
Abstract
In this paper, we delve into the crucial role of constraints in maintaining data integrity in knowledge graphs with a specific focus on Wikidata, one of the most extensive collaboratively maintained open data knowledge graphs on the Web. The World Wide Web Consortium (W3C) recommends the Shapes Constraint Language (SHACL) as the constraint language for validating Knowledge Graphs, which comes in two different levels of expressivity, SHACL-Core, as well as SHACL-SPARQL. Despite the availability of SHACL, Wikidata currently represents its property constraints through its own RDF data model, which relies on Wikidata’s specific reification mechanism based on authoritative namespaces, and – partially ambiguous – natural language definitions. In the present paper, we investigate whether and how the semantics of Wikidata property constraints, can be formalized using SHACL-Core, SHACL-SPARQL, as well as directly as SPARQL queries. While the expressivity of SHACL-Core turns out to be insufficient for expressing all Wikidata property constraint types, we present SPARQL queries to identify violations for all 32 current Wikidata constraint types. We compare the semantics of this unambiguous SPARQL formalization with Wikidata’s violation reporting system and discuss limitations in terms of evaluation via Wikidata’s public SPARQL query endpoint, due to its current scalability. Our study, on the one hand, sheds light on the unique characteristics of constraints defined by the Wikidata community, in order to improve the quality and accuracy of data in this collaborative knowledge graph. On the other hand, as a “byproduct”, our formalization extends existing benchmarks for both SHACL and SPARQL with a challenging, large-scale real-world use case.
Introduction
A Knowledge Graph (KG) uses a graph-based model to represent real-world entities, their attributes, and relationships [40]. Entities are anything that can be uniquely identified and described, such as people, places, things, or concepts, but also the relationships between those. The “graph” metaphor stems from the idea of depicting statements representing relationships between entities as directed graph edges. A wide range of information can be represented using KGs, including encyclopedic knowledge, scientific data, corporate data, and, – along with meta-information attached to statements – also contextual information, such as who provenance, preference amongst statements, or temporal context (e.g. when a statement was added, so-called transaction time, or was valid, called validity time, cf. e.g. [30,61]). The Semantic Web initiative within the World Wide Web Consortium (W3C) has established a set of essential standards, readily available to manage and process KGs:
the Resource Description Framework (RDF) [54] to publish and interchange KGs; the SPARQL Protocol and RDF Query Language [32] to query KGs; RDF Schema (RDFS) [15] and the Web Ontology Language (OWL) [37] to define and describe the schema of KGs in RDF itself; the Shapes Constraint Language (SHACL) [29,41] to validate KGs.
The goal of said standards is to enable interoperability, but also the ability to unambiguously describe the (allowed) schema and semantics of knowledge graphs, which in turn is a crucial aspect in order to maintain KG quality, as more and more KGs are published in a decentralized, collaboratively created fashion across the Web.
Since its creation by the Wikimedia Foundation in 2012, Wikidata has become one of the largest such KGs, publicly available on the Web, with more than 100M items1
In terms of supporting the above-mentioned Semantic Web standards, the Wikidata KG is available in standard RDF format and can be queried via a public SPARQL endpoint. Yet, Wikidata does neither adhere to OWL/RDFS, nor SHACL: while other knowledge graphs often have predefined formal ontologies or schemas defined in RDFS and OWL, Wikidata takes a different approach, with its community focusing on the development of the data layer (A-box) and the terminology layer (T-Box) evolving alongside with it. This means that Wikidata does not have a single, pre-defined formal ontology [50] adhering to RDFS/OWL’s well-defined semantics. In fact, while some Wikidata properties, such as subclassOf (P279) or subproperty of (P1647), loosely correspond to constructs of the OWL and RDFS vocabularies [31], Wikidata does not make any formal ontological commitment on these properties in terms of OWL’s Description Logics based semantics, and the respective properties are rather freely used and usable by the community. Rather, in order to reinforce consistent usage of the community-developed terminology, separate Wikidata projects have emerged to specify constraints, which serve as a means to identify errors in the data layer wrt. vocabulary usage. However, none of these projects deploys the current W3C recommendation for validating RDF graphs against constraints, namely, SHACL.
In the current paper, we focus on the largest and most widely supported amongst these constraints approaches in Wikidata, namely the Wikidata Property Constraints Project:3
When it comes to how property constraints should be interpreted/checked, there is a description in natural language for each constraint type available on a respective help page, for instance, the single-value constraint (Q19474404).4
In the present paper, we explore the use of both SHACL and SPARQL as tools for formalizing Wikidata’s property constraints; the use of these standardized tools should provide more accurate, open, and efficient means of identifying and addressing inconsistencies in Wikidata and resolving potential ambiguities. To this end, our main contributions are as follows:
We provide a gentle and comprehensive introduction to Wikidata’s specific, namespace-based RDF reification model with many illustrative examples, that show how Wikidata’s wide range of different property constraints are represented using this model.
We study to what extent the expressiveness of the SHACL-Core language is sufficient to express Wikidata property constraints and come to the conclusion that the SHACL-Core language is not expressive enough to represent all Wikidata property constraints: Among the 32 investigated property constraint types, SHACL-Core lacks components to express two of them. In addition, we argue that another four constraint types are not reasonably, or only partially expressible.
For the Wikidata property constraints expressible in SHACL-Core, we present a tool to automatically translate such constraints; the tool can benefit also other Wikibase KGs that import Wikidata property constraints.
We show how the non-SHACL-Core-expressible remaining constraints can be formalized in full SHACL (using the SHACL-SPARQL extension), and argue for an, in our opinion more effective, formalization in SPARQL alone.
We consequently unambiguously formalize all 32 Wikidata property constraint types as SPARQL queries which provide a declarative means to express constraints, directly operationalizable via Wikidata’s SPARQL endpoint.6
Notably, as it turns out, some constraint types can only be partially evaluated online due to incomplete RDF representation of Wikidata’s own RDF data model on Wikidata’s SPARQL query endpoint.
We present a comparison of our SPARQL approach to the current Wikidata violation reports, demonstrating the feasibility of using SPARQL to actually check constraints: particularly, we highlight potential ambiguities and reasons for deviations in violations found with our approach compared to the Wikidata violation reports; we believe that our approach as such helps clarifying such ambiguities in a reproducible manner.
We note that, due to the known scalability limits of Wikidata’s SPARQL endpoint, we still run into timeouts in checking some of the most violated constraints; yet we argue that our work, can be understood as providing challenging benchmarks for both (i) SHACL validators and (ii) SPARQL engines, based on the real-world use case of Wikidata; as such we extend and go beyond recent related benchmarks.7
For instance, our constraint checking queries are not restricted to “truthy” statements, as opposed to the recent WDbench [6] SPARQL benchmark.
The remainder of this paper is structured as follows. Section 2 presents an exhaustive, tutorial-style introduction to Wikidata’s property constraints, diving into Wikidata’s RDF meta-modeling, and explaining how property constraints are represented within this model.
Section 3 discusses how to represent the semantics of Wikidata property constraints in SHACL-Core. We also present wd2shacl, a tool that automatically generates expressible SHACL constraints from Wikidata property constraints, and as such could be viewed as a “benchmark generator” for SHACL motivated by a real use case.
Yet, as not all Wikidata property constraints are expressible in SHACL-Core, in Section 4 we instead present a complete mapping of all Wikidata property constraints to SPARQL: we argue that SPARQL can be used for operationalizing all property constraints’ verification continuously, directly on the Wikidata SPARQL endpoint.
As a demonstration of feasibility, we present a detailed analysis and experiments, comparing violations found by our approach with the officially reported constraint violations by Wikidata itself in Sections 5 and 6.
Finally, after discussing related works on constraint formalization and quality analysis for Wikidata and other KGs in Section 7, we conclude in Section 8 with pointers to future research directions.
As mentioned already in the introduction, standard ontological inference as a means to detect inconsistencies is not directly applicable to the approach taken by Wikidata. Firstly, Wikidata’s data model may arguably be described as extending RDF’s plain, triple-based model, by various meta-modeling features for adding references and other contextual qualifiers to statements. Indeed, Wikidata’s data model is mapped to RDF via a specific reification mechanism. Secondly, there is neither a strict distinction between the data and terminology layers nor does Wikidata’s terminology rely on OWL/RDFS [31]. Rather, the terminology layer evolves in the background as editors add/update new facts, potentially introducing new properties and classes in a community-based approach. Additionally, proprietary, community-driven, ad-hoc processes have been set up within Wikidata to define constraints on the terminology used. In particular, the Property Constraints project,8
In order to provide the required background, in the following subsections we introduce the RDF data representation adopted by Wikidata (Section 2.1) with several examples, followed by illustrating details of how Wikidata’s property constraints are represented within this data model (Section 2.2), in particular focusing on qualifiers used as “parameters” for constraint definitions (Section 2.3). Finally, we discuss both (i) challenges in understanding the exact meaning of these property constraints (the semantics of which are largely described in natural language only), as well as (ii) potential issues in verifying them on Wikidata’s RDF representation (Section 2.4).
In this section, we describe how Wikidata’s data model – and specifically property constraints – are modeled in RDF and can be queried with SPARQL.9
For details, we refer the reader to
To this end, let us start with the bare basics of RDF and SPARQL and then gradually dive into the specifics of Wikidata. When talking about RDF, as usual, we will refer to RDF graphs and their subgraphs as sets of triples

Simple RDF (sub-)graph example from Wikidata, showing two statements/triple, indicating that Lionel Messi (URL:
The most important namespaces used in Wikidata’s RDF representation; we omit some additional standard namespaces such as dct: (Dublin core terms), schema: (Schema.org), rdf: (RDF), owl: (OWL), etc
Here, URIs are represented as namespace-prefixed identifiers, e.g. wd:Q615 which should be understood as a shortcut for a full URI, e.g. ⟨

