
Abstract
The world wide web has furthered the emergence of a multitude of online expert communities. Continued progress on many of the remaining complex scientific questions requires a wide ranging expertise spectrum with access to a variety of distinct data types. Moving beyond peer-to-peer to
Introduction
In recent years, community websites such as Facebook [http://facebook.com].1,2 and MySpace [http://myspace.com] have moved social networking into the spotlight..3,4 Although these two communities are broad, others are focused on specific interests, for instance photography (Flickr [http://fickr.com]), microblogging (Twitter [http://twitter.com]),.5,6 video (YouTube [http://youtube.com]),.7,8 and shared book-marking ([http://del.icio.us]). 9 And while industry is still figuring how to capitalize on this phenomenon, professional communities such a LinkedIn [http://linkedin.com] 10 have already begun to take a more business oriented approach to social networking.
LinkedIn goes a step farther than other social networking sites in how it manages connections between users. Most social networking sites have a single distinction for connections—a friend or contact list. Any user in the system can indicate attachment to any other user in the system. Depending on the social network (and user security settings), attachment is either granted immediately or upon confirmation from the other user. LinkedIn however requires a confirmation of a professional connection to the other person. A professional connection can be verified by an up to date email address, a common employer, or a mutual friend who brokers the connection. 6 This maintains LinkedIn as a web of coworkers, past and present, as opposed to Facebook's web of people who may have once met socially.
Many of these communities are open to the public while others are intentionally kept private. Sites, such as ExpertMapper [http://expertmapper.com], 11 maintain large lists of experts organized according to region and interest. These lists are useful for finding a local specialist, but provide no means for communication. While it is possible to use this kind of site to make connections and form a network, the site itself provides no infrastructure for communication. So while ExpertMapper and similar directories may include hundreds or thousands of experts, those experts are not actively participating community members, but entries in a virtual phone book.
In the Life Sciences, communities such as Biomed Experts [http://www.biomedexperts.com/] 12 bring professional social-networking to the medical research world. Others include Spidera [http://spidera.eu], a European Commission-supported social network that operates as an interface of academia and small-to-medium enterprises in the health care and life sciences domain, Nature Network [http://network.nature.com], which is a professional networking site for scientists worldwide, and CViT.org [https://www.cvit.org]13–15 (see Fig. 1) an NIH/NCI-supported online community dedicated to supporting cancer modeling and simulation.
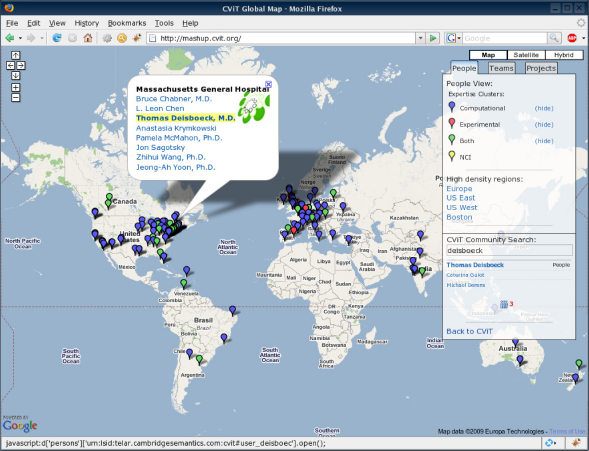
CViT global map. CViT global map lists all CViT users. Also available are displays of projects and files stored in the semantic layered Digital Model repository.
While these web-based expert networks claim to facilitate interaction and promote data sharing in the interest of optimizing collective output, such web-based communities also experience significant challenges. The obstacles faced by online communities are broad in range: a provenance system that maintains ownership of shared data and addresses copyright issues; securing sustained funding, necessary to provide fresh and relevant content for a growing community; and to continue the buildup of infrastructure to distribute this content.
Discussion
However, the central challenge for many of these highly focused communities is that the very essence of their appeal, a high level of expertise paired with the prospect of facilitated peer-to-peer interaction, determines the content that they have to continue to offer to keep their core user base engaged. The result is an initial period of accelerated growth at the price of self-selecting isolation; that is, eventually most of these communities will have to slow their expansion as the available highly trained talent in that expertise segment is limited: growth in an expert community stagnates once the supply of experts is exhausted. Students participating in the community will eventually graduate, advance and can become experts in their field thus raising the total level of available expertise. While this may seem like a very reasonable long term investment, it is risky short-term. That is, arguably, a well known expert has little to gain instantly from joining a community of students or lay personnel; by diluting expertise a community risks lessening its appeal to established experts who can contribute now. Life Sciences research, however, is not a members-only club. Work in isolation cannot be a road to success as there is growing consensus that most remaining grand challenges in the Life Sciences require large-scale interdisciplinary approaches that per definition will exceed the expertise, data, and tool sets available in any one of these communities.
We therefore argue that there is significant and as of yet untapped value in interacting with communities in neighboring expertise areas and thus accessing additional expertise, data, metadata, models and tools that have the potential to accelerate domain-specific research. 16 The question is then twofold: (i) how to maintain community growth from sources outside the core expertise area which will require opening up the content spectrum, while (ii) minimizing alienation to its core constituency? How can separately developed professional networks communicate with each other? In other words, how can we move from the current peer-to-peer to community-to-community interaction?
