
Abstract
In a distributed environment, replication is the most investigated phenomenon. Replication is a way of storing numerous copies of the same data at different locations. Whenever data is needed, it will be fetched from the nearest accessible copy, avoiding delays and improving system performance. To manage the replica placement strategy in the Cloud, three key challenges must be addressed. The challenges in determining the best time to make replicas were generated, the kind of files to replicate, as well as the best location to store the replicas. This survey conducts a review of 65 articles published on data replication in the cloud. The literature review examines a series of research publications and offers a detailed analysis. The analysis begins by presenting several replication strategies in the reviewing articles. Analysis of each contributor’s performance measures is conducted. Moreover, this survey offers a comprehensive examination of data auditing systems. This work also determines the analytical evaluation of replication handling in the cloud. Furthermore, the evaluation tools used in the papers are examined. Furthermore, the survey describes a lot of research issues & limitations that might help researchers support better future work on pattern mining for data replication in the cloud.
Nomenclature
Nomenclature
(Continued)
Operating systems, storage, networks, hardware, databases, and even complete software applications are supplied to consumers as on-demand services through cloud computing, which is a network-based architecture [45,63]. Cloud computing does not make use of certain latest techniques, but it saves money and improves the scalability of IT services management. SaaS, IaaS, PaaS, & EaaS are the four types of cloud computing. A tremendous quantity of data is currently a significant and critical portion of shared resources across several scientific fields. In several disciplines, the size of data is estimated in terabytes or even petabytes. Cloud data centres [61,67] are often used to store such massive amounts of data. As a result, data replication is commonly used to manage a large amount of data by producing identical copies of data in geographically dispersed locations known as replicas. Data replication [56,74] has the benefit of accelerating data access, lowering access latency, and enhancing data availability. To enhance the response time to consumers, a common method is to deploy numerous replicas spread across geographically distant clouds. The overheads of producing, maintaining, & updating replicas are essential, and the difficult concern in distributed setups is ‘multiple copies of data at several places. Cloud service providers offer a variety of geographically dispersed facilities that users can share in accordance with the Service Level Agreement, and the market for these services is expanding quickly. Using cloud computing, a potent paradigm for addressing the requirements of people and companies, information may be exchanged across the Internet. Distributed cloud-based or peer-to-peer (P2P)-based material on a wide scale can be effectively replaced by the peer-to-peer-cloud (P2P-Cloud).By solving some of this criterion’s major issues, including availability, reliability, security, bandwidth, and reaction time of data access, data replication’s primary goal is to increase performance for data-intensive applications [29,57,58,70].
In the field of distributed & cloud computing, data replication [71] has been widely investigated. If one of the nodes is unavailable, the data can be retrieved through another node. The staging, placement, & transfer of data across a cloud are all part of data replication. Data staging refers to the temporary storage of data for evaluation at a later stage of implementation. Data replication is frequently used by cloud service providers to meet their service level goals for availability and response speed. Cloud computing is a rapidly evolving paradigm that gives users the flexibility and on-demand access to cloud services they need using a pay-as-you-go pricing structure. A well-known method for increasing data availability, lowering bandwidth usage, and achieving fault tolerance is data replication [23,60,68]. If a shared resource is unavailable in a cloud computing [62] system, data is “staged-in” at the execution site. The data is “staged-out” of the storage after it has been “staged-in.” Data placement is the process of placing the data at various locations, and data movement is focused on how (a) data should be transferred to maintain replication levels & (b) data would be accessible from various locations. Traditionally, many strategies are included to improve the cloud performance by dividing the file into multiple blocks & distributing the pieces among data nodes for parallel data transmission. Data management & replication strategies should be built to reach QoS in consideration of preventing performance degradation. Mostly, data replication is used to handle enormous amounts of data in a dispersed manner. Data replication [22] improves data availability, which also increases data access speed & lowers access latency. While considering replication of data operations in cloud storage clusters, there are two major issues to be considered: the right amount of data replicas and the replicas must be placed in the system correctly to complete the task efficiently.
Many replication levels [47] are typical in cloud-based systems that run all over the world, particularly between clusters, servers, inter-data centers, and even cloud systems. Conventional approaches for consistency across an object’s replicas include pessimistic (i.e. lock-based) & optimistic (i.e. non-lock-based). Although the replication process enhances application performance, there is a situation that results in poor overall performance. Updates require various organizations across the network when the data file is read as the load, causing performance reduction. The replication protocol is also utilized, as well as the replication cost has a significant impact on the process of replication [42,70]. Data replication can increase costs & energy consumption despite it has many benefits. Another concept of data replication is the method of enhancing performance, availability, & dependability by maintaining multiple copies of a data file across many sites. It’s frequently used in applications that require a large amount of data to be collected from multiple locations across the world. Whenever one of the sites’ replicas fails, the requested data file could still be supplied from other locations. The purpose of data replication is to fulfill requests from nearby locations to keep the appropriate replicated files. Thus, it is required to implement a data replication [54,55] technique that analyses the balancing of several trade-offs. Optimization has become a popular area in recent years for determining the best answer to complex situations. As a consequence, researchers have concentrated on meta-heuristic algorithms to address replication issues. Many people and businesses are outsourcing their data to remote cloud service providers (CSP) to cut maintenance costs and the workload associated with managing huge data storage systems. Replication of the data is essential for boosting information availability and reliability. Additionally, maintaining numerous copies of the data across many hosts results in higher maintenance costs for the providers, who then pass those costs along to the client in the form of higher prices. However, occasionally they might not preserve that copy on all servers. The clients’ requests for data updates were also not adequately carried out.
The following is a list of the key contributions to this work.
Conduct a comprehensive review of 65 research papers based on pattern mining of data replication in the cloud.
Analyzes various replication methods in reviewing articles. This survey provides a comprehensive analysis of data auditing schemes. Moreover, the analytical review on replication handling in the cloud is performed.
Moreover, evaluation tools used in the papers are also analyzed. Analysis of performance measures of each contribution is also done. Finally, research gaps and challenges in this topic are determined.
The previous literature based on data replication in the cloud is listed in Section 2 of this article. In Section 3, a review of cloud data replication models cloud, performance, & maximum attainments is preferred. Section 4 contains an evaluation of the replication handling schemes in the cloud and a chronological review. Section 5 also includes a review of data auditing schemes and simulation tools. Section 6 also listed the research gaps and challenges. The conclusion of this work is preferred in Section 7.
Literature review
Related work
This study evaluates 65 papers that were published between 2015 and 2021. The papers are chosen from well-known publishers including IEEE, Springer, Elsevier, and others. The papers are arranged as follows:
Replication management approach
In 2016, Mansouri et al. [43] have presented a novel replica placement to provide cost-effective availability, reduce application response time, & load balance cloud storage. The replica placement was determined by five key factors: mean service time, failure probability, load fluctuation, latency, & storage use. Nevertheless, since each site’s storage capacity was restricted, replication should be handled with caution. They use the CloudSim simulator to analyze the method & discover that it outperforms existing algorithms based on mean response time, effective network utilization, load balancing, replication frequency, & storage consumption.
In 2012, Sun et al. [73] have explored a dynamic data replication approach in this study, along with a brief examination of replication strategies appropriate for distributed computing settings. It entails: 1) evaluating as well as modelling the relationship among system availability as well as the number of replicas; 2) analyzing as well as specifying popular data & triggering a replication operation whenever the popularity data reaches a dynamic threshold; 3) determining a suitable number of copies to fulfill a sensible system byte effective rate necessity as well as evenly distributing replicas among data nodes; as well as 4) developing the dynamic data replication method in the cloud. Results demonstrate that the proposed cloud technique increases the accuracy & effectiveness of the enhanced system.
In 2019, Ramanan et al. [65] have investigated the use of these data corruption like effective reliability of data replication using an SDS technique to continually fulfill the QoS constraints. When the proposed technique was compared to cost-effective dynamic data replication, it was observed that the average recovery time was reduced by 18.18% for the 250 amount of requested nodes, 11.11% for the 750 amount of requested nodes, 14.28% for the 500 quantity of suggested nodes, as well as 8.69% for the 1000 amount of requested nodes.
