
Abstract
Although the link prediction problem, where missing relation assertions are predicted, has been widely researched, error detection did not receive as much attention. In this paper, we investigate the problem of error detection in relation assertions of knowledge graphs, and we propose an error detection method which relies on path and type features used by a classifier for every relation in the graph exploiting local feature selection. Furthermore, we propose an approach for automatically correcting detected errors originated from confusions between entities. Moreover, we present an approach that translates decision trees trained for relation assertion error detection into SHACL-SPARQL relation constraints. We perform an extensive evaluation on a variety of datasets comparing our error detection approach with state-of-the-art error detection and knowledge completion methods, backed by a manual evaluation on DBpedia and NELL. We evaluate our error correction approach results on DBpedia and NELL and show that the relation constraint induction approach benefits from the higher expressiveness of SHACL and can detect errors which could not be found by automatically learned OWL constraints.
Introduction
Many of the knowledge graphs published as Linked Open Data have been created from semi-structured or unstructured sources. The sheer size of many of such knowledge graphs, e.g.: DBpedia, NELL, Wikidata, YAGO, do not allow for manual curation, and, instead, require the use of heuristics. Such heuristics, in turn, allow for the automatic or semi-automatic creation of large-scale knowledge graphs, but do not guarantee that the resulting knowledge graphs are free from errors. In addition, Wikipedia, which serves as source for DBpedia and YAGO, is estimated to have 2.8% of its statements wrong [70], which add up to the error caused by the extraction heuristics. Therefore, automatic approaches to detect wrong statements are an important tool for the improvement of knowledge graph quality.
Incompleteness is another major problem of most knowledge graphs. Automatic knowledge graph completion has been widely researched [46], with a variety of methods proposed, including embedding models. Although such methods can also be trivially employed for error detection, their performance has not yet been extensively evaluated on the task.
Many existing large-scale error detection methods rely exclusively on the types of subject and object of a relation [13,52,53], and try to spot violations of the underlying ontology and/or typical usage patterns. In the example depicted in Fig. 1, the error
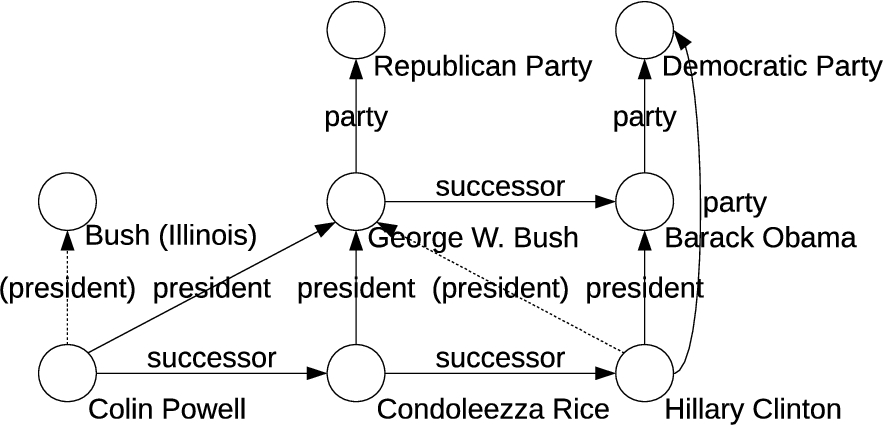
Example excerpt from DBpedia. Two erroneous president relations, indicated by brackets and dashed lines, have been incidentally added.
While types can be a valuable feature, some knowledge graphs lack this kind of information, have only incomplete type information, or have types which are not very informative. Moreover, some errors might contain wrong instances of correct types. For example, the fact
In knowledge graph completion, paths in the graph have been proven to be valuable features [18,27]. In the example depicted in Fig. 1, to predict whether a person a is member of a party b (
Typically, in knowledge graph completion, such paths are then exploited to predict missing relation assertions [17,36]. For error detection, these features can complement the type features. However, searching for interesting paths for all the relations in a knowledge graph can be a challenging task, especially in datasets with many relations.
Once erroneous triples in a knowledge graph are detected, there are various ways of how to proceed. The simplest approach is to delete them, however, in some cases the erroneous relation assertions can be corrected instead. One common source of errors is the confusion between instances of a similar names [49,53], as in the (artificial) example in Fig. 1, where
An actual example from DBpedia is the fact
By exploiting such cases, it is possible to also reduce incompleteness while reducing noise. This also helps reduce the search space of possible facts a knowledge graph could be enriched with. The number of possible relation assertions grows quadratically with the number of instances
When correcting wrong facts originated from confusions between entities, the search space is composed by the entities which could have been confused with the subject and the object. In many cases, the source of such confusions are entities with the same or similar names. Hence, in order to find candidates entities, we can e.g., exploit Wikipedia disambiguation links (which identifies entities which are often confused with each other), or use approximate string matching.
Another interesting field of research is the derivation of higher level patterns from the errors found in a knowledge graph. There are two major motivations: (1) for validating the results of error detection, a user can inspect a small number of patterns instead of a large number of individual mistakes [53]. Furthermore, given that errors follow typical patterns, (2) a set of higher level patterns can be directly deployed in the knowledge graph creation process, or even for live updates.
The problem of finding higher level patterns is addressed by ontology induction approaches, which normally represent relation constraints in the form of RDFS domain and range restrictions. Since designing a good ontology can be a challenging task, there has been a lot of work on learning ontologies from data, using methods such as inductive logic programming (ILP) [8] or association rule mining [66] for automatically learning ontology axioms.
One of the main problems with these methods is the restricted expressiveness of the learned ontologies. Modern knowledge graphs are often complex, and constraints may require the use of more expressive axioms which cannot be learned by current state-of-the-art methods. Furthermore, the intended and the actual use of a property often diverge, leading to situations where a single ontology can hardly describe the different, often competing usages of a property.