For queries over RDF data, we will use SPARQL [32]: indeed the RDF representation of Wikidata can be fully queried by means of Wikidata’s SPARQL query service. Wikidata’s query service.,10
available at
Here, the triple pattern
Note that, interestingly, the query from above also returns
Other methods, apart from Wikidata’s query service to access RDF from Wikidata include complete RDF dumps12
cf.
For instance, supporting content negotiation, the result of running
Statement nodes: Wikidata’s internal data model heavily relies on meta-modeling, i.e., claims such as the ones represented by the triples in
In a nutshell, a dataset speaks “authoritatively” about a URI, or likewise a namespace prefix, if it is published/accessible on the same pay-level-domain. I.e., for instance, Wikidata is authoritative for all URIs (and, resp., namespaces) which start with

Subgraph example from Wikidata. Direct claims can be stated (using wdt), while metadata is added through qualifiers (using pq). Statement ranks use the property Wikibase:rank.
In this reification model, Wikidata uses URIs that represent hashes for “anonymous” reified statement nodes and quantity value nodes as illustrated in our examples in the following: for instance, Fig. 2 shows a more complete graphical illustration of Wikidata’s RDF model including meta-information about Messi, adding such statement nodes, which yields the following set of triples G:
As a side note, let us emphasize that Wikidata’s use of such “hashed” statements nodes is a deliberate choice to avoid the use of blank nodes [39].15
cf.
Entities: Items and properties, and lexemes In principle, any concept in Wikidata is an entity, such as real-world entities, but also properties, classes, or specific property constraint types; entities can be directly referred to as subjects or objects in statements via the namespace wd:. Entities are further subdivided into Properties, and Items which – rather than by prefix – can be distinguished by their numeric identifiers:
Besides Items and Properties, since a large part of Wikidata is also specialized in linguistics knowledge and multilinguality, another special kind of entities, so-called Lexemes, i.e., words with their senses and forms in particular different languages, are identified by separate
Claims and statements: Claims made about entities are represented as “flat” RDF triples and use Properties in the predicate position with the namespace wdt:, such as the triples in
Such direct claims can be further described and annotated with meta-information. That is, for each claim, a separate, wds:-prefixed statement node is created in Wikidata’s RDF graph, which permits to refer to the claim itself in meta-statements, such as for instance declaring since when Messi has the Argentinean citizenship. These statement nodes are connected to the claim’s subject entity via the claim’s property using prefix p: instead of wdt:; additional meta-information about statement nodes uses specific so-called qualifier properties, denoted by the prefix pq:, and the statement node itself is connected back to the claim’s object via the claim’s property using prefix ps:.
Fig. 2 presents a subgraph of Wikidata that illustrates this RDF representation, containing two claims about Lionel Messi (Q615), concerning his two nationalities and their different respective start time (P580) as qualifiers of the respective claims’ statement nodes. We will explain the additional wikibase:rank triples also visible in the next figure.
Statement ranks and truthy statements: Note that not all statements in Wikidata are represented as directly queryable wdt: claims, the reason being that statements may be marked as normal (wikibase:NormalRank), preferred (wikibase:PreferredRank), or deprecated (wikibase:DeprecatedRank), via the special “statement-rank” (wikibase:rank) property. While in Fig. 2, both claims have rank wikibase:NormalRank, i.e. denoting equally valid – so-called “truthy” claims, let us provide another illustrating example to show a different setting.
Fig. 3 shows two claims about the capital of the US, one of which (the current capital) has a wikibase:PreferredRank, while the other has wikibase:NormalRank: when you compare both figures, note that in presence of a wikibase:PreferredRanked statement, only this preferred statement has a direct, i.e. “truthy” wdt: triple. Intuitively, in this example, this makes sense, as it allows us to write simple SPARQL queries to Wikidata’s query service, asking for the capital (P36) of the USA (Q30) just with:
which will only return the current capital, whereas if we wanted to query for all past and present capitals, we would need a more complex query using a path expression:

A subgraph showing claims about two capitals (P36) of the USA (Q30) and their start and end times. According to a single-value constraint on P36, multiple values are allowed as long as they have different values for start time (P580) (and other so-called “separators”, not shown here).
Note that similarly, wikibase:DeprecatedRanked statements (which we do not illustrate at this point in a separate example, but which we will get back to later) do not have a wdt: claim in Wikidata’s RDF representation. Following the intuition that only preferred, non-deprecated, normal ranked statements without an “overriding” preferred statement are represented as wdt: triples, these wdt:statements are also called “truthy” statements in Wikidata terminology.
Quantity values: quantity values such as numbers, dates, etc. are represented in Wikidata – yet again different to RDFs typed literals – using a similar, specific reification mechanism, referring to properties using the separate namespace psv: to refer to quantity values, which can have an amount and unit, referred to by special wikibase: properties.
References: references can be given for any claims, where all such references are referred to with the prov:derivedFrom property. Similar to quantity values, reference nodes are represented by hash values in a separate namespace (wdref:), which can be further described with property-value pairs, using reference properties – identified by yet another separate namespace (pr:).
The upper half of Fig. 4 illustrates the modeling of quantity values in Wikidata, in this case about Lionel Messi’s height. The lower part of the figure illustrates another heavily used feature of Wikidata, namely references: the property “reference URL” (pr:P854) is used to provide a reference source for the quantity claim, in the form of a URL that reported Lionel Messi’s height.

A subgraph containing a quantity claim about the height (P2048) of Messi, and a reference for this claim. According to an allowed-units constraint on P2048, centimetre (Q174728) is an allowed unit for this property.
Labels and descriptions: strings used to name or describe entities, i.e., Items, Properties, or also Lexemes, in different languages, are denoted in Wikidata’s RDF dump by language tagged literals, using the reserved properties rdfs:label and schema:description, respectively.
Figure 5 illustrates labels and descriptions, where English, Spanish, and Arabic labels and descriptions for Item Q615 (Messi) are shown.

A subgraph illustrating additional RDF triples for representing (multi-lingual) labels and descriptions of Wikidata entities, leveraging RDF’s language-tagged literals.
Special statements about lexemes: linguistic knowledge about lexemes plays a key role in Wikidata, and uses a yet again dedicated representation; as a final example, we present a subgraph about the lexeme “football”, involving its senses (ontolex:sense) and lexical forms (ontolex:lexicalForm).
As illustrated in Fig. 6, the lexeme football (L6458), is an English noun, with different senses – such the team sports (L6458-S1) and the physical object (L6458-S2) – and forms – such as its singular (L6458-F1) and plural (L6458-F2) forms.
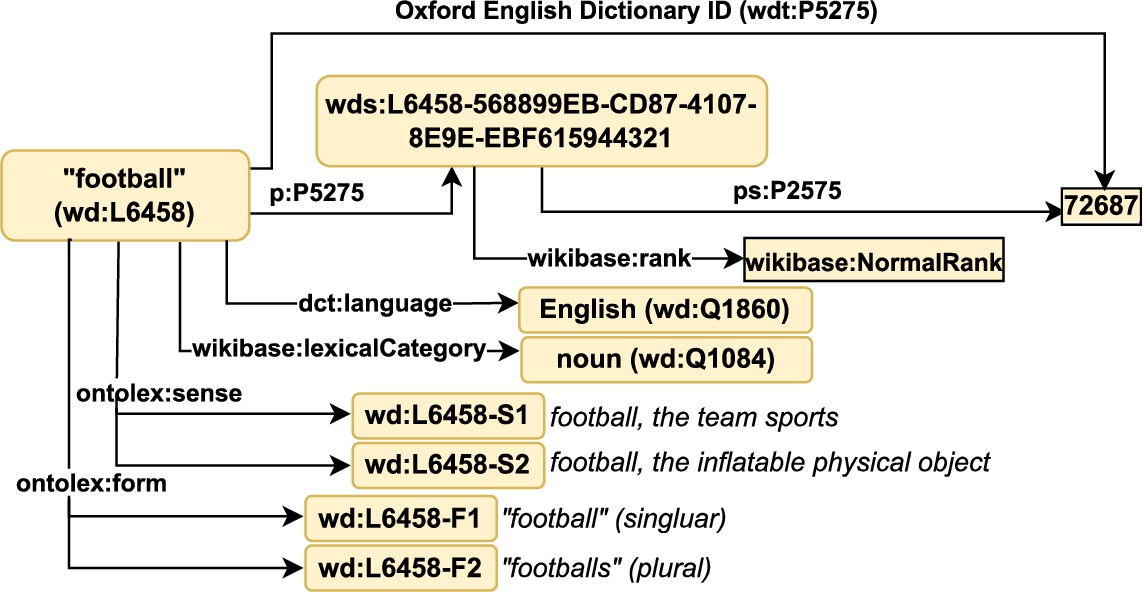
A subgraph about the English noun “football”, including normal claims, but also Wikidata-specific additional vocabulary to talk about languages.
As we can see in the example, lexemes can be involved in normal (wdt:) statements as discussed before, such as carrying external identifiers in particular dictionaries, but also involve lexeme-specific statements for identifying the language (dct:language), category (wikibase:lexicalCategory) and lexicographic forms and senses (prefix ontolex:). Note that these extra statements have no statement nodes nor qualifiers, somewhat deviating from the standard Wikidata statement model. Also observe, as opposed to language-tagged literals for labels and descriptions, these special statements about lexemes represent the language explicitly as an item (in our example Q1860 for English).
Figure 7(a) summarizes the modeling of regular statements and ranks, including the involved namespaces, in a more abstract manner. As shown in Fig. 7(b), the RDF model contains also triples to “navigate” between the differently prefixed URIs per property ID (PID); we will need to make use of these connections in our modeling of constraints in SHACL and SPARQL later on, but let us first turn to how these constraints themselves are actually represented within RDF model.

