
Abstract
Background
Cytoplasmic polyadenylation element binding proteins (Cpebs) are a family of proteins that bind to defined groups of mRNAs and regulate their translation. While Cpebs were originally identified as important features of oocyte maturation, recent interest is due to their prospective roles in neural system plasticity.
Results
In this study we made use of bioinformatic tools and methods including NCBI Blast, UCSC Blat, and Invitrogen Vector NTI to comprehensively analyze all known isoforms of four mouse
Conclusions
Together, the large number of transcripts and proteins indicate the presence of a hitherto unappreciated complexity in the regulation and functions of Cpebs. The evolutionary retention of variable regions as described here is most likely an indication of their functional significance.
Introduction
Cytoplasmic polyadenylation element binding proteins are a family of mRNA binding proteins that play essential regulatory roles in the translation of defined mRNAs. First discovered during oocyte maturation,
1
the role of Cpeb-mediated control of translation has now been expanded to include a wider variety of scenarios including cell cycling2,3 and synaptic plasticity.
4
The identification of
Four
Previous biological findings suggested that
Results and Discussion
Cpeb1 protein isoforms with internal deletions of 1 or 5-amino acid (aa), or with an N-terminal truncation of 75-aa
A total of nine cDNA sequences for mouse

Analysis of
Two Cpeb1 protein sequences were extracted from the UniProt protein database and aligned using Vector NTI software (Fig. 1C). Meanwhile, we computationally translated all non-redundant full-length
The 15-nt (5-aa) is located within the first RRM (Fig. 1C). Further analysis identified that the 5-aa is adjacent to the octamer consensus of the first RRM (Fig. 5, green box). The insertion or deletion of the 5-aa may have a pivotal impact on the specificity of Cpeb1, because the sequences surrounding the consensus of RRMs are important for the specificity of RNA binding.14,15 To what extent this 5-aa impacts RNA binding is yet to be established.
Two alternative splicing isoforms containing a 75-aa N-terminal truncation were evident in human CPEB1 (Fig. 1D). With the knowledge that there is a near-identical conservation between human CPEB1 and mouse Cpeb1 (Fig. 6B–D), the question arises: Does the 75-aa truncation in human have a counterpart in mouse? Based on our theoretical translation with Vector NTI, we postulated that the 75-aa truncation in mouse could be derived from the removal of exon 2, which leads to a frame shift and an alternative translational initiation site (Fig. 1A). Therefore, we designed primers spanning this alternative region in mouse. A primer pair at exon 1/3 junction and within exon 3 confirmed the presence of a
Cpeb2 protein isoforms with internal deletions of 30-aa or 8-aa
We extracted eight cDNA sequences for

Analysis of
One mouse Cpeb2 protein sequence was documented in the UniProt database (Q812E0). An additional isoform which was recently updated in the NCBI protein database (but not in the UniProt database) was added to the top (Fig. 2C, NP_787951.2). Both sequences contain an 8-aa deletion resulting from the removal of exon 7 (Fig. 2A). When we translated non-redundant full-length
Both mouse and human Cpeb2 sequences have been updated in the NCBI database during the preparation of this manuscript. Of particular interest, the updated sequences demonstrate the presence of an extra-long isoform of Cpeb2—almost double the previously published size (Fig. 2C, 2D, top isoforms). Our sequence alignment demonstrated that both the previous and the updated mouse isoforms are legitimate—the use of an extended exon1 leads to the much longer N terminus in the newly uncovered isoform (Fig. 2A, insert). This may be of relevance to prior investigations of CPEB3, in which antibodies recognized the predicted protein at ~78 kD in western blots, but also detected an additional protein band above 100 kD6,8 (see below).
Cpeb3 protein isoforms with internal deletions of 23-aa or 8-aa, an N-terminal truncation of 216-aa, or a C-terminal truncation of 132-aa with an altered C terminus
Eight full-length cDNA sequences of mouse

Analysis of
Six protein sequences of mouse Cpeb3 were extracted from the UniProt and the NCBI protein databases. Sequence comparisons demonstrated four variable regions (Fig. 3C). The alternative usage of a 23-aa region and an 8-aa region is attributable to the alternative splicing in exon 5 and exon 7, respectively. A 216-aa N-terminal truncation may result from the use of an alternative translation initiation codon when intra-exon skipping occurs to exon 4. A 132-aa C-terminal truncation which removes the majority of the second RRM2, and terminates with four distinct amino acids (Fig. 3C, Q7TN99-5) can be derived from the extension of exon 11 (Fig. 3A).