In 2019, Edwin et al. [13] have provided 3 different features on dynamic, cost-aware data replication methods via optimization, that determine the least quantity of data replication information necessary to ensure the data availability growth when the replication process is increased. By combining these optimization objectives, an EIMORM may solve this optimum problem. As a consequence, the simulation findings could be used to promote energy efficiency as data replication recommendations.
In 2021, Mohammad et al. [50] have suggested a CSO-based method for SDR that uses a smart fuzzy inference system with four inputs: centrality, energy, storage usage, as well as load to identify the best data center for a novel replica. In particular, a high-quality knowledge base was created to characterize the CSO method’s fuzzy system. They use the CloudSim toolkit to test the suggested algorithm, as well as the results reveal that the SDR method could decrease total energy usage and reaction time by 31% & 28% (on average) compared to other relevant algorithms.
In 2015, Boru et al. [6] has investigated data replication in cloud computing data centres. This study examines data replication in geographically dispersed cloud computing data centers & provides a new replication strategy that maximizes the system’s energy efficiency in combination with standard performance measures like network bandwidth availability. The findings of the comprehensive simulations aid in revealing performance and energy efficiency trade offs for guiding the development of future data replication systems.
In 2021, Maheshwari et al. [41] has suggested a consensus-based file replication methodology based on the message forwarding framework that tackles the previous methods’ server confidence problem. The Master–Slave protocol employs a two-layered framework that divides servers into masters and slaves. Following the suggested methodology, the updated data file would be provided instantly to the readers without any ambiguity. The protocol was conducted, as well as the experimental and theoretical results were confirmed.
In 2021, Ulabedin et al. [78] have presented a workflow scheduling strategy to resolve data transmission & complete workflow activities under tight deadlines & budgets. The suggested strategies include an initial data placement phase that clusters & distributes datasets depending on their interconnections, as well as an R-PCP methodology that organizes tasks with data locality & continuously manages the dependency matrix for the deployment of created data sets. When comparing random & ADAS approaches, R-PCP has 44.93% & 31.37% less data movement, correspondingly. When compared to the ADAS approach, R-PCP uses 26.48% less energy.
In 2013, Chen et al. [35] have suggested two QADR techniques in the cloud computing environment. The first method utilizes the HQFR concept to conduct data replication. Nevertheless, this greedy approach has been unable to reduce the cost of data replication as well as the count of data copies with QoS violations. Furthermore, a cloud computing system is known to have a huge number of sensor nodes. Furthermore, simulation tests were conducted to show that the suggested methods were successful in data replication & restoration.
In 2019, Toosi et al. [53] have developed the best offline solution based on dynamic & linear programming approaches and also the requirement of accurate workload knowledge on objects. The second online method was randomized, and it used the RHC approach to utilize future workload data for “w” time periods. Experiments employing a workload created based on features of the Facebook workload confirmed the efficacy of the suggested algorithms.
In 2021, Latip et al. [2] has proposed the VRS-BQ replica placement approach in cloud contexts to reduce storage usage, response time, & replication process time. The suggested VRS-BQ algorithm achieves a 25% reduced average response time, 22% lesser replication time, as well as 20% lower storage consumption similar to the previous DPRS algorithm while maintaining the highest level of data availability, according to extensive experiments performed by using well-known CloudSim simulation platform.
In 2021, Mseddi et al. [61] has determined a CRANE cost-effective replication migration strategy for a distributed cloud storage scheme. CRANE enhances any replica placement technique by effectively managing replica generation in geo-distributed infrastructures to (1) reduce the time it takes to copy data to a new replica site, (2) eliminate network congestion, & (3) assure the data’s current minimum availability. They further demonstrate that, when compared to OpenStack Swift, CRANE was able to cut replica generation & migration time to 60% & inter-data center network traffic to 50% while maintaining minimal data availability.
In 2021, Raouf et al. [66] has suggested a CB-MT DBMS that anticipates migration & replication choices by monitoring as well as responding before the SLA violation. In comparison to earlier methodologies, investigational results demonstrate that the proposed MTDB-MR method seems to be the best candidate for migration as well as replication of violated multi-tenant databases because it minimizes the total count of SLA violations, the amount of multi-tenant client SLA violations, client sites average response time, as well as the overall execution time of every multi-tenant client site.
In 2021, Zhang et al. [83] has determined BDS+, a near-optimal network solution for large-scale inter-DC data replication. BDS+ had been a completely centralized application-level multicast overlay network which permitted a central controller to keep track of the data delivery condition of intermediary servers throughout accessible overlay pathways. Furthermore, dynamic bandwidth separation could decrease bulk data transfer execution times by approximately 1.2 to 1.3 times.
In 2021, Awad et al. [5] has suggested two bio-inspired methods to optimize both data replica selection & placement in the clouds. MO-PSO & MO-ACO were offered as algorithms for dynamic data replication. In comparison to other methods, the simulation results show that MOPSO provides better data replication. When compared to other techniques, MOACO has greater data availability, cheaper cost, & reduced bandwidth usage.
In 2020, Amel et al. [30] have presented a unique mixture of the BVS algorithm for scheduling and the CEMR method for dynamic data replication. The goal was to increase data access efficiency while maintaining provider profit to achieve service level objectives based on reaction time SLORT & least availability SLOMA. The numerical simulations show that the suggested scheduling & replication algorithms work much better than existing solutions.
In 2019, Riad et al. [59] has presented a data replication solution within Cloud data centers that fits both the performing tenant goal as well as the provider profit goal. Data replication was performed if only: (i) the expected Response Time of Q outperforms a crucial RT threshold (per-query replication), or (ii) more frequently if RTQ surpasses another (smaller) RT threshold for a specific amount of times before the tenant query Q was executed (replication per set of queries). RSPC outperforms the other 4 techniques in terms of RT under heavy loads, complicated queries, & restrictive RT criteria. Furthermore, penalty & data transmission costs have been drastically decreased, affecting provider profit.
In 2018, Liang et al. [34] has tackled co-residence attacks, in which a malicious attacker might steal or damage a user’s sensitive information by co-residing the attacker’s VM on the same physical server as the target user’s VM. Dynamic data replication rules were investigated and optimized using the proposed evaluation methodology. The effects of different method parameters on dynamic data sustainability & security were demonstrated using numerical results.
In 2018, Mansouri et al. [46] have developed a novel dynamic replication approach known as PDR, that uses file access history to identify the correlation of data files as well as pre-fetches the most popular files. PDR delivers excellent data availability, a good hit ratio, and minimal storage & bandwidth usage, according to comprehensive CloudSim tests. As compared to other techniques, PDR decreases reaction time by an approximate average of 35%.
In 2016, Navneet et al. [19] has investigated a dynamic, cost-aware, optimal data replication technique in this research that determines the smallest number of copies needed to achieve the specified availability. The CloudSim toolbox was used to evaluate the suggested technique. The test findings show that the method was beneficial in lowering replication costs and maximizing data availability.
In 2021, Gregory et al. [33] has developed a cloud system that relies on the TRC approach to increase the likelihood of a real-time activity being completed successfully by reducing system loads & user costs. A probabilistic model for evaluating job completion possibility by a specific deadline, projected work completion duration, & data theft success probability would be included in the solution technique.
In 2020, Behnam et al. [52] have introduced a multi-objective optimized placement method on a meta-heuristic approach as well as the fuzzy system that balances the trade-offs among the six optimization objectives to discover the best places for replicas. Furthermore, comprehensive experiments using CloudSim demonstrate that the suggested replication algorithms improve the most popular replication strategies in terms of hit ratio, amount of replications, load variance, latency, average service time, availability, & energy usage.
In 2019, Gustavo et al. [27] has introduced FT-Aurora, a high-availability IaaS cloud manager which permits access to cloud resources even though the manager fails. By enabling network programmability, FT-Aurora allows for more efficient and flexible resource management. Both the efficiency & reliability of FT-Aurora were tested as well as the conclusions were given.