The Wikidata meta-model in RDF and its namespaces usage illustrated for (a) statements and claims, (b) properties, and (c) property constraint definitions. Dashed lines represent equivalent entities. Figures 2 and 3 illustrate concrete instantiations of the “Wikidata Statement” block (a), while Fig. 8(c) illustrates the block “property constraint definition” block (c). Abbreviations: QID = entity ID, PID = property ID.
Wikidata property constraints make use of the described modeling to represent specific community-defined constraint types, where specific instantiations of a constraint type are defined as qualified statements on a particular property that should fulfill this constraint. To date, Wikidata represents
Wikidata property constraints types: incl. information about their usage in constraint definitions, information about whether and how we could express them in SHACL-Core and SPARQL, as well as which qualifiers they use (verified on the status at the writing of the paper using a variation of this query: https://w.wiki/7KrH ; the short links in the SPARQL column refer to our direct links into our Github repository, available at https://github.com/nicolasferranti/wikidata-constraints-formalization/ : besides the SPARQL formalizations you also find all corresponding SHACL shapes (where expressible) there
Wikidata property constraints types: incl. information about their usage in constraint definitions, information about whether and how we could express them in SHACL-Core and SPARQL, as well as which qualifiers they use (verified on the status at the writing of the paper using a variation of this query:
(Continued)

Example of a Wikidata property constraint and data graphs with different behaviors (as of 2022-03-29).
Whereas each constraint type is modeled as an item – for instance, the item-requires-statement (IRS) constraint (Q21503247), such constraint types are instantiated and parameterized specifically per property. That is, each such instantiation is defined by a constraint-definition-statement linked to the respective constrained property P via the property constraint (P2302) property, as illustrated abstractly in Fig. 7(c).
In terms of parameters, constraint-type specific property qualifiers are used on the constraint-definition-statement: the overview in Table 2 list all property qualifiers that can be used per constraint type, as well as the number of different properties that use each constraint type (from February 2023).
For instance, the item-requires-statement (IRS) constraint type (Q21503247), is used to specify that each item with the constrained property P should also have another given property
property (P2306), defining the required additional property
item of property constraint (P2305), which, if provided, contains permitted values for
Fig. 8a illustrates how these qualifiers are concretely instantiated for an IRS constraint the property P = P1469, FIFA player ID: this instance of IRS constraint states that if an item has a FIFA player ID (P1469), this very same item should also (i) have an occupation (P106), (ii) with one of the following four items: association football player (Q937857), futsal player (Q18515558), beach soccer player (Q21057452), or association football manager (Q628099); (i)+(ii) are defined through the resp. qualifiers P2306+P2305 specific to the particular constraint type. That is, firstly, the triple
connects the property FIFA player ID (wd:P1469) to its constraint-definition-statement via the property property constraint (P2302).
Further, the IRS-specific qualifier property (pq:P2306) is bound to occupation (wd:P106) through the triple:
whereas the respective allowed values are defined via four additional triples using the item of property constraint (pq:P2305) qualifier, similarly illustrated in Fig. 8a.
Figures 8b and 8c presents data subgraphs for two different items, Messi (Q615) and Thiago Neves (Q370014): both have a FIFA player ID but only the first one complies with the IRS constraint, having a valid occupation, whereas the second one violates it.
As a second example, let us look at another constraint type, the so-called single-value constraint (Q19474404), which imposes that property P is only allowed to have one single value unless there are different values for at least one separator, parameterizable by the separator (pq:P4155) qualifier.

