
Abstract
In this article, we propose a regression model to compare the performances of different diagnostic methods having clustered ordinal test outcomes. The proposed model treats ordinal test outcomes (an ordinal categorical variable) as grouped-survival time data and uses random effects to explain correlation among outcomes from the same cluster. To compare different diagnostic methods, we introduce a set of covariates indicating diagnostic methods and compare their coefficients. We find that the proposed model defines a Lehmann family and can also introduce a location-scale family of a receiver operating characteristic (ROC) curve. The proposed model can easily be estimated using standard statistical software such as SAS and SPSS. We illustrate its practical usefulness by applying it to testing different magnetic resonance imaging (MRI) methods to detect abnormal lesions in a liver.
Keywords
Introduction
The receiver operating characteristic (ROC) curve plots two accuracy measures of tests (the false-positive rate and the true-positive rate), which are frequently used to measure and compare the accuracy of different diagnostic methods. It frequently depends on covariates such as gender and age as in the hearing impairment example in Dodd and Pepe. 1 To explain the effects of covariates, the covariate-dependent ROC models are studied extensively in the literature. Two most common approaches are as follows: (i) one that introduces covariate-dependent error distributions 2 and (ii) the other that directly quantifies the covariate effect on the ROC curve.1,3–8
The clustered outcomes are multiple measurements of a diagnostic test from a single subject (or cluster). They typically occur when subjects are repeatedly tested over time and are naturally correlated to each other. The random-effects model is introduced to explain the correlation among observations within a cluster. In particular, the location-scale model, where the location and scale parameters are modeled with random effects to explain the correlation among observations within a cluster, is popularly used.9,10 On another direction, there are efforts to directly model the area under the ROC curve (AUC). Obuchowski 11 estimated the AUC (without covariates) with the Mann–Whitney (MW)-type statistics and made pairwise comparisons among several diagnostic methods. Dodd and Pepe 1 introduced the generalized estimation equation (GEE) framework to model the AUC with covariates. However, they both did not consider the clustered outcomes. Recently, Lim et al. 12 extended the study of Dodd and Pepe 1 to incorporate the clustered outcomes by considering a wider class of GEE weights and proposed a procedure to choose the optimal weights to minimize the variance of the regression estimator of interest.
Despite many scholastic discussions on the ROC regression model, we have a limited number of models for the clustered ordinal outcomes and practitioners still have difficulties in using them. In this article, we propose a simple regression model (a nonlinear mixed-effects model) for the clustered ordinal test results with covariates. The proposed model is originally from the proportional hazard model for grouped-survival (GS) time data by Hedeker et al. 13 We find that the proposed model defines a new type of location-scale model and also a Lehman family of ROC curves, where the Lehman family was proposed and extensively studied by Gönen and Heller. 15 Finally, due to the formulation of the GS time (or GS in short) model, our model can be estimated by fitting a nonlinear mixed-effects model, which is supported by many common statistical software, including SAS and SPSS.
The remainder of the article is composed of four sections. In the Model section, we introduce the model we proposed and discuss its connection to the existing models. In the Numerical study section, we present a numerical study to assess the performance of the proposed method. We apply the model to comparing different magnetic resonance imaging (MRI) methods to detect the presence of hepatic metastases in the Data example section. The Conclusion section provides a brief summary of the article. Finally, the sample codes for the example are presented in the Appendix section.
Model
This section introduces the nonlinear random effects model we proposed in this article. Let Yij be an ordinal marker value with K categories of the ith cluster (or subject) and the jth measurement (diagnostic result), for i = 1, 2, …, n, and j = 1,2, …, n i . Let x ij be a p-dimensional covariate vector and V i be a random effect to explain correlation of observations in the ith cluster. Let d ij be an indicator variable of the true diagnostic class, where d ij = 0 and d ij = 1 imply that the true class of the (i,j)th observation is normal (negative) class and tumor (positive) class, respectively.
The regression model we propose is, for k = 1, 2, …, K, as follows:

By reading the ordinal results as GS times, we have a handy and interesting class of nonlinear random-effects models for the ROC curves of correlated categorical diagnostic results. In particular, the model we propose is also closely related to the several models in the previous literature.
First, the model (1) with the link function as g(p) = log(–log p) defines an extension of the Lehmann family of the ROC curves to the model with random effects. Suppose x is a covariate vector attached to the test results Y. The Lehmann family of the ROC curves is defined as a collection of the ROC curves of the form:

where

Here, S0(t) is the survival function (=1 – cumulative distribution function) of the outcome of normal subject with x = 0. It assumes that the survival functions of normal and diseased subjects have the proportional hazard specification on the covariates. The hazard rate at (the outcome value) t is the instantaneous rate that we have a diagnostic outcome value at t when its value is known to be not <t. The proportional hazard means that the covariates are multiplicatively related to the hazard rate. Given the cluster-specific random effect v, our model specifies
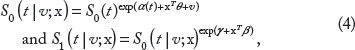
and its ROC curves forms the same Lehmann family (2) mentioned earlier. In addition, if we further assume that log v i is distributed as a gamma distribution, a simple algebra shows that the marginal model (integrating out v i ) also defines the same Lehmann family. Second, the model (1) is closely related to the location-scale ROC model introduced in Pepe (page 151 in Chapter 6.3), 16 that is
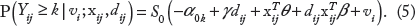
The model in (4) tells that, given V i , the survival function of Y ij is

and it defines the location-scale family mentioned earlier if log S0(t) = exp(–t). In addition, our model (4) assumes that the intercept is random in S0(t|v;x), and all other coefficient vectors are fixed, not cluster-specific random. This simplification makes the cluster-specific ROC curve be the same with (2).
Our primary goal of the ROC analysis is the comparison of different diagnostic methods. To do it, we introduce dichotomous covariates x indicating the choice of methods and test their coefficients in model (1). In our motivating example (the example followed in the next section), we have three imaging methods by two readers (two medical doctors who read the images) and we use the three-dimensional covariate vector with two levels (0 or 1), x = (xr,xm2,xm3), where x r = 1 implies the outcome is recorded by the second reader, xm2 = 1 implies the outcome is from the second imaging method, and xm3 = 1 implies the outcome is from the third imaging method.
Finally, the proposed model (1) is a nonlinear mixed-effects model, which is well studied in the literature. Many refined approximations to the likelihood function of the model are proposed and encoded into common statistical packages, including SAS and SPSS. The comparison of different diagnosis methods could be done by testing the regression coefficients of the covariates, indicating the choice of diagnostic methods. This feature is illustrated in details by analyzing a real data in the next section. We refer readers to Davidian and Giltinan 17 for the details of the nonlinear mixed-effects model.
Numerical Study
In this section, we conduct a small numerical study to access the performance of the proposed GS model. The study considers one sample problem to estimate and test the effectiveness of a single diagnostic method with the AUC instead of comparing the ROCs of two or more diagnostic methods. Thus, we have the diagnostic outcomes of two populations, say the normal and cancer populations, by a given diagnostic method.
The data sets for the study are generated as follows. The number of subjects from each population is set as 25 (n = 50 (= 25 + 25)) and 50 (n = 100 (= 50 + 50)). The number of repeated observations per subject is set as m = 2 and m = 4. The ordinal data are generated by categorizing exponentially distributed random variables as follows. For the ith subject of the normal population, we generate m continuous repeatedly measurements from the exponential distribution with the rate λ = 0.1v
i
, where log v
i
is from normal distribution with mean 0 and variance

where log v
i
is again from normal distribution with mean 0 and variance
In (7), γ = 0 implies that there is no difference in the distributions of diagnostic outcomes of normal and cancer populations. In the study, we vary γ = 0, 0.2, 0.4, 0.6, 0.8, 1.0 and consider the powers in testing H0: γ = 0 (versus γ > 0) as a measure of effectiveness of the procedure. To test the hypothesis, we apply the proposed GS model with link function

where d
i
is the indicator variable for the cancer population (it has value 1 if the ith subject is from the cancer population, otherwise, 0) and P
ij
(k|v
i
;d
ij
= P(Y
ij
≤ k|v
i
;d
i
) for k = 0, 1, 2, 3, 4. The hypothesis is tested by the Z-statistic
For the comparison, we consider the AUC estimate based on the MW statistic, which is popularly used in practice. Here, the MW statistic does not take into account the within-cluster correlation and treats all observations as independent samples. The sample AUC for the ordinal data is computed as the MW statistic with ties as