To answer this, we must first consider what exactly community-to-community interaction is. Perhaps the closest example is an academic journal. Members of a research community compile their knowledge into a series of papers; if peer-review asserts that the papers are of sufficient quality and interest they are published in a journal and disseminated to neighboring communities with access to this journal. This is a community-to-community broadcast, rather than interaction. Any interaction or feedback that results from the paper takes place outside of the journal and becomes peer-to-peer interaction instead. We would like to enable this level of back and forth communication, without taking a step back from intersubjective community space to do so.
Solutions for this problem will have to be both technological and sociological. The core user group will have to understand and ‘buy’ into the added value of growth beyond the immediate domain expertise which in turn necessitates not only a conceptual shift in approaching the problem but also a multitude of technological advancements. Those will include sophisticated search tools that can query, access, and retrieve data from domain-specific databases across a variety of overlapping communities, which at the minimum requires shared ontologies, standardized metadata, and cross-authentications of access credentials.
A number of blogs and other informal communities have achieved
Another innovation of the blog world which brings us closer to community-to-community interaction is Linkback (also known as Trackback or Pingback depending on implementation). Each of these methods is used to inform blog authors of references to their articles. When a blog is published on a Linkback enabled server, the server sends a message to all links mentioned in the blog post. If the recipient of one of these messages is also a Linkback-enabled blog server, that server becomes aware that its posts are being mentioned elsewhere on the web. What happens at that point depends on the blog software. Usually the original blog post is updated with links to the referring posts. This effectively opens a portal between the two communities (and if OpenID is involved visiting the other side of that portal becomes several steps easier) but requires an active effort on the part of members of each side to communicate with the other side. Perhaps a more active way to encourage intercommunity participation would involve blog software which, instead of representing the Linkback as a link, displayed its entirety as a follow-up blog post. Blog software could even aggregate user comments together into one discussion between two or more distinct groups.
Similarly,
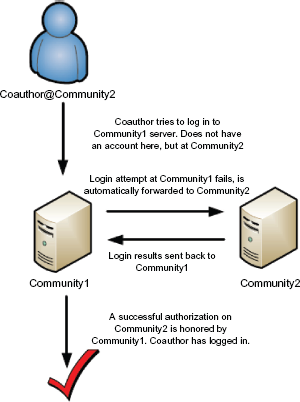
Login authentication forwarding. The coauthor of a paper is able to log in to the author's community site if it is configured to honor authorizations from the coauthor's own community.
This sharing paradigm is not dissimilar to the Digital Model Repository (DMR) run by CViT.org. The semantic-layered DMR infrastructure allows users to upload modeling files and to share those with other DMR users, either as individuals or as members of specific institutions. Because data files often have intellectual property value, all outgoing sharing has to be approved by an institution's licensing officer. This approval is tracked to ensure provenance of data ownership. This allows data to be shared between neighboring groups, while respecting the intellectual property rights of each group. That said the DMR is a single site. Even though the groups within CViT can be seen as distinct communities (see Fig. 3), they all exist in the same system on the same server. A true community-to-community interaction would have to take place between different community sites on different servers. Nonetheless, CViT allows and encourages discussion between researchers who would otherwise have no contact with each other. Furthermore this discussion takes place in near real time, allowing for research to be shared immediately, instead of at a rate determined by publishers.
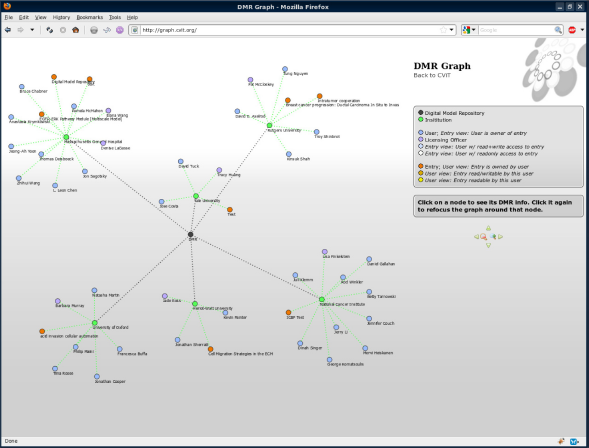
DMR graph. CViT graph shows institutions in the semantic layered Digital Model Repository and their respective users/projects.
As always,

Biomed Experts and Expert Mapper both contain a great many user profiles. These profiles are not user submitted. They are scraped from published papers. In the case of expert Mapper, researchers who publish under different names will have duplicate listings.
Conclusion
In summary, community-to-community interaction is one of the biggest challenges faced by developing scientific online communities. Global interdisciplinary Life Sciences research must figure out smart ways to have separately evolved expert networks and their infrastructures communicate. Cross-domain search, data retrieval, and ontology issues will remain important innovation areas to enable and facilitate this interaction.
Disclosures
This manuscript has been read and approved by all authors. This paper is unique and is not under consideration by any other publication and has not been published elsewhere. The authors and peer reviewers of this paper report no conflicts of interest. The authors confirm that they have permission to reproduce any copyrighted material.
Footnotes
Acknowledgements
This work has been supported in part by NIH grant CA 113004 and by the Harvard-MIT (HST) Athinoula A. Martinos Center for Biomedical Imaging and the Department of Radiology at Massachusetts General Hospital.