Another example of a Wikidata property constraint and data graphs (as of 2022-08-20).
As illustrated in Fig. 9, the property P = P36 (capital) instantiates a single-value constraint (Q19474404). As shown in Fig. 9a, several separator (pq:P4155) qualifiers can be declared as parameters, only one of which needs to differ, in order to fulfill the constraint, despite non-single values for P. The item USA (Q30), shown in Fig. 3, therefore complies with this constraint since the two capitals have different start times (pq:580). Figure 9 also illustrates, another “feature” of property constraints modeling in Wikidata, exceptions, which we will turn to next.
Exceptions to constraints Using the dedicated qualifier property exception to constraint (P2303), an instantiation of a constraint on a specific property can explicitly mention exceptions. These are items which, for various reasons may be valid, despite violating the constraint.
The single-value constraint on P36 in Fig. 9a, lists (amongst others) the Canary Islands (wd:Q5813) as an exception of the single-value constraint on capital (P36), since it has two co-capitals. Therefore, the data graph in Fig. 9b should, while not complying with the constraint, be considered an “allowed” violation.
We hope that the previous subsection has sufficiently illustrated the most relevant aspects of modeling and parameterizing property constraints. Rather than in terms of fully elaborated examples, let us summarize all mentioned and remaining qualifiers used in the context of constraint modeling and parameterization in the following. To this end, Table 2 provides an overview of which qualifiers are used in current descriptions of constraints of different types. For each of the used qualifiers, we will provide a description of how they are used in the context of the different constraint types listed in Table 2, along with specific constrained properties P, also mentioning concrete usage examples. We present these qualifiers in three overall groups:
(Section 2.3.1), which are essential for modeling the semantics of constraints and for verifying them; i.e., these will be essential for our formalization in SHACL and SPARQL. (Section 2.3.2), which essentially mark concrete items as exceptions to constraints or deactivate whole constraints, that do not need to be verified. (Section 2.3.3), which have no semantic relevance for formalizing the (verification of) constraints as such, but serve other, mostly descriptive purposes.
Core constraint qualifiers
Case 1: P itself, or Case 2: another path Usage examples: Besides our IRS constraint from Example 6 above, where P2305 is used to set to Usage example: the property Spotify user ID (P11625) uses a format constraint (Q21502404) to restrict its value to conform to the specific regular expression “[a-z∖d_.-]+”, matching sequence of one or more characters that can be lowercase letters, digits, underscores, periods, or hyphens. a label (i.e., the path a description (i.e., Usage example: the property Library of Congress authority ID (P244) uses a label in language (Q108139345) constraint to ensure subjects have an English label. As an interesting side observation, we note that the similar-in-spirit lexeme requires language (Q55819106) constraint rather uses the item of property constraint (P2305) qualifier to specify the required language, inline with the different modeling of languages for labels and descriptions vs. lexemes, illustrated in Figs 5 and 6. Usage examples: as an illustrating example we have already discussed the separator qualifier’s use in single-value (Q19474404) constraint, such as the instantiation on the property capital (P36) from Fig. 9: here, multiple values are allowed as long as they have different combinations of the start time (P580) and end time (P582) qualifiers.16 We note that the actual definition of the single-value constraint on P36 on Wikidata lists even more separator properties.
Usage examples: as an example for Case 1, the one-of constraint (Q21510859) on the property sex or gender (P21) uses qualifier P2305 to declare a list of allowed genders. Example 6 provides an instance of Case 2, where the item requires statement (Q21503247) constraint restrict the values of property
for the subject items of constrained property P in a particular language.
I.e., note that P2309 is itself restricted by a one-of constraint, which restricts values of a property to single values of an enumeration.
Usage example: For instance, property date of birth (P569) has a subject type (Q21503250) constraint, defining that the subjects of this property should be an instance of (Relation) human (Q5), fictional character (Q95074), or other “classes” of living beings. Here, according to the description of the subject type property constraint,18
Usage examples: As an example, the property atomic number (P1086), representing the number of protons in an atom’s nucleus, has a range constraint limiting the values between 0 and 155 using the P2313 and P2312 qualifiers. Likewise, a difference-within-range constraint can be found on property P = P570 (date of death) to be within
year (Q577) is again a type of quantityUnit in Wikidata, similar to the “centimetre” unit mentioned in Fig. 4. While we do not detail unit conversion with SHACL and SPARQL, or likewise, interval duration computation between dates in the present work, we refer to preliminary work under submission for the Wikidata 2023 workshop [60] that points in this direction, proposing a resp. query rewriting approach.
Case 1: “as main values”, i.e. using the namespaces for claims (p:, and for truthy statements (wdt:) Case 2: “as qualifiers”, i.e. using the pq: namespace Case 3: “as reference” (i.e., only in reference statements about claims, identifiable via the pr: namespace
Usage example: the property reference URL (P854) – which we saw used in Fig. 4 – uses a property scope constraint, scoping this predicate to be always be used as reference, i.e., exclusively with the pr: prefix.
Usage Example: cf. Fig. 9 above; In principle this qualifier is applicable to all constraint types, i.e., all constraints could list such exceptions, as we can see in Table 2 (last column) though, not all qualifiers have exceptions (i.e., we did not find usage of this qualifier in all constraint types). Just like any other “regular” claims about Items, constraint-definition-statements about Properties also have a wikibase:rank; notably, at the time of writing, we found 5 constraint definitions using qualifier P2241, while actually having a non-deprecated rank, cf.
Usage Examples: Previously, entities having place of birth (P19) should also have sex or gender, but currently, this restriction is deprecated, with reason Q99460987 (“constraint provides suggestions for manual input”): constraints of this nature should not be checked or enforced, since the constraint should be rather interpreted as a suggestion than enforcing/restricting certain values.
Usage Example: for instance, for the property population (P1082) a group by qualifier specifies that violations for the allowed qualifier (Q21510851) constraints should be grouped by country (P17), as visible in in Wikidata’s database reports.21
Notable, at the time of writing, there were 17 property constraint definitions with a different status, cf.
Usage Example: For example, the subject type constraint on property academic degree (P512) states that it is mandatory, that all the subjects be an instance of human, fictional character, or person. On the contrary, the above-mentioned subject type constraint on date of birth (P569), does not have an explicit status (and therefore should be considered a “normal” constraint).
Usage Examples: For instance, a none-of constraint (Q52558054) for country of citizenship (P27) lists several “Pokemón regions”, such as Kanto (Q1657833), that should not be used, where the additional P6607 clarifies that “It’s not always clear in Pokémon canon if regions are part of a larger country or are countries in and of themselves.”
Usage Example: for instance, the property country (P17) uses a conflicts-with constraint, in combination with item of property constraint (P2306) qualifiers listing values
musical group (Q215380) musical ensemble (Q2088357) musical duo (Q9212979) musical trio (Q281643)
stating that entities that are instances of these values24
i.e., additionally using qualifier property (P2305) restricting
Interestingly, other sub-types of musical ensembles, such as string quartet (Q207338) are not explicitly listed in this conflicts-with constraint.
The above summary of the used qualifier properties to parameterize constraints should have illustrated that the semantics of Wikidata’s vocabulary used to describe constraints are not always uniquely determined: indeed, the interpretation of constraint qualifiers depends on (i) in which context (ii) in which particular combination with other qualifiers, they are used (iii) in particular constraint types.
Before we continue in Section 3 with more details on how these qualifier properties are interpretable as parameters in SHACL-Core shapes for verifying different constraint types, let us discuss some additional challenges that potentially complicate these formalizations, and motivate our idea to design bespoke translations per constraint type.
The above description of Wikidata property constraints modeling in RDF defines how constraints are represented but not how they should be checked. To understand how to check constraints, a description property (schema:description) is provided along with the described at URL (P973) property, indicating a link to a page that describes the constraint. The vast majority of Wikidata constraint types (more precisely, 28 out of 32) have such a “Help”-page .26
The description page of our running example item-requires-statement is available at
It is important to note here that the Wikidata community has defined all existing property constraint types in a manner where these types and their modeling have grown organically. In our formalizations of such constraints, we tried to stay as close as possible to the – partially heterogeneous – interpretations derivable from the natural language descriptions of constraint types. We could find and document several cases of textual ambiguity, leaving room for different interpretations and as a result, for different implementations of the respective constraint checks. We illustrate some of these issues.
Let us first note that in Wikidata constraint type descriptions, it is rarely explicitly/uniformly specified whether subclass of (P279) relationships should be interpreted transitively, or whether instance of (P31) relationships should also affect instances of (transitive) subclasses.
Indeed, some of these constraints resemble known RDFS axioms: for instance, the subject type constraint (Q21503250) is logically equivalent to the constraint reading of an rdfs:domain statement, which intuitively poses restrictions on the entities allowed in the domain of the property P. Analogously, the value-type constraint (Q21510865) resembles rdfs:range.
For instance in our formalizations of the subject type constraint (Q21503250), and likewise the analogous value-type constraint, we took a choice interpreting the relationship (pq:2309) instance of (Q21503252) as a property path wdt:P31/wdt:P279*, i.e., including transitive “subclass of”-reasoning. Note this is similar to the RDFS encoding by query rewriting in [11]. This particular interpretation was driven by the following natural language description on a separate Help-page for Q21503250:27
“Subclass relations according to subclass of (P279) are taken into account: if a constraint demands that an item should be an instance of building (Q41176), it is not a violation if the item is an instance of skyscraper (Q11303), because there is a subclass of (P279) path from skyscraper (Q11303) to building (Q41176). (If an indirect relation should not be permitted, item-requires-statement constraint (Q21503247) can be used.)”
The interested reader might have noted the last sentence in parentheses, which indirectly informed our respective interpretation of IRS constraints (Q21503247). Here we did
This potential issue is, by the way, not restricted to IRS constraints, cf. Footnote 25 on p. 2349, which illustrates a similar questionable example for the potential non-consideration of subclass-inferencing in the context of a conflicts-with constraint.
Along these lines, similar issues of interpretation may arise, in the context of (sub-)properties (P). Recall the allowed qualifiers constraint (Q21510851) states that when using a particular property, only a limited set of properties can be used as qualifiers through the reification mechanism: for instance, the capital (P36) property has an allowed qualifiers constraint permitting start time (pq:580) and end time (pq:582) qualifiers.
Yet, the claim that Stralsund (Q4065) was the capital of Swedish Pomerania (Q682318) until 1815 is considered a violation of this constraint since the temporal range end (P524) qualifier is used to mark the end of the period. The Wikidata UI reports a violation, although P524 is a subproperty of P582, i.e.,
We consequently do not consider (transitive) subproperty relationships in our formalization, in line with the observed behavior within Wikidata: indeed, although subproperty of (P1647) is semantically similar to subclass of (P279) when it comes to the hierarchy of properties, the page that describes the allowed qualifiers constraint29
The description page for single-value constraint states:30
“specifies that a property generally only has a single value. […] A qualifier can be defined as a separator (P4155). This allows for multiple values when using such qualifiers. […] If specified, multiple statements with the same value do not constitute a violation of this constraint as long as they have different qualifiers for the properties specified here.”
Values to be considered different if they use different values for all (common) qualifier properties.
Values to be considered different if they use different values for some (common) qualifier.
It is arguable whether we should consider exceptions – marked as Exception to the constraint (P2303) – in our formalisation: while exceptions are indeed not marked as violations in the UI, we cannot for sure determine whether they are counted in the Wikidata Database Reports: the reports only contain aggregated counts of constraint violations, but not all single violations are linked from the database reports pages. We will therefore discuss handling of exceptions as an optional “feature” in our formalization.
Deprecated Constraints are, interestingly, still being tested and reported by Wikidata’s Database Reports; likewise, no distinction is made on the constraint status – denoted by constraint status (P2303) – in the reports; our formalization therefore will consider violations independent of their status. As an interesting side note, we refer to the fact that there are various constraint definitions that report a reason for deprecated rank (P2241) while the constraint definitions themselves have a non-deprecated rank. 20 We consequently decided not to treat deprecated constraints, nor constraints with a non-normal status in any special way in our formalisation.
Differences in Wikidata RDF serialization
Another remarkable finding arose for us when taking a closer look at allowed entity types (Q52004125) constraints; as per its description, this type of constraint limits the subject of a respective property to certain listed entity types, such as:
Wikibase Item (
Wikibase property (
Wikibase MediaInfo (
Lexeme (
Sense (
Form (
Wikidata Item (
Notably, though, these types can only be partially checked, depending on the RDF serialisation, for various reasons:
incoherent serialisation with respect to different entity types;
differences between RDF serialisations on the SPARQL endpoint vs. RDF dumps;
checks requiring unintuitive workarounds
Incoherent serialisation with respect to different entity types : neither the entity types that are part of the Wikibase base ontology (
returns over 10000 results (apparently covering all properties), on the other hand, the query
returns 0 results on the Wikidata SPARQL endpoint.
Differences between RDF serialisations: In addition, interestingly, there are apparently even differences in Wikidata’s RDF serialization via RDF dumps (cf. Footnote 12) vs. the RDF triples served on the public SPARQL endpoint. For instance, as manually verified, Wikidata’s RDF latest N-Triples RDF dump did not contain any triples using the
For instance, the SPARQL endpoint returned over 13M instances of
Checks requiring unintuitive workarounds The documentation of Wikdata’s query service32
Indeed, these subtleties and incoherence within Wikidata’s RDF serialization(s) make it hard to define generic parameters to test allowed entity types constraints automatically, forcing case-by-case implementations (either in terms of SHACL shapes or in a SPARQL query), depending on whether working on the SPARQL endpoint or on Wikidata’s RDF dump.
In the context of this paper, we have designed both our SHACL-Core formalization (cf. Fig. 12 below) of allowed entity types (a)s well as the respective SPARQL query (cf. the query referenced in first line of Table 2) to conform with the data available in the Wikidata query service, implementing all documented workarounds.
In summary, all of these examples and issues should motivate the following disclaimer: the SHACL-Core shapes and SPARQL queries proposed in this paper were created from the available descriptions and aim to reduce the margin of interpretation in dealing with Wikidata constraints while keeping as close as possible to the documented interpretations. As such, all our SHACL and SPARQL formalizations discussed in the following Sections 3 and 4 (and linked from Table 2) reflect our best-effort interpretations of the respective natural language definitions. Yet, the goal and scope of our work is to contribute to these interpretations in an unambiguous, declarative manner.
In this section, we will present Wikidata property constraint types in terms of SHACL shapes, i.e., deploying the official W3C standarised language to express constraints on RDF graphs.
To this end, we will first provide some necessary background on RDF and SHACL, introducing some notions that will be useful in the rest of the section (Section 3.1), whereafter we will dive into details of formalization and expressibility of particular Wikidata property constraint types (Section 3.2), again mostly driven by examples; for a full list of SHACL formalizations per constraint type, we refer to Table 2.
SHACL validation
The SHACL standard specifies constraints through so-called shapes, which are to be validated against an RDF graph. SHACL shapes themselves are represented as RDF Graphs, and may contain a wide variety of constraint components that allow the construction of possibly complex expressions to be checked over the input data. As usual in the majority of the SHACL works, in this paper, we focus on the core constraint components of SHACL and refer to it as SHACL-Core; an extension to this core language that allows the addition of full SPARQL queries for constraint checking will be introduced later, in Section 3.4.
A shapes graph contains shapes paired with targets specifying the focus nodes in the RDF graph that should be checked for validation. In a nutshell, an RDF data graph validates a shapes graph if these targets conform with the constraints specified in the corresponding shape. We illustrate these notions with a first example of a shapes graph implementing an item-requires-statement constraint type.
The shapes graph in Fig. 10a describes the shape :P1469_ItemRequiresStatementShape, which defines its targets as nodes in the subject of the wdt:P1469 property (line 3), that is, nodes that have a wdt:P1469-outgoing edge. Intuitively, a data graph validates this shapes graph if each target node has at least one wdt:P106-edge to one of the nodes (constants) listed in sh:in (lines 7 and 8).
Consider the RDF graph represented by Fig. 8b:33
Note that the nodes and edges are labeled with both names and their (namespace-abbreviated) URIs, but we assume the corresponding RDF graph is implicitly clear to the reader.
This is not the case for the RDF graph in Fig. 8c, since Thiago Neves has only one occupation-edge to a node that is not listed in the constraint. However, this second data graph validates the shapes graph shown in Fig. 10b: toughly speaking, this variant of the original shape relaxes the constraint with an additional
Overall, the shapes introduced in Example 9 define exactly the intended semantics of the item-requires-statement constraint represented in Fig. 8a, where we already give a hint, that even optional exception handling can be easily expressed in SHACL-Core.

