
Abstract
Because of privacy concerns and the expense involved in creating an annotated corpus, the existing small-annotated corpora might not have sufficient examples for learning to statistically extract all the named-entities precisely. In this work, we evaluate what value may lie in automatically generated features based on distributional semantics when using machine-learning named entity recognition (NER). The features we generated and experimented with include n-nearest words, support vector machine (SVM)-regions, and term clustering, all of which are considered distributional semantic features. The addition of the n-nearest words feature resulted in a greater increase in F-score than by using a manually constructed lexicon to a baseline system. Although the need for relatively small-annotated corpora for retraining is not obviated, lexicons empirically derived from unannotated text can not only supplement manually created lexicons, but also replace them. This phenomenon is observed in extracting concepts from both biomedical literature and clinical notes.
Keywords
Background
One of the most time-consuming tasks faced by a Natural Language Processing (NLP) researcher or practitioner trying to adapt a machine–learning based NER system to a different domain is the creation, compilation, and customization of the needed lexicons. Lexical resources, such as lexicons of concept classes, are considered necessary to improve the performance of NER. It is typical for medical informatics researchers to implement modularized systems that cannot be generalized. 1 As the work of constructing or customizing lexical resources needed for these highly specific systems is human-intensive, automatic generation is a desirable alternative. It might be possible that empirically created lexical resources would incorporate domain knowledge into a machine-learning NER engine and increase its accuracy.
Although many machine–learning based NER techniques require annotated data, semi-supervised and unsupervised techniques for NER have long been explored due to their value in domain robustness and minimizing labor costs. Some attempts at automatic knowledgebase construction included automatic thesaurus discovery efforts, 2 which sought to build lists of similar words without human intervention to aid in query expansion or automatic lexicon construction. 3 More recently, the use of empirically derived semantics for NER is used by Finkel and Manning, 4 Turian et al, 5 and Jonnalagadda et al 6 Finkel's NER tool uses clusters of terms built apriori from the British National corpus 7 and English gigaword corpus 8 for extracting concepts from newswire text and PubMed abstracts for extracting gene mentions from biomedical literature. Turian et al 5 also showed that statistically created word clusters9,10 could be used to improve named entity recognition. However, only a single feature (cluster membership) can be derived from the clusters. Semantic vector representations of terms had not been used for NER or sequential tagging classification tasks before. 5 Although Jonnalagadda et al 6 use empirically derived vector representation for extracting concepts defined in the GENIA 11 ontology from biomedical literature using rule-based methods, it was not clear whether such methods could be ported to extract other concepts or incrementally improve the performance of an existing system. This work not only demonstrates how such vector representation could improve state-of-the-art NER, but also that they are more useful than statistical clustering in this context.
Methods
We designed NER systems to identify treatment, tests, and medical problem entities in clinical notes and proteins in biomedical literature. Our systems are trained using (1) sentence-level features using training corpus; (2) a small lexicon created, compiled, and curated by humans for each domain; and (3) distributional semantics features derived from a large unannotated corpus of domain-relevant text. Different models are generated through different combinations of these features. After training for each concept class, a Conditional Random Fields (CRF) machine-learning model 12 is created to process input sentences using the same set of NLP features. The output is the set of sentences with the concepts tagged. We evaluated the performance of the different models in order to assess the degree to which human-curated lexicons can be substituted by the automatically created list of concepts.
The architecture of the system is shown in Figure 1 and the different components and settings are detailed in Table 1. We first used a state-of-the-art NER algorithm, CRF, as implemented by MALLET, 13 that extracts concepts from both clinical notes and biomedical literature using several sentence-level orthographic and linguistic features derived from respective training corpora. Then, we studied the impact on the performance of the baseline after incorporating manual lexical resources and empirically generated lexical resources. The CRF algorithm classifies words according to IOB or IO-like notations (I = inside, O = outside, B = beginning) to determine whether they are part of a description of an entity of interest, such as a treatment or protein. We used four labels for clinical NER: “Iproblem,” “Itest,” and “Itreatment,” for tokens that were inside a problem, test, or treatment respectively, and “O” if they were outside any clinical concept. For protein tagging, we used the IOB notation, ie, the three labels “Iprotein,” “Bprotein,” and “O.”
