
Abstract
This paper presents a novel approach for a quantitative appraisal model to identify human intent so as to interact with a robot and determine an engagement level. To efficiently select an attention target for communication in multi-person interactions, we propose a fuzzy-based classification algorithm which is developed by an incremental learning procedure and which facilitates a multi-dimensional pattern analysis for ambiguous human behaviours. From acquired participants' non-verbal behaviour patterns, we extract the dominant feature data, analyse the generality of the model and verify the effectiveness for proper and prompt gaze behaviour. The proposed model works successfully in multiple people interactions.
Keywords
1. Introduction
It is of great importance for a robot to understand the complicated social behaviours of humans and properly respond to them. Social factors, such as information usability, dialogue preference, social acceptance, societal impact, intimacy level and user experience, affect human-robot interaction (HRI). To appropriately manage context awareness in the current situation, an intelligent robot system is required to evaluate external perception and internal inference, as well as the determination of holistic information for social factors. As a communication partner, a situation associated with interaction can be represented by a user's mood or intention, the spatial distance between humans and robots, the correlation with other users and current conversation states. In particular, human intention in human-human communication refers to a human agent's mental determination to act in a certain way and a psychophysical approach with functional neuroimaging reviewed evidence that human agents possess the ability to infer other people's intentions by observing their actions [1].
For understanding a human's intention from communication signals, some studies report that it is necessary to know the following information: human verbal and non-verbal behaviour [2, 3], spatial relationships [4] and prior knowledge of the other participant as well as communication skills [5]. We can see the importance that gaze direction in human face-to-face communication serves in shifting roles during turn-exchanges [6].
As one of the most salient signals in HRI, gaze cues can also be effective in shaping the participant roles of conversational partners [7] and the selection of a conversational attention target to exhibit gaze behaviour is surely needed in the presence of multi-person interactions. Other studies propose that computational methods managing the engagement process in dynamic interactions with multiple people are required for detecting whether or not the engaged participants are actively maintaining conversational engagement [8, 9]. An emerging egocentric interaction paradigm based on perception, action, intention and attention capabilities, as well as a lack of human agents, also supports these essentialities [10].
On the other hand, multi-modal interfaces have the potential to improve the usability and accessibility of communication flows, including human activities, and supplement single sensory limitations. The use of multiple HRI modalities in the engagement mechanism with the levels of interaction engagement is proposed in [11]. The multi-modal anchoring approach also shows a schematic example for anchoring a person through anchoring component symbols to their associated percepts with the symbolic level and sensory level [12]. Accordingly, the data acquisition of human activities using multiple sensors plays an important role in the delivery of efficient human communication.
In this paper, we would like to focus on establishing a solution that judges the engagement levels of multiple people by analysing a fuzzy-based human engagement model and multi-dimensional human behavioural features. The empirical evaluation of the proposed fuzzy model, which is developed by a learning procedure of the dominant human behavioural patterns, is utilized to quantitatively classify the uncertainty of human intent so as to interact with the robot. For analysing the generality of the model with individual peculiarities, we perform a quantitative fuzzy region analysis for each participant's activity through the communicative process and verify its effectiveness from the selection of the communicative attention target from among multiple people.
This paper is organized as follows. Section 2 introduces human activity analysis, Section 3 describes the FMMNN algorithm, Section 4 deals with the evaluation of a fuzzy-based human engagement model, Section 5 presents gaze behaviour among multiple people and, finally, in Section 6, conclusions are drawn and future work is outlined.
2. Human activity analysis
2.1 System configuration
Humans may understand the other party's intention through interpreting various forms of non-verbal behaviours during communication. To observe these behavioural characteristics, we configure the following robot system.
An intelligent robot platform - namely MERO - is mainly designed to provide cognitive services to mentally disordered people. It currently provides healthcare for the elderly, educational assistance at elementary schools, and interactive contents in the reception and entertainment events. With respect to HRI, we have the following robot system configuration: a webcam on the robot head, four microphones on the base, a 3D depth sensor located at a certain distance from the robot along the Z-axis in order to detect multiple people and track each person's trajectory easily through a large sensing range, a 4-DOF neck and 17-DOF face modules (eyebrow, eyelid, pupil and lip). Fig. 1 illustrates the configuration of the robot.