One example for the latter case is the
In the example above, path constraints can be useful for describing the relation. In DBpedia, both members of the government and presidents have
While disjunction can be problematic for the complexity of general purpose OWL reasoners, data validation with disjunctive patterns can be performed rather efficiently.
We assume that each variable only occurs once in a path, i.e., the underlying patterns are acyclic. However, as in the example above, constraints may be formulated using multiple paths, which allows also for validating patterns of that kind.
With the method we propose in this paper, we are able to learn such complex logical expressions, which subsume path patterns and simple domain and range restrictions. The patterns are expressed in the language SHACL (Shapes Constraint Language), which is particularly designed for data validation.3
This paper addresses the following research questions:
We propose a hybrid approach called PaTyBRED (Paths and Types with Binary Relevance for Error Detection), which incorporates type and path features into local relation classifiers which predict whether a pair of subject and object belongs to a relation or not.
We propose a method for translating a PaTyBRED model learned with decision trees as classifiers into SHACL relation constraints. SHACL is a versatile constraints language for validating RDF graphs, with which we are able to generate expressive and flexible relation constraints and better handle incomplete and noisy datasets.
We propose CoCKG, an automatic correction approach which identifies and resolves relation assertion errors caused by confusion between instances. The approach relies on error detection methods as well as type predictors to assess the confidence of the corrected facts. It uses approximate string matching and exploits both searching for entities with similar IRIs as well as Wikipedia disambiguation pages (if available) to find candidate instances for correcting the facts.
This paper is an extension of [38], which addresses the detection of relation assertion errors problem, and [37], which introduces the idea of correction of confusions between entities. As part of the extension, we propose the learning of SHACL relation constraints, and perform evaluations on additional knowledge graphs.
In the experiments, we perform an extensive comparison of our PaTyBRED with state-of-the-art error detection and knowledge completion methods, and we conduct a manual evaluation of our approach on DBpedia and NELL, as well as evaluate the scalability using synthetic knowledge graphs. Furthermore, we manually evaluate the suggestions made by CoCKG, and we evaluate the generated SHACL relation constraints and perform another manual evaluation comparing them with domain and range restrictions induced with Statistical Schema Induction [66].
We define a knowledge graph
The problem addressed by research question RQ1 is the detection of erroneous relation assertions in the set
The problem addressed by research question RQ2 is the induction of relation constraints from data. That is, instead of trying to directly improve
The problem addressed by research question RQ3 is the identification and correction of errors generated by confusions between entities. In this paper, we assume that errors originate from a confusion in either the subject or object entity. That is, an originally correct relation assertion
Related work
The works related to this paper can be divided into two parts: detection and correction of relation assertion errors (related to RQ1 and RQ3), which includes error detection and knowledge completion models, and ontology learning, which includes works which induce ontology axioms from data, more specifically relation constraints (related to RQ2). In the next subsections we discuss each part in more details.
Detection of relation assertion errors
The problem of relation assertion error detection in knowledge graphs has been intensively researched by the Semantic Web community. As discussed in the introduction, there are erroneous relation assertions that are at the same time a violation to the ontology or T-Box of the knowledge graph (e.g., referring to a city instead of a sports team), while others are not (e.g., referring to one person instead of another). Apart from synonyms, a lack of domain and range restrictions of relations or too general restrictions is one of the main causes of problems of the latter category. Most recent methods proposed for cleansing large-scale LOD knowledge graphs, such as DBpedia and NELL, therefore do not rely solely on the schema, but use characteristics of the knowledge graph’s A-box to detect erroneous assertions. A detailed survey including link prediction and error detection methods for knowledge graphs can be found in [50].
SDValidate [52] exploits statistical distributions of types and relations, and [13] applies outlier detection on type-based entity similarity measures to detect erroneous relation assertions. In more detail, SDValidate computes a distribution of object types for a given property. For a given relation assertion
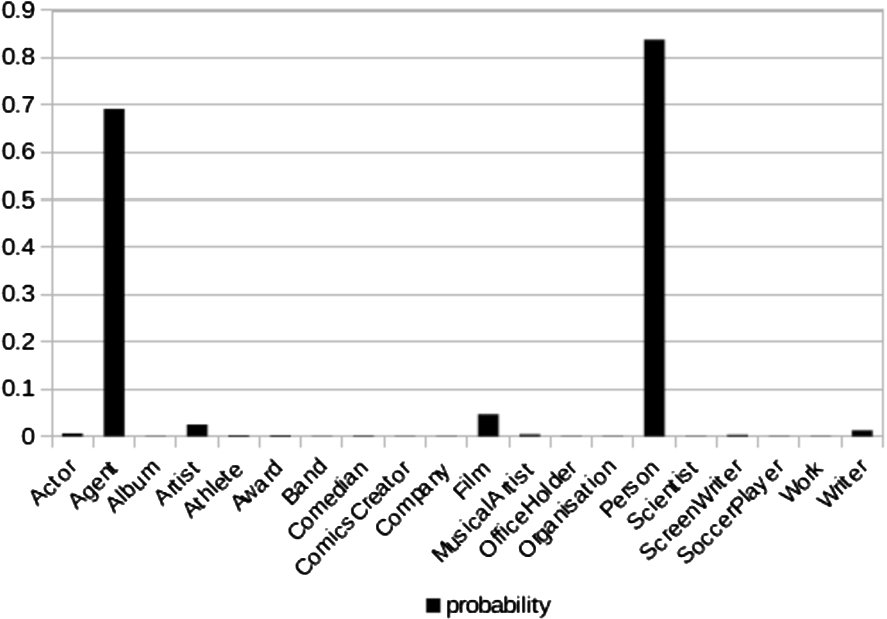
Example distribution of the object types of the DBpedia property
Knowledge graph completion (KGC) is a field highly related to error detection. Despite addressing a different problem, many KGC methods can also be used on the problem addressed in this paper. This kind of methods can be divided into graph-based, which relies on features which can be directly observed in the graph, and embedding methods, which learn latent features that represent entities and relations in an embedding space.
