
Abstract
Recent applications and developments based on support vector machines (SVMs) have shown that using multiple kernels instead of a single one can enhance classifier performance. However, there are few reports on performance of the kernel-based Fisher discriminant analysis (kernel-based FDA) method with multiple kernels. This paper proposes a multiple kernel construction method for kernel-based FDA. The constructed kernel is a linear combination of several base kernels with a constraint on their weights. By maximizing the margin maximization criterion (MMC), we present an iterative scheme for weight optimization. The experiments on the FERET and CMU PIE face databases show that, our multiple kernel Fisher discriminant analysis (MKFD) achieves high recognition performance, compared with single-kernel-based FDA. The experiments also show that the constructed kernel relaxes parameter selection for kernel-based FDA to some extent.
Keywords
1. Introduction
As there exist many image variations such as pose, illumination and facial expression, face recognition is a highly complex and nonlinear problem which could not be sufficiently handled by linear methods, such as principal components analysis (PCA) [1] and Fisher discriminant analysis (FDA) [2]. Therefore, it is reasonable to assume that a better solution to this inherent nonlinear problem could be achieved using nonlinear methods, such as the so-called kernel machine techniques [3]. Following the success of applying the kernel trick in SVMs, many kernel-based PCA and FDA methods have been developed and applied in pattern recognition tasks, such as kernel PCA (KPCA) [4], kernel Fisher discriminant (KFD) [5], generalized discriminant analysis (GDA) [6], and kernel direct FDA (KDDA) [7].
It has been shown that the kernel-based FDA method is a feasible approach to solve the nonlinear problems in face recognition. However, the performance of the kernel-based FDA method is sensitive to the selection of a kernel function and its parameters. Kernel parameter selection to date can mainly be achieved by Cross Validation [8], which is computationally expensive, and the selected kernel parameters can not be guaranteed optimal. Furthermore, a single and fixed kernel can only characterize the geometrical structure of some aspects for the input data and, thus, not always be fit for the applications which involve data from multiple, heterogeneous sources [9][10], such as face images under broad variations of pose, illumination, facial expression, aging, etc.
Recent applications and developments based on SVMs [11][12] have shown that using multiple kernels (i.e., a combination of several “base kernels”) instead of a single fixed one can enhance classifier performance, which raised the so-called multiple kernel learning (MKL) method. With m kernels, input data can be mapped into m feature spaces, where each feature space can be taken as one view of the original input data [10]. Each view is expected to exhibit some geometrical structures of the original data from its own perspective such that all the views can complement for the subsequent learning task. It has been proven that MKL can offer some needed flexibility and well manipulate the case that involves multiple, heterogeneous data sources [9][13][14]. However, MKL is proposed for SVMs, and there have been few reports on performance of the kernel-based FDA method with multiple kernels.
In this paper, we propose multiple kernel Fisher discriminant analysis (MKFD), in which the constructed kernel is a linear combination of several base kernels with a constraint on their weights, and we give an iterative scheme for weight optimization.
The rest of this paper is organized as follows. First we describe the kernel construction for MKFD in section 2. Then in section 3, the optimization scheme for the multi-kernel weights is presented. The experimental results are reported in section 4, while we draw our conclusion in section 5.
2. Kernel construction for MKFD
Given M Mercer kernel functions k(m)

where γ2
m
is the weight of base k(m)
We apply the multiple kernel function (1) in kernel-based FDA, which produces what we call MKFD. To achieve good performance of MKFD for face recognition, we consider the problem of learning proper weights of the base kernels, i.e., choosing the best γ = {γ1, γ2,…,γ M )T, without regard to the specific structures of base kernel functions.
3. Weight optimization for MKFD
3.1 Some notations on MKFD
Let 𝕏 ⊂ ℝ
d
be the original sample space. Let X be a training set of N samples and C be the number of sample classes. Assume the i th class Xi contains Ni samples, i.e.,
Denote M nonlinear mappings as

where
Given γ = (γ1, γ2,…,γ) subject to σ M m=1γm = 1, N × N multiple kernel matrix is

