
Abstract
This paper addresses the question of how to make a robot learn natural terrain selectively and use the knowledge to estimate the terrain for planning an optimal path. A scheme which combines vision learning and interaction is proposed. The vision learning module employs an online boosting learning algorithm to constantly receive and learn the terrain samples each of which comprise the visual features extracted from the sub terrain region image and the traversability measured by the onboard Inertia Measurement Unit (IMU). Using this knowledge, the robot could estimate the new terrains and search for the optimal path to travel using the particle swarm optimization method. To overcome the shortcoming that the robot could not understand the intricate environment exactly, the vision interaction method, which complements the robot's capacity of terrain estimation with the human reasoning ability of path correction, is further applied. Experimental results show the effectiveness of the proposed method.
1. Introduction
Useful mobile robots must be able to adapt to natural terrain around them and learn from experience. As soon as robots can learn and predict the traversability of the terrain well, they can effectively plan their paths.
In the literature on terrain traversability analysis, vision-based learning methods have mostly been proposed. In general, they can be categorized as supervised and unsupervised traversability learning methods according to the way learning samples have been employed. For supervised traversability learning approaches [1-3], the learning samples are manually selected and labelled with the classes that represent relevant terrain traversability, e.g., traversable and non-traversable, and the learning procedure performs in an offline learning manner. These methods have shown success on specific terrains. Nevertheless, it is difficult to find general rules which work for a wide variety of terrain types, thus the learning machine will be unlikely to work reliably in the complex unknown environment. In contrast, unsupervised traversability learning methods [4-6] use learning samples which are acquired online by the robot. Meanwhile, such learning samples are associated with class labels according to the terrain traversability obtained from the real-time analysis of sensor data. These methods enable the robot to exploit its experience in the navigation process autonomously. However, these methods assume that the equipped sensors on the robot should perceive the terrain accurately and the terrain traversability should be assessed with appropriate class label. The complexity of the real environment increases the number of learning samples with incorrect class labels and decreases the precision of the learning machine.
To the best of our knowledge, little research has been dedicated to terrain analysis and path planning by complementing the robot capacity of terrain estimation with the human reasoning capability of path correction. In this paper, we propose a novel scheme which combines vision learning and interaction to navigate the robot safely and to facilitate selective learning by the robot.
The remainder of the paper is organized as follows. In Section 2, an overview of the proposed method is presented. Section 3 introduces the details of the vision learning method, including visual feature extraction, terrain traversability assessment and online boosting learning. In Section 4, the process of vision interaction is described, in particular, the selective learning procedures are given. Section 5 presents the extensive experiments. The concluding remarks are given in the last section.
2. System Overview