The Path Ranking Algorithm (PRA) [27] has shown that a logistic regression classifier using path features generated with random walks can be used for learning and inference in KGs and outperforms N-FOIL horn-clause inference on NELL [28]. PRA learns HORN clauses to predict relations, e.g.,
In later works, the PRA approach has been improved with Sub-graph Feature Extraction (SFE) [18], which also simplifies aspects of PRA. For instance, while PRA uses real valued features which correspond to the probabilities to reach o from s with a given path, SFE simply uses binary features which indicate if o can be reached from s or not. SFE not only reduces runtime by an order of magnitude when compared with PRA, but it also improves the qualitative performance.
In the recent years, knowledge graph embedding models, i.e., projections of knowledge graphs into lower-dimensional, dense vector spaces, have received a lot of attention [68]. Several different models have been developed for the knowledge graph completion problem and have brought improvements in performance.
There is a plethora of different embeddings models for knowledge graphs. One of the earliest embedding models is RESCAL [48], which performs tensor factorization on the knowledge graph’s adjacency tensor, with the resulting eigenvectors corresponding to the entity embeddings and the core tensor the relations matrices. TRESCAL [10] extends RESCAL by exploiting entity types as well as domain and range restrictions of relations to improve the data quality and speed up the tensor factorization process. Neural Tensor Model (NTN) [62] represents each relation as a bilinear tensor operator followed by a linear matrix operator. Other early embedding models include Structure Embeddings (SE) [5], Semantic Matching Energy (SME) [3] and Latent Factor Model (LFM) [25].
Translation-based embeddings represent relations as translations between subject and object entities. TransE [4] was the first translation-based model and entities and relations share the same embeddings space. In TransH [69] and TransR [33] the translations are performed in the relations space, which is different from the entities space, and require projection matrices to map the entities onto the relations space. TransG [71] and CTransR [33] incorporate multiple relation semantics, where a relation may have multiple meanings determined by the entities pair associated with the relation. PTransE [32] extends TransE by considering relation paths as regular relations, which makes the number of relations considered grow exponentially.
Other approaches include DistMult [72], which uses dot product instead of translations to compute the triple scores. HolE [47] used circular correlation as an operator to combine the subject and object embeddings, Complex Embeddings [65] represents a triple score as the hermitian dot product of the relation, subject and object embeddings, which consist of real and imaginary vector components. ProjE [61] formulates the knowledge graph completion as a ranking problem, and it optimizes the ranking of candidate entities collectively. It is reportedly one of the best performing KGC methods.
Some embedding models, such as RDF2Vec [58,59] and Global RDF vectors [11], are not conceived for the KGC task and cannot generate triple scores. Thus, they cannot be directly used for error detection in the same way the other models mentioned earlier can, but in principle, they can serve as feature generation mechanisms for training relation scoring models.
Recently some works have raised doubts about the performance of new KGC embeddings models. Most of the experiments rely exclusively on two datasets (WN18 and FB15k), which contain many inverse relations [64]. Therefore some of the models may exploit this characteristic and not necessarily perform as well on other KGs. It has also been shown that the presence of relations between candidate pairs can be an extremely strong signal in some cases [64]. Moreover, recent works showed that a hyperparameter tuning has been overlooked and that a simple method, such as DistMult, can achieve state-of-the-art performance when well tuned [26].
As mentioned in the previous subsection, there are several different approaches for link prediction and some for error detection. It is important to note that none of those approaches mentioned address the problem of covering the candidate triples space (of size
Rule-based systems, such as AMIE [17], cannot assign scores to arbitrary triples. However, they could be used to restrict the
Wang et al. [67] studied the problem of erroneous links in Wikipedia, which is also the source of many errors of DBpedia. They model the Wikipedia links as a weighted directed mono-relational graph, and propose the LinkRank algorithm which similar to PageRank, but instead of ranking the nodes (entities), it ranks the links. They use LinkRank to generate candidates for the link correction and use textual features from the description of articles to learn a SVM classifier that can detect errors and choose the best candidate for correction. While this is a closely related problem, which can help mitigate the problem studied in this paper, their method cannot be directly applied on arbitrary knowledge graphs. Our approach takes advantage of the multi-relational nature of KGs, entity types, ontological information and the graph structure.
Ontology learning
As discussed above, most works on detecting errors in knowledge graphs address the level of individual assertions, with the already mentioned shortcomings. There are few works which attempt to derive reusable, higher-level artifacts.
One such approach has been proposed in [63]. The authors provide means of learning additional domain and range restrictions for relations, which can then facilitate more fine-grained fact checking. The domain and range axioms learned are a reusable artifact, but, as discussed above, are not always suitable for the complex scenarios induced by modern knowledge graphs.
In [53], we have introduced an approach that clusters similar relation assertion errors. Those clusters can be more easily inspected by experts (e.g., by presenting them one typical, prominent example as a proxy for a class of errors), but the expert still needs to identify the cause and come up with a suitable fix manually.
The work presented in [49] aims at closing that gap by precisely pinpointing the cause of an error. For DBpedia, it is able to identify single axioms in the ontology or single mapping elements (i.e., the smallest building blocks of the creation process) that are responsible for a class of errors. It is, however, tightly tangled to the DBpedia creation process and cannot be trivially transferred to other knowledge graphs built with different methods.
Since we discuss the learning of constraints to be used for validating a knowledge graph, we target a problem which is similar to that of ontology learning or enrichment; a field in which quite a bit of related work exists. Rudolph [60] uses a class of OWL axioms that generalize domain and range restrictions, which support the conjunction of concepts. Statistical schema induction (SSI) [66] uses association rule mining to learn OWL 2 EL axioms, such as class and relation subsumptions, relation’s domain and range restrictions, relation transitiveness. Bühmann and Lehmann [8] propose a method for enriching ontologies with OWL 2 axioms implemented in the DL-Learner framework. Regarding relation assertion constraints, domain and range restrictions relation cardinalities [44] are the only kind of constraint which can be learned by these methods. A brief introduction to ontology learning and overview of the main approaches can be found in [31].