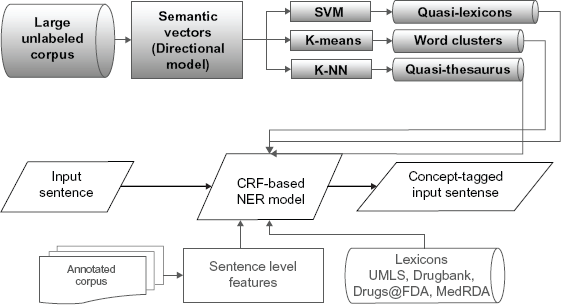
Description of different components and settings of the system.
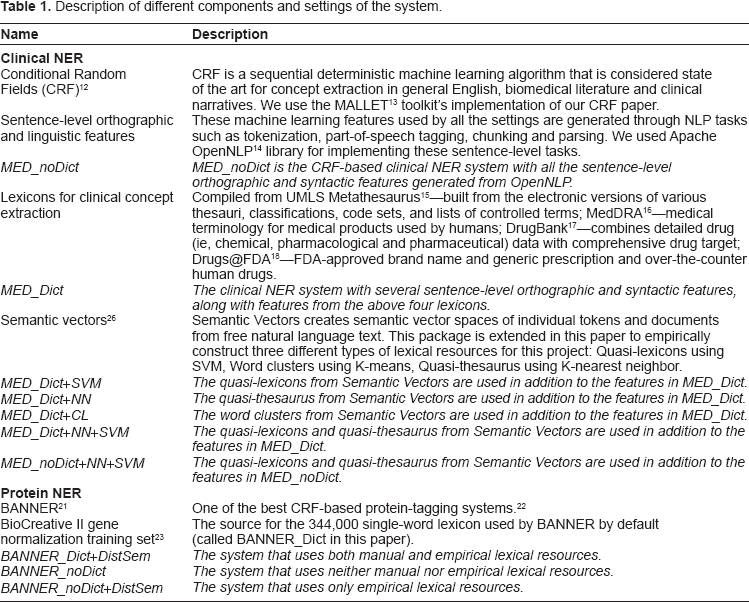
Overall Architecture of the System.
Several sentence-level orthographic and linguistic features such as lower-case tokens, lemmas, prefixes, suffixes, n-grams, patterns such as “beginning with a capital letter” and parts of speech were adapted from the OpenNLP 14 package to build the NER model and tag the entities in input sentences. This configuration is referred to as MED_noDict for clinical NER and BANNER_noDict for protein tagging.
The UMLS Metathesaurus, 15 MedDRA, 16 DrugBank, 17 and Drugs@FDA 18 are used to create dictionaries for medical problems, treatments, and tests. The guidelines of the i2b2/VA NLP entity extraction task 19 are followed to identify the corresponding UMLS semantic types for each of the three concepts. The other three resources are used to add more terms to our manual lexicon. In an exhaustive evaluation on the nature of the resources by Gurulingappa et al, 20 UMLS and MedDRA were found to be the best resources for extracting information about medical problems among several other resources. For protein tagging, BANNER, 21 one of the best protein-tagging systems, 22 uses the 344,000 single-word lexicon constructed using the BioCreative II gene normalization training set. 23 This configuration is referred to as MED_Dict for clinical NER and as BANNER_Dict for protein tagging.
Distributional Semantic Feature Generation
Here, we implemented automatically generated distributional semantic features based on a semantic vector space model trained from unannotated corpora. This model, referred to as the directional model, uses a sliding window that is moved through the text corpus to generate a reduced-dimensional approximation of a token-token matrix, such that two terms that occur in the context of similar sets of surrounding terms will have similar vector representations after training. As the name suggests, the directional model takes into account the direction in which a word occurs with respect to another by generating a reduced-dimensional approximation of a matrix with two columns for each word, with one column representing the number of occurrences to the left and the other column representing the number of occurrences to the right. The directional model is therefore a form of sliding-window based Random Indexing,
24
and is related to the Hyperspace Analog to Language.
