary to define which output symbols are emitted for the input symbols. This is called alignment of the grapheme and allophone transcription.
There are multiple ways to align the two transcriptions by changing the input/output symbol set. For example, another possible alignment of the pronunciation lexicon from Table 1 would produce the FST in Figure 4.

An alternative alignment of the pronunciation lexicon produces a different FST in comparison to Figure 2
Figure 5 shows that some symbols in the grapheme and allophone transcriptions have been grouped together. These new groups of symbols can be represented by new symbols. The input and output alphabet of the FST are thereby changed and consequently the FST has changed. This new FST has a different equivalent MDFST, with a possibly smaller number of states and transitions. The mappings between the groups of symbols and the new symbols need to be recorded.

The MDFST for alternative alignment from Figure 4
If the alignments are completely arbitrary, the number of possible alignment variations is large and it is unfeasible to test which alignment produces the FST with a minimal number of states. Such arbitrary alignments that do not obey any specific rules would probably introduce many new symbols that would be impractical to keep track of. A better option is to calculate the alignments with respect to some statistical properties or rules that reflect the nature of the given data. Below we discuss two different ways to align the data.
3.1 One-to-one alignment
The most straightforward is the alignment of one grapheme to one allophone; this is known as one-to-one alignment [19]. However, the number of graphemes in the word and the number of its allophones is not always the same. In some words multiple graphemes map to a single allophone, and vice versa. Therefore it is necessary to introduce a new empty symbol that we will call epsilon. For the sake of simplicity, this is the most common means of alignment of graphemes and allophones before building the FST because the input and output alphabets simply include all the graphemes and all the allophones in addition to epsilon.
3.2 Many-to-many alignment
Recently, an efficient open source tool has been developed for many-to-many alignment: the m2m aligner [20], which makes it possible to align more than one grapheme to more than one allophone. By defining some constraints such as the maximum number of grouped graphemes or allophones, it is possible to provide different alignments. Experiments in building FSTs using one-to-one and many-to-many alignments are discussed in Section 5.
4. Language resources
This paper reports results for pronunciation lexicons for three languages belonging to different language groups: Slavic, Germanic and Romance.
For the Slavic language group, we used the Slovenian SI-Pron pronunciation lexicon containing 1,239,410 lexical entries [21]. For the Germanic language group we used the freely available CMU-US pronunciation lexicon for North American English (The Carnegie Mellon Pronouncing Dictionary) with 133,720 lexical entries. For the Romance language group we used the Italian pronunciation lexicon FST-IT, taken from the Festival TTS toolkit, which contains 402,962 lexical entries.
All three lexicons contain grapheme and allophone transcriptions for all lexical entries. The SI-Pron pronunciation lexicon contains additional information such as syllabification, morphological information and stress positions. It is also possible to extract stress information from the CMU-US pronunciation lexicon. Table 3 shows some statistical properties of these lexicons.
Statistical properties of the three chosen pronunciation lexicons

Slovenian and Italian are both highly inflected languages, which is reflected in the number of lexical entries. No homographs (words with the same spelling but different meaning) are included in any of the pronunciation lexicons described.
5. Experiments and results
5.1 Impact of different alignments
We studied the impact of different alignments of grapheme and allophone transcription on the number of states and transitions of an MDFST representing a pronunciation lexicon. We used three different pronunciation dictionaries for Slovenian, English and Italian, as described in the previous section. The m2m-aligner tool was used to derive the grapheme and allophone transcription alignments. This tool is capable of aligning one or many graphemes to one or many allophones. It is possible to constrain the maximum number of graphemes and allophones grouped together. For building the FST from the aligned data and its determinization and minimization to the MDFST, the OpenFST [11] tool was used. The algorithms for minimization and determinization used by the tool are explained in [18, 22].
In the first experiment, the data were aligned with the m2m-aligner using four different constraints. Table 4 defines all the alignments tested along with constraints imposed on the various alignment variations.
Alignment constraints on the maximum number of graphemes or allophones grouped together for four different alignment variations: a11 to a22

