
Abstract
Facial landmark localization is still a challenge task in the unconstrained environment with influences of significant variation conditions such as facial pose, shape, expression, illumination, and occlusions. In this work, we present an improved boundary-aware face alignment method by using stacked dense U-Nets. The proposed method consists of two stages: a boundary heatmap estimation stage to learn the facial boundary lines and a facial landmark localization stage to predict the final face alignment result. With the constraint of boundary lines, facial landmarks are unified as a whole facial shape. Hence, the unseen landmarks in a shape with occlusions can be better estimated by message passing with other landmarks. By introducing the stacked dense U-Nets for feature extraction, the capacity of the model is improved. Experiments and comparisons on public datasets show that the proposed method obtains better performance than the baselines, especially for facial images with large pose variation, shape variation, and occlusions.
Introduction
Facial shape that composed of a series of corresponding facial landmarks is an important face description information for face analysis. Facial landmark localization, as so called face alignment, plays a key role in various applications, such as face recognition, 1,2 facial expression recognition, 3 facial attribute analysis, 4 and so on. While extensive efforts have been devoted and large step has been made in recent years, the performance of existing face alignment methods still unsatisfactory in real tasks. Faces captured in real world with unconstrained conditions usually suffer from significant variations of pose, expression, illumination, and partial occlusions.
In recent years, deep neural networks have been widely applied in the fields of image understanding and computer vision. 5 –7 Applying fully convolutional neural networks to facial landmark prediction has drawn great attention in the face alignment community owing to their great performance. 5,8 –10 By formulating face alignment as a heatmap regression problem, these methods 5,6,8 –10 aim to learn a set of landmark heatmaps, which illustrate the probability of the landmark location at one pixel. Since heatmap regression is a dense regression problem, the model can be improved by studying the feature representation between resolutions and connecting the spatial information of each resolution. Among various heatmap regression methods, the stacked hourglass network 8 which can extract the deep features from the original scale without changing the dataset size has recently achieved great success. Inspired by the stacked hourglass networks, Guo et al. 9 propose a stacked dense U-Nets which improve the model capacity without increasing the computational complexity by increasing the model size and simplifying the sampling step. The dual transformers of inside and outside make the stacked dense U-Nets spatially invariant to an arbitrary face, which make the method much more robust for face alignment in the wild condition. However, the lack of explicit constraint among landmarks makes the method still cannot well deal with facial images with large shape variation and occlusions.
Since most of the facial landmarks are not corner points, their semantical location may change greatly with large shape variation, pose variation, and occlusion, which make them difficult to be localized. Many methods represent the geometric structure of the face by constructing the relationship among landmarks implicitly or explicitly. The classical active appearance model (AAM)-based methods 11,12 and cascaded regression model-based methods 13 –15 generally treat the face landmarks as a whole shape to remain the structure. For deep neural networks, Wu et al. 16 introduce a boundary-aware regressor to represent the structure by using well-defined facial boundaries. The boundary heatmaps algorithm can make good use of facial contour information.
In this work, we take advantage of the stacked dense U-Nets for improving the capacity of feature extraction model and the boundary heatmaps for facial shape structure constraint, proposing an improved boundary-aware face alignment method by using stacked dense U-Nets. The boundary line of human face can be used as the key point location medium, and the stacked dense U-Nets can extract the feature information of different scales to improve the effect of heatmaps regression. The proposed method is evaluated on three popular benchmarks including WFLW, 16 300-W, 17 and COFW. 18 Experimental results demonstrate that our method has a good performance on challenging faces with occlusions, large pose variation, and shape variation. The accuracy of landmarks on the face contour has been greatly improved.
Related works
As a fundamental topic in face recognition area, face alignment has received considerable attention for a long period. The popular face alignment methods have revolved around from active shape model, 19 AAM, 11 moving to Gauss–Newton deformable part model, 20 constrained local model, 12 and cascaded regression models. 13 –15 The current state-of-the-art methods revolve around deep convolutional neural networks, especially the heatmap regression models. 21 –24 In the following, we briefly introduce the recent face alignment methods with a special focus on heatmap regression models.
The heatmap regression models can generate a heatmap for each key point, which can be used to estimate the current landmark location in the image. In the deep alignment network (DAN), 24 DAN is divided into multiple stages, and the landmark heatmaps are used as the input of the intermediate stage to transfer the information about estimated landmark location in the previous stage. Yang et al. 22 use the supervised transformations to normalize faces and obtain prediction heatmaps through a stacked hourglass network 8 . Deng et al. 23 propose a joint multiview convolutional network for faces in-the-wild with large pose variations and achieve multiview face alignment by using a stacked hourglass network 8 . Merget et al. 21 generate heatmaps based on the labeled dataset and Gaussian model and then use the heatmap as a guide for supervised learning with convolutional neural network to estimate the facial landmarks. Inspired by the efficiency of boundary detection in vision tasks, Wu et al. 16 propose to estimate facial boundary heatmaps by using the stacked hourglass structure 8 and then utilize the boundary lines which identifies the facial geometry structure to help face alignment.
Hourglass network with symmetrical structure 8 is proposed to capture information at each scale in human pose estimation, and it also performs well in face alignment 25 . Chu et al. 26 use the stacked hourglass network to obtain different levels of heatmaps by changing the inputs between structures. Yang et al. 27 use the stacked hourglass network and generate a score map of joint positions at the end of each hourglass. To improve model capacity, Guo et al. 9 propose a scale aggregation topology (SAT) by adding down-sampling inputs for aggregation nodes. They present a channel aggregation block which increases robustness when local observation is blurred. Compared with the original hourglass network, the dense U-Net greatly improves the capacity of the model while maintaining similar computational complexity and model size.
Proposed method
In this section, we describe the proposed face alignment framework in details. As shown in Figure 1(a) and (b), the proposed framework consists of two stages: (a) boundary heatmap estimation stage to generate boundary lines for the later stage assistance; (b) boundary-aware facial landmark localization stage to predict the final face alignment result with the incorporated facial boundary information.

