
Abstract
In the field of computer-aided mammographic mass detection, many different features and classifiers have been tested. Frequently, the relevant features and optimal topology for the artificial neural network (ANN)-based approaches at the classification stage are unknown, and thus determined by trial-and-error experiments. In this study, we analyzed a classifier that evolves ANNs using genetic algorithms (GAs), which combines feature selection with the learning task. The classifier named “Phased Searching with NEAT in a Time-Scaled Framework” was analyzed using a dataset with 800 malignant and 800 normal tissue regions in a 10-fold cross-validation framework. The classification performance measured by the area under a receiver operating characteristic (ROC) curve was 0.856 ± 0.029. The result was also compared with four other well-established classifiers that include fixed-topology ANNs, support vector machines (SVMs), linear discriminant analysis (LDA), and bagged decision trees. The results show that Phased Searching outperformed the LDA and bagged decision tree classifiers, and was only significantly outperformed by SVM. Furthermore, the Phased Searching method required fewer features and discarded superfluous structure or topology, thus incurring a lower feature computational and training and validation time requirement. Analyses performed on the network complexities evolved by Phased Searching indicate that it can evolve optimal network topologies based on its complexification and simplification parameter selection process. From the results, the study also concluded that the three classifiers – SVM, fixed-topology ANN, and Phased Searching with NeuroEvolution of Augmenting Topologies (NEAT) in a Time-Scaled Framework – are performing comparably well in our mammographic mass detection scheme.
Keywords
Introduction
Cancer is a major threat to human life, and studies have shown that breast cancer is the second most prevalent cancer in women after skin cancer. 1 It is also the second leading cause of cancer death in women after lung cancer. 1 Scientific evidence has shown that over the last four decades, early breast cancer detection combined with improved treatment strategies significantly reduced patients’ mortality and morbidity rates.2,3 As a result, mammography-based breast screening has been well established for early breast cancer detection. However, mammographic image interpretation is a difficult and time-consuming task, which also has large inter-reader variability in the cancer screening environment. To help improve the efficacy of screening mammography, in the last two to three decades, there has been a significant interest in the development and advancement of computer-aided detection (CAD) schemes of mammograms including detection of breast mass and micro-calcifications.
In CAD schemes for breast mass detection, a mass is defined as a space-occupying lesion seen in more than one projection, 4 and is frequently characterized by its shape and margin. In general, a mass with more regular and rounded shape has a high probability of being benign whereas a mass depicting an irregular and spicular shape has a high probability of being malignant. Studies have shown that CAD can improve the breast cancer detection rate at its early stages.5,6
Many CAD schemes have been developed for mass detection using various features (ie features based on shape, texture, spiculation, and presence of calcifications7–10) and different classifiers including linear discriminant analysis (LDA), support vector machines (SVMs), artificial neural networks (ANNs), Bayesian belief networks, and rule-based classifiers.7,9–15 In the literature, ANNs and SVMs are the two most popular classifiers that have been widely explored for mass detection and/or classification.7,11,16–20 However, a problem that is frequently associated with fixed-topology ANN classifiers is the determination or design of the optimal network topology or structure. In many approaches, the ANN topology is frequently determined by trial-and-error methods or experiments,8,11,16,20 which often lead to suboptimal solutions.
Genetic algorithms (GAs) are algorithms that are inspired by natural evolution, and proceed in a similar way as events that occur in natural evolution. The advantage of GAs is that they are purported to find globally optimal solutions that do not get trapped in local optima, which is a frequent issue associated with gradient descent algorithms in training of fixed-topology ANNs. In the literature for mass detection or classification, GAs and evolutionary algorithms have mainly been used for feature selection21,22 or parameter optimization,23,24 and rarely for directly determining the classifier topology. 25
In this study, we analyze a method that uses GAs to evolve ANNs with optimal weights and structure (hidden nodes, input features, and connections), which is called “Phased Searching with NEAT in a Time-Scaled Framework” 26 in our mass detection scheme. This framework is based on the NeuroEvolution of Augmenting Topologies (NEAT) algorithm proposed by Stanley and Miikkulainen 27 and Stanley et al. 28 The NEAT algorithm evolves both the weights and structure of ANNs, unlike most methods that only evolve the connection weights and have fixed topologies.29,30 NEAT's performance has been analyzed and proven in various and diverse domains.28,31–35
Recently, it was shown that Phased Searching with NEAT in a Time-Scaled Framework 26 and another variant of NEAT (feature-deselective NEAT or FD-NEAT)36,37 performed well in a lung nodule detection scheme of CT images. The advantage of Phased Searching over conventional NEAT is that feature selection is enabled in Phased Searching, and it produces simpler networks than FD-NEAT and NEAT, which are faster to train and validate, and require less parameter (connection weight) tuning.
