
Abstract
In recent years, several noteworthy large, cross-domain, and openly available knowledge graphs (KGs) have been created. These include DBpedia, Freebase, OpenCyc, Wikidata, and YAGO. Although extensively in use, these KGs have not been subject to an in-depth comparison so far. In this survey, we provide data quality criteria according to which KGs can be analyzed and analyze and compare the above mentioned KGs. Furthermore, we propose a framework for finding the most suitable KG for a given setting.
Keywords
Introduction
The vision of the Semantic Web is to publish and query knowledge on the Web in a semantically structured way. According to Guns [21], the term “Semantic Web” had already been used in fields such as Educational Psychology, before it became prominent in Computer Science. Freedman and Reynolds [19], for instance, describe “semantic webbing” as organizing information and relationships in a visual display. Berners-Lee has mentioned his idea of using typed links as vehicle of semantics already since 1989 and proposed it under the term Semantic Web for the first time at the INET conference in 1995 [21].
The idea of a Semantic Web was introduced to a wider audience by Berners-Lee in 2001 [8]. According to his vision, the traditional Web as a Web of Documents should be extended to a Web of Data where not only documents and links between documents, but any entity (e.g., a person or organization) and any relation between entities (e.g., isSpouseOf) can be represented on the Web.
When it comes to realizing the idea of the Semantic Web, knowledge graphs (KGs) are currently seen as one of the most essential components. The term “knowledge graph” was reintroduced by Google in 2012 [41] and is intended for any graph-based knowledge repository. Since in the Semantic Web RDF graphs are used we use the term
In this survey, we focus on those KGs having the following aspects:
The KGs are freely accessible and freely usable within the Linked Open Data (LOD) cloud.
See
See
See
The KGs should cover general knowledge (often also called cross-domain or encyclopedic knowledge) instead of knowledge about special domains such as biomedicine.
Thus, out of scope are KGs which are not openly available such as the Google Knowledge Graph4
See
See
See
See
For selecting the KGs for analysis, we regarded all datasets which had been registered at the online dataset catalog
This catalog is also used for registering Linked Open Data datasets.
In this paper, we give a systematic overview of these KGs in their current versions (as of April 2016) and discuss how the knowledge in these KGs is modeled, stored, and queried. To the best of our knowledge, such a comparison between these widely used KGs has not been presented before. Note that the focus of this survey is not the life cycle of KGs on the Web or in enterprises. We can refer in this respect to [5]. Instead, the focus of our KG comparison is on data quality, as this is one of the most crucial aspects when it comes to considering which KG to use in a specific setting.
Furthermore, we provide a KG recommendation framework for users who are interested in using one of the mentioned KGs in a research or industrial setting, but who are inexperienced in which KG to choose for their concrete settings.
The main contributions of this survey are:
Based on existing literature on data quality, we provide 34 data quality criteria according to which KGs can be analyzed.
We calculate key statistics for the KGs DBpedia, Freebase, OpenCyc, Wikidata, and YAGO.
We analyze DBpedia, Freebase, OpenCyc, Wikidata, and YAGO along the mentioned data quality criteria.9
The data and detailed evaluation results for both the key statistics and the metric evaluations are online available at
We propose a framework which enables users to find the most suitable KG for their needs.
The survey is organized as follows:
In Section 2 we introduce formal definitions used throughout the article. In Section 3 we describe the data quality dimensions which we later use for the KG comparison, including their subordinated data quality criteria and corresponding data quality metrics. In Section 4 we describe the selected KGs. In Section 5 we analyze the KGs using several key statistics and using the data quality metrics introduced in Section 3. In Section 6 we present our framework for assessing and rating KGs according to the user’s setting. In Section 7 we present related work on (linked) data quality criteria and on key statistics for KGs. In Section 8 we conclude the survey.
We define the following sets that are used in formalizations throughout the article. If not otherwise stated, we use the prefixes listed in Listing 1 for indicating namespaces throughout the article.

Default prefixes for namespaces used throughout this article.
An
See
RDF terms comprise URIs, blank nodes, and literals.
Complementary,
Note that knowledge about the KGs which were analyzed for this survey was taken into account when defining these sets. These definitions may not be appropriate for other KGs.
Furthermore, the sets’ extensions would be different when assuming a certain semantic (e.g., RDF, RDFS, or OWL-LD). Under the assumption that all entailments under one of these semantics were added to a KG, the definition of each set could be simplified and the extensions would be of larger cardinality. However, for this article we did not derive entailments.
Everybody on the Web can publish information. Therefore, a data consumer does not only face the challenge to find a suitable data source, but is also confronted with the issue that data on the Web can differ very much regarding its quality. Data quality can thereby be viewed not only in terms of accuracy, but in multiple other dimensions. In the following, we introduce concepts regarding the data quality of KGs in the Linked Data context, which are used in the following sections. The data quality dimensions are then exposed in Sections 3.2–3.5.
As soon as data is considered w.r.t. usefulness, the data is seen in a specific context. It can, thus, already be regarded as information, leading to the term “information quality” instead of “data quality.”
One of the most important and foundational works on data quality is that of Wang et al. [45]. They developed a framework for assessing the data quality of datasets in the database context. In this framework, Wang et al. distinguish between data quality criteria, data quality dimensions, and data quality categories.13
The quality dimensions are defined in [45], the sub-classification into parameters/indicators in [44, p. 354].
A
In order to measure the degree to which a certain data quality criterion is fulfilled for a given KG, each criterion is formalized and expressed in terms of a function with the value range of
A
Data quality dimensions and their respective data quality criteria are further grouped into
Criteria of the category of the intrinsic data quality focus on the fact that data has quality in its own right.
Criteria of the category of the contextual data quality cannot be considered in general, but must be assessed depending on the application context of the data consumer.
Criteria of the category of the representational data quality reveal in which form the data is available.
Criteria of the category of the accessibility data quality determine how the data can be accessed.
Since its publication, the presented framework of Wang et al. has been extensively used, either in its original version or in an adapted or extended version. Bizer [9] and Zaveri [47] worked on data quality in the Linked Data context. They make the following adaptations on Wang et al.’s framework:
Bizer [9] compared the work of Wang et al. [45] with other works in the area of data quality. He thereby complements the framework with the dimensions consistency, verifiability, and offensiveness.
Zaveri et al. [47] follow Wang et al. [45], but introduce licensing and interlinking as new dimensions in the linked data context.
In this article, we use the DQ dimensions as defined by Wang et al. [45] and as extended by Bizer [9] and Zaveri [47]. More precisely, we make the following adaptations on Wang et al.’s framework:
Consistency is treated by us as separate DQ dimension. Verifiability is incorporated within the DQ dimension Trustworthiness as criterion Trustworthiness on statement level. The Offensiveness of KG facts is not considered by us, as it is hard to make an objective evaluation in this regard. We extend the category of the accessibility data quality by the dimension License and Interlinking, as those data quality dimensions get in addition relevant in the Linked Data context.
When applying our framework to compare KGs, the single DQ metrics can be weighted differently so that the needs and requirements of the users can be taken into account. In the following, we first formalize the idea of weighting the different metrics. We then present the criteria and the corresponding metrics of our framework.
Given are a KG g, a set of criteria
The fulfillment degree
Based on the quality dimensions introduced by Wang et al. [45], we now present the DQ criteria and metrics as used in our KG comparison. Note that some of the criteria have already been introduced by others as outlined in Section 7.
Note also that our metrics are to be understood as possible ways of how to evaluate the DQ dimensions. Other definitions of the DQ metrics might be possible and reasonable. We defined the metrics along the characteristics of the KGs DBpedia, Freebase, OpenCyc, Wikidata, and YAGO, but kept the definitions as generic as possible. In the evaluations, we then used those metric definitions and applied them, e.g., on the basis of own-created gold standards.
Intrinsic category
“Intrinsic data quality denotes that data have quality in their own right” [45]. This kind of data quality can therefore be assessed independently from the context. The intrinsic category embraces the three dimensions Accuracy, Trustworthiness, and Consistency, which are defined in the following subsections. The dimensions Believability, Objectivity, and Reputation, which are separate dimensions in Wang et al.’s classification system [45], are subsumed by us under the dimension Trustworthiness.
Accuracy
Batini et al. [6] distinguish between syntactic and semantic accuracy: Syntactic accuracy describes the formal compliance to syntactic rules without reviewing whether the value reflects the reality. The semantic accuracy determines whether the value is semantically valid, i.e., whether the value is true. Based on the classification of Batini et al., we can define the metric for Accuracy as follows:
Syntactic validity of RDF documents, Syntactic validity of literals, and Semantic validity of triples.
The fulfillment degree of a KG g w.r.t. the dimension Accuracy is measured by the metrics
Syntactic validity of RDF documents The syntactic validity of RDF documents is an important requirement for machines to interpret an RDF document completely and correctly. Hogan et al. [27] suggest using standardized tools for creating RDF data. The authors state that in this way normally only little syntax errors occur, despite the complex syntactic representation of RDF/XML.
RDF data can be validated by an RDF validator such as the W3C RDF validator.14
See
Syntactic validity of literals Assessing the syntactic validity of literals means to determine to which degree literal values stored in the KG are syntactically valid. The syntactic validity of literal values depends on the data types of the literals and can be automatically assessed via rules [20,32]. Syntactic rules can be written in the form of regular expressions. For instance, it can be verified whether a literal representing a date follows the ISO 8601 specification. Assuming that L is the infinite set of literals, we can state:
In case of an empty set in the denominator of the fraction, the metric should evaluate to 1.
Semantic validity of triples The criterion Semantic validity of triples is introduced to evaluate whether the statements expressed by the triples (with or without literals) hold true. Determining whether a statement is true or false is strictly speaking impossible (see the field of epistemology in philosophy). For evaluating the Semantic validity of statements, Bizer et al. [9] note that a triple is semantically correct if it is also available from a trusted source (e.g., Name Authority File), if it is common sense, or if the statement can be measured or perceived by the user directly. Wikidata has similar guidelines implemented to determine whether a fact needs to be sourced.15
See
We measure the Semantic validity of triples based on empirical evidence, i.e., based on a reference data set serving as gold standard. We determine the fulfillment degree as the precision that the triples which are in the KG g and in the gold standard
Formally, let
In case of an empty set in the denominator of the fraction, the metric should evaluate to 1.
