
Abstract
In recent years, knowledge graphs (KGs) have been considered pyramids of interconnected data enriched with semantics for complex decision-making. The potential of KGs and the demand for interpretability of machine learning (ML) models in diverse domains (e.g., healthcare) have gained more attention. The lack of model transparency negatively impacts the understanding and, in consequence, interpretability of the predictions made by a model. Data-driven models should be empowered with the knowledge required to trace down their decisions and the transformations made to the input data to increase model transparency. In this paper, we propose InterpretME, a tool that using KGs, provides fine-grained representations of trained ML models. An ML model description includes data – (e.g., features’ definition and SHACL validation) and model-based characteristics (e.g., relevant features and interpretations of prediction probabilities and model decisions). InterpretME allows for defining a model’s features over data collected in various formats, e.g., RDF KGs, CSV, and JSON. InterpretME relies on the SHACL schema to validate integrity constraints over the input data. InterpretME traces the steps of data collection, curation, integration, and prediction; it documents the collected metadata in the InterpretME KG. InterpretME is published in GitHub1?> and Zenodo2?>. The InterpretME framework includes a pipeline for enhancing the interpretability of ML models, the InterpretME KG, and an ontology to describe the main characteristics of trained ML models; a PyPI library of InterpretME is also provided3?>. Additionally, a live code4?>, and a video5?> demonstrating InterpretME in several use cases are also available.
Introduction
Interpretability is the degree to which humans can understand the decisions made by computational frameworks. Specifically, in Artificial Intelligence (AI), the higher the interpretability of predictive models, the easier for humans to understand why a model makes certain decisions. The recent advancements and complexity of machine learning (ML) methods have demonstrated their success in forecasting complex problems (e.g., disease diagnosis or progression [29,31]). Unfortunately, they are often opaque and do not offer interpretations for their predictions, and it is not always possible to comprehend the results. Interpretable predictive models have rapidly become a relevant problem [5]. Nevertheless, although various tools aim to interpret the algorithmic decisions of ML models [27,34], they are incapable of capturing the knowledge required to translate a model’s insights into the application domain. On the contrary, KGs encode data and knowledge; they, together with domain ontologies (e.g., ML Schema [30]), represent building blocks for increasing the understanding of the behavior and effects of a predictive model.

InterpretME resorts to SHACL for providing a meaningful description of a target entity (as shown in Fig. 1). The target entity is a specific node from the input KG or CSV, and JSON file that is of particular interest of a predictive model. Figure 1 depicts a target entity representing a lung cancer patient (
InterpretME is designed to work with both KGs (accessible via Web interfaces, e.g., SPARQL endpoints), and datasets in various formats (e.g., CSV, and JSON). InterpretME models – as factual statements – everything learned while training an ML model and its interpretation; these statements compose the InterpretME KG. To retrieve data for a predictive pipeline, the user must provide either a SPARQL endpoint or the path to a dataset. If the input data is retrieved from KGs, InterpretME can validate constraints expressed in SHACL, align the InterpretME KG to the input KGs, and execute federated queries. On the other hand, if the input data is collected from datasets in CSV, and JSON formats, a user can also explore interpretations with the InterpretME KG. The latest version of InterpretME is customized for supervised ML models (e.g., decision trees and random forests) and interpretable tools (e.g., LIME). InterpretME is publicly available as a resource in GitHub1 and Zenodo2; a PyPI library is also available3. We empirically evaluate InterpretME in real-world KGs regarding execution time, interpretation quality, and traceability of target entities. The observed results reveal the key role of Semantic Web technologies in the interpretation of the outcomes of predictive models. As a result, InterpretME assists ML model users by allowing for exploring – using SPARQL queries – metadata represented as factual statements in the InterpretME KG.
The rest of the paper is structured as follows: Section 2 describes the main concepts and motivates our work. Section 3 defines the InterpretME architecture, while Section 4 reports the results of our experimental studies. Section 5 presents the main characteristics of InterpretME as a resource. Section 6 discusses the state of the art, and our conclusions and future work are outlined in Section 7.
Main concepts
Predictive modeling frameworks

Predictive modeling conceptualization by De Bie et al. [5]. It comprises four stages: Data Engineering, Data Exploration, Model Building, and Exploitation. They offer three forms of automation: Mechanization, Composition, and Assistance.
Predictive Modeling comprises methods to forecast future outcomes based on data encoding what has happened in the past (e.g., historical data) and what is currently happening (e.g., current data). Predictive modeling resorts to a variety of models and algorithms (e.g., random forest, gradient boosting model or decision trees) to solve predictive problems (e.g., classification or outlier detection) [32]. Despite the large spectrum of mature models and well-defined problems, predictive modeling is a complex task that requires user expertise in the domain context and modeling. De Bie et al. [5] conceptualizes predictive modeling in four stages, as depicted in Fig. 2.
De Bie et al. [5] identify three forms of automation:
Current developments in automation have mainly impacted the stages of Model Building and Exploitation. In particular, Automated Machine Learning (AutoML) systems (e.g., AutoML7 and AutoWeka [24]) successfully implement mechanization, and can automatize the processes of model building and feature selection, and the optimization of the hyperparameters and target functions. Furthermore, interactive tools like RapidMiner,8 the Local Interpretable Model-agnostic Explanations (LIME) framework [34], and SHapely Additive exPlanations (SHAP) [27] provide assistance by reporting explanations of a model’s results. Specifically, LIME relies on local surrogate models to explain the prediction of each entity of a test dataset. It computes – for the tested entities – the feature contribution for each target class and the prediction probability. In general, LIME is independent of the original algorithm given to the model and works locally to provide explanations for the prediction relative to each instance. LIME tries to fit the local model using sample data points that are similar to the instance being explained.