In 2018, Suji et al. [20] has presented an approach for dynamically adjusting the replica factor for each data item based on the data’s popularity, its present replication factor, as well as the number of active nodes in the cloud services. HDFS was used to accomplish the suggested technique. The test findings demonstrate that the suggested strategy keeps an appropriate number of clones for each data item depending on its popularity while respecting the cloud storage availability limitation.
In 2017, Kuchaki et al. [51] has developed a data replication approach based on data access behavior called the PRS on Cloud system. Depending on the 80/20 principle, DPRS duplicates just a tiny portion of frequently requested data files. Using the CloudSim simulation, they measure efficient network consumption, mean task execution time, hit ratio, the overall amount of replications, & percent of storage filled. Extensive testing has shown that DPRS was successful in the majority of access patterns.
In 2014, Sai et al. [39] has presented a multi-objective offline optimization strategy regarding replica management. MORM, the suggested method, balances the trade-offs among the 5 optimization goals to provide near-optimal alternatives. The MORM outperforms the default HDFS replication management as well as the MOE method in terms of reliability & load balancing for large-scale cloud storage clusters, according to experimental data.
In 2014, Tao et al. [11] has introduced the SSOR technology, a middleware capable of meeting the consistency needs of applications while duplicating cloud-based services. They introduce an MSP, which needs an aware version of the standard fixed sequencer technique, to handle the linked sub-problem of atomic broadcasting. Furthermore, comparing the adopted method to the traditional replication strategy and performing experiments show that the suggested technique offers superior scalability with much more adjustable consistency requirements.
In 2020, Abbes et al. [1] has discussed the issues of replication factor adaptation & presents a unique replication factor modelling strategy that uses prediction models to forecast the correct replication factor. They performed regression analysis to determine the relationship between availability as well as the number of copies. Simulations on the Grid’5000 testbed show the advantages of the concept for meeting the availability criterion by utilizing real fault-tolerant cloud infrastructure.
In 2020, He et al. [26] have developed a unique DPRS that combines file access frequency with a prediction algorithm to anticipate future file access & calculate the optional amount of replicas based on real as well as prospective access periodically. The findings of this research reveal that DPRS may significantly cut the response time of a file request, which also reduces the additional cost of cloud storage.
In 2021, Khelifa et al. [31] have suggested a new scheduling method known as BCVS, as well as a new dynamic data replication approach known as CEMR. According to test findings, the suggested mixture of scheduling & replication methods provides a 30 percent larger monetary profit for the cloud provider than conventional approaches. It also provides for improved performance.
In 2020, Javidi et al. [48] has investigated a novel dynamic replication approach dubbed DMDR, that uses the file access histories to measure the correlation of data files retrieved. They’re especially interested in how extracted information combined with maximum frequent correlated pattern mining optimizes data replication. In comparison to the present technology, numerical simulations using CloudSim show that the DMDR strategy seems to have a significant benefit in average response time, efficient network utilization, & hit ratio.
In 2014, Kumar et al. [32] has designed SWORD, a workload-aware data placement & replication technique to decrease resource use in a scenario. They demonstrate that these strategies result in a considerable decrease in total resource consumption for analytical read-only applications. They illustrate that lowering the amount of distributed transactions increases transaction latencies & total throughput for OLTP workloads.
In 2016, Galen et al. [40] has designed and developed an active machine learning system for temporal updating (or backcasting) of land cover data at 3 NLCD research sites. These findings show that the land cover data included in the NLCD may be efficiently retrieved for replication purposes utilizing only Landsat images. The system was completely automated & adaptable at numerous points in time at the landscape as well as regional sizes.
In 2015, Sreekumar et al. [79] has implemented a dynamic data replication mechanism to improve the efficiency of the software application. They evaluate the popularity degree as well as the replica factor to choose the best file to replicate as well as the appropriate number of replicas. They utilize the round-robin approach to arrange the replicas in the specified systems, but they use the fuzzy logic system for determining the system to position the replicas. They evaluate the approach’s effectiveness to traditional algorithms.
In 2016, Bui et al. [8] has created a system for dynamically replicating data files based on predictive analysis & thoughtful consideration of the HDFS replication disadvantages. After that, the popular files could be copied due to their own access capabilities. As a result, when compared to the default technique, the technique significantly enhances availability and maintains dependability. In addition, while dealing with Big Data, complexity reduction was used to improve the prediction’s efficacy.
Replication selection approach
In 2016, Sookhtsaraei et al. [72] have suggested the LRM, or recommended replication manager, uses two fundamental algorithms that take use of the physical adjacency property of blocks. They evaluated the method against MOE, MORG, & Hadoop in terms of replica count. For replication management, the HDFS structure was employed. A series of simulations was also published to illustrate that LRM might be a good alternative for distributed environments since it requires less energy and resources, optimizes load distribution, and also has higher availability & lower latency.
In 2019, Shen et al. [37] have introduced a PMCR technique for cloud storage with great data durability. PMCR divides the cloud storage service into a primary and backup layer, it categorises data into hot, warm, & cold categories depending on its popularity. In comparison to previous replication systems, extensive performance calculations based on trace parameters as well as actual results from real-world Amazon S3 reveal that PMCR delivers great data durability, the minimal likelihood of data loss, inexpensive storage as well as bandwidth costs.
In 2018, Bilal et al. [3] have suggested DROPS, which addresses performance and security problems jointly. Additionally, the DROPS approach for data security does not rely on existing cryptographic procedures, alleviating the platform of computationally costly methodologies. Researchers also compared the DROPS methodology’s performance to those of eleven other systems. The improved level of security has been seen with a little performance overhead.
In 2018, Mansouri et al. [46] have developed a novel dynamic replication approach known as PDR, that uses file access history to identify the correlation of data files as well as pre-fetches the most popular files. PDR delivers excellent data availability, a good hit ratio, and minimal storage & bandwidth usage, according to comprehensive CloudSim tests. As compared to other techniques, PDR decreases reaction time by an approximate average of 35%.
In 2018, Marwa et al. [56] have been intended to function primarily in a cloud-based Advanced Metering Infrastructure with 3 levels: Smart Meter, Aggregator, and Cloud. While sent from the Aggregator layer to the Cloud layer, the System greatly decreases the amount of the energy consumption data provided through smart meters. The findings suggested a 55% reduction in uncorrelated data, which would be impressive. The particular amount of decrease was demonstrated to be highly dependent on parameters including forecasting tolerance & switching period duration.
Replication placement approach
In 2021, Ulabedin et al. [78] have presented a workflow scheduling strategy to resolve data transmission & complete workflow activities under tight deadlines & budgets. The suggested strategies include an initial data placement phase that clusters & distributes datasets depending on their interconnections, as well as an R-PCP methodology that organizes tasks with data locality & continuously manages the dependency matrix for the deployment of created data sets. When comparing random & ADAS approaches, R-PCP has 44.93% & 31.37% less data movement, correspondingly. When compared to the ADAS approach, R-PCP uses 26.48% less energy.
In 2020, Salem et al. [67] have provided varied costs & shortest path sides in the cloud with relation to replication as well as its location among DCs via MOO, and also the cost distance evaluated using knapsack issues. In the suggested system, the MOABC method may be employed to obtain the maximum efficiency & minimum cost. The extensive experiments show that the suggested MOABC seems to be more effective & efficient than other methods for the optimal replication location.
In 2021, Bowers et al. [7] have proposed LAST-HDFS, a solution that combines LAST with open-source HDFS. The LAST-HDFS platform implements location-aware file deployments & monitors file transactions in the cloud in real-time to prevent possibly unlawful transfers. They deployed the suggested architecture & conducted thorough empirical evaluations in large-scale real-world cloud infrastructure to establish the system’s performance & effectiveness.
In 2020, Peng et al. [38] have investigated new offline community discovery & online community adjustment strategies for scalable & adaptive replica deployment. Depending on typical read/write rates over some time, the offline strategy could determine a replica placement option. Extensive empirical analyses based on real-world data traces indicate the usefulness of the approach in handling huge databases.