As depicted in Fig. 1, the proposed mobile robot path planning method consists of two main modules, namely: vision learning and vision interaction. In the vision learning module, when given a sub terrain region, the vision features are extracted and the terrain traversability is also calculated. The vision features and the terrain traversability form a sample that is then used for getting a classifier by the online boosting learning algorithm. After a period of study, the robot could estimate the terrain using its own knowledge. Furthermore, several path planning algorithms can be employed and executed according to the terrain analysis results. Nevertheless, at the start of vision learning, there are not enough samples to be trained and the terrain estimation results are thus not reliable. The path planning procedure should mainly rely on the human guidance procedure. It also should be noticed that human guidance is necessary even when the robot has learned various terrains over a long period of time. This is based on the consideration that the real environment is intricate and unpredictable, and the robot should perform continuing selective learning under human guidance. The terrain estimation and human guidance procedures supplement each other in the evolving vision learning process of the robot. We name their mutual effect as vision interaction.
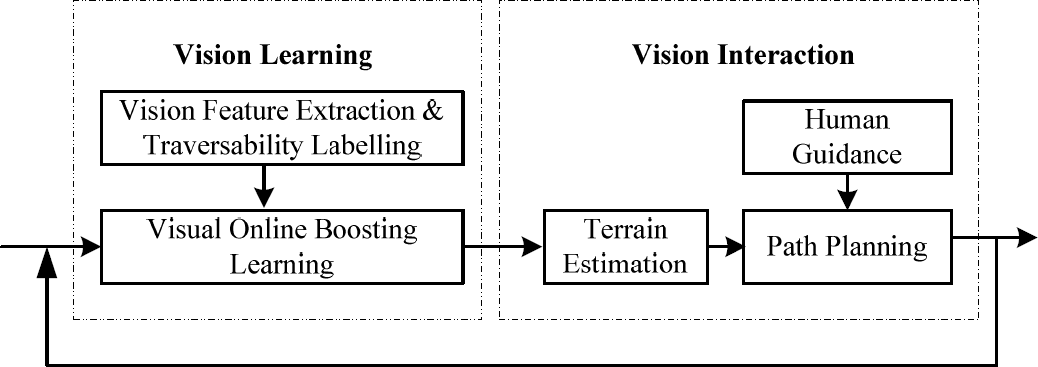
The framework of the proposed method
3. Vision Learning
The main task of vision learning is to learn the traversability of a sub terrain region to travel from the corresponding image region. A sub terrain region means a small portion of the actual terrain [7]. Once the corresponding image region of a sub terrain region is determined, the visual features could be extracted. The class label which represents certain traversability should also be associated with the visual features for the successive learning procedure. The details are illustrated in the following sub sections.
3.1 Visual Feature Extraction
For visual feature extraction, the terrain image should be divided into a finite number of image regions. However, most research is focused purely on how to segment the image, typically using the methods of patch and superpixel segmentation. The performances of these two methods in traversability classification are discussed in [8]. At their cores, the position and size of the sub terrain region are not fixed and always unpredictable. In our opinion, the visual features can be directly extracted from the image region which represents the sub terrain region with fixed position and size. This will also bring us advantages in path planning. Therefore, we propose a novel method to segment the terrain image. As shown in Fig. 2, this method finds the mapping relationship between the given sub terrain region and the corresponding image region.
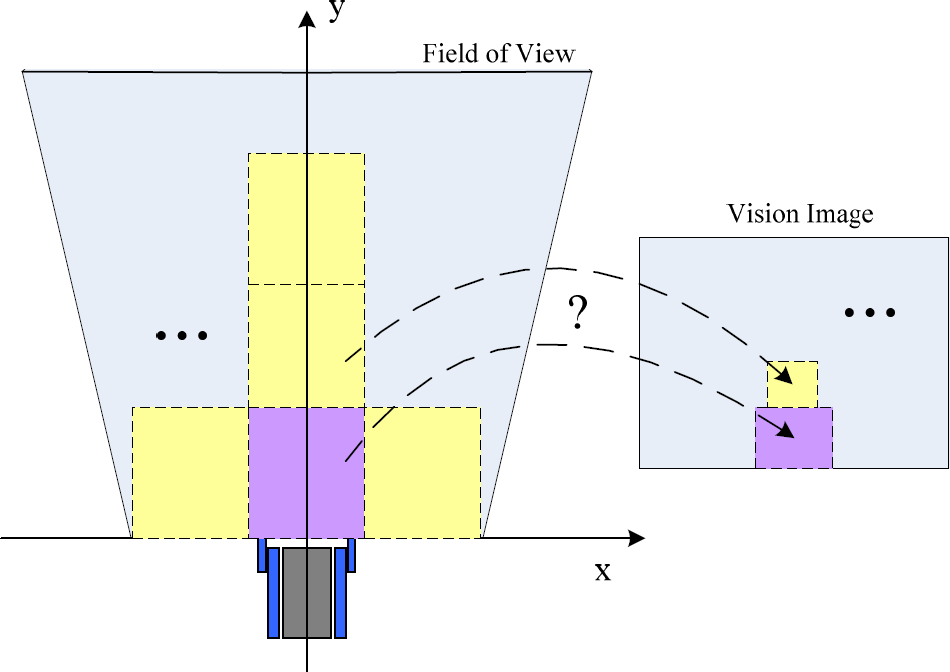
The problem of segmenting the terrain image
As we know, the field of view of the robot is closely related to the geometric model of the camera. In our work, the geometric model is built as in Fig. 3. The camera is installed on the robot at height h and pitch angle θ, so the optical axis o c intersects with the ground, where o denotes the optical centre of the camera, and c denotes the image centre. The length of o c represented as f is the focal length of the camera. Suppose the coordinate of pixel c is (uc, vc), the coordinate of pixel a which is the imaging point of any ground point A(x, y) is (ua, va), and the physical size of any pixel along x and y axes is (sx, sy). By using the pinhole imaging theory, the coordinate transformation between the image pixel and the real ground point is then obtained as follows:
The geometric model of the camera

