
Abstract
In this paper, a stable leader-following formation control for multiple non-holonomic mobile robot systems using only limited on-board sensor information is proposed. The control can be used for the conventional single leader – single follower (SLSF) or for novel two leaders – single follower (TLSF) schemes. The control algorithm utilizes estimations of the leaders' translational and angular accelerations in a simple form to reduce the measurement of indirect information. Simulation results show that the TLSF scheme can suppress the oscillation and damping in formation of large robot teams.
1. Introduction
In recent years, control and coordination of multi-agent systems has emerged as a topic of major interest (Liu, B.; Chu, T.; Wang, L.; & Xie, G., 2008). This is partly due to broad applications of multi-agent systems in cooperative control of unmanned vehicles, formation control of swarms, where collective motions may emerge from groups of simple individuals through limited interactions. Many swarm systems, such as flying wild geese, fighting soldiers, and robots performing a task, always form and maintain a certain kind of formation according to overlapping information structure constraints (Xu, W.B. & Chen, X.B., 2008). In practice, forming and maintaining desired formations would have great benefits for the system to perceive unknown or partially known environment, to perform its tasks. In the formation control design of mobile robots, there are various control approaches such as the behaviour-based method (Lawton, J. R. T.; Beard, R. W. & Young, B. J., 2003; Monteiro, S. & Bicho, E., 2002; Reynolds, C. W., 1987), the leader-follower method (Das, A. K., et al., 2002; Gustavi, T. & Hu, X., 2008; Wang, P. K. C., 1991), the artificial potential field method (Barnes, L.E.; Fields, M.A. & Valavanis, K.P., 2009; Wang, J.; Wu, X. & Xu, Z., 2008), the bio-inspiration method (Tanner, H. G.; Jadbabaie, A. & Pappas, G. J., 2005; Warburton, K. & Lazarus, J., 1991), the virtual-structure method (Egerstedt, M.; Hu, X. & Stotsky, A., 2001; Lewis, M. A. & Tan, K. H., 1997), the graph-based method (Desai, J. P., 2002; Fierro, R. & Das, A. K., 2002), and swarm intelligence (Gerasimos, G. R., 2008; Kwok, N. M.; Ha, Q. P. & Fang, G., 2007). Among these, due to its wide domain of application and easiness to understand and implement, the leader-follower formation control problem has received special attention and has stimulated a great deal of research. In a robot formation with leader-follower configuration, one or more robots are selected as leaders, and track predefined trajectories while the other robots, named followers, track transformed versions of the states of their leaders according to given schemes.
From the leader-following formation control strategy based on a unicycle model discussed in (Das, A. K., et al., 2002), many other papers, for instance (Kang, W.; Xi, N.; Zhao, Y.; Tan, J. & Wang, Y., 2004; Tanner, H. G.; Pappas, G. J. & Kumar, V., 2004; Vidal, R.; Shakernia, O. & Sastry, S., 2003), have also treated formation control of multiple mobile robots with unicycle dynamics. A different approach, relying on the neighbourhood-based control algorithm, has been used for the formation control law in (Jadbabaie, A.; Lin, J. & Morse, A. S., 2003; Olfati-Saber, R. & Murray, R. M., 2002), and many papers that have followed them; however, this control scheme applies to linear systems only. Other researchers have proposed the use of a second-order model of the robot for SLSF scheme and used feedback, robust and adaptive control methods (Liu, S.C.; Tan, D.L. & Liu, G.J., 2007) which analyze the acceleration of the robot in detail, even if the leader has complex trajectories (straight paths, curved paths, circular paths) but the relative orientation between the follower robot and its leader robot cannot be converged to zero.
One of the latest researches is artificial force based approach (Samitha, W. E. & Pubudu N. P., 2010) has many potential real-world applications, but the assumption that agents/members have identical physical properties limits the application of this method.
Other recent researches, such as (Sun, D.; Wang C.; Shang W. & Feng G., 2009; Wang, C. & Sun, D., 2008), transfers the formation problem to a synchronization control problem, and a synchronous controller is developed to converge both the position and synchronization (formation) errors toward zero in formation switching tasks, but they used a centralized cooperative control scheme which is susceptible to bandwidth limitation as well as external disturbances and hence is not scalable for a team with a large number of mobile agents. The drawback of complexity and resource assumption in aforementioned research is also the disadvantage of using neural networks as in (Chen, X. & Li, Y., 2008).
Besides complexity of controller, another problem is that the majority of these existing results require the measurement of the leader's speed as input to the feedback controller. The reason is that the absolute velocity of the leader cannot be measured directly by local sensors carried by the follower robot and it must be estimated by positioning measurements, which tend to enhance measurement noise dramatically; therefore, the estimation of absolute speed is difficult to obtain because it is required simultaneously in all the robot's own speed controllers. The above problems motivate the contribution of this paper.
A novel approach to this problem has recently been developed by (Gustavi, T. & Hu, X., 2008), which presents dynamic feedback controllers that do not require direct measurement of the leader's speed, but instead a method to predict that speed. However, their scheme of SLSF, which theoretically does not depend on the number of robots, is still not scalable for a big group of robots due to the accumulated errors and resulting oscillations.
This paper proposes a new stable leader-follower formation control algorithm for multiple non-holonomic mobile robots systems, which utilizes both translational acceleration and angular acceleration to control the damping/oscillations and eliminates the need to measure the leader's velocity. In addition, the control law can be quickly calculated with some basic operations and uses only some information such as distances and angles, which are easily acquired by on-board sensors. A novel TLSF scheme is also proposed to take advantage of the conventional SLSF scheme in order to deal with the unwanted oscillations and the convergence rate of all followers except the first one. The algorithm is common to both SLSF and TLSF schemes so that global formation of the local control laws can be formed flexibly and stably. It is proven that all errors in the relative states will converge to zero quickly, and the TLSF formation can have a higher rate of convergence.
This paper is organized as follows. Section 2 gives the mathematical background of the problems studied and Section 3 presents the new proposed method along with an examination of its stability and parameter tuning methodology. Section 4 will have some simulation results which show the merits of the proposed control law and this is followed by a summary and conclusions which are provided in Section 5.
2. Problem Statement
2.1. Formation
We consider a group of non-holonomic mobile robots move along a desired trajectory while maintaining a desired formation. In any case and at any time, the group of robots must do two basic tasks: forming and maintaining. Fig. 1 illustrates an example where a robot team moves along a road with a requirement to maintain a pyramid formation when the road is wide enough and a sequential formation when the road is narrow. The formation is, therefore, required to switch back and forth between the two configurations. With the leader-follower formation strategy, there is defined a group leader R0 which leads the group bulk motion, and the other robots, labelled as R i (i = 1, 2, … n) are the followers that maintain the respective relationships with the group leader R0, in general. However, when the number of robots in the group is large, the relationships of some followers with R0 are hard to define due to the limitation of sensors' working range. Therefore, the definition of whole group relationships is a combination of unit relationships. Each unit contains one follower and one leader (SLSF) or two leaders (TLSF). The leaders here are local leaders, which are the robots physically close to the follower for easy sensorial connection. Hence, all robots in the group are linked, either directly or indirectly. Without loss of generality, we assume that the desired formation configurations are designed in a feasible way such that the robots can form the required formations without conflicts with each other.

