
Abstract
Reverse phase protein arrays (RPPA) measure the relative expression levels of a protein in many samples simultaneously. Observed signal from these arrays is a combination of true signal, additive background, and multiplicative spatial effects. Background subtraction alone is not sufficient to remove all nonbiological trends from the data. We developed a surface adjustment that uses information from positive control spots to correct for spatial trends on the array beyond additive background. This method uses a generalized additive model to estimate a smoothed surface from positive controls. When positive controls are printed in a dilution series, a nested surface adjustment performs an intensity-based correction. When applicable, surface adjustment is able to remove spatial trends and increase within slide replicate agreement better than background subtraction alone as demonstrated on two sets of arrays. This work demonstrates the importance of including positive control spots on the array.
Introduction
Protein arrays are assays that measure protein expression in a high-throughput format. These are able to address questions about postranslational modifications and protein pathway relationships that genomic studies alone cannot answer. 1 Several different protein array formats have been developed, but they can be generally dichotomized into forward phase or reverse phase assays. Forward phase assays simultaneously measure the levels of many proteins or antibodies within a single sample, where as reverse phase assays simultaneously measure the level of a single protein for many samples. One reverse phase approach that uses lysed homogenized samples is the protein lysate or reverse phase protein array (RPPA) first described by Paweletz et al. 2
RPPAs have been used to research a number of biological issues. For example, RPPAs were used to study proteomic signatures of signaling pathways in prostate cancer.2,3 Nishizuka et al 4 used RPPAs to find molecular markers that can distinguish colon from ovarian cancer, two types of cancer that at onset are difficult to separate. Gulman et al 5 found unique proteomic signatures that were able to distinguish fast progressing follicular lymphoma from slow progressing disease. Other studies found proteins that play key roles in the regulation of pathways in different types of cancer including breast cancer, 6 glioma, 7 and leukemia. 8 More studies using RPPAs include.9–15
The RPPA assay is described in detail by Paweletz et al, 2 Tibes et al, 16 and in several review articles.17–19 For the specific methods we use, see Tibes et al. 16 Briefly, sample lysates are spotted onto a nitrocellulose backed array in a dilution series. The array is then hybridized with a specific rigorously validated antibody manufactured to recognize the protein of interest. Protein signal is amplified starting with a biotinylated secondary antibody that binds to the primary antibody. Next, a streptavidin-biotin complex binds to the secondary antibody and produces a visible precipitate after chemical processing. The processed array is scanned on an ordinary flatbed scanner and the resulting image is quantified with MicroVigene (VigeneTech, Inc., North Billerica, MA), an array software that measures the intensity of the label at each spot on the array. The array software provides measurements of both foreground and background intensities at each spot, where the local background at a spot is the intensity measured just outside a printed spot.
In the RPPA setting, a false positive signal can occur for one of two reasons. First, either the primary antibody binds to an incorrect target and the secondary antibody and biotin complex react appropriately to this misbound antibody or, second, the secondary antibody and biotin complex, alone or in combination, bind promiscuously and deposit signal in a process that is independent of the primary antibody. The first cause, incorrect binding of the primary antibody, has been addressed by using only antibodies that have been strictly validated using a Western blot. The vigorous validation scheme used to screen antibodies is described in detail by Tibes et al. 16 The binding of the primary antibody to an incorrect target is not generally a concern in the RPPA setting. It is the second cause, the undiscriminate binding of secondary antibody or biotin complex, that is of major concern in this paper. When these substances react with the nitrocellulose membrane or with contaminants in the non-print areas of the array, regional non- specific signal will be detected that could make the data unuseable. Figure 1 shows an RPPA that exhibits this global patchy signal across the slide that must be dealt with. In general, the data from “dirty” slides, such as the one in Figure 1, will be usable once the regional non-specific non-print area staining is appropriately accounted for.

An example RPPA slide that shows visible regional non-print area staining.
The usual approach for adjusting for these spatial artifacts is through background correction, which is accomplished by subtracting the local background intensity at a spot from the foreground intensity of that spot. Figure 2 illustrates the importance of background correction for RPPAs. The figure shows Bland-Altman plots 20 of biological replicates that were printed on different parts of the array for four example RPPAs both before and after subtracting local background signal from the foreground signal. Each of these slides were printed with protein from the same samples, but different antibodies were used to measure different proteins on each slide. Clearly, inter-slide reproducibility is vastly improved after background correction, especially for Array C. However, some slides (for example, Array A and Array B) suggest background subtraction alone is not sufficient.