In this paper, we analyze Phased Searching's performance in a computer-aided mass detection scheme, and compare its performance and optimization efficacy with four other established classifiers in this task, namely the fixed-topology ANNs, LDA, bagged decision trees, and SVMs using a common testing image dataset. The details of our experimental procedures and results are reported in the following sections.
Materials/Dataset
Our image dataset consists of 1,600 regions of interests (ROIs), which were randomly extracted from a large database of digitized screen-film-based mammograms. The detailed description of the image data characteristics has been previously reported.38–41 In this dataset, 800 ROIs are positive in which each consists of one mass region detected by radiologists during the original mammogram reading, and was later verified by pathology examinations from the biopsy specimens. The remaining 800 ROIs are negative, but involve the false-positive (FP) mass regions detected by our previous CAD scheme.39–41
The size of each ROI is 512 x 512 pixels, which was extracted from the center of each identified suspicious mass lesion. We used a multilayer topographic region growth algorithm9,38 to automatically segment the lesions. If there was noticeable segmentation error, the lesion boundary was corrected or re-drawn. Each lesion ROI was reduced or sub-sampled by a pixel averaging method using a kernel of 8 x 8 pixels in both x and y directions. The pixel size was thus increased from 50 x 50 μm in the original digitized image to 400 x 400 μm in the reduced image. Examples of a malignant mass and an FP detection from our dataset are displayed in Figures 1 and 2, respectively, along with their corresponding segmentations extracted by our mass segmentation scheme.

Example of a malignant mass ROI (
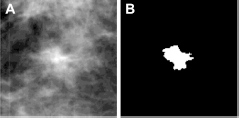
example of an FP ROI (
Methods
Neuroevolution
Neuroevolution methods use the evolutionary algorithms to train ANNs and can be divided into various groups based on the different encoding methods to optimize the connection weights and/or topology of the ANNs. 42 With the fixed-topology neuroevolution systems,43,44 the ANN topologies are fixed and only the node connection weights are evolved. Methods that evolve both the ANN weights and topologies are termed “topology and weight evolving artificial neural networks (TWEANNs).”27,32,45 With TWEANNs, each individual in the population has a full specification with complete weight representation or information. Fitness evaluation is also accurate as there is a one-to-one mapping between the genotype and its phenotype. 42 Another advantage of TWEANNs is that there is an option to start with minimal structure, and to increment structure only if there is an associated fitness improvement.
With TWEANNs, how to encode the individual genome is essential. The main issue associated with reproduction through the crossover process in TWEANNs is the competing conventions problem, also known as the permutations problem or variable length genome problem. 46 A systematic encoding system is required to ensure that there are no glitches in the evolutionary process, such as offspring genomes with the same structures being assigned to different innovation numbers or historical markings. Furthermore, a good encoding system will also ensure a more compact genome representation. Various types of encoding systems have been proposed in the literature.47–52
NEAT is another recently developed neuroevolution method that has been proven effective in various applications and successfully solved the competing conventions problem in TWEANNs.27,28 NEAT works through the process of complexification, namely the networks start with minimal topology, and structure is only incremented when it is found to improve or enhance network performance. 33 However, one of the pitfalls of NEAT is that feature selection is not enabled in NEAT. Feature selection is tremendously important as the exclusion of relevant features leads to suboptimal solutions, whereas the exclusion of irrelevant or redundant features adds unnecessary dimensions to the search space. In recent years, several variants of NEAT have been introduced and incorporated to feature selection or deselection (exclusion).26,31,53–55 For a more in-depth discussion on neuroevolution methods in the literature, the reader is referred to several literature reviews or surveys about the topic.42,56
Phased searching with NEAT in a Time-Scaled Framework
In Ref. 26, Phased Searching with NEAT in a Time-Scaled Framework was presented and examined on 360 CT scans from the public Lung Image Database Consortium (LIDC) database. The method was shown to outperform the conventional NEAT in terms of sensitivity results, complexity of evolved networks, and evolution time.
