
Abstract
BACKGROUND:
With the exponential increase in the volume of biomedical literature, text mining tasks are becoming increasingly important in the medical domain. Named entities are the primary identification tasks in text mining, prerequisites and critical parts for building medical domain knowledge graphs, medical question and answer systems, medical text classification.
OBJECTIVE:
The study goal is to recognize biomedical entities effectively by fusing multi-feature embedding. Multiple features provide more comprehensive information so that better predictions can be obtained.
METHODS:
Firstly, three different kinds of features are generated, including deep contextual word-level features, local char-level features, and part-of-speech features at the word representation layer. The word representation vectors are inputs into BiLSTM as features to obtain the dependency information. Finally, the CRF algorithm is used to learn the features of the state sequences to obtain the global optimal tagging sequences.
RESULTS:
The experimental results showed that the model outperformed other state-of-the-art methods for all-around performance in six datasets among eight of four biomedical entity types.
CONCLUSION:
The proposed method has a positive effect on the prediction results. It comprehensively considers the relevant factors of named entity recognition because the semantic information is enhanced by fusing multi-features embedding.
Introduction
With the rapid development of biomedical technology, biomedical literature is also growing at an exponential rate. For example, since the global COVID-19 outbreak in March 2020, PMC has published more than 280,000 papers related to COVID-19. So, it is very important to quickly and efficiently extract disease-related information. The Biomedical Named Entity Recognition (BNER) is the first step and the most important step in biomedical semantic information extraction [1, 2, 3]. BNER is a prerequisite and critical part of building medical knowledge graphs, medical question and answer systems, medical text classification in biomedical field [4, 5]. In addition, highly accurate entity extraction largely guarantees the high reliability and applicability of the constructed knowledge graphs and medical Q&A systems [6, 7, 8]. It is the basic step of many downstream text mining applications and lays a foundation for further mining the rich information in the biomedical literature.
BNER has received attention from researchers and it is a interesting research topic in Natural Language Processing (NLP). BNE mainly includes gene, protein, DNA, RNA, disease, drug, and chemical substance [9]. Until now, various text mining methods are applied to identify BNEs, such as lexicon and rule-based methods [10, 11, 12], statistical machine learning methods [13, 14, 15, 16, 17, 18, 19], deep learning methods [20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31].
The deep learning approach uses end-to-end model training and automatic feature extraction to avoid tedious manual extraction by acquiring features and distributed data representations with good generalization capabilities. Compared to the lexicon and rule-based methods or statistical machine learning methods, deep learning neural network-based methods have the advantage of no longer relying on manual features and domain knowledge, reducing the cost of manual feature extraction, having more robust generalization, and effectively improving system efficiency [2, 3, 4].
In the last few years, the performance of Long Short-Term Memory Networks [18] (LSTM) and Conditional Random Fields [19] (CRF) for NER has improved considerably. Yao et al. [20] first built a multi-layer neural network on unlabeled biomedical texts to implement word embedding vectors for biomedical words on a large-scale corpus. Huang et al. [21] proposed a BiLSTM-CRF model for predicting sequence labels. Lyu et al. [22] used the BiLSTM-RNN model to combine biomedical word embedding and character embedding for entity recognition. Although their work has achieved some success, the word vector methods used are too simple to study the deep meaning of biomedical texts.
Gridach et al. [26] first used character-level embedding to represent features in the biomedical domain and constructed the hybrid model BiLSTM-CRF for named entity recognition. Liu et al. [27] extracted lexical and morphological features of words, and a multi-channel convolutional neural network was post-connected to the BiLSTM-CRF model for entity extraction. Patel et al. [28] adopted a method based on Flair and GloVe embeddings and a bidirectional LSTM-CRF-based sequence tagger to train a BNER model. Yoon et al. [29] build a model using multiple BiLSTM-CRFs that are constructed on top of multiple individual task NER models (STMs). They can exchange information to each other for better prediction result. Wang et al. [30] constructed a multi-task learning framework that shares character-level information and word-level information of related BNEs to achieve significant performance gains. Sachan et al. [31] proposed BiLM-NER model, a bi-directional language model (BiLM) which is trained on unlabeled data, a better method is adopted to initialize the parameters of NER model. In addition, recent work on building tools in the biomedical field, such as HunFlair [32] and BERN [33], has achieved good results.
However, direct biomedical application methods has the following limitations: (i) Word representation models like Word2Vec [34], ELMo [35], BERT [36], and ALBERT [37] are mainly trained on datasets with general non-domain specific texts (e.g., Wikipedia). The general word and sentence patterns are different from the biomedical text patterns. It is difficult to catch the biomedical semantic information from the text. (ii) The representation layer in previous work [26, 27, 28, 29, 30, 31] is simple and does not effectively capture local and global information of words. A single word vector representation inevitably avoids the problem of multiple word meanings.