Motion and formation process of a group of robots with two basic tasks: forming and maintaining
This paper focuses on the formation task control only and is neither going into the details of the formation protocols for coordinating and organizing the grouped robots to accomplish the formation task, nor collision avoidance. The environment is also assumed to be obstacle free. The problem to be investigated is formulated as follows: a group of n non-holonomic mobile robots are controlled to follow a group leader R0, which moves along a desired trajectory, and to maintain a desired form implicitly defined by the relative distance and angle between each follower and its leader (in the SLSF scheme) or the relative distances between a follower and its two leaders, as well as the relative angle with one of those two leaders (in the TLSF scheme). The SLSF and TLSF schemes are shown in Fig. 2.
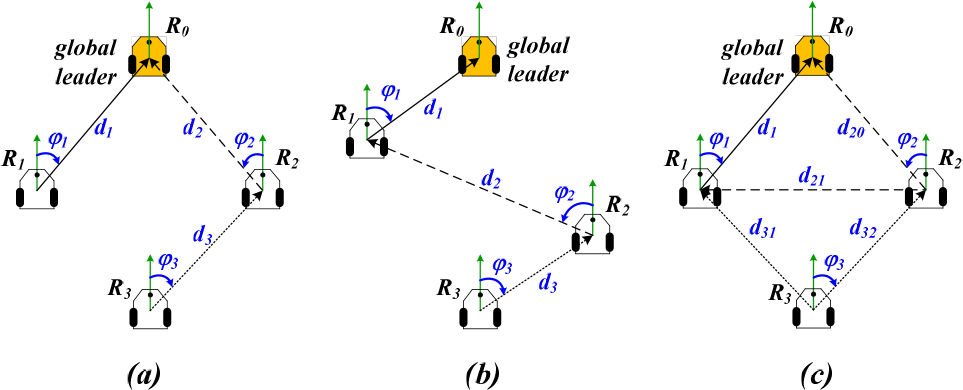
(a) SLSF scheme in diamond formation, (b) SLSF scheme in zigzag formation, and (c) TLSF scheme in diamond formation of a four-robot team.
In Fig. 2, the robot R i (i = 1, 2, 3) must keep a relative distance d i and a relative bearing angle φ i with its leader in SLSF scheme. Robot R2 and R3 can have many choices of its leader, e.g. the leader of R2 is R0 in Fig. 2(a) while its leader in Fig. 2(b) is R1. In TLSF scheme, the follower R2 is required to follow two leaders at a distance of d20 and d21, respectively, as well as a bearing angle φ2 with one of them. By changing required relative distances and a relative bearing angles, it is easily to switch from diamond form to zigzag form and vice versa.
2.2. Robot Model
This section considers a system of n non-holonomic mobile robots labelled as R0,…, Rn-1, where R0 is the global leader. The problem of this study deals with wheeled mobile robots with two degrees of freedom and the dynamics of the ith robot are described by the unicycle model, as follows:
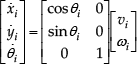
where v i is the linear velocity, ω i is the angular velocity of the mobile robot, θ i is the angle between the heading direction and the x axis, and (x i ,y i ) are the Cartesian coordinates of the centre of mass of the vehicle (see Fig. 3).