The proposed framework: (a) Boundary heatmap estimation stage to generate boundary lines for the later stage assistance. (b) Boundary-aware facial landmark localization stage to predict the final face alignment result with the incorporated facial boundary information. (c) Adversarial learning to improve the quality of the estimated boundary heatmaps during training.
The facial boundaries as the representation of facial geometric structure can present accurate and universal geometric structure of the face. The facial boundary heat map can be derived from the facial landmarks of different annotations as constraints for the next regression. Since the quality of boundary heatmaps is crucial for the final landmark regression, following the work boundary heatmap estimation, 16 an adversarial learning 28 operation between the estimated boundary heatmaps and the ground-truth boundary heatmaps is added to discriminate effective boundaries, as shown in Figure 1(c). In the facial landmark localization stage, we use the estimated boundary heatmaps as a constraint condition into the stacked dense U-Nets to predict the landmarks.
Boundary heatmap estimation
Facial boundary is closely related to the facial landmark. More than piecemeal landmarks, facial boundary can well describe the geometry structure of a face. When associate each facial landmark with a semantical boundary, such as the mouth and the nose bridge, we can get a whole shape structure that covers the face. In this manner, the piecemeal landmarks are related to each other by the geometrical and semantical relationship among them. Therefore, when large occlusion or large pose variation occurred, the influenced landmarks can be better estimated by the current related stable landmarks through a message passing strategy. Motivated by that, we aim to estimate boundary heatmaps to obtain facial boundary information.
In order to fuse boundary lines in feature learning, we need to define facial boundary heatmaps to aid the learning of feature. Given a facial image I and n corresponding landmark annotations Sl
,
To implement the boundary heatmap estimation, here we utilize the boundary heatmap estimator proposed by LAB 16 as the baseline, and the mean squared error (MSE) between the ground-truth and estimated boundaries is used as the loss function. Different from LAB, here we use the superimposed SAT 9 as the backbone instead of hourglass network. Compared with hourglass network, SAT has better advantages in feature extraction and model capacity.
As shown in Figure 1(a), the input face image is put into the stacked U-Nets after convolution and down sampling to generate boundary heatmaps. To use the geometrical and semantical information of facial shape constraint, the information transfer layers are introduced after each stack SAT. Following LAB 16 , two kinds of message passing layers are utilized for information transfer: intra-level layers and inter-level layers.
Intra-level message passing layer
It plays a role at the end of each stack to pass information between visible boundaries and occluded ones. In the process of occlusion, the prediction of the occlusion part can be improved through the visible boundary information.
Inter-level message passing layer
Since different stacks get different aspects of facial information, in the case of multiple stacks, the face information is transferred in different stacks by the way of passing message from former stacks to latter stacks.
Here the implementation of message passing layers refers to the work of Chu et al. 29 As shown in Figure 2, the facial boundary is divided into K branches, each represents a feature map. The calculation of boundary message passing is less than that of landmark heatmap 22,23 for the small and constant number K of them.

