
Abstract
Although face alignment using the Active Appearance Model (AAM) is relatively stable, it is known to be sensitive to initial values and not robust under inconstant circumstances. In order to strengthen the ability of AAM performance for face alignment, a two step approach for face alignment combining AAM and Active Shape Model (ASM) is proposed. In the first step, AAM is used to locate the inner landmarks of the face. In the second step, the extended ASM is used to locate the outer landmarks of the face under the constraint of the estimated inner landmarks by AAM. The two kinds of landmarks are then combined together to form the whole facial landmarks. The proposed approach is compared with the basic AAM and the progressive AAM methods. Experimental results show that the proposed approach gives a much more effective performance.
1. Introduction
In recent years, with the rapid development of biometrics, artificial intelligence and the new generation of human-computer interaction technology, the face-related image processing techniques, such as face recognition, facial expression analysis, face pose estimation, face image encoding, etc., have attracted the attention of many researchers. However, these techniques require the facial feature point information that is obtained from the image or video as a precondition. That is, we first need to align the face to locate the facial landmarks and extract the corresponding facial feature information. The facial landmarks roughly include the contour points of eyes, mouth, nose, eyebrows, chin and cheeks. As the human face is non-rigid, the accuracy of face alignment is affected by many factors, such as facial size, position, posture, expression, age, as well as the hair, glasses and light changes. A literature review shows that face alignment is still a difficult problem far from being resolved.
Many methods have been proposed for face alignment, including the Active Contour Model (ACM) [1], the Deformable Template [2, 3], Elastic Graph Matching [4, 5], the Active Shape Model (ASM) [6], the Active Appearance Model (AAM) [7, 8] and so on. Among them, AAM is the most effective.
AAM was proposed by Cootes et al. in 1998 [7]. Its idea can be traced back to ASM. Face alignment using AAM is relatively stable, but is known to be sensitive to initial values and not robust under inconstant circumstances. In order to strengthen the ability of AAM, many improvements have been proposed [9-11]. Under various face poses and illumination conditions, the contour of the outer parts of the face (like the chin and the cheeks) tends to be more variant than the inner parts of the face (like the eyes, eyebrows, nose and mouth). The outer contour of the face may be easily affected by the background of the face images. Daehwan Kim et al. [12] utilized the fact and proposed a progressive AAM-based face alignment. The progressive AAM constructs two AAM models: the inner face model and the whole face model. It first uses the inner face model to locate the inner points of the new input face and then uses them to estimate a better initial shape for the whole face model, and lastly uses the whole face model to locate all facial feature points with the estimated initial shape. However, for inconstant circumstances, AAM couldn't locate the outer contour accurately though it is better initialized. As pointed out by Cootes et al. [13], ASM is faster and achieves more accurate feature point location than AAM; so we can turn to ASM, which is the source of AAM, to find a better solution.
Both ASM and AAM are based on the Point Distribution Model (PDM) and construct two models: the shape model and the texture model. They share the same shape model. But for the texture model, ASM only models the image texture in the neighbouring of each landmark point, whereas AAM uses a model of the appearance of the entire facial region. There are many differences between AAM and ASM, and each has advantages over the other. ASM is faster and has a broader search range than AAM, whereas AAM gives a better match to the texture. Therefore, some researchers have combined the two methods to improve the performance [14, 15].
In this paper we make use of the idea of “progressive” and propose a two step approach for face alignment by combining AAM and ASM. In the first step, we use AAM to locate the inner facial landmarks (Seeing Figure 1(a)). In the second step, we use ASM to locate the outer facial landmarks (see Figure 1(b)) with the constraint of the inner facial landmarks. Finally the two kinds of landmarks are combined to a whole (see Figure 1(c)). Experimental results confirm that our approach is effective and robust for face alignment.