MDFSTs were built for all defined alignments and all available lexical resources. Table 5 shows the number of states and transitions for all the corresponding MDFSTs. It also shows the numbers of input and output symbols of the input and output alphabets of the MDFSTs.
Number of states, transitions, input symbols and output symbols for different alignments for all available lexical language resources. The leading results for every lexicon are in bold
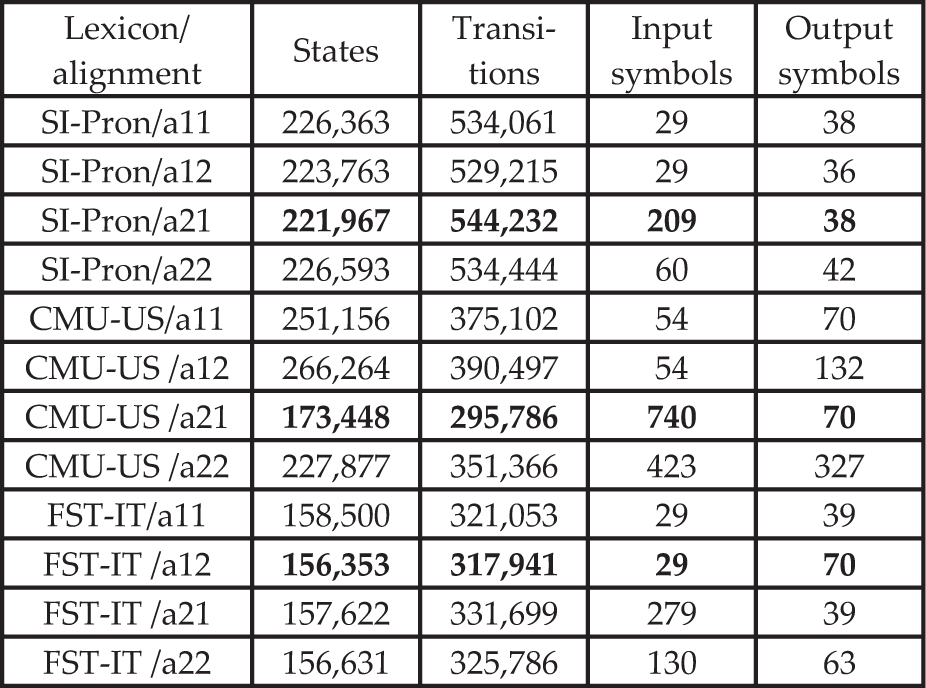
Let alignment a11 be the baseline alignment. The results in Table 5 show that the alignments that lead to the highest reduction of the number states were a21 for SI-Pron (-1.9%) and CMU (-30.9%), and a12 for FST-IT (-1.4%). The results show that the reduction of the number of states for a specific alignment is different for every lexicon. To examine the consistency of the reduction of states for a specific lexicon, we repeated the experiment with different sizes of the same lexicon. The smaller lexicons were built by random selection of lexical entries from the original lexicon.
The results are shown in Figure 6, 7 and 8 as the relative deviation of the number of states from the baseline alignment a11. The relative deviation of the number of states differs little for various lexicon sizes for all the pronunciation lexicons. Slightly higher deviations can be detected only for the CMU-US lexicon (Figures 6 and 8), which is also the smallest lexicon used.