SLSF scheme
2.3. Formation Control Framework for SLSF scheme
In SLSF configuration (shown in Fig. 3), R i is leader robot and R k is follower robot. Let d ki denote the actual distance between R i and R k , φ ki is the actual bearing angle from the orientation of R k to the d ki -axis (the axis connecting R i and R k ). The definition of the SLSF formation scheme requires that distance between R i and R k to be equal to d k0 and the bearing angle from the orientation of R k to the d ki -axis is desired to be φ k0 .
The difference between headings of two robots is defined as:

Based on the configuration and these definitions, the dynamics of the system are expressed as:


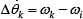
where (5) can be derived easily from (2) by taking the derivative of both sides. Equation (3) is found from the observation that on d ki -axis, the change of relative distance between two robots (d ki ) is the difference in the velocities of R i and R k . To derive equation (4), note that the change of bearing angle (φ̇ ki ) is caused by three components: the angular velocity of R k , the relative motion of R i to R k , and the relative motion of R k to R i . The objective of the leader–follower control in SLSF scheme, therefore, is stated as following:

In order to solve this problem, a reference point M(x km , y km ) is chosen (see Fig. 3) at a distance d k0 from the leader in the direction whose angular deviation with the orientation of the follower robot is φ k0 . Hence, the coordinates of reference point can be calculated by:

With the definition of this reference point, the desired control of the follower robot can be obtained by controlling the position of follower (x k , y k ) towards (x km , y km ). This means that the distance d ki and the angle of orientation, φ ki , can be simultaneously controlled so that the relative distance d ki and relative bearing angle φ ki approaches d k0 and φ k0 respectively.
3. Proposed Control
3.1. Formation Control Framework for TLSF Scheme
The system of n mobile robots is the same as SLSF scheme and the robot R j is required to keep a distance d j0 from its leader R i and its bearing angle at φ j0 . However, the robot R k in this scheme must simultaneously follow two leaders with two desired separations to R i and R j of d k0 and l k0 , respectively, besides the desired bearing angle φ k0 from the orientation of R k to the d ki -axis.
As shown in Fig. 4, the three robots are currently located at A, B, and C, and the desired formation is the triangle ΔADE (dj0 = AE, dk0 = AD, l k0 = DE). The triangle ΔAMN is found by rotating the triangle ΔADE an angle Ψ so that the side AE always lies on the d ji -axis. By this definition, the robot R j is controlled to reach E (N comes towards E) and the robot R k is controlled to reach M (M will come towards D because of N). When R j is at E, R k is obviously at D, as is required. Therefore, TLSF helps both followers reach the desired points nearly at the same time, and the oscillations in the motion of R k on the way to reach a stable state are restricted by the constraint with the second leader R j . This is the major difference between the two schemes. In the SLSF scheme, the second follower can be only at a stable state after the first follower is stable. However, the TLSF scheme implicitly requires that the two leaders must be well configured and controlled, or the follower may encounter difficulties.

