
Abstract
Whole genome microarray investigations (e.g. differential expression, differential methylation, ChlP-Chip) provide opportunities to test millions of features in a genome. Traditional multiple comparison procedures such as familywise error rate (FWER) controlling procedures are too conservative. Although false discovery rate (FDR) procedures have been suggested as having greater power, the control itself is not exact and depends on the proportion of true null hypotheses. Because this proportion is unknown, it has to be accurately (small bias, small variance) estimated, preferably using a simple calculation that can be made accessible to the general scientific community. We propose an easy-to-implement method and make the R code available, for estimating the proportion of true null hypotheses. This estimate has relatively small bias and small variance as demonstrated by (simulated and real data) comparing it with four existing procedures. Although presented here in the context of microarrays, this estimate is applicable for many multiple comparison situations.
Introduction
Genomic technologies are producing vast amounts of biological data that are the basis for investigations that require repetitive testing of the same hypothesis. Because the number of tests performed (e.g. differential expression) is so large, sometimes the multiple comparison procedures that control the familywise error rate are too strict for biological applications (e.g. differential methylation). In fact, many biologists would rather experience several more false positives (i.e. type I errors; false rejections of the null hypothesis) than lose important information. In an attempt to address the multiple comparison issue Benjamini and Hochberg (1995) introduced an error rate measure called False Discovery Rate (FDR). Specifically, a family of m hypothesis tests is considered, of which m0 are true. The proportion of erroneously rejected null hypotheses among all the rejected null hypotheses can be captured by the random variable Q = V/R, where R is the number of rejected hypotheses and V is the number of false rejections (type I errors). Benjamini and Hochberg (1995) formally define the FDR to be the expected proportion of falsely rejected hypotheses among all the rejections,

where Q = 0 when R = 0 (no rejections).
If we let p(1) ≤ p(2) ≤ … ≤ P(m) be the ordered p-values and H(i) be the null hypothesis corresponding to p(i), then in Benjamini and Hochberg's (BH) FDR controlling procedure (Benjamini and Hochberg, 1995), K is considered to be the largest k such that pk ≤ (k/m)α, where α is the pre-chosen FDR significance level. If K exists, all null hypotheses H(i), i = 1, …, K are rejected. If no such K exists, then no hypotheses are rejected. The BH FDR controlling procedure controls the FDR at exactly the level (m0/m)α≤ α, and hence conservatively at a, for independent test statistics and for any configuration of false null hypotheses (Benjamini and Yekutieli, 2001; Storey, et al. 2004). In 2000 Benjamini and Hochberg proposed an adaptive procedure which provides more power than the original FDR controlling procedure by comparing each p(k) with
We propose a simple and easy-to-implement method for estimating the proportion of true null hypotheses. The performance of this estimate is compared to existing methods via simulated and real data. Specifically, Benjamini and Hochberg (2000) estimated the number of true hypotheses from the observed p-values using the Lowest SLope (LSL) estimator. Their approach was based on a modification of the graphical method of Schweder and Spjotvoll (1982). Alternatively, Storey (2002) proposed an estimate of π0 by assuming the p-values corresponding to true null hypotheses are uniformly distributed on the interval (0,1) and selecting a reasonable tuning parameter 0 ≤ λ < 1. Finally, Langaas, et al. (2005) derived estimators based on nonparametric maximum likelihood estimation of the p-value density, under the restriction of decreasing and convex decreasing densities. Although Benjamini and Hochberg's original and adaptive FDR controlling procedure are developed for independent statistics these procedures can also be applied to some dependence structures (Benjamini and Yekutieli, 2001). Simulations have also demonstrated that they can be used for situations where there is a weak correlation structure among the genes (Storey et al. 2004). However, because of the small number of biological replicates used in most microarray experiments, it is very difficult to measure the correlation structure among a set or family of genes. Reiner et al. (2003) proposed a procedure for the general case, but it is conservative when compared to the adaptive FDR controlling procedures.
Methods
Storey's Approach
Our approach is motivated by the work of Storey (2002), where the proportion of true null hypotheses, % is estimated by

where
Instead of choosing one specific λ, Storey and Tibshirani (2003) proposed an estimate of π0 using
Average Estimate Approach
As mentioned previously, the estimate

where

The bias of
Define 0 = t1 < t2 < … < tB < tB+1 = 1 as equally spaced points in the interval [0,1] such that the interval [0,1] is divided into B small intervals with equal length 1/B. Specifically, ti = (i–1)/B. For example, when B = 10, t1 = 0, t2 = 0.1, …, t10 = 0.9. For each ti (i = 1,…,B),