To solve these problems, we propose an end-to-end approach based on biomedical fuse multi-feature embedding to handle the shortcomings mentioned above for BNER. Our goal is to extract a variety of features representing biomedical named entities from different dimensions, so as to improve the effect of entity recognition. Our contributions are as follows:
A multi-feature embedding based BNER method to capture features from biomedical texts is proposed. Combining deep contextual word-lever features, local char-level features, and part-of-speech features of biomedical texts enhances the semantic information representation of words to identify entities effectively.
We have validated the effectiveness of our method on eight datasets of four entity types in the biomedical field: disease, drug/chemical, gene/protein, and species, and all results show that our model is better than other published methods.
Method
Our proposed model consists of two main components: (i) Multi-Feature Representation layer for enhancing the semantic information, (ii) Downstream named entity recognition task layer for capturing long dependent information, and getting globally optimal tagging sequence. The whole workflow is shown in Fig. 1.
Multi-Feature Embedding BiLSTM-CRF architecture.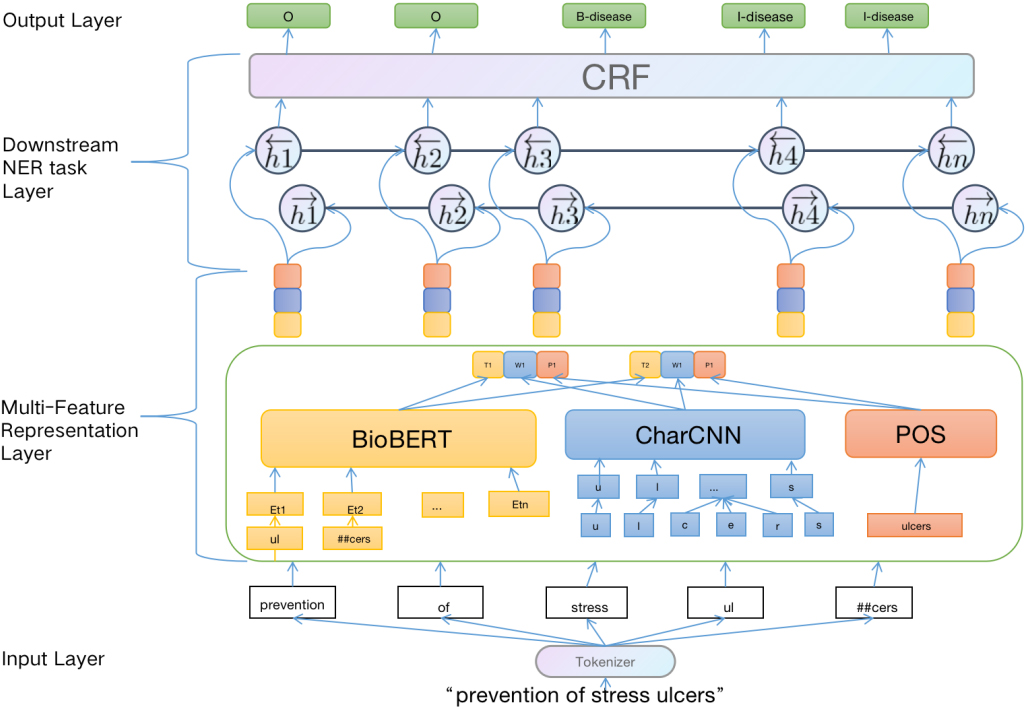
The NER task is to label the entities in a given sentence. More formally, given the input sentence
To extract the coverage information of the input sentence as much as possible, we apply the following three feature extraction methods from different perspectives to represent the input sequence: deep context word-level features, local char-level features, and part-of-speech features.
Deep context word-level features
At the text representation layer, we adopt the BERT architecture [36] as our model to obtain deep contextual word-level features of biomedical texts. Since what needs to be identified in this study are entities in the biomedical domain, we employ BioBERT [38], which is a model pre-trained on a large-scale biomedical corpus based on the BERT architecture. A language model trained with masks using bidirectional transformers does a good job of contextualizing words. Below we will briefly introduce the core architecture in the BERT model: the Transformer Encoder.
In order to better represent biomedical text, twelve Transformer Encoders are used in the pre-trained language model BioBERT. In the Encode layer, use a multi-headed self-attention mechanism instead of the traditional LSTM model. The formula for the self-attention mechanism is shown in Eq. (1):
where,
The multi-headed self-attention mechanism learns multiple
To fully consider the internal information of biomedical texts, Character-level Convolutional Neural Network [40] (CharCNN) is used to extract the local char-level features of each word in the biomedical text. In this paper, the character-level convolutional neural network contains three components: a character vector layer, a one-dimensional convolutional layer, and a maximum pooling layer.