Relative deviation of the number of states for alignment a12 compared to the baseline alignment a11 for different sizes of lexicons
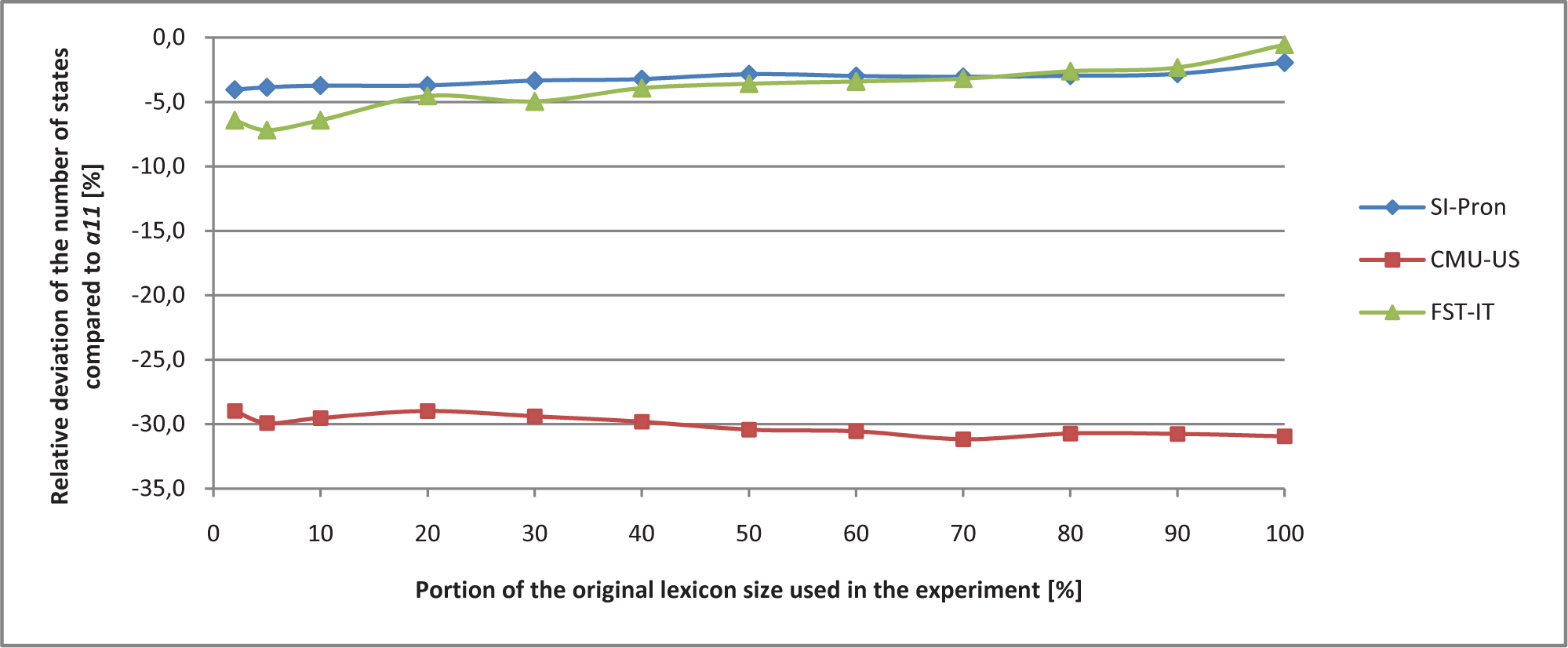
Relative deviation of the number of states for alignment a21 compared to the baseline alignment a11 for different sizes of lexicons