Gayo et al. [20] use SHACL and ShEX to define constraints to validate and describe linked data portals. Arndt et al. [1] uses rule mining to learn RDF-CV (RDF Constraints Vocabulary). Swift Linked Data Miner (SLDM) [55] is the only system at the moment which can automatically learn SHACL constraints. However, it does not learn relation constraints, only class expressions.
Rule learning approaches, such as AMIE [17] and DL-Learner [30], could in principle have some of their rules converted into SHACL constraints. Since they were not originally conceived for learning relation constraints, these approaches would need to be extended in order to support it. As of now there are no works in that direction.
Detection of relation assertion errors
In this section, we describe PaTyBRED (Paths and Types with Binary Relevance for Error Detection), a method for detecting relation assertion errors which relies both on path and type features. This method addresses research question RQ1.
PaTyBRED
Our proposed approach is inspired by the Path Ranking Algorithm (PRA) [27] and SDValidate [52]. It consists of a binary classifier for every relation which predicts the existence of a given pair of subject and object in the given relation. The set of classifiers can be thought of as a single multilabel classifier with binary relevance (i.e., each relation that can hold between a pair of instances is a label), where one binary classifier is learned for each class separately, and local feature selection [39], with different classifiers being able to work on different sets of specialized features.
We use two kinds of features. The first one are the types of subject and objects. This kind of information has been successfully used for error detection in SDValidate [52]. By analyzing the types of subject and object in one given relation, one can easily spot a very common kind of error without relying on the domain and range restrictions, which are often inexistent or too general. For example, in DBpedia the triple
The main problem with this kind of approach is that it solely relies on type features. That means such approaches do not work on knowledge graphs with no type assertions, and may have poor performance on datasets with a shallow type hierarchy, with non informative types, or with incomplete type assertions. Moreover, solely using type features, it is impossible to detect wrong facts with wrong entities of correct types, for instance, when a person instance is confused with another of same or similar name.
Alternatively, we can use path features similar to those of PRA. However, solely relying on path features also may lead to different problems. One of those issues is that correct facts may be labeled as errors because of incompleteness. For instance, if river instances have the properties
Another problem is that since
In order to make our approach more robust and rule out issues caused by the two approaches, we combine both type and path features.
Finding the relevant paths for each relation can be a challenging task. Since several paths may be relevant for different relations, we compute all possible paths up to a given length, and for every relation’s local classifier, we perform local feature selection. The number of possible paths grows exponentially with the number of relations, therefore an exhaustive search can easily become unfeasible. It is then crucial to have heuristics to efficiently navigate the search space. In the following subsection we propose and discuss such heuristic measures.
Extracted features
Our method includes the following parameters that define the path selection: maximum path length, maximum number of paths per length, and path selection heuristics. Following the approach described in [27], we use the domain and range restrictions of relations for pruning uninteresting paths, and we do not allow a relation to be immediately followed by its inverse. If the number of possible paths of a certain length exceeds the maximum number of paths per length, we apply our path selection heuristics to prune the least interesting paths and comply with the specified paths upper limit.
We define a path P as a sequence of relations
PaTyBRED supports type and path features. The features for learning the classifier for a relation r are shown in Table 1, where each instance is a pair of a subject and an object entity
Kinds of binary features supported by PaTyBRED
Kinds of binary features supported by PaTyBRED
Relations and paths can be represented as adjacency matrices of size
Let A and B be adjacency matrices – which can refer to a single relation or a path – which we want to concatenate in order to form a new path
Paths with empty adjacency matrices (
While paths with empty adjacency matrices can be pruned safely without information loss, paths with very sparse, yet non-empty adjacency matrices are less likely to be informative for the classifier. Hence, we apply a less defensive pruning and define heuristics for pruning paths with sparse adjacency matrices. Since the size of the intersection
For each length, a only a fixed number of paths is kept, which is a parameter in our approach (
Once the relevant paths have been selected, we compute their adjacency matrices and use them to populate the features used to train the relation classifiers. One of the problems of computing the whole adjacency matrix of paths is that some can be very dense and require a lot of memory. For example, the path
It is worth pointing out that the
Once the paths have been selected, and their adjacency matrices have been computed, we can use them together with types as features to predict the existence of an entity pair
As label, we use information from r indicating the existence of
In order to clarify how the relation classifiers are trained, Table 2 depicts provide a simple example of training data for the relation
Example of training data instances for the relation livesIn
Example of training data instances for the relation livesIn
Before we learn the local classifiers, we evaluate the relevance of the features. Since different features might be relevant for different relations, we perform feature selection separately for every relation. This allows the relation classifiers to work on a small set of locally relevant features, and, at the same time, removes irrelevant features which might act as noise and reduce the classifier’s performance [39]. We use the filter method, which simply select the top-k most relevant features, with
Algorithm 1 shows how PaTyBRED works. The function
Subsequently the relation classifiers need to be trained. For every relation r the positive
When comparing PaTyBRED with PRA and SFE, our approach has the following advantages:
By decoupling the feature extraction and the learning step, we can use different popular classifiers to learn the relations, and we found indeed that logistic regression, which is used in PRA and SFE, is not the best performer. We introduce a local feature selection step prior to training the relation classifiers, which can significantly increase the computational performance. We propose heuristic measures to explore the paths search space, again for gaining computational performance.
Moreover, negative evidence features, i.e. paths which connect negative but no positive entity pairs of a relation, are also considered. Since our approach is supervised and includes negative examples in the training data, this kind of features is extremely important to identify wrong facts.

