
Abstract
In robotics, solving the direct kinematics problem (DKP) for parallel robots is very often more difficult and time consuming than for their serial counterparts. The problem is stated as follows: given the joint variables, the Cartesian variables should be computed, namely the pose of the mobile platform. Most of the time, the DKP requires solving a non-linear system of equations. In addition, given that the system could be non-convex, Newton or Quasi-Newton (Dogleg) based solvers get trapped on local minima. The capacity of such kinds of solvers to find an adequate solution strongly depends on the starting point. A well-known problem is the selection of such a starting point, which requires a priori information about the neighbouring region of the solution. In order to circumvent this issue, this article proposes an efficient method to select and to generate the starting point based on probabilistic learning. Experiments and discussion are presented to show the method performance. The method successfully avoids getting trapped on local minima without the need for human intervention, which increases its robustness when compared with a single Dogleg approach. This proposal can be extended to other structures, to any non-linear system of equations, and of course, to non-linear optimization problems.
1. Introduction
In recent years, parallel robots have become an excellent solution for applications where a precise pose (position and orientation) is needed. Such kinds of applications can be found on machining centres and radio telescopes among others. Today, for successful application, the kinematics of these structures requires a robust solution that has a significant role when high accuracy and low computational cost are needed. Depending on a particular configuration, in the simplest cases, the direct kinematics problem of this kind of structure can be solved in closed form. Generally the generalized coordinates cannot be expressed in an analytical manner as functions of the actuated joint coordinates [1]. In these cases, optimization algorithms and non-linear solvers can be used. Due to the characteristics of parallel robots, such as intrinsic closed chains, there is no one to one relationship between controllable variables and degrees of freedom. Thus, each controllable variable affects output degrees of freedom and vice versa. Usually non-linear functions are involved therefore it is not surprising that Newton and Quasi-Newton methods can get trapped on local minima when trying to solve the non-linear system.
One of the best known parallel manipulators is the Stewart platform [2]. Although this structure was first introduced by Gough [3], it is often referred to just as the Stewart platform. Some authors have recognized this paradox and they use the term Gough-Stewart platform. We will refer it as the Stewart platform, without recognizing this fact. It was selected for the case studied here, since this structure can be intended for highly precise applications. In the last two decades, many different aspects of this parallel manipulator have been studied and reported on [4] [5] [6] [7] [8].
There are some configurations that can be referred to as simplified Stewart platforms [9]. They are represented schematically in Fig. 1. Fig. 1 (a) shows the configuration with regular hexagons for the base and mobile platforms. Fig. 1 (b) shows a configuration with similar symmetric hexagons for both platforms. The architecture in Fig. 1 (c), termed SSM (Simplified Symmetric Manipulator), is characterized by the fact that the planar base and platform have an axis of symmetry. The architecture shown in Fig. 1 (e), termed TSSM (Triangular Simplified Symmetric Manipulator), is an SSM manipulator with a triangular platform. The architecture shown in Fig. 1 (d), the MSSM (Minimal Simplified Symmetric Manipulator), is a TSSM with a triangular base. Fig. 1 (f) shows the configuration commonly called the 3-2-1 configuration. In fact, taking into count the location of the joints on the base and mobile platforms, Figs. 1 (a), Fig. 1 (b) and SSM are architectures have a 6-6 configuration, often called general 6-6 Stewart platforms; meanwhile, MSSM is referred to as a 3-3 configuration and TSSM as a 6-3 configuration. The direct kinematics problem of the Stewart platform with a 6-6 configuration has been approached by many researchers in the past. However, research in this area is still continuing, due the lack of an effective solution approach. In fact, no matter what approach for the DKP of a general 6-6 Stewart platform is used, a unique solution is still a challenging problem. Some methodologies have been used: analytical methods, use of redundant sensors, numerical approaches, neural network-based methods, and recently, by using evolutionary algorithms.