Trustworthiness has been discussed as follows:
Trustworthiness on KG level The measure of Trustworthiness on KG level exposes a basic indication about the trustworthiness of the KG. In this assessment, the method of data curation as well as the method of data insertion is taken into account. Regarding the method of data curation, we distinguish between manual and automated methods. Regarding the data insertion, we can differentiate between: 1. whether the data is entered by experts (of a specific domain), 2. whether the knowledge comes from volunteers contributing in a community, and 3. whether the knowledge is extracted automatically from a data source. This data source can itself be either structured, semi-structured, or un-structured. We assume that a closed system, where experts or other registered users feed knowledge into a system, is less vulnerable to harmful behavior of users than an open system, where data is curated by a community. Therefore, we assign the values of the metric for Trustworthiness on KG level as follows:
Trustworthiness on statement level The fulfillment of Trustworthiness on statement level is determined by an assessment whether a provenance vocabulary is used. By means of a provenance vocabulary, the source of statements can be stored. Storing source information is an important precondition to assess statements easily w.r.t. semantic validity. We distinguish between provenance information provided for triples and provenance information provided for resources.
The most widely used ontologies for storing provenance information are the Dublin Core Metadata terms16
See
See
Indicating unknown and empty values If the data model of the considered KG supports the representation of unknown and empty values, more complex statements can be represented. For instance, empty values allow to represent that a person has no children and unknown values allow to represent that the birth date of a person in not known. This kind of higher explanatory power of a KG increases the trustworthiness of the KG.
In OWL, restrictions can be introduced to ensure consistent modeling of knowledge to some degree. The OWL schema restrictions can be divided into class restrictions and relation restrictions [11].
Class restrictions refer to classes. For instance, one can specify via
Relation restrictions refer to the usage of relations. They can be classified into value constraints and cardinality constraints.
Value constraints determine the range of relations.
Cardinality constraints limit the number of times a relation may exist per resource. Via
Check of schema restrictions during insertion of new statements Checking the schema restrictions during the insertion of new statements can help to reject facts that would render the KG inconsistent. Such simple checks are often done on the client side in the user interface. For instance, the application checks whether data with the right data type is inserted. Due to the dependency to the actual inserted data, the check needs to be custom-designed. Simple rules are applicable, however, inconsistencies can still appear if no suitable rules are available. Examples of consistency checks are: checking the expected data types of literals; checking whether the entity to be inserted has a valid entity type (i.e., checking the
Consistency of statements w.r.t. class constraints This metric is intended to measure the degree to which the instance data is consistent with the class restrictions (e.g.,
In the following, we limit ourselves to the class constraints given by all
Implicit restrictions which can be deducted from the class hierarchy, e.g., that a restriction for
Consistency of statements w.r.t. relation constraints The metric for this criterion is intended for measuring the degree to which the instance data is consistent with the relation restrictions (e.g., indicated via
In case of evaluating the consistency of instance data concretely w.r.t. given
We chose those relations (and, for instance, not
Let
Then we can define the metrics
In case of an empty set of relation constraints (
Contextual data quality “highlights the requirement that data quality must be considered within the context of the task at hand” [45]. This category contains the three dimensions (i) Relevancy, (ii) Completeness, and (iii) Timeliness. Wang et al.’s further dimensions in this category, appropriate amount of data and value-added, are considered by us as being part of the dimension Completeness.
Relevancy
We do not consider the relevancy of literals, as there is no ranking of literals provided for the considered KGs.
Creating a ranking of statements By means of this criterion one can determine whether the KG supports a ranking of statements by which the relative relevance of statements among other statements can be expressed. For instance, given the Wikidata entity “Barack Obama” (
Note that this criterion refers to a characteristic of the KG and not to a characteristic of the system that hosts the KG.
We include the following two aspects in this dimension, which are separate dimensions in Wang et al.’s framework:
Appropriate amount of data: Appropriate amount of data is “the extent to which the quantity or volume of available data is appropriate” [45].
Value-added: Value-added is “the extent to which data are beneficial and provide advantages from their use” [45].
Schema completeness, i.e., the extent to which classes and relations are not missing, Column completeness, i.e., the extent to which values of relations on instance level – i.e., facts – are not missing, and Population completeness, i.e., the extent to which entities are not missing.
The Completeness dimension is context-dependent and therefore belongs to the contextual category, because the fact that a KG is seen as complete depends on the use case scenario, i.e., on the given KG and on the information need of the user. As exemplified by Bizer [9], a list of German stocks is complete for an investor who is interested in German stocks, but it is not complete for an investor who is looking for an overview of European stocks. The completeness is, hence, only assessable by means of a concrete use case at hand or with the help of a defined gold standard.
The fulfillment degree of a KG g w.r.t. the dimension Completeness is measured by the metrics
Schema completeness By means of the criterion Schema completeness, one can determine the completeness of the schema w.r.t. classes and relations [39]. The schema is assessed by means of a gold standard. This gold standard consists of classes and relations which are relevant for the use case. For evaluating cross-domain KGs, we use as gold standard a typical set of cross-domain classes and relations. It comprises (i) basic classes such as people and locations in different granularities and (ii) basic relations such as birth date and number of inhabitants. We define the schema completeness
Column completeness In the traditional database area (with fixed schema), by means of the Column completeness criterion one can determine the degree by which the relations of a class, which are defined on the schema level (each relation has one column), exist on the instance level [39]. In the Semantic Web and Linked Data context, however, we cannot presume any fixed relational schema on the schema level. The set of possible relations for the instances of a class is given “at runtime” by the set of used relations for the instances of this class. Therefore, we need to modify this criterion as already proposed by Pipino et al. [39]. In the updated version, by means of the criterion Column completeness one can determine the degree by which the instances of a class use the same relations, averaged over all classes.
Formally, we define the Column completeness metric
We thereby let
Note that there are also relations which are dedicated to the instances of a specific class, but which do not need to exist for all instances of that class. For instance, not all people need to have a relation
For an evaluation about the prediction which relations are of this nature, see [1].
Population completeness The Population completeness metric determines the extent to which the considered KG covers a basic population [39]. The assessment of the KG completeness w.r.t. a basic population is performed by means of a gold standard, which covers both well-known entities (called “short head”, e.g., the n largest cities in the world according to the number of inhabitants) and little-known entities (called “long tail”; e.g., municipalities in Germany). We take all entities contained in our gold standard equally into account.
Let
The fulfillment degree of a KG g w.r.t. the dimension Timeliness is measured by the metrics
Timeliness frequency of the KG The criterion Timeliness frequency of the KG indicates how fast the KG is updated. We consider the KG RDF export here and differentiate between continuous updates, where the updates are always performed immediately, and discrete KG updates, where the updates take place in discrete time intervals. In case the KG edits are available online immediately but the RDF export files are available in discrete, varying updating intervals, we consider the online version of the KG, since in the context of Linked Data it is sufficient that URIs are dereferenceable.
Specification of the validity period of statements Specifying the validity period of statements enables to temporally limit the validity of statements. By using this criterion, we measure whether the KG supports the specification of starting and maybe end dates of statements by means of providing suitable forms of representation.
Specification of the modification date of statements The modification date discloses the point in time of the last verification of a statement. The modification date is typically represented via the relations
Representational data quality
Representational data quality “contains aspects related to the format of the data [...] and meaning of data” [45]. This category contains the two dimensions (i) Ease of understanding (i.e., regarding the human-readability) and (ii) Interoperability (i.e., regarding the machine-readability). The dimensions Interpretability, Representational consistency and Concise representation as in addition proposed by Wang et al. [45] are considered by us as being a part of the dimension Interoperability.
Ease of understanding
Description of resources Heath et al. [24 ,28] suggest to describe resources in a human-understandable way, e.g., via
Beschreibung). Darüber hinaus ist das Ergebnis der Evaluation auf Basis der Entitäten interessant -> DBpedia weicht deutlich ab, da manche Entitäten (Intermediate-Node-Mapping) keine rdfs:label haben. Folglich würde ich die Definition der Metrik allgemein halten (beschränkt auf proprietäre Ressourcen, d.h. im selben Namespace), die Evaluation jedoch nur anhand der Entitäten machen.
Labels in multiple languages Resources in the KG are described in a human-readable way via labels, e.g., via
Using the namespace
Understandable RDF serialization RDF/XML is the recommended RDF serialization format of the W3C. However, due to its syntax RDF/XML documents are hard to read for humans. The understandability of RDF data by humans can be increased by providing RDF in other, more human-understandable serialization formats such as N3, N-Triple, and Turtle. We measure this criterion by measuring the supported serialization formats during the dereferencing of resources.
Note that conversions from one RDF serialization format into another are easy to perform.
Self-describing URIs Descriptive URIs contribute to a better human-readability of KG data. Sauermann et al.23
See
For an overview of URI patterns see
Interoperability is another dimension of the representational data quality category and subsumes Wang et al.’s aspects interpretability, representational consistency, and concise representation.
In the literature, it is often not differentiated between “reification” in the general sense and “reification” in the sense of the specific proposal described in the RDF standard (Brickley, D., Guha, R. (eds.): RDF Vocabulary Description Language 1.0: RDF Schema. W3C Recommendation, online available at
Avoiding blank nodes and RDF reification
Provisioning of several serialization formats
Using external vocabulary
Interoperability of proprietary vocabulary
The fulfillment degree of a KG g w.r.t. the dimension Interoperability is measured by the metrics
Avoiding blank nodes and RDF reification Using RDF blank nodes, RDF reification, RDF container, and RDF lists is often considered as ambivalent: On the one hand, these RDF features are not very common and they complicate the processing and querying of RDF data [24,28]. On the other hand, they are necessary in certain situations, e.g., when statements about statements should be made. We measure the criterion by evaluating whether blank nodes and RDF reification are used.
Provisioning of several serialization formats The interpretability of RDF data of a KG is increased if besides the serialization standard RDF/XML further serialization formats are supported for URI dereferencing.
Using external vocabulary Using a common vocabulary for representing and describing the KG data allows to represent resources and relations between resources in the Web of Data in a unified way. This increases the interoperability of data [24,28] and allows a comfortable data integration. We measure the criterion of using an external vocabulary by setting the number of triples with external vocabulary in predicate position to the number of all triples in the KG:
Interoperability of proprietary vocabulary Linking on schema level means to link the proprietary vocabulary to external vocabulary. Proprietary vocabulary are classes and relations which were defined in the KG itself. The interlinking to external vocabulary guarantees a high degree of interoperability [24]. We measure the interlinking on schema level by calculating the ratio to which classes and relations have at least one equivalency link (e.g.,
Accessibility data quality refers to aspects on how data can be accessed. This category contains the three dimensions
Accessibility, Licensing, and Interlinking.