The structure of message passing layers. hi represents the characteristics of 256 channels obtained by convolution at the end of the dense U-Nets. The channel features are divided into K branches, each represents a type of boundary feature map. The boundary feature maps in the previous stack are transferred to the next stack as inter-level message passing, and all feature Ai are also transferred in message passing. Then the feature Bi obtained by the opposite direction tree and Ai are connected together to get the final prediction map.
Boundary-aware landmark localization
In order to obtain robust face alignment performance, the boundary heatmaps are fusion with the input facial image for feature learning. Here we use the stacked dense U-Nets 9 as the backbone for landmark localization, as shown in Figure 1(b).
Scale aggregation topology
The topology design for heatmap regression can obtain local and global features at different scales, while maintaining the resolution information. Hence the stacked dense U-Nets network can get better effect by improving the topology design. As shown in Figure 3(a) and (b), the U-Net and hourglass network as classic topology design have four pooling layers. At each down-sampling step, high resolution features are acquired, then these features are combined into corresponding up-sampling features. These spatial informations are saved at each resolution through the cross layer connection. The U-Net and hourglass network achieves compelling accuracy with a bottom-up, top-down design which endows the network with capabilities of obtaining multiscale information. Based on the U-Net and hourglass network, deep layer aggregation (DLA) 30 (as shown in Figure 3(c)) augments shallow lateral connections with deeper aggregations to better fuse information across layers. Inspired by DLA, the SAT can obtain more information. As shown in Figure 3(d), SAT also adopts a bottom-up, top-down design, but there are only three pooling layers. Reducing the pool layer can greatly reduce the computational complexity and model size. In addition, the SAT adds the lower sampling input to the aggregation nodes to retain more scale feature information. Depth-wise separable convolutions 31 and lateral connections 32 are used to consolidate multiscale feature representations and to fuse information across layers. The SAT greatly improves the capacity of the model while the computational complexity and model size are similar to the hourglass network. Because of the performance of SAT is well in feature extraction, we use stacked dense U-Nets to get the features of images at different scales.

Illustration of different network topologies: (a) U-Net; (b) hourglass network; (c) DLA; (d) SAT. DLA: deep layer aggregation; SAT: scale aggregation topology.
Deformable convolution
In order to further improve the capacity of the model, two U-Nets are stacked end-to-end. However, the stacked U-Nets still lacks the ability of transformation modeling due to the fixed geometry structures. Here we use the Deformable ConvNets V2 33 to obtain the spatially invariant ability to the arbitrary input facial images. As shown in Figure 4, the Deformable ConvNets V2 is composed of two parts, the ordinary convolution and the migration layer. We obtain the offset of deformable convolution by convoluting the input feature map with ordinary convolution layer, and then the convolution kernel is offset by the offset field to get the deformable convolution result. The offset of Deformable ConvNets V2 can be learned in the target task without the design of features manually. In addition, Deformable ConvNets V2 adds the modulation to the offset and allocates different weights to the region modified by the offset. Accordingly, the extracted features are more concentrated in the effective region. Deformable ConvNets V2 can modify the shape of revolution kernel by learning local and dense extra offsets, thus it can have better performance on the deformation of objects, size changes and other issues.