In 2021, Fan et al. [15] has presented a reliability-aware & energy-efficient task replica assignment mechanism depending on the operational task replicas at slower rates & allowing numerous task replicas to use similar server resources. To decrease the number of servers necessary, many task replicas could share server resources. The suggested method has efficiently reduced energy usage while maintaining a healthy balance between the number of servers used & job completion time, as demonstrated by test findings.
In 2017, Israel et al. [9] have described a BaRRS method for scheduling scientific application operations in cloud computing settings. BaRRS parallelizes scientific workflows into several sub-workflows to balance system consumption. Four well-known scientific procedures were tested, each with a specific dependence structure & data file size. The findings were encouraging, and they also emphasized the most important elements influencing the implementation of application areas on clouds.
In 2019, Amrith et al. [69] has been described a novel fault-tolerant workflow scheduling method that develops replication heuristics in an unsupervised approach. Compared to the Replicate-All method, the suggested method enhances measures including Resource Wastage & Resource Usage yet retains an acceptable increase in Makespan when compared to the vanilla HEFT.
In 2017, Qiu et al. [64] has created models to calculate the response-time dispersion for networks wherein replica cancellation could be too expensive or impossible to perform, including “quick” technologies like web services or older technologies. Additional testing on MATLAB benchmarks as well as a three-tier web application (MediaWiki) indicates exceptional accuracy, with queries taking seconds to complete. This rigorous quantitative study provided insights into appropriate replication levels below several system circumstances.
In 2012, Mansouri et al. [44] have suggested a DHR algorithm that places replicas at the most suitable sites, i.e. the greatest site with the most access for that replica. The simulation findings with OptorSim, the European Data Grid simulation indicate that the DHR method outperforms the other techniques as well as avoids the construction of unneeded replicas, leading to more efficient storage consumption.
In 2021, Younes et al. [28] has suggested a method for allocating replicas to IoT data in the cloud computing environment depending on the HS algorithm in an attempt to lessen data access costs. The suggested technique chooses the optimum location for data replication within a cloud computing system using the HS algorithm. The suggested strategy beat the other approaches in terms of data access time & latency, as well as energy usage, as per the deployment findings.
In 2017, Wiese et al. [80] has developed a replication technique that permits several fragmentations of the same data table in a distributed database system. They also investigate the effects of data updates (insertions & deletions) on the data distribution if there were more fragmentations (resulting in the circumstance where some replication criteria were unnecessary).
Replication creation approach
In 2021, Javidi et al. [49] have proposed HDRS, a dynamic replication technique. HDRS comprises of replica creation, which could also adaptively increase replicas based on exponential growth or decay rates, replica placement based on the access load & labelling approach, as well as replica replacement associated with future file value. Results demonstrate that when compared to other approaches, HDRS could minimize reaction time & bandwidth utilization. By balancing the load of sites, this strategy prevents unnecessary replications & reduces access latency.
Replication retirement approach
In 2018, Tos et al. [76] has presented PEPRv2, Performance, & Profit Oriented Data Replication Strategy for Cloud Systems. PEPRv2 provides the tenant with both throughput & minimum availability requirements even while considering the cloud provider’s profitability. They constructed a virtual cloud system that handles tenant inquiries using a simulation platform. PEPRv2 was compared against its predecessor, PEPR, as well as another data replication approach, CDRM, that does not include the cost of cloud computing.
In 2021, Mokadem et al. [75] have introduced APER, a dynamic data replication strategy in the cloud that meets both the response time goal as well as the provider’s economic advantage. If a query was predicted to break the SLA, the suggested technique contemplates making a new replica depending on the placement heuristic to continue the execution, ensuring that the response time SLO was met whereas the provider earns a profit. They compared APER’s performance to that of PEPR & CDRM techniques. APER met the provider’s expectations and made a profit by carefully positioning copies to increase data access time while reducing resource usage.
In 2020, Guo et al. [22] have introduced Mirror, a multi-replica method to solve the challenges. They discovered that was susceptible to a storage-saving attack, in which a dishonest provider may save significant storage costs relative to the costs of honestly keeping all the replicas even while passing any issue. They also discovered that Mirror was vulnerable to replacement & forgery attacks, posing additional security dangers for cloud users. Experiments demonstrate that the system performs similarly to Mirror but maintains a high level of security.
Replication decision approach
In 2020, Nannai et al. [63] have developed a unique dynamic data replication technique based on the IWD algorithm to handle replication & cloud storage management concerns. The IWD algorithm, a swarm intelligence-based optimization technique, was utilized to optimize the processes of cloud storage replication & administration. They compared the D2R-IWD algorithm to common optimization approaches like PSO and GA and discovered that the methodology provides superior outcomes in terms of access effectiveness for numerous test scenarios, improving cloud performance.
In 2018, Mansouri et al. [45] was used HRS in replica placement, selection, & replacement processes. HRS was designed to replicate data files on the cloud & comprises three steps. To improve reaction time, the decision to replace was adopted. The results of the experiments show that HRS may greatly improve data-intensive application availability, performance, & load balancing. Furthermore, it performs admirably without adding to overhead costs.
In 2019, Ali et al. [4] have suggested a method named “Secure Provable Data Possession method with Replication support in the Cloud utilizing Tweaks,” which protects the CSP from deceiving the data owner by keeping fewer replicas than the SLAs stipulate but also enables dynamic data operations. For all replicas of the outsourced data blocks, they employ the MHT-based storage mechanism to provide security and integrity. They use experimental analysis to demonstrate the effectiveness of their strategy and show that it outperforms previous solutions.
In 2021, Maheshwari et al. [41] has suggested a consensus-based file replication methodology based on the message forwarding framework that tackles the previous methods’ server confidence problem. The Master–Slave protocol employs a two-layered framework that divides servers into masters and slaves. Following the suggested methodology, the updated data file would be provided instantly to the readers without any ambiguity. The protocol was conducted, as well as the experimental and theoretical results were confirmed.
In 2021, Liu et al. [36] has developed a nonlinear integer programming approach to optimize the availability of data in both sorts of failures and thereby reduce replication costs. As compared to earlier replication systems, numerical simulation findings using trace parameters as well as trials from real-world Amazon S3 revealed that MRR delivers excellent data availability, minimal data loss probability, and inexpensive consistency maintaining & storage costs.
In 2020, Castro et al. [10] has examined various approaches for database fragmentation, allocation, & replication, as well as a Web application termed FRAGMENT, which uses the work methodology chosen during the analysis step. It proposes a fragmentation and replication strategy that may be implemented in a cloud environment and seems to be simple to implement, intending to enhance the effectiveness of database operations. Testing with the TPC-E benchmarks revealed that queries conducted against the distributed database built using FRAGMENT had a faster response time than queries performed against a centralized database.
In 2017, Tziritas et al. [77] have examined the usage of data replication in conjunction with the VM assignment problem, to improve methods that determine both data should indeed be replicated wherever VMs should be transferred to reduce network overhead between standard cloud & mobile cloud platforms. As compared to the extant methods in the literature, experiment results demonstrated that the suggested technique reduces network overhead by up to 53%.
In 2019, Sheng et al. [74] has introduced a file replication approach for assuring RRSD, intending to reduce the number of copies to improve load balancing while maintaining the data dependability. To accomplish this, RRSD employs the methods of many-time replica placement & redundant replica deletion. Comprehensive testing shows that RRSD outperforms other comparable approaches in terms of load balance, data reliability, as well as storage consumption, with a 10% increase in load balance as well as a 60% reduction in storage consumption while fulfilling data reliability requirements.
In 2018, Liang et al. [34] has tackled co-residence attacks, in which a malicious attacker might steal or damage a user’s sensitive information by co-residing the attacker’s VM on the same physical server as the target user’s VM. Dynamic data replication rules were investigated and optimized using the proposed evaluation methodology. The effects of different method parameters on dynamic data sustainability & security were demonstrated using numerical results.