The Semantic Web [4] aims at humans and machines working cooperatively in data exchange. Technologies capable of encoding semantics have been defined to achieve this goal. One of these technologies is the Resource Description Framework (RDF) [26], i.e., the W3C standard for publishing and exchanging data over the web. An RDF graph
SPARQL [33] is the W3C recommendation language to query RDF graphs. SPARQL 1.1 [17] provides the
The Shapes Constraint Language (SHACL) [23] is the W3C recommendation language to define integrity constraints over RDF data. SHACL integrity constraints are expressed in RDF and modeled as a network of shapes, called shape schema. A shape consists of An InterpretME KG is a heterogeneous graph where each node and edge is assigned to a type, i.e., InterpretME KG = (V, E, L, T), where: InterpretME KG
Motivating example
The motivation for our work originates from the lack of automated assistance despite the great potential of integrating knowledge graphs with predictive modeling frameworks. Tracing and explaining the predictive models built over data collected from the KGs in order to provide assistance is the main goal of our tool InterpretME. An InterpretME KG comprises the vocabulary shown in Fig. 3 and is further detailed in Section 5. Even though the state-of-the-art successfully developed automated machine learning systems, through mechanization and composition, pipelines for predictive modeling are unable to generate human- and machine-readable decisions to assist users and enhance their efficiency. LIME creates human-readable interpretations for a particular predicting task. They cannot deliver factual statements about interpretations of the target entity. They also fail to take into account the target entity’s properties in the predictive model and the input KG.
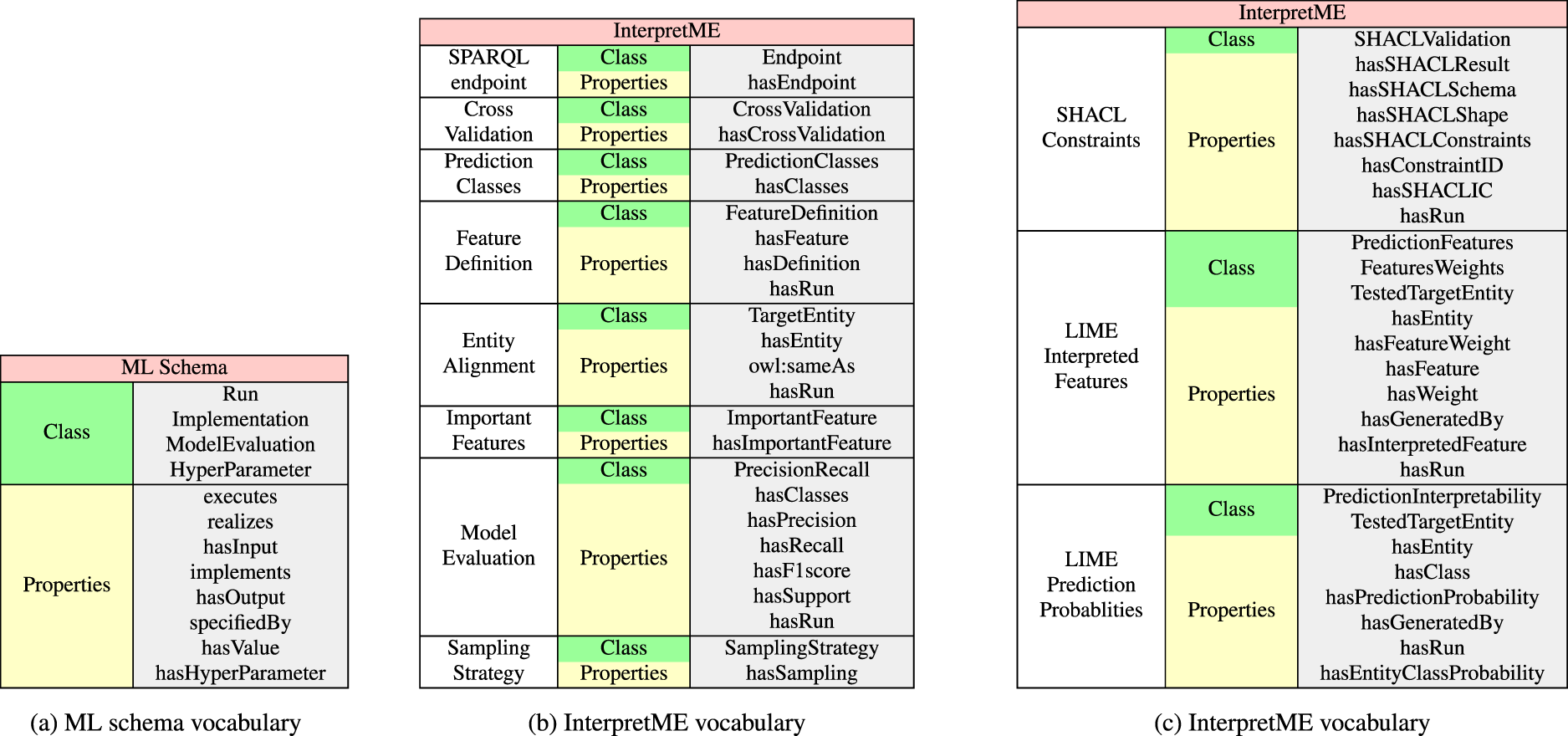

Figure 4a depicts a predictive modeling pipeline, where an automated machine learning system (e.g., AutoML) is utilized for model and feature selection, and hyperparameters’ optimization. Moreover, interpretable tools (e.g., LIME) provides interpretable results. Figure 4a illustrates the pipeline  ; an input dataset
; an input dataset  is collected from an
is collected from an  ; based on AutoML recommendations, the random forests and decision tree models are selected to implement the classification problem. Further, the interpretable surrogate tools LIME and Decision trees are utilized to provide local interpretations of each patient in the test dataset. Decision trees yield the relevant features which contribute to the model outcomes
; based on AutoML recommendations, the random forests and decision tree models are selected to implement the classification problem. Further, the interpretable surrogate tools LIME and Decision trees are utilized to provide local interpretations of each patient in the test dataset. Decision trees yield the relevant features which contribute to the model outcomes  .