Wang’s dimension access security is considered by us as being not relevant in the Linked Open Data context, as we only take open data sources into account.
In the following, we go into details of the mentioned data quality dimensions:
Accessibility
Availability “of a data source is the probability that a feasible query is correctly answered in a given time range” [37].
According to Naumann [37], the availability is an important quality aspect for data sources on the Web, since in case of integrated systems (with federated queries) usually all data sources need to be available in order to execute the query. There can be different influencing factors regarding the availability of data sources, such as the day time, the worldwide distribution of servers, the planed maintenance work, and the caching of data. Linked Data sources can be available as SPARQL endpoints (for performing complex queries on the data) and via HTTP URI dereferencing. We need to consider both possibilities for this DQ dimension.
Response time characterizes the delay between the point in time when the query was submitted and the point in time when the query response is received [9].
Note that the response time is dependent on empirical factors such as the query, the size of the indexed data, the data structure, the used triple store, the hardware, and so on. We do not consider the response time in our evaluations, since obtaining a comprehensive result here is hard.
In the context of Linked Data, data requests can be made (i) on SPARQL endpoints, (ii) on RDF dumps (export files), and (iii) on Linked Data APIs.
Dereferencing possibility of resources
Availability of the KG
Provisioning of public SPARQL endpoint
Provisioning of an RDF export
Support of content negotiation
Linking HTML sites to RDF serializations
Provisioning of KG metadata
The fulfillment degree of a KG g w.r.t. the dimension Accessibility is measured by the metrics
Dereferencing possibility of resources One of the Linked Data principles [7] is the dereferencing possibility of resources: URIs must be resolvable via HTTP requests and useful information should be returned thereby. We assess the dereferencing possibility of resources in the KG by analyzing for each URI in the sample set (here: all URIs
Availability of the KG The Availability of the KG criterion indicates the uptime of the KG. It is an essential criterion in the context of Linked Data, since in case of an integrated or federated query mostly all data sources need to be available [37]. We measure the availability of a KG by monitoring the ability of dereferencing URIs over a period of time. This monitoring process can be done with the help of a monitoring tool such as Pingdom.26
See
Provisioning of public SPARQL endpoint SPARQL endpoints allow the user to perform complex queries (including potentially many instances, classes, and relations) on the KG. This criterion here indicates whether an official SPARQL endpoint is publicly available. There might be additional restrictions of this SPARQL endpoint such as a maximum number of requests per time slice or a maximum runtime of a query. However, we do not measure these restrictions here.
Provisioning of an RDF export If there is no public SPARQL endpoint available or the restrictions of this endpoint are so strict that the user does not use it, an RDF export dataset (RDF dump) can often be used. This dataset can be used to set up a local, private SPARQL endpoint. The criterion here indicates whether an RDF export dataset is officially available:
Support of content negotiation Content negotiation (CN) allows that the server returns RDF documents during the dereferencing of resources in the desired RDF serialization format. The HTTP protocol allows the client to specify the desired content type (e.g., RDF/XML) in the HTTP request and the server to specify the returned content type in the HTTP response header (e.g.,
Linking HTML sites to RDF serializations Heath et al. [24] suggest linking any HTML description of a resource to RDF serializations of this resource in order to make the discovery of corresponding RDF data easier (for Linked Data aware applications). For that reason, in the HTML header the so-called Autodiscovery pattern can be included. This pattern consists of the phrase
An example is
Provisioning of KG metadata In the light of the Semantic Web vision where agents select and make use of appropriate data sources on the Web, also the meta-information about KGs needs to be available in a machine-readable format. The two important mechanisms to specify metadata about KGs are (i) using semantic sitemaps and (ii) using the VoID vocabulary28
See namespace
See
See
See
See
Noteworthy is that most data sources in the Linked Open Data cloud do not provide any licensing information [29] which makes it difficult to use the data in commercial settings. Even if data is published under CC-BY or CC-BY-SA, the data is often not used since companies refer to uncertainties regarding these contracts.
The fulfillment degree of a KG g w.r.t. the dimension License is measured by the metric
Provisioning machine-readable licensing information Licenses define the legal frameworks under which the KG data may be used. Providing machine-readable licensing information allows users and applications to be aware of the license and to use the data of the KG in accordance with the legal possibilities [24,28].
Licenses can be specified in RDF via relations such as
Using the namespace
See
See
See
See
Interlinking via
Validity of external URIs
The fulfillment degree of a KG g w.r.t. the dimension Interlinking is measured by the metrics
Interlinking via
The interlinking on schema level is already measured via the criterion Interoperability of proprietary vocabulary.
Validity of external URIs The considered KG may contain outgoing links referring to RDF resources or Web documents (non-RDF data). The linking to RDF resources is usually enabled by
In case of an empty set A, the metric should evaluate to 1.
In this section, we provided 34 DQ criteria which can be applied in the form of DQ metrics to KGs in order to assess those KGs w.r.t. data quality. The DQ criteria are classified into 11 DQ dimensions. These dimensions are themselves grouped into 4 DQ categories. In total, we have the following picture:
Intrinsic category Accuracy Syntactic validity of RDF documents Syntactic validity of literals Semantic validity of triples Trustworthiness Trustworthiness on KG level Trustworthiness on statement level Using unknown and empty values Consistency Check of schema restrictions during insertion of new statements Consistency of statements w.r.t. class constraints Consistency of statements w.r.t. relation constraints Contextual category Relevancy Creating a ranking of statements Completeness Schema completeness Column completeness Population completeness Timeliness Timeliness frequency of the KG Specification of the validity period of statements Specification of the modification date of statements Representational data quality Ease of understanding Description of resources Labels in multiple languages Understandable RDF serialization Self-describing URIs Interoperability Avoiding blank nodes and RDF reification Provisioning of several serialization formats Using external vocabulary Interoperability of proprietary vocabulary Accessibility category Accessibility Dereferencing possibility of resources Availability of the KG Provisioning of public SPARQL endpoint Provisioning of an RDF export Support of content negotiation Linking HTML sites to RDF serializations Provisioning of KG metadata License Provisioning machine-readable licensing information Interlinking Interlinking via Validity of external URIs
Selection of KGs
We consider the following KGs for our comparative evaluation:
See There is also DBpedia live which started in 2009 and which gets updated when Wikipedia is updated. See See See See https://www.cia.gov/library/publications/the-world-factbook/, requested on Dec 31, 2016. See See See See See See See a complete list of the links on the websites describing the single DBpedia versions such as
See
See
See
See
See
See
See
See
See
See http://www.mpi-inf.mpg.de/departments/databases-and-information-systems/research/yago-naga/yago/downloads/, accessed on Nov 1, 2016.
See
Key statistics
In the following, we present statistical commonalities and differences of the KGs DBpedia, Freebase, OpenCyc, Wikidata, and YAGO. We thereby use the following key statistics:
Number of triples
Number of classes
Number of relations
Distribution of classes w.r.t. the number of their corresponding instances
Coverage of classes with at least one instance per class
Covered domains w.r.t. entities
Number of entities
Number of instances
Number of entities per class
Number of unique subjects
Number of unique predicates
Number of unique objects
In Section 7.2, we provide an overview of related work w.r.t. those key statistics.
Triples
The idea of N-Quads is based on the assignment of triples to different graphs. YAGO uses N-Quads to identify statements per ID.
In case of DBpedia, Freebase, and Wikidata, reification is implemented by means of n-ary relations. An n-ary relation denotes the relation between more than two resources and is implemented via additional, intermediate nodes, since in RDF only binary statements can be modeled [15,25]. In Freebase and DBpedia, data is mostly provided in the form of plain N-Triples and n-ary relations are only used for data from higher arity.63
In Freebase Compound Value Types are used for reification [38]. In DBpedia it is named Intermedia Node Mapping, see
The number of classes in a KG may also be calculated by taking all entity type relations (

Coverage of classes having at least one instance.
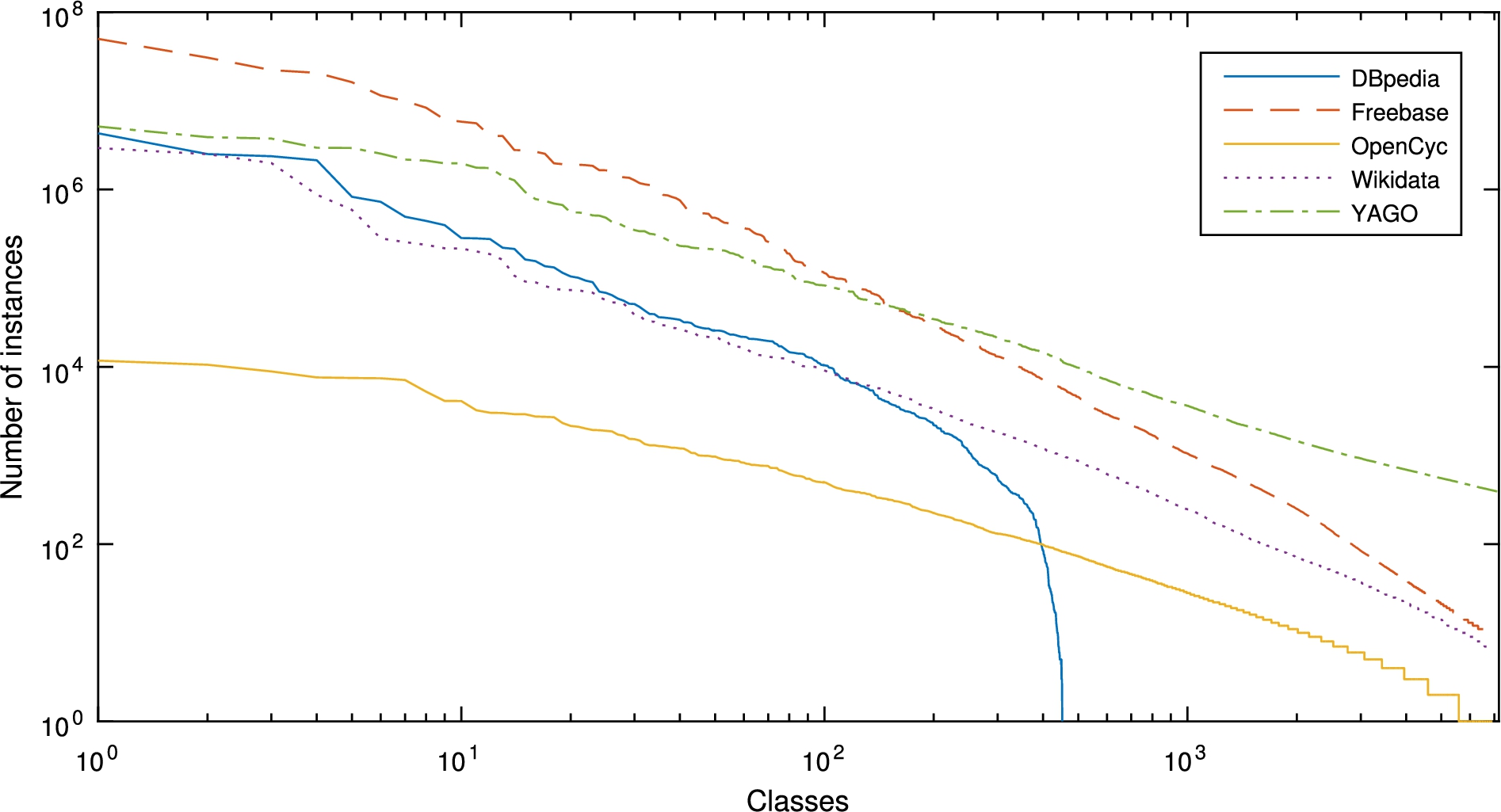
Distribution of classes w.r.t. the number of instances per KG.