TLSF scheme
The pair R i - R j is the SLSF scheme, then the remaining is finding the reference point for R k . From two required separations d k0 and l k0 , and desired bearing angle φ k0 , the instantaneous bearing angle φ km can be calculated as follows:

where


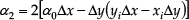


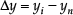


To choose the unique value of φ km , we need to compare directions of the two vectors AN→ and AM→, as shown in Fig. 4, which are defined as

These give a criterion of
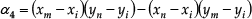
When M is at the left-hand side of AN→, select x m such that α4 > 0, and vice versa.
The objective of the leader–follower control in TLSF scheme is re-stated from SLSF scheme as following:

Compared with the SLSF scheme, the only difference is that the bearing angle in the SLSF scheme is a constant, but the bearing angle in the TLSF is not. This is an advantage in building the control rule because the control rule just needs to deal with the time-variant bearing angle φ km then it can apply to both schemes, so that the bearing angle in the proposed control algorithm, which is presented in the next section, is time-varying.
3.2. Proposed Control Law
Fig. 5 is redrawn from Fig. 4 with some supporting information in order to find the following control: as t→∞, the follower robot's position (x k (t),y k (t)) can be controlled to reach the reference point (x km (t),y km (t)), i.e. the point C needs to approach the point M.

TLSF scheme with detailed information
Now consider the d k0 -axis. On this direction, the change of position from C to M is mirrored as the change from F to M and the component on the d k0 -axis of the relative velocity between v k and v i will do this task. Therefore, the following is obtained:

where k1 is a postitive tuning coefficient.
Next, in order to find ω k , the a k -axis should be considered, as shown in Fig. 5 to be perpendicular to v k . Similar to the way of calculating v k , the change of velocity on this axis (C→G) is caused by the rotation with angular velocity ω k and v i which gives:

One problem is that the above control rule and most other controllers in the literature require the measurement of the leader's speed v i which is practically impossible using only onboard sensors particularly if the speed is supposed to be fed back into the robot's own speed regulation, as in equations (11) and (12). In addition, ω i is also impossible to measure.
In (Gustavi, T. & Hu, X., 2008), the authors tried to estimate only v i by mathematically transform the system model into a cascade system for easier analysis. However, they must assume that ω i = 0 and v̇ i = 0 to decouple the system for proving stability by Lyapunov theory. The aim of our method is to build a control law that can both compensate the change of v i and ω i , and drive the follower to the desired position, without knowing the exact value of v i and ω i , based on a kinematic analysis (Fig. 5). In order to do this, R k should be considered in the coordinate of R i , i.e. the coordinate (x i , y i ), instead of (x,y). In this coordinate, R i is not moving and there is a velocity -v i applied to R k . Assuming that v i at time t becomes v i + Δv i at time t + Δt which will put into the control of R k a component Δv to adaptively compensate the change of v i . This is the change of velocity in the time step, so it is also the instantaneous translational acceleration of leader robot, and can be approximated by:
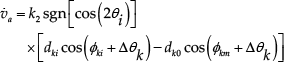
where k2 > 0 is another tuning coefficient, and v a = v i + Δv. Using the same technique as applied with the leader's velocity, that is, the change Δω of ω km is also considered from time t to time t+Δt and Δω is then the angular acceleration of the reference point and can be approximated by:

where k x and k y are tuning coefficients. ω a = ω km + Δω, e x = -dk0 sin(Δθ k + φ km ) + d ki sin(Δθ k + φ ki ), and e y = dk0 cos(Δθ k + φ km ) - d ki cos(Δθ k + φ ki ).
In summary, the proposed leader-follower control is equation (15). As seen in equation (15), the control law requires values of d ki , φ ki , Δθ k which are assumed to be available by measurements from the on-board sensors.
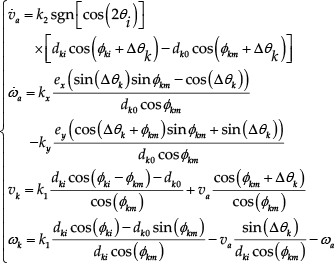
The necessary information includes only distance and angles, and many kinds of sensor can be used to gather those data. In the SLSF scheme, φ km = φ k0 = const. and ω a = 0, so it is not necessary to use the second equation of (15). Our approach is based on the approximation of accelerations, which helps to build a common control law for both SLSF and TLSF schemes. Therefore, it is generally different from the control law in (Gustavi, T. & Hu, X., 2008) which can be applied to an SLSF scheme only.
v i (t) ⩾ v0 > 0, v̇ a (t) ∈ L2[0, ∞), ω i (t) ∈ L2[0,∞), ω̇ a (t) ∈ L2[0,∞). Then, with the control (15), where we let

as t → ∞ we will have globally (x k , y k ) → (x km , y km ), i.e. d ki → d k0 and φ ki → φ km .

