
Abstract
Code-message coevolution (CMC) models represent coevolution of a genetic code and a population of protein-coding genes (“messages”)- Formally, CMC models are sets of quasispecies coupled together for fitness through a shared genetic code. Although CMC models display plausible explanations for the origin of multiple genetic code traits by natural selection, useful modern implementations of CMC models are not currently available. To meet this need we present CMCpy, an object-oriented Python API and command-line executable front-end that can reproduce all published results of CMC models. CMCpy implements multiple solvers for leading eigenpairs of quasispecies models. We also present novel analytical results that extend and generalize applications of perturbation theory to quasispecies models and pioneer the application of a homotopy method for quasispecies with non-unique maximally fit genotypes. Our results therefore facilitate the computational and analytical study of a variety of evolutionary systems. CMCpy is free open-source software available from http://pypi.python.org/pypi/CMCpy/.
Introduction
Code-Message Coevolution (CMC) models were introduced to facilitate the study of co-evolutionary systems in which a large population of individuals share an evolvable genetic code coupled to many and/or long protein-coding genes (“messages”). Initial study of these models demonstrated that base mutations in protein-coding genes can significantly influence the fitness of genetic codes. 1 More detailed study of CMC models has yielded formal demonstrations for how natural selection likely contributed to the origins of codon redundancy 2 and non-random patterns of amino acid assignments3,4 in genetic codes. CMC models have been extended to study the effects of population structure and gene sharing on coevolving systems of codes and messages. 5
In their original formulations, CMC models are deterministic evolutionary genetic models that couple together sets of large populations of asexually reproducing genotypes evolving under mutation and natural selection. One such population is called a “quasispecies”, 6 a concept reviewed recently both generally 7 and specifically in connection to population genetics theory.8,9 In CMC models, each of multiple quasispecies represents a large population of codons evolving to meet the same physicochemical requirements of a “site-type” in proteins under translation by a given genetic code. The coupling of multiple quasispecies through a genetic code occurs through reuse of the same codon type (or allele) in different site-types. CMC models follow deterministic trajectories that alternate between equilibration of messages to an established genetic code by mutation and selection, and locally adaptive “gradient ascent” hill-climbing of the genetic code through single codon assignments and reassignments. This “quasistatic” dynamic continues until no single codon reassignment yields higher fitness with the current message population. Published CMC models always converge to a stable local fitness optimum–-a process called “code freezing.”
Because CMC models compound quasispecies models, analytical solutions to quasispecies models are relevant to their study. Previous applications of perturbation theory for approximate solutions to quasispecies models assume uniqueness of maximally fit genotypes and small perturbation parameters (small mutation rates).10–12
In this work, we present two analytical methods that relax these assumptions. The first is a perturbative method that clarifies, extends and generalizes the perturbative approach to quasispecies models. Our presentation provides a derivation to arbitrary order, which relaxes any restriction on the magnitude of the perturbation parameter. The second method is the first published application of homotopy methods to quasispecies models, which handles cases with non-unique maximally fit genotypes. Numerical tests show that, for two example problems, both algorithms converge. Notably, the error of the perturbative method decreases exponentially in the number of iterations, suggesting its potential to outperform the power method. Both approaches are flexible and can be extended to a variety of quasispecies mutation models and fitness schemes. Also, both methods have been formulated so as to facilitate future connections between quasispecies models and established results in eigenvalue perturbation theory13–15 and homotopy methods. 16
In addition to these analytical results, we present a new code-base implementing CMC models. The dissemination and further study of CMC models has been sorely hindered by the lack of a modern code-base implementing them. The original C/C++ CMC code-base has been rendered obsolete by evolution of compilers and language standards from the time of its writing in the late 1990s. This has created a need for reimplementation of the original models in an easy-to-use and program, powerful, and efficient, high-level scripting language like Python.
Here we present CMCpy, a free open-source code-base that implements CMC models in an easy to use object oriented Python API. The code-base comes with a front-end command-line executable called cmc that can drive the exploration of a variety of CMC models and reproduce published results.
Implementation
CMCpy was developed in Python 2.7. Figure 1 shows the organization of classes in CMCpy. A rich class hierarchy allows convenient specification of a wide-range of CMC models with very few lines of Python code.