All considered KGs are cross-domain, meaning that a variety of domains are covered in those KGs. However, the KGs often cover the single domains to a different degree. Tartir [43] proposed to measure the covered domains of ontologies by determining the usage degree of corresponding classes: the number of instances belonging to one or more subclasses of the respective domain is compared to the number of all instances. In our work, however, we decided to evaluate the coverage of domains concerning the classes per KG via manual assignments of the mostly used classes to the domains people, media, organizations, geography, and biology.65
See our website for examples of classes per domain and per KG
The manual assignment of classes to domains is necessary in order to obtain a consistent assignment of the classes to the domains across all considered KGs. Otherwise, the same classes in different KGs may be assigned to different domains. Moreover, in some KGs classes may otherwise appear in various domains simultaneously. For instance, the Freebase classes
As the reader can see in Table 1, our method to determine the coverage of domains, and, hence, the reach of our evaluation, includes about 80% of all entities of each KG, except Wikidata. It is calculated as the ratio of the number of unique entities of all considered domains of a given KG divided by the number of all entities of this KG.66
We used the number of unique entities of all domains and not the sum of the entities measured per domain, since entities may be in several domains at the same time.
Percentage of considered entities per KG for covered domains

Number of entities per domain.

Relative number of entities per domain.
Figure 3 shows the number of entities per domain in the different KGs with a logarithmic scale. Figure 4 presents the relative coverage of each domain in each KG. It is calculated as the ratio of the number of entities in each domain to the total number of entities of the KG. A value of 100% means that all instances reside in one single domain.
The case of Freebase is especially outstanding here: 77% of all entities here are located in the media domain. This fact can be traced back to large-scale data imports, such as from MusicBrainz. The class
In DBpedia and YAGO, the domain of people is the largest domain (50% and 34%, respectively). Peculiar is the higher coverage of YAGO regarding the geography domain compared to DBpedia. As one reason for that we can point out the data import of GeoNames into YAGO.
Wikidata contains around 150K entities in the domain organization. This is relatively few considering the total amount of entities being around 18.7M and considering the number of organizations in other KGs. Note that even DBpedia provides more organization entities than Wikidata. The reason why Wikidata has not so many organization entities is not fully comprehensible to us. However, we can point out that for our analysis we only considered Wikidata classes which appeared more than 6,000 times67
This number is based on heuristics. We focused on the 150 most instantiated classes and cut the long tail of classes having only few instances.
Relations – as short term for explicitly defined relations – refers to (proprietary) vocabulary defined on the schema level of a KG. We identify the set of relations of a KG as the set of those links which are explicitly defined as such via assignments (for instance, with In contrast, we use predicates to denote links used in the KG independently of their introduction on the schema level. The set of unique predicates per KG, denoted as
It is important to distinguish the key statistics for relations from the key statistics for predicates, since they can differ considerably, depending on to which degree relations are only defined on schema level, but not used on instance level.
Relations
Summary of key statistics
Summary of key statistics
DBpedia Regarding DBpedia relations we need to distinguish between so-called mapping-based properties and non-mapping-based properties. Mapping-based properties are created by extracing the information from infoboxes in Wikipedia using manually created mappings. These mappings are specified in the DBpedia Mappings Wiki.68
See
For instance, The DBpedia ontology contains
For instance,
Freebase The high number or Freebase relations can be explained by two facts: 1. About a third of all relations in Freebase are duplicates in the sense that they are declared by means of the
OpenCyc For OpenCyc we measure 18,028 unique relations. We can assume that most of them are dedicated to statements on the schema level.
Wikidata In Wikidata a relatively small set of relations is provided. Note in this context that, despite the fact that Wikidata is curated by a community (just like Freebase), Wikidata community members cannot insert arbitrarily new relations as it was possible in Freebase; instead, relations first need to be proposed and then get accepted by the community if and only if certain criteria are met.71
See
YAGO For YAGO we measure the small set of 106 unique relations. Although relations are curated manually for YAGO and DBpedia, the size of the relation set differs significantly between those KGs. Hoffart et al. [26] mention the following reasons for that:
Peculiarity of relations: The DBpedia ontology provides quite many special relations. For instance, there exists the relation
Granularity of relations: Relations in the DBpedia ontology are more fine-grained than relations in YAGO. For instance, DBpedia contains the relations
Date specification: The DBpedia ontology introduces several relations for dates. For instance, DBpedia contains the relations
Inverse relations: YAGO has no relations explicitly specified as being inverse. In DBpedia, we can find relations specified as inverse such as
Reification: YAGO introduces the SPOTL(X) format. This format extends the triple format “SPO” with a specification of

Frequency of the usage of the relations per KG, grouped by (i) zero occurrences, (ii) 1–500 occurrences, and (iii) more than 500 occurrences in the respective KG.
Predicates
DBpedia DBpedia is ranked third in terms of the absolute numbers of predicates: about 60K predicates are used in DBpedia. The set of relations and the set of predicates varies considerably here, since also facts are extracted from Wikipedia info-boxes whose predicates are considered by us as being only implicitly defined and which, hence, occur only as predicates. These are the so-called non-mapping-based properties. Note that in the studied DBpedia version 2015-04 the set of explicitly defined relations (mapping-based properties) and the set of implicitly defined relations (non-mapping-based properties) overlaps. An example is
Freebase We can observe here a similar picture as for the set of Freebase relations: With about 785K unique predicates, Freebase exceeds the other KGs by far. Note, however, that 95% of the predicates (around 743K) are used only once. This relativizes the high number. Most of the predicates are keys in the sense of ids and are used for internal modeling (for instance,
OpenCyc In contrast to the 18,028 unique relations, we measure only 164 unique predicates for OpenCyc. More predicates are presumably used in Cyc.
Wikidata We measure more Wikidata predicates than Wikidata relations, since Wikidata predicates are created by modifying Wikidata relations. An example are the following triples, which express the statement “Barack Obama (

The relation extension “s” indicates that the RDF term in the object position is a statement. The “v” extension allows to refer to a value (in Wikidata terminology). Besides those extensions, there is “r” to refer to a reference and the “q” extension to refer to a qualifier. In general, these relation extensions are used for realizing reification via n-ary relations. For that, intermediate nodes are used which represent statements [15].
YAGO YAGO contains more predicates than DBpedia, since infobox attributes from different language versions of Wikipedia are aggregated into one KG,72
The language of each attribute is encoded in the URI, for instance
Instances are belonging to classes. They are identified by retrieving the subjects of all triples where the predicates indicate class affiliations.
Entities are real-world objects. This excludes, for instance, instantiated statements for being entities. Determining the set of entities is partially tricky: In DBpedia and YAGO entities are determined as being an instance of the class
For instance,
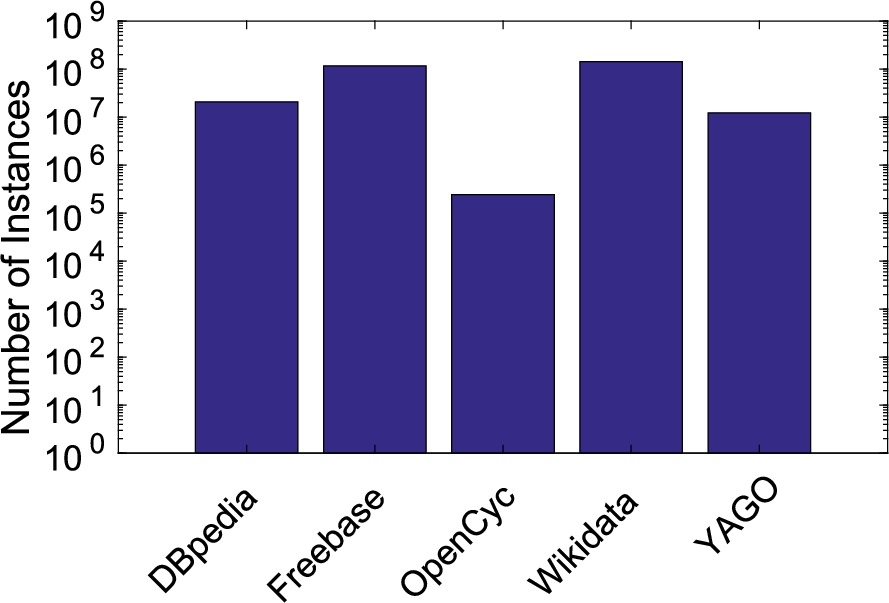
Number of instances per KG.