In 2016, Songling et al. [16] have suggested DOSN technologies to preserve data privacy. In DOSN, a user’s published data & replicas were only ever saved in the user’s friendship circle. While complete replication could increase DA, clean DOSNs may not be able to provide long-term DA. This research also suggests data placement options for achieving the required DA & enhancing other aspects of performance. Cadros’ efficiency has been verified by investigations.
In 2019, Moin et al. [25] have suggested a cloud FFTF. To apply the appropriate level of FT, FFTF allows customers to designate their activities as premium, standard, or economy. In terms of FT capacity, resource consumption, as well as utilization with an established FT architecture, the effectiveness of FFTF was studied and the results were through comprehensive simulation tests on simulated and real workloads.
In 2016, Galen et al. [40] has designed and developed an active machine learning system for temporal updating (or backcasting) of land cover data at 3 NLCD research sites. These findings show that the land cover data included in the NLCD may be efficiently retrieved for replication purposes utilizing only Landsat images. The system was completely automated & adaptable at numerous points in time at the landscape as well as regional sizes.
Replication decision approach
In 2016, Nahir et al. [62] has created a distinctive technique that eliminates any scheduling overhead from the task’s critical route by incurring no communication overhead between users and service providers upon work arrival. The strategy involved making several copies of each work and transmitting each copy to a separate server. They propose a heuristic solution to the performance loss that occurs in such situations and demonstrate that it effectively mitigates the negative effects of propagation delays through experiments.
In 2015, Sreekumar et al. [79] has implemented a dynamic data replication mechanism to improve the efficiency of the software application. They evaluate the popularity degree as well as the replica factor to choose the best file to replicate as well as the appropriate number of replicas. They utilize the round-robin approach to arrange the replicas in the specified systems, but they use the fuzzy logic system for determining the system to position the replicas. They evaluate the approach’s effectiveness to traditional algorithms.
Static and dynamic replication
In 2021, Shakarami et al. [70] this study gives a thorough analysis and classification of state-of-the-art data replication schemes among several existing cloud computing solutions in the form of a classical classification to characterize current schemes on the subject and discuss open challenges. The three key categories in the classification that is being offered are data management, data auditing, and data de-duplication systems. A thorough analysis of the replication schemes emphasizes their key characteristics, including the classes they use, the type of scheme, the location of implementation, the evaluation methods, and their strengths and shortcomings. Table 2 shows the reviews on the existing model.
Review of the existing model
Review of the existing model
(Continued)
In 2021, Séguéla et al. [68] have provide the dynamic data replication technique (DE2ARS) in this research changes the number of copies based on the workload and tackles difficulties with energy consumption and cost. It is initiated by a Control Chart and occurs after an initial placement. To properly analyze the suggested technique, we first contrast various parameter options. We contrast DE2ARS with methods found in the literature.
In 2021, Hamrouni et al. [23] offers a thorough examination of the data replication techniques now in use in cloud systems, including both standalone and networked clouds. We also describe critical steps for data correlation-aware techniques. In addition, we look at the characteristics of the main techniques, such as how replication problems are addressed, how providers and consumers are prioritized, how service level agreements are taken into account, how cost and economic factors are taken into account, and how assessment tools are used. Finally, using extensive simulations of several replication algorithms designed for standalone and networked clouds, we present a performance study.
In 2022, Mokadem et al. [60] provides a new classification of data replication tactics in cloud systems in this research. It also considers a number of other factors that are unique to cloud settings, including (i) the profit orientation, (ii) the examined objective function, (iii) the number of tenant objectives, (iv) the cloud environment’s characteristics, and (v) the assessment of economic expenses. Regarding the final criterion, we concentrate on the provider’s financial gain and take into account the provider’s energy use.
Economic profit
As a result, getting the most economic benefit at the lowest possible operating cost may not always coincide with achieving satisfactory performance. A replica is actually only constructed if a node that could receive a new duplicate is located, even if a replication is taken into consideration (per-query or per set of queries). Moreover, the provider needs to make money from this duplication. Before choosing to duplicate (before Q is executed), the provider’s economic advantage (Q_Profit) is also calculated for this purpose. As a result, the provider’s estimated revenues (Q_Revenues) and expenses (Q_Expenses), as indicated by Formula (1), are determined.
In order to ensure profitability for the provider when implementing Q, its income must exceed its expenses when several renters are served.
Review on data replication models in the cloud, performances and the maximum attainments
Review on adopted data replication models in the cloud
Each work is reviewed regarding adopted data replication methods in the cloud, and the pictorial depiction is shown in Fig. 1. By delivering several copies with a coherent state of the same service, data replication a well-known distributed approach is the key mechanism utilized in the cloud for lowering user waiting time, boosting data availability, and minimizing cloud system bandwidth usage. Moreover, it was observed that the ADRS method was adopted in [43], and the LALW method was exploited in [49]. For Grid environments, a novel dynamic replication approach known as LALW [49] is employed. The LALW technique’s primary objective is to assign different weights to files of differing ages. As a consequence, the weight declension rate would be reduced.

Architectural diagram of data replication models in the cloud.
Further, the PEPRv2 scheme was adopted in [76], the D2RS model was exploited in [73], SDS algorithm was determined in [65]. The suggested SDS [65] method would reduce the cost of data duplication. SDS is a positive feedback system that encourages the investigation of superior solutions by allocating additional agents to them. EIMORM model was exploited in [13], the APER scheme was adopted in [75], the D2R-IWD model was determined in [63], the fuzzy inference system was adopted in [45], and the LRM model was employed in [72], respectively. LRM [72] is the replication manager referred to in this study. LRM’s [72] primary responsibility is to obtain user inquiries, gather information about the cluster’s data nodes, as well as eventually choose the greatest host for the blocks. LRM carries out these responsibilities in collaboration with its other components. LRM is the last arbiter.
Moreover, the CSO algorithm was adopted in [50], the SPDPR-Tweaks model was employed in [4], the three-tier cloud computing data centre architecture was determined in [6], the CB-DRP model was adopted in [41], the R-PCP technique was adopted in [78], QADR algorithm was exploited in [35], MRR scheme was determined in [36], PMCR scheme was exploited in [37], the optimal offline algorithm was used in [53], and VRS-BQ technique was exploited in [2], correspondingly. In a cloud scenario, the VRS-BQ [2] replica placement strategy is utilized to reduce storage usage, response time, as well as replication process time. In addition, the MOABC algorithm was used in [67] and the DROPS model was adopted in [3]. Furthermore, the Mirror scheme was exploited in [22], the FRAGMENT model was adopted in [10], and CRANE scheme was adopted in [61], and the LAST-HDFS system was adopted in [7]. The LAST-HDFS [7] technology guarantees location-aware file allocations & monitors file transfers in the cloud in real-time to prevent any unlawful transfers.
Moreover, other data replication models in the cloud such as the MTDB-MR algorithm was deployed in [66], Quadratic HPA was exploited in [77], the BDS+ scheme was employed in [83] and MO-PSO and MO-ACO algorithm was adopted in [5] correspondingly. In addition, the DCD and OCA algorithm was deployed in [38], the RER algorithm was employed in [15], the BVS algorithm was exploited in [30], the RSPC strategy was adopted in [59] and the RRSD model was deployed in [74] respectively. RRSD [74] employs the approach of making minimum copies to enhance load balancing and minimize storage consumption, and data dependability.