Overview of class hierarchy and containment relationships in CMCpy.
An element not shown in Figure 1 is that the ArdellSellaEvolver class is an abstract base class for a variety of subclasses implementing different strategies to solve dominant eigenpairs. The default solver relies on the Numpy eig() function for its speed and accuracy, but for reasons of flexibility, verification, and to experiment with different methods, we include a legacy central processing unit (CPU)-based power method, a multicore CPU-based power method implementation and an experimental graphics processing unit (GPU) implementation of the power method that relies on pyCUDA. 17
The pyCUDA solver is implemented in a CUDA C kernel with supportive Python code. The Python code uses NumPy for simple operations, to cast data to types acceptable by the CUDA platform, and to reshape matrices to one-dimensional data frames, for use by CUDA C. The CUDA C implementation of the power method approximately solves the eigenvector of each site-type, in parallel. Each site-type is assigned to one virtual “block” of the GPU, each of which corresponds to a physical processor when the number of blocks is below a hardware limit. This organization of the parallel workload was chosen to stay below CUDA specification limits, access GPU memory efficiently, and avoid excess complexity. Ultimately, the CUDA power method implementation is faster than the CPU power method implementation. Figure 2 shows system clock execution times of various methods on a 3.0 GHz Core 2 Duo with an Nvidia GeForce 460 GTX GPU running Ubuntu 12.04. The benchmark script in R that generated this figure is provided as supplementary data.
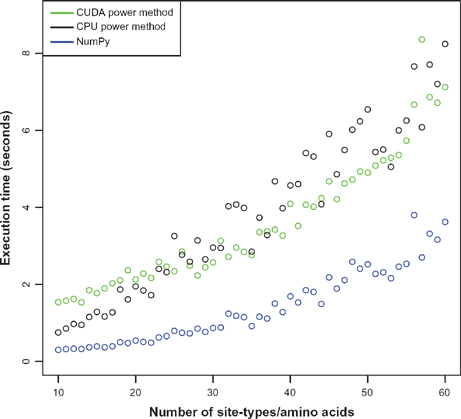
Comparison of wall-clock execution times of the cmc executable with three different eigensystem solvers using the double ring model 4 with eight codons, μ 0.1 and 0 = 0.25.
CMCpy comes with a front-end command-line executable in Python called cmc. This executable provides users, including non-programmers, the capability to reproduce (at least qualitatively) all of the published results on CMC models1–4 as well as run individual and batch simulations of other models and parameter spaces. In Table 1 we list command-line options to the cmc executable and their corresponding model parameters.
Options to the cmc executable and corresponding model parameters.

A variety of observables and statistics are implemented including the Normalized Encoded Range 2 for one-dimensional amino acid/site-type spaces. Although CMC models are deterministic, exact quantitative differences may arise in results with CMCpy depending on floating point representation differences by platform and differences in convergence thresholds using power method-based eigensolvers.
It may be useful to restate the assumptions of the “Ardell-Sella” models currently implemented and available in CMCpy. These include the following:
The numbers and/or lengths of protein-coding genes, or “messages,” translated by a common genetic code, are large with respect to every possible site-type in proteins. For every possible site-type in proteins there corresponds a uniquely most fit amino acid. The machineries to decode codons, and to associate any codon to any amino acid, pre-exist the evolution of the genetic code. Fitness contributions of amino acids across sites are independent and multiplicative. Fitness contributions of different amino acids within the same site are independent and additive. Bases in messages mutate independently of one another. Messages are haploid and asexually reproducing. Genetic codes evolve much slower than messages, through discrete and independent assignments or reassignments of amino acids to codons.
Analytical Methods for Quasispecies Solutions
In this section we develop two different analytical methods to solve for the equilibrium growth rate and genotype distributions for a wide range of quasispecies models. The Matlab/Octave code used to implement these solutions are provided as supplementary data. A version of the homotopy method is also implemented in CMCpy for ring models. Full implementions of both methods will be incorporated into CMCpy at a later date.
Perturbative method: quasispecies with unique fittest genotype
We start with a ring mutation model discussed in prior work.
1
Let μ denote the N x N mutation matrix