Shape models of the AAM and ASM
The rest of the paper is organized as follows. In Section 2 the AAM and ASM are reviewed. In Section 3 the improvements to AAM and ASM, and our face alignment approach are presented. The experimental results are given in Section 4 and finally the conclusion is given in Section 5.
2. Model Description
ASM and AAM share the same shape model, but for the texture model, ASM only models the image texture in the neighbouring of each landmark, while AAM uses a model of the appearance of the whole facial region. Let D be a training set
2.1 Shape Model
The shape S can be described by n facial landmarks S = (x1, y1, x2, y2,…, xn, yn)
T
in the image. ASM and AAM both allow linear shape variation. This means that the shape S can be expressed as a base shape S0 plus a linear combination of k shape vectors {Si}:

where p = (p1, p2,…, pk) T is the shape parameter. The base shape S0 and the k shape vectors {Si} are computed by applying Principal Component Analysis (PCA) to the training shapes (from a hand-labelled training set). The base shape S0 is the mean shape and the shape vectors {Si} are the k eigenvectors corresponding to the k largest eigenvalues{λi}.
The shape parameter p defines a set of parameters of a deformable model. By varying the elements of p we can vary the shape S(p) using Eq. (1). The variance of the i-th parameter pi across the training set is given by λi. To ensure that the shape generated is similar to those in the original training set, the following limit is applied to pi:

This limit prevents the synthesized shape from distorting.
2.2 Appearance model for AAM
The appearance of AAM is defined within the mesh of the mean shape of the training set, which also is the base shape S0 in the shape model. Let M0 denote the set of pixels {x = (x, y)
T
} that lie inside the mesh of S0. The appearance model of AAM is then an image A(x) defined over the pixels

where the coefficients {qi} are the appearance parameters. The base appearance A0(x) and appearance images {Ai(x)} are computed by applying PCA to the shape-normalized training images. Each training image is shape-normalized by warping the hand-labelled training shape onto the mean shape S0. The base appearance A0 is the mean image and the appearance images {Ai} are the h eigenimages corresponding to the h largest eigenvalues.
2.3 Local profile models for ASM
ASM forms one profile model for each landmark. The profile is a fixed-length normalized gradient vector by sampling the image along the normal line which is orthogonal to the shape boundary at the landmark. During training on the hand-labelled faces, the mean profile vector ḡ and the profile covariance matrix Rg are calculated at each landmark. The quality of fit of a new landmark is given by
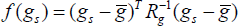
where gs is the profile of the new landmark.
3. A Two Step Face Alignment Approach
The problem of ASM is that it easily converges to local minima and thus cannot obtain the global optimal solution. But for the outer contour of the face, which has significant gradient values, ASM can get accurate fitting results. To solve the local minima problem, we use AAM to locate the inner landmarks of the face and use the result to initialize and constrain ASM fitting.
3.1 Outline of Our Approach
Model Constructing
Construct the whole shape model from the whole facial landmarks of the training faces.
Construct the inner face AAM model from the inner facial landmarks of the training faces, including the inner shape model and the inner appearance model.
Construct the outer face ASM profile models from the outer facial landmarks of the training faces.
Model Fitting
Use the similarity transformation [13] to translate the whole mean shape of the whole shape model to the estimated inner landmarks. The outer landmarks of the translated whole mean shape are then selected as the initial values of the ASM fitting.
Fit the outer face ASM profile models into the new incoming face by applying a constraint in each iteration.
3.2 Extension to ASM
The classical ASM uses a one-dimensional profile at each landmark. As pointed by S. Milborrow et al. [16], using two-dimensional “profiles” can give improved fits. We can select a square region around the landmark to form the 2D profile, which captures more information around the landmark. The region is displaced in two directions, which are orthogonal or tangent to the shape edge at the landmark respectively.
In order to reduce the lighting effects, we use the VHE bands [17] to represent the RGB values of each pixel:
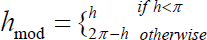
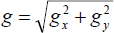
where gx and gy are horizontal and vertical gradient images obtained from numeric differential operators with a suitable amount of Gaussian smoothing.
The VHE bands can effectively eliminate some impact of the lighting variation and improve the fitting robustness. For each landmark point, the selected 2D profile matrix is reshaped and normalized as a long vector Gj. To reduce the dimension of Gj, we also apply a PCA on it. The profile Gj of the j-th model point is then represented as a linear combination of a mean profileG0j and l basis vectors Gij:

where{βi}are the profile parameters. The basis vectors {Gij} are the l eigenvectors corresponding to the l largest eigenvalues {λij}.
Let b = (β1, β2,…, βl) and