Relative deviation of the number of states for alignment a22 compared to the baseline alignment a11 for different sizes of lexicons
6. Combining grapheme-to-allophone rules and FST
It has been reported that for Slovenian it is possible to achieve a grapheme-to-allophone transcription accuracy of 99.1% by using a set of context-dependent rules if the stress position and the transcription of the graphemes e and o in stressed syllables are known in advance [23].
The idea of the following experiment is to remove all unnecessary information from the pronunciation lexicon and to model the information left with a simpler and possibly lighter FST.
The potential of this approach becomes clearer if one recalls the basic principle of FST minimization. When minimizing an FST, equivalent states are merged. Equivalent states are those that have transitions with the same input and output symbols targeting the same or equivalent states.
According to [23], the necessary information for reconstructing the allophone transcription from the grapheme transcription in Slovenian is the lexical stress position and the transcriptions of the graphemes e and o in stressed syllables, which we were able to model with only three different symbols in the FST output alphabet. This highly reduced number of different output symbols offers more possibilities for the state transitions to have equal input and output symbols, and a greater chance for the possible states to merge.
In this experiment we built an FST representing the pronunciation lexicon emitting information containing only the stress position and the transcription variation of graphemes e and o in stressed syllables.
In Slovenian, when words of foreign origin are included, the six graphemic vowels a, e, i, o, u and y, along with the reduced vowel schwa @, can be stressed. A lexical item can have multiple lexical stress positions.
The lexical stress position can be modelled implicitly with an FST if, for every accepted grapheme, it emits information on whether it is stressed or unstressed. The reduced vowel @ is not part of the grapheme symbol set. It appears in allophone transcriptions before the consonant r when preceded and followed by a consonant (e.g., potrt → pOt@”rt, prvi → p@”rvi). Therefore, if the reduced vowel @ is stressed, the FST outputs the information about stress when it accepts the consonant r.
The allophone transcriptions of the stressed vowels e and o can be either close e: and o: or open E: and O:. To model this information, for every accepted vowel e or o, the FST has to emit information on whether the vowel is unstressed, stressed open or stressed close. Therefore, there are three possible output symbols.
Table 7 shows the possible output symbols of the FST if we group both the stress and the transcription of the graphemes e and o into one model. Table 8 shows an alternative grouping.
Modelling the FST information output for stress position and the grapheme e and o transcription. Stressed vowels e and o with open transcriptions are grouped with other stressed vowels
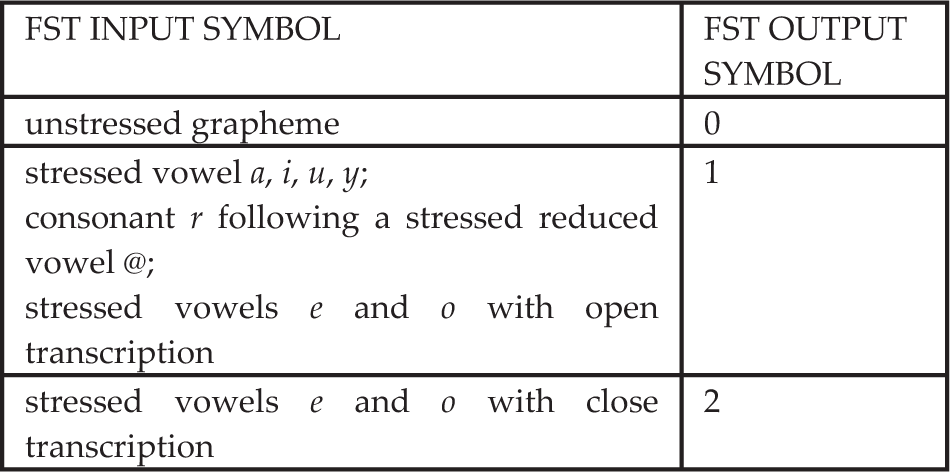
Modelling the FST information output for stress position and the grapheme e and o transcription. Stressed vowels e and o with close transcriptions are grouped with other stressed vowels

The first two temporary lexicons were constructed for the SI-Pron pronunciation lexicon based on the mappings from Tables 7 and 8. These two lexicons represented the alignments of the symbols (graphemes) in input strings and symbols (numbers) in output strings. Then we built the MDFST from these temporary lexicons using the OpenFST tool.
Tables 7 and 8 represent two possible mappings between FST input and output symbols. Table 9 shows a few examples of FST input and output strings derived from the mapping presented in Table 7 for a few Slovenian words.
FST output strings for three Slovenian words (medved, prvi, roža) and their complete allophone transcription in the last column

Table 10 shows the comparison between different approaches. The results in Table 10 show a considerable 65% reduction in the number of states (using the mapping from Table 8) compared to MDFST storing the complete allophone transcription.
Comparison between different approaches to representing the information in the SI-Pron pronunciation lexicon with FST. The finite-state acceptor (FSA) stores the information when the specific input string is valid. It represents the lower bound of the number of states of the FST with the same input alphabet and accepting the same language