We assume that w1 is the unique maximum of the finite set (w1 …, wN}. We also assume w > 0 for each i, consistent with prior work. 1
Our goal in this derivation is to determine the leading eigenpair, consisting of the largest eigenvalue together with its corresponding eigenvector, of the matrix

We write 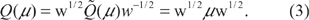
Since the matrices Q and Q are related by a similarity transformation, their eigenpairs are closely related. One can check that

We focus our attention on Q because it is symmetric, i.e., Q(μ) T = Q(μ) for all μ.
For Q(μ), the leading eigenpair λ(μ), v(μ)) must satisfy

When μ = 0, the matrix μ reduces to the N x N identity matrix. Therefore, Q(0) = w, and the leading eigenpair of Q(0) is given by
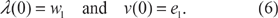
Hereej denotes the j-th basis vector in N-dimensional space, i.e., the vector with all zeros except for 1 in the j-th slot.
Guiding principle
Since Q(μ) is symmetric for all real μ, standard theoretical results in eigenvalue perturbation theory
14
guarantee that both the eigenvalue λ(μ) and eigenvector v(μ) are analytic functions of μ. This means that there exists M > 0 such that for μ ∈ (-M, M), the following power series expansions converge:


In this notation, (6) can be written as λ0 = w1 and v0 = e1. Note also that we have arranged the coefficients so that


Our strategy now will be to derive from (5) a recursive set of equations for the coefficients λj, μj. Once we have these coefficients for j = 0, 1, …, J, we have an approximation to the leading eigenpair.
Let I denote the n × n identity matrix. Then μ = 1 + μs, where



Perturbative solution: part I
Armed with the above facts, we differentiate (5) with respect to μ on both sides:

We then set μ = 0 and use (8), (3), (9), and (6) to obtain
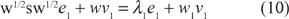
Multiply this equation on the left by the row vector 
Note that 
This shows that if we already know (λ0, v0), we can determine λ1. To determine v1 we return to (10) except now we treat λ1 as known. Rearranging the equation, we have

We substitute our definition of w on the left-hand side to obtain

Suppose that v1 = (v1(1),v1(2),…, v1(N)). We set v1(1)=0. For the remaining components, we solve the above matrix-vector system to obtain

We have completed the loop, showing how to proceed from the zeroth-order eigenpair (λ0, v0) to the first-order eigenpair (λ1,v1).
In the next section, we show how to iterate this procedure to generate the j-th order eigenpair (λj, vj) from the previously obtained eigenpairs.
Perturbative solution: part II
We return to (5) and take j derivatives with respect to μ on both sides. Using the general Leibniz rule, we have
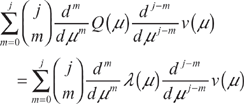
After differentiating, we set μ = 0 and use (8) to obtain

Applying (3) and (9) yields

We peel off the m = 0 term from the right-hand side:
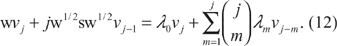
Multiplying on the left by 
Now on the right-hand side, we peel off the m =j term—note that this the only term in which λj appears. Hence

We use (6) and 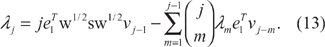
We have therefore shown that if we already know (λm, vm) for m = 0, 1, …,j − 1, we can solve for λj. Now, using this λj, we can solve for vj in the same way as before. We go back to (12), isolate all terms involving vj, and apply (6) to derive

The right-hand side is clearly valid only for j ≥ 1. The matrix on the left-hand side is the same one that appeared earlier:

We again set 
Algorithmic improvements
Equations (13) and (14) complete the step of deriving both (λj, vj) using only the previously derived eigenpairs (λm, vm for m = 0, 1, …j − 1, giving us a recursive solution procedure. Once we have determined (λj, vj) for j = 0, 1, …, J, we can use these coefficients in (7) and thereby obtain approximations to the the leading eigenpair (λ(μ), v(μ)). Hence we view (13) and (14) as an algorithm for computing the leading eigenpair.
Turning to the numerical implementation, we now describe two improvements to the algorithm given by (13) and (14).
First, we note that in (14), we always set 
Second, we note that (14) contains a binomial coefficient that becomes prohibitively large to compute for large j. A natural question is whether these large coefficients are compensated by the inverse factors of j! in (7). To quantify this, we define