The distance between gj and the profile model can be defined as:
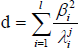
where{βi}are obtained of Eq. (8). During the search we sample profiles of the current candidate points and choose the one which gives the minimum distance value.
3.3 Constraint of the inner landmarks
We use the estimated inner landmarks that are given by AAM to give a better initial shape by applying the similarity transformation to the entire mean shape of the whole shape model. Then, in each iteration of the ASM fitting, the estimated outer landmarks are joined together with the inner landmarks to form the whole shape S. The shape parameter p is then computed as follows:
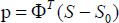
where Φ = (S1, S2,…, Sk), {Si} are the shape vectors and S0 is the mean shape of the whole shape model. The constraint of Eq. (2) is then applied on the parameter p. The two operations prevent the ASM fitting from converging to local minima.
4. Experiment
In order to validate the performance of our method, we have conducted extensive experiments and comparisons on the IMM database [18] and the BU-3DFE database [19]. The point-to-point (pt-pt) error is used to evaluate the fitting accuracy. The pt-pt error is given by the difference between the estimated landmarks and the hand-labelled landmarks:

where S is the ground-truth shape and s' is the estimated shape. The fitting is considered to be successful if the pt-pt error is within three pixels.
The IMM database consists of 240 images of 40 people, exhibiting variations in pose, expression and lighting. Each image is annotated with 58 landmarks. Half of the images are selected for training and the rest for testing.
The BU-3DFE database contains 2500 image of 100 subjects (56% female and 44% male). Each subject performed seven expressions in front of the 3D face scanner. With the exception of the neutral expression, each of the six prototypic expressions (happiness, disgust, fear, angry, surprise and sadness) includes four levels of intensity. Each image is annotated with 83 landmarks. 300 images are selected for training and the rest for testing.
The experiment results for the IMM face database are summarized in Table 1 and Figure 2, while the experimental results for the BU-3DFE database are summarized in Table 2 and Figure 3.
Face alignment results of the IMM database

Face alignment results of the BU-3DFE database


Fitting result comparison on IMM database: (a) Result of AAM; (b) Result of Progressive AAM; (c) Result of the proposed approach

Fitting result comparison on BU-3DFE database: (a) Result of AAM; (b) Result of Progressive AAM; (c) Result of the proposed approach
The proposed approach is compared with the basic AAM [7] and the progressive AAM [12]. Table 1 and Table 2 show the pt-to-pt fitting errors and the failure rates of the three different methods, which show that the proposed approach produces the smallest fitting error. The progressive AAM produces a lower failure rate than the proposed approach dose on the IMM database, which is shown in the last column of Table 1. However, as shown in the last column of Table 2, the proposed approach produces a lower failure rate than the progressive AAM dose on the BU-3DFE database, which has more complex expressions than the IMM database.
Some examples of the fitting results are cut into suitable sizes and shown in Figure 2 and Figure 3. The proposed approach locates the landmarks more accurately than do the AAM and the progressive AAM, especially for the outer contour and the mouth. In our approach, the AAM just constructs the inner face model in which the texture can be less limited by the shape information of the outer face, which is more variable. Therefore it can give a more accurate inner landmark locating result than that of the whole AAM model, particularly in the situation of pose variation and expression variation.
5. Conclusions
In this paper a two step face alignment approach is presented by combining two statistical models, the AAM and ASM. The ASM has a broader search range than AAM. It is also less limited by the texture information, therefore it can give a much more accurate fitting result on the outer contour of the face. The proposed approach is compared with the basic AAM and the progressive AAM methods. The experimental results confirm that our approach gives a much more effective performance on face alignment.
The relationship between the inner landmarks and the outer landmarks is now only linked up through a simple constraint. In future work we will dig deeper into the relationship between the two kinds of landmarks and the relationship between the two kinds of statistical models.
Footnotes
6. Acknowledgments
This work is partially supported by the Natural Science Foundation of China under grant no. 60973098, 61005005 and 61125305.