Phased searching is based on the NEAT algorithm, which is distinct from other neuroevolution methods in three ways: 27 (1) crossover of different topologies is performed using innovation numbers as historical markings, (2) structural innovation is protected by speciation, and (3) incremental growth is performed from almost minimal structure. Phased searching outperforms NEAT in that it enables automatic feature selection or deselection on the input feature set, removes redundant structure, and also evolves simpler networks that are faster to be trained and validated in the evolutionary run.
With Phased Searching with NEAT in a Time-Scaled Framework, the search for useful network topologies is evolved in alternating between complexification and simplification phases. 26 During the complexification phases, useful structure (features, nodes, and connections) is added to the networks whereas during the simplification phases, redundant and irrelevant structure is discarded. Hence, the process of discarding redundant and irrelevant connections enables the search for optimal structure to proceed faster. For a detailed description of Phased Searching with NEAT in a Time-Scaled Framework, the reader is referred to Ref.26.
In the previous work in Ref. 26 , the complexification and simplification phases were implemented with equal generation numbers. In this study, we analyzed the performance of Phased Searching with equal and different generation numbers for the complexification or simplification phases. We implemented a new fitness function computed as the maximization of the area under the receiver operating characteristic (ROC) curve (AUC) on the training subsets. Namely, the network that maximized the AUC result on the training subset was selected, and subsequently applied to the testing subset. The computation of the fitness function as the maximization of the AUC is a proven criterion function as it has been analyzed and shown to perform well on other GA-based schemes or methods.21,24
We also modified SharpNEAT 2.2.0, 57 which is a C# implementation of NEAT, to implement Phased Searching with NEAT in a Time-Scaled Framework. We also performed the training and validation of our mass detection scheme using a 10-fold cross-validation method, the details of which are provided in the Experimental Setup and Classification Methodology section. In any GA process, several runs on the training subsets have to be repeated to perform a global search over the search space for the optimal network before the trained network is applied on the testing subsets. We selected the network that maximized the AUC result on the training subset over five runs. This process was repeated 10 times for the 10 different training subsets using our 10-fold cross-validation method (namely, five runs for each training subset, repeated 10 times for the 10 individual subsets).
Feature computation
In this study, we computed 271 image features for our mass detection scheme on all 1,600 ROIs of our database. The top-level block diagram of our mass detection scheme is displayed in Figure 3. The computed features are based on shape, spiculation, texture, contrast, isodensity, presence and location of fat, and/or calcifications. We also included 27 previously computed features for mass detection in our previous studies.9,39 A summary of the computed features is provided in Table 1. In this section, we present a brief overview of these features; for their detailed description, the reader is referred to Ref.58.

A flow diagram of our mass detection scheme.
summary of computed image features for our mass detection scheme.

Various shape features have been proposed in the literature for mass detection or classification.7,11,14 We computed a mixture of novel and previously proposed shape features as listed in Table 1. The modified compactness59,60 and shape factor ratio61,62 are the most common and established shape features that have appeared in the literature. For a full description of the shape features, the reader is referred to Refs.58,63.
We proposed four fat-related features to determine the presence and location of fat within the segmented lesions. First, we applied an empirically determined threshold of 2,600 to extract the fat regions within the lesion segments. Then, we computed four features on the extracted fat regions: area, ratio of the fat area to the lesion segment area, number of fat regions within the mass (the fat regions were segmented by eight-connected-component labeling), and the average distance between the centroids of the segmented fat regions and the centroid of the whole lesion segment. We also computed three features to detect the presence of calcifications within the lesion segments, which are listed in Table 1 and are self-explanatory.
In the literature, many studies have proposed various texture features for mass detection or classification. 11 We computed some previously determined features (22 gray-level run length and 4 gray-level co-occurrence matrix-based features) on original (undilated) lesion segments. On dilated lesion segments, we computed 24 average and maximum values of gray-level co-occurrence matrix-based features, and 66 average and maximum values of gray-level run length-based texture features.