25
Sliding-window Random Indexing models achieve dimension reduction by assigning a reduced-dimensional index vector to each term in a corpus. Index vectors are high dimensional (eg, dimensionality on the order of 1,000), and are generated by randomly distributing a small number (eg, on the order of 10) of +1's and
The performance of distributional models depends on the availability of an appropriate corpus of domain-relevant text. For clinical NER, 447,000 Medline abstracts that are indexed as pertaining to clinical trials are used as the unlabeled corpus. In addition, we have also used clinical notes from the Mayo Clinic and the University of Texas Health Science Center to understand the impact of the source of unlabeled corpus. For protein NER, 8,955,530 Medline citations in the 2008 baseline release that include an abstract 27 are used as the large unlabeled corpus. Previous experiments 28 revealed that using a directional model with 2000-dimensional vectors, five seeds (number of +1's and –1's in the vector), and a window radius of six is better suited for the task of NER. While a stop-word list is not employed, we have rejected tokens that appear only once in the unlabeled corpus or have more than three nonalpha-betical characters.
SVM: quasi-lexicons of concept classes using SVM
A support vector machine (SVM) 29 is designed to draw hyper-planes separating two class regions such that they have a maximum margin of separation. Creating the quasi-lexicons (automatically generated word lists) is equivalent to obtaining samples of regions in the distributional hyperspace that contain tokens from the desired (problem, treatment, test, and none) semantic types. In clinical NER, each token in a training set can belong to either one or more of the classes: problem, treatment, test, or none of these. Each token is labeled as “Iproblem,” “Itest,” “Itreatment,” or “Inone.” To remove ambiguity, tokens that belong to more than one category are discarded. For example, based on the information that “thoracic cancer” is a problem, “CT of the thoracic cavity” is a test and “thoracic surgery” is a treatment, “thoracic” is discarded, “cancer” is labeled as problem, “CT” is labeled as test, and “surgery” is labeled as treatment. Each token has a representation in the distributional hyperspace of 2,000 dimensions. Six (C[4,2] = 4!/[2!*2!]) binary SVM classifiers are generated for predicting the class of any token among the four possible categories. During the execution of the training and testing phase of the CRF machine-learning algorithm, the class predicted by the SVM classifiers for each token is used as a feature for that token.
CL: clusters of distributionally similar words over K-means
The K-means clustering algorithm 30 is used to group the tokens in the training corpus into 200 clusters using distributional semantic vectors. As an illustration, cluster number 33 contains the tokens: Sept, August, January, December, October, March, April, November, June, July, Nov, February, and September. Cluster number 46 contains the tokens: staphylococcus, faecium, enterococci, staphylococci, hemophilus, streptococcus, pneumoniae, klebsiella, bacteroides, coli, enterobacter, mycoplasma, aureus, anitratus, influenzae, calcoaceticus, serratia, aeruginosa, diphtheroids, proteus, methicillin, enterococcus, cloacae, oxacillin, mucoid, escherichia, mirabilis, fragilis, citrobacter, staph, acinetobacter, faecalis, pseudomonas, legio-nella, coagulase, and viridans. The cluster identifier assigned to the target token is used as a feature for the CRF-based system for NER. This feature is similar to the Clark's automatically created clusters, 10 used by Finkel and Manning, 31 where the same number of clusters are used. We focused on using features generated from semantic vectors as they allow us to also create the other two types of features.