Bland-Altman plots of replicates on four arrays. Each row represents a separate array. The first column shows replicate agreement before any correction, the center column shows replicate agreement after background subtraction, and the third column shows replicate agreement after surface adjustment. While background subtraction improves agreement, the off-center B-A plots of the center column indicate remaining spatial artifacts that are removed with surface correction.
In the presence of regional non-print area staining, low expressions will not be detected because they are dominated by the spatial background, although the strongest signals will still be discernible. Figure 3 illustrates this concept using three ficticious samples with high, moderate and low levels of protein, each in 5-spot dilutions. The right column of Figure 3 shows the cumulative effect of protein expression dependent on differing degrees of non-specific background staining representing 0%, 25%, 50% and 75% of maximum signal strength. Even at the highest level of background, the strongest signals are still discernible, but the signal from the higher dilutions or from samples with lower abundance become disproportionately overwhelmed by the levels of background. In this paper, we propose a method to correct the regional spatial effects with a multiplicative model using high expression control spots (positive controls) on the array. The proposed method is able to appropriately account for the spatial non-print area staining effects that would otherwise prevent use of the data.
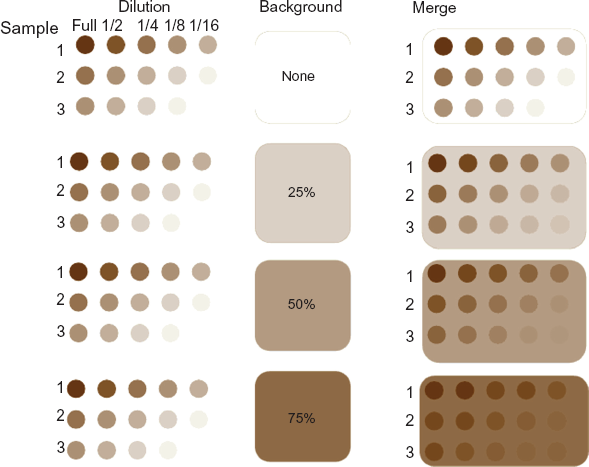
Effect of different background levels on overall signal. In this schematic, three samples with high, moderate and low levels of protein are shown as they would appear on the array with the 5 dilutions. Differing degrees of non-specific background staining representing 0%, 25%, 50% and 75% of maximum signal strength are shown in the center. On the right side, the cumulative effect of the actual protein dependent staining and the non-specific background are shown merged. Even at the highest level of background, the strongest signals are still discernible, but the signal from the higher dilutions or from samples with lower abundance become disproportionately overwhelmed by the levels of background.
Methods
Data
This study uses data from two separate RPPA experiments. The first dataset is a collection of 52 arrays described by Kornblau et al 8 and Kornblau and Coombes. 21 Each array contains 550 patient samples printed in duplicate on separate sections of the array. The 52 slides represent the different antibodies with which the arrays were probed. The second dataset is also described by Kornblau and Coombes. 21 The number of samples included in this dataset necessitated printing on two slides, so for the 138 antibodies used, a total of 276 slides were stained. There were 1152 samples printed on the two slides (576 samples per slide) in replicate.
Both sets of arrays were printed, processed, and analyzed using methods previously described in Tibes et al, 16 Kornblau et al, 8 and Kornblau and Coombes. 21
Positive Controls
The positive control spots on the arrays from this study were made from a mixture of cell lines designed to have levels of all proteins of interest. As a result, the PC spots printed on the arrays will always be expressed. Furthermore, when there is more than one PC spot on an array, they should all be expressed at the same level.
Negative control (NC) spots are spots on the array that are printed with buffer. NC spots, therefore, should not bind to antibodies and can also be another estimate of background signal. Buffer is used as the NC to aid in determining where the non-print signal is coming from.
This paper examines the spatial effects of two RPPA datasets. The first is a set of 52 arrays, each printed in the format of Design I. Design I has 8064 spots in a 56 × 144 grid. Each 14 × 12 subgrid (shown in Figure 4, left) contains 28 samples printed in a 5-spot dilution series. Each dilution series is followed alternatively by a PC or a NC spot. There are 48 subgrids on the array, each with 14 PC and 14 NC spots for a total of 672 PC and 672 NC on the array.