A 3 × 3 deformable convolution, the offset is obtained by the output of a small convolution layer, and then it is applied to the convolution kernel.
Image fusion with boundary heatmaps
In order to improve the robustness in the case of occlusion and large pose, we need to fuse the boundary heatmaps with the input facial image. To fuse boundary heatmap H with an input image I, the fusion function F is defined as

where ⊕ is the channel-wise concatenation and ⊗ is the element-wise dot product operation. The fusion operation fuses the estimated boundary heatmaps information with the original information and only focuses on the boundary information. Therefore, texture-less face regions are ignored, which can make the fusion information more effective. After fusing the information, the original input is added to keep the other valuable information.
Adversarial learning for boundary effectiveness
Bad boundary heatmaps will greatly deprecate the performance of the landmark localization. During training, in order to ensure the effectiveness of the heatmaps obtained in the boundary heatmaps estimation stage, we take use of adversarial learning between the estimated boundary heatmaps and the ground-truth heatmaps. For the boundary heatmaps

where θ is the distance threshold to ground-truth boundary and δ is the probability threshold. This discriminator predicts whether boundary information is valid.
According to the idea of confrontation learning, the boundary effectiveness discriminator D and the boundary heatmap estimator G are matched. The loss of D can be expressed as

where M is the ground-truth boundary heatmap. High-confidence maps can be obtained by discriminator learning, which will benefit the learning of localization network.
The training process of our method is summarized Algorithm 1.
The training pipeline of the proposed method.


Experiments
To validate the performance of the proposed method, extensive experiments are conducted on three popular facial image in-the-wild datasets: WFLW, 300-W and COFW.
Datasets
WFLW 16 dataset is a challenging one, which contains 7500 faces for training and 2500 faces for testing based on WIDER Face with 98 manually annotated landmarks. 16 The dataset is partitioned into six subsets according to challenging attribute annotation of large pose, expression, illumination, makeup, occlusion, and blur.
300-W 17 provides multiple face datasets including LFPW, AFW, HELEN, XM2VTS, and IBUG with 68 automatically annotated landmarks. We use 3148 images as training samples and 689 images as testing samples. The testing images include two subsets, where 554 test samples from LFPW and HELEN form the common subset and 135 images from IBUG constitute the challenging subset.
COFW 18 dataset contains 1345 faces for training and 507 faces for testing. All training face are occlusion-free while testing face are occluded partially. Each COFW face originally has 29 manually annotated landmarks.
Evaluation metric
To evaluate our method, we use standard normalized landmarks mean error as the evaluation criteria. We also report two further statistics: the area under the curve (AUC), and failure rate for the maximum error of 0.1. For these datasets the results are normalized by inter-pupil (eye-center-distance) distance.
Implementation details
All training images are cropped and resized to 256 × 256 according to provided bounding boxes. The boundary estimator is stacked four times and the dense U-Nets in localization is stacked two times. For the whole network, we set the initial learning rate to
Evaluation on WFLW
For comprehensively evaluating the robustness of our method, we report on six typical subsets of WFLW. We compared our method with the backbone LAB* and five other popular methods. The comparison results are shown in Table 1. Note that the LAB* is reported by our re-implemented work, but others are publicly reported in LAB. Though limited by the conditions, we cannot reach the reported result in LAB, but compared with other five methods, the LAB* and the proposed method IBFA still obtain the best results. The proposed method achieves 6.23% and 7.19% mean error on large expression subsets and occlusion subsets which has obvious advantages over the original method under the same conditions. In addition, the evaluation of IBFA in failure rate and AUC is better than other methods. The failure rate on large expression subsets and occlusion subsets are only 8.13% and 14.90%. The AUC on large expression and occlusion subsets are also reached 0.4188 and 0.3942 which are higher than the AUC of LAB*. This reflects the effectiveness of the improved method for exaggerated expressions and heavy occlusion as shown in Figure 5.
Evaluation on testset and six typical subsets of WFLW (98 landmarks).