and define
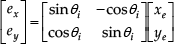
Equations (3), (4) and (5) can be rewritten as

Consider a Lyapunov function candidate as

where ω c = Δωdk0 cos(Δθ k + φ km ), ω s = Δωdk0 sin[Δθ k + φ km ). Before examining this Lyapunov function, there are several matrices, and a number which needs to be defined:
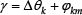





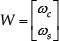
The derivation of this Lyapunov function is long but not difficult, so only some of the key steps are shown here, in which the derivative of a scalar variable is denoted by a dot, while the derivative of a matrix valued function is denoted by a prime. The variable in scalar is in lower case, and the matrix is presented in capital letters (except V).
Taking derivative of V, we have

By noting the following properties,
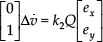




it is easily to derive

It is obvious that if the condition (16) is satisfied, v̇ ⩽ 0. This implies that e x and e y are exponentially convergent to zero. ▪
4. Simulations and Analysis
In order to show the validity, quality and feasibility of the proposed leader-follower control method, we carried out several simulations. We will compare our new control law (15) with the control law proposed in (Gustavi, T. & Hu, X., 2008) (which will be called control law [Ref] from now on). The time step is chosen at 0.2s, which assumes 0.1s for the measurement and communication, and 0.1s for the driving and transportation. The leader is controlled to follow a sinusoidal path, which is similar to (Gustavi, T. & Hu, X., 2008) for purpose of comparison, with a slowly varying speed. Besides those parameter settings, we will compare the performance of control laws in both forming and maintaining tasks in small-scale as well as large-scale robot teams.
4.1. First Simulation
A simulation with control law (15) is performed to form a line formation of the three robots, where robot R0 is the global leader. At the beginning the three robots may be placed anywhere in the field. However for this simulation, we will specify the initial states of the three robots as [x0, y0, θ0] = [0, 0, 0], [x 1 , y 1 , θ 1 ] = [−1.5, −2.6, 0], and [x2, y2, θ2] = [−3, −5.2, 0]. The desired distance between the follower R1 and R0 is 3m and the desired bearing angle is π/6. The follower R2 is required to keep a distance of 3m and 6m to R1 and R0 respectively, and a bearing angle of π/6 with R0. Another simulation using control law [Ref] is also conducted with a similar configuration and the only difference is that R2 is not required to keep a distance of 6m with R0.
Fig. 6 shows the performance of the two control laws in the global x-y coordinates. There is only a small difference in the trajectory of robot R2 can be seen from Figs. 6(a) and 6(b). It is not apparent that R2 tracks the leaders better (quicker convergence) when using control law (15) than when using control law [Ref]. Figs. 7, 8 and 9 will show this more clearly. As seen from Figs. 7(a), 8(a) and 9(a), the robots' performance based on the new control law (15) is not significantly different from performance based on control law [Ref] because this is the SLSF scheme in both cases.