where f, sx and sy can be obtained from the camera datasheet or the camera calibration process, while h and θ be obtained through direct measurement.
Hence, given the four corner coordinates of any sub terrain region, the corresponding image region could be easily determined by Eq. (1). This procedure is repeated until every sub terrain region in the field of view is processed. This also means the terrain image segmentation is finished.
Subsequently, various vision features can be easily extracted from the corresponding image region of a given sub terrain region. These vision features include colour, texture, v-disparity [1], etc. In this work, we use colour features, such as average RGB and grey values, and texture features such as energy, contrast and entropy.
3.2 Labelling with Traversability
For describing the traversability of a sub terrain region where the robot travels, we extend our previous work [9] and employ five types of measure values including the angles of roll and pitch, the angular acceleration of roll and pitch and the acceleration of gravity to describe the robot attitude associated with the terrain traversability at a sampling time. The five type values are measured by the IMU inside the robot and represented as follows:
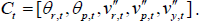
Furthermore, the measure values can be accumulatively sampled when the robot travels the sub terrain region. The overall robot attitude is calculated by

with σ(x) =
Finally, the traversability of a given sub terrain region is assessed by the normalization:

where C0 and Cmax denote the overall robot attitudes when travelling the most flat and uneven terrain, respectively. It can be seen that the larger the value of the traversability, the more difficult it is to travel the sub terrain region.
3.3 Online Boosting Learning
Owing to the complexity and unpredictability of terrain, visual learning should be a long-term process of knowledge accumulation. Therefore, the robot should possess the online learning ability in order to constantly enrich its own knowledge. The online boosting learning algorithm based on feature selection [10] is adopted. The main characteristic is that the fixed number weak classifiers in the online learning process are all updated by using only one sample, while the updating procedure is not directly applied to the weak classifiers but to the selectors.
In the robot navigation process, the terrain samples can be collected continually. One sample is formed by the visual features and the traversability of the first sub terrain region in front of the robot. Once one sample obtained, it is then used for the online boosting learning procedure. The sample collecting process is described in Fig. 4.

The sample collecting process
4. Vision Interaction
Due to limitations with regard to environment perception, incorrect terrain samples are always learned by the robot. This means that the robot studies in the manner of unquestioning learning, rather than selective learning. Therefore, we propose employing vision interaction to promote the ability of online selective learning for the robot and to navigate the robot safely. In addition, vision interaction is not the goal, but a method of facilitating selective learning for the robot. In our case, the vision interaction comprises two procedures: terrain estimation and human guidance.
4.1 Terrain Estimation
Terrain estimation is considered one of the independent abilities of the robot. When the robot tries to plan a feasible path to travel, it takes the photo in the field of view. As to any sub terrain region, the vision features are extracted, and then the classifier trained by the online boosting learning method is employed to calculate its traversability with the vision features. Subsequently, the path planning is utilized to find a set of such sub terrain regions with minimum total traversability while taking the real distance into account. The path planning problem becomes the following optimization problem:

where
Path planning using particle swarm optimization

where d(•) and ρ(•) are the distance and traversability measurements from zi,d to zid+1. All of the particles fly through the problem space by following the current optimum particles. In our case, each dimension of a particle should fly horizontally with its own range constraint zi,d ∈ [zi,dmin, zi,dmax], d = 2,…,n – 1. In addition, zi,1 denotes the initial position of the robot, while zi,n denotes the local target position. After a finite number of iterations, the global optimal position of the particle swarm is the best solution which represents the optimal path to travel.
4.2 Human Guidance
Once the robot plans a path based on terrain estimation, the path could be overlapped with the captured terrain image and displayed to the operator, and meanwhile the robot requests human guidance. When the operator finds that there are some unreasonable or infeasible sub terrain regions in the planned path, the operator could reset the position of the sub terrain region by human robot interfaces, i.e., dragging the region in the touch screen by hand. The operator corrects the path by taking the complex environment the robot could not understand into account. This procedure combines the advanced reasoning capabilities of the operator with the local autonomous capacities of the robot efficiently. Nevertheless, as mentioned above, vision interaction is utilized to facilitate selective learning for the robot. After the operations of human guidance, the selective learning procedure which consists of two parts is executed. Firstly, let zi,d and zi,d be the sub regions before and after correction respectively, we deduce that the traversability of zi,d denoted as ψ(zi,d) which is estimated by the robot is not right and is less than ψ(zi,d). Therefore, we adjust the traversability of zi,d as ψ(zi,d) = ψ(zi,d) + η, where η is an empirical value, we set, η = 0.05. Then, the visual features and the new adjusted traversability of zi,d form a new training sample which is learned by the robot. Secondly, the robot captures and learns the samples according to its computing load by using the method as described in Section 3.3, when navigating along the corrected path.
5. Experiment
The proposed method has been applied on the mobile robot [11] designed by ourselves for real terrain tests. The robot is propelled by tracks and carries a CCD camera on top and the IMU (Crossbow VG400) inside. The size of the robot body is 73cm × 55cm. The former is length, while the latter is width. The size of a real sub terrain region is then set to 100cm × 80cm. The CCD camera with 1/4 inch size and 3.6mm focal length is installed on the robot for terrain sensing at the height h = 50cm and the pitch angle θ = 22 o . The terrain image resolution is 768 × 494, so we get (uc, vc) = (384,247), sx = 3.2/768 mm and sy = 2.4/494 mm. By using Eq. (1), the field of view could be further calculated. The four corner coordinates of the trapezoid view are (±3.39m,8.02m) and (±0.33m,0.33m), and the blind distance is 0.59m. Subsequently, the number of sub terrain regions in the field of view is set to 7 and the dimension of a particle which represents a possible path is 9. The flying range of each dimension [zi,dmin, zi,dmax], d = 2,…,8 could also be easily computed by Eq. (1). The developed human robot interaction interface which is used for human guidance is shown in Fig.6.

The human robot interaction interface
5.1 Online learning under human guidance
At the beginning stage of vision learning, the path planning depends completely on human guidance. The operator plans the path for the robot using the human robot interaction interface. When the robot navigates along the planned path, it captures the terrain image in the field of view, e.g., Fig.7 shows a captured terrain image. Then, the image region of the first sub terrain region in front, denoted by white lines as shown in Fig. 7, is only used for vision feature extraction.

A captured terrain image
Accordingly, the terrain traversability is calculated using the measure values of the robot attitude as shown in Fig. 8. Furthermore, the formed sample is then applied for online boosting learning. The overall procedure is repeated until the robot has a preliminary and good understanding of various terrains.

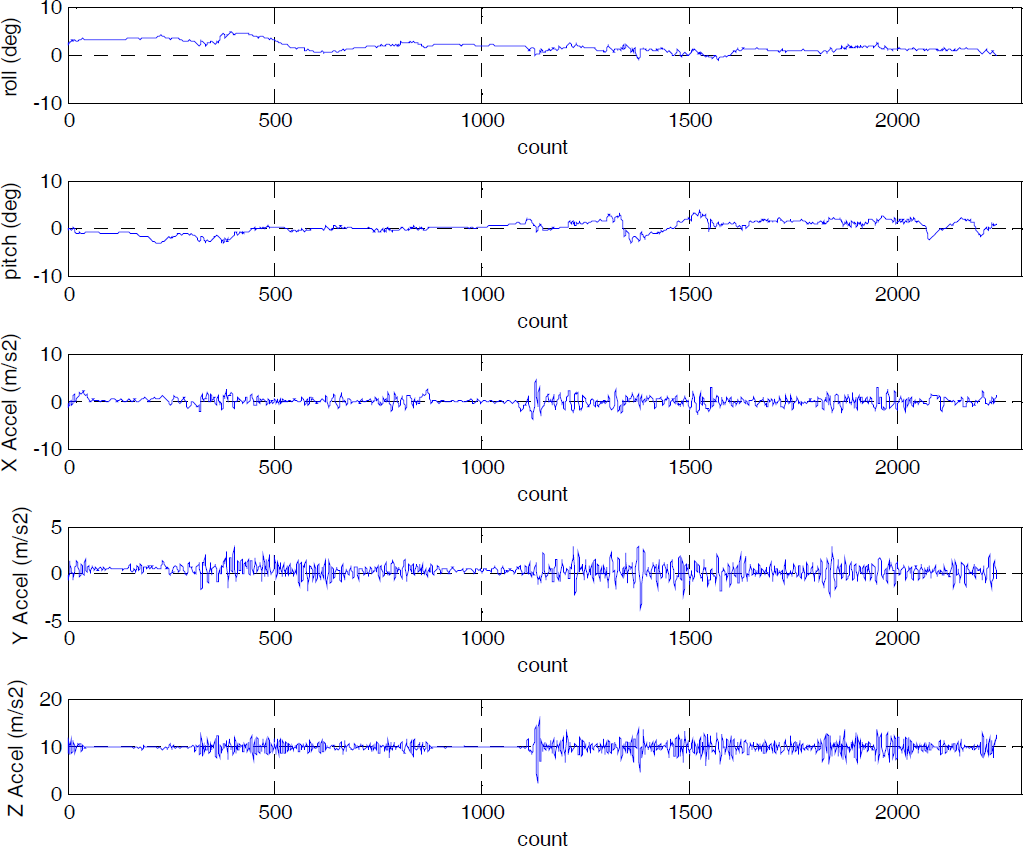
The measure values of the robot attitude
5.2 Path planning based on terrain estimation
The path planning experiments are performed on many real captured terrain images on condition that the robot could estimate the traversability of a given sub terrain region only by the vision features. Fig. 9 shows a real terrain image for path planning. The local target is set to the region in the distance.