.  depicts an exemplar entity where LIME determines a prediction probability of 0.7 to belong to the target class ALK (i.e., Class 0), otherwise, 0.3 target class Others (i.e., Class 1). LIME also identifies the top 10 relevant features for the target entity and assigns weights. These outcomes allow for understanding the quality of the implemented pipeline. Nevertheless, when they are reported to oncologists, many questions may still arise Fig. 4b:
depicts an exemplar entity where LIME determines a prediction probability of 0.7 to belong to the target class ALK (i.e., Class 0), otherwise, 0.3 target class Others (i.e., Class 1). LIME also identifies the top 10 relevant features for the target entity and assigns weights. These outcomes allow for understanding the quality of the implemented pipeline. Nevertheless, when they are reported to oncologists, many questions may still arise Fig. 4b:
Tracing metadata in machine learning pipelines
We aim to collect metadata during the different stages of a predictive model pipeline. Figure 5 shows, in a pictorial view, the characteristics of the data collected towards the improvement of automation Assistance; this figure is based on the conceptualization of predictive modeling proposed by De Bie et al. [5] reported in Fig. 2. In the Data Engineering stage, InterpretME captures metadata from the input KG (e.g., features’ definition, endpoint, and target classes) and records the SHACL constraints, used for data validation. During Model Building, suggestions from AutoML systems can be considered. InterpretME traces the optimized hyperparameters and estimated features’ relevancy, and records the model performance metric outcomes (e.g., precision) for a particular run. SHACL validation reports are also included in the InterpretME KG. InterpretME also exploits decision trees and visualizes the validation report to enhance exploration. Lastly, for Exploitation, InterpretME aligns target entities with entities in KGs, where the model’s features are defined. These facts allow for

Figure 6 depicts the InterpretME architecture. InterpretME is a tool for fine-grained representations of the main characteristics of a trained predictive modeling framework. The architecture of InterpretME deals with training the predictive models and collecting information generated as output of predictive models (i.e., model accuracy, list of important features, prediction probabilities, and classified classes for each instance). InterpretME provides assistance (Fig. 5) to the user by tracing metadata to generate instances of the InterpretME KG. Federated queries are obtained on top of the InterpretME KG and the input KG to trace back, and answers questions in Fig. 4b. InterpretME takes a JSON file as input (i.e., endpoints of KGs, features’ definition, target definition, SHACL constraints, sampling strategy, and class definition)9; a SPARQL query is generated based on the feature definition given by the user and the query is used to retrieve the application domain data from the input KGs. Users perform the step of providing a SPARQL endpoint or path to a dataset and its corresponding feature definition in the input JSON file. InterpretME performs additional steps automatically, such as extracting data based on the query, running predictive models, saving prediction results, and so on. The structure of the query enables entities in the input KGs to be aligned to the identifiers of the entities in the ML models’ datasets. These alignments facilitate the SHACL validation and federated query processing over the InterpretME KG and the input KGs.
 InterpretME evaluates the SHACL constraints over the nodes of the input KGs and outputs a validation report per constraint and target entity. These results indicate whether an entity validates or invalidates the constraints defined by the user. The validation reports states the validity of data used by the predictive models10. Thus, SHACL constraints are a crucial part of the InterpretME KG. Their evaluation identifies if a particular entity is violating the integrity constraints, where True represents that the particular entity is valid, inversely represented by False.
InterpretME evaluates the SHACL constraints over the nodes of the input KGs and outputs a validation report per constraint and target entity. These results indicate whether an entity validates or invalidates the constraints defined by the user. The validation reports states the validity of data used by the predictive models10. Thus, SHACL constraints are a crucial part of the InterpretME KG. Their evaluation identifies if a particular entity is violating the integrity constraints, where True represents that the particular entity is valid, inversely represented by False.
 Preprocessing includes transforming data collected from the input KGs or from CSV, and JSON files into a form that can be used in the training of a predictive model. Many machine learning models cannot handle categorical values directly, InterpretME generates one hot-encodings using the Python library sklearn to transform the model’s categorical features into binary features that can be further used for predictive models11; it makes training data more expressive, and can be easily re-scaled. Also, the target class can be defined in InterpretME. Sampling strategies (e.g., under-sampling or over-sampling) are also utilized to reduce data imbalance so that the machine learning algorithms can perform better. Many machine learning algorithms, like decision trees, random forests, and neural networks resort to class distribution in the training dataset to compute the probability of instances in each class when the model will be used to make predictions. Model configuration (during Preprocessing) can be done based on automated systems’ selections (e.g., AutoML/OpenML) or based on a user’s preferences. Automated tools (e.g., Optuna [2]) can be used to generate optimized hyperparameters for predictive models.