The sequences and locations of the 23-aa and the 8-aa regions are conserved in human CPEB3 and mouse Cpeb3 (Fig. 3C, 3D). One human isoform has a deletion of 17-aa, which includes the 8-aa and the adjacent 9-aa C-terminal to it (Fig. 3D, Q8NE35-1). To further explore the validity of the 17-aa deletion, we compared additional organisms. A particular exon (supplementary Table 6, column denoted by the pound sign) shows two variants (141-nt or 168-nt) among the species investigated. We postulated that the presence of the 141-nt was due to a 27-nt skipping within the 168-nt exon. Sequence alignment indicated that this 168-nt is exon 8 in mouse
One human CPEB3 isoform (BAG54433.1) has a 317-aa N-terminal truncation (Fig. 3D). The strong homology between mouse and human prompted us to question the validities of the 317-aa truncation in the human and the 216-aa truncation in the mouse (Fig. 3C). The 216-aa truncation in mouse Cpeb3 is derived from an intra-exon skipping of exon 4 (Fig. 3A). The corresponding cDNA (AK127060.1) for human CPEB3 isoform with 317-aa truncation has a very short 5′ UTR. Computational translation indicated that the truncation of 317-aa could be due to an incomplete 5′ sequence of the cDNA. Based on the stringent conservation between mouse and human, particularly in the alternatively spliced regions (Fig. 6 C–D), it is possible that this human CPEB3 protein isoform has an N terminal truncation of 216-aa instead of 317-aa. Techniques such as 5′ rapid amplification of cDNA ends (5′ RACE) may be used in future studies to obtain the complete 5′ sequence of this transcript as a means to confirm the length of N-terminal truncation in human CPEB3.
More drastic changes appear in the Cpeb3 isoform with a 132-aa C-terminal truncation and an altered tail (VELA→GEWK) (Fig. 3C, and yellow box in Fig. 5). This isoform lacks the majority of the second RRM, including its octamer consensus. This is likely to have a significant impact on RNA-protein interaction and specificity. The DNA or RNA binding proteins thus far identified have one to four RRMs. 16 NMR characterization of the structures of several proteins revealed different binding mechanisms for even- and odd-numbered RRMs. For example, heterogeneous nuclear ribonucleoprotein A1 (Hnrnpa1) and polypyrimidine tract binding protein (Ptbb), which contain two and four RRMs, respectively, form homodimers when binding to two molecules of mRNA in anti-parallel arrangement.17,18 In contrast, poly (A) binding protein 2 (Pabp2) which has a single RRM, forms homodimers in the absence of RNA, but becomes monomeric upon mRNA binding. 19 Thus the Cpeb3 isoform with a 132-aa C-terminal truncation and an altered tail would likely have its binding characteristics altered.
The largest predicted size for mouse Cpeb3 is approximately 78 kD, but a protein greater than 100 kD has also been detected with antibodies in western blots.6,8 This larger protein has been proposed to be a pre-protein.
6
Since Cpeb2 and Cpeb3 are closely- related in the Cpeb family (Fig. 6A), the recent finding of the extra-long Cpeb2 (Fig. 2A, C, D, the top isoforms) makes it plausible to postulate the presence of a similar extra-long isoform for Cpeb3. Both human and chimpanzee have a beginning exon of 193-nt (supplementary Table 6, the double pound signs) which, if mapped to mouse genome, would be adjacent to the 61-nt exon. In addition, one isoform of mouse
Cpeb4 protein isoforms with internal deletions of 17-aa or 8-aa, or an N-terminal truncation of 382-aa
Sixteen cDNA sequences representing mouse

Analysis of
Four isoforms of mouse Cpeb4 proteins were extracted from the UniProt database. The alignment of the protein isoforms reflects the deletions of 17-aa and 8-aa motifs (Fig. 4C), which correspond to the removal of exon 3 and exon 4, respectively (Fig. 4A). Computational translation of cDNA BC079599.1 yielded a novel protein with a 382-aa N-terminal truncation (Fig. 4C). The deletion of 382-aa, like the deletions of the 17-aa, and 8-aa, was identified in human CPEB4 at the same locations (Fig. 4D). These sequences of the alternatively spliced regions were also strictly conserved in mouse and human (Fig. 6D).