Top view of different configurations for Stewart platforms; (a) configuration with regular hexagons; (b) configuration with similar symmetric hexagons; (c) SSM configuration; (d) MSSM configuration; (e) TSSM configuration; (f) 3-2-1 configuration
In particular, analytical methods have been proposed to address the DKP for a general Stewart platform; their main differences can be explained as: i) by formulating a system of non-linear equations and converting them to higher degree polynomial, after multiple solutions are obtained by finding roots of this polynomial, [10] [11] [12] [13]. These solutions are referred as the assembly modes of the manipulator. ii) The pose parameters can be decoupled, which leads to reduced complexity and computational cost [14]; iii) other analytical methods in the literature include the continuation method [15] [16], elimination methods [17] [18] [19] [20] and interval analysis [10]. However, the DKP is not fully solved just by finding all the possible solutions. For practical purposes, a unique actual pose in the platform workspace is necessary. Moreover, some approaches are not suitable for real-time operation, due their computation time.
Installation of redundant sensors has been proposed to address the DKP [21]. But this approach has practical limitations such as cost and additional measurement errors. On the other hand, the DKP could be solved by using a numerical technique like the Newton-Raphson method [22] [23] [24]. The Newton-Raphson iterative technique has been the most popular method for solving the DKP of parallel robots as in some cases it gives very accurate results. Unfortunately, by using just this technique, there is no guarantee of convergence to the solution and the successful convergence of this method is highly dependent on the starting values for the solution.
Taking the same form, strategies based on neural networks have been proposed [25]. They propose a hybrid method where a neural network achieves the starting values for a Newton-Raphson algorithm. Other approaches have been reported in [26] [27] and[28], and recently [29], for a cable Stewart platform. The main drawback is that training, testing and validation tasks for the neural network demand a lot of information from the robot workspace.
Referring to robotics in general, evolutionary algorithms have begun to be considered for addressing optimization problems. In particular, genetic algorithms have been used from the optimal planning of experiments for the calibration problem of serial robots [30], most recently, for the optimal control of parallel manipulators [31]. In addition, recently a hybrid method based on genetic algorithms has been implemented to address the direct kinematics of the Stewart platform, by finding all real solutions [32]. The approach presented in [33] deals with the synthesis of mechanisms using differential evolution to solve the dimensional and multi-objective problem of planar mechanisms. The main contribution of this work is in the non-linear solver for the non-linear kinematics of the general Stewart platform. We introduce a novel proposal that could be applied to solve difficult non-linear problems which are not convex in general, but have various convex regions in the search space. Derivative free optimizers, such as genetic algorithms, estimation of distribution algorithms and other population-based algorithms, are computationally expensive and must be used when no other more efficient strategy is known. On the other hand, derivative-based algorithms, such as Newton or Cuasi-Newton methods, are quite efficient when the objective function is smooth and convex, but they tend to be trapped in local minima. In this work, a novel approach which takes advantage of both strategies is used, in order to solve the non-linear kinematics of the general Stewart platform with adequate precision and minimum computational effort. Several experiments and discussions are presented to show the method performance. The method successfully avoids getting trapped on a local minimum without the need for human intervention, which increases the robustness of the solver when compared with a single Dogleg approach. The paper is organized as follows: in Section 2, a kinematic model of the general Stewart platform is introduced and corresponding kinematic equations are formulated as an adequate optimization problem in order to implement a hybrid optimizer. In Section 3 a description of the hybrid optimizer implementation is presented. In Section 4, the performance of numerical experiments is shown to validate the proposed method.
2. Problem Formulation: Non-linear Kinematics of the Stewart Platform
A general Stewart platform has been selected for the case studied here. A kinematic model of this platform was formulated by Gosselin in [34]. It is a manipulator with semi-regular hexagons, where the joints are symmetric in pairs. Its kinematic configuration consists of a fixed plate connected through six legs to a mobile platform, Fig. 2. Each leg has a prismatic joint (actuator), a spherical joint at the fixed end and a universal joint at the mobile end. The fixed and mobile platforms can have the same dimensions. In order to improve the mechanism stability, the spherical and universal joints can be located as close as possible. The centre points of the spherical joints are located at radius rA and the universal joints are located at radius r B , Fig. 3. Ai is the centre point of each spherical joint (vertex of a hexagon on the base platform), and Bi is the centre point of each universal joint (vertex of a hexagon on the mobile platform), Fig. 3(a) and Fig. 3(b), respectively.