We have also computed some spiculation features on the lesion segments based on the divergence of the normalized gradient (DNG) and the curl of the normalized gradient (CNG). If an FP ROI is modeled as a circular region with homogeneous intensity against a darker background, the computation of the DNG feature should produce a maximum value at the location of its center point. On the other hand, the computation of the CNG feature will produce a high result at the location of the center point of a spicular region. We computed altogether 20 spiculation-based features (including mean, maximum, minimum, standard deviation, and median of the CNG and DNG, and the same statistical features computed on the maxima points located near the center regions of the lesion segments), on Gaussian-blurred images of the lesion segments.
In Ref. 58 we presented a novel approach of computing four previously determined contrast measures8,62,64 over differently predefined inner and outer regions of the lesion segments. Our approach differs from previous approaches in that we compute the contrast features over different-sized regions of the lesion and over different regions of the lesion background. This approach is based on our observation that different inner regions of the lesion have different structural appearances and intensities eg, pixels immediately adjacent to the mass contour frequently have a different structure and appearance from the pixels near the center of the mass region. Additionally, different regions of the lesion background have a different structural appearance ie the pixel intensities near the lesion contour are slightly higher than the pixel intensities further away.
To compute the contrast-based features, we extracted the outer region (O), by dilating the lesion segment with fat, disk-shaped, or “disc” structuring elements (SEs) of three different sizes: (1) mean radial length of the mass, (2) 1/2 of the mean radial length, and (3) 1/4 of the mean radial length, whereby the mean radial length was defined previously. 61 We also defined the inner region of the lesion (I) by the whole inner segment of the lesion within its contour, and also defined two other regions of the lesion by performing an erosion operation on I. To obtain the other two inner segments, we performed an erosion operation on I using a “disc” SE of three different sizes: (1) mean radial length of the mass, (2) 1/2 of the mean radial length, and (3) 1/4 of the mean radial length. After the erosion operation, we obtained the eroded image denoted by I1, and the resultant image by subtracting I 1 from I, denoted by I 2. Thus, the new contrast-based features were computed between the inner and outer regions of the mass (between O and I, O and I 1, and O and I 2). In this way, we computed altogether 5 x 3 x 4 = 60 contrast-based features per lesion segment.
Finally, we computed 27 ROI morphological features that were defined in our previous publications.9,39,65 These features consisted of different intensities, contrasts, shapes, border segments, and local topological-based features.
Performance comparisons with other classifiers
To assess Phased Searching's performance, we performed performance comparisons with other well-established classifiers for the mass detection task, namely fixed-topology ANNs, SVMs, bagged decision trees, and LDA. The parameter tuning for each classifier was performed on the training subsets that were kept completely separated from the testing subsets.
First, we trained and optimized a LIBSVM classifier
66
with the radial basis function (RBF) kernel, defined as K(
Second, we analyzed a standard feed-forward ANN with a single hidden layer and with a hyperbolic tangent activation function at the hidden nodes, and a linear activation function at the output node (default parameters in the Matlab® Neural Network toolbox). The number of input nodes was equal to the number of features (271). The fixed-topology ANN was trained by a backpropagation algorithm whereby the network's performance was analyzed for 2–40 nodes in the hidden layer (using the AUC computed on the training set as the performance measure), which was always initialized with random weights.
Third, the LDA and decision tree classifiers are also popular and used for mass detection.11,68–72 We included them in our study. Bagged decision trees are an ensemble of classification trees, and in initial experiments, they gave a better response than the single decision tree with binary splits for classification. The LDA classifier is a traditional classification method that has a high performance for linearly separable problems; however, it might adapt poorly for non-linear separable data.
The input features were linearly normalized (between 0 and 1) for the SVM, fixed-topology ANN, and Phased Searching classifiers. For LDA and bagged decision trees, normalization of the input features did not affect the classifier outcomes, and was thus omitted.
Experimental setup and classification methodology
Training and validation of our mass detection scheme was performed in a 10-fold cross-validation framework. In this method, the 800 malignant true-positive (TP) ROIs and 800 FP ROIs were randomly segmented into 10 exclusive subsets. Classifier training was then performed on nine TP and nine FP subsets, with the remaining one TP subset and one FP subset used for testing. This process was repeated iteratively using the different combinations of the nine TP and nine FP subsets each time so that each of the TP and FP ROIs was tested once with a classifier-generated probability score. Finally, the results on all 10 testing subsets were averaged and used to generate a ROC curve. By averaging the results on the 10 testing subsets, we can obtain the mean and standard deviation intervals at specific points on the ROC curve.