Across-paralog comparison of mouse Cpeb1, 2, 3 and 4
The overall sequence of
Cpeb2 motifs spanning the 30-aa and 8-aa predicted with the aid of ELM. The motifs in red are missing in the isoform with 8-aa deletion; the ones in dark blue are missing in the isoform with 30-aa deletion; the ones in both colors are missing in the isoform with 30-aa and 8-aa deletions. The motifs in green are located in the linker region. The motif in light blue is missing in the newly identified 9-aa deletion.

Note: The numeric positions in column 3 are based on the following sequence investigated: NNSNTLLPLQ
The motifs in Cpeb3 spanning the 23-aa and 8-aa regions predicted with the aid of ELM. The motifs in red are missing in the 8-aa deletion isoform; the ones in dark blue are missing in the 23-aa deletion isoform; the ones in both colors are missing in the isoform with 23-aa and 8-aa deletions. The motif in pink appears only in the isoforms with 23-aa deletion, or 23-aa and 8-aa deletion. The motifs in green are located in the linker region. The motif in light blue is missing in the newly identified 9-aa deletion.
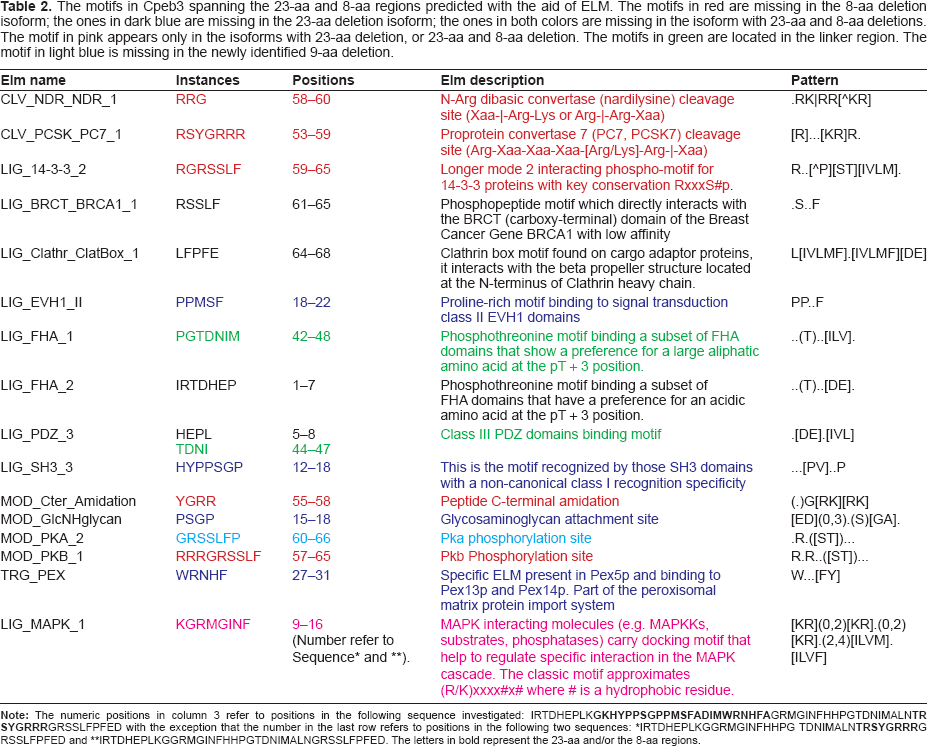
IRTDHEPLKGGRMGINFHHPG TDNIMALN
IRTDHEPLKGGRMGINFHHPGTDNIMALNGRSSLFPFED. The letters in bold represent the 23-aa and/or the 8-aa regions.
Cpeb4 motifs spanning the 17-aa and 8-aa regions predicted with the aid of ELM. The motifs in red are missing in the 8-aa deletion isoform; the ones in dark blue are missing in the 17-aa deletion isoform; motifs in both colors are missing in the isoform with 17-aa and 8-aa deletions.