where U
ij
= 1, if

where Sk is the number of observations whose scores are j for k = 1, …, 5. The test for non-effectiveness of the diagnostic method is done using the standardized statistics
We generate 1000 data sets for each case of
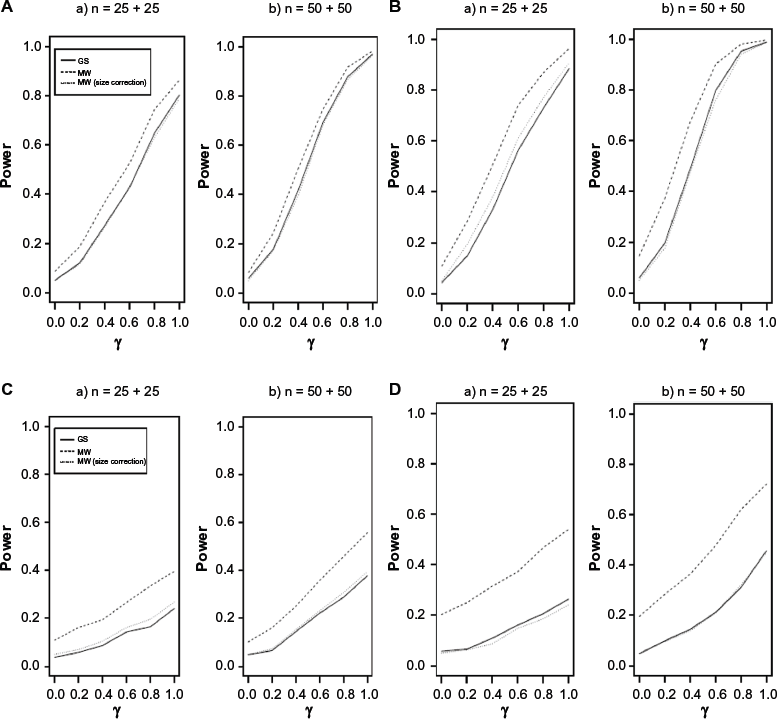
Power comparison between the proposed grouped-survival model-based and MW-based tests (not considering correlation among outcomes of a single subject). The “size corrected MW” implies the MW test is implemented with an empirically decided critical value. The empirical critical value is decided with the percentile of the (evaluated) MW test statistics for the case γ = 0. (
Figure 1 shows that the size of MW-based test (the power when γ = 0) is biased significantly and its magnitude increases as either
Data Example
In this section, we apply our model to the detection of hepatic lesions. The liver is the most frequent site of metastases from various extrahepatic malignancies, and determining the presence of hepatic metastases is important in order to provide the optimal plan for patients who are candidates for surgery and in order to assess prognosis after initial treatment.
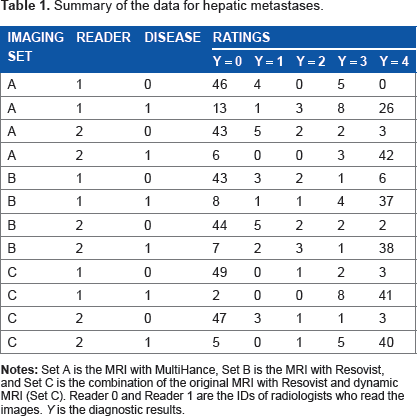
The data analyzed in this article are the records of patients who underwent liver MRI with separate acquisition of double contrast enhancement between November 2005 and June 2006. The data are collected from the database of the radiology department at Asan Medical Center in Seoul, Republic of Korea. The data record the test results of the 106 focal liver lesions from 36 patients
Summary of the data for hepatic metastases.
Let Y ij be the jth rating of the ith subject having an ordinal integer mark value between 0 and 4, for i = 1, 2, …, 36 and j = 1, 2, …, n i ; let d ij be the binary variable, which equals to 1 if the (i, j)th rating is from the disease (positive) group in truth, otherwise 0. For the (i, j)th rating, let x ij = (xijr, xij2, xij3) be the three-dimensional covariate vector of indicator variables, where x ijr = 1 if the rating is done by the first reader, xij2 = 1 if the rating is on the MRI by Set B, and xij3 = 1 if it is by Set C.
We apply the model (1) with the complementary log–log link, so that we have

where
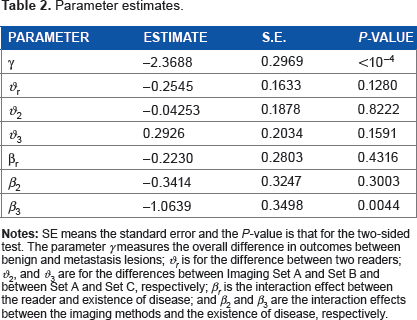
Table 2 displays the parameter estimates calculated from the data, and Figure 1 plots the estimated ROC curves for the six combinations of readers and MRI methods. The results tell that the MRI methods and the reader do not perform differently for normal liver lesions. However, for the tumor lesions, the MRI method Set C performs better than Set A (P-value = 0.0044). In addition, the P-value for jointly testing H0: β2 = β3 = 0 is 0.0160 and that for testing H0: β2 – β3 = 0 is 0.0490. This implies that the MRI method Set C performs better than any of Set A and Set B for tumor lesions. In tumor groups, there is no statistically significant difference between readers.
Parameter estimates.
The covariate-specific ROC curve R(u|x, d) from (11) is in the form of
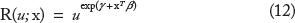
and its AUC is