The PaTyBRED algorithm
In this section, we first briefly present the datasets used in the evaluations, then we present the experiments conducted, which are split into two parts. In the first part we perform an automatic evaluation to compare PaTyBRED with SDValidate and state-of-the-art link prediction methods, and in the second we conduct a manual evaluation of PaTyBRED on three large-scale datasets (DBpedia, NELL and YAGO) with actual erroneous relation assertions. The experiments are designed to answer research question RQ1.
Datasets
In our experiments, we use a variety of knowledge graphs, some of which are clean, and others noisy. In the first part of our experiments we automatically evaluate the performance of the error detection algorithms. In order to make the evaluation automatic, we use a variety of datasets to which we add synthesized wrong facts. We generate the erroneous facts by corrupting the subject or object f true facts, i.e., replacing the original entity with a randomly selected which results in a fact which does not exist in the original data. For our generation process, we corrupt 1% of the triples, using two different kinds of errors:
For type 1 errors, we corrupt the triple by substituting the object with any entity from the knowledge graph (independent of its type). For type 2 errors, we corrupt the triple by substituting the object with any entity from the knowledge graph which has the same type(s).
That means the errors of the second kind are, in principle, more difficult to be detected than those of the first kind, since the new entity is more likely to have characteristics similar to those of the original one.4
It should be noted that, although type 2 errors are, in theory, a subset of type 1 errors, the sets of errors added to the testsets are not subsets of each other. The probability of generating a type 1 error which is also a type 2 error depends on the distribution of types and differs from datasets to dataset; for the datasets used in our evaluation, it falls into a range between 0.13 and 0.32. However, a correlation of that probability with the approach’s performance on the different datasets could not be observed.
The datasets used are the following: As input knowledge graphs, we use DBpedia (2015-10) [2], NELL (08m-690) [9], and YAGO3 [35]. We use the following smaller domain specific datasets: Semantic Bible,5
The Semantic Web dog food datasets are known to be correct and locally complete, i.e. no errors or missing relations between contained entities, therefore, the generated errors can be used as gold standard. We could not find any evaluation the of quality of AIFB, Semantic Bible, or Nobel Prize. Since we cannot guarantee the quality of the data, the synthesized errors can be considered a silver standard.9
We follow the notion that a gold standard is guaranteed to contain only correct examples (i.e., in our case, the labels for correct and incorrect triples are always accurate), whereas a silver standard may also contain a small fraction of incorrect examples (i.e., in our case, correct triples labeled as incorrect, or vice versa).
The number of false positives is likely to be low even for highly incomplete datasets, since in general, the number of missing facts is significantly smaller than the number of possible facts (
In the second part of the experiments, we use DBpedia and NELL as large-scale real-world use cases. These datasets are known to be noisy and incomplete, with type assertion completeness estimated to be at most 63.7% on DBpedia [52]. We do not synthesize any erroneous facts, and rank all the facts by their confidence values. Since we do not know the noisy facts or even the number of errors which exist in DBpedia, we manually evaluate the top-100 results.
In our experiments, we evaluate the impact of different parameter settings in our approach, and compare it with SDValidate and embedding-based knowledge graph completion methods. We use ProjE10
Furthermore, to analyze the benefits of combining path and type features, we also compare against the variants of PaTyBRED using only path features (PaBRED) and only type features (TyBRED). For that reason, we omit a direct comparison our method with SFE, since, by design, PaBRED performs at least as good as SFE. The implementation of PaTyBRED, as well as the SHACL constraint generation is available on Github.12
The reported results from the embedding methods were obtained by not considering the type assertions. We tried adding the type assertions as an extra relation, however, this did not improve the results. The embedding methods suffer from the problem that the distribution of scores over different relations is not uniform. Often some relations have average triple scores lower than others, and this can result in a bias when detecting errors.
In order to address this problem, we use the following strategy to normalize the scores across different relations: in a first step, we run the isolation forest outlier scoring algorithm [34] to detect outliers in the confidence values of each relation separately. We then use the outlier scores instead of the triple confidence values to rank the facts, since they share a common global scale. Since unusually high confidence values are also outliers and we are interested only in the outliers of low scores, we do not consider as outlier any fact with score greater than the relation’s average.
For the error detection problem, we use ranking measures to evaluate the performance of the error detection algorithms, since we compute scores for every triple in the graph and generate a ranking. More specifically, we generate an error score for each triple, and we rank the triples by that error score. With that ranking, ideally all erroneous triples should be ranked higher than the correct ones. We use the mean rank (μR) and mean reciprocal rank (MRR):
One shortcoming of those metrics is that they are not comparable across datasets.
Toy example showing rankings of two error detection approaches on two datasets
Toy example showing rankings of two error detection approaches on two datasets
To illustrate those shortcomings, Table 3 shows a toy example with the rankings of two approaches on two datasets. While approach 1 is perfect and ranks all errors (E) higher than all correct relations (C), approach 2 makes some mistakes. As we can observe in this example, the μR and MRR are not comparable across datasets of different sizes: approach 2 has a the same μR and a better MRR on dataset 1 than approach 1 on dataset 2, although the results are actually worse.
To overcome those shortcomings and make the results comparable, we use the filtered variants fμR and fMRR (cf. Equations (6) and (7)), which filter out correctly higher ranked predictions:
Subtracting
First, we evaluate how the different PaTyBRED parameters affect its performance. The evaluated parameters are the maximum path length (
As far as the maximum path length (
In none of the datasets used in our experiments, a
Comparison of local classifiers and number of selected features on generated errors of kind 1
Comparison of local classifiers and number of selected features on generated errors of kind 1
In our experiments, we evaluate three different classifiers (
The heuristic measures used for selecting relevant adjacency matrices are those proposed in Section 4.2, i.e.,
The diagram is to be read as follows: the x axis depicts the average rank of the different approaches across different datasets. A higher ranked approach which is more than the critical distance (CD) away from a lower ranked one outperforms the lower ranked one statistically significantly. The black bars groups approaches whose performance differences are not statistically significant. This means that in this diagram:
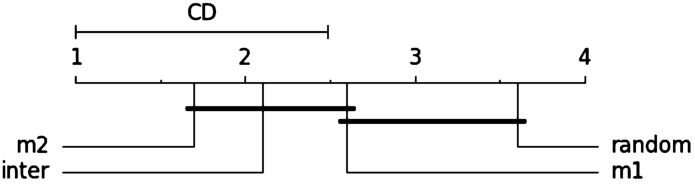
Critical distance diagram comparing path selection heuristics.