System configuration of an interactive robot.
2.2 Multi-modal cues
To acquire human behavioural features, each attached sensor has the following characteristics (see Fig. 2). Four microphones were used in the auditory system, which combined the sound source localization (SSL) and a multichannel Wiener filter (MWF). The SSL is an algorithm which estimates the direction of a speaking person using time delay of arrival (TDOA) among the microphones [13]. We also used a DSP-based embedded system. The MWF and SSL are incorporated in this DSP system. To detect sound direction reliably, a post-process using a histogram is applied to achieve robust sound localization [14].

Feature extraction process from multi-modal sensors.
A vision sensor easily estimates face location and face recognition for multiple people through a variety of vision algorithms in complex environments. To make a unique ID - such as a person's name - for each human model, we applied an illumination-robust face recognition using the statistical and non-statistical methods proposed in [15]. For verifying users' identities, it compares the feature histogram of the current facial image and the pre-registered information for each person (namely, a gallery). The recognizer can guarantee an identification accuracy of around 82%, even in a situation in which a robot head-camera dynamically moves to express its behaviours or track the human. Further detail on face recognition can be found in [15] and [16].
We also recognize the current emotional state of the people by pre-processing a facial image with a neural network and obtain four facial expression states (smiling, surprised, neutral and angry states) with recognition reliability from the current user's facial expression through the pre-trained weighting factor.
As a spatial modality, the 3D depth sensor provides valid data to measure the 3-dimensional distance of labelled moving objects by creating a depth map clustering, and interpret specific gestures by major joint angles in the kinematic model. To get the human position and posture data, we use the OpenNI library [17]. The library provides a moving object's location and 24 elements of skeleton position data. From the library, we developed the following perception information: human's movement patterns (approach, depart, sideways and stop) are analysed from the velocity and direction of moving objects with a naive Bayesian filter, while human gestures (standing, waving and nod) and physical information (human height, shoulder width, limb length, etc.) were easily estimated using the velocity of each skeleton point and the linking vector between skeleton positions.
2.3 Feature extraction
Human behaviours are divided into five categories: oculesic, kinesic, proxemic, vocalic and tactile behavioural features [18]. Each behaviour has dominant features that are commonly observed in human-human non-verbal communication. These features are utilized in human-robot communication to estimate a human's intimacy [19].
As shown in Table 1, we defined 8 dominant features in the 4 behavioural characteristics to inquire as to the dominant cues for analysing the engagement level. Each feature represents the perception information extracted by the multi-modal cues. These features do not represent all human senses and they have performance restrictions. Nevertheless, we believe that they can be significantly utilized to estimate the interaction intent of humans.
Non-verbal features based on behavioural factors
2.3.1 Oculesic feature
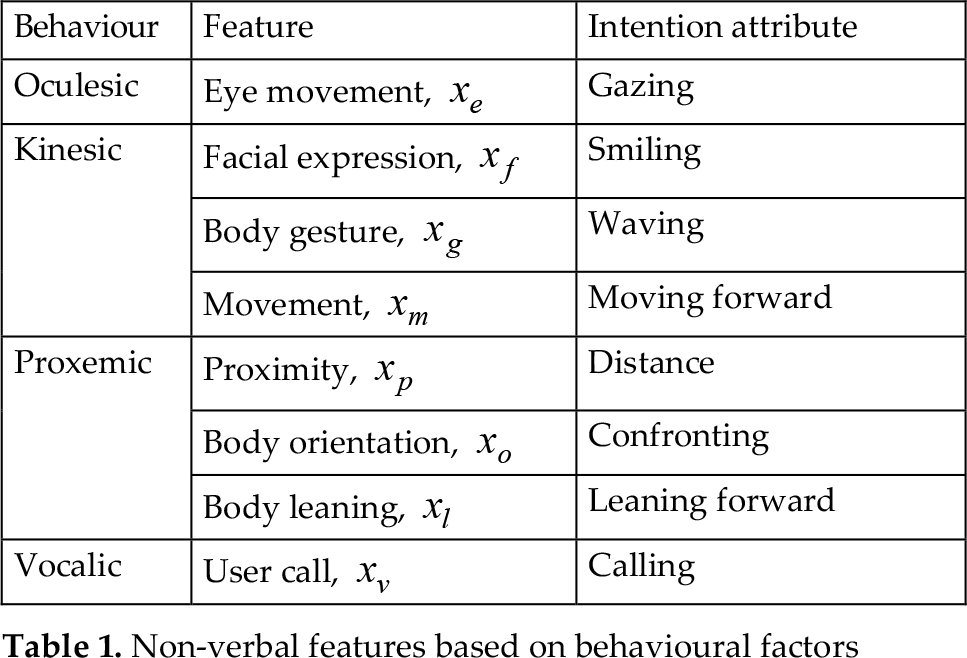
Oculesic features are measured by averaging the mutual gazing time of each eye movement between a human and a robot during the perception time. To perform human eye tracking and eye contact with the robot is not easy. Instead, we estimate the human's gazing time by using face detection while a robot looks at the user as follows.