Preprocessing includes transforming data collected from the input KGs or from CSV, and JSON files into a form that can be used in the training of a predictive model. Many machine learning models cannot handle categorical values directly, InterpretME generates one hot-encodings using the Python library sklearn to transform the model’s categorical features into binary features that can be further used for predictive models11; it makes training data more expressive, and can be easily re-scaled. Also, the target class can be defined in InterpretME. Sampling strategies (e.g., under-sampling or over-sampling) are also utilized to reduce data imbalance so that the machine learning algorithms can perform better. Many machine learning algorithms, like decision trees, random forests, and neural networks resort to class distribution in the training dataset to compute the probability of instances in each class when the model will be used to make predictions. Model configuration (during Preprocessing) can be done based on automated systems’ selections (e.g., AutoML/OpenML) or based on a user’s preferences. Automated tools (e.g., Optuna [2]) can be used to generate optimized hyperparameters for predictive models.
 Predictive Modeling. An automated model can also perform stratified shuffle split cross-validation with random forest, and identify the relevant features; they are used to train a decision tree classifier to predict and visualize the outcomes of the predictive models, and report on precision and accuracy12.
Predictive Modeling. An automated model can also perform stratified shuffle split cross-validation with random forest, and identify the relevant features; they are used to train a decision tree classifier to predict and visualize the outcomes of the predictive models, and report on precision and accuracy12.
 Interpretation is utilized to enhance the understanding of the trained predictive model. Also, a visualization of the decision tree can be obtained with associated constraints. This module provides more insights of a validated/invalidated feature, and interpretable surrogate tools like LIME [34] (as in Fig. 4a) yields the most relevant features and local explanations list. They reflect the contribution of each feature to the prediction.
Interpretation is utilized to enhance the understanding of the trained predictive model. Also, a visualization of the decision tree can be obtained with associated constraints. This module provides more insights of a validated/invalidated feature, and interpretable surrogate tools like LIME [34] (as in Fig. 4a) yields the most relevant features and local explanations list. They reflect the contribution of each feature to the prediction.
 Semantification is a module of InterpretME, where mapping rules are defined with the RDF Mapping Language (RML) [8] using the data collected from the predictive models. RML expresses – using triples maps – the conversion of raw data, e.g., JSON, CSV, and XML, into RDF KGs. RML states correspondences between traced metadata and factual statements in the InterpretME KG. Listing 3.3 demonstrates an example of an RML triples map where, the
Semantification is a module of InterpretME, where mapping rules are defined with the RDF Mapping Language (RML) [8] using the data collected from the predictive models. RML expresses – using triples maps – the conversion of raw data, e.g., JSON, CSV, and XML, into RDF KGs. RML states correspondences between traced metadata and factual statements in the InterpretME KG. Listing 3.3 demonstrates an example of an RML triples map where, the
 During Tracing, SPARQL queries can be executed to explore the InterpretME results of a particular target entity. Users can identify patterns and correlations between the given features and also perform statistical analysis of a particular target entity. The InterpretME KG provides clarification and eases the interpretation of the model’s prediction of a particular entity aligned with the SHACL validation results.
During Tracing, SPARQL queries can be executed to explore the InterpretME results of a particular target entity. Users can identify patterns and correlations between the given features and also perform statistical analysis of a particular target entity. The InterpretME KG provides clarification and eases the interpretation of the model’s prediction of a particular entity aligned with the SHACL validation results.
 Exploration of Federated KGs. Query processing allows for querying the InterpretME KG and the input KGs (if there is any). A user is involved in executing federated SPARQL queries to gain more insights from the predictive model’s decision. Mostly results of interpretable tools are hard to interpret and understand the characteristics of target entity’s behavior in predictive models. As a result, the advantage of comparing the predictive model’s characteristics in the InterpretME KG to the characteristics of a specific entity in the input KGs is obtained by using query processing. Thus, a user can trace back via query federation to interpret the results for a specific target entity with input characteristics aligned with SHACL validation results. Exemplar queries are shown in GitHub13.
Exploration of Federated KGs. Query processing allows for querying the InterpretME KG and the input KGs (if there is any). A user is involved in executing federated SPARQL queries to gain more insights from the predictive model’s decision. Mostly results of interpretable tools are hard to interpret and understand the characteristics of target entity’s behavior in predictive models. As a result, the advantage of comparing the predictive model’s characteristics in the InterpretME KG to the characteristics of a specific entity in the input KGs is obtained by using query processing. Thus, a user can trace back via query federation to interpret the results for a specific target entity with input characteristics aligned with SHACL validation results. Exemplar queries are shown in GitHub13.

To exemplify different components of the InterpretME architecture, we have used the following running example (Fig. 7). In our GitHub repository, we provide a comparable example with the
 The Lung Cancer KG integrates the features’ and class target definitions about lung cancer patients; their constraints are defined in terms of SHACL. Features’ definitions are classified into independent and dependent variables. Independent variables are features that the user selects for analyzing the model’s prediction. On the other hand, a dependent variable is a feature under investigation that is expected to change in response to changes in the independent variable. They are used later in the predictive modeling pipeline and are defined as follows:
The Lung Cancer KG integrates the features’ and class target definitions about lung cancer patients; their constraints are defined in terms of SHACL. Features’ definitions are classified into independent and dependent variables. Independent variables are features that the user selects for analyzing the model’s prediction. On the other hand, a dependent variable is a feature under investigation that is expected to change in response to changes in the independent variable. They are used later in the predictive modeling pipeline and are defined as follows:

where
 Considering our running example in Fig. 7, the SHACL shapes represent integrity constraints. A SHACL schema defines integrity constraints, used by InterpretME for validating results and for uncovering their impact on a model’s decisions. Here, the “constraint”: “Afatinib is not recommended for NSCLC EGFR negative (hasDrug)” is applied over the extracted data from the input KG. The above constraint states a medical protocol that Afatinib is a drug that is not recommended for a patient being EGFR negative. Figure 7 depicts the traced metadata about SHACL validation, i.e., the patient lc: 1501042 with EGFR positive satisfies the constraint, an entity alignment is performed to trace the original entity of the input KG with SHACL validation results.