NN: quasi-thesaurus of distributionally similar words using nearest neighbors
Cosine similarity of vectors is used to find the 20 nearest tokens for each token. These nearest tokens are used as features for the respective target token. Figure 2 shows the top few tokens closest in the word space to “haloperidol” to demonstrate how well the semantic vectors are computed. Each of these nearest tokens is used as an additional feature whenever the target token is encountered. Barring evidence from other features, the word “haloperidol” would be classified as belonging to the “medical treatment,” “drug,” or “psychiatric drug” semantic class based on other words belonging to that class sharing nearest neighbors with it.
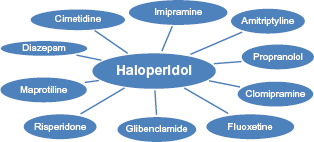
Nearest Tokens to Haloperidol.
Evaluation strategy
The previous sub-sections detail how the manually created lexicons are compiled and how the empirical lexical resources are generated from semantic vectors (2000 dimensions). In the machine-learning system for extracting concepts from literature and clinical notes, each manually created lexicon (three for the clinical notes task) contributes one binary feature whose value depends on whether a term surrounding the word is present in the lexicon. Each quasi-lexicon will also contribute one binary feature whose value depends on the output of the SVM classifier discussed before. Together, the distributional semantic clusters contribute a feature whole value that is the id of the cluster which the word belongs to. The quasi-thesaurus contributes 20 features which are the 20 words distributionally similar to the word for which features are being generated.
As a gold standard for clinical NER, the fourth i2b2/VA NLP shared-task corpus 19 for extracting concepts of the classes–-problems, treatments, and tests–-was used. The corpus contains 349 clinical notes as training data and 477 clinical notes as testing data. For protein tagging, the BioCreative II Gene Mention Task 32 corpus is used. The corpus contains 15,000 training set sentences and 5,000 testing set sentences.
Results
Comparison of different types of lexical resources on extracting clinical concepts
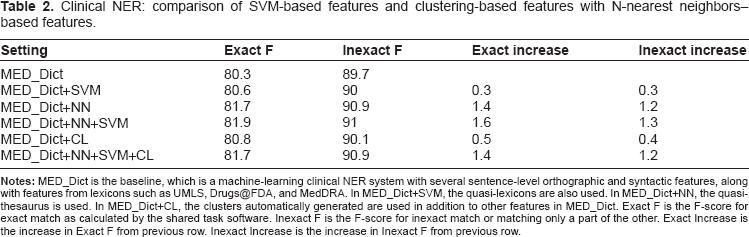
Table 2 shows that the F-score of the clinical NER system for exact match increases by 0.3% after adding quasi-lexicons, whereas it increases by 1.4% after adding the quasi-thesaurus. The F-score increases slightly more with the use of both these features. The F-score for an inexact match follows a similar pattern. Table 2 also shows that the F-score for an exact match increases by 0.5% after adding clustering-based features, whereas it increases by 1.6% after adding quasi-thesaurus and quasi-lexicons. The F-score decreases slightly with the use of both the features. The F-score for an inexact match follows a similar pattern.
Clinical NER: comparison of SVM-based features and clustering-based features with N-nearest neighbors–based features.
Overall impact on extracting clinical concepts
Table 3 shows how the F-score increased over the baseline (MED_noDict, which uses various sentence-level orthographic and syntactic features). After manually constructed lexicon features are added (MEDDict), it increased by 0.9%. On the other hand, if only distributional semantic features (quasi-thesaurus and quasi-lexicons) were added without using manually constructed lexicon features (MED_noDict+NN+SVM), it increased by 2.0% (
Clinical NER: impact of distributional semantic features.

Moreover, the improvement was consistent even across different concept classes, namely medical problems, tests, and treatments. Each time the distributional semantic features are added, the number of TPs increases, and the number of FPs and FNs decreases.