Performance of (a) control law [Ref] and (b) control law (15).
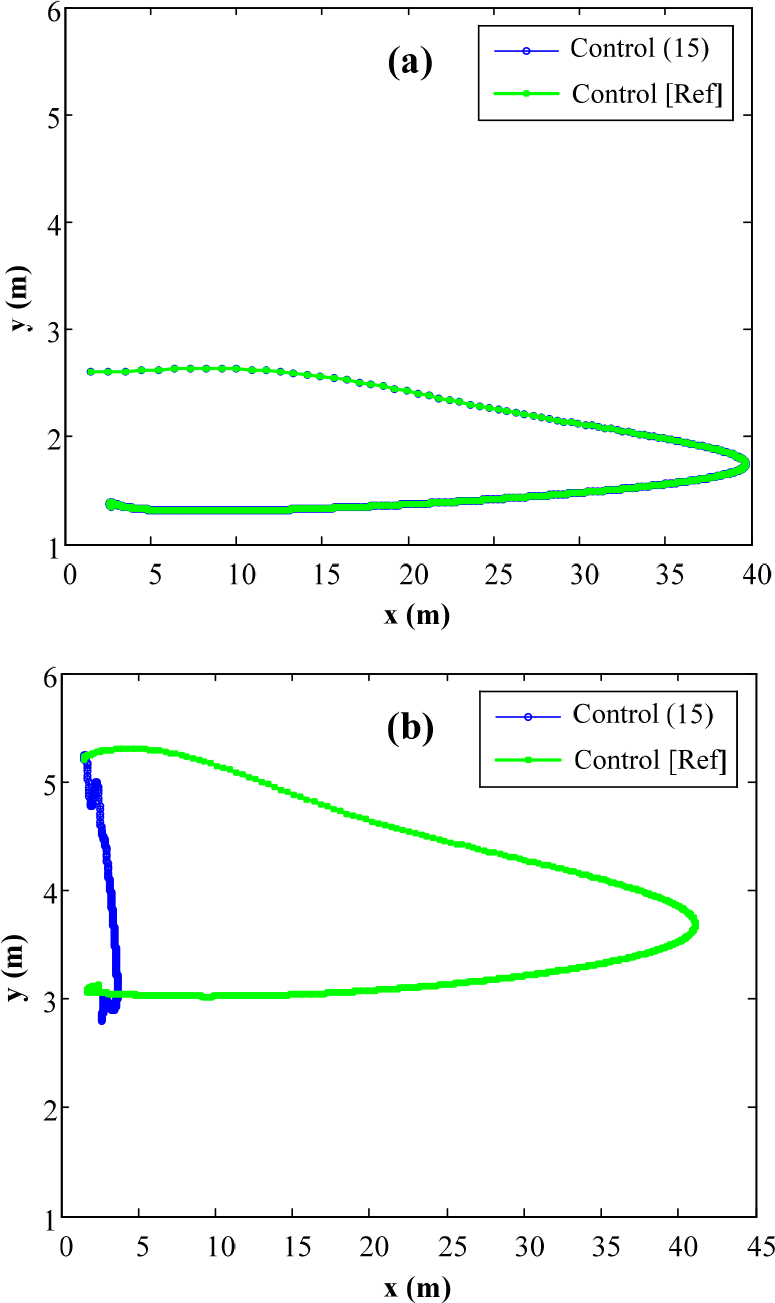
Trajectory seen from leader robot R0 of (a) R1 and (b) R2.
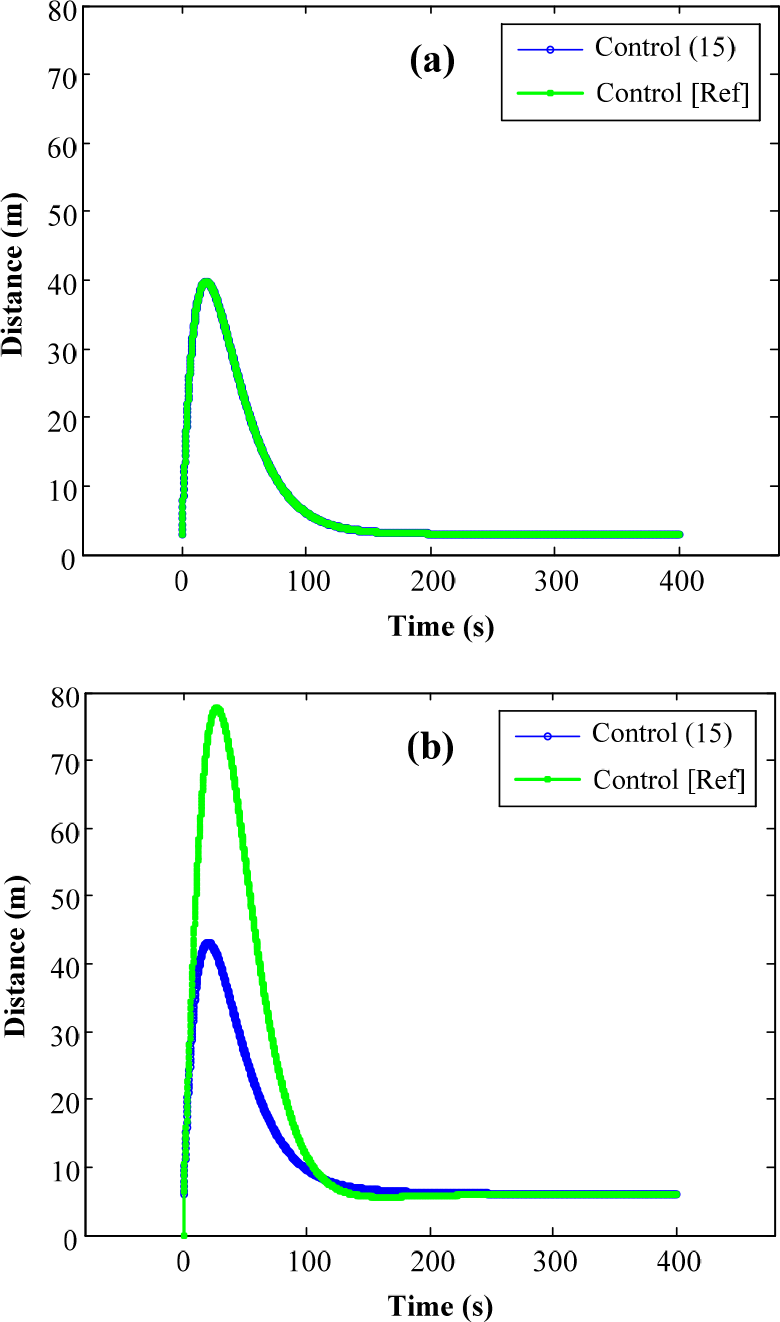
Relative distance over time between (a) R1 and R0 and (b) R2 and R0.