Considering our running example in Fig. 7, the SHACL shapes represent integrity constraints. A SHACL schema defines integrity constraints, used by InterpretME for validating results and for uncovering their impact on a model’s decisions. Here, the “constraint”: “Afatinib is not recommended for NSCLC EGFR negative (hasDrug)” is applied over the extracted data from the input KG. The above constraint states a medical protocol that Afatinib is a drug that is not recommended for a patient being EGFR negative. Figure 7 depicts the traced metadata about SHACL validation, i.e., the patient lc: 1501042 with EGFR positive satisfies the constraint, an entity alignment is performed to trace the original entity of the input KG with SHACL validation results.
 The preprocessed and sampled data with optimized hyperparameters is then fed to the automated tools for model building (e.g., ensemble learning) to perform the predictive task. Here, the automated model can also perform stratified shuffle split cross-validation with models like Random forest, AdaBoost classifier, Gradient boost classifier, and identify the relevant features; they are used to train a decision tree classifier to predict and visualize the outcomes
12
. InterpretME stores the metadata about the evaluation of the model for a particular run.
The preprocessed and sampled data with optimized hyperparameters is then fed to the automated tools for model building (e.g., ensemble learning) to perform the predictive task. Here, the automated model can also perform stratified shuffle split cross-validation with models like Random forest, AdaBoost classifier, Gradient boost classifier, and identify the relevant features; they are used to train a decision tree classifier to predict and visualize the outcomes
12
. InterpretME stores the metadata about the evaluation of the model for a particular run.
 The trained predictive model in
The trained predictive model in  can be visualized by means of Decision trees; they can be visualized with SHACL constraints to observe which subtree validates or invalidates the protocol16. To understand the predictive model’s outcomes, InterpretME resorts to interpretable tools, e.g., LIME, to provide a local explanation of each entity. LIME provides the prediction probability of the target class ALK (i.e., Class 0) as 0.65 and target class Others (i.e., Class 1) as 0.35. For example, Fig. 7 demonstrates that the target entity intr:1501042 has a prediction probability of 0.35 for class Others (i.e., Class 1) interpreted by LIME. The relevant features list is often used to illustrate which features may cause a change in the prediction of the trained model. LIME results are also represented in the InterpretME KG; a user can utilize SPARQL queries to perform statistical analyses over these factual statements.
can be visualized by means of Decision trees; they can be visualized with SHACL constraints to observe which subtree validates or invalidates the protocol16. To understand the predictive model’s outcomes, InterpretME resorts to interpretable tools, e.g., LIME, to provide a local explanation of each entity. LIME provides the prediction probability of the target class ALK (i.e., Class 0) as 0.65 and target class Others (i.e., Class 1) as 0.35. For example, Fig. 7 demonstrates that the target entity intr:1501042 has a prediction probability of 0.35 for class Others (i.e., Class 1) interpreted by LIME. The relevant features list is often used to illustrate which features may cause a change in the prediction of the trained model. LIME results are also represented in the InterpretME KG; a user can utilize SPARQL queries to perform statistical analyses over these factual statements.
 Traced metadata are semantified using RML. RML mapping rules specify the role of transforming collected metadata into RDF triples for the InterpretME KG17. The unified schema of InterpretME represents the meaning of data in the InterpretME KG18. The following RML syntax is used to define one of the mapping rules:
Traced metadata are semantified using RML. RML mapping rules specify the role of transforming collected metadata into RDF triples for the InterpretME KG17. The unified schema of InterpretME represents the meaning of data in the InterpretME KG18. The following RML syntax is used to define one of the mapping rules:

SDM-RDFizer [21] integrates entities collected during the training of a ML model into the InterpretME KG as factual statements. RML provides a declarative definition of the classes and properties of the InterpretME ontology and ML schema to the collected entities. As a result, the InterpretME KG comprises machine and human statements that document the trained ML behavior. The generated RDF data is uploaded to an instance of Virtuoso. Entities in the InterpretME KG and the input KGs are aligned to ensure traceability. InterpretME can accept input from multiple KGs and therefore the process of entity alignment as shown in Fig. 8 plays a vital role. The federation of KGs requires the identification of a specific entity, as well as the source of the entity. As a result, the URI of an entity in the input KGs differs from the URI in the InterpretME KG. The InterpretME federated query engine allows for tracing back the ML models’ results, i.e., main properties of target entities, LIME prediction probabilities, and SHACL validation reports. InterpretME has the advantage of assessing target entities not only based on ML models but also based on the entity’s properties. Appendix includes some queries to be executed over the SPARQL endpoint of InterpretME; their answers provide insights about the behavior of the trained ML models. Additionally, a short tutorial is available to demonstrate the use of InterpretME 14 .