Tables 5 and 6 report a comparison between PaTyBRED and the other state-of-the-art models. Table 5 refers to errors generated by replacing entities with entities of arbitrary types (errors of kind 1). Table 6 refers to errors where entities have been replaced by entities with the same types as the original entity (errors of kind 2). Table 6 does not contain results for WN18 and FB15k because the original datasets do not contain entity types, which prevents errors of kind 2 to be generated. For the same reason the results of SDValidate and TyBRED in Table 5 are not reported for WN18 and FB15k. We report values for
It is noticeable that the results for AIFB are significantly worse than other datasets. One of the reasons is the fact that it has no inverse relations, which can be extremely helpful on the error detection. Another reason is the fact that in AIFB the
We can observe some larger variations in and between the datasets. The smaller sets, like nobel or aifb, do not have enough training information for some approaches, which work better on the larger wn18 and fb15k datasets. The same holds for SDValidate, which is relying on larger datasets to create stable statistical distributions – in fact, SDValidate even has a hard coded switch that prevents it from reporting errors based on small distributions and little evidence to avoid false negatives. On the other hand, the classifiers used in PaTyBRED and its variants can learn stable models also for smaller datasets. Moreover, the embedding based approaches TransE, HolE, and ProjE, which have been developed for link prediction on large datasets, tend to overfit when it comes to link validation, especially for smaller scale datasets. Although there are quite a few successors and alternatives to the embedding based approaches tested here, the difference is so large that we do not expect a larger shift when trying more different embedding based methods.
Comparison of FMRR on generated errors of kind 1
Comparison of FMRR on generated errors of kind 1
Comparison of FMRR on generated errors of kind 2
As discussed above, PaTyBRED, TyBRED and PaBRED were run with 6 different configuration:
It is worth mentioning that the score normalization via outlier detection helped improve the performance of embeddings’
Our proposed method outperforms all the other methods, with the embedding methods having a surprisingly low performance. PaTyBRED performs best when combining types and paths, with TyBRED (with types only) and PaBRED (with paths only) being generally worse. To further understand the importance of combining path type features, we analyze what kind of features are selected on the local classifiers and report the proportion of types and paths. Table 7 shows the average proportion of selected features over all relation classifiers with
Proportion of path and type features selected
Table 6, where the erroneous facts contain wrong instances of correct types, shows how the performance of methods which rely on types exclusively (SDValidate and TyBRED) is similar to that of random ranking with

Runtime comparison of the evaluated methods.
In addition to evaluating the result quality, we also conducted a scalability study of the evaluated methods. The scalability test is performed on synthesized replica of DBpedia with the M3 model [40] of sizes {0.01%, 0.1%, 1% and 10%} of the original size, that means the number of triples varies from around 1.5k to 1.5M triples. The results are shown in Fig. 4.
We can observe that SDValidate has by far the lowest runtimes, since it is a simpler model than the others. Amongst the embedding methods, ProjE which directly optimizes the rankings in the link prediction task, has the steepest runtime growth. HolE and TransE have similar scalability being more scalable than ProjE. PaTyBRED, due to the aggressive local feature selection and sampling, has the least steep of the curves, and, together with SDValidate, was the only approach to handle the larger knowledge graphs in less than 24 hours. This indicates the appropriateness of PaTyBRED for handling large datasets.
In this section, we perform a manual validation of PaTyBRED on three large-scale knowledge graphs: DBpedia, NELL, and YAGO. We have a deeper look at the top-100 results and classify the triples as correct, wrong and other errors, i.e., correct triples with related errors, e.g., wrong or missing types of subject or object. Note that by analyzing the top-100 results, we do explicitly not draw a representative, random sample of 100 triples to validate the accuracy of our approach. We rather measure precision@100 of the approaches. This is similar to how a knowledge graph engineer would utilize the approach: they would typically not inspect random errors, but the ones in which the automated approach has the highest confidence.

Manual evaluation on DBpedia, NELL, and YAGO.
The results are shown in Fig. 5 with PaTyBRED
Some of the errors come from mistakes when linking Wikipedia pages with very similar names. Such problems could potentially be evaluated with CoCKG. Section 6 presents the approach in more details and evaluates its performance on DBpedia and NELL.
Entities in DBpedia are described in much more detail than in NELL [57]. Around 20% of NELL’s instances are untyped, while in DBpedia, only 1% of them have no types other than
Amongst the five correct facts from DBpedia which were wrongly predicted to be errors, two were from the relation
For YAGO, the results are considerably worse than for DBpedia and NELL. There are various reasons here: first, the schema of YAGO is very different, with only 77 relations, but 488,469 classes [35]. Hence, compared to DBpedia with 1,105 relations and 760 classes, the search space for path and type features is completely different – we cannot construct too many interesting paths, and many of the types are too specific to be meaningful for error detection. Second, the global error rate of YAGO is lower [15], with more sophisticated checking in place already during YAGO’s construction process, which makes the error detection task inherently more difficult.
Once erroneous relation assertions have been identified at a high level of confidence, they may be removed from the knowledge graph. In case a suitable replacement for the relation can be found, they may be also be corrected instead of removed. In this section, we discuss the CoCKG (Correction of Confusions in Knowledge Graphs) approach for finding suitable replacements for an erroneous relation assertion. The approach is designed to address research question RQ3.