The character vector layer transforms the characters in each word of the input sequence into its corresponding character vector, which constitutes the character vector matrix of the word that will be continuously updated and learned during the model training. The alphabet used in our models consists of 70 characters [30] as shown in Table 1.
The alphabet used in all of our CharCNN models
The alphabet used in all of our CharCNN models
In the convolution layer, multiple layers of convolution kernels are used on the character vector matrix to extract the local features of the words. Finally, the local char-level feature vectors of biomedical text words are obtained by using maximum pooling.
To represent the syntactic pattern characteristics of the words in the input sentence, such as the dependencies between the suffixes and the output labels, we use the NLTK to get the part-of-speech tag sequence of the text sentence.
Lexicality, as the fundamental grammatical property of words, is a crucial feature of words and utterances. The part-of-speech tag sequence contains the syntactic information of the words in the sentence.
Design downstream named entity recognition task layer
BiLSTM for long dependency information
To process the long dependency and contextual information in the input text sequence, we apply Bidirectional Long Short-Term Memory Networks (BiLSTM) to access more semantic dependencies.
LSTM introduces a gating mechanism in the RNN structure to selectively change what needs to be retained and capture long-range associative information, which effectively overcomes the problems of traditional RNN models. The specific calculation process of LSTM is given in Eq. (2.2.1):
where,
The BiLSTM model which uses a forward and backward LSTM module can consider the contextual information to extract bi-directional sentence features to obtain better results, which is more suitable for the characteristics of BNER.
To solve the problem of possible inter-dependencies and mutual constraints in the tag sequences, such as B-gene tags should not be followed by I-chem tags, we adopt the Conditional Random Field (CRF) in this research.
Although the BiLSTM model can recognize entity boundaries, it does not fully learn the label dependencies between entity sequences. CRF is a probabilistic graphical model proposed based on the EM [41] model and the HMM [42] model commonly used for tagging sequences such as named entity recognition, target recognition, and linguistic annotation. It can get a globally optimal tagging sequence by considering the relationship of adjacent tags and using a state transfer matrix to decode jointly.
Assume that the output sequence of the BiLSTM model is X and one of the predicted sequences is Y. then the evaluation score P (X, Y) can be obtained by Eq. (5).
where,
Experiment datasets
To verify the universality and effectiveness of the proposed model, our method is evaluated in eight datasets containing four entity types: gene/protein, drug/chemical, disease and species. Datasets including gene and protein include BC2GM and JNLPBA corpus. Datasets including drug and chemical include BC4CHEMD and BC5CDR-chem corpus. Datasets including disease include NCBI and BC5CDR-disease corpus. Datasets including species include LINNAEUS and Species-800 corpus. A brief explanation of the dataset used in this paper is as follows:
BC5CDR: This dataset is provided by BioCreative V Chemical Disease Relation Extraction (BC5CDR) Task [43]. The dataset has two subtasks, the first is to identify chemical entities, and the second is to identify disease entities. BC4CHEMD: This dataset is provided by BioCreative Community Challenge IV Task [44]. It is a data manually marked by expert chemistry from 10,000 PubMed abstracted references for the development and evaluation of chemical NER tools, and eventually contains about 80,000 chemical entities. NCBI Disease: This dataset is provided by Doğan et al. [45], which includes 6892 disease mentions from 793 abstracts. It is worth mentioning that the dataset is labeled at the Mention and conceptual levels, with the characteristics of large scale and high quality, and it aligns the disease name with the corresponding disease concept ID. JNLPBA: This dataset was provided by Kim et al. [46] and annotated on 2400 abstracts in MEDLINE database, resulting in a total of 22,402 sentences containing five entity types: DNA, RNA,cell-type, cell-line and protein. BC2GM: This dataset is provided by Smith et al. [47] at 2008 the BioCreative II Gene Mention Task. The entire dataset contains 20,000 sentences, and participants were asked to identify the genes mentioned in the sentences by giving the beginning and end characters of the sentences. LINNEAUS: This dataset is proposed by Gerner et al. [48], which is an open-source species name recognition and normalization software system. To verify the system, the authors created a LINNEAUS dataset of 100 full-text documents randomly selected from the PMC and manually annotated, resulting in 4259 species references. Species-800: This dataset is proposed by Pafilis et al. [49]. and the species entities were annotated manually on 800 PubMed abstracts.
Biomedical NLP researchers widely use these datasets for testing BNER models. The above datasets used in our paper are publicly available and can be downloaded from the following
Statistics of datasets
To evaluate the performance of our method, we adopt three evaluation measures: precision (P): indicates the proportion of items that should be retrieved among all retrieved items, recall (R): indicates the proportion of all retrieved items to all items that should be retrieved, F1-score (F1): indicates the weighted harmonic average of Precision and Recall. In order to more accurately identify entities in biomedical literature, we believe that the entity predicted by the model is correct only when the entity type and boundary are completely matched.