SHACL shape item-requires-statement constraint for the (a) FIFA player ID (wdt:P1469) and (b) a variant with exceptions.
The SHACL specification allows for shapes to refer to other shapes which may result even in cyclic references and recursive constraints. In this context, we note that the official specification only provides semantics for non-recursive constraints, therefore, in line with our goal, to create shapes with standard validators, we may consider it as a requirement to avoid such recursive shapes. Indeed, the shapes that we obtain in this paper are all non-recursive; the fact that current Wikidata property constraints apply locally (per Subject Item) and do not transitively or even recursively depend on the fulfillment of other constraints, plays in our favor: as our example shows, we can express an item-requires-statement, and as we will show most other constraint types, in single shapes.
The constructs defining a shapes graph can syntactically be viewed as concepts in expressive Description Logics [9], a well-known family of decidable fragments of first-order logic. That is, the shape components can be viewed as logical constructs, such as existential and universal quantifications, qualified number restrictions, constants, or regular path expressions. For instance, the shapes graph in Fig. 10a can be expressed as the tuple containing the target
Let us proceed to describe more systematically now, how Wikidata property constraints can be translated to SHACL-Core shapes.
The targets of property constraints in Wikidata are always the subjects of the resp. constrained property P, i.e., we can use uniformly use SHACL-Core’s
Constraint types requiring the existence of a specific statement, such as our running example’s item-requires-statement constraint (and, likewise required qualifier constraints, one-of constraints…), are naturally captured by SHACL-Core constraint components. Roughly speaking, these types of constraints can be represented by choosing a target node, verifying the existence of an
On the contrary, constraints forbidding certain statements, such as conflicts-with, or likewise property scope constraints can modeled analogously with a combination of

Further building upon and extending the discussion of Example 9, we discuss and illustrate translations to SHACL guided by the constraint qualifier properties to parameterize them in the following, where we go through the constraint qualifiers in the same order as in Section 2.3.
As noted in Section 2.3.1, the P2306 qualifier may also in the context of other constraint types, refer to more generic paths  where the listed allowed units in line 6 denote milimtre (Q174789), centimetre (Q174728), metre (Q11573), etc.
where the listed allowed units in line 6 denote milimtre (Q174789), centimetre (Q174728), metre (Q11573), etc.





This concludes the discussion of the treatment of core constraint qualifiers (Section 2.3.1) in our translation: essentially, we have created templates for each constraint type using SHACL-Core expressible constraint qualifiers. I.e., these templates can be instantiated with the respective qualifiers used as parameters in an automated fashion. Before we present a prototype implementing this automatic translation in the next subsection (Section 3.3), let us also briefly elaborate on the treatment of constraint exception qualifiers (Section 2.3.2) and descriptive qualifiers (Section 2.3.3), which, as we will see, also partially can be cast into respective SHACL-Core constructs.
 Yet, along the lines of our discussion in Section 2.4.3 above, where we remarked that Wikidata does not seem to make an explicit distinction between constraint statuses in its Database Reports, we also do not consider the constraint status (P2316) in our translation.
Yet, along the lines of our discussion in Section 2.4.3 above, where we remarked that Wikidata does not seem to make an explicit distinction between constraint statuses in its Database Reports, we also do not consider the constraint status (P2316) in our translation.

In summary, by “templating” the respective qualifier parameter translations from Wikidata’s constraint representation to SHACL shapes based on the illustrating above examples, we can cover most constraint types, and – additionally carry over also some useful descriptive information to dedicated SHACL-Core constructs, that are not strictly needed for validation as such, but can be used by validators to generate explaining output.
A prototype, reading constraint definitions in Wikidata’s representation and accordingly creating their shapes representation on-the-fly is presented in Section 3.3 below. Table 2 presents the entire set of analyzed constraint types, their Wikidata IDs, as well as a column to state whether it was possible to map the constraint type to SHACL (and SPARQL, respectively, see Section 4). The particular SHACL encodings, created by using the above-introduced “mappings” between Wikidata qualifiers and SHACL-Core components, can be found in an online GitHub repository accompanying our paper.35
In order to demonstrate the feasibility of an automated translation, we developed wd2shacl, a demo tool to automatically convert constraints from the Wikidata model to the corresponding SHACL shape (for those that could be represented). This allows for the creation of a large, real-world SHACL benchmark from Wikidata, thus also addressing the scarcity of respective benchmarks for SHACL-Core currently available. Wd2shacl allows testing Wikidata property constraints with SHACL validators and generates verifiable shapes for any Wikidata property, extracting its associated constraints.
In a nutshell, we first generalized the example SHACL shapes (such as the one in Fig. 10a to become templates for specific constraint types, e.g. by replacing the specific qualifier values assigned to a single property, illustrated by the following “template abstraction” for IRS constraints:

Our wd2shacl tool then populates these templates according to the actual qualifier values instantiated for a specific property P. The architecture of wd2shacl is shown in Fig. 11. As input, we provide the
Available at
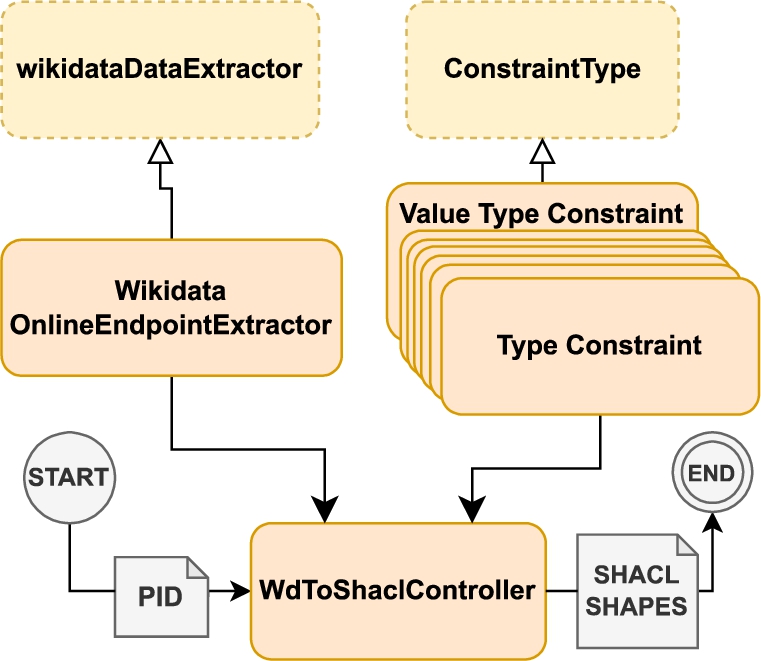
Wikidata to SHACL architecture. Dashed lines represent abstract classes.
After collecting constraint types and qualifiers for the input property P, the controller instantiates the template to create respective SHACL constraints for the extracted applicable constraint types. A specific class (a concrete subclass of ConstraintType) is implemented for each SHACL-expressible constraint type to create the SHACL shape by combining the template with the given qualifiers. The controller returns the populated SHACL templates as SHACL Turtle files, containing the required prefixes and a list of SHACL shapes, written using SHACL-Core language, for all the translatable constraint types associated with the input PID. The tool is freely available online within our GitHub repository.38
As shown in Table 2 the vast majority of Wikidata constraint types can be rewritten into SHACL-Core Shapes (26 out of 32); yet, three could only be partially translated, one cannot be expressed in a reasonable way, while for further two we did not find any way to express them in SHACL-Core at all. Let us discuss these, and the involved challenges in more detail:
difference-within-range (Q21510854): not expressible
allowed qualifiers (Q21510851): not reasonably expressible
allowed entity type (Q52004125): only partially verifiable
single-value (Q19474404): only partially expressible
distinct-values (Q21502410): only partially expressible
single-best-value (Q52060874): not expressible
Firstly, the difference-within-range (Q21510854) constraint requires the difference between two values to be calculated and compared to a predefined range. Despite SHACL-Core having components to check for equalities (
Next, the allowed qualifiers (Q21510851) constraint is also not directly/reasonably expressible in SHACL-Core. This constraint type specifies that only the listed qualifiers should be used when a certain statement is made, meaning that the use of all other qualifiers is disallowed. The problem here lies in the fact that SHACL-Core does not have direct means to query non-allowed paths (e.g. by referring to a path/property via a specific type).39
We leave it as an open question at this point whether there exists a more concise formulation in terms of more complex, possibly nested SHACL Shapes.
Don’t try this at home!
The allowed entity type (Q52004125) originally seemed easily expressible in SHACL-Core to us. However, as mentioned in Section 2.4.4, it needs a number of workarounds to be executable on Wikdata’s query service (and might not generalise to other Wikidata RDF serialisations). Figure 12 shows a respective translation of an allowed entity type constraint on the property object has role (P3831), restricting its subjects to the following entity types:
Wikibase item
Wikibase MediaInfo
Wikibase lexeme
Wikibase form
Wikibase sense
Wikibase property

SHACL-Core shape for verifying an allowed entity type (Q52004125) constraint on property object has role (P3831) , incl. workarounds defined in Wikidata’s query service documentation to check entity types missing in the RDF serialization (cf. Section 2.4.4).
The last three constraint types in our problematic list (single-value (Q19474404)) distinct-values (Q21502410), and single-best-value (Q52060874)) are those using the separator (P4155) qualifier. We recall from Section 2.4.2 this qualifier is difficult to express in itself.
On the contrary, it is straightforward to verify the uniqueness or difference of a property value with respect to the claimed subject in the absence of separators: as such, both (single-value (Q19474404)) and distinct-values (Q21502410) constraints are easily expressible in SHACL-Core, as long as they do not specify separators. We illustrate this with a simple single-value “shape” in Fig. 13a.