A real terrain image with random particles
Firstly, a list of particles with total number 50 is randomly initialized. Each particle represents a possible path and each dimension of a particle represents a real sub terrain region. Thus, as shown in Fig. 9, the random particles could be visualized on the terrain image.
In Fig. 9, only five particles are displayed. Secondly, as to any particle, the traversability of each dimension is dynamically and efficiently estimated by the learned classifier. Then, the fitness value of each particle could be computed by f(

The path planning result

The fitness value change curves
5.3 Autonomous navigation based on vision interaction
The test field for autonomous navigation, as shown in Fig. 12, is mainly covered with rubble, sand, bricks and other obstacles. The navigation task is that the robot should travel from the start position to the goal position autonomously.

The test field for autonomous navigation
Firstly, the robot turns toward the goal and captures the terrain image as shown in Fig. 13(a). The path planning procedure based on terrain estimation as described in Section 5.2 is then performed. The path planning result is also displayed on the figure. The planned path shows that the robot could keep away from the frontage bricks effectively. However, the robot could not predict the sub terrain region covered with deep sand based on its own knowledge. This terrain region is denoted by the yellow lines as shown in Fig. 13(a). This will bring about a potential security risk in that the robot may slip and even get stuck in the sand. Therefore, the operator corrects in a timely fashion the planned path using the developed human robot interaction interface. The corrected path is shown in Fig. 13(b). Subsequently, the robot could travel to the goal following the path through the method of inertia navigation. At the same time, the selective learning process described in Section 4.2 is initiated. The entire navigation process is shown in Fig. 14. During the navigation process, the five type values are measured by the onboard IMU and shown in Fig. 15. It can be seen that the robot travels to the goal successfully by combining the terrain estimation ability and the advanced reasoning capabilities of humans, while the robot attitude varies smoothly during the overall navigation process.

The planned path (a) and the corrected path (b)

The navigation process based on vision interaction including (a), (b), (c) and (d)
The planned path (a) and the corrected path (b)
6. Conclusion
This paper has presented a path planning method for autonomous navigation by combining vision learning and interaction. The vision learning module employs an online boosting learning algorithm to constantly receive and learn a new sample which is comprised of visual features extracted from the sub terrain region image and the terrain traversability measured by the onboard IMU. The vision learning procedure makes the robot expand its knowledge through continual learning and then independently plans the path to travel based on terrain estimation and particle swarm optimization. During the travelling, the robot could perform the vision learning procedure again, however, this is done by unquestioning learning, rather than selective learning. The vision interaction method is proposed to supplement the terrain estimation capacity of the robot with the reasoning capability of the operator. Under human guidance, the path planned by the robot is corrected according to the real situation. Then, the navigation process is performed and meanwhile the selective learning procedure is initiated. Experiments show that the robot could understand the environment in front well and plan a feasible path under human guidance, effectively avoiding the uncertainties such as violent vibration, slip and even shut down when travelling on intricate terrains. Future work will comprehensively evaluate the efficacy of the selective learning method and improve the efficiency of the developed algorithm.
Footnotes
7. Acknowledgments
This research is made possible with support from the Science Innovation Programme of the Chinese Education Ministry (no. 708045) and Nature Science Foundation of Jiangsu Province under grant (no. BK2009183).