Relative bearing angle over time between (a) R1 and R0, and (b) R2 and R0.
However, there is an advantage of the new control law (15) in the TLSF scheme, as seen in Figs. 7(b), 8(b) and 9(b). In Fig. 7(b), the robot R2 quickly approaches the desired position with the trajectory being nearly a straight line due to the existence of the constraint about the distance with R1, while robot R2 using control [Ref] moves in a long curve before reaching the desired position. In Fig. 8(b), the error of R2 in the SLSF seems to be cumulative with the error of R1, so the farthest distance that it has with R0 is about double. Meanwhile the TLSF scheme causes R2 to have a similar behavior as R1, and to converge to a stable state nearly at the same time as R1. These are two advantages of the new controller (15) within the TLSF scheme. Fig. 9(b) shows the advantage of the approximation of the angular velocity. In the SLSF scheme, there is no constraint for the bearing angle, so oscillations easily occur.
By approximating the angular acceleration of the reference point in the new control law (15) and choosing appropriate parameters, the oscillations and damping can be reduced.
4.2. Second Simulation
The second simulation demonstrates that it is possible and beneficial to apply the algorithm to a large team of robots. The number of robots is now 5 and the trajectory of the leader is still sinusoidal and the robots form a line with the distance between each adjacent robot being 3m, and the bearing angle is π/6. The performance of the controller [Ref] and the new controller (15) are compared in Fig. 10.

Performance of a team of 5 robots using (a) the control law [Ref] and (b) the control law (15) in the TLSF scheme.
From Fig. 10 and the displacement error values presented in Tables 1 and Table 2, it can be seen that the controller (15) has better performance, especially for robots which are at greater distance from the global leader. The convergence rate is faster and the transient errors are smaller. The mean and standard deviation of both distance and angular errors of the second, third and fourth follower robots using controller (15) are much less than when using controller [Ref]. Moreover, those values do not show much difference nor are they incremental as when using controller [Ref]. This means that the TLSF scheme simply keeps the errors away from cumulation.
Displacement errors of control law [Ref]

Displacement errors of control law (15)