The approach consists of first running an error detection algorithm (PaTyBRED in the case of this paper), selecting the top-k facts most likely to be wrong. In the next step, the error is heuristically verified to be an actual relation assertion error and not caused by missing or wrong type assertions in the object or subject with a type predictor
The function

Knowledge base correction process
After selecting the k triples most likely to be wrong, we first check if their confidence is low because of missing or wrong instance types (subject or object). In order to do that, we run a type predictor
If in neither case (i.e., after recomputing the confidence with changed types for the subject and the object) the confidence thresholds are satisfied, we assume that the triple is actually wrong (i.e., a true negative), and not identified as erroneous by mistake (i.e., a false negative). In that case, we proceed to the next part where we try to substitute the subject and object with their respective lists of candidates.
Combining the type prediction process with the error detection also has the advantage that the newly predicted types can be validated on triples containing the instance whose types were predicted. This can help support, or contradict the type predictor, possibly detecting types which are wrongly predicted by identifying triples where the score is lowered with the new types.
Retrieving candidates
As discussed above, we assume that one common source of erroneous assertions is the confusion of entities with similar names. Hence, a simple way to find candidate entities to resolve entity confusions is to use disambiguation pages in Wikipedia. However, since disambiguation pages are only available for Wikipedia-based knowledge graphs, and furthermore are not available for each entity (e.g.
Since in our experiments we consider DBpedia and NELL, which have informative IRIs (in the case of DBpedia extracted from the correspondent Wikipedia’s page), we search for candidate entities which have similar IRIs. Alternatively, for knowledge graphs with non-informative IRIs (e.g., Wikidata or Freebase), we could pursue the same approach and search for entities with similar labels. In this paper, we refer to the informative part of an IRI as the “name” of the entity, and note that there might be other sources of a name, such as an entity label.
Retrieving all the instances of similar names can be a time consuming task. This kind of problem is known as approximate string matching, and it has been widely researched [45,73]. For our method, we use an approximate string matching approach based on [43]. First, we remove the IRI’s prefix and work with the suffix as the entity’s name. We then tokenize the names and construct a deletions dictionary with all tokens being added with all possible deletions up to a maximum edit distance
When searching for entities similar to a given entity, we perform queries for every token of the entity’s name and we require that all tokens are matched. That is, for a certain entity to be considered similar, it has to contain tokens similar to all the tokens of the queried entity. A retrieved entity may have more tokens than the queried entity, but not less. The idea is that in general, when referring to an entity, it is common to underspecify the entity, but highly unlikely to overspecify it. E.g., it is more likely that
We also perform especial treatment on DBpedia and NELL entity names because of peculiarities in their IRI structures. In DBpedia it is common to have between parentheses information to help disambiguate entities, which we consider unnecessary since the entity types are used in the error detection method. In NELL the first token is always the type of the entity, therefore, for similar reasons, we ignore it.
Correcting wrong facts
At this point, for each assertion identified as erroneous, we have a list of candidate entities for replacing the subject and the objects, gathered, e.g., by exploiting disambiguation pages and approximate string matching. We then compute a custom similarity measure
For that to happen in the case of DBpedia, a Wikipedia user would have to go to the wrong article page and insert a wrong link in the infobox. In NELL, an extraction would have to extract a relation by misinterpreting both involved entities at the same time, which, since reasoning, among other plausibliity checks, is involved in the creation of NELL, would require a plausible triple with a subject and object with a similar name and a compatible type, e.g., two football players and two football clubs with a similar name.
From the set of candidate triples, we remove those triples which are already existent in the KG. We compute the confidence of the remaining candidate triples and select that with highest confidence, given that
To validate the performance of error correction, and to answer research question RQ3, we conduct a manual evaluation on DBpedia (2016-10) and NELL (08m-690). For each knowledge graph, we have run PaTyBRED, and presented the top-1% most likely to be errors to CoCKG. We inspected the resulting corrections and classified them into four different categories:
WC: wrong fact turned into correct; WW: wrong fact turned into another wrong fact; CW: correct fact turned into wrong fact; CC: correct fact turned into another correct fact.
Note that while WC is the only class that actually improves the knowledge graph, it does not mean that the other classes actually make it worse. In fact, only CW reduces the quality of the underlying knowledge graph, while WW and CC do not alter the amount of correct and wrong axioms in the knowledge graph.
Our approach was run with
The parameter values were selected based on heuristics and may not be optimal.
For the evaluation, since manually evaluating all these corrections would be impossible, we randomly select 100 suggested corrections on each knowledge graph to perform the evaluation.
The results of our manual evaluation are shown in Fig. 6. The proportion of facts successfully corrected (WC) was rather low. However, the majority of suggested replacements is WW (which does not alter the quality the of the knowledge graph), and only a small fraction (8% and 12%, respectively) are of the problematic category CW. These results show that the approach is at least capable of making meaningful suggestions, and can be used by experts to maintain the quality of a knowledge graph, although maybe not in a fully automatic setting.
When evaluating some relations individually, we notice that some of them achieve good results. E.g., the relations

Manual evaluation on DBpedia and NELL respectively.
One of the problems of our approach is that since it relies on PaTyBRED, which cannot find many relevant path features on DBpedia and NELL [38], it is difficult to distinguish between candidate entities of same type. For example, in NELL, the entity
The decision to generate candidate triples by corrupting either the subject or object seemed to have worked well for DBpedia, where we could not find a triple where both subject and object were wrong. On the other hand, in NELL such case was observed a few times, e.g.
Also, our assumption that confusions tend to use a more general IRI instead of a more specific, requiring all tokens of the queried to be matched, does not always hold. One example in DBpedia which contradicts this assumption is
In this section we present our approach for translating models for the correctness of relation assertions learned with PaTyBRED into SHACL relation constraints. This approach is designed to address research question RQ2. It is important to note that we focus on the creation of constraints for relations between entities, i.e.