Freebase had been created mainly from data imports such as from MusicBrainz. Therefore, entities in the domain of media and especially song release tracks are covered very well in Freebase: 77% of all entities are in the media domain (see Section 5.1.3), out of which 42% are release tracks.74
Those release tracks are expressed via
Due to the large size and the world-wide coverage of entities in MusicBrainz, Freebase contains albums and release tracks of both English and non-English languages. For instance, regarding the English language, the album “Thriller” from Michael Jackson and its single “Billie Jean” are there, as well as rather unknown songs from the “Thriller” album such as “The Lady in My Life”. Regarding non-English languages, Freebase contains for instance songs and albums from Helene Fischer such as “Lass’ mich in dein Leben” and “Zaubermond;” also rather unknown songs such as “Hab’ den Himmel berührt” can be found.
In case of DBpedia, the English Wikipedia is the source of information. In the English Wikipedia, many albums and singles of English artists are covered – such as the album “Thriller” and the single “Billie Jean.” Rather unknown songs such as “The Lady in My Life” are not covered in Wikipedia. For many non-English artists such as the German singer Helene Fischer no music albums and no singles are contained in the English Wikipedia. In the corresponding language version of Wikipedia (and localized DBpedia version), this information is often available (for instance, the album “Zaubermond” and the song “Lass’ mich in dein Leben”), but not the rather unknown songs such as “Hab’ den Himmel berührt.”
For YAGO, the same situation as for DBpedia holds, with the difference that YAGO in addition imports entities also from the different language versions of Wikipedia and imports also data from sources such as GeoNames. However, the above mentioned works (“Lass’ mich in dein Leben,” “Zaubermond,” and “Hab’ den Himmel berührt”) of Helene Fischer are not in the YAGO, although the song “Lass’ mich in dein Leben” exists in the German Wikipedia since May 2014 and although the used YAGO version 3 is based on the Wikipedia dump of June 2014.75
See
Wikidata is supported by the community and contains music albums of English and non-English artists, even if they do not exist in Wikipedia. An example is the song “The Lady in My Life.” Note, however, that Wikidata does not provide all artist’s works such as from Helene Fischer.
OpenCyc contains only very few entities in the music domain. The reason is that OpenCyc has its focus mainly on common-sense knowledge and not so much on facts about entities.

Average number of entities per class per KG.
We measure the number of unique subjects by counting the unique resources (i.e., URIs and blank nodes) on the subject position of N-Triples:

Number of unique subjects and objects per KG. Note the logarithmic scale on the axis of ordinates.

Ratio of the number of instances to the number of entities for each KG.
The high number of unique subjects in YAGO is surprising and can be explained by the reification style used in YAGO. Facts are stored as N-Quads in order to allow for making statements about statements (for instance, storing the provenance information for statements). To that end, IDs (instead of blank nodes) which identify the triples are used on the first position of N-Triples. They lead to 308M unique subjects, such as
DBpedia contains considerably more
Based on the evaluation results presented in the last subsections, we can highlight the following insights:
Triples: All KGs are very large. Freebase is the largest KG in terms of number of triples, while OpenCyc is the smallest KG. We notice a correlation between the way of building up a KG and the size of the KG: automatically created KGs are typically larger, as the burdens of integrating new knowledge become lower. Datasets which have been imported into the KGs, such as MusicBrainz into Freebase, have a huge impact on the number of triples and on the number of facts in the KG. Also the way of modeling data has a great impact on the number of triples. For instance, if n-ary relations are expressed in N-Triples format (as in case of Wikidata), many intermediate nodes need to be modeled, leading to many additional triples compared to plain statements. Last but not least, the number of supported languages influences the number of triples. Classes: The number of classes is highly varying among the KGs, ranging from 736 (DBpedia) up to 300K (Wikidata) and 570K (YAGO). Despite its high number of classes, YAGO contains in relative terms the most classes which are actually used (i.e., classes with at least one instance). This can be traced back to the fact that heuristics are used for selecting appropriate Wikipedia categories as classes for YAGO. Wikidata, in contrast, contains many classes, but out of them only a small fraction is actually used on instance level. Note, however, that this is not necessarily a burden. Domains: Although all considered KGs are specified as crossdomain, domains are not equally distributed in the KGs. Also the domain coverage among the KGs differs considerably. Which domains are well represented heavily depends on which datasets have been integrated into the KGs. MusicBrainz facts had been imported into Freebase, leading to a strong knowledge representation (77%) in the domain of media in Freebase. In DBpedia and YAGO, the domain people is the largest, likely due to Wikipedia as data source. Relations and predicates: Many relations are rarely used in the KGs: Only 5% of the Freebase relations are used more than 500 times and about 70% are not used at all. In DBpedia, half of the relations of the DBpedia ontology are not used at all and only a quarter of the relations is used more than 500 times. For OpenCyc, 99.2% of the relations are not used. We assume that they are used only within Cyc, the commercial version of OpenCyc. Instances and entities: Freebase contains by far the highest number of entities. Wikidata exposes relatively many instances in comparison to the entities, as each statement is instantiated leading to around 74M instances which are not entities. Subjects and objects: YAGO provides the highest number of unique subjects among the KGs and also the highest ratio of the number of unique subjects to the number of unique objects. This is due to the fact that N-Quad representations need to be expressed via intermedium nodes and that YAGO is concentrated on classes which are linked by entities and other classes, but which do not provide outlinks. DBpedia exhibits more unique objects than unique subjects, since it contains many
Data quality analysis
We now present the results obtained by applying the DQ metrics introduced in the Sections 3.2–3.5 to the KGs DBpedia, Freebase, OpenCyc, Wikidata, and YAGO.
Accuracy
The fulfillment degrees of the KGs regarding the Accuracy metrics are shown in Table 3.
Evaluation results for the KGs regarding the dimension Accuracy
Evaluation results for the KGs regarding the dimension Accuracy
Syntactic validity of RDF documents,
See
See
Syntactic validity of literals,
Note that OpenCyc is not taken into account for this criterion: Although OpenCyc comprises around 1.1M literals in total, these literals are essentially labels and descriptions (given via
As long as a literal with data type is given, its syntax is verified with the help of the function
In DBpedia, for instance, data for the relation
Date of birth For Wikidata, DBpedia, and Freebase, all verified literal values (1M per KG) were syntactically correct.79
Surprisingly, the Jena Framework assessed data values with a negative year (i.e., B.C.; e.g., “-600” for
In order to model the dates to the extent they are known, further relations would be necessary, such as using
Number of inhabitants The data types of the literal values regarding the number of inhabitants were valid in all KGs. For DBpedia, YAGO, and Wikidata, we evaluated the syntactic validity of the number of inhabitants by checking if
ISBN The ISBN is an identifier for books and magazines. The identifier can occur in various formats: with or without preceding “ISBN,” with or without delimiters, and with 10 or 13 digits. Gupta81
See http://howtodoinjava.com/regex/java-regex-validate-international-standard-book-number-isbns/, requested on Mar 1, 2016.
E.g., we found the 16 digit ISBN 9789780307986931 (cf.
See
An example is “ISBN 0755111974 (hardcover edition)” for
Semantic validity of triples,
See
During evaluation we identified the following issues:
For finding the right entry in GND, more information besides the name of the person is needed. This information is sometimes not given, so that entity disambiguation is in those cases hard to perform.
Contrary to assumptions, often either no corresponding GND entry exists or not many facts of the GND entity are given. In other words, GND is incomplete w.r.t. to entities (cf. Population completeness) and relations (cf. Column completeness).
Values of different granularity need to be matched, such as an exact date of birth against the indication of a year only.
In conclusion, the evaluation of semantic validity is hard, even if a random sample set is evaluated manually. Meaningful differences among the KGs might be revealed only when a very large sample is evaluated, e.g., by using crowd-sourcing [2,3,46]. Another approach for assessing the semantic validity is presented by Kontokostas et al. [32] who propose a test-driven evaluation where test cases are created to evaluate triples semi-automatically: For instance, an interval specifies the valid height of a person and all triples which lie outside of this interval are evaluated manually. In this way, outliers can be easily found but possible wrong values within the interval are not detected.
Our findings appear to be consistent with the evaluation results of the YAGO developer team for YAGO2, where manually assessing 4,412 statements resulted in an accuracy of 98.1%.86
With a weighted averaging of 95%, see
The fulfillment degrees of the KGs regarding the Trustworthiness criteria are shown in Table 4.
Trustworthiness on KG level,
Evaluation results for the KGs regarding the dimension Trustworthiness
Evaluation results for the KGs regarding the dimension Trustworthiness
Cyc is edited (expanded and modified) exclusively by a dedicated expert group. The free version, OpenCyc, is derived from Cyc and only a locally hosted version can be modified by the data consumer.
Wikidata is also curated and expanded manually, but by volunteers of the Wikidata community. Wikidata allows importing data from external sources such as Freebase.87
Note that imports from Freebase require the approval of the community (see
Freebase was also curated by a community of volunteers. In contrast to Wikidata, the proportion of data imported automatically is considerably higher and new data imports were not dependent on community approvals.
DBpedia and YAGO The knowledge of both KGs is extracted from Wikipedia, but DBpedia differs from YAGO w.r.t. the community involvement: Any user can engage (i) in mapping the Wikipedia infobox templates to the DBpedia ontology in the DBpedia mappings wiki88
See
Trustworthiness on statement level We determine the Trustworthiness on statement level by evaluating whether provenance information for statements is used in the KGs. The picture is mixed:
DBpedia uses the relation
E.g.,
YAGO uses its own vocabulary to indicate the source of information. Interestingly, YAGO stores per statement both the source (via
In Wikidata several relations can be used for referring to sources, such as “imported from” (
All relations are instances of “Wikidata property to indicate a source” (
See
This is the number of instances of
This is the number of instances of
Freebase uses proprietary vocabulary for representing provenance: via n-ary relations, which are in Freebase called Compound Value Types (CVT), data from higher arity can be expressed [38].94
E.g., for a statement with the relation
OpenCyc differs from the other KGs in that it uses neither an external vocabulary nor a proprietary vocabulary for storing provenance information.
Indicating unknown and empty values,
YAGO supports the representation of unknown values and empty values by providing explicit relations for such cases.95
E.g.,
The fulfillment degrees of the KGs regarding the Consistency criteria are shown in Table 5.
Check of schema restrictions during insertion of new statements,
Evaluation results for the KGs regarding the dimension Consistency
Evaluation results for the KGs regarding the dimension Consistency
The values of the metric
Consistency of statements w.r.t. class constraints,
Note that the sample size varies among the KGs (depending on how many
Freebase and Wikidata do not specify any constraints with
Consistency of statements w.r.t. relation constraints,
See https://www.wikidata.org/wiki/Category:Properties_with_one-of_constraints for an overview; requested on Jan 29, 2017.