AUC: area under the curve.

Boundary heatmaps and landmarks of two methods in WFLW: (a) Test results of LAB* and (b) test results of IBFA.
As shown in Table 2, We compare the two method with error rate of the five facial parts on WFLW and speed of the models. Our method performs better than LAB* in all five facial parts, especially performs well in the mouth and nose. It can be seen from Table 2 that with the increase of the scale of model, the speed of model will decrease. How to speed up the model is a problem to be solved in future.
Error rate of five facial parts on WFLW and the speed of models.

Evaluation on 300-W
We compare our method with the backbone LAB* and eight other popular methods on 300-W dataset in the same environment. The results are shown in Table 3. Our method performs best among all of previous methods. Also, we compared the localization results on five parts of face on 300-W and report the mean error results in Table 4. It can be observed that performance is improved consistently in five parts of face, and the accuracy of location in eye and chin is improved most obviously.
Mean error (%) on 300-W common subset, challenging subset and fullset (68 landmarks).

Error rate of five facial parts on 300-W and the speed of models.

The results of LAB* and IBFA are trained under the same conditions which reflects that the improved method obtains significantly better performance. The IBFA performs better on the challenging subset, which indicates the robustness of our method to handle occlusions and large expression. The test image of the two methods are shown in the Figure 6. We find that they are similar in the acquisition of boundary heat map, while the improved method performs better on the effect of coordinate regression. This shows that the multilayer aggregation network topology can effectively use the boundary information, thus greatly improving the accuracy of key point prediction.

Boundary heatmaps and landmarks of two methods in 300-W: (a) Test results of LAB* and (b) test results of IBFA.
Evaluation on COFW
We compare our method with LAB* and other six popular methods on COFW. Table 5 exhibits the experimental results we evaluated on COFW dataset. It can be seen from the results, the mean error and failure rate of our method are smaller than those methods specific to the occlusion problem, for example, HPM and DRDA. In particular, the error rate of the improved method is reduced to 2.37%, we can conclude that our improved boundary-aware face alignment model is robust against occlusion. This can also be reflected in the test result comparison Figure 7.
Mean error (%) on COFW dataset (29 landmarks).