4.3. Third Simulation
In above two simulations, the formation-maintaining task is shown. In third simulation, the forming task is performed. A four-robot team will change from a triangular form to a line form (Fig. 11). At first, the three robots are keeping the triangular form (form A), where R0 is the global leader. The initial poses of R0, R1, and R2 are (0, 0, 0), (−2, 2, 0), and (−2, −2, 0), respectively. The team is required to change to a line form (form B) where R1 follows R0 with a distance of 3m and bearing angle π/4; R2 follows R0 with bearing angle of π/4 and distance of 6m, and simultaneously keeps a distance 3m with R1. The results are depicted in Fig. 11. It is shown that the formation is switched well and quickly. The trajectory of R2 when using controller (15) is not as smooth as when using controller [Ref], but the overall error is smaller. All the advantages of TLSF scheme and controller (15) stated in section 4.2 above are also shown in this simulation (see Table 3 and Table 4).
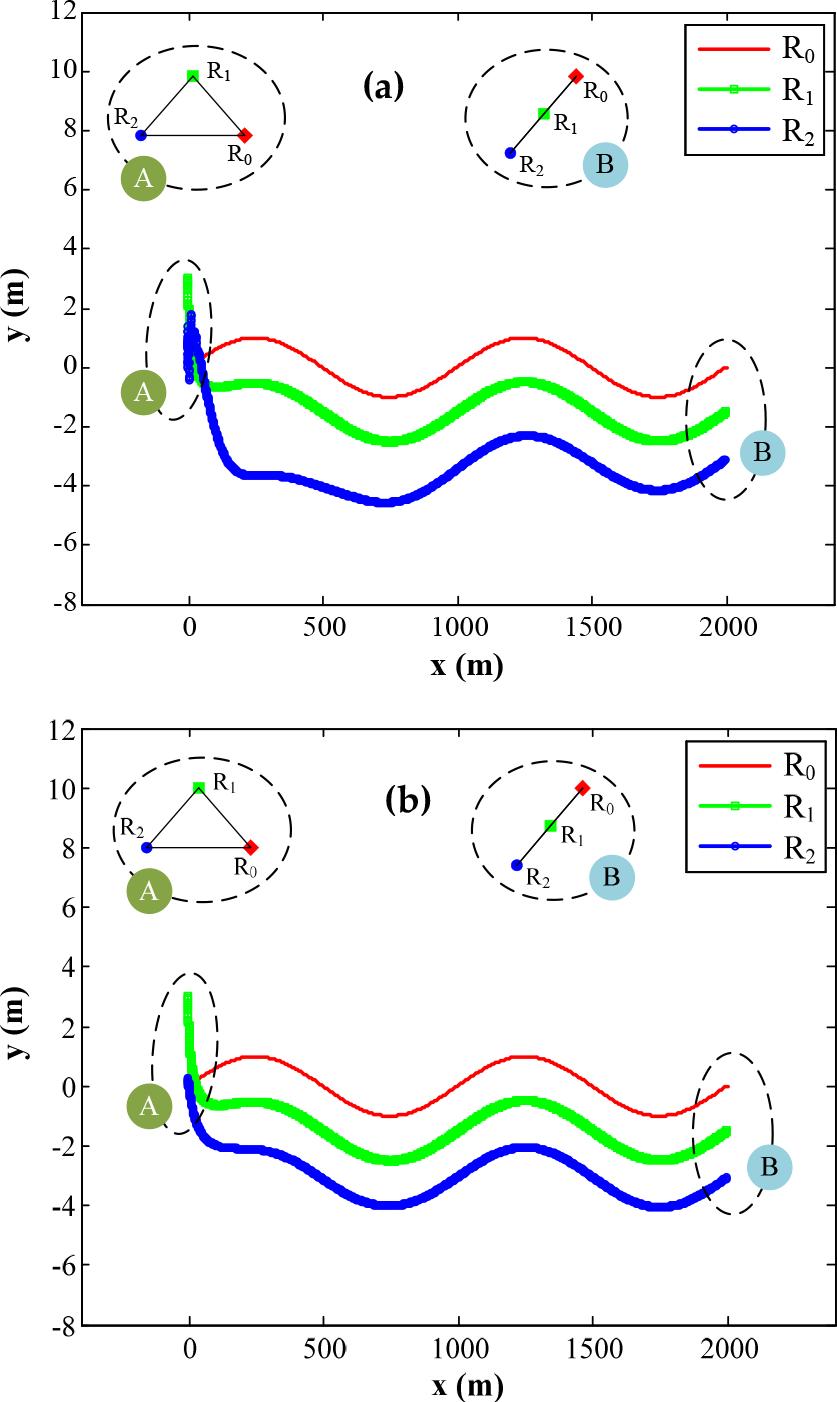
Performance of a team of 3 robots in switching from a triangular formation to a line formation using (a) control law [Ref] and (b) control law (15)
Displacement errors of control law [Ref] in forming task

Displacement errors of control law (15) in forming task

5. Conclusions
In this paper, we propose a new leader-following control method for swarm formation using the approximation of translational and angular accelerations. The control law can be applied to both SLSF and TLSF schemes. Simulations have been presented which show that the stability of the control algorithm can be achieved by tuning the parameters properly, and the algorithm can work well in any scale of formation. The TLSF scheme is better for larger groups of robots because the approximation of the angular acceleration can help to suppress the damping and oscillations and increase convergence rate of the third, fourth, and succeeding follower robots. In addition, the controller uses only available data of the distances and the angles, acquired from onboard sensors. No indirect data such as the translational velocity and angular velocity of the leader robot are required. Thus the number of measurements is reduced, the errors from the measurements are smaller and as a consequence the calculation time is shorter.
Footnotes
6. Acknowldgment
This research was supported by the Yeungnam University research grants in 2008.