Consequently, the Poisson stochastic process was adopted in [34], the PDR Strategy was deployed in [46], the DOSN system was exploited in [16], the adaptive forecasting replication Framework was employed in [56] and the BaRRS algorithm was adopted in [9]. Similarly, the DCR2S was adopted in [19], the MR-PDP scheme was deployed in [81], SaRBP was employed in [82], the TRC technique was used in [33], the FSDA method was adopted in [52], and FT-Aurora Robust Cloud Manager was adopted in [27]. To evaluate the trade-offs between the six objectives, FSDA [52] was utilized. It’s used to assess fitness and more accurately characterize the solution. The new replica is placed in the most optimal position to decrease access time while maximizing network & resource utilization. Likewise, the weighted dynamic replication strategy, DPRS, FFTF scheme, fault-tolerant workflow scheduling algorithm, MORM strategy, SSOR architecture, replication factor modelling approach, Single Exponential Smoothing method, BCVS algorithm, DMDR, SWORD approach, EM algorithm, replication-based load balancing scheme, DHR algorithm, HS algorithm, active machine learning framework, fuzzy logic system, ILP model, and GPR model were adopted in [1,11,20,25,26,28,31,32,39,40,44,48,51,62,64,69,79,80] and [8], respectively. To forecast future file demand, the single exponential smoothing approach [26] is utilised. It creates a smoothed time series & removes irregular as well as random interference. The DHR technique in [44] distributes replicas at the most suitable sites, i.e. the optimum site with the most access for such replicas. While many locations host replicas, it also decreases access latency by picking the optimal replica. When compared to other regression models, GPR [8] is quite accurate.
Table 3 determines the performance measures obtained from various contributions regarding data replication models in the cloud. From Table 3, it is noted that 19 papers that have made a performance analysis under response time have contributed about 29.23% of the reviewed works, and the computation time was examined in 9 papers which had contributed about 13.84% of the entire works. Likewise, the SEU has contributed about 12.30% (8 papers). Further, energy consumption, cost computation, execution time, and storage capacity have been adopted in 9.23% (6 papers). Moreover, the AUC and FPR have contributed about 9.23% (6 papers) of the entire contribution. In addition, the false network usage and load variance have been contributed about 7.69% (5 papers). Furthermore, the bandwidth, delay, and several files have contributed about 6.15% (4 papers) of the entire contribution. Likewise, the latency, storage cost, number of replications, and transmission time have contributed about 4.61% (3 papers). On the other hand, the replication frequency, number of storage nodes, replication cost, file size, storage overhead, query size, recovery time, and completion time have been adopted in 3.07% (2 papers). Accordingly, the measures like provider expenditure, execution rate, block availability, mean block unavailability, efficiency, updation time, makespan, access time, TUE, runtime, replication time, R/W ratio, size of outsourced file, replica size, number of partition, mitigation time, detection correctness rate, number of violation, network overhead reduction, accuracy, time complexity, total provider expenditure, VM processing capability, load balance, reliability, security levels, desired level of data availability, current time point, data reduction rate, number of data centers, available probability, TPV verification time, MDS memory, request arriving rate, task failure penalty, P-value, number of data nodes, VM size, memory usage, CPU utilization, number of replica factors, hit ratio, task count, check point interval, average resource usage, number of requests, failure rate, threshold error rate, number of host, average error, arrival rate, computational capacity, NLCD ref data, RLCD ref data, RLCD-NLCD data, SBER value, time of execution query, mapping time, replication factor, and data locality have contributed about 1.54% (1 paper), respectively.
Review of various performance measures based on data replication in the cloud
Review of various performance measures based on data replication in the cloud
(Continued)
Maximum performance attained in the reviewed works
(Continued)
The maximum performance attained in every reviewed paper based on data replication in the cloud is illustrated in Table 4. Further, the response time attained in [63] has obtained a better range of 100 ms and the computation time used in [62] has the best value of 200 ms. By using the replication-based load balancing scheme [62], the computation time is lower with better outcomes than other techniques. Moreover, SEU has obtained a better value of 20% measured in [5] and Energy consumption has obtained a better value of 0.3 kwh examined in [78] respectively. The R-PCP approach [78] built a cloud platform with computing, storage, & bandwidth capabilities. To enhance resource utilization and energy consumption, R-PCP restricts the amount of provided resources. Likewise, the cost computation and execution time have attained a better value of 0.025$ and 500 ms which is examined in [31] and [79]. The response speed and average response time are greater by using the BCVS algorithm [31]. Similarly, storage capacity, network usage, load variance, bandwidth, delay, number of files, latency, storage cost, number of replications, transmission time, replication frequency, number of storage nodes, replication cost, and file size have attained better values of 100%, 0.25 ENU, 0.17, 640 Gb/s, 2500 ms, 1500 Mb, 0.6 ms, 15.3, 2, 50 sec, 0.1, 36, 1000, and 1500 Mb it has been examined in [6,22,36,38,43–45,48,49,49,59,67,67,77] and [48], correspondingly. The storage overhead, query size, recovery time, completion time, provider expenditure, execution rate, block availability, mean block unavailability, efficiency, updation time, makespan, access time, Traffic Usage Efficiency (TUE), runtime, replication time, R/W ratio, size of the outsourced file, replica size, number of partition, mitigation time, detection correctness rate, number of violation, network overhead reduction, and accuracy has attained a better value of 50%, 11, 0.5 sec, 200 ms, 26.94$, 92%, 0.8, 0.1428, 6.5%, 15 sec, 0.95, 0.25 sec, 1.38%, 10 sec, 22%, 0.50, 64 Mb, 15 Gb, 4, 10 minutes, 100%, 89%, 50%, and 99% that are examined in [2,3,7,11,22,32,35–37,41,50,61,61,61,62,66,72,73,73,76–78,80] and [83]. CRANE [61] can decrease replica construction & migration time by up to 60% & inter-data center network traffic by up to 50% when maintaining the minimum necessary data availability. The measures such as time complexity, total provider expenditure, VM processing capability, load balance, reliability, security levels, desired level of data availability, current time point, data reduction rate, number of data centers, available probability, TPV verification time, and MDS memory have attained higher values of 3.7, 95$, 1500MIPS, 10%, 8%, 0.9, 99%, 31, 99%, 1, 0.6–0.9, 18.827 ms, and 8 G and they have been analysed in [15,16,16,19,19,30,34,56,59,74,74,81], and [82], respectively. In comparison to other existing techniques, the experiments show that RRSD [74] can achieve better load balancing & assure data dependability. Also, request arriving rate, task failure penalty, P-value, number of data nodes, VM size, memory usage, CPU utilization, number of replica factors, hit ratio, task count, checkpoint interval, average resource usage, number of requests, failure rate, and threshold error rate were exploited in [1,11,20,25,25,27,27,27,33,51,52,52,69,82], and [1] and they have acquired higher values of 104 per unit time, 20000, 0.05, 7, 2.5 MB, 95%, 92%, 3, 72%, 100,000, 1 hour, 41%, 30, 50%, and 9% correspondingly. The replication factor modelling approach [1] minimized the failure rate more than other schemes. In addition, the number of hosts, average error, arrival rate, computational capacity, NLCD ref data, RLCD ref data, RLCD-NLCD data, SBER value, time of execution query, mapping time, replication factor, and data locality have attained higher values of 3–10, 2.72%, 6.67, 90%, 41.8%, 36.9%, 36.3%, 0.7, 0.25 s, 0.5 s, 1.22, and 73.96% and they have been measured in [8,8,40,40,40,48,62,64,64,79,80], and [8], respectively. EM method [64] was applied to lower the average error and improve the arrival rate. When compared to the default replication method and the second best option, the GRP model [8] helps to minimize mapping time (ERMS). The average replication factor is better than the default method, as can be observed. Furthermore, lowering the thresholds improves the data locality measure.
Evaluation of adopted replication handling schemes in the cloud and chronological review
Review on replication handling in cloud storage systems
A review of major studies on replication handling in cloud storage systems is presented. As it will be explained, some of the studies evaluated took a replication modelling technique, whereas others took a different strategy: replication management, replication selection, replication placement, replication creation, replication retirement, replication choice, & replication assignment. Figure 2 depicts the replication handling in cloud storage systems.