A scheme for the Stewart platform

Location of the joints on the base and mobile platforms
The angular position between the connecting joints is Φ
A
at the base platform and Φ
B
at the mobile platform.

and

where

and

The position vector of the mobile platform is defined as

with
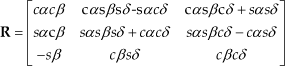
where α, β, δ are the orientation angles of the mobile platform, c, s represent cos() and sin() functions respectively.
Subtracting

The length li of each leg is calculated from the Euclidean norm of Eq. 7 as:

In this way, the solution of the inverse kinematic problem can be written as:
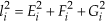
where

recalling that R11, R12, R21… are the components of the matrix
In this way, the individual length of each leg is calculated as a function of the position and orientation of the mobile platform. The final position of the mobile platform can be controlled adjusting li to a specific length. From Eq. 10, it can be seen that x, y, z and α, β, δ, position and orientation variables depend on the length of the six legs, i.e., the direct kinematic problem consists of finding the pose given the six length legs. The resolution of the direct kinematics is essential for control purposes, on-line simulations and performance analysis, and primordial tasks in real applications. The problem consists of solving the non-linear system of equations in Eq. 10 for the Cartesian coordinates; the system can be completed with additional equations by using the rotation matrix and its invariants. Six residual functions fi(x˜)=[f1…f6] can be formulated as

Thus, the system of six equations with six unknowns of Eq. 11 can be solved giving a vector x˜=[x,y,z,α,β,δ] which contains the starting values for position and orientation of the mobile platform, and minimizing the function errors as

3. Implementation of the Hybrid Optimizer
In order to minimize Eq. 12 an optimizer is needed. A widely used, effective and efficient optimizer is the Dogleg [35]. Its process is described in Algorithm 1, it is a minimization/maximization method from the family of the trust-region algorithms, which combines the so-called Cauchy and Newton directions (a direction based on the gradient and another based on second derivatives information, respectively). Nevertheless, the Dogleg produces impressive results when the function to minimize is convex, however, it can be trapped on a local minimum if non-convexity and/or many local minima are present.
As a consequence, this method requires an adequate starting point to converge to the global minimum.
Thus, if the user does not have a priori information about the global minimum position, there is no certainty about finding the actual global minimum. To circumvent this issue, we propose using an Estimation of Distribution Algorithm (EDA) [36]. EDAs are powerful evolutionary optimizers which can avoid local minima and do not need derivatives. Nevertheless, EDAs have been proposed as an extension of Genetic Algorithms (GAs) as it has been proven that EDAs are more effective than GAs when the correlation among variables is an important factor in the optimization process.
Dogleg

The main subject of this proposal is the parameter optimization of a mechanical system. Considering that each one of the mechanical parts is related one another, the parameters are strongly correlated, thus, an EDA which considers variable dependencies can be an adequate strategy to tackle this problem. Then, the hybrid optimizer is built as follows: an EDA-based multivariate Gaussian model is used to generate starting points for the Dogleg method, thus, we expect to improve the starting points for the Dogleg method through the generations of the EDA. Even though there is no guarantee of finding the global optimum, our experiments show that the hybrid optimizer delivers the global optimum in 100% of the cases. The general description of the EDA method is shown in Algorithm 2, in step 4, the objective function evaluation refers to applying the Dogleg using each point in the population as a starting point, then, the smaller the norm of the function in Eq. 12, the better the individual (starting point) is.
The selection method in step 5 refers to the truncation of 50% of the population with the worst function values. The re-computation step in 6 means the estimation of the mean and covariance matrix of a multivariate Gaussian model by using the remaining individuals after truncation. The initial probability model is a uniform distribution, assuming that initially we do not have information about the optimum location, and such information is inferred through the iterations.
EDA implemented with Dogleg algorithm