We also computed the AUCs of each examined classifier, and performed statistical significance tests on the obtained results. Furthermore, we performed an analysis on the features selected by Phased Searching in terms of frequency of selection per feature grouping/type. This analysis is important to examine the features that were beneficial for Phased Searching, and were thus included in the learning process and throughout the evolutionary run(s).
We performed an analysis of varying the alternating complexification and simplification parameter values of Phased Searching. In the original study performed on 360 lung CT scans from the LIDC database, 26 Phased Searching was examined only for equal values of the alternating complexification or simplification phases or cycles. Thus, in this study, we analyzed Phased Searching's performance for equal and unequal values of the complexification and simplification phases. We performed the following analysis on the networks evolved by Phased Searching: (1) best fitness per generation, (2) complexity (number of connections) of the best network per generation, and (3) average network complexity per generation. The AUCs obtained by varying the complexification or simplification parameters are tabulated.
Results
The computed ROC curves for all analyzed classifiers are displayed in Figure 4. We also computed and tabulated the average AUC results with standard deviation intervals over the 10 folds of each classifier in Table 2. The results indicate that SVM, fixed-topology ANNs, and Phased Searching outperform the bagged decision trees and LDA classifiers. The SVM classifier slightly outperformed the ANN and Phased Searching classifiers.

ROC curves of the five compared classifiers computed over the 10-fold cross-validation experiments–(1) Phased searching with neat in a time-scaled framework using the maximization of AUC as the fitness function, (2) fixed-topology ANNs, (3) SVMs, (4) bagged decision trees, and (5) LDA. The error bars are symmetric, and are two standard deviation units in length.
Average AUC values and the corresponding standard deviations for the five compared classifiers computed using the 10-fold cross-validation experiments.

Table 3 displays the P-values comparing the AUC results of the different classifiers. In Table 3, the diagonal P-values are equivalent and thus omitted. It shows that Phased Searching outperforms the bagged decision trees and LDA classifiers, and the difference in the AUC results is statistically significant for bagged decision trees (P, 0.001), but not for LDA (P = 0.270). SVM outperforms Phased Searching with a statistical significance (P = 0.026). Fixed-topology ANNs slightly outperform Phased Searching, but the difference is not statistically significant (P = 0.242). SVM also outperforms fixed-topology ANNs, but it is not statistically significant (P = 0.196). LDA is significantly outperformed by ANN (P = 0.024) and SVM (P = 0.002).
Student's t-test performed at the 5% significance level to study if the AUC results of the different classifiers are significantly different from each other. The P-value of rejecting the null hypothesis is given in the table. The diagonal P-values in the table are equivalent; thus, they have been omitted (–).

Table 4 shows the distributions of the features selected or retained by Phased Searching at the end of the evolutionary runs. The middle column of Table 4 shows the number of features in each group (eg, there are 4 fat-related features out of 271 total features). The far-right column thus displays the percentage of features that were retained in the group and their standard deviation intervals computed over the 10-fold cross-validation experiments. For example, 80.0% of the fat-related features (80.0% x 4 = 3.2 features) were retained by Phased Searching with a standard deviation interval of 23.0% or 0.92 features.
features selected or retained by Phased searching with neat in a time-scaled framework. The 271 proposed features are divided into nine feature groups or types listed in the far-left column. The number of the features represented in each group is represented in the middle column. The average percentages of the features selected by Phased searching with standard deviation intervals are shown in the far-right column.

Figures 5–7 display the results of the analysis performed as the change of complexification and simplification parameters selected in Phased Searching algorithm. The figures display the average and standard deviation intervals of the best fitness, complexity of the best network, and average network complexity, respectively, of the networks evolved over the 10-fold cross-validation experiments. The AUC results corresponding to the performed parameter analysis are tabulated in Table 5.
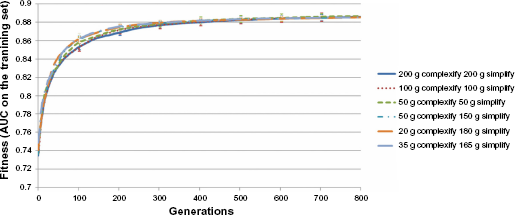
Graphs of the fitness computed as the AUC of the training subsets of the best network per generation in the run of the best-performing network (selected out of five runs), averaged on the 10 folds of Phased Searching with NEAT in a Time-Scaled Framework with alternating generations of complexification or simplification phases.