Note: The numeric positions in column 3 are based on the following sequence investigated: IMRAENDSIK

Comparison of the conserved regions in mouse Cpeb1–4 protein. The alternatively spliced 17~30-aa regions are highlighted in blue, the alternatively spliced 8-aa in red, and the alternatively spliced 9-aa in orange. The parentheses indicate that all Cpeb2 isoforms recorded in the UniProt database have the 8-aa deleted. Cpeb2, 3, and 4 share high homology in the 8-aa and the 9-aa regions, but little homology in the 17~30-aa region. The underlined sequences represent the first and second RRMs, respectively, in all four CPEBs. The regions in grey are hexamer and octamer consensus sequences within the RRMs. The hexamer and octamer consensus sequences within the RRMs and the linker between two RRMs are identical in Cpeb2–4, suggesting that it is highly likely that Cpeb2–4 share the same protein/RNA interaction mechanisms. The sequences surrounding the consensuses, N terminal to the first RRM, and C terminal to the second RRM are similar among Cpeb2–4, with a few amino acid replacements. This suggests that Cpeb2–4 recognizes similar substrates. In contrast, Cpeb1 demonstrates significant differences to Cpeb2–4 within these regions, including the consensus sequences, suggesting that Cpeb1 not only employs a distinct mechanism for protein/RNA interaction, but also targets a different group of RNAs. The insertion of the 5-aa in Cpeb1 (highlighted in green) is adjacent to the octamer consensus in the first RRM, possibly posing a potential impact on its specificity. An early termination with an altered tail which alters VELA (highlighted in yellow) to GEWK disrupts the second RRM in a Cpeb3 isoform. This may pose an impact on both the binding mechanism and the substrate specificity of Cpeb3. Accession numbers used for the alignment are as follows: Cpeb1: NP_031781, Cpeb2: NP_787951; Cpeb3: NP_938042; Cpeb4: NP_080528. Alignment was achieved with the aid of ClustalW2. Asterisks represent perfect matches; colons represent substitutions with similar amino acids; periods represent substitutions with rather distinct amino acids.

Comparisons between (MOUSE) Cpebs and (HUMAN) CPEBs.
Another common feature of Cpeb2–4 is the alternatively splicing of the 17~30-aa N-terminal to the 8-aa motif. In contrast to the 8-aa and 9-aa sequences which are highly conserved among Cpeb2–4, the 17~30-aa sequences show little evidence of homology among the three paralogs (Fig. 5, the blue boxes). Functional predictions demonstrated that the deletion of this region removes motifs implicated in protein-protein interactions, phosphorylation, and post- translational modifications (Table 1–3). Noteworthy among these findings is the deletion of the 23-aa motif in Cpeb3: this not only removes certain functional motifs, but also creates a novel site for Mapk interaction (Table 2).
This 17~30-aa variable regions become shorter and closer to the 8-aa motif in the order of Cpeb2→Cpeb3→Cpeb4, until the gap closes in Cpeb4 (Fig. 5). Functional predictions revealed that the linker regions may harbor class III PDZ (postsynaptic density-95, discs-large, zonula occludens-1) domain binding motifs. The numbers of such motifs vary: there are 3 in CPEB2 (Table 1), 1 in Cpeb3 (Table 3), and none in Cpeb4 (Table 5). The sequences of class III PDZ domain binding motifs are also different. Such motifs may recruit different Cpeb paralogs to different protein partners, thereby leading to distinctive localizations and functions.
Together, the aforementioned variations enclosing the 8-aa, 9-aa, and 17~30-aa region would likely determine protein-protein interaction, phosphorylation, and post-translational modifications of Cpebs. The functional significance of this region is of great interest for future studies.
Three paralogs, Cpeb1, 3 and 4, have isoforms with large N-terminal truncations. Such truncations may have a major impact on the function of the proteins. For instance, the Cpeb4 isoform with a large N terminal truncation may be deprived of many, if not all, of the phosphorylation sites (Fig. 4C). This would likely make it a putative candidate for a dominant negative form. Our analysis using the bioinformatics tool Eukaryotic Linear Motif resource (ELM, http://elm.eu.org) indicated that the N-terminal fragments may also harbor featured sites such as those required for post-translational modification and protein-protein interaction (data not shown). The presence or absence of such sites may alter signaling pathways, stimulus-dependence, or the development of particular protein complexes.