Impact of the source of the unlabeled data
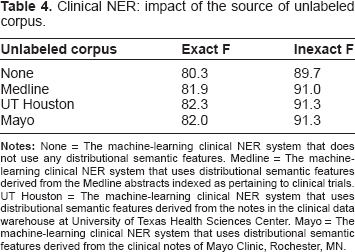
We utilized three sources for creating the distributional semantics models for NER from i2b2/VA clinical notes corpus. The first source is the set of Medline abstracts indexed as pertaining to clinical trials (447,000 in the 2010 baseline). The second source is the set of 0.8 million clinical notes (half of the total available) from the clinical data warehouse at the School of Biomedical Informatics, University of Texas Health Sciences Center, Houston, Texas (http://www.uthouston.edu/uth-big/clinical-data-warehouse.htm). The third source is the set of 0.8 million randomly chosen clinical notes written by clinicians at Mayo Clinic in Rochester. Table 4 shows the performance of the systems that use each of these sources for creating the distributional semantics features. Each of these systems has a significantly higher F-score than the system that does not use any distributional semantic feature (
Clinical NER: impact of the source of unlabeled corpus.
Impact of the size of the unlabeled data
Using a set of 1.6 million clinical notes from the clinical data warehouse at the University of Texas Health Sciences Center (after adding 0.8 million clinical notes to those in the previous experiment) as the baseline, we studied the relationship between the size of the unlabeled corpus used and the accuracy achieved. We randomly created subsets of size one-half, one-fourth, and one-eighth the original corpus and measured the respective F-scores. Figure 3 depicts the F-score for exact match and inexact match, suggesting a mono-tonic relationship with the number of documents used for creating the distributional semantic measures. While there is a leap from not using any unlabeled corpus to using 0.2 million clinical notes, the F-score is relatively constant from there. We might infer that by incrementally adding more documents to the unlabeled corpus, one would be able to determine what size of corpus is sufficient.
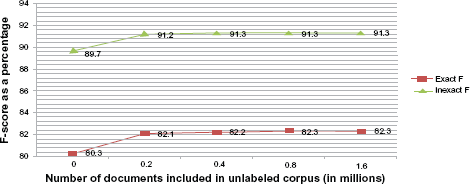
Impact of the size of the unlabeled corpus.
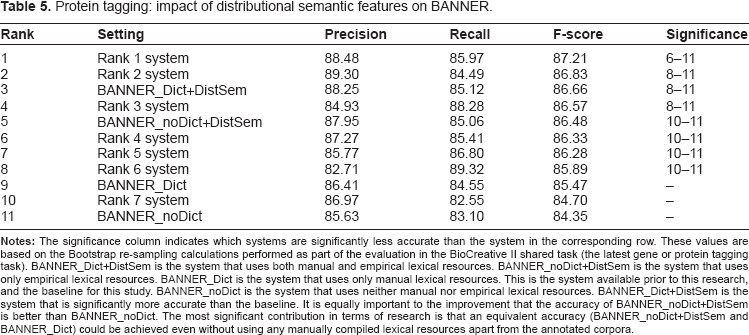
Impact on extracting protein mentions
In Table 5, the performance of BANNER with distributional semantic features (row 3) and without distributional semantic features (row 9) is compared with the top ranking systems in the most recent gene-mention task of the BioCreative shared tasks. Each system has an F-score that has a statistically significant comparison (
Protein tagging: impact of distributional semantic features on BANNER.
Discussion
The evaluations for clinical NER reveal that the distributional semantic features are better than manually constructed lexicon features. Some examples of the differences in the output are shown in Table 6. The accuracy further increases when both manually created dictionaries and distributional semantic feature types are used, but the increase is not very significant (
Example outputs of the additional true positives found in the clinical NER system that uses distributional semantic features over the one that does not.