We evaluate InterpretME with the goal of answering the following research questions:
Statistics about input KG and InterpretME KG

Statistics about input KG and InterpretME KG
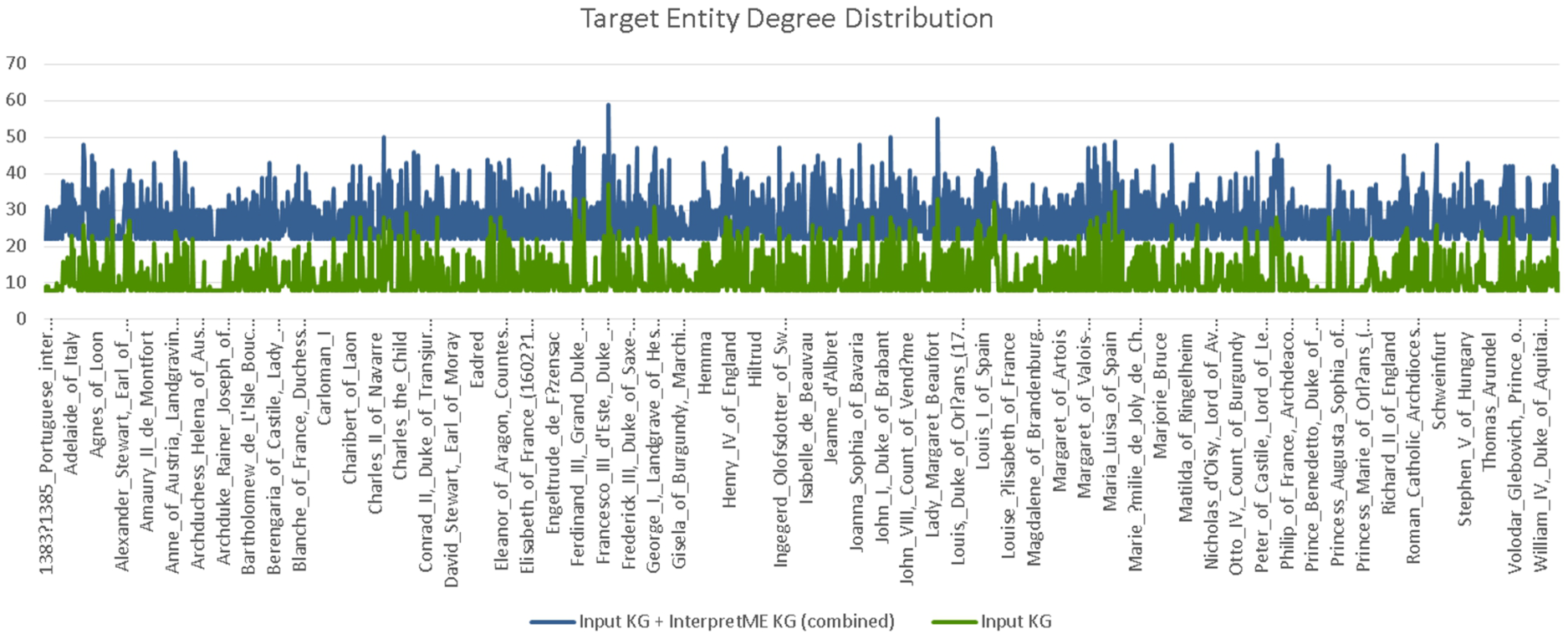
Degree distributions of the entity targets in the French royalty KG. The distribution in blue depicts the degrees of the target entities semantically enhanced with InterpretME, while green shows their original degree distribution.
In graph theory and complex networks, an entity’s degree (or the number of neighbors ignoring edges’ direction) is defined as the number of relations with other entities. Increasing the degree of an entity expresses a richer, more accurate view of the particular entity. Better context means better interpretability, not just volume. For instance, in the predictive task described in the running example Section 3.3, the predictive model states the decision of a particular target entity; it is unclear how these decisions are generated with only knowing the node of a patient and its attributes.While InterpretME tries to increase more contextual edges of a patient node via annotating the contextual information and behavior about the patient (e.g., Validation report) in the pipeline. In a nutshell, increasing the degree of a node with more context makes the interpretation not only human-understandable but also machine-readable. InterpretME traces the entities of the target classes (e.g., ALK) defined as dependent variables via SPARQL queries over the input KGs. In the InterpretME KG, these entities are described in terms of metadata collected by InterpretME components (e.g., hasInterpretedFeature, hasFeatureWeight, hasEntityClassProbability, hasPredictionProbability, hasSHACLResult, hasSHACLConstraint). For instance, Fig. 8 shows entity alignment. Given a predictive task over the Lung Cancer KG, we know the main characteristics of a target entity
Figure 9 depicts the degree distribution results of the French Royalty KG; the average number of neighbors is WithInterpretME: 27.19 (with a standard deviation of 6.13) and 11.39 (with a standard deviation of 5.06) WithoutInterpretME. InterpretME increases the number of RDF triples that describe a target entity; a user can query these triples to explore the predictive model decisions. The InterpretME KG properties are retrieved. These values of degree distribution quantify the information gained for each target entity in terms of all that InterpretME traces. The execution of queries 1 and 419 over the InterpretME KG retrieves the values of these properties for