We call the mapping from 𝕏 to
Under multiple nonlinear mapping φ, the i th mapped class and the mapped sample set are respectively given by

Also, the mean of the mapped class φ(Xi) and that of the mapped sample set φ(X) are respectively given by
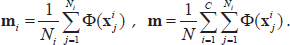
In kernel feature space 𝕏, the within-class scatter matrix


Where
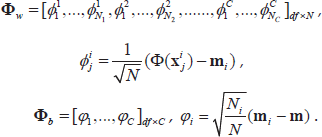
The kernel Fisher criterion is defined as

where
3.2 Diagonalization strategy
We use the same diagonalization strategy as KDDA [7] to deal with the small sample size (SSS) problem in our MKFD, i.e., first diagonalzing
3.2.1 Eigen-analysis of S Φ
w
in the feature space.
ΦT
b
can be expressed using the multiple kernel matrix

where
Let λ
i
and
3.2.2 Eigen-analysis of S Φ
w
in the feature space
Based on the analysis in section

where
Let
Based on the derivation presented in section
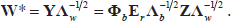
Certainly, as the multiple nonlinear mapping φ is implicitly defined by the multiple kernel function (or matrix), φ
b
(defined by Eq. (6)) remains unknown, and
3.3 Optimization criterion and objective
We adopt the maximum margin criterion (MMC) [15] as the objective function to optimize weight γ:

where W is a projection matrix, γ = {γ1, γ2,…,γ
M
)T, subject to
Based on the result (8) in 3.2, the optimal projection matrix

where

where
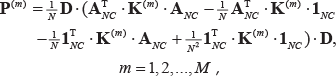
with

where
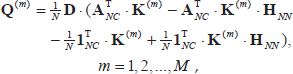
Therefore, to find the best weights (γ1, γ2, …, γ
M
) for the multiple kernel matrix

3.4 Solving the optimization problem
We introduce a Lagrangian
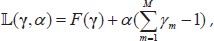
with one multiplier α. From Eq. (11) and (12), we can obtain
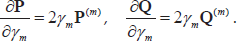
Moreover, temporarily regarding

Where
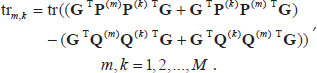
Now, differentiating

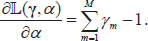
Setting these partial derivatives to zero, we get the following set of M + 1 equations:

We use Newton's iteration method to solve these nonlinear equations. Let
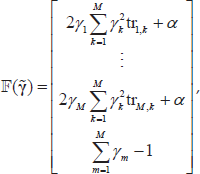
where
Then the iteration formula is
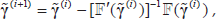
where
3.5 Weight optimization procedure
Based on the analysis above, the detailed weight optimization procedure for MKFD is described as follows.
Input :
Output : γ = (γ1,…, γ
M
)T, with γ2
m
being the weight of base kernel
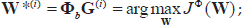
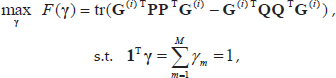
and calculate matrix (tr m,k )M × M' where

In our experiments reported in Section
4. Experiments
To evaluate the performance of our MKFD for face recognition, we have made experimental comparisons with KDDA based on single kernels, in terms of low-dimensional representation and image recognition. Images are from two face databases, namely the FERET and the CMU PIE databases.
In our experiments, three base kernels (
4.1 Face image datasets
From the FERET database [16], we select 72 people, with 6 frontal-view images for each individual. Face image variations in these 432 images include illumination, facial expression, wearing glasses, and aging. All the images are aligned by the centers of the eyes and the mouth and then normalized with a resolution of 92 × 112. The pixel value of each image is normalized between 0 and 1. The original images with resolution 92 × 112 are reduced to wavelet feature faces with resolution 49 × 59 after 1-level Daubichies-4 (Db4) wavelet decomposition. Images from one individual are shown in Fig. 1.