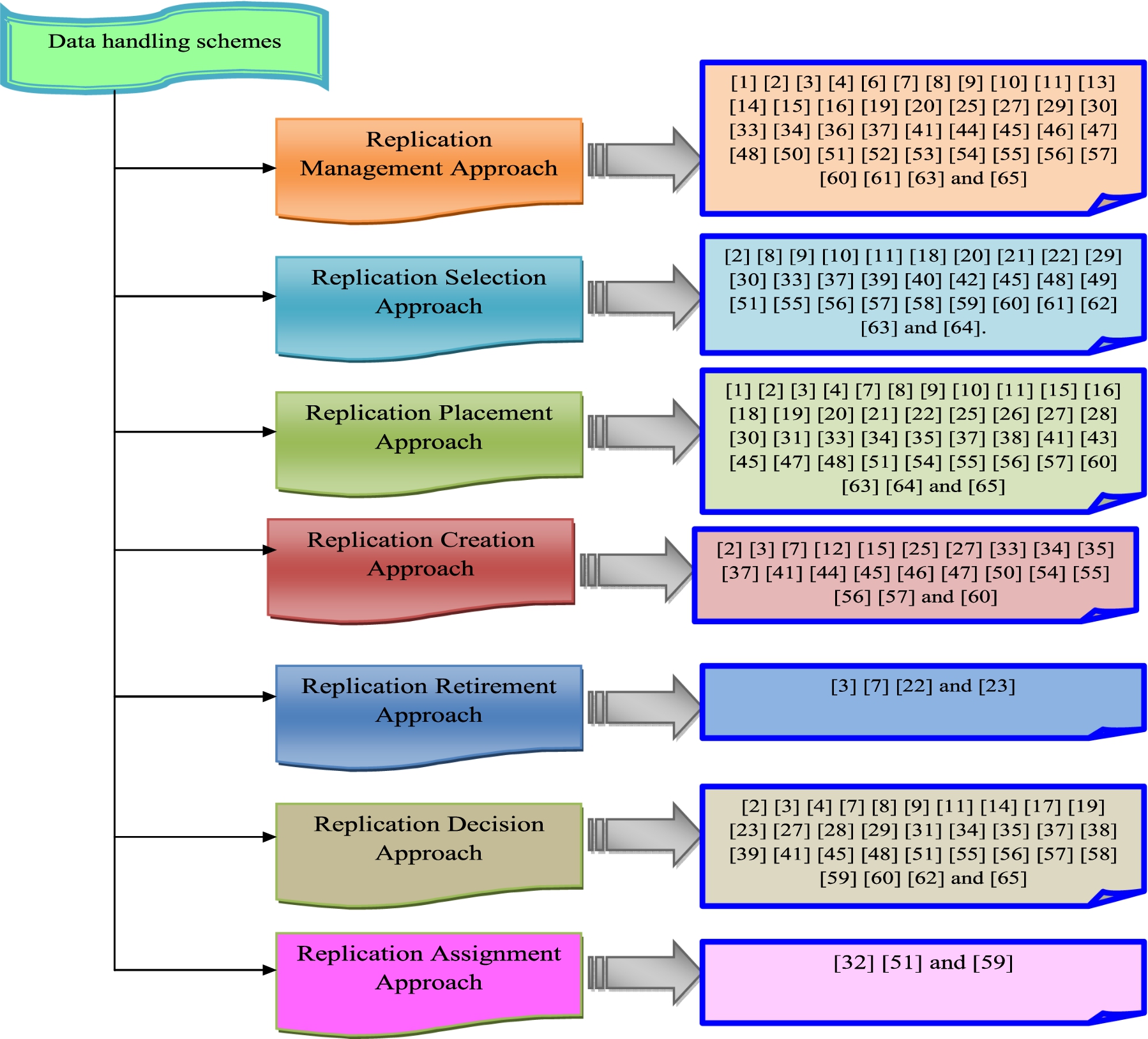
Pictorial representation on review of replication handling in cloud system.
From the review, the replication management approach was employed in [1,2,5,6,11,13,19,20,26–28,30–35,39,41,43–46,48–53,59,61,63,66,69,72,73,75,76,78,79,83] and [8] respectively. An important topic that is closely related to replication migration is replication placement. One of the most difficult to solve when evaluating new replication requests is choosing the most effective location to transmit the duplicate. To reduce network congestion & ensure replica availability while keeping access time efficient, the updated schedule placement should be evaluated. Another key related problem is the replica’s effective size that falls within this group. The incremental technique which is a dynamic way of replicating could be a fair guideline for replica size. The size of replicas could be affected by the size of the targeting storage. In terms of replica size, replication might well be regarded as the granularity of replication that relates to the quantity of data size involved in replication creation. The replication selection approach was adopted in [2,3,5,9,25,28,30–32,37,39,40,44–46,48–52,56,62–64,67,72,79,81,83] and [80]. In addition, the replication placement approach was used in [2,3,5,7,16,19,20,26,30–32,35,37–39,43–46,48–53,59,61,63,66,67,72–80,82] and [8] respectively. However, replication creation approach was exploited in [4,19,20,26,27,30–33,46,48,49,52,59,61,66,69,74–76,78] and [44]; the replication retirement approach was adopted in [3,75,76] and [22], correspondingly. From the review, it is attained that the replication decision approach was used in [16,19,22,31,32,36,38–41,44–46,48–53,56,59,62–64,66,73–77,83] and [8], correspondingly Moreover, replication assignment approach was exploited in [15,39] and [62], correspondingly.
Data auditing schemes
The review of data auditing schemes is analysed from the papers [12,14,18,21,24,65] and [17], respectively. Ramanan et al. [65] have developed a public auditing method that would achieve 3 objectives: (1) Accuracy: A public verifier (i.e., a data user) may accurately validate the security of cloud data. (2) Public auditing: a public verification may audit the accuracy of data without having to download the whole data set from the cloud; (3) Certification less: this implies the accuracy of public auditing that does not require the use of a public verifier to manage certificates.
Jaya et al. [21] have presented a Certificateless Multi-Replica Dynamic Public Auditing Scheme for Shared Data in Cloud Storage to address these issues. The replica version table, a unique data structure in the method, facilitates shared data dynamics. This system also allows for safe user revocation from the organization. Under the hardness premise of the usual CDH & DL challenges in the ROM, they establish that the approach was evidentially safe against type I/II/III opponents using the security analysis. This approach was efficient & practical, as demonstrated by its performance & test assessment.
Imad et al. [14] have suggested an auditing strategy that allows consumers to audit their outsourced data in an expedient & secure manner. By providing the data delegation key & utilizing the auditing key while constructing IDs for the data blocks, they allow the data user to outsource the data auditing process to the TPA. The suggested technique provides a minimal computing cost for users and allows them to outsource the data verification system to a 3rd auditor thereby preserving a low computing & communication cost without endangering the stored data’s confidentiality.
Xiang et al. [18] have proposed a cloud data auditing technique that supports the deduplication of files & authenticators. To their information, the suggested approach would be the first actual implementation of low-entropy security. The malicious cloud cannot fabricate any authenticator to satisfy the auditing verification for a file having insufficient entropy. The suggested technique was simple to use. During the auditing phase, users may not be able to engage with the TPA. To demonstrate that the suggested approach was safe, they provided comprehensive security proof. Extensive tests demonstrate the effectiveness of this strategy.
Jing et al. [24] presented a public cloud auditing approach for smart cities that’s also lightweight & privacy-preserving and does not need bilinear couplings. Mainly, the suggested methodology was pairing-free, enabling a third-party auditor to construct authentication on behalf of users. Additionally, it safeguards data privacy from third-party auditors & cloud service providers. Furthermore, in a multi-user environment, this novel technique might well be readily & naturally extended to batch auditing. When compared to conventional public cloud auditing techniques, detailed performance and security assessments demonstrated that the proposed scheme seems to be simpler and more secure.
Daniel et al. [12] have provided a lightweight auditing approach for outsourced data integrity testing & deduplication. The suggested method integrates hashing as well as symmetric encryption with a distributed hash table data structure that decreases computational and communication costs for integrity verification while also allowing for rapid data dynamic functions. The suggested methodology’s results show that this lightweight data audit method exceeds extant systems in terms of computing, communication, & processing costs.