The improvement in F-scores after adding manually compiled dictionaries (without distributional semantic features) is only around 1%. However, many NER tools, both in the genomic domain21,34 and in the clinical domain35,36 use dictionaries. This is partly because systems trained using supervised machine-learning algorithms are often sensitive to the distribution of data, and a model trained on one corpus may perform poorly on those trained from another. For example, Wagholikar 37 recently showed that a machine-learning model for NER trained on the i2b2/VA corpus achieved a significantly lower F-score when tested on the Mayo Clinic corpus. Other researchers recently reported this phenomenon for part of speech tagging in clinical domain. 38 A similar observation was made for the protein-named entity extraction using the GENIA, GENETAG, and AIMED corpora,39,40 as well as for protein-protein interaction extraction using the GENIA and AIMED corpora.41,42 The domain knowledge gathered through these semantic features might make the system less sensitive. This work showed that empirically gained semantics are at least as useful for NER as the manually compiled dictionaries. It would be interesting to see if such a drastic decline in performance across different corpora could be countered using distributional semantic features.
Currently, very little difference is observed between using distributional semantic features derived from Medline and unlabeled clinical notes for the task of clinical NER. Future research would study the impact of using clinical notes related to a specific specialty of medicine. We hypothesize that the distributional semantic features from clinical notes of a subspecialty might be more useful than the corresponding literature. Our current results lack qualitative evaluation. As we repeat the experiments in a subspecialty such as cardiology, we would be able to involve the domain experts in the qualitative analysis of the distributional semantic features and their role in the NER.
Conclusion
Our evaluations using clinical notes and biomedical literature validate that distributional semantic features are useful to obtain domain information automatically, irrespective of the domain, and can reduce the need to create, compile, and clean dictionaries, thereby facilitating the efficient adaptation of NER systems to new application domains. We showed this through analyzing results for NER of four different classes (genes, medical problems, tests, and treatments) of concepts in two domains (biomedical literature and clinical notes). Though the combination of manually constructed lexicon features and distributional semantic features provides a slightly better performance, suggesting that a manually constructed lexicon should be used if available, the de-novo creation of a lexicon for purpose of NER is not needed.
The distributional semantics model for Medline and the quasi-thesaurus prepared from the i2b2/VA corpus and the clinical NER system's code is available at (http://diego.asu.edu/downloads/AZCCE/) and the updates to the BANNER system are incorporated at http://banner.sourceforge.net/.
Funding
This work was possible because of funding from possible sources: NLM HHSN276201000031C (PI: Gonzalez), NCRR 3UL1RR024148, NCRR 1RC1RR028254, NSF 0964613 and the Brown Foundation (PI: Bernstam), NSF ABI:0845523, NLM R01LM009959A1 (PI: Liu) and NLM 1K99LM011389 (PI: Jonnalagadda).
Author Contributions
Conceived and designed the experiments: SJ. Analyzed the data: SJ, TC, GG. Wrote the first draft of the manuscript: SJ. Contributed to the writing of the manuscript: SJ, TC, SW, HL, GG. Agree with manuscript results and conclusions: SJ, TC, SW, HL, GG. Jointly developed the structure and arguments for the paper: SJ, GG. Made critical revisions and approved final version: SJ, TC, SW, HL, GG. All authors reviewed and approved of the final manuscript.
Competing Interests
Author(s) disclose no potential conflicts of interest.
Disclosures and Ethics
As a requirement of publication the authors have provided signed confirmation of their compliance with ethical and legal obligations including but not limited to compliance with ICMJE authorship and competing interests guidelines, that the article is neither under consideration for publication nor published elsewhere, of their compliance with legal and ethical guidelines concerning human and animal research participants (if applicable), and that permission has been obtained for reproduction of any copyrighted material. This article was subject to blind, independent, expert peer review. The reviewers reported no competing interests. The submission is intended for the special issue of Biomedical Informatics Insights–-on Computational Semantics in Clinical Text. It is a revised and extended version of the long paper accepted at the Computational Semantics in Clinical Text workshop (editors: Wu and Shah).
Footnotes
Acknowledgements
We thank the developers of BANNER (http://banner.sourceforge.net/), MALLET (http://mallet.cs.umass.edu/) and Semantic Vectors (![]() ) for the software packages and the organizers of the i2b2/VA 2010 NLP challenge for sharing the corpus.
) for the software packages and the organizers of the i2b2/VA 2010 NLP challenge for sharing the corpus.