We then substitute 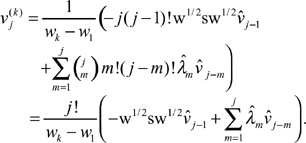
Dividing through by j! and using (16), we derive, again for j ≥ 1,

Applying the same substitutions in (15), we derive
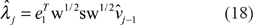
Using (16) in (7), we obtain
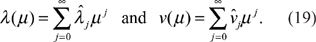
Examining the equations in the
Example
Let us give an example of the perturbative method in practice. We set N = 5, μ = 0.01, and w equal to a diagonal matrix whose entries along the diagonal are (φ, φd, φ2d, φ2d, φ2d, φd) where d = 0.2 and φ = 0.32768.
Let J denote the total number of iterations we run the perturbative method. Starting from
For an N-dimensional vector x = (x1, x2, …, xN), let ‖x‖∞ = max1≤i≤N, the infinity-norm of x, with respect to which the error of the approximate solution after J iterations is
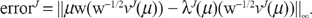
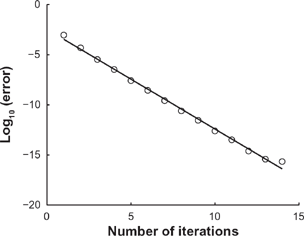
In Figure 3, we plot (in circles) the log10 of the error as a function of the number of iterations J, and (in solid black) the least-squares line of best fit to the data. From J = 1 to J = 14, the log10 errors show a strongly linear trend, confirmed by the R
2
= 0.9958 value for the regression line. The slope of the line is approximately −0.9944, implying

For a particular eigenvalue problem, we plot (in circles) the log10 of the error committed by the the perturbative method after J iterations, where J goes from 1 to 14.
Machine epsilon in Octave is approximately 2.2204 × 10−16, and the error after J = 14 iterations is 2.2590 × 10−16. Therefore, for this particular example, Figure 3 shows that the perturbative method converges exponentially to a solution with error on the order of machine epsilon.
Extension to base/codon/word mutation models
Consider now a matrix μB defined as follows:
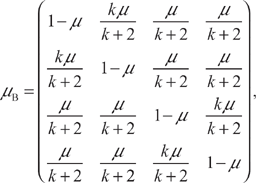
Matrix μB shares with matrix μ the properties of linearity in parameter μ, and reduction to the identity matrix when μ = 0. The methods of this section therefore apply to μB directly.
More biologically realistic CMC models2–4 employ codon mutation models. Let C = Bp, the p-th Cartesian product of the set B. A codon c ∈ C is a string of bases blb2…bp of pre-specified length p with bi ∈ B.
The codon mutation models studied by Ardell and Sella assume independence of mutation of bases within codons and that all bases mutate according to the same model of evolution μB. With these assumptions, mutation from any codon c1, ∈ C to another codon c2 ∈ C is represented by a matrix μc that is the p-th Kronecker power of a matrix μB as follows:

If λ is the leading eigenvalue μB then λc = λp is the leading eigenvalue of μc. Similarly, if v is the eigenvector corresponding to the leading eigenvalue of μB, then
Therefore, the methods of this section allow calculation of the leading eigenpairs of matrices μc as Kronecker powers of leading eigenpairs of μB.
Homotopy method: quasispecies with multiple most fit genotypes
We now give a second method for finding the leading eigenpair of the matrix Q defined in (3). This method, which we call the homotopy method, is motivated by the desire to handle a fitness matrix w that does not have a unique maximal element along its diagonal. The homotopy method produces accurate approximations of the leading eigenpair for such problems.
Problem formulation
Our goal is still to find the leading eigenpair of 
Note that F(0) = μ and F(1) = Q. The function F smoothly deforms μ into Q—such a function is often called a homotopy in the mathematical literature.
16
Note that for all ∈ ∈ [0,1], the leading eigenpair (λ(∈), v(e)) of F must satisfy
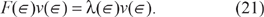
The basic idea behind the homotopy method is to use F to form a bridge between μ, a matrix whose leading eigenpair we already know, and Q, a matrix whose leading eigenpair we seek.
When ∈ = 0, (21) reduces to μv(0) = λ(0)v(0). By the results provided in supplementary materials, we know that the leading eigenvalue of F(0) = μ is 1 with corresponding eigenvector 
When ∈ = 1, (21) reduces to Qv(1) = λ(1)v(1). Thus the question is how we can use our knowledge of (λ(0), v(0)) and the function F(∈) to derive (λ(1), v(1)), the leading eigenpair of Q.
Unlike the perturbative solution, at no point will we assume that the entries of w have a unique maximum. To make the derivation easier to read, we define
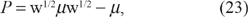