We also compared the sizes (in MB) of different data structures representing the information stored in pronunciation lexicons. We disregarded the sizes of program code that are necessary to manipulate the data structures because, if implemented properly, they are negligible in size in comparison to the data structures.
The SI-Pron lexicon as UTF8 encoded text represents the baseline and 100% size. We used the OpenFST tool to build a MDFST representing the complete lexicon information and an MDFST representing only the necessary information for rule-based grapheme-to-allophone conversion as described above.
Additional memory footprint reduction was achieved by deriving a compact representation of the FST using the implementation methods that have previously been proposed for FSAs [7]. It is interesting to compare the lexicon reduction techniques used to standard methods used in text compression, such as zip, even though standard text compression methods are not useful for solving our problem because their data have to be decompressed completely to their full size before they can be used. The results are shown in Table 11.
Size of data structures representing information in the SI-Pron pronunciation lexicon
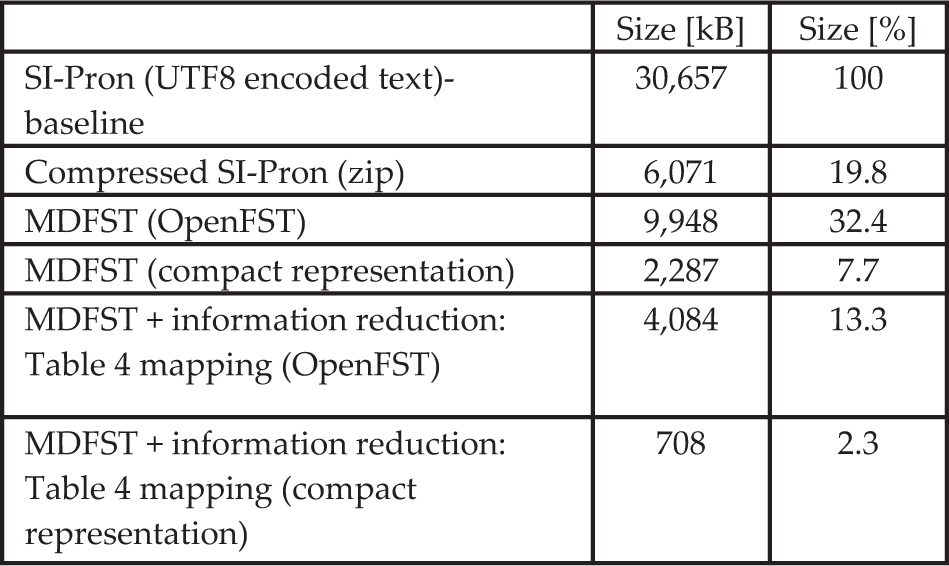
In its compact form, the MDFST structure representing the reduced information of the SI-Pron pronunciation lexicon is over 40 times smaller than the original UTF8-encoded text representation as seen in Table 11. It is also three times smaller than the MDFST representing the complete allophone transcription.
7. Discussion
We have studied the potential of finding smaller MDFSTs for representing pronunciation lexicons while changing the input and output alphabets of the FST with different many-to-many alignments of grapheme and allophone transcription. The results (Figures 6–8) show that the greatest reduction in the number of states for two out of three pronunciation lexicons is achieved using the a21 alignment, whereas for the a12 alignment with the CMU-US lexicon the number of states even increased in comparison to the a11 alignment. For the CMU-US lexicon and a21 alignment, the reduction of the number of states was 30%, which is promising, whereas for other lexicons the reduction was significantly lower. One explanation would be that the other two lexicons represent highly inflected languages.
Additional experiments with lexicons for other languages with more and less rich morphology should be performed to support this claim. An additional drawback when changing the input and output alphabet of the FST is that we have to keep track of the newly introduced symbols. The alphabet for CMU-US with the a21 alignment has 740 input symbols, whereas the equivalent a11 alignment alphabet consists of 54 input symbols only (Table 5). The increase in the number of input symbols is considerable, but keeping track of them is negligible in comparison to the benefit of saving memory space by reducing the number of states in the FST.
In the second experiment, all the information that can be reconstructed with a set of context-dependent rules was removed from the allophone transcription in the Slovenian pronunciation lexicon. By building the MDFST for the new lexicon, we succeeded in significantly reducing the number of states by 65% (Table 10) and in achieving an implementation over three times smaller (Table 11). The proposed method can be used for efficiently representing Slovenian pronunciation lexicon resources; the use of a similar principle could also be considered for other languages with similar pronunciation properties.
8. Conclusion
Finite-state transducers are frequently used for pronunciation lexicon representations in speech engines, in which memory and processing resources are scarce. Two possibilities for further memory footprint reduction of finite-state transducers representing pronunciation lexicons were proposed in the paper. First, different alignments of grapheme and allophone transcriptions were studied and an up to 30% reduction in the number of states was achieved. Second, a combination of grapheme-to-allophone rules with an FST yielded a 65% smaller finite-state transducer than conventional approaches. The proposed method can be used for efficiently representing Slovenian pronunciation lexicon resources; it should also be tested for other languages with similar pronunciation properties.
Footnotes
9. Acknowledgements
The research work by the first author was partially financed by the European Union, European Social Fund, the framework of the Operational Programme for Human Resources Development for the Period 2007–2013 under contract no. P-MR-10/94.