4. Experiments and Results
Our proposal has as its main objective to reduce the human intervention dependency of the optimizer, by sampling random points as starting points of the Dogleg algorithm. Thus, the local Dogleg optimizer is turned into a hybrid global optimizer which uses an EDA and the Dogleg. The EDA's main function is to learn about and use the best regions in the search space to sample random points in order to reduce the computational cost. Notice that we can draw random points using a uniform distribution, but using this strategy means that there is no preference for any region in the search space and the algorithm does not learn how to draw better points. On the other hand, we expect that the EDA is capable of training the parameters of the multivariate Gaussian distribution to sample intensively the most promising regions. We expect that our proposal infers the most promising regions and obtains the information needed to estimate an adequate approximation to the optimum faster than the uniform distribution.
4.1 Contrasting EDA-based Gaussian and Uniform Distributions
We contrast our proposal with another global optimizer which uses a uniform distribution to draw starting points. For our experiments we use 20 well-distributed points in the platform workspace, i.e., we want to solve the direct kinematics problem for 20 different postures of the parallel manipulator. We run the hybrid algorithm and the algorithm based on the uniform distribution100 times, and we statistically test if one of them is better (perform less Dogleg-minimizations) than the other. In other words, let us define x* as a closed approximation to the global optimum (the norm in Eq. 12 is less or equal to 1e-6). To find x, different random starting points are used and the corresponding six lengths are computed by solving the inverse kinematics (Eq. 8). Then, with these lengths a Dogleg-minimization process is run for each one, until the algorithm converges to an optimum approximation with the desired precision.
To draw the random starting points, we can utilize two different approaches:
by using a uniform distribution and
by using the EDA based on a multivariate Gaussian distribution, shown in Algorithm 2.
We contrast these two approaches according to the number of Dogleg-minimizations they need to reach the desired optimum approximation.
Let u be the mean of the number Dogleg-minimizations performed when the random starting points are uniformly generated and μ n the mean of the Dogleg-minimizations performed by the EDA proposed in Algorithm 2. Then we perform a two hypothesis test:
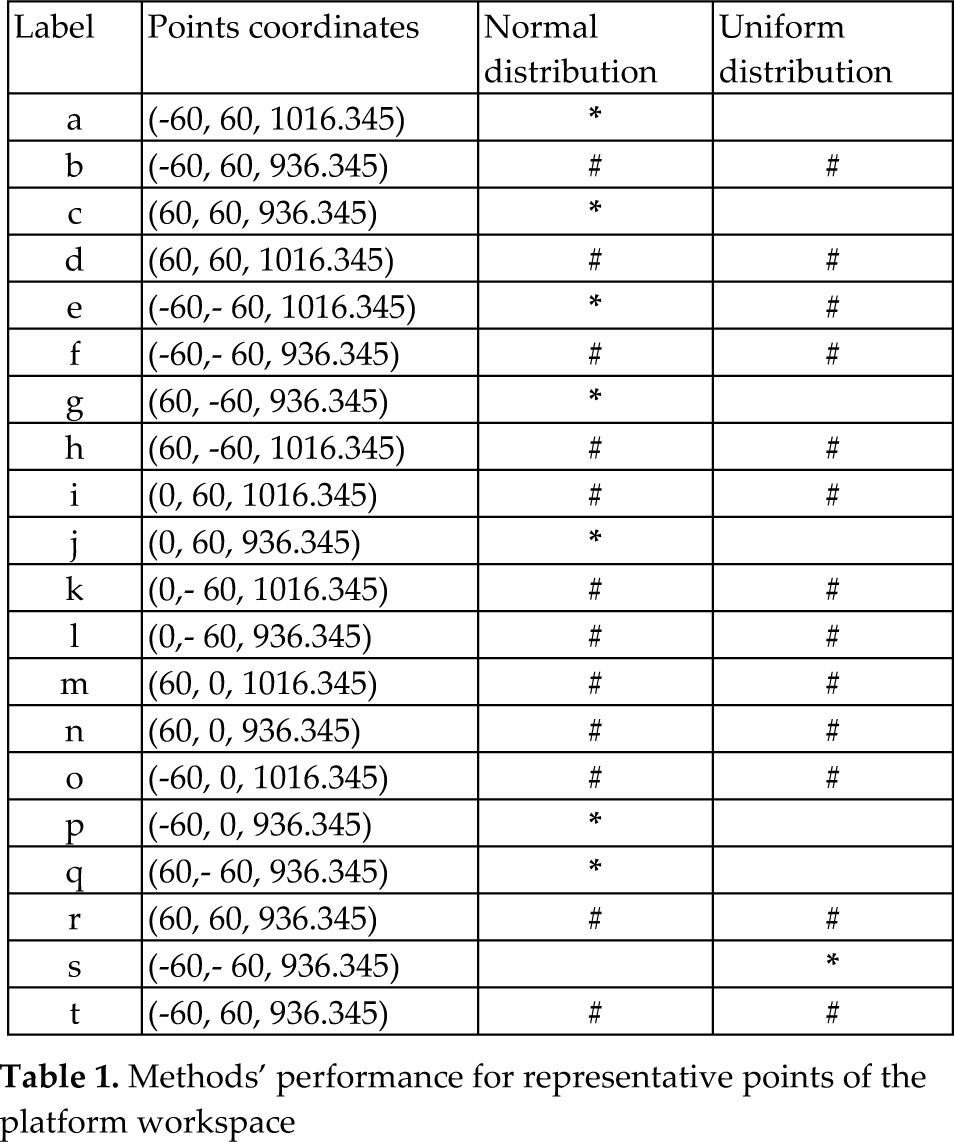
a) We test if μ u < μ n (as alternative hypothesis) and b) μ u > μ n (as alternative hypothesis). Notice that even though the tests are related, rejecting the first test does not mean accepting the second. In order to avoid assuming a given distribution for the test, we use the Bootstrap methodology [37]. The 20 points tested are labelled as presented in Table 1. We used arbitrary values for orientation parameters in each experiment. The last two columns represent the obtained results. When the decision is better made using a specific distribution (normal or uniform), the corresponding point is labelled with an asterisk (*). In the other case, when no decision can be made given the obtained values, both columns are marked with a hash symbol (#). From Table 1 it can be seen that in seven points out of 20, the normal distribution was better, whereas the uniform distribution was better in just one point. We can assume that the EDA based on a multivariate Gaussian distribution learns about some local minimizations to speed up the optimum estimation with the desired precision and even though the method does not speed up the process in all cases, we can say that (according to statistical evidence) our method will never perform worse than simply drawing uniform starting points.
Methods' performance for representative points of the platform workspace
4.2 A Numerical Example
To verify the proposed direct kinematics method explained in Section 3, we conduct numerical simulations with the following parameters for the general Stewart platform (all in mm),
The length of each leg:

The side lengths of the base platform:
The side lengths of the mobile platform:

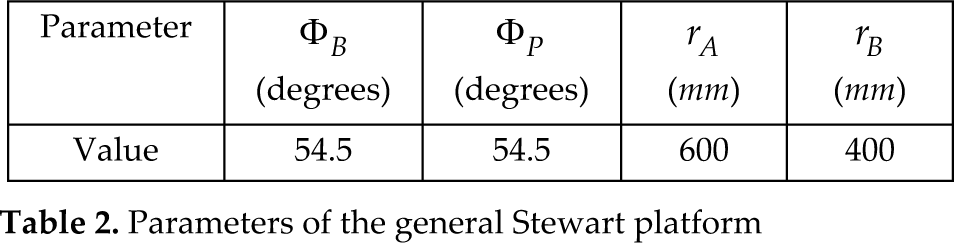
The radius of the base circumscribed in a circle and the distributing angles of the manipulator are written in Table 2.
Parameters of the general Stewart platform
Therefore, the coordinates of the joints on the base platform are:

The workspace of the platform has been defined as a cube centred at Cartesian coordinates [x,y,z] = [0,0,976.3450], see Fig. 4. Orientation angle δ has been defined as a zero constant value (degrees). In this form the elements of x˜ can be written as


A scheme showing the prescribed workspace for the Stewart platform
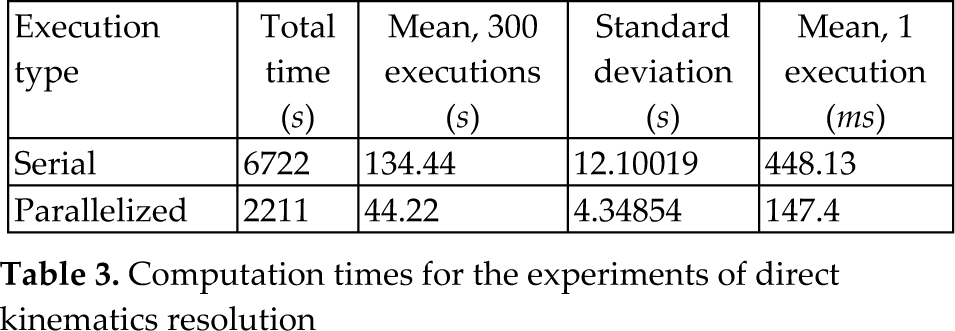
Using the hybrid algorithm described in Section 3, several experiments were run. The proposal was programmed in C and compiled with a GNU compiler. All experiments were executed in the SO Linux Open Suse version 12.1 in a CPU with 3.4 Ghz, 4 cores and 16Gb of RAM. For the hybrid optimizer, we considered two kinds of implementations, serial and parallelized executions. This code was parallelized with openMP, by executing the evaluation process using a Dogleg algorithm. In particular, serial experiments consisted of a set of 300 serial executions, repeated 10 times for statistical purposes. In the same form, the parallelized experiments consisted of a set of 300 parallelized executions which were repeated 10 times. The times of executions for experiments are shown in Table 3. From Table 3 it can be seen that by using four cores, the time for parallelized executions (evaluations with the Dogleg algorithm) is reduced 67.11% with respect to serial executions. Today, there are computers for high performance computing with 96 cores that could offer more reduction of computation times.