Estimated ROC curves of three methods by two readers. The “Empirical” is the empirical ROC curve based on empirical (cumulative) distribution functions of (diagnostic outcomes of) normal and diseased populations. The Empirical disregards the correlations among repeated measurements of a subject and treats them as independent samples. The “Model” is the ROC curve from the model with the estimated parameters.
Table 3 summarizes the estimates of the AUCs for the combinations of a reader and an imaging method. The standard errors (SEs) of the model-based estimates of the AUC are obtained by the delta method. We also report their empirical estimates without taking account the within-cluster correlation of outcomes by Obuchowski. 11 The formulas of empirical estimates can also be found from Pepe (Chapter 6.3). 16
The estimates of the AUC and their SEs for the combinations of a reader and a picturing method.

The AUCs may not be always sensible to detect the differences for specific covariates, regardless of whether they are model based or empirical, since they are functional forms of many other components as given:
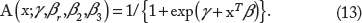
On the other hand, the proposed regression model can test the contribution from each covariate separately. To be specific, in our example, if we want to find the performance difference between imaging methods of Set A and Set C for reader 1, the (model-based) AUC estimates are 0.914 and 0.969, respectively. The 95% confidence interval for AUC of Set C is (0.793, 1), which overlaps the confidence interval of AUC for Set A, (0.876, 0.952). This indicates that there is no significant difference between the AUCs of two sets. However, the test based on the proposed regression model makes it possible to test the significance for particular parameter. For example, the P-value of test H0: β3 = 0 is 0.0044, and it indicates the existence of significant interaction between sets (A and C) and disease groups (disease and non-disease) at α = 0.05; this implies that the imaging methods A and C perform differently in detecting the cancer.
Conclusion
In this article, we propose a new ROC regression model for clustered ordinal outcomes. The new model views the ordinal outcomes as GS times and uses the grouped-time survival model to define the regression model of the ROC curve. It is shown that the proposed model is closely related with many existing models including the Lehman family and the location-scale family of the ROC curves and further provides their extensions to the random-effects models. Our proposed model has an additional advantage of being easily programmed in many standard statistical packages, which makes it easy to use and interpret. In summary, the model proposed in this article provides a flexible exploratory tool for identifying covariate effects on the ROC curve with clustered ordinal outcomes.
Author Contributions
Conceived and designed the experiments: S-CY, M-SL. Analyzed the data: JK, WS, DHR Wrote the draft of the manuscript: JK, JL. All authors reviewed and approved of the final manuscript.
Footnotes
Appendix
The following SAS code fits the random-effects grouped-time survival model:
DATA Final;
SET Temp; TRT2=0;TRT3=0;RD=0;TD2=0;TD3=0;
IF TRT=2 THEN TRT2=1;
IF TRT=3 THEN TRT3=1;
IF READER=2 AND DISEASE=1 THEN RD=1;
IF TRT=2 AND DISEASE=1 THEN TD2=1;
IF TRT=3 AND DISEASE=1 THEN TD3=1; RUN;
PROC NLMIXED DATA=Final;
PARMS b0=0 b1=0 b2=0 b3=0 b4=0 b5=0 b6=0 b7=0 sd=1 t2=1 t3=2 t4=3 t5=4;
ODS OUTPUT ParameterEstimates=estb;
Z=b0+b1*DISEASE + b2*TRT2+b3*TRT3+b4*READER+b5*RD+b6*TD2+b7*TD3+u;
DO;
IF (Y=0) THEN p=1-exp(0-exp(t2+z));
ELSE IF (Y=1) THEN p=(1-exp(0-exp(t3+z)))-(1-exp(0-exp(t2+z)));
ELSE IF (Y=2) THEN p=(1-exp(0-exp(t4+z)))-(1-exp(0-exp(t3+z)));
ELSE IF (Y=3) THEN p=(1-exp(0-exp(t5+z)))-(1-exp(0-exp(t4+z)));
ELSE IF (Y=4) THEN p=exp(0-exp(t5+z)); END;
like=LOG(p);
MODEL Y~ General(like);
Random u~ NORMAL(0,sd*sd)
SUBJECT=id;
CONTRAST “all TRT” b6, b7;
ESTIMATE ‘3 vs 2 TRT’ b7-b6;
RUN;