The C termini of RNA binding proteins determine the affinity and specificity of RNA binding. Two highly conserved short consensus motifs, a hexamer and an octamer, are separated by about 30-aa and embedded in a structurally conserved, but not sequence conserved RRM region of approximately 90-aa16,20 (Fig. 5). These two short consensuses are deemed hallmarks of RNA binding proteins. The linker sequences between two RRMs are also highly conserved among RNA binding proteins. The hexamer and octamer consensuses and the linker regions are essential for protein-RNA interaction. However, the specificity of RNA binding is determined by sequences surrounding the hexamer and octamer, as well as sequences N terminal to the first RRM and C terminal to the second RRM.14,15 Based on the near-identical homology of these important functional regions in Cpeb2, 3, and 4 (Fig. 5), we predict that Cpeb2, 3, and 4 recognize similar targets. However, Cpeb1, whose sequence deviates significantly from that of Cpeb2–4 even with regard to the short consensus, must recognize a different set of targets and employ a distinct mechanism for RNA interaction. Indeed certain RNA oligonucleotides interact with Cpeb3 and Cpeb4, but not Cpeb1 protein, and the reverse is also true. 8
Across-ortholog comparisons provide new insights
Comparisons across species can be instructive. In this study we found that the exon structures of
One may also exploit such logic to predict functional motifs in one species according to the other. A good example is the prediction of phosphorylation sites (PhophoSitePlus). A few amino acids have been confirmed as phosphorylation sites in mouse or human (Figs. 1–4C, D, the solid triangles) by various techniques including nuclear magnetic resonance (NMR) and mass spectrometry (MS).21,25 Based on the stringent homology between mouse and human, the same amino acids at identical or similar locations were identified and predicted to be phosphorylation sites in the other species (Figs. 1–4C, D, the open triangles). 31
Multiple levels of variability indicate extraordinary complexity in the regulation and function of Cpebs
The presence of more than one isoform in each
Conclusions
In conclusion, our study delineated alternative splicing isoforms for mouse
Methods
Animal handling and tissue collection
All animal experimental procedures were performed in compliance with animal care regulations set by the University of Louisville Institutional Animal Care and Use Committee (IACUC) as well as the Association for Research in Vision and Ophthalmology (ARVO) statement for the use of animals in vision research.
C57/BL6 mice (Charles River Laboratories, Davis, CA) were used in this study to confirm the presence and/or absence of some isoforms predicted by
RNA extracton and RT-PCR
Frozen retinas were homogenized using a PowerGen 250 homogenizer (Fisher Scientific, Pittsburgh, PA). Total RNA was extracted using RNeasy mini kits (Qiagen, Valencia, CA) following the manufacturer's instructions. The concentration of RNA was determined using a BioPhotometer (Eppendorf, Westbury, NY), and the quality of RNA was determined by the ratio of 28S/18S on an agarose gel. RNA was frozen in −80 °C for long term storage.
0.2 μg of total RNA was used in a 20 μl RT reaction using AMV reverse transcriptase (Promega, Madison WI). 1 μl of the cDNA was used for subsequent PCR. The gene-specific primers spanning the regions of interest for
Gene Nomenclature
All gene symbols in the manuscript abide by the guidelines recommended by Human Genome Organization (HUGO) Gene Nomenclature Committee (HGNC), and are in accordance with the human HGNC database and the mouse genome databases (MGD). For example,
Data mining, sequence alignment, and theoretical translation
Both mouse curated RefSeq sequences (NM_) and uncurated cDNAs were extracted from the UniGene database (www.ncbi.nlm.nih.gov/unigene) to collect as much information as possible. For all the other species, only RefSeq sequences were extracted for simplicity. The genomic sequences were derived from UCSC genome database (www.genome.ucsc.edu). UCSC Blat (www.genome.ucsc.edu/cgi-bin/hgBlat; Genome: mouse; at default settings) was used to align cDNA sequences to the genome, to deduce the length of exons, and to define the boundaries of exons. The location of each alternative splice was determined by comparing the genomic locations of exon-exon boundaries. NCBI Blast was used to align cDNAs to one another and to remove redundant sequences from further analysis. Whenever possible, partial sequences encompassing alternative regions of the cDNA entries were confirmed in our laboratory using RT-PCR and subsequent sequencing.