Graphs of the number of connections of the best network per generation in the run of the best-performing network (selected out of five runs), averaged on the 10 folds of Phased Searching with NEAT in a Time-Scaled Framework with alternating generations of complexification or simplification phases.

Graphs of the average network complexity (average number of connections) per generation in the run of the best-performing network (selected out of five runs), averaged on the 10 folds of Phased Searching with NEAT in a Time-Scaled Framework with alternating generations of complexification or simplification phases.
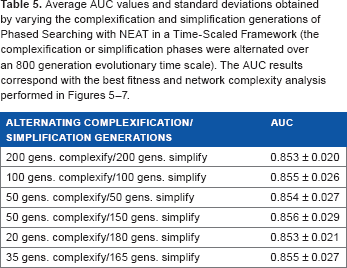
average AUC values and standard deviations obtained by varying the complexification and simplification generations of Phased searching with neat in a time-scaled framework (the complexification or simplification phases were alternated over an 800 generation evolutionary time scale). The AUC results correspond with the best fitness and network complexity analysis performed in Figures 5–7.
Discussion
The results show that Phased Searching outperformed bagged decision trees and LDA in the classification task, and its performance was not significantly different from the ANN classifier (P = 0.242). SVM produced the best performance among all the classifiers analyzed, and significantly outperformed Phased Searching at the 5% significance level (P = 0.026). This result is somehow unexpected. We had initially expected that the number of input features (271) was too large for the task at hand, and that Phased Searching's ability to select relevant features during the complexification phases and discard (deselect) irrelevant and redundant features during the simplification phases would give it an advantage over the other classifiers. The results indicate, however, that the inclusion of the 271 features was beneficial for the classifiers analyzed, especially for the fixed-topology ANN and SVM classifiers.
Another advantage of the SVM classifier over ANNs is that it is a maximum margin classifier, namely it minimizes the classification error and maximizes the geometric margin simultaneously. In doing so, unlike ANNs, SVM does not suffer from “overfitting” on the training sets. Phased Searching, which is an ANN-based classifier, can thus also be affected by “overfitting.” Furthermore, as Phased Searching relies entirely on GAs during the training and evolution processes, the GA algorithm enables it to search globally optimal solutions; however, its performance might be affected by the lack of a refinement procedure (such as backpropagation training). 42
Although Phased Searching was outperformed by SVM, it performed better than the LDA and decision tree classifiers, both of which are widely used and are highly popular for mass detection.11,68–72 Furthermore, Phased Searching's overall performance is comparable with and simultaneously uses fewer features than fixed-topology ANNs. Although it is slightly outperformed by SVM, it requires the computation of fewer features, which reduces the computational time requirement at the feature computation stage, and also reduces the overall training and validation time requirement of the mass detection scheme.
The results of the analysis of features selected by Phased Searching at the end of 800 generations show that the fat, calcification, and shape-related features were most frequently selected or retained by Phased Searching. The isodensity and spiculation features were the least frequently selected features.
The results of analyzing the complexification or simplification parameters in Table 5 and in Figures 5–7 show that varying these parameters only produced a small change in the AUC results of Phased Searching. The highest AUC result of 0.856 ± 0.029 was obtained from an experiment involving 50 generations of complexification and 150 generations of simplification, which indicates that those were the best parameters for the classification task at hand.
This outcome cannot be ultimately predicted from the analysis performed on the fitness of the best networks evolved for more than 800 generations in Figure 5, as the graphs for the unequal complexification or simplification runs overlap too closely. However, in Figures 6 and 7, namely the analysis of the best network and average network complexities, we observe that the network complexities in the experiment involving the 50 complexification and 150 simplification generations stabilized at a fixed value or range at the end of 800 generations. For the experiments of equal complexification and simplification generations (ie, 200, 100, and 50), the average and the best network complexities displayed an increasing trend, and continued to increase at the end of 800 generations. This trend in the network complexities was also observed in the original experiments that analyzed Phased Searching's performance in a lung nodule detection task, which was conducted solely with equal complexification and simplification phases. 26
The average and the best network complexities obtained for the other two experiments conducted with unequal complexification or simplification generations (namely, 35 complexification or 165 simplification generations, and 20 complexification or 180 simplification generations) in Figures 6 and 7 show that unlike the experiment with a mix of 50 complexification and 150 simplification generations, the network complexities gradually decreased and did not stabilize at the end of 800 generations for these two experiments. The results in Figures 5–7 and the corresponding AUC results in Table 5 indicate that the optimal network topologies (connections and nodes) were evolved for the 50 complexification and 150 simplification generation parameter values, which produced the best network and average network complexities to evolve and stabilize the classification task at hand.