DBpedia obtains the highest measured fulfillment score w.r.t. consistency of
YAGO, Freebase, and OpenCyc contain range inconsistencies primarily since they specify designated data types via range relations which are not consistently used on the instance level. For instance, YAGO specifies proprietary data types such as
The fulfillment degrees of the KGs regarding the Relevancy criteria are shown in Table 6.
Creating a ranking of statements,
Evaluation results for the KGs regarding the dimension Relevancy
Evaluation results for the KGs regarding the dimension Relevancy
Only Wikidata supports the modeling of a ranking of statements: Each statement is ranked with “preferred rank” (
See
The fulfillment degrees of the KGs regarding the Completeness criteria are shown in Table 7.
Evaluation results for the KGs regarding the dimension Completeness
Evaluation results for the KGs regarding the dimension Completeness
Schema completeness,
See
DBpedia DBpedia shows a good score regarding Schema completeness and its schema is mainly limited due to the characteristics of how information is stored and extracted from Wikipedia.
Classes: The DBpedia ontology was created manually and covers all domains well. However, it is incomplete in the details and therefore appears unbalanced. For instance, within the domain of plants the DBpedia ontology does not use the class “tree” but the class “ginko,” which is a subclass of trees. We can mention as reason for such gaps in the modeling the fact that the ontology is created by means of the most frequently used infobox templates in Wikipedia.
Relations: Relations are considerably well covered in the DBpedia ontology. Some missing relations or modeling failures are due to the Wikipedia infobox characteristics. For example, to represent the gender of a person the existing relation
Freebase Freebase shows a very ambivalent schema completeness. On the one hand, Freebase targets rather the representation of facts on instance level than the representation of classes and their hierarchy. On the other hand, Freebase provides a vast amount of relations, leading to a very good coverage of the requested relations.
Classes: Freebase lacks a class hierarchy and subclasses of classes are often in different domains (for instance, the classes
Freebase ID
Freebase ID
Relations: Freebase exhibits all relations requested by our gold standard. This is not surprising, given the vast amount of available relations in Freebase (see Section 5.1.4 and Table 2).
OpenCyc In total, OpenCyc exposes a quite high Schema completeness scoring. This is due to the fact that OpenCyc has been created manually and has its focus on generic and common-sense knowledge.
Classes: The ontology of OpenCyc covers both generic and specific classes such as
Relations: OpenCyc lacks some relations of the gold standard such as the number of pages or the ISBN of books.
Wikidata According to our evaluation, Wikidata is complete both with respect to classes and relations.
Classes: Besides frequently used generic classes such as “human” (
Relations: In particular remarkable is that Wikidata covers all relations of the gold standard, even though it has extremely less relations than Freebase. Thus, the Wikidata methodology to let users propose new relations, to discuss about their outreach, and finally to approve or disapprove the relations, seems to be appropriate.
YAGO Due to its concentration on modeling classes, YAGO shows the best overall Schema completeness fulfillment score among the KGs.
Classes: To create the set of classes in YAGO, the Wikipedia categories are extracted and connected to WordNet synsets. Since also our gold standard is already aligned to WordNet synsets, we can measure a full completeness score for YAGO classes.
Relations: The YAGO schema does not contain many unique but rather abstract relations, which can be understood in different senses. The abstract relation names make it often difficult to infer the meaning. The relation
Column completeness,
The selection of class-relation-pairs was depending on the fact which class-relation-pairs were available per KG. Hence, the choice is varying from KG to KG. Also, note that less class-relation-pairs were used if no 25 pairs were available in the respective KG.
Metric values of
DBpedia fails regarding the relation sex for instances of class
Freebase surprisingly shows a very high coverage (92.7%) of the authors of books, given the basic population of 1.7M books. Note, however, that there are not only books modeled under
OpenCyc breaks ranks, as mostly no values for the considered relations are stored in this KG. It contains mainly taxonomic knowledge and only thinly spread instance facts.
Wikidata achieves a high coverage of birth dates (70.3%) and of gender (94.1%), despite the high number of 3M people.103
These 3M instances form about 18.5% of all instances in Wikidata. See
YAGO obtains a coverage of 63.5% for gender relations, as it, in contrast to DBpedia, extracts this implicit information from Wikipedia.
Population completeness,

Population completeness regarding the different domains per KG.
See http://km.aifb.kit.edu/sites/knowledge-graph-comparison/, requested on Jan 29, 2017.
The well-known entities were chosen without temporal and location-based restrictions. To take the most popular entities per domain, we used quantitative statements. For instance, to select well-known athletes, we ranked athletes by the number of won olympic medals; to select the most popular mountains, we ranked the mountains by their heights.
To select the rather unknown entities, we considered entities associated to both Germany and a specific year. For instance, regarding the athletes, we selected German athletes active in the year 2010, such as Maria Höfl-Riesch. The selection of rather unknown entities in the domain of biology is based on the IUCN Red List of Threatened Species.105
See
Note that selecting entities by their importance or popularity is hard in general and that also other popularity measures such as the PageRank scores may be taken into account.
Selecting four entities per class and five classes per domain resulted in 100 entities to be used for evaluating the Population completeness.
Well-known entities: Here, all considered KGs achieve good results. DBpedia, Freebase, and Wikidata are complete w.r.t. the well-known entities in our gold standard. YAGO lacks some well-known entities, although some of them are represented in Wikipedia. One reason for this fact is that those Wikipedia entities do not get imported into YAGO for which a WordNet class exists. For instance, there is no “Great White Shark” entity, only the WordNet class
Not-well-known entities: First of all, not very surprising is the fact that all KGs show a higher degree of completeness regarding well-known entities than regarding rather unknown entities, as the KGs are oriented towards general knowledge and not domain-specific knowledge. Secondly, two things are in particular peculiar concerning long-tail entities in the KGs: While most of the KGs obtain a score of about 0.88, Wikidata deflects upwards and OpenCyc deflects strongly downwards.
Wikidata exhibits a very high Population completeness degree for long tail entities. This is a result from the central storage of interwiki links between different Wikimedia projects (especially between the different Wikipedia language versions) in Wikidata: A Wikidata entry is added to Wikidata as soon as a new entity is added in one of the many Wikipedia language versions. Note, however, that in this way English-language labels for the entities are often missing. We measure that only about 54.6% (10.2M) of all Wikidata resources have an English label.
OpenCyc exhibits a poor population degree score of 0.14 for long-tail entities. OpenCyc’s sister KGs Cyc and ResearchCyc are apparently considerably better covered with entities [34], leading to higher Population completeness scores.
The evaluation results concerning the dimension Timeliness are presented in Table 9.
Evaluation results for the KGs regarding the dimension Timeliness
Evaluation results for the KGs regarding the dimension Timeliness
Timeliness frequency of the KG,
DBpedia is created about once to twice a year and is not modified in the meantime. From September 2013 until November 2016, six DBpedia versions have been published.107
These versions are DBpedia 3.8, DBpedia 3.9, DBpedia 2014, DBpedia 2015-04, DBpedia 2015-10, and DBpedia 2016-04. Always the latest DBpedia version is published online for dereferencing.
See
Freebase had been updated continuously until its close-down and is not updated anymore.
OpenCyc has been updated less than once per year. The last OpenCyc version dates from May 2012.109
See
Wikidata provides the highest fulfillment degree for this criterion. Modifications in Wikidata are via browser and via HTTP URI dereferencing immediately visible. Hence, Wikidata falls in the category of continuous updates. Besides that, an RDF export is provided on a roughly monthly basis (either via the RDF export webpage110
See
See
YAGO has been updated less than once per year. YAGO3 was published in 2015, YAGO2 in 2011, and the interim version YAGO2s in 2013. A date of the next release has not been published.
Specification of the validity period of statements,
DBpedia and OpenCyc do not realize any specification possibility. In YAGO, Freebase, and Wikidata the temporal validity period of statements can be specified. In YAGO, this modeling possibility is made available via the relations
Specification of the modification date of statements,
In Freebase the date of the last review of a fact can be represented via the relation
The evaluation results of the dimension Ease of understanding are presented in Table 10.
Evaluation results for the KGs regarding the dimension Ease of understanding
Evaluation results for the KGs regarding the dimension Ease of understanding
Description of resources,
Human-readable resource descriptions may also be represented by other relations [14]. However, we focused on those relations which are commonly used in the considered KGs.
YAGO, Wikidata, and OpenCyc contain a label for almost every entity. In Wikidata, the entities without any label are of experimental nature and are most likely not used.113
For instance,
Surprisingly, DBpedia shows a relatively low coverage w.r.t. labels and descriptions (only 70.4%). Our manual investigations suggest that relations with higher arity are modeled by means of intermediate nodes which have no labels.114
E.g.,
Labels in multiple languages,
Note that literals such as
Understandable RDF serialization,
Self-describing URIs,
On the other hand, Wikidata and Freebase (the latter in part) rely on opaque URIs: Wikidata uses Q-IDs for resources (“items” in Wikidata terminology) and P-IDs for relations. Freebase uses self-describing URIs only partially, namely, opaque M-IDs for entities and self-describing URIs for classes and relations.116
E.g.,
The evaluation results of the dimension Interoperability are presented in Table 11.
Evaluation results for the KGs regarding the dimension Interoperability
Evaluation results for the KGs regarding the dimension Interoperability
Avoiding blank nodes and RDF reification,
See Section 5.1.1 for more details w.r.t. the influence of reification on the number of triples.
Blank nodes are non-dereferencable, anonymous resources. They are used by the Wikidata and OpenCyc data model.
Provisioning of several serialization formats,
Using external vocabulary,
Wikidata reveals a high external vocabulary ratio, too. We can mention two obvious reasons for that fact: 1. Information in Wikidata is provided in a huge variety of languages, leading to 85M
Interoperability of proprietary vocabulary,
OpenCyc uses
Regarding its classes, DBpedia reaches a relative high interlinking degree of about 48.4%. Classes are thereby linked to FOAF, Wikidata, schema.org and DUL.119
See
E.g.,
Freebase only provides
In OpenCyc, about half of all classes exhibit at least one external linking via
Regarding the classes, Wikidata provides links mainly to DBpedia. Considering all Wikidata classes, only 0.1% of all Wikidata classes are linked to equivalent external classes. This may be due to the high number of classes in Wikidata in general. Regarding the relations, Wikidata provides links in particular to FOAF and schema.org and achieves here a linking coverage of 2.1%. Although this is low, frequently used relations are linked.121
Frequently used relations with stated equivalence to external relations are, e.g.,
YAGO contains around 553K
The evaluation results of the dimension Accessibility are presented in Table 12.