Homotopy solution
We differentiate both sides of (21) once with respect to ∈ and obtain

Since F(∈) is symmetric for all ∈, we see that the transposition of (21) can be written v(∈)TF(∈) = λ(∈) v(∈)
T
. Thus, after multiplying (25) through on the left by v(∈)T, the second term on the left-hand side cancels the second term on the right-hand side, leaving
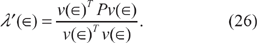
Now let us substitute (26) back into (25). Solving for v'(∈), we have
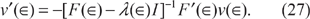
We now recognize (26) and (27) as a system of ordinary differential equations (ODEs) with ∈ playing the role of a time-like independent variable:

We also recognize (22) as the initial conditions for this system of ODEs. Let us now describe an elementary algorithm for solving this system:
Set λ = 1 and Whiles ∈ < 1: Compute λ′ using (26), i.e., λ′ = (vTPv)/(vTv). Set λ ← λ + (Δ∈)λ. Using this updated λ, compute v' using (27), i.e., v' = -[μ+∈P-λI]−1 Pv. Set v ← v+(Δ∈)v'. Set ∈ ← ∈ Δ∈.
The algorithm will terminate in nsteps steps, yielding an approximation to the leading eigenpair of Q that is stored in λ and v.
To obtain the leading eigenvector of
Example
We now give test results for the homotopy method applied to a particular problem. We set N = 8, μ = 0.1, and w equal to a diagonal matrix whose entries along the diagonal are (a, b, b, b, b, b, b, b) T with a = 0.63631836 and b = 0.73306514. We also set the parameter, φ = 1.
We repeatedly run the algorithm given above for different values of nsteps; specifically, we take nsteps = 10j' j = 1, 2, 3, 4, 5, 6. For each value of nsteps, we compute an approximation to the leading eigenpair, which we denote by (λ
j
, vj. We then evaluate the residual error of this approximation using