where i = 1,…,B.
If the NBi p-values come from the null distribution, then on average there are


where

where
A remaining challenge is how to choose B. Specifically, how many λ's should be used in the interval [0,1]. Recall that a motivating factor of the proposed average estimate approach is to balance the bias and variance. The natural way to measure both the bias and variance is the mean-squared error, For each B ∊ I, I = {5, 10, 20, 50,100}, compute Form N bootstrap samples of the p-values, and compute the bootstrap estimates For each B ∊ I, estimate its respective mean-squared error as
Where
Let

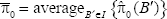
Notice that in step three the value of π0 is estimated by the average of the
Results
Simulation Studies
To investigate the performance of the proposed average estimate approach, a simulation study was performed. Taking m = 1,000 (i.e. 1,000 genes are tested for differential expression), let π0 vary over a wide range, say π0 = 0.50,0.60,…,0.90 which are reasonable for microarray experiments. Hypotheses, H0: μ = 0 versus Ha. μ > 0, are tested for independent random variables Zi(i = 1,…,m) from null distribution N(0,1) and alternative distribution N(2,1). Specifically, mπ0 and m(1 –π0) random variables have mean 0 and 2, respectively. For each test, the p-value is computed as pi = P(Z > zi), where Z is a random variable from a standard normal distribution N(0,1) and zi is the observed value of Zi. For each value of π0, l = 1,000 data sets were simulated.
For the choice of B, B is either fixed (i.e. B = 5, 10, 20, 50, and 100) or chosen by the proposed bootstrap approach. For each of the l = 1,000 simulated data sets, when B is fixed, the estimate of π0 is computed via Equation (8), that is,
For completion the performance of the proposed average estimate approach is compared with several existing procedures:
Benjamini and Hochberg's lowest slope estimate (LSL) (Benjamini and Hochberg, 2000), Storey's bootstrap estimate (Storeyboot) (Storey et al. 2004), Storey and Tibshirani's smoother estimate (STsmoother) (Storey and Tibshirani, 2003), Langass et al.'s nonparametric maximum likelihood estimate (convest) (Langaas et al. 2005).
For procedures 2 and 3, the QVALUE software (http://www.faculty.washington.edu/~jstorey/) was employed. For procedure 4, the R function ‘con-vest’ was downloaded from the R library ‘limma’ as part of the Bioconductor project (http://www.bioconductor.org).
Table 1 summarizes the simulation results. Bias and the standard deviation of the estimates are estimated by

The estimate of the proportion of true null hypotheses is compared for: Benjamini and Hochberg's lowest slope approach (LSL), Storey's

where
The average of the true false discovery rate (FDR) from 1000 simulations is also compared in this simulation study by applying Benjamini and Hochberg's adaptive FDR controlling procedure (Benjamini and Hochberg, 2000) with π0 estimated using the above mentioned five methods (Fig. 1). The FDR significance level was chosen as α = 0.05. For the purpose of comparison, the original BH FDR controlling procedure (Benjamini and Hochberg, 1995) and the adaptive FDR controlling procedure with the incorporation of the true value of π0 were also applied to the p-values. It can be seen that the original BH FDR controlling procedure has the lowest FDR as expected. Because Benjamini and Hochberg's lowest slope approach overestimates π0, the FDR is below, but much lower than, the pre-chosen α, although this approach has a bigger FDR than that of the BH procedure. Storey's bootstrap estimate, the smoother estimate and convest estimate produce higher FDRs than the pre-chosen level because all three methods underestimate π0. Our proposed average estimate approach overestimates π0, its FDR is below but very close to the pre-chosen significance level α = 0.05. Table 1 also demonstrates that the FDR for the proposed average estimate has the relatively small variation.