where e(s) ∈ {gazing, not gazing} is the frontal face detection and T is the perception time.
2.3.2 Kinesic feature
Kinesic features are measured by recognizing facial expressions, human movement and body gestures. Facial expressions consist of four states, as mentioned before, and each reliability value is obtained from the neural net output. To make a normalized value between 0 and 1, smiling adds a positive value and the rest of the expression adds negative values.

where f (Ip) and f (In) represent the positive and negative reliability value.
As shown in Fig. 3, the human information about the 15 body components in terms of 3D coordinates allows us to locate various structural feature points around the body. We assume that a waving feature can be easily estimated by tracking the skeleton data of the human body, as follows:

The 15 body components.



where
From the spatial trajectories of the human, we can also calculate the human movement features by applying the moving velocity and direction of the people:




where
2.3.3 Proxemic feature
Proxemic features are easily measured by averaging the spatial distance between a person and a robot, body orientation and the angle of body leaning. To describe an appropriate spatial relationship between intimate people and in order to perform effective communication, each personal (≤ 1.2m), social (≤ 2.5m) and public (≤ 3.5m) space proposed in [20] is assigned according to the radius. As a feature value, the average distance for the perception time is compared with each predefined space:

where dp is the spatial distance, Dpersonal is the radius of personal space, and Dsocial is the radius of social space.
As shown in Fig. 4, we can also estimate body orientation and the angle of body leaning by tracking the 3D skeleton point vector of the neck

Proxemic feature extraction in 3D coordinates. (a) Body orientation and (b) body leaning angle.

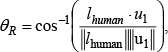

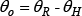




where
2.3.4 Vocalic feature
Vocalic features are measured by estimating the direction of a speaking person with TDOA and their spatial location. We assumed a designated person to be a speaker if a sound signal (sTDOA) is detected in azimuth for the human location:

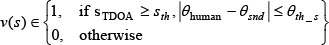

where θhuman is the human relative angle for a robot, sth is the threshold value of a TDOA signal, θsnd is the sound azimuth and θth_s is the threshold value of the azimuth.
3. FMMNN
In this section, we propose a method to assess engagement level using the fuzzy min-max neural networks (FMMNN), which is characterised by a nonparametric classification, a simple learning method and incremental parameter tuning [21, 22]. We applied the proposed model for the following reason: it explicitly provides quantitative design criteria with fuzzy regions so as to determine the human's interaction intent, and facilitates the multi-dimensional analysis of the extracted numeric feature data as a powerful pattern classifier. The feature values are transformed to the quantifying membership value by fuzzy composition rules.
3.1 Algorithm description
A fuzzy hyperbox membership function plays an important role in the fuzzy min-max classification. As a fuzzy set, hyperboxes are defined by pairs of min-max points. Following [21], let the jth hyperbox fuzzy set (Bj) be formally defined by the ordered set:

for all h = 1,2, …, m, where Xh is the hth input feature, Vj is the min point and Wj is the max point for the jth hyperbox, and the membership function for the jth hyperbox is 0 ≤ b j (Xh, Vj, Wj) ≤ 1. Following [22], to meet the required criteria, a membership function is defined as:
where
An implementation of the neural network is shown in Fig. 5. It has a three layer feedforward neural network: input, hyperbox and class nodes. The connections between the second- and third-layer nodes are binary values stored in the matrix U. The equation for assigning the values of matrix ujk is:
The three-layer neural network which implements a FMMNN classifier.

where bj is the jth second-layer node and ck is the kth third-layer node. Each third-layer node represents a class. The output of the third-layer node represents the degree to which the input feature Xh fits within the class k. the transfer function for each of the third-layer nodes is defined as:
3.2 FMMNN learning procedure
To create a fuzzy hyperspace for reading human intention, the following input feature vectors should be trained by the FMMNN. The training data D consists of a set of M ordered pairs, namely:

where xi(h) is the normalized value of the ith feature vector at a perception time h and dh ∈{c0, c1} is the index of one of the class layer nodes.
We set a total of 7 feature vectors as input nodes. The outputs of the class layer nodes are defined by an engagement term with two classes of an inattention (c0) and an attention (c1) attitude and were classified by the following learning algorithm. Fuzzy min-max learning has an expansion/contraction process with four steps and repeats steps 1 to 4 for the two classes by turns:
Step 1: Extract the behavioural feature values from the perception information during a perception time T.
Step 2: Search the hyperbox that can expand and then expand it when it has expanded. If there is no such hyperbox, add a new one.
Step 3: Find overlaps between hyperboxes from different classes.
Step 4: Adjust between overlapped hyperboxes to eliminate it.
Two classes can be fuzzified by hyperbox membership functions to quantify fuzzy regions for behavioural features, and we can determine the class for the engagement level by winner-take-all rules, as shown in (25). As can be seen in Fig. 6, a fuzzy hyperbox membership function can also represent these fuzzy classes on a one-dimensional feature axis.

Fuzzy hyperbox membership function with the inattention and attention classes.
The membership values for the class are de-fuzzified to the appropriate engagement values by fuzzy min-max composition rules from multi-dimensional features, as described in:

engagement value, i is the number of ith feature, N is the feature dimension size andb(xi, c) is the membership function of class c for the ith feature. The engagement values are acquired from the membership function having maximum values by the min operation. Finally, we can evaluate a quantitative human intention interacting with the robot by numerical values.
3.3 Learning human model from the HRI
To acquire the training data set of M ordered pairs {Xh,dh} for two classes, we conduct an interaction scenario with a turn-taking procedure. As shown in Fig. 7, the main communicative process of the HRI consists of six steps, as follows:

Communicative process for acquiring a human model.
Step 1: A robot starts from idling mode when no one is present.
Step 2: Once a user appears, the robot detects a spatial location for the participant, begins the behavioural percepts from multi-modal sensors and induces the participant to come up to the robot.
Step 3: While analysing the dominant behavioural features for the participants who are not identifiable, face recognition is used to determine whether or not to register once.
Step 4: Once checking user registration, the robot simply makes an acknowledgement and greets based on the personal information for each identified person.
Step 5: After finishing the user identification for the participant, the robot establishes a simple dialogue strategy, including the participant's vocal response, in order to perform turn-taking with ten consecutive questions.
Step 6: For the whole communicative process through the two attention and inattention classes, the robot observes human activities in each turn-taking procedure and identifies each user's intention from the behavioural features of the human.
The turn-taking procedure in the dialogue context consists of a robot's question, the user's response and the robot's interjection flow. Questions include general knowledge, personal information and the user's current feelings through facial expression recognition. According to the user's response for the question, a robot can be represented by positive or negative interjections.
Fig. 8 shows a sample scene of the different learning procedures of a fuzzy-based human engagement model for participants' behavioural patterns.

Fuzzy-based human engagement model analysis from extracted feature cues.
4. Evaluation of a human model
Ten users participated in the learning experiment of the communicative process with 7 behavioural features. Each participant has a dialogue process with a greeting, identification and a questions game. To make a decision criteria for robot gaze behaviour, a total of 1400 elements of training data (2 classes for an engagement level, 10 participants, 10 dialog process, and 7 dominant behavioural features) were acquired in the experiment. Fig. 9 shows two fuzzy-based human engagement models with different aspects in relation to the 10 participants.

Fuzzy-based human model developed from the FMMNN learning procedure: Red colour: attention class; Green colour: inattention class.
Subject 6 in Fig. 9(a) actively expresses his intention for the attention and inattention attitude. With each dialogue in an attention class, he variously changes a gaze, a facial expression and a gesture. In the opposite class is a similar trend. In particular, for the body orientation and leaning part, he shows a positive approach by expressing frontal and forward behaviours in both classes compared with the other participants.
Subject 9 in Fig. 9(b) expresses an inactive behaviour when compared relatively with the other participants. Low activities, such as significantly less gesture, a non-frontal body leaning pose and a relatively distant location, are expressed during the conversation. Regardless of the two classes, he gazes at the robot and poses his body orientation with the frontal side.
Fig. 9(c) shows the generalized fuzzy-based human engagement model made by all the training data sets. The fuzzy boundaries of most features converse in two classes. A gesture feature shows fully dominant characteristics in order to get the robot's attention. However, movement and proximity features effects are relatively small in relation to the behavioural factors of the model.
From this result, the analysis of behavioural features in FMMNN shows clearly that the hyperboxes of each feature should be condensed and spaced between two classes and that membership values placed in fuzzy boundaries numerically represent the quantity of the interaction intent of individuals.
To validate the effectiveness of a fuzzy-based human engagement model from the feature data acquired from the 10 participants, we generate the trained model by randomly selecting 7 training sample sets while the rest are tested as a testing sample. The result demonstrates that the space is sufficient to classify the engagement level with 86.2% accuracy between two opposite classes in the scenario. Fig. 10 shows a fuzzy-based trained human model with 3 representative features of 7 participants.

Fuzzy-based human engagement model trained by seven participants.
We agree with the fact that the boundaries within many hyperboxes neither allow the clear description of the human's overall behaviours nor cover the individual peculiarities of all people. However, we assert that this fact is still useful for evaluating people's engagement levels and conversational attention, and that it forms the robot's gaze behaviour from the human behavioural analysis.
5. Gaze behaviour in multiple people
In order to appropriately perform a robot's gaze behaviour for multiple users, we assume that a robot can spontaneously select the person who stands closer than do other people from the robot if no one has interaction intent. To handle this situation as well as with multiple person interactions, a proximity ranking should be calculated according to the relative location of the people from the robot. We created the performance test of the robot's gaze behaviour for 3 participants and set it so that each participant could express their behavioural activities with discretion, as shown in Fig. 11.