Subgrid layout of two array designs. The left layout (Design I) prints a full strength positive control (red) or negative control (white) at the end of each dilution series (gray). The right layout (Design II) prints the positive control spots in a 5-spot dilution series (red and pink).
The second dataset is a collection of 276 arrays, each printed in the format of Design II. Design II has 6912 spots in a 48 × 144 grid. Each of the 48 subgrids on the array (see Figure 4, right) has 24 samples printed in a 5-spot dilution series. Each dilution series is followed by either a NC, a PC, or a diluted PC spot. The PC spots are printed at full, 1/2, 1/4, 1/8, and 1/16 strength dilutions (see Figure 5). There are 4 NC spots and 4 PC spots at each of the 5 dilution strengths on the subgrid for a total of 192 NC spots and 192 PC spots at each dilution strength.

Positive control (PC) expression for a slide with low regional variation. The PC dilution is fairly linear on average. The 1/2 strength dilution is expressed at the same level as the full strength because both are protein saturated.
With RPPA data, a simple additive correction for background is sometimes not sufficient to remove all spatial trends from the signal. Figure 2 shows that there are remaining artifacts that background subtraction does not fully correct. These effects are generally from non-print area staining, although other factors such as uneven hybridization will occasionally contribute. Empirical evidence suggests that spots with more protein are more affected by non-print area spatial staining than low expression spots.
We use the following equation to model the relationship between observed signal intensity, background, spatial effects, and true signal intensity:

where
Surface Adjustment
The assumption for recovery of Y ij is that the PC spots (of the same dilution strength) are expressed at the same intensity. Prior data suggests that PC expression has a CV of less than 6%–15% and dot size variation is very low. Therefore, we use the PC spots to estimate the spatial surface needed to adjust the observed intensities in order to return spatially independent values. We will first discuss an adjustment method for Design I arrays, in which PCs are only printed at full strength. Next, we will discuss a method for Design II arrays, in which PCs are spotted at different dilution strengths. In both cases, PC spots expressed below the 75 percentile of the negative control expression were not used.
Design I methods
The Design I array has 14 full strength PC spots and 140 spots with biological samples, both in full and diluted strengths in each subgrid (see Figure 4). To do the spatial adjustment, we need a PC estimate,
We used a generalized additive model (GAM) to build a smooth surface from which to estimate PC values at each spot on the array. For the GAM,
Design II methods
When the PC spots are printed in a dilution series, the levels of positive controls are exploited to perform an intensity-based adjustment. We first build PC surfaces at each dilution level using the predicted values from a GAM as explained previously. Let

In practice, if
Next, each spot is scaled to the surface it is closest to in intensity. When the observed intensity falls between two surfaces, the scaling is a weighted average of the two surfaces with weights based on the linear interpolation between the two surfaces. The multi-surface scaling method is written:
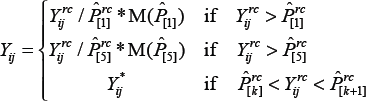
where M(·) is the median function
Evaluation
We evaluated the single surface method with a set of 52 slides that were printed using Design I. Likewise, the multi-surface method was evaluated with a set of 276 arrays printed using Design II. We also used the Design II arrays to compare the single surface and multi-surface methods. Although there is not a gold standard in the data set, we can still adequately judge the effectiveness the spatial correction by comparing interslide reproducibility and spatial association.
Interslide Reproducibility
Interslide reproducibility was measured using the concordance correlation coefficient (CCC) 23 between the biological replicates on the array. The replicates were printed on different locations and sides (left vs. right), so replicate agreement is a reasonable assessment of the spatial correction. The CCC measures both correlation and deviation from the 45 degree identity line of the set of spots on the left side of the array and their corresponding replicates printed on the right side of the array. Like Pearson's correlation coefficient, the CCC is a number in the interval [–1,1] where a value of 1 represents perfect agreement.
Spatial Association
Spatial association was measured using Moran's I, a standard statistic in spatial data used to measure the strength of spatial correlation [2]. Moran's I is based on the definition of the “neighbors” of each spot. We defined the neighbor of a spot to be the 4 closest PC spots in all directions. Moran's I is a value in the interval [–1,1]. Under the null model, the expected value is
Results and Discussion
Interslide Reproducibility
The mean CCC was higher for both Design I and Design II arrays after the surface correction was performed (Design I: no adjustment, 0.610; background, 0.850; surface, 0.886; Design II: no adjustment, 0.763; background, 0.865; surface, 0.892). Boxplots of CCC for both designs in Figure 6 show the variability of these measures.