Dereferencing possibility of resources,
Evaluation results for the KGs regarding the dimension Accessibility
Evaluation results for the KGs regarding the dimension Accessibility
For Wikidata, which contains also not that many unique predicates, we analyzed around 35K URIs. Note that predicates which are derived from relations using a suffix (e.g., the suffix “s” as in
Regarding Freebase, mainly all URIs on subject and object position of triples could be dereferenced. Some resources were not resolvable even after multiple attempts (HTTP server error 503; e.g.,
Availability of the KG,
See
See diagrams per KG on our website (
Availability of a public SPARQL endpoint,
See
See
Especially regarding the Wikidata SPARQL endpoint we observed access restrictions: The maximum execution time per query is set to 30 seconds, but there is no limitation regarding the returning number of rows. However, the front-end of the SPARQL endpoint crashed in case of large result sets with more than 1.5M rows. Although public SPARQL endpoints need to be prepared for inefficient queries, the time limit of Wikidata may impede the execution of reasonable queries.
Provisioning of an RDF export,
Support of content negotiation,
The endpoints for DBpedia, Wikidata, and YAGO correctly returned the appropriate RDF serialization format and the corresponding HTML representation of the tested resources. Freebase does currently not provide any content negotiation and only the content type
Noteworthy is also that regarding the N-Triples serialization YAGO and DBpedia require the accept header
Linking HTML sites to RDF serializations,
Provisioning of metadata about the KG,
See
See
The evaluation results of the dimension License are shown in Table 13.
Provisioning machine-readable licensing information,
Evaluation results for the KGs regarding the dimension License
Evaluation results for the KGs regarding the dimension License
DBpedia and Wikidata provide licensing information about their KG data in machine-readable form. For DBpedia, this is done in the ontology via the predicate
See
See
See
See
License information is provided as plain text among further information with the relation
Evaluation results for the KGs regarding the dimension Interlinking
The evaluation results of the dimension Interlinking are shown in Table 14.
Linking via owl:sameAs,
The interlinking on schema level is already covered by the criterion Interoperability of proprietary vocabulary.
In DBpedia, there are about 5.2M instances with at least one
In Wikidata, neither
Although the equivalence statements in Wikidata can be used to generate corresponding
YAGO has around 3.6M instances with at least one
In case of OpenCyc, links to Cyc,134
I.e., sw.cyc.com .
See Interoperability of proprietary vocabulary in Section 5.2.8.
Validity of external URIs,
DBpedia stores provenance information via the relation
Freebase achieves high metric values here, since it contains
OpenCyc contains mainly external links to non-RDF-based Web resources to wikipedia.org and w3.org.
YAGO also achieves high metric values, since it provides
For Wikidata the relation “reference URL” (
Noticeable is that DBpedia and OpenCyc contain many
E.g.,
We now summarize the results of the evaluations presented in this section.
Syntactic validity of RDF documents: All KGs provide syntactically valid RDF documents. Syntactic validity of Literals: In general, the KGs achieve good scores regarding the Syntactic validity of literals. Although OpenCyc comprises over 1M literals in total, these literals are mainly labels and descriptions which are not formatted in a special format. For YAGO, we detected about 519K syntactic errors (given 1M literal values) due to the usage of wildcards in the date values. Obviously, the syntactic invalidity of literals is accepted by the publishers in order to keep the number of relations low. In case of Wikidata, some invalid literals such as the ISBN have been corrected in newer versions of Wikidata. This indicates that knowledge in Wikidata is curated continuously. For DBpedia, comments next to the values to be extracted (such as ISBN) in the infoboxes of Wikipedia led to inaccurately extracted values. Semantic validity of triples: All considered KGs scored well regarding this metric. This shows that KGs can be used in general without concerns regarding the correctness. Note, however, that evaluating the semantic validity of facts is very challenging, since a reliable ground truth is needed. Trustworthiness on KG level: Based on the way of how data is imported and curated, OpenCyc and Wikidata can be trusted the most. Trustworthiness on statement level: Here, especially good values are achieved for Freebase, Wikidata, and YAGO. YAGO stores per statement both the source and the extraction technique, which is unique among the KGs. Wikidata also supports to store the source of information, but only around 1.3% of the statements have provenance information attached. Note, however, that not every statement in Wikidata requires a reference and that it is hard to evaluate which statements lack such a reference. Using unknown and empty values: Wikidata and Freebase support the indication of unknown and empty values. Check of schema restrictions during insertion of new statements: Since Freebase and Wikidata are editable by community members, simple consistency checks are made during the insertion of new facts in the user interface. Consistency of statements w.r.t. class constraints: Freebase and Wikidata do not specify any class constraints via Consistency of statements w.r.t. relation constraints: The inconsistencies of all KGs regarding the range indications of relations are mainly due to inconsistently used data types (e.g., Regarding the constraint of functional properties, the relation Creating a ranking of statements: Only Wikidata supports a ranking of statements. This is in particular worthwhile in case of statements which are only temporally limited valid. Schema completeness: Wikidata shows the highest degree of schema completeness. Also for DBpedia, OpenCyc, and YAGO we obtain results which are presumably acceptable in most cross-domain use cases. While DBpedia classes were sometimes missing in our evaluation, the DBpedia relations were covered considerably well. OpenCyc lacks some relations of the gold standard, but the classes of the gold standard were existing in OpenCyc. While the YAGO classes are peculiar in the sense that they are connected to WordNet synsets, it is remarkable that YAGO relations are often kept very abstract so that they can be applied in different senses. Freebase shows considerable room for improvement concerning the coverage of typical cross-domain classes and relations. Note that Freebase classes are belonging to different domains. Hence, it is difficult to find related classes if they are not in the same domain. Column completeness: DBpedia and Freebase show the best column completeness values, i.e., in those KGs the predicates used by the instances of each class are on average frequently used by all of those class instances. We can name data imports as one reason for it. Population completeness: Not very surprising is the fact that all KGs show a higher degree of completeness regarding well-known entities than regarding rather unknown entities. Especially Wikidata shows an excellent performance for both well-known and rather unknown entities. Timeliness frequency of the KG: Only Wikidata provides the highest fulfillment degree for this criterion, as it is continuously updated and as the changes are immediately visible and queryable by users. Specification of the validity period of statements: In YAGO, Freebase, and Wikidata the temporal validity period of statements (e.g., term of office) can be specified. Specification of the modification date of statements: Only Freebase keeps the modification dates of statements. Wikidata provides the modification date of the queried resource during URI dereferencing. Description of resources: YAGO, Wikidata, and OpenCyc contain a label for almost every entity. Surprisingly, DBpedia shows a relatively low coverage w.r.t. labels and descriptions (only 70.4%). Manual investigations suggest that the intermediate node mapping template is the main reason for that. By means of this template, intermediate nodes are introduced and instantiated, but no labels are provided for them.137 An example is
Labels in multiple languages: YAGO, Freebase, and Wikidata support hundreds of languages regarding their stored labels. Only OpenCyc contains labels merely in English. While DBpedia, YAGO, and Freebase show a high coverage regarding the English language, Wikidata does not have such a high coverage regarding English, but instead covers other languages to a considerable extent. It is, hence, not only the most diverse KG in terms of languages, but also the KG which contains the most labels for languages other than English.
Understandable RDF serialization: DBpedia, Wikidata, and YAGO provide several understandable RDF serialization formats. Freebase only provides the understandable format RDF/Turtle. OpenCyc relies only on RDF/XML, which is considered as being not easily understandable for humans.
Self-describing URIs: We can find mixed paradigms regarding the URI generation: DBpedia, YAGO, and OpenCyc rely on descriptive URIs, while Wikidata and Freebase (in part; classes and relations are identified with self-describing URIs) use generic IDs, i.e., opaque URIs.
Avoiding blank nodes and RDF reification: DBpedia, Wikidata, YAGO, and Freebase are the KGs which use reification, i.e., which formulate statements about statements. There are different ways of implementing reification [25]. DBpedia, Wikidata, and Freebase use n-ary relations, while YAGO uses N-Quads, creating so-called named graphs.
Provisioning of several serialization formats: Many KGs provide RDF in several serialization formats. Freebase is the only KG providing data in the serialization format RDF/Turtle only.
Using external vocabulary: DBpedia and Wikidata show high degrees of external vocabulary usage. In DBpedia the RDF, RDFS, and OWL vocabularies are used. Wikidata has a high external vocabulary ratio, since there exist many language labels and descriptions (modeled via
Interoperability of proprietary vocabulary: We obtained low fulfillment scores regarding this criterion. OpenCyc shows the highest value. We can mention as reason for that the fact that half of all OpenCyc classes exhibit at least one
While DBpedia has equivalence statements to external classes for almost every second class, only 6.3% of all relations have equivalence relations to relations outside the DBpedia namespace.
Wikidata shows a very low interlinking degree of classes to external classes and of relations to external relations.
Dereferencing possibility of resources: Resources in DBpedia, OpenCyc, and YAGO can be dereferenced without considerable issues. Wikidata uses predicates derived from relations that are not dereferencable at all, as well as blank nodes. For Freebase we measured a quite considerable amount of dereferencing failures due to server errors and unknown URIs. Note also that Freebase required an API key for a large amount of requests.
Availability of the KG: While all other KGs showed almost no outages, YAGO shows a noteworthy instability regarding its online availability. We measured around 100 outages for YAGO in a time interval of 8 weeks, taking on average 3.5 hours.
Provisioning of public SPARQL endpoint: DBpedia, Wikidata, and YAGO provide a SPARQL endpoint, while Freebase and OpenCyc do not. Noteworthy is that the Wikidata SPARQL endpoint has a maximum execution time per query of 30 seconds. This might be a bottleneck for some queries.
Provisioning of an RDF export: RDF exports are available for all KGs and are provided mostly in N-Triples and Turtle format.