Computation times for the experiments of direct kinematics resolution
In order to show the proposal performance in terms of its precision, we compute the Euclidean norm of the differences between the desired pose variables (x) and the computed pose variables (x*). Figure 5 shows a mapping between the norm of pose's variables differences and the norm of the solver (desired precision of the hybrid optimizer) for the executions with serial implementation, where |x| represents the norm of pose variables differences and |f(x)| the norm of the optimizer. The norm of the solver was computed by using the Minpack enorm function [38]. The maximum precision that the solver can achieve is 2.22044604926e-16, i.e., the desired precision for all executions.
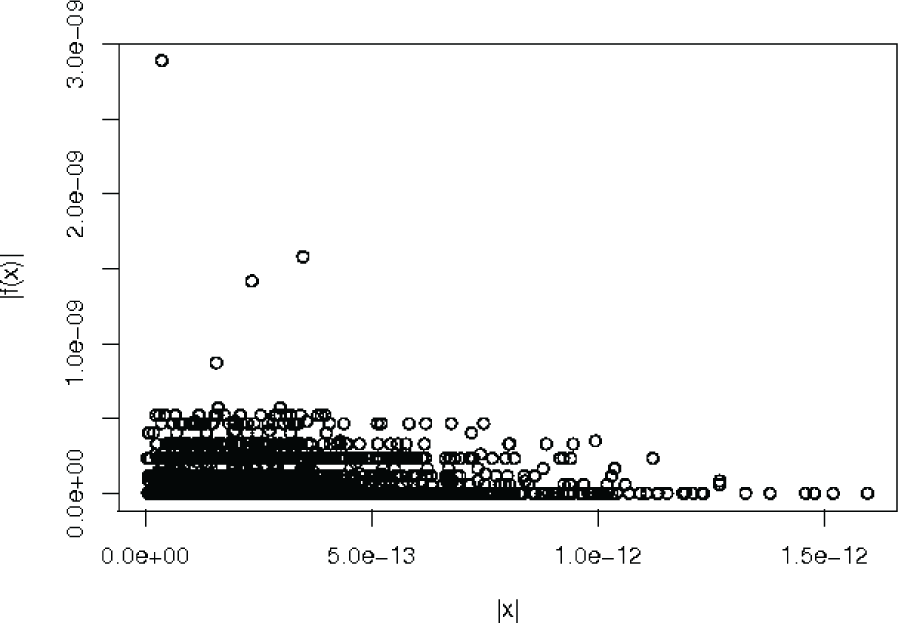
A map of the norm of pose's variables differences and the norm of the hybrid optimizer for serial implementation
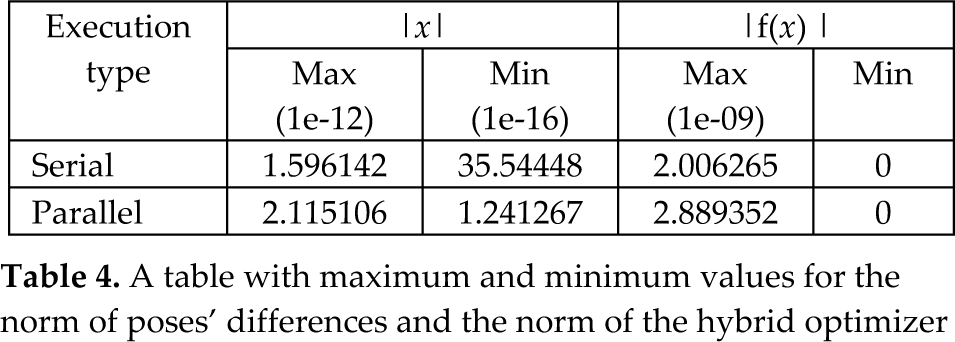
In the same way, Figure 6 shows this mapping for the experiments with a set of parallelized executions. From these figures it can be seen that the differences between the computed poses and the desired ones remain below 1.5e-12 for serial executions and below 2.5e-12 for the case of parallelized executions. In resume, Table 4 shows the maximum and minimum values for these differences, we can observe that in both cases the desired precision is achieved.