Mouse and human protein sequences were extracted from the UniProt database (www.uniprot.org/). The NCBI protein database (www.ncbi.nlm.nih.gov/protein/) was also explored for additional information. Mouse protein sequences were compared to mouse cDNA sequences with the aid of computational translation using Vector NTI software (Analyses module, Translation). Six frames (3 direct, 3 complementary) were used for each translation. The frame that gave the longest continuous read was selected, and the product designated as the protein product. If the translation started with the first codon which is not a methionine, or terminated at the last codon which is not a stop codon, then the cDNA is considered “fragmented” and removed from further analysis. Vector NTI (Align module, AlignX—Align selected molecules) and ClustalW2 (www.ebi.ac.uk/clustalw2/, at default settings) were used to align the alternatively spliced protein isoforms as well as human and mouse protein orthologs.
A phylogenetic tree was generated for Cpeb1–4 from multiple vertebrate species with the aid of Geneious Pro ver 4.8 (www.geneious.com) at the following settings: Tree Alignment Options—Cost matrix: Blosum62. Gap open penalty: 12. Gap extension penalty: 3. Alignment type: Global alignment with free end gaps. Tree Builder Options—Genetic distance model: Jukes-Cantor. Tree build method: Neighbor-joining. Outgroup: No Outgroup. The accession numbers of protein sequences used to generate the phylogenetic tree were listed in supplementary Table 10.
Functional prediction of alternatively used motifs
No 3D structural information is readily available except for the RRM structure for human CPEB3 (NCBI Cn3D database). Whereas the deletions may lead to critical changes in the secondary/tertiary structures of the proteins, we could only predict the possible functional motifs based on consideration of the linear sequences at this stage. Potential functional motifs were identified with the aid of Eukaryotic Linear Motif resource (ELM, http://elm.eu.org). Since the lengths of the functional motifs used by the ELM algorithm are within 10-aa, to keep the integrity of potential motifs, we included 10-aa N-terminal and 10-aa C-terminal to the regions encompassing the short deletions. Additional predicted and experimentally confirmed phosphorylation sites were from PhosphoSitePlus (www.phosphosite.org).
Footnotes
Abbreviations
Supplementary Materials
Protein sequences used to generate the phylogenetic tree. For simplicity, only the longest RefSeq sequences were used for each species. As in the tree, C1–C4 represents Cpeb1–Cpeb4.

| C1 | C2 | C3 | C4 | ||||
|---|---|---|---|---|---|---|---|
| chicken | XP_413713.2 | cow | XP_001787349.2 | chimpanzee | XP_001145135.1 | chimpanzee | XP_001155432.1 |
| chimpanzee | XP_001158685.1 | horse | XP_001498950.2 | cow | XP_880185.2 | human | NP_085130.2 |
| cow | XP_869784.3 | human | NP_872291.1 | frog | NP_001015925.1 | marmoset | XP_002744608.1 |
| frog | NP_001017330.1 | mouse | NP_787951.1 | horse | XP_001917452.1 | mouse | NP_080528.2 |
| horse | XP_001498303.2 | rat | NP_001101831.1 | human | NP_055727.3 | rat | NP_001100462.1 |
| human | NP_085097.3 | zebrafish | NP_001170928.1 | mouse | NP_938042.2 | zebrafish | NP_957275.1 |
| marmoset | XP_002749216.1 | rat | XP_220043.5 | ||||
| mouse | NP_031781.1 | zebrafish | NP_001161134.1 | ||||
| orangutan | NP_001126432.1 | ||||||
| pig | NP_001090979.1 | ||||||
| rat | NP_001099746.1 | ||||||
| zebrafish | NP_571502.1 |
Acknowledgments
We thank Dr. Ben Harrison and Dr. Eric Rouchka for helpful discussions. This study was supported by NEI R01EY017594, NCRR P20 RR16481 and NIEHS P30ES014443.
This manuscript has been read and approved by all authors. This paper is unique and is not under consideration by any other publication and has not been published elsewhere. The authors and peer reviewers of this paper report no conflicts of interest. The authors confirm that they have permission to reproduce any copyrighted material.