SHACL shapes encoding: from simple SHACL-Core shapes to the SPARQL formalization.
The scenario changes though when a separator qualifier property is introduced. According to both possible interpretations
To illustrate this, consider again the instantiation of the separator qualifier for the single-value (Q19474404) constraint on the property capital (P36) from Fig. 9. In order to not have to distinguish between
Therefore, the variants of all three, single-value (Q19474404)) distinct-values (Q21502410), and single-best-value (Q52060874) constraints which include separators cannot be represented in SHACL-Core. We additionally mention that, for analogous reasons, the single-best-value (Q52060874) constraint, used to specify that the property P shall only have a single value claim marked with wikibase:BestRank as wikibase:rank, is not expressible in SHACL-Core either, even without separators, due to a similar dependence on the rank.
We show in the next section how these remaining constraint types can be expressed with formalisms beyond SHACL-Core.
Beyond its core language, SHACL provides a mechanism to refine constraints in terms of full SPARQL queries through a SPARQL-based constraint component (sh:sparql). In order to illustrate this feature, we refer to Figs 13a and 13b: both these SHACL shapes have the same semantics, while the shape in Fig. 13a uses only SHACL-Core language components, the one in Fig. 13b uses the sh:sparql extension to state that only one value is expected by means of a SPARQL query (starting at line 6): here, the reserved variable
Figure 13c extends the SHACL-SPARQL shape the existence and – in case – equality of the start time (P580) qualifier, thereby implementing an extension towards handling a single separator.
However, as there may be several qualifiers, this shape is not sufficient. Figure 13d generalizes the SHACL shape to consider as violations entities that have qualifiers any with equal values, as such implementing interpretation
Towards SPARQL
In summary, we note the following limitations for the implementation of Wikidata property constraints via SHACL.
In summary, we observe that not all Wikidata constraints were possible to directly map as shapes in SHACL-Core.
Firstly, we can cover only a subset of SHACL-expressible Wikidata property constraints in SHACL-Core;
Secondly, our approach introduced so far instantiates separate SHACL shapes for each property constraint definition, even if we used SHACL-SPARQL;
Thirdly, the capacity of checking these constraints (there were over 72K constraint definitions in total at the time of writing) against the whole Wikidata graph – to the best of our knowledge – goes beyond the scalability (and feature coverage) of existing SHACL validators.
As for the first item, clearly, the above-mentioned issues regarding the expressivity of Wikidata property constraints within SHACL-Core limit its applicability. Moreover, non-core features are unfortunately not mandatorily (and thus rarely) implemented by SHACL validators so far.
As for the second and third items, we argue that due to the limitations associated with the expressibility of the SHACL constraints and the lack of tools capable of efficiently validating large graphs, a direct SPARQL translation potentially presents itself as a more generic, flexible, and operationalizable approach for validating Wikidata Property constraints.
Let us demonstrate this idea with a straightforward SPARQL translation of a simple conflicts-with (Q21502838) constraint for the property family name (P734), which, according to the constraint property (P2306) qualifier should not be used together with the property given name version for another gender (P1560), as expressible relatively concisely in the following SHACL shape:

An even more direct and crisp, and also executable formulation of this constraint can be easily constructed by the following SPARQL query:

In fact, we claim that violations of this particular constraint type, i.e. the conflicts-with constraint, could be checked more generally on all properties in one go, with a single SPARQL query:41

Indeed, this single query checks all violations of the conflicts-with constraint type and returns all violations of conflicts-with constraints at once. Intuitively, lines 2–3 lookup properties
Overall, we hope the illustrative examples in this section have sufficiently motivated that a direct translation of property constraints to SPARQL has advantages over SHACL for various reasons. That is, while in this section we in principle have made a case for using (a subset of) Wikidata’s property constraints as a “playground” to automatically generate a large testbed for SHACL(-Core) validators (and have also sketched how to extend this approach to SHACL-SPARQL), we also hope to have convinced the reader that this approach is not (yet) practically feasible, and in the end have made a case for direct generalizing our approach to fully operationalize Wikidata constraint validation via SPARQL.
As opposed to the prototypical nature of the previous section, here we aim at a fully operationalizable formalization. We propose SPARQL as a constraint representation formalism that fulfills both the requirements to be (i) operationalizable – in the sense of being able to compute and report inconsistencies, in a similar fashion as the existing Wikidata database reports – as well as (ii) declarative – in the sense of an unambiguous, exchangeable formalization, capable of understanding the meaning of constraints.
The availability of Wikidata’s database reports web page,42
For instance, our example item-requires statement constraint on FIFA player ID is reported at
As a summary of these database reports, Fig. 14 shows the development of property constraints over time for the 10 most violated constraints: according to the Wikidata database reports web page, we observed that since the introduction of Wikidata property constraints in 2015, the total number of constraints has grown from 19 in 2015 to 32 in 2023; new constraints were created, evolved, or ceased to exist. Data in Fig. 14 point to an increase in the number of violations for the one-of (Q21510859) constraint type. Required qualifier (Q21510856) constraints were introduced and began to be analyzed in 2019 only and are already emerging among the main causes of violations. The modeling of constraints is constantly evolving, for instance, used for values only (Q21528958), used as reference (Q21528959), and used as qualifier (Q21510863) constraints no longer exist and were migrated to a single constraint type: property scope (Q53869507). As such, we emphasize that our endeavor to model and formalize constraint types as SPARQL queries should not be viewed as a once-off exercise.

#violations for top 10 most violated constraint types (logarithmic scale).
Rather we aim at proposing to rethink the process of developing such constraints themselves in terms of such SPARQL queries to be included as an (i) operationalizable and (ii) declarative means for their definitions:
as for (i), Wikidata as an RDF graph can be queried through a SPARQL query service – by expressing constraint violations per constraint type as SPARQL queries, we can benefit from the query language’s operationalizable nature, and various existing SPARQL implementations, that scale to billions of triples.
as for (ii), SPARQL itself is a declarative language, with well understood theoretical properties and mappable to other locigal languages, such as Datalog [8,49,51]

SPARQL queries general template with exemplification.
In this section, we describe the overall structure of our Wikidata constraint validation approach using SPARQL queries. We again illustrate it via our running example from Fig. 8.
Figure 15a presents a generic structure followed by each SPARQL query proposed in this paper. We generalize queries into different “blocks”, such that each block can contain multiple triple patterns as exemplified in Fig. 15b, which fulfill different functions. Figure 15b represents the concrete query for the item-requires-statement constraint: for this constraint type a required property and its required value(s) need to be checked. Each block of the query structure of Fig. 15b is detailed as follows.
We have encoded all 32 constraint types (some of which are in separate queries for different variations) in SPARQL queries, following similar patterns corresponding to
Again, we note that apart from Wikidata itself, there are an increasing number of other Wikibase instances listed in the Wikibase Registry44
We now show how to formally express the constraint types that could not be directly represented with SHACL-Core in SPARQL.
Single-value Used to specify that one property generally contains a single value per concept, we already discussed the partial representability within SHACL-Core, when there are no separators defined. The following SPARQL query for the property capital (P36) shows how to capture violations in two scenarios: either there are multiple different values with no separators or there are separators with equal values. Block 4 binds multiple statements that are further tested in block 5. In block 5, it is tested if the values are different (line 14), if there are no separators (lines 16–19), or if it does not exist a separator (line 23) where the separator values (lines 24 and 25) for two different statements are different (line 26). Overall, this captures the intended semantics