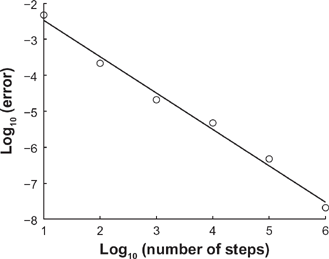
In Figure 4, we plot (in circles) the log10 of the error as a function of the log10 of the number of steps. We also plot (in solid black) the least-squares line of best fit to the data; for this line, R
2
= 0.9899 and the slope is approximately −1.0115, implying
For a particular eigenvalue problem, we plot (in circles) the log10 of the error committed by the the homotopy method using a number of steps given by nsteps = 10 j , where j goes from 1 to 6.
Note that with nsteps = 10 3 , the error is approximately 2 × 10−5. This level of error is acceptable if we seek to use the homotopy method to reproduce, for example, Figure 4 in a previously published paper. 4 Hence we use this value of n steps as the default value in the CMCpy implementation of the homotopy method.
Further note that when nsteps = 10 6 , even the elementary algorithm described above to solve the system of nonlinear ODEs (28) is capable of producing a residual error of approximately 2 × 10−8.
For this example, the homotopy method displays convergence that is linear in Δ∈—-this relatively slow rate can be improved dramatically by using more sophisticated methods to solve the system of nonlinear ODEs (28), an issue we leave for future work.
Extension to base/codon/word mutation models
In order to apply the homotopy method to models where the mutation matrix is given by μB as defined earlier, there is one requirement: we must be sure that μB has a unique maximal eigenvalue of 1. For the μB matrix, it turns out that we can explicitly derive all eigenvectors and eigenvalues, for general values of both μ and k. With the constraints 0 < μ < 1 and k ≥ 1, the derivation that we give in supplementary materials below proves that the μB matrices have a unique largest eigenvalue of 1. Matrices μB therefore fulfill the minimum requirements for applicability of the methods of this section, after which the leading eigenpair for corresponding matrices μC may be calculated using Kronecker powers as before.
Future outlook
We succeeded in programming a GPU-based power method implementation that is faster than its CPU analogue; however, the performance gain that we obtained with it was not as great as we had hoped. Furthermore, even though our implementation is correct, we could not completely eliminate divergence in evolutionary trajectories in power method implementations arising from differences in machine number representations and precision across platforms. We believe that this arises from deviations in the way double precision floating point numbers are represented, computed on, and rounded in CUDA compute capability 1.3. Perhaps utilization of the cuBLAS library in the future would make performance closer to Numpy and better conform to IEEE standards.
Furthermore, while the power method converges linearly, our new perturbation method provides exponential convergence with the same accuracy. However, this method cannot handle the case of non-unique most fit genotypes that occurs in CMC models at their initialized state. On the other hand, our new homotopy method does handle this case, yet as currently implemented it also converges linearly, rather slower than the power method (results not shown). Incorporation of more sophisticated methods to solve systems of nonlinear ordinary differential equations should dramatically improve performance of our new homotopy method application. We leave further development of both methods and their implementation in CMCpy for future work; perhaps other CPU or GPU implementations of them will compete with Numpy. More generally, our analytical results greatly expand the domain of quasispecies models that can be accurately solved using analytical approaches, particularly multi-site models with biologically realistic mutation parameters.
A variety of open problems remain concerning CMC models and in the field of the evolution of the genetic code.20–24 CMCpy can easily be extended to implement the model studied by Vetsigian et al. (2006) 5 with variations, or alternative observables, such as the “evenness” of amino acids. 23 Current models of the genetic code have not yet integrated a theory for the origin of translation per se.5,21 We believe that extensions to CMC models will better address such fundamental questions and hope that CMCpy and our analytical solutions to quasispecies models will play a role in that work.
Funding
DHA acknowledges the UC Merced division Graduate Research Council for a UC Faculty Research and Chancellor's awards that supported undergraduate BPS, as well as the NSF-funded program in Undergraduate Research in Computational Biology at UC Merced (DBI-1040962), which supported and trained PJB and paid publication costs.
Competing Interests
Author(s) disclose no potential conflicts of interest.
Author Contributions
Conceived CMCpy project: DHA. Wrote software: DHA, PJB, BPS. Analyzed data: DHA, HSB, PJB, BPS. Analytical results: HSB, with minor contributions from DHA. Wrote first draft of the manuscript: DHA, HSB. Contributed to the writing of the manuscript: DHA, HSB. Agree with manuscript results and conclusions: DHA, HSB, PJB, BPS. Developed the structure and arguments for the paper: DHA, HSB. Made critical revisions and approved final version: DHA, HSB, PJB. All authors reviewed and approved of the final manuscript.
Disclosures and Ethics
As a requirement of publication author(s) have provided to the publisher signed confirmation of compliance with legal and ethical obligations including but not limited to the following: authorship and contributorship, conflicts of interest, privacy and confidentiality and (where applicable) protection of human and animal research subjects. The authors have read and confirmed their agreement with the ICMJE authorship and conflict of interest criteria. The authors have also confirmed that this article is unique and not under consideration or published in any other publication, and that they have permission from rights holders to reproduce any copyrighted material. Any disclosures are made in this section. The external blind peer reviewers report no conflicts of interest.
Footnotes
Acknowledgements
The authors would like to thank members of the Ardell Lab, Jason Davis and Suzanne Sindi, for their comments and suggestions on this work, as well as Prof. Masakatsu Watanabe and Prof. Michael Colvin for their leadership in creating and running the Undergraduate Research in Computational Biology (URCB) program at UC Merced, without which the collaboration of undergraduate Peter Becich would not have been possible.