Analysis of experiment result
Comparison with different representation
In order to test the multi-feature embedding representation, our proposed method compare with two main representation methods, Word2Vec and BioBERT. The benchmark methods of downstream NER tasks all adopt method BiLSTM-CRF.
As shown in Fig. 2, the performance of the models based on the pre-training BioBERT is better than Word2Vec. The main reason is the latter uses the word vectors obtained by traditional statics embedding method and cannot handle the problems of ambiguity and polysemy.
In addition, our model outperforms in terms of F1 values due to the character-level local features and lexical features incorporated. That is because CharCNN module can extract local character-level features, which can not only represent morphological information to a certain extent, but also model biological entities with mixed case, special characters and fuzzy boundaries. The addition of lexical features adds more linguistic information to the text. Thus, the combined feature embedding method proposed in this paper improves the accuracy of the model for entities.
Comparison with state-of-the-art studies
To evaluate the performance of the proposed method, we compare with the state-of-the-art methods including CollaboNet [29], MTM [30], BiLM [31], MTL-LS [52], BioBERT [38], DTranNER [50], BioBERT-MRC [51], Bio-XLNet-CRF [53], MT-BioNER [54].
Comparison of BNER methods for “Gene/Protein”
Comparison of BNER methods for “Gene/Protein”
Comparison of experimental results of Word2Vec, BioBERT and our method.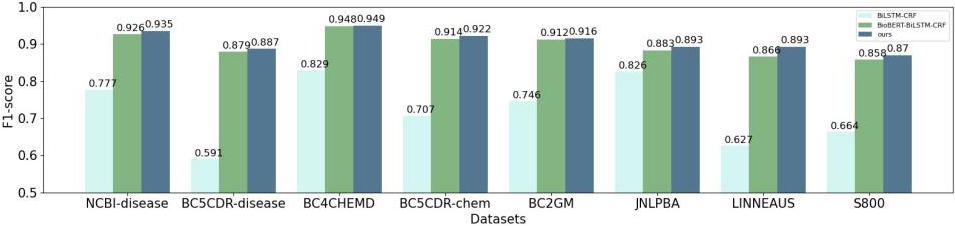
Comparison of BNER methods for “Disease”
Results are summarized in Tables 3–6. The table reports three indicators on each dataset: precision (P), recall(R) and F1 score (F1). We use bold to show the best score, and use the underline to show the second best score. As a result, our proposed method acquire the best performance on six datasets among eight..
The reasons why our model achieves better performance are (i) It enhances the semantic representation of the entity by fusing features of different perspectives. (ii) We use multiple layers of convolution kernels in CharCNN, which can catch the non-surface information of the word from multiple angles. In addition, character level has the advantage that it can be easily generalized to all languages.
Comparison of BNER methods for “Species”
Comparison of BNER methods for “Chemical/drug”
As shown in Tables 3–6, it can be seen that the F1 score of our model is the highest in the medical datasets of (i) Gene/protein-related datasets, our model achieves 91.67% (6.56% improvement) in the BC2GM and 89.30% (10.72% improvement) in the JNLPBA. (ii) Disease-related datasets achieves 93.57% (5.66% improvement) in the NCBI. (iii) Chemical/drug-related datasets achieves 94.97% (2.27% improvement) in the NCBI. (iv) Species-related datasets achieves 89.37% (1.13% improvement) in the LINNAEUS and 87.02% (12.96% improvement) in the Species-800. Compared with other recent methods, the results are competitive and definite improvements can be seen on most datasets
On BC5CDR dataset, the result is not the best one because our method differentiates between subsets in BC5CDR dataset. BC5CDR dataset contains two subsets, BC5CDR-disease and BC5CDR-Chem. In the experiment, we split it into the recognition tasks of two entity categories, resulting in the loss of the relationship between the entity types in sentences.
The above excellent results are attributed to the fact that the model proposed in this paper can extract deep context word-level, local char-level, and part-of-speech features, so that the training of the word vector can better represent the grammatical and semantic information, thus improving the performance of entity recognition.
In this paper we proposed a method that fuses multi-feature embedding representations to represent words for named entity recognition in the biomedical domain. Enhanced semantic information representation of words is achieved by fusing deep contextual features, character-level local features, and lexical features of biomedical texts. Our presentation layer can help solve some problems in linguistics such as polysemy, semantics, out of vocabulary, and special entity within biomedical texts. Experiments are conducted to validate the model’s effectiveness proposed in this paper on eight datasets of four entity types in the biomedical domain. As a result, our model accomplished good performance on six BNER datasets.
Footnotes
Acknowledgments
This study was supported by the National Natural Science Foundation of China (Nos 61911540482 and 61702324) and the Shanghai Sailing Program (No. 21YF1416700).
Conflict of interest
None to report.