Simulation results of the False Discovery Rate (FDR) at significance level α = 0.05 for seven procedures: Benjamini and Hochberg's FDR controlling procedure with incorporation of the true π0 (BHπ0), Benjamini and Hochberg's FDR controlling procedure (BH), Benjamini and Hochberg's adaptive approach with incorporation of the estimate of π0 which is estimated by the proposed average estimate procedure where B is chosen via bootstrapping (Bboot), Benjamini and Hochberg's lowest slope approach (LSL), Storey's bootstrapping approach (Storeyboot), Storey and Tibshirani's smoother method (STsmoother), and Langass et al.'s nonparametric maximum likelihood estimate (convest), respectively. The black straight line represents FDR = 0.05. The total number of hypotheses tests is m = 1, 000 and the size of simulation study 1,000 for each value of π0.
The power of the five adaptive FDR controlling procedures is compared (Fig. 2). The power of a procedure is measured by average power which is defined to be the ratio of average number of correct rejections of true alternative hypotheses to the total number of true alternative hypotheses. Formally, average power = E(S)/(m – m0). As illustrated, the power decreases when π0 increases for all of the FDR controlling procedures. The original BH procedure has the lowest power, while Benjamini and Hochberg's adaptive procedure has the second lowest power. It is not surprising that Storeyboot procedure has the largest statistical power, because the FDR of this procedure exceeds the pre-chosen FDR significance level (Fig. 1).

Simulation results for the evaluation of statistical power at significance level α = 0.05 for seven procedures: Benjamini and Hochberg's FDR controlling procedure with incorporation of the true π0 (BHπ0), Benjamini and Hochberg's FDR controlling procedure (BH), Benjamini and Hochberg's adaptive approach with incorporation of the estimate of π0 which is estimated by the proposed average estimate procedure where B is chosen via bootstrapping (Bboot), Benjamini and Hochberg's lowest slope approach (LSL), Storey's bootstrapping approach (Storeyboot), Storey and Tibshirani's smoother method (STsmoother) and Langass et al.'s nonparametric maximum likelihood estimate (convest), respectively. The total number of hypotheses tests is m = 1, 000, and the size of simulation study is 1,000 for each value of π0.
Microarray Data Application
The same five estimating π0 methods were also applied to the training samples of the leukemia data of Golub et al. (1999), which consist of 27 patients with acute lymphoblastic leukemia (ALL) and 11 patients with acute myeloid leukemia (AML). The samples were assayed using Affymetrix Hgu6800 chips and the gene expression data of 7129 genes (Affymetrix probes) are available from R library golubEsets. For each gene, a simple two-sample t-test was employed for testing differential gene expression and the p-value was computed. Table 2 gives the estimate of the proportion of true null hypotheses and the number of statistically significant genes.
The estimate of the proportion of true null hypotheses and the number of statistically significant genes for the leukemai data (Golub et al. 1999) at significance level α = 0.05 after applying Benjamni and Hochberg's adaptive FDR controlling procedure with π0 estimated using five methods: Benjamini and Hochberg's lowest slope approach (LSL), Storey's

From this real data analysis, it can be seen that the Benjamni and Hochberg's LSL approach conservatively overestimates π0, hence it leads to lowest power in terms of the number of rejections. Our proposed average approach provides a slightly larger estimate than Storey's bootstrap approach, the smoother estimate and the nonparametric maximum likelihood approach (convest), even though they end up with a similar number of rejections.
Summary
As array technology improves, it is anticipated that the number of features per array will only increase, hence multiple comparisons will continue to be a challenging problem. Specific to microarrays, the false discovery rate (FDR) is preferred to familywise error rate (FWER) because the FDR controlling procedures have more statistical power than the FWER controlling procedures, even at the cost of a few more type I errors (i.e. false positives). Since Benjamini and Hochberg (1995) proposed their FDR controlling procedure, a variety of methods have been proposed to estimate π0 the proportion of true null hypotheses. As seen here, overestimating π0 controls the FDR below the specified rate. When our and others, estimate of π0 is incorporated into the Benjamini and Hochberg's FDR controlling procedure, the adaptive FDR controlling procedure has more power and an FDR close to the pre-chosen level.
In this work, we have compared several methods for estimating the proportion of true null hypotheses (π0). Benjamini Hochberg's lowest slope approach (Benjamini and Hochberg, 2000) overestimates % Storey's estimate
Using the limitations of the existing approaches for estimating π0 as the motivation, we propose the average estimate approach by taking average of the estimates of π0 over a range of equally spaced points on the interval [0,1]. While our average estimate approach has a slightly larger bias, it also has smaller variation than any of the other methods. Furthermore, when compared to the other methods it is easy to implement (e.g. Excel) when the number of points used in approach is fixed (say, B = 10), and can be automated to choose B via a bootstrap procedure (R code available: http://www.stat.purdue.edu/~doerge). When our proposed estimated value of π0 is incorporated into Benjamini and Hochberg's adaptive FDR controlling procedure, more statistical power is gained such that the FDR can be controlled below, yet extremely close to a desired level α.