Support of content negotiation: DBpedia, Wikidata, and YAGO correctly return RDF data based on content negotiation. Both OpenCyc and Freebase do not support any content negotiation. While OpenCyc only provides data in RDF/XML, Freebase only returns data with
Linking HTML sites to RDF serializations: All KGs except OpenCyc interlink the HTML representations of resources with the corresponding RDF representations.
Provisioning of KG metadata: Only DBpedia and OpenCyc integrate metadata about the KG in some form. DBpedia has the VoID vocabulary integrated, while OpenCyc reveals the current KG version as machine-readable metadata.
Provisioning machine-readable licensing information: Only DBpedia and Wikidata provide licensing information about their KG data in machine-readable form.
Interlinking via
Validity of external URIs: The links to external Web resources are for all KGs valid in most cases. DBpedia and OpenCyc contain many
We now propose a framework for selecting the most suitable KG (or a set of suitable KGs) for a given concrete setting, based on a given set of KGs
In Step 1, the preselection criteria and the weights for the criteria are specified. The preselection criteria can be both quality criteria or general criteria and need to be selected dependent on the use case. The Timeliness frequency of the KG is an example for a quality criterion. The license under which a KG is provided (e.g., CC0 license) is an example for a general criterion. After weighting the criteria, in Step 2 those KGs are neglected which do not fulfill the preselection criteria. In Step 3, the fulfillment degrees of the remaining KGs are calculated and the KG with the highest fulfillment degree is selected. Finally, in Step 4 the result can be assessed w.r.t. qualitative aspects (besides the quantitative assessments using the DQ metrics) and, if necessary, an alternative KG can be selected for being applied for the given scenario.

Proposed process for using our KG recommendation framework.
Description of the use case: The publisher BBC wants to enrich news articles with fact sheets providing relevant information about musicians mentioned in the articles. In order to obtain more details about the musicians, the user can leave the news section and access the musicians section where detailed information is provided, including a short description, a picture, the birth date, and the complete discography for each musician. For being able to integrate the musicians information into the articles and to enable such a linking, editors shall tag the article based on a controlled vocabulary.
Framework with an example weighting which would be reasonable for a user setting as given in [31]
The KG Recommendation Framework can be applied as follows:
Requirements analysis:
Preselection criteria: According to the scenario description [31], the KG in question should (i) be actively curated and (ii) contain an appropriate amount of media entities. Given these two criteria, a satisfactory and up-to-date coverage of both old and new musicians is expected.
Weighting of DQ criteria: Based on the preselection criteria, an example weighting of the DQ metrics for our use case is given in Table 15. Note that this is only one example configuration and the assignment of the weights is subjective to some degree. Given the preselection criteria, the criterion Timeliness frequency of the KG and the criteria of the DQ dimension Completeness are emphasized. Furthermore, the criteria Dereferencing possibility of resources and Availability of the KG are important, as the KG shall be available online, ready to be queried.138
We assume that in this use case rather the dereferencing of HTTP URIs than the execution of SPARQL queries is desired.
Preselection: Freebase and OpenCyc are not considered any further, since Freebase is not being updated anymore and since OpenCyc contains only around 4K entities in the media domain.
Quantitative assessment: The overall fulfillment score for each KG is calculated based on the formula presented in Section 3.1. The result of the quantitative KG evaluation is presented in Table 15. By weighting the criteria according to the constraints, Wikidata achieves the best rank, closely followed by DBpedia. Based on the quantitative assessment, Wikidata is recommended by the framework.
Qualitative assessment: The high population completeness in general and the high coverage of entities in the media domain in particular give Wikidata advantage over the other KGs. Furthermore, Wikidata does not require that there is a Wikipedia article for each entity. Thus, missing Wikidata entities can be added by the editors directly and are then available immediately.
The use case requires to retrieve also detailed information about the musicians from the KG, such as a short description and a discography. DBpedia tends to store more of that data, especially w.r.t. discography. A specialized database like MusicBrainz provides even more data about musicians than DBpedia, as it is not limited to the Wikipedia infoboxes. While DBpedia does not provide any links to MusicBrainz, Wikidata stores around 120K equivalence links to MusicBrainz that can be used to pull more data. In conclusion, Wikidata, especially in the combination with MusicBrainz, seems to be an appropriate choice for the use case. In this case, the qualitative assessment confirms the result of the quantitative assessment.
The use case shows that our KG recommendation framework enables users to find the most suitable KG and is especially useful in giving an overview of the most relevant criteria when choosing a KG. However, applying our framework to the use case also showed that, besides the quantitative assessment, there is still a need for a deep understanding of commonalities and difference of the KGs in order to make an informed choice.
Linked data quality criteria
Overview of related work regarding data quality criteria for KGs
Overview of related work regarding data quality criteria for KGs
Zaveri et al. [47] provide a conceptual framework for quality assessment of linked data based on quality criteria and metrics which are grouped into quality dimensions and categories and which are based on the framework of Wang et al. [45]. Our framework is also based on Wang’s dimensions and extended by the dimensions Consistency [9], Licensing and Interlinking [47]. Furthermore, we reintroduce the dimensions Trustworthiness and Interoperability as a collective term for multiple dimensions.
Many published DQ criteria and metrics are rather abstract. We, in contrast, selected and developed concrete criteria which can be applied to any KG in the Linked Open Data cloud. Table 16 shows which of the metrics introduced in this article have already been used to some extent in existing literature. In summary, related work mainly proposed generic guidelines for publishing Linked Data [24], introduced DQ criteria with corresponding metrics (e.g., [18,28]) and criteria without metrics (e.g., [27,39]). 27 of the 34 criteria introduced in this article have been introduced or supported in one way or another in earlier works. The remaining seven criteria, namely Trustworthiness on KG level,
Pipino et al. [39] introduce the criteria Schema completeness, Column completeness and Population completeness in the context of databases. We introduce those metrics for KGs and apply them, to the best of our knowledge, the first time on the KGs DBpedia, Freebase, OpenCyc, Wikidata, and YAGO.
OntoQA [43] introduces criteria and corresponding metrics that can be used for the analysis of ontologies. Besides simple statistical figures such as the average of instances per class, Tartir et al. introduce also criteria and metrics similar to our DQ criteria Description of resources,
Based on a large-scale crawl of RDF data, Hogan et al. [27] analyze quality issues of published RDF data. Later, Hogan et al. [28] introduce further criteria and metrics based on Linked Data guidelines for data publishers [24]. Whereas Hogan et al. crawl and analyze many KGs we analyze a selected set of KGs in more detail.
Heath et al. [24] provide guidelines for Linked Data but do not introduce criteria or metrics for the assessment of Linked Data quality. Still, the guidelines can be easily translated into relevant criteria and metrics. For instance, “Do you refer to additional access methods” leads to the criteria Provisioning of public SPARQL endpoint,
Flemming [18] introduces a framework for the quality assessment of Linked Data quality. This framework measures the Linked Data quality based on a sample of a few RDF documents. Based on a systematic literature review, criteria and metrics are introduced. Flemming introduces the criteria Labels in multiple languages,
SWIQA [20] is a quality assessment framework introduced by Fürber et al. that introduces criteria and metrics for the dimensions Accuracy, Completeness, Timeliness, and Uniqueness. In this framework, the dimension Accuracy is divided into Syntactic validity and Sematic validity as proposed by Batini et al. [6]. Furthermore, the dimension Completeness comprises Schema completeness, Column completeness and Population completeness, following Pipino et al. [39]. In this article, we make the same distinction, but in addition distinguish between RDF documents, RDF triples, and RDF literals for evaluating the Accuracy, since we consider RDF KGs.
TripleCheckMate [33] is a framework for Linked Data quality assessment using a crowdsourcing-approach for the manual validation of facts. Based on this approach, Zaveri et al. [46] and Acosta et al. [2,3] analyze both syntactic and semantic accuracy as well as the consistency of data in DBpedia.
Kontokostas et al. [32] present the test-driven evaluation framework RDFUnit for assessing Linked Data quality. This framework is inspired by the paradigm of test-driven software development. The framework introduces 17 SPARQL templates of tests that can be used for analyzing KGs w.r.t. Accuracy and Consistency. Note that those tests can also be used for evaluating external constraints that exist due to the usage of external vocabulary. The framework is applied by Kontokostas et al. on a set of KGs including DBpedia.
Duan et al. [13], Tartir [43], and Hassanzadeh [23] can be mentioned as the most similar related work regarding the evaluation of KGs using the key statistics presented in Section 5.1.
Duan et al. [13] analyze the structuredness of data in DBpedia, YAGO2, UniProt, and in several benchmark data sets. To that end, the authors use simple statistical key figures that are calculated based on the corresponding RDF dumps. In contrast to that approach, we use SPARQL queries to obtain the figures, thus not limiting ourselves to the N-Tripel serialization of RDF dump files. Duan et al. claim that simple statistical figures are not sufficient to gain fruitful findings when analyzing the structuredness and differences of RDF datasets. The authors therefore propose in addition a coherence metric. Accordingly, we analyze not only simple statistical key figures but further analyze the KGs w.r.t. data quality, using 34 DQ metrics.
Tartir et al. [43] introduce with the system OntoQA metrics that can be used for analyzing ontologies. More precisely, it can be measured to which degree the schema level information is actually used on instance level. An example of such a metric is the class richness, defined as the number of classes with instances divided by the number of classes without instances. SWETO, TAP, and GlycO are used as showcase ontologies.
Tartir et al. [43] and Hassanzadeh et al. [23] analyze how domains are covered by KGs on both schema and instance level. For that, Tartir et al. introduce the measure importance as the number of instances per class and their subclasses. In our case, we cannot use this approach, since Freebase has no hierarchy. Hassanzadeh et al. analyze the coverage of domains by listing the most frequent classes with the highest number of instances as a table. This gives only little overview of the covered domains, since instances can belong to multiple classes in the same domain, such as
Conclusion
Freely available knowledge graphs (KGs) have not been in the focus of any extensive comparative study so far. In this survey, we defined a range of aspects according to which KGs can be analyzed. We analyzed and compared DBpedia, Freebase, OpenCyc, Wikidata, and YAGO along these aspects and proposed a framework as well as a process to enable readers to find the most suitable KG for their settings.
Footnotes
Acknowledgements
This work was carried out with the support of the German Federal Ministry of Education and Research (BMBF) within the Software Campus project SUITE (Grant 01IS12051).
The research leading to these results has received funding from the European Union Seventh Framework Programme (FP7/2007–2013) under grant agreement No. 611346.