Three participants' activities in the event timeline; P1 = participant 1, P2 = participant 2, P3 = participant 3, R = proximity ranking.
According to the event timeline in Fig. 11, three participants come to the robot sequentially and individually express human activities so as to show interaction intent with time intervals, and then go away from the robot in turn. We ordered the scenario so that nobody would perform an action in interacting with the robot for any moment in the event timelines 1 and 4 in order to verify gaze behaviour based upon the proximity ranking in an inattention class of the human engagement model.
Fig. 12 shows the participants' moving trajectories in accordance with the event timeline, where three people employ a number of non-verbal signals to show their engagement level. Fig. 13(a) shows the analysis of the proximity ranking and each participant's numerical feature patterns in multi-person interactions.
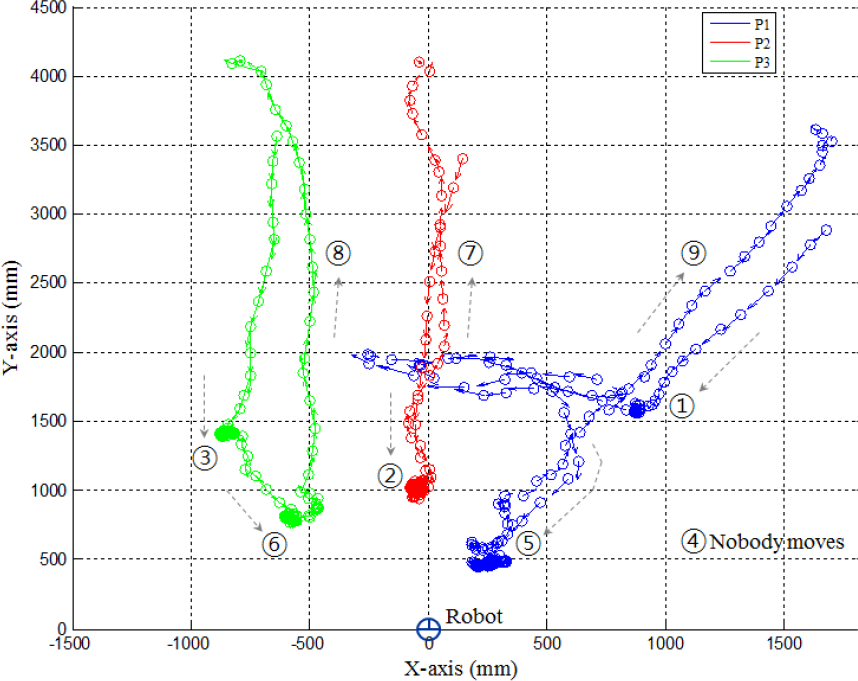
Path trajectories for three participants with an event timeline.

Gaze behaviour for the communicative attention target in three participants. (a) Analysed oculesic, kinesic, proxemic and vocalic features, and (b) Attention target selection and corresponding gaze direction.
All of the participants as a whole tried to pay more attention to that robot which talked to them rather than to another person because the robot verifies user's identity and asks questions for the corresponding personal information in a communicative process. Each participant has been selected by a fuzzy-based human engagement model analysis as a conversational attention target on three separate occasions and the robot performed a gaze behaviour with tracking of the designated person (see Fig. 13(b)).
6. Conclusion
We propose a novel approach in order to efficiently select a communicative attention target from among multiple people. Human activities are modelled from 8 dominant features in the four categories (kinesic, proxemic, oculesic and vocalic characteristics). The dominant features are extracted by multi-modal cues during the communicative process. The evaluation of a fuzzy-based human model with two engagement classes comes from the extraction of multi-dimensional human behavioural features and identifies the user's intent to interact with the robot according to the empirical evaluation of two quantitative classes. To verify the quantity for each participant's intent, we tested an engagement level by assessing the human's numerical values and performed the robot's gaze behaviour in an interaction situation with multiple people.
Footnotes
7. Acknowledgments
This research was performed for the Intelligent Robotics Development Programme, one of the Frontier R&D Programs funded by the Ministry of Knowledge and Economy (MKE) of the Republic of Korea.