Concordance correlation coefficient (CCC) for the set of Design I (52 arrays) and Design II (276 arrays) slides before any adjustment and after background subtraction and surface corrections. Surface correction CCC is slightly higher than background subtraction alone.
For the Design I arrays, there was an increase of more than 0.025 in 27 of the slides, no substantial change in 24 slides, and a decrease of CCC in 1 slide. Furthermore, for the Design II arrays, single surface comparison with background subtraction alone showed that there was an increase of more than 0.025 of the CCC in 68 of the 276 arrays, no substantial change in 201 arrays, and a similar decrease in 7 of the arrays. When comparing the multi-surface technique with background subtraction alone, the CCC increased by more than 0.025 in 122 of the slides, had no substantial change in 145 slides, and decrease in 9 of the slides.
In summary, spatial correction with this data increases or does not change replicate agreement in 97% of the slides, with very dramatic improvement in some cases, for example, Arrays A and B from Figure 2. Furthermore, when replicated agreement is decreased, the slide generally had low variation to begin with (see Figure 8).

Moran's I (a measure of spatial correlation) for the set of Design I (52 arrays) and Design II (276 arrays) slides before any adjustment and after background subtraction and surface corrections. There is substantially less spatial correlation after surface adjustments.
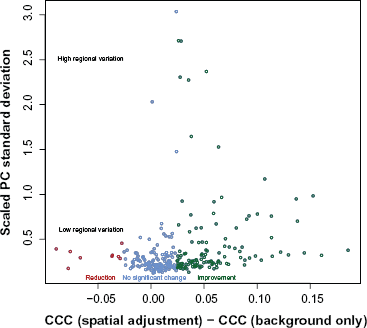
Surface adjustment is typically most benefical when high regional variation from non-print area staining is present. A reduction in interslide reproducibility is seen only for slides where spatial correction is not necessary (slides with low non-print area staining).
Spatial Association
Spatial association as measured by Moran's I indicated less spatial correlation in intensities after the surface correction. The mean Moran's I for Design I arrays was 0.705, 0.664, and 0.102 for no adjustment, background subtraction, and surface correction respectively. The means for Design II arrays were 0.371, 0.365, and –0.022. See Figure 7 for boxplots.
The Moran's I statistics was reduced (indicating less spatial correlation) for every slide from both the Design I and Design II arrays after surface correction.
Conclusion
In general, surface adjustment of intensities improves replicate agreement and better removes non-biological effects from the observed signal. There may be a concern that the surface adjustment does not uniformly improve interslide reproducibility. This method is useful when there is high regional variation from non-print area staining. Figure 8 shows that the slides for which the surface adjustment reduces replicate agreement are when the regional variation (measured as the scaled standard deviation of the positive controls) is low. There were some arrays with low regional variation that benefited from surface adjustment, therefore suggesting that the amount of regional variation is not always good indicator for when the method should not be used. We are currently researching criteria that will better indicate whether interslide reproducibility will suffer after surface adjustment.
Additional improvements in the surface adjustment can be attained when the positive control spots are printed in a dilution series. Often this is due to the fact that PC spots are saturated with protein when printed with full strength (Fig. 5). PC with a higher buffer to protein ratio will aid in surface correction when the full strength spots are saturated.
Overall, adjusting for regional variation from non-print area staining using positive controls improves interslide reproducibility and reduced spatial variability in RPPA. Background correction alone is not always sufficient to remove all the spatial variation that is present in RPPA data. The method that we have presented here using the positive control spots is both sensible and effective. We have developed a method that fits a 3-dimensional surface to positive controls and improves replicate concordance over typical background subtraction. When the positive control spots are printed in a dilution series, a set of nested surfaces built from different levels of positive control further improves replicate concordance. An important contribution of this method is that it allows valid use of data from a slide with regional non-print area staining that would otherwise have too much variation between replicates to be used. Application of the method saves from the need to restain slides and, thus, is an easy yet effective way to save resources.
Author Contributions
Conceived and designed the experiments: ESN, KAB, SMK. Analysed the data: ESN. Wrote the first draft of the manuscript: ESN, SMK. Contributed to the writing of the manuscript: ESN, KAB, SMK. Agree with manuscript results and conclusions: ESN, KAB, SMK. Jointly developed the structure and arguments for the paper: ESN, KAB, SMK. Made critical revisions and approved final version: ESN, KAB, SMK. All authors reviewed and approved of the final manuscript.
Funding
This work was supported by a Leukemia and Lymphoma Society translational research grant for SMK.