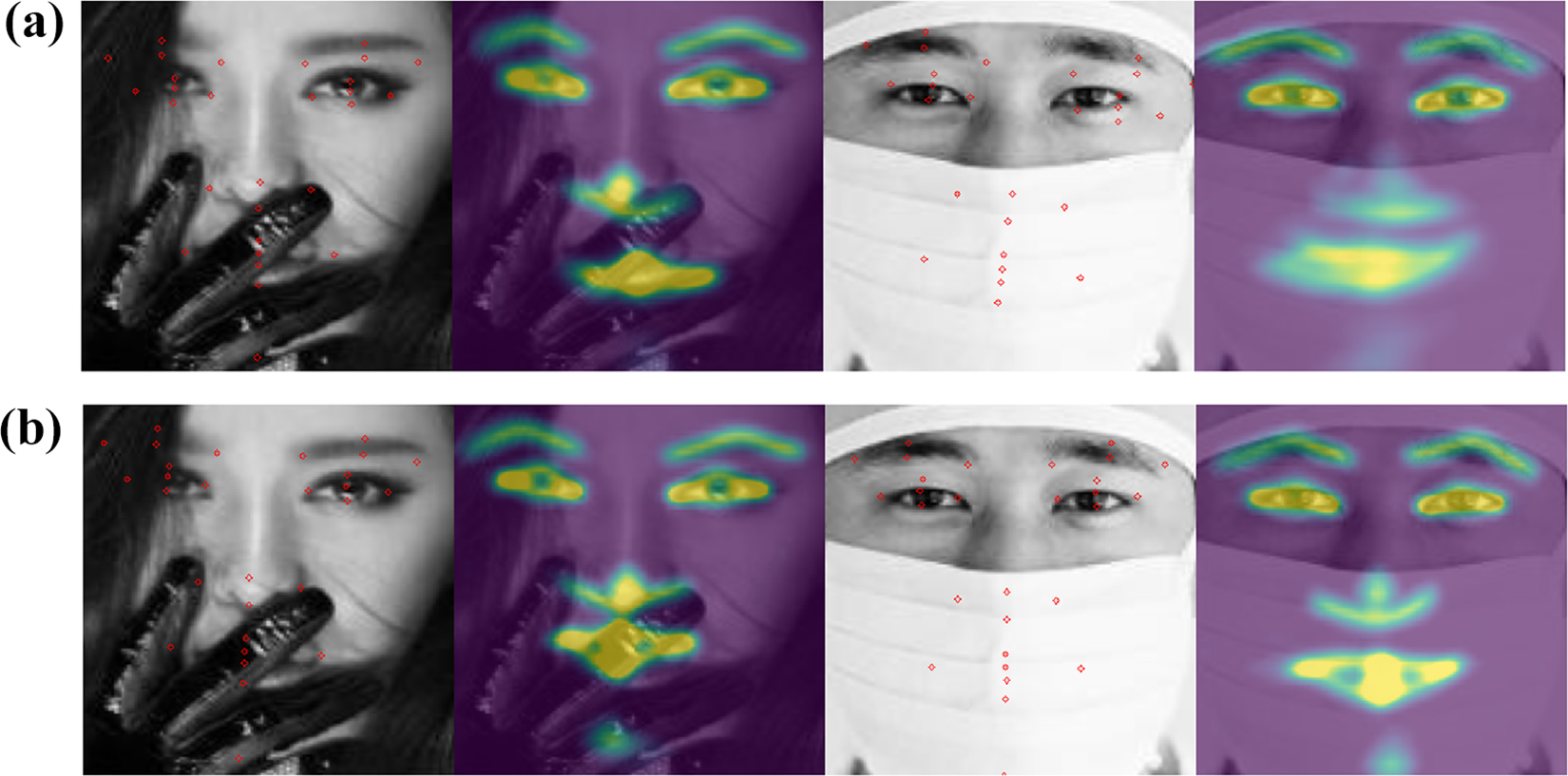
Boundary heatmaps and landmarks of two methods in COFW: (a) Test results of LAB* and (b) test results of IBFA.
Conclusions
In this article, we propose an improved boundary-aware method using stacked dense U-Nets for robust face alignment. By utilizing the facial boundary heatmap for landmark estimation constraint, we are able to handle facial occlusions, large shape, pose, and appearance variations. Through boundary-aware landmark localization network, we can accurately regress the facial boundary heatmap to the facial feature points. Our experimental results show that the localization effect of the boundary heatmap can be improved by stacked dense U-Nets. In experiments, our method can achieve leading performance in WFLW, 300-W, and COFW.
Footnotes
Author contributions
JY devised the conception and design, contributed to the coding implementation, data analysis, and drafting the article; YC contributed to the conception and design, data analysis, and article drafting; XP, HZ, DG, and YR contributed to the conception and design and article revising.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Ethical approval/Patient consent
All analyses were based on previous published studies, thus no ethical approval and patient consent are required.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was supported in part by Zhejiang Provincial Natural Science Foundation of China (grant nos LQ18F030014, LQ18F030013, LY19F020031, and LQ17F030004) and in part by National Natural Science Foundation of China (grant no.61871350).