Although this study demonstrates promising results, it is rather preliminary and has a number of limitations. For example, this is a laboratory-based technology development study using a testing dataset with an equal number of positive to negative images, which does not represent the actual cancer prevalence ratio in general breast screening practice. Also, as a relatively small image testing dataset, the potential case selection bias might exist making it unable to fully represent the diversity in the general breast cancer screening population. Therefore, the robustness of this new approach and our new scheme needs to be further validated using the large and diverse image databases in future studies.
Conclusions
We conducted experiments to analyze a new GA-based classifier, Phased Searching with NEAT in a Time-Scaled Framework in a challenging computer-aided mass detection task, and compared its performance with several other well-established classifiers in the field. Phased Searching achieved an AUC result of 0.856 ± 0.029, and significantly outperformed a bagged decision tree classifier (P, 0.001), and slightly outperformed an LDA classifier (P = 0.270). Phased Searching was only significantly outperformed by the SVM classifier (P = 0.026), and performed comparably with the fixed-topology ANN classifier (P = 0.242). The highest AUC result was achieved in this task by the SVM classifier (AUC = 0.886 ± 0.026). Analysis performed on the network complexities evolved by Phased Searching indicates that it can evolve optimal network topologies provided that its complexification and simplification parameters are optimally chosen, as it produced AUC results that are comparable to the state-of-the-art classifiers, but with fewer number of features being selected, and thus a lower training and validation time requirement. From this study, it can also be concluded that the three classifiers, namely SVM, fixed-topology ANN, and Phased Searching with NEAT in a Time-Scaled Framework, are performing comparably well in our computer-aided mammographic mass detection scheme.
Author Contributions
MT, JP, and BZ conceived and designed the experiments. MT analyzed the data. MT wrote the first draft of the manuscript. MT and BZ contributed to the writing of the manuscript. MT, JP, and BZ agreed with manuscript results and conclusions. MT and BZ jointly developed the structure and arguments for the paper. MT, J P, and BZ made critical revisions and approved the final version. All authors reviewed and approved the final manuscript.
Supplementary Data
The parameters are based on SharpNEAT 2.2.0, 57 and remained constant throughout the evolutionary run. The best parameter values were obtained on the training subsets of the 10-fold cross-validation experiments, which were kept completely separated from the testing subsets:
Population number (number of genomes/networks): 200
Species number: 10
Number of generations (per run): 800
Connection weight range: {-0.05, 0.05}. This parameter gets or sets the connection weight range to use in the genomes eg, a value of 5 defines a weight range of -5 to 5. The weight range is strictly enforced ie when creating new connections and mutating existing ones.
Probability that all the excess and disjoint genes were copied into an offspring genome during sexual reproduction: 0
Interspecies mating rate: 0.01
Elitism proportion: 0.2. The species genomes are first sorted by fitness. The top N% are kept, whereas the other genomes are removed to make way for the offspring.
Selection proportion: 0.2. The species genomes are first sorted by fitness. Then, the parent genomes are selected for producing offspring from the top N%. Selection is performed before elitism is applied, thus selecting from more genomes than will be made elite is possible.
We also used the hyperbolic tangent activation function at the hidden nodes and a modified sigmoidal activation function 27 at the output node.
The following parameter values were used only during the complexification phases:
Probability of adding a new node: 0.15
Probability of adding a new connection: 0.35
Connection weight mutation probability: 0.5
Probability that a genome mutation was a “delete connection” mutation: 0.001
Proportion of offspring from asexual reproduction (mutation): 0.8
Proportion of offspring from sexual reproduction (crossover): 0.2
These parameter values follow a logical pattern eg, connections (links) need to be added more often than nodes. The following parameter values were used only during the simplification phases:
Connection weight mutation probability: 0.6
Probability that a genome mutation was a “delete connection” mutation: 0.4
Proportion of offspring from asexual reproduction (mutation): 1
Proportion of offspring from sexual reproduction (crossover): 0.