A map of the norm of pose's variables differences and the norm of the hybrid optimizer for parallelized executions
A table with maximum and minimum values for the norm of poses' differences and the norm of the hybrid optimizer
From Figure 7, we can see that the two implementations have similar dispersions and data distribution. For both distributions, 75% of data for pose differences are below 6.66e-13, approximately. In the same form, we can identify some atypical values, but these always belong to the desired range of precision.

A boxplot graph comparing hybrid optimizer precision, left for serial implementation and right for parallelized implementation
These results are confirmed by the histograms of Figures 8 and 9, for serial and parallelized experiments, respectively. From these histograms we can assume that a lot of executions for solving the direct kinematics of the general Stewart platform are achieved with a high precision (differences between the desired poses and the computed ones below 1.5e-12).

A histogram of the norm of pose differences for serial executions

A histogram of the norm of pose differences for parallelized executions
4.3 Confidence about the Global Minimum
In this section we present strong arguments about the confidence of the global optimum found by our algorithm. The first argument is about the verification of a solution once we have found it. The second argument is about exploration in order to find such a solution. The second order optimality conditions [35] state that if the gradient equals 0 in x*, ∇ F(x*) = 0, and the Hessian of the function is greater than 0, ∇2F(x*) >0. Then we can ensure that a local minimum of the function is found. These conditions are ensured by the Dogleg method used for local minimization. In addition, for this case, or in general, when solving systems of non-linear equations by intending to minimize the square norm of the error, the following argument holds: if the image of a proposed solutionis 0, that is to say F(x̂) = 0, then we certainly know that x is a solution of the system of equations because it satisfies such a system. For example, suppose a 2-variable, 2-equation system as follows: f1(x1,x2) = c1,f 2(x1,x2) = c2. The error vector is: [f1(x1,x2)-c1,f2(x1,x2)-c2]. The norm of the error is given as the function F as follows:
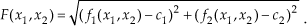
If we found such a point (x̂1,x̂2), that (x̂1,x̂2), then (f1(x̂1,x̂2)-c1)=0, and (f2(x̂1,x̂2)-c1)=0, in consequence: f1(x̂1,x̂2)=c1,f2(x̂1,x̂2)-c2. This means that we can ensure that the global solution of the system has been found. In our experiment we have verified that F(x̂) = 0; for the direct kinematics system in practice it is not easy to solve the direct kinematics, but it is easy to verify if a point x̂ is a solution. In other words, it is not easy to find x̂, but once we have verified that F(x̂) = 0 we can ensure that it is a global optimum.
The argument just stated tackles the verification of a solution when it is found; the second argument is about the exploration, when looking for the actual global optimum. Consider that the optimum (the solution of the direct kinematics) is in a “convex” region or an attractor that represents 5% of the search space, that is to say, if we can pose a point in this region, then we have found the optimum. If we sample a single candidate solution using a uniform distribution on the search space, the probability of posing such a candidate solution in the attractor region is 0.05, consequently the probability of not sampling the region is 0.95. Even though this probability is large, notice that if we sample two candidate solutions, the probability of “not” sampling the region is 0.952, if we sample n candidate solutions, then the probability of not sampling the attractor region is 0.95 npop when using a uniform distribution (the first generation of the EDA). In our examples we use npop =100 and the number of points randomly drawn is from 100 to 15000, according to the generation when the solution is found. Then, for the hypothetical example of an attractor of 5% of the search space, the probability of not sampling such a region using a uniform distribution is from 0.95100=0.00592 to 0.951500 ≈ 0. These probabilities are computed by considering a uniform distribution. In our experiments we have tested (statistically) that in most cases our algorithm performs better than a uniform distribution, therefore our probabilities of “not sampling” the optimum could be smaller than those of the uniform distribution. In the same vein, we have verified that the solution found for our algorithm is always a global minimum according the first argument of this section.
5. Conclusion
This article proposes a hybrid method to solve the direct kinematics of general Stewart platforms, which can directly generate a unique solution. The proposal combines a state of the art optimizer which is not based in derivatives which are widely used and also a state of the art optimizer for convex functions. The first one avoids becoming trapped in local minima, providing well performed starting points for the second one, which provides a high precision solution efficiently (in a convex region). The novelty of our proposal is the combination of both strategies and the use of them to solve a hard optimization real world problem. We present statistical evidence about the method in order to argue that it performs better than a “blind search”, that is to say our method performs better than using random starting points. Notice that this is quite important if we are looking for the automation of the direct kinematics solver, avoiding the need for user intervention and a priori knowledge. Additionally, our proposal is highly parallelizable, which can lead us to reduce computation time by exploiting the resources of today's high performance computers. This proposal can be used to solve non-convex global optimization problems.
Footnotes
6. Acknowledgments
The authors would like to thank PROMEP-Mexico for supporting part of this project through grant 103.5/10/5489.