Traceability
We evaluate InterpretME in terms of the traceability of a target entity. Table 2 reports on the average number of answers to the type of questions presented in our motivating example (Section 2). InterpretME efficiently traces the target entity and provides the user with additional information about the prediction probability of the entity. Also, it helps users to uncover relevant features of an entity that contribute to the prediction, with assigned weight distribution for the top-10 features. The federated query engine, DeTrusty [37], evaluates SPARQL queries to retrieve data from the original KG, the InterpretME KG, or both. Instances in the InterpretME KG are linked to the entity in the original KG via
Average number of answers per target entity to questions from Fig. 4a

Average number of answers per target entity to questions from Fig. 4a
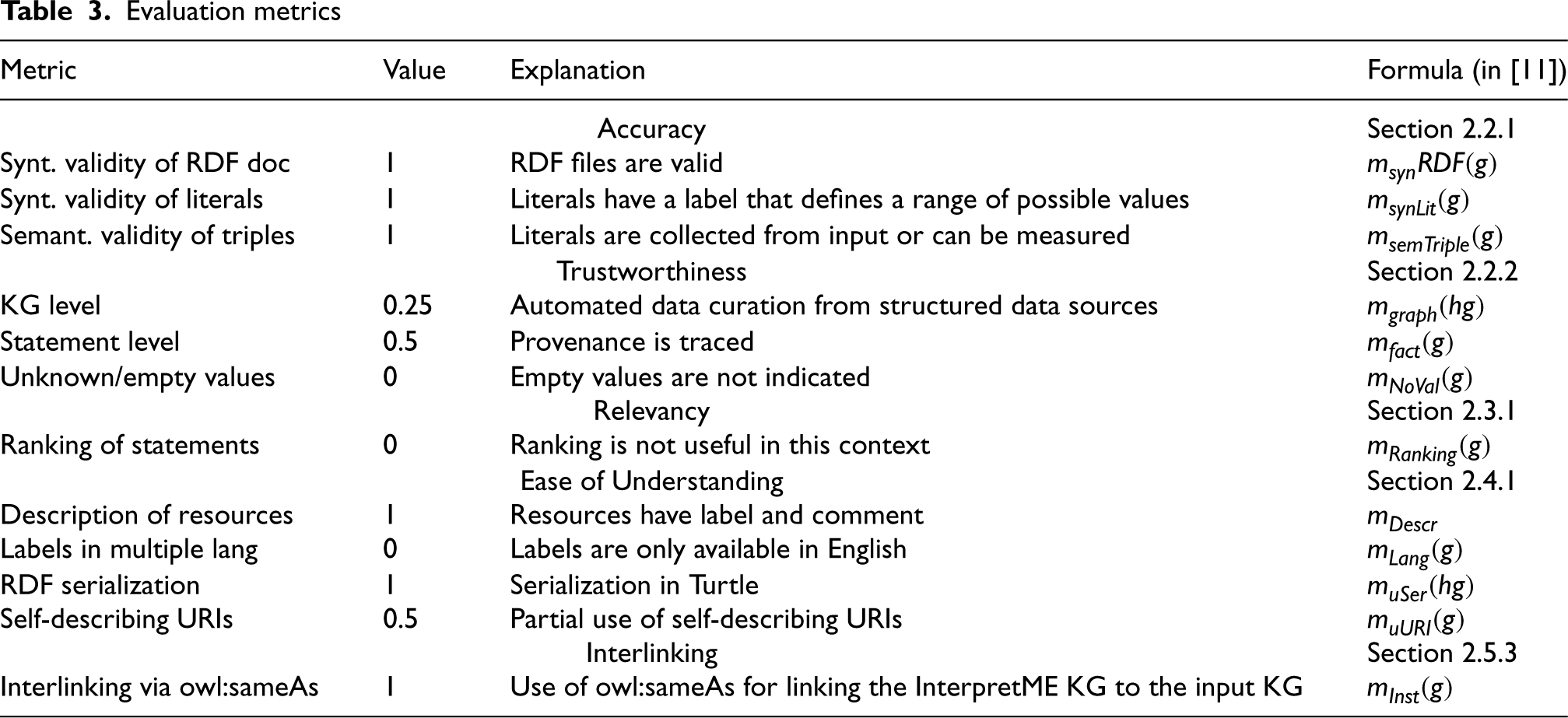
Evaluation metrics
This section answers

This section describes Fig. 10a and aims at answering
The average execution time of the first component, i.e., the SHACL validation, is 1.46 and 67.19 seconds, respectively. The second component – Preprocessing – where data is extracted and preprocessed to be given to the machine learning model, takes on average 0.30 and 0.47 seconds in the two use cases, respectively. The next component is training the model (Predictive Modeling); the average execution time is 3.14 and 4.22 seconds for the French Royalty KG and the Lung Cancer KG, respectively. Further, Interpretation component, where the decision trees for the model are generated, takes an average 1.39 and 1.92 seconds, respectively. For French Royalty, the number of target entities is slightly higher compared to the Lung Cancer KG. Thus, using LIME to generate the interpretable results requires 58.09 and 20.18 seconds in the use cases, respectively. Lastly, the Semantification of the traced metadata takes 42.87 and 15.87 seconds for the French Royalty KG and the Lung Cancer KG, respectively.
The reported results are consistent with the fact stated by Figuera et al. [12] that the SHACL validation is mainly impacted by the KG size and number of SHACL constraints. The validation of the Lung Cancer constraints takes much longer than for the French Royalty, since the Lung Cancer KG is much larger and the constraints used are more complex, e.g., we are using the concept of linked shapes for the Lung Cancer KG. As a result, the ML pipeline execution time is also impacted, as well as the generation of the InterpretME KG instances.