Images of one person from the FERET database
In the CMU PIE face database [17], there are totally 68 people, and each person has 13 pose variations ranged from the full right profile image to the full left profile image and 43 different lighting conditions, 21 flashes with ambient light on or off. In our experiments, for each person, we select 56 images including 13 poses with neutral expression and 43 different lighting conditions in the frontal view. For all frontal-view images, we apply alignment based on two eye center and nose center points, and no alignment is applied on the other images with poses. All the segmented images are rescaled to the resolution of 92 × 112, and then reduced to wavelet feature faces with resolution 49 × 59 after 1-level Daubichies-4 (Db4) wavelet decomposition. Some images of one person are shown in Fig. 2.

Some images of one person from the CMU PIE face database
4.2 Distribution of extracted features
This section aims to provide insights on how the proposed MKFD simplifies the face pattern distribution, compared with KDDA based on single kernels, when the patterns are subject to pose and illumination variations.
We select five subjects, 56 images per subject, with varying pose and illumination, from our CMU PIE face dataset determined above (56 × 5 = 280 images in all). Four types of feature bases are generalized from the images by utilizing KDDA with linear kernel, KDDA with Gaussian RBF kernel, KDDA with polynomial kernel, and our MKFD, respectively. In the sequence, all the 280 images are projected onto the four subspaces. For each image, its projections in the first two most significant feature bases of each subspace are visualized in Fig. 3.

Distribution of 280 images of five subjects under varying pose and illumination in four types of subspaces
Fig. 3(a)–(d) depict the first two most discriminant features extracted by utilizing KDDA with linear kernel, KDDA with Gaussian RBF kernel, KDDA with polynomial kernel and MKFD, respectively. Obviously, our MKFD extracts the most discriminant features.
4.3 Recognition results
This section reports the recognition results of MKFD and KDDA with single kernels on the FERET and the CMU PIE datasets. For each subject in the FERET dataset, we randomly select n (n = 2 to 5) out of 6 images for training, with the rest for testing. In the CMU PIE dataset, the number of randomly selected training images is ranged from 10 to 18 out of 56 for each individual, while the rest are testing images. The average recognition accuracies over 10 runs on the FERET and CMU PIE datasets are shown in Fig. 4(a)–(b), respectively.

Comparison of accuracies obtained by MKFD and KDDA with single kernels
Table 1 shows the average and standard deviation of the accuracies for FERET (n = 3: 3 images per subject for training with the rest for testing) and CMU-PIE (n = 14: 14 images per subject for training with the rest for testing), respectively.
Performance comparison between MKFD and KDDA with single kernels

From the results in Fig. 4 and Tables 1, it can be seen that, the blending of multiple kernels in the proposed MKFD can achieve higher accuracies than any of the three single kernels, but a simple summation of multiple kernels is hardly a good idea for improving the classification performance, while our constructed multiple kernel function with optimized kernel weights leads to enhanced performance.
Note that in the experiments, neither the parameter for RBF kernel nor the one for polynomial kernel is optimally selected, and even linear kernel has no parameter. This means that, to a certain extent, the multiple kernel function relaxes parameter selection about the base kernels.
5. Conclusion
In this paper, on the assumption that multiple kernels can characterize geometrical structures of the original data from multiple views which can complement to improve recognition performance, we apply kernel-based FDA with multiple kernels, which we call MKFD, to recognition of face images under variations of pose, illumination, facial expression, etc. The constructed kernel for MKFD is a linear combination of several base kernels with a constraint on their weights. By maximizing the margin maximization criterion, we propose an iterative scheme based on the method of Lagrange multipliers for the weight optimization, which yields updated kernel weights resulting in high recognition accuracy on the FERET and CMU PIE face database, compared with the single kernels. The experiments also demonstrate that the multiple kernel function relaxes parameter selection to some extent.
It is important to point out that the proposed weight optimization scheme is generic and, with minor modifications, can be applied to all kernel-based FDA algorithms.
Footnotes
6. Acknowledgement
This work is partially supported by the National Natural Science Foundation of China under grant No. 60975083.