Allowed qualifiers This constraint type specifies that only the listed qualifiers should be used when a certain statement is made, meaning that the use of all other qualifiers needs to be restricted. Since there is no way to list non-allowed paths implicitly (e.g. by referring to a path/property via a specific type), this constraint could not be expressed with SHACL-Core. However, when using SPARQL, it is possible to test all the predicates where the statement node is a subject. The following query presents the SPARQL formalization for property party chief representative (P210), where Block 4 binds all the statements about P210 (line 6) and their respective qualifiers (lines 7 and 8). Next, Block 5 creates the violation pattern, where the statement of Block 4 is considered a violation if at least one found qualifier is not part of the set of expected ones.
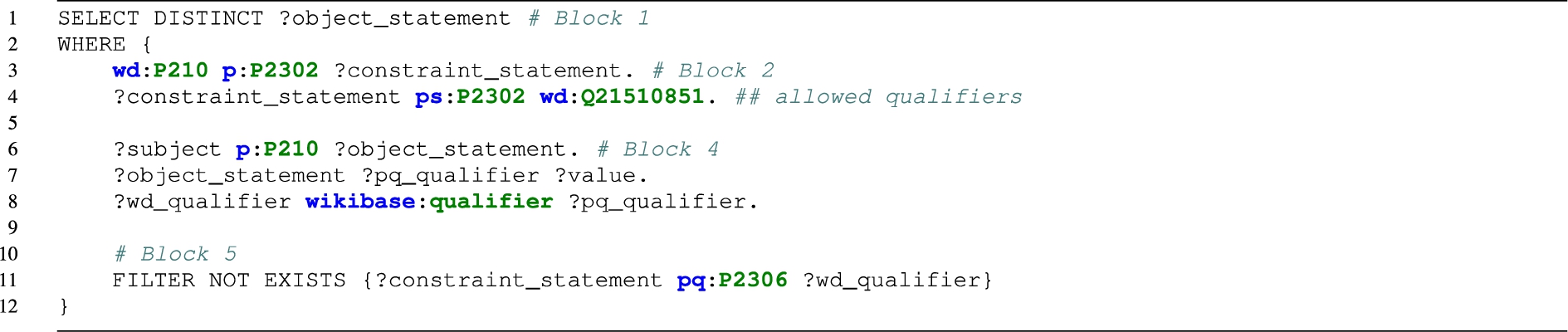
Difference-within-range The constraint requires the difference between two values to be calculated and compared to a predefined range. SHACL-Core provides functionalities for checking equalities and inequalities, but it does not encompass arithmetic operations as part of its components. Below we present a simplified version of the query to check difference-within-range violations for date of burial or cremation (P4602). Block 3 binds all the necessary qualifiers, such as the minimum and maximum value (lines 10 and 11) and the property necessary to create a valid range (line 12), which in this case is date of death (P570). Block 4 binds the values for P4602 and P570. Finally, the interval is compared with the expected period (block 5). 
Experiments
We designed an experiment to evaluate the semantics of our SPARQL queries to verify our approach against the Wikidata database reports. We compared the violations obtained by our queries with the violations published in the Wikidata Database reports (cf. Footnote 5). Unlike DBpedia, where a version of the KG is pragmatically generated and made available every three months,46
In order to still ensure comparability of results as far as possible, the conducted experiment was designed on a sample of constraint violations collected according to the following steps:
We identified the top-5 most violated constraint types from Wikidata’s violation statistics table on December 16, 2022: One-of (Q21510859), item-requires-statement (Q21503247), Single value constraints (Q19474404 and Q52060874), required qualifier (Q21510856), and value-requires-statement (Q21510864).
We ranked the associated properties in descending order of the number of violations for each of these constraint types.
We executed our SPARQL queries to collect the violations of five different properties for the five constraint types, totaling 25 violation sets available in our GitHub repository.47
The ad-hoc violation checking system used in Wikidata takes about a day to execute and publish results, thus our queries were executed one day before the data was available. Consequently, we extract the set of corresponding violations published by the Wikidata portal referring to the same properties on the next day. For instance, the FIFA player ID (P1469) property-specific violations are made available in the Wikidata report page.48
Finally, we structured and compared the violations reported by the Wikidata Database reports with the violations retrieved by the SPARQL queries on the Wikidata endpoint.
As the queries were executed on the SPARQL endpoint and our target was the properties with the highest numbers of violations, we also had to consider timeout-related issues due to limitations of the Wikidata environment itself: due to the high number of triples associated with some of the targeted properties, the limit of 60 seconds for a query, established by Wikidata’s SPARQL endpoint is not enough to process the entire target set. Therefore, it was necessary to discard the target properties that timed out and proceed with the subsequent one with the next highest number of violations (in steps 2+3 above), to arrive at 5 properties for each of the 5 chosen constraint types. Note that in order to have a reasonable basis for comparison, the SPARQL endpoint is the only option at the moment, since the database reports are computed on this state of the KG. In future work, we intend to create a benchmark to facilitate the testing of different approaches to collecting violations including testing of other engines and environments; more on that in the related and future work sections below.
In the next subsections, we provide a table for every constraint type containing the list of properties analyzed (Property ID), the total number of violations the Wikidata database reports claimed to have found (# of violations), the total number of violations made available by the database reports on the specific HTML pages for each property, the number of violations available (
One-of constraint
The first results concern the
One of constraint violations
One of constraint violations
For
Note: it is necessary to be logged in in Wikidata to see violations in the UI).
The four violations not captured by our approach for the property
Lastly, in
For Item requires statement constraints (IRS), which are very common, ten properties were skipped due to the timeout in the Wikidata SPARQL endpoint. The values displayed in the VA column of Table 4 can exceed the value 5001 for this constraint type because the same property can have multiple IRS instances. Moreover, such instances can request the existence of only one property or a pair ⟨property, value⟩. Therefore, the Wikidata database reports present a list of violations for each instance of IRS, which we summed up in tables to report the respective
Item requires statement constraint violations
Item requires statement constraint violations
In Table 4, note that for the top 3 properties (P1559, P1976, and P2539), our approach found all the available violations and some extra violations that unfortunately cannot be compared because the results available in the Wikidata database reports are incomplete. For
The 90 violations not found by our SPARQL query for
The statistic table of the Wikidata database reports points to Single-value constraint as the third most violated constraint type. We notice that this statistic takes into account Single-value (Q19474404) and Single-Best-value (Q52060874) constraints. Therefore, it was necessary to use the queries designed for these two types of constraints to perform the experiment. Eleven properties were skipped for presenting timeout in the SPARQL endpoint for at least one of the query types. The results are presented in Table 5, where, unlike the previous tables, we include in columns VA and OV the total number of unique entities found, i.e., the total number without repeated entities.
Single value/best single value constraints violations
Single value/best single value constraints violations
In
The analysis of
The occurrence of properties from the astronomy domain, such as type of variable star (P881) and surface gravity (P7015), was expected, since the astronomy community in Wikidata uses deprecation and different rankings to represent historical data, as also observed in [55]. Therefore, it is common to find statements with multiple values, where the higher-ranked ones represent more accurate or currently accepted data by the community.
The required qualifier constraint has the same principle described for IRS: the same property can have multiple instances of the required qualifier constraint, each one of them requiring a different property to be used as a qualifier for a given statement. For this constraint type, which again is very common, three properties were skipped due to timeout on the Wikidata SPARQL endpoint, where the properties with the next highest violation rates were selected. The results are available in Table 6, showing that the whole set of available violations (VA) was found by our SPARQL approach (OV).
Required qualifiers constraint violations
Required qualifiers constraint violations
Value requires statement constraint violations
Finally, Value-requires statement constraints (VRS) are similar to IRS, but instead of requiring the existence of a statement in the subject, these quite common constraints require a statement in the object. Ten overly common properties were skipped due to timeouts in the SPARQL endpoint. Two different queries were used for each property, one checking required properties and another checking pairs of required properties and values. The main results are available in Table 7.
For
In summary, common reasons for mismatches include – as a matter of interpretation – whether only truthy statements or also non-preferred and deprecated statements should be checked for constraint violations. Also, other deviations could arguably be identified as a matter of interpretation. As we also discussed, our constraints could be adapted to the respective different interpretations relatively easily with minor modifications of our query patterns. Overall, while we only conducted these analyses on a sample, we argue that the experiment has confirmed our opinion that a declarative and adaptable formulation of Wikidata property constraints in terms of SPARQL queries is both feasible and could add to the clarification of the constraints’ actual semantics. The deviations between the Wikidata UI pages and the Wikidata database reports confirm our opinion that such clarification is dearly needed.
Regarding the practical feasibility of the proposed approach, it is important to acknowledge the generic nature of the SPARQL queries proposed in this study. The absence of hard-coded parameters ensures adaptability to diverse constraint parameters, with queries exclusively relying on the Wikidata data model to match the triple patterns that generate specific constraint violations. This flexibility enables the applicability of generic queries checking violations across all properties instantiating a specific constraint type. On the downside, as we have discussed, such generic queries potentially lead to scalability problems for current SPARQL engines. As a practical workaround, constraints can also be checked by instantiating our generic queries per property, mitigating scalability challenges to a certain extent: in the context of the Wikidata ecosystem, the envisaged solution is therefore promising for deployment as a background process capable of processing batches of properties. By doing so, the system can systematically uncover candidate inconsistencies, according to the available resources and relevance of properties.
Related work
Constraints play an important role in specifying rules for data, defining the requirements to prevent it from becoming corrupt, and ensuring its integrity. There has been significant research on the development of constraint representations and validation techniques specifically for knowledge graphs.
Constraint languages for graph data
RDF has long served as the W3C-recommended graph-based data model for presenting information in the Semantic Web, whereas a standardized language to express and validate data graphs has only recently been introduced. Ontology languages like RDFS, OWL, and its sublanguages, which have been standardized along with RDF, have been widely used for modeling the data through axiomatic structures. For instance, DBpedia, like other open knowledge graphs (e.g. YAGO, GeoNames), makes use of ontologies to model the data, which have been employed also for detecting (some) inconsistencies (e.g., [11,48]). However, ontologies have been particularly criticized for their limited use when checking the conformance of data graphs. Indeed, the primary utility of ontologies lies in facilitating deductive reasoning tasks, such as node classification or evaluating overall satisfiability, and not in describing constraints on KGs. With the growing emphasis on data accuracy for graph-based applications, the absence of constraint languages similar to those found in relational [3] and semi-structured data [2] contexts became noticeable. To address this gap, multiple strategies have emerged. Hogan [38] used rule-based fragments of OWL/RDFS for scalable inconsistency identification and repair suggestions. The idea to use scalable variants of bespoke Datalog-based reasoning for constraint checking and verification originally imposed in Hogan’s thesis may be argued to be not unlike our approach: SPARQL has been shown to be equally expressive as non-recursive Datalog with negation [8], where features like property paths only mildly add harmless, linear recursion [51]. Another line of research regards extending ontology languages to treat axioms as integrity constraints under the closed-world assumption [45,58].
In particular, to address the lack of dedicated constraint languages for graph data, novel schema formalisms for RDF graph validation like the Shape Expressions language (ShEx) [13,29,56,57] were proposed before SHACL became a W3C recommendation. ShEx is a formal modeling and validation language for RDF data, which allows for the declaration of expected properties, cardinalities, and the type and structure of their objects. ShEx is closely related to SHACL, and in some cases, it is possible to translate SHACL shapes into ShEx shape expressions since their expressiveness is similar for common cases [29]. For instance, the shapes graph presented in Fig. 10 can be respectively represented in ShEx as follows:

Yet, we leave a full discussion about whether our approach, and therefore all existing constraint types transfer over to ShEx as an open question to future work. Additionally, validation languages based on ShEx supporting the Wikibase data model have been recently proposed in the literature [28], however, they still lack support for many Wikibase constructs and there is no operational validator yet.
Furthermore, SPARQL-based approaches to validate knowledge graphs can also be found in the literature [42,59], including the SPARQL Inferencing Notation (SPIN) 51

According to Corman et al.’s translation,

Unfortunately, this query currently times out on Wikidata’s SPARQL endpoint, mainly due to the nested negation yielding from a modular translation. The

In addition, not all Wikidata constraints could be directly represented in SHACL-Core. We therefore had to devise specific SPARQL queries for each of the 32 Wikidata constraint types to generate viable and functional solutions.
Data restrictions within Wikidata are also discussed by the community and implemented through further projects using other pre-established technologies. For instance, the Wikidata Schemas project52
meaning that the absence of a “mother” does not lead to inconsistencies, which indicates that the objective of such schema is rather to assist in the “design” of classes than constraint checking in the strict sense. Also, although there are some ShEx to SHACL conversion tools,58
Erxleben et al. [24] exploit properties describing taxonomic relations in Wikidata to extract an OWL ontology from Wikidata. The authors also propose the extraction of schematic information from property constraints and discuss their expressibility in terms of OWL axioms. However, whereas we focus herein concretely on covering all property constraints as a means to find possible violations in the data, Erxleben and colleagues rather stress the value of their corresponding OWL ontology as a (declarative) high-level description of the data, without claiming complete coverage of all Wikidata property constraints.
Martin and Patel-Schneider [44] discuss the representation of Wikidata property constraints through multi-attributed relational structures (MARS), as a logical framework for Wikidata. Constraints are represented in MARS using extended multi-attributed predicate logic (eMAPL), providing a logical characterization for constraints. Despite covering 26 different constraint types, to the best of our knowledge, the authors have not performed experiments to evaluate the accuracy of the proposed formalization, nor its efficiency, and do not discuss implementability. In fact, the theoretical framework partially skips over the subtleties of checking certain constraints in practice. As an example, the translation of allowed entity types constraints in the extended version of [44] assumes that entity types in Wikidata can be checked via simple instance-of type checking. Our SPARQL query shows that this is not the case in practice for all entity types as they are differently represented in the actual Wikidata RDF dump.59
cf.
Abián et al. [1] propose a definition of contemporary constraint that was indeed later adopted by Wikidata property constraints. Shenoy et al. [55] present a quality analysis of Wikidata focusing on correctness, checking for weak statements under three main indicators: constraint violation, community agreement, and deprecation. The premise is that a statement receives a low-quality score when it violates some constraint, highlighting the importance of constraints for KG refinement. Boneva et al. [12] present a tool for designing/editing shape constraints in SHACL and ShEx suggesting Wikidata as a potential use case, but – to the best of our knowledge – without exhaustively covering or discussing the existing Wikidata property constraints.
Apart from works specifically on constraint for Wikidata, in [48] the authors systematically identify errors in DBpedia, using the DOLCE ontology as background knowledge to find inconsistencies in the assertional axioms. They feed target information extracted from DBpedia and linked to the DOLCE ontology into a reasoner checking for inconsistencies. Before, Bischof et al. [11] already highlighted logical inconsistencies in DBpedia which can be detected using OWL QL, rewritten to SPARQL 1.1 property paths – not unlike our general approach.
Despite the partially negative result that some of our SPARQL queries time out, and also – as we discussed above – we did not find SHACL validators that would allow us to check our constraint violations at the scale of Wikidata, we believe, besides our primary goal of clarifying Wikidata property constraint semantics, our results should be considered as a real-world challenge benchmark for both SPARQL engines and SHACL validators.
As for SHACL, real-world performance benchmarks still seem to be rare. Schaffenrath et al. [53] have presented a benchmark consisting of 58 SHACL shapes over a graph with 1M N-quads sample from a tourism knowledge graph, evaluated with different graph databases, emphasizing that “larger data exceeded […] available resources”. The shapes we present are on the one hand targeting an (orders of magnitude) larger dataset, but on the other hand can also be evaluated locally on a per entity level, thus providing a benchmark of quite different nature. Also, the evolving nature of Wikidata makes a dynamic/evolving benchmark that can be evaluated/scaled along the natural evolution and growth of Wikidata itself. Next, [27] presents a synthetic SHACL benchmark derived from the famous LUBM ontology benchmark, while also emphasizing the current lack of real-world benchmarks for SHACL.
Closest but also orthogonal in focus to our own work is a recent paper by Rabbani et al. [52], which focuses on the orthogonal problem of automatically extracting shapes (representable as SHACL) from large KGs such as Wikidata in a data-driven manner, rather than on the formalization of community-driven constraints as we do.
Finally, apart from serving as a basis for novel benchmarks for SHACL, our SPARQL formalization particularly extends, and in our opinion complements, the existing landscape of real-world SPARQL benchmarks. Indeed, the – to the best of our knowledge – only benchmark for Wikidata, WDbench [6] covers a significantly different kind of Wikidata queries than we do. WDbench is a benchmark extracted from Wikidata query logs, focusing on queries that time out on the regular Wikidata query endpoint, but it is restricted to queries on truthy statements only, that is for instance not covering queries on qualifiers. Our queries on the contrary, by definition all relate to querying qualifiers and, as such they require the whole Wikidata graph and cannot be answered on the truthy statements alone. Yet, similar to the WDbench queries, many of the queries we present, particularly on very common properties, suffer from timeouts, as our experiments confirm. Thus, while the approach we present shows in principle feasible, it calls for novel more scalable approaches to efficiently solve such SPARQL queries that currently time out. We hope, as the queries we focus on typically only affect local contexts of entities and properties, they could hopefully be solved, e.g., by clever modularisation and partitioning techniques.
Conclusions and future work
We have formalized all 32 different property constraint types of Wikidata using SPARQL and discussed ways to encode them with W3C’s recommendation mechanism for formalizing constraints over RDF Knowledge Graphs, SHACL. This study made it possible to clarify to which extent SHACL-Core can represent community-defined constraints of a widely used real-world KG. One of our results is a collection of practical SHACL-Core constraints that can be used in a large and growing real-world dataset. Indeed the non-availability of practical SHACL performance benchmarks has already been emphasized by [27], where we believe our work could be a significant step forward towards leveraging Wikidata as a large benchmark dataset for SHACL validators. Other results include clarifications of heretofore uncertain issues, such as the representability of permitted entities and exceptions in Wikidata property constraints within SHACL [55]. We also could argue the non-expressibility of certain Wikidata constraints, due to the impossibility of comparing values obtained through different paths matching the same regular path expression within SHACL-Core.
As we could show, all these issues could be addressed when using SPARQL to formalize and validate constraints, where all 32 constraints could in principle be formalized. In this context, as a partially negative result, one of the main limitations of the work was the increasing performance limitations of Wikidata’s query endpoint, which calls for more scalable query interfaces and bespoke evaluation mechanisms. On the positive side, these limitations give rise to further research considering property constraint violation detection as a performance SPARQL benchmark as such. As a first next step in this direction, we aim to compare our results from the Wikidata SPARQL endpoint with a local installation, comparing different graph databases or lightweight query approaches such as HDT [25] to support a queryable version of Wikidata constraints checks independent of the SPARQL endpoint, which, for reasons of immediate comparison with the current Wikidata violation reports, was beyond our scope of the present paper.
Wikidata property constraints are dynamically evolving and maintained by the community, as shown by new constraint types such as Citation needed (Q54554025), a constraint type not even yet reported by Wikidata’s official constraint reporting tool, cf. Footnote 42. We believe that our formalization and operationalization of property constraints in a declarative way, using SPARQL, establish a mutual relationship with the Wikidata community. Analyzing the formalization helps to enrich the way constraints are modeled and vice versa clarifies their semantic interpretation, as opposed to the current, partially ambiguous natural language definitions, verifiable only through the partially disclosed Wikidata database reports. We further hope that this article stimulates discussions in the community to enrich the representation of constraints that still might have subjective interpretations.
In future work, we plan to use and build on the results of this paper to further systematically collect and analyze the kinds of constraint violations in Wikidata and study their patterns as well as their evolution over time. Understanding data that violates the constraints and its evolution is fundamental to identifying modeling or other systematic data quality issues and proposing further refinements, but also repairs, especially in collaboratively and dynamically created KGs such as Wikidata. Proposing refinements is a process that can be envisioned when taking into account the repair information declaratively represented in and retrievable through operationalizable constraints.
We have established SPARQL, as a declarative and operationalizable means to implement Wikidata’s property constraints and also briefly discussed its relationship to other potential formalisms, such as Datalog and Description Logics. In order to further clarify the exact formal properties of Wikidata’s property constraints, further research on a concise and bespoke formal language, e.g. in terms of extended DLs, which captures all and only the required features, would be an interesting route for further work; attempts such as MARS [44] provide promising starting points already in this direction.
Footnotes
Acknowledgements
The present paper is based on a preliminary workshop paper originally presented at the Wikidata workshop 2022 [![]() ]; we thank the workshop organizers and participants for their feedback during the workshop. We thank the reviewers, for their valuable comments which helped us to considerably improve the original submission of this paper. This work is supported by funding in the European Commission’s Horizon 2020 Research Program under Grant Agreement Number 957402 (TEAMING.AI) and Shqiponja Ahmetaj was supported by the Austrian Science Fund (FWF) and netidee SCIENCE project T1349-N.
]; we thank the workshop organizers and participants for their feedback during the workshop. We thank the reviewers, for their valuable comments which helped us to considerably improve the original submission of this paper. This work is supported by funding in the European Commission’s Horizon 2020 Research Program under Grant Agreement Number 957402 (TEAMING.AI) and Shqiponja Ahmetaj was supported by the Austrian Science Fund (FWF) and netidee SCIENCE project T1349-N.