User study
We report the results of a user study20 (Fig. 10b) about interpretability in InterpretME. We aim to assess how each participant understands the term interpretability. Further, we conduct a user experience evaluation of the framework based on usability criteria. The goal is to answer the following questions:
During a lecture of data management, we shared the overall 12 questions to
In the
InterpretME as a tool
InterpretME is publicly available as a Python library on PyPI3. While the core of the pipeline is entirely new, InterpretME reuses available tools from the community. InterpretME pipeline() receives a JSON file as a configuration input from the user to extract all the features’ definition, SPARQL endpoints or Datasets, SHACL constraints, target classes, and sampling strategies. Features are defined in the form of independent and dependent variables, provided to the InterpretME pipeline to perform the prediction tasks. For the SHACL validation, InterpretME relies on Trav-SHACL [12] since it is capable of validating a SHACL schema against a SPARQL endpoint and scales better compared to other approaches with the same capability. InterpretME provides the Preprocessing component for data curation, optimize hyperparameters, and sampling strategy. Predictive Modeling provides binary and multi-class classification with ensemble learning techniques. Also, cross-validation and classification reports are obtained for a particular predictive model. Currently, InterpretME uses LIME [34] to create model interpretations. RML [8] is used to define the process of integrating the traced metadata into the InterpretME KG; it is semantified using SDM-RDFizer [21] (version 4.5.5 [20]), an efficient RML-compliant engine for KG creation. The RDF data is uploaded into an instance of Virtuoso 7.20.3233. The following pipeline() command executes the whole pipeline; It includes the extraction of data and metadata from the input data, validating SHACL constraints, preprocessing the data, running predictive models, semantifying the results, and populating the InterpretME KG:

The InterpretME ontology extends ML Schema [10], a vocabulary to deal with machine learning algorithms. ML Schema can be used to describe different algorithms, implementation, model evaluation, and the input and output considered by the algorithms; it also represents relationships between ML algorithms and their executions. InterpretME reuses 12 concepts in the mappings from ML Schema as shown in the Fig. 3a. They include classes

The data from the InterpretME KG – and from the input KGs – can be queried using the federated query engine DeTrusty (version 0.12.3 [37]). DeTrusty is based on MULDER [9], i.e., it uses semantic source descriptions during decomposition and planning. Rohde [36] describes the vision of incorporating the SHACL validation result into SPARQL query answers by executing the validation during query processing. While we are not providing an engine fulfilling this vision, a similar outcome can be achieved when querying the original KG together with the InterpretME KG since the SHACL validation result is part of it. InterpretME is a stand-alone framework that works locally on individual systems, with multiple runs that can be combined into a single InterpretME KG to compare interpretations. InterpretME comprises the following resources:
Related work
Tools for supporting interpretability Artificial intelligence and machine learning have gained global prominence across numerous domains, resulting in a growing demand for automated machine learning frameworks with assistance in both research and various sectors. De Bie et al. [5] discuss the challenges to achieve automated machine learning and highlight that existing tools contribute to mechanization and composition automatization, lacking support in assistance. InterpretME also aims at bridging this gap, and resorts to Semantic Web technologies to enhance users’ assistance. Lundberg et al. [27] propose an interpretation framework called SHAP based on coalition game theory (Shapely values). SHAP provides feature contributions for each individual instance, global explanations, and feature importance. Ribeiro et al. [34] present LIME, an approach for local surrogate models, which are used to explain individual predictions of a pipeline. Local surrogate models are trained to approximate the predictions of models locally, instead of training a surrogate model globally. As a result, LIME generates human-friendly explanations for target entities. However, these explanations are not machine-readable and cannot be translated into the domain application. InterpretME overcomes these limitations, and provides fine-grained representations of local interpretations which are linked to the target entities in the domain application KGs.
Semantic web technologies in machine learning Semantic Web technologies like ontologies are used to improve the accuracy of predictive models. Ristoski et al. [35] provide a comprehensive survey of the use of Semantic Web Technologies in data mining and knowledge discovery and highlights the potential benefits and challenges of the need for more efficient algorithms and tools in practice. Kulmanov et al. [25] study the role of ontologies in semantic similarity and machine learning, and present ontology embeddings as background knowledge. Further, ontologies can constrain the output of a machine learning model, i.e., making the model consistent with the axioms of the ontology. Min et al. [28] improve the performance of predictive models by using ontological adjustments, i.e., using the hierarchy of an ontology to move samples of rare classes into the next broader concept. On average, Min et al. [28] reduce the area under the receiver operating curve (AROC) by 9.0% in predicting the effectiveness of antidepressants in patients with rare conditions. Haug et al. [18] propose the combination of a large enterprise data warehouse with medical knowledge from a disease-oriented ontology. This combination allows for automating the generation of computable diagnostic models, which aim at supporting researchers in generating and evaluating tools for real-time clinical diagnosis. Similarly, InterpretME resorts to Semantic Web technologies to document ML pipelines and enhances not only accuracy but also improves interpretability.
Conclusions and future work
InterpretME enhances predictive models by incorporating metadata throughout the predictive modeling pipeline. Leveraging concepts from the ML Schema and employing a cutting-edge SHACL engine for efficient constraint validation, the InterpretME KG ensures accurate and insightful results. Our empirical observations have found that InterpretME facilitates the description of predictive model insights using factual statements and establishes links to application domain KGs, thereby bridging the gap between data meaning and predictive modeling [13].
InterpretME supports random forests, decision trees, and the LIME interpretable model in its current version. However, our future plans involve integrating additional models and tools. Additionally, we aim to establish connections between InterpretME and automated ML systems and causal KGs [22]. These enhancements will further enrich domain understanding and expand the portfolio of Semantic Web tools available for data analytics.
Footnotes
Acknowledgements
This work has been supported by the project TrustKG- Transforming Data in Trustable Insights with grant P99/2020, the EU H2020 RIA project CLARIFY (GA No. 875160) and the EraMed project P4-LUCAT (GA No. 53000015).
EU H2020 Funded project
German Funded project
EraMed project
SPARQL queries to represent statistical queries over the InterpretME KG
SPARQL query to retrieve target entity and the associated feature contributions generated by LIME SPARQL query to retrieve target class and the probability ordered in decreasing order SPARQL query to retrieve the MAX and MIN and AVG of the prediction probability generated by LIME for the target entity


These queries can be executed over the SPARQL endpoint of the InterpretME KG28 to gain some insights into the behavior of the trained predictive model. Listing 1 presents a SPARQL query that collects the information about the entities that define the class
Listing 2 depicts a SPARQL query that retrieves the count of the target entities with respect to the target class that entity is classified into and the prediction probability generated by LIME.
Listing 3 performs a SPARQL query that performs the statistical analysis of probability, i.e., MAX, MIN, AVG about the classification of target entities in a specific target class.