Gan et al. [17] have offered an efficient auditing strategy for outsourcing large data which uses algebraic signatures as well as an XOR-homomorphic function to accomplish some benefits, including fewer problems and proofs, non-block verification, data privacy protection, reduced computational & communication costs. The proposed approach allows a trustworthy third-party auditor to examine outsourcing data in the cloud on account of DOs. Furthermore, the suggested basic method is secure against different assaults using the security framework. The basic & expanded schemes were both very efficient, according to the performance assessment.
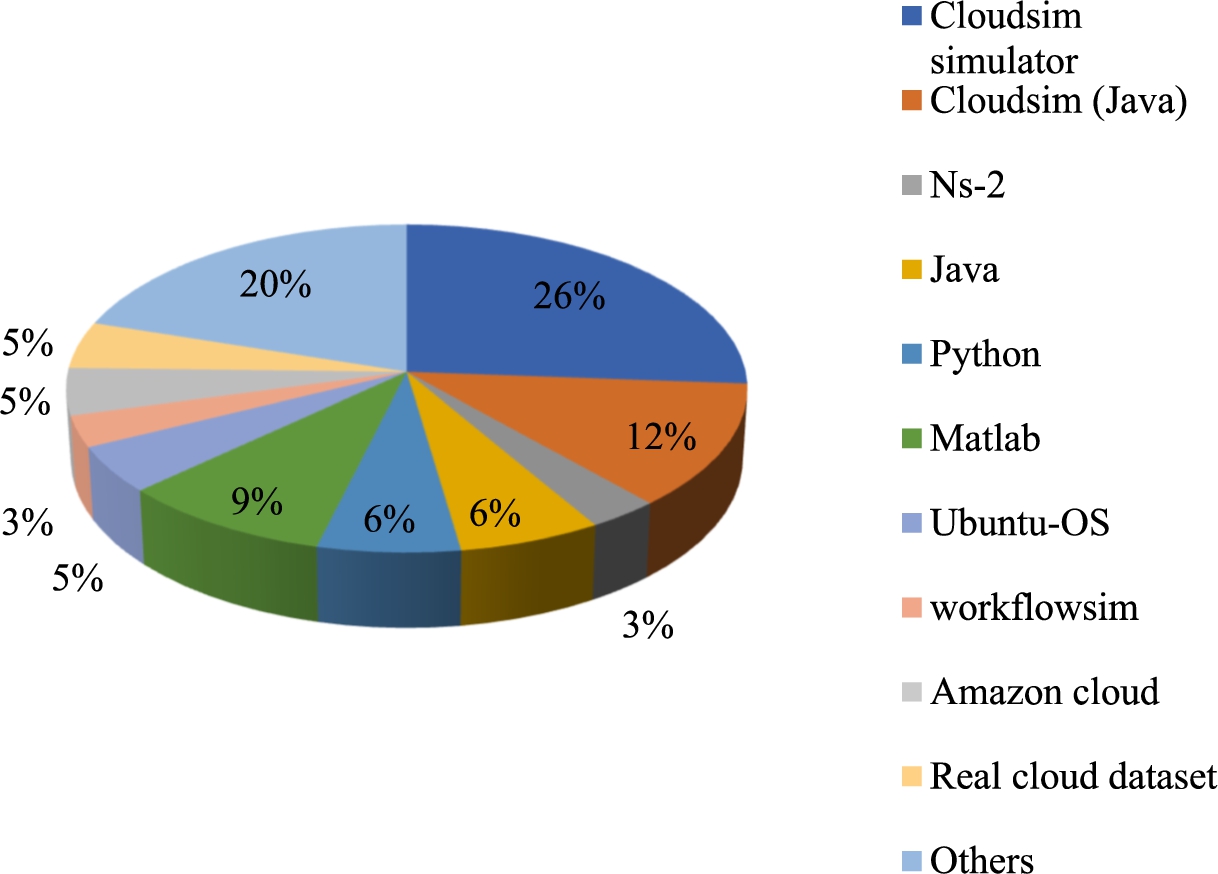
Representation of simulation tools used in each paper.
65 papers related to data replication in the cloud are taken for review on the simulation tool used in each paper. Figure 3 shows the representation of simulation tools used in each paper. Initially, 8 papers [2,13,43,45,51,63,73] and [19] have used Cloudsim (Java) as a simulation tool. Further, 17 papers [5,10,16,25,26,30,31,46,48–50,52,53,59,67,75,76] has contributed normal cloud sim simulator tool. Moreover, 4 papers [11,20,79] and [72] have adopted Java as a simulation tool. Likewise, 4 papers [11,20,79] and [72] have adopted Java as a simulation tool. Moreover, 6 papers [35,39,62,64,83] and [28] has adopted the MATLAB as a simulation tool. In addition, 4 papers [22,41,61] and [38] have adopted the PYTHON as a simulation tool. Still, 2 papers [6] and [77] have adopted the NS-2 as a simulation tool. Furthermore, 3 papers [9,27], and [1] have used Ubuntu as an operating system. Workflows have been used in 2 papers [78] and [69]. 3 papers [32,36] and [37] have used Amazon cloud datasets. Further, 3 papers [7,8] and [56] have used real cloud datasets. Also, 13 papers [3,4,15,33,34,40,44,65,66,74,81,82] and [80] have used other simulation tools.
Research gaps and challenges
The number of individuals using cloud storage has exploded recently. The reason was that the cloud storage system is difficult to keep and has lower storage costs than other storage options. It also offers excellent dependability, and availability, and is well-suited to large-scale data storage. The technologies use redundancy to ensure high availability & reliability. Objects were cloned numerous times in replicated networks, with each copy stored in a distinct place in distributed computing. As a consequence, Data Replication poses a minor danger to the Cloud Storage System for users, while providing effective Data Storage would be a major difficulty for providers. Data replication enables users to view data in real-time from many sources including servers, websites, as well as other sources, overcoming the difficulty of ensuring consistent data availability. The procedure of storing and maintaining multiple copies of critical data across several devices is referred to as data replication. To ensure a flawless replication process, they need to invest in a variety of hardware & software components, including CPUs, storage drives, and other components, as well as a full technical setup. Setting up a reaction pipeline is required to complete the arduous work of replication without any defects, errors, or other issues. Establishing a response pipeline that works correctly might take days, weeks, or even months, based on the replication requirements as well as the task’s complexity. Furthermore, large firms might find it difficult to maintain patience & maintain all stakeholders on the same page at this time. A considerable volume of data moves from the data source to the target database during replication. A significant amount of bandwidth was required to enable a smooth flow of information & prevent data loss. Even among big enterprises, keeping bandwidth capable of sustaining and processing enormous amounts of complex data in doing replication may be a difficult issue. It also necessitates investing in more “manpower” with a superior technological background. All of these constraints make data replication difficult, especially for large enterprises. As a consequence, the different existing data replication solutions were examined as well and the major challenges caused by data replication were highlighted. The goal of this study work in the future is to lower the number of replications while maintaining data availability & dependability.
Conclusion
This paper offered a complete review of data replication in the cloud. The contribution of this paper is as follows;
This paper determined the reviews in 65 papers related to data replication in the cloud.
The analysis has reviewed the performance measures and its maximum achievements were contributed by different data replication schemes.
Various data handling schemes in the cloud exploited in every reviewed work were also analyzed and determined diagrammatically.
In addition, the data auditing schemes were analyzed in certain papers and the simulation tools were analysed in 65 papers.
In the end, this paper presented different research issues that were helpful for researchers in further work on data replication in the cloud.
In the future, the cost analysis of the replication can be considered.
In addition, real time test bed can be considered.
In order to increase provider profit, it may be possible to balance tenant volume and performance in subsequent work.
In this case, we want to demonstrate that the ‘pay as you go’ model yields the most return for the provider when it is used to serve an ideal number of tenants.
This serves as justification for the suggested strategy’s design.
To determine which replicas should be replicated or removed beforehand, the log of previous queries may also be considered for making these decisions.
To further minimize resource consumption, RSPC could also be assessed while employing data compression or de-duplication in the environment.