Learning such constraints has an important advantage when comparing to opaque relation assertion error detection methods, such as embeddings. The SHACL constraints are human-readable and can be directly evaluated and improved by specialists without requiring the manual evaluation of its output. Furthermore, once learned, they can be deployed in the knowledge graph creation process and evaluated more efficiently.
SHACL
Shapes Constraint Language (SHACL) is a language for validating RDF graphs against a set of conditions, which are provided as shapes expressed in the form of an RDF graph called shapes graph. The RDF graphs that are validated against a shapes graph are called data graphs. The shape graphs conditions may be used for a variety of purposes beside validation, including user interface building, code generation and data integration. SHACL was created as an extension of ShEX (Shape Expressions).16
The SHACL specification is divided into SHACL Core and SHACL-SPARQL.17
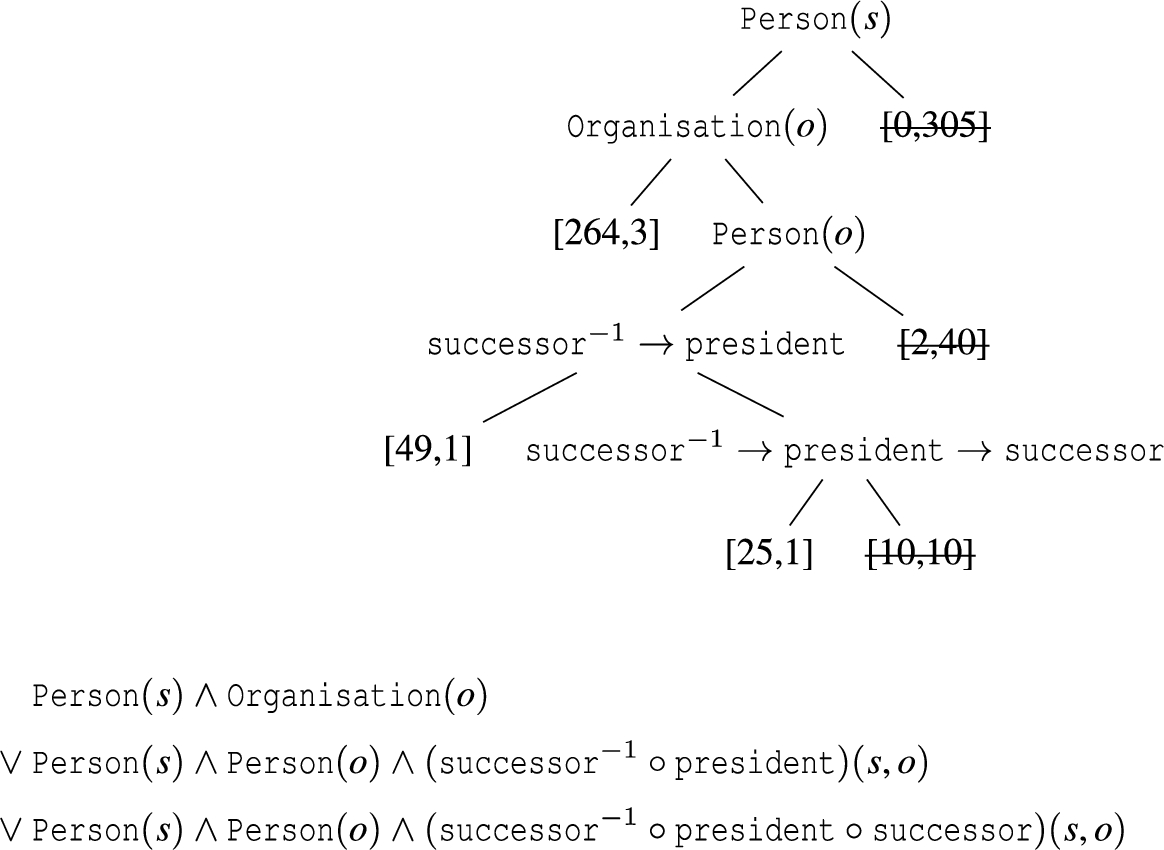
Deriving constraints from a learned decision tree. First, leaves are pruned (marked as struck through). Then, logical constraints are derived from the remaining paths in the tree (lower part).
SHACL-SPARQL consists of all features of SHACL Core plus the advanced features of SPARQL-based constraints and an extension mechanism to declare new constraint components. Constraint can be written as SPARQL ASK or SELECT queries. These queries are interpreted against each shape focus node. If an ASK query does not evaluate to true for a given node, then the constraint is violated. Constraints described using a SELECT query must return an empty result set when conforming with the constraint and non-empty set when violated.
SHACL also supports three different constraint severity levels: Info, Warning and Violation. The different levels have no impact on the validation, but may be used by to categorize validation results. It is up to the user to define how the different severity levels are handled.
To generate SHACL constraints, we follow the idea of generating rules from decision trees. Hence, we first run PaTyBRED with a tree learner to generate a decision tree for classifying assertions into correct and erroneous ones, and extract rules for erroneous statements. Those rules are then expressed as SHACL constraints. Following [56], the trees are not optimized or pruned during learning, but we apply a specific pruning procedure later in the process.
To create the constraints, we consider the subtrees whose leave nodes state that the example should be classified as erroneous. The subtree is then converted it into a logical expression, whose negation is used as a constraint for the relation. The idea is that we used as constraints the negation of the expression that defines the examples which are predicted by PaTyBRED to be highly erroneous. In the rest of this section we describe in details how the generation of the constraints is done.
Firstly we identify the nodes which contain only – or mostly – erroneous relation assertions. For a node not to be pruned it needs to satisfy minimum support and confidence thresholds, or be an ancestor of a node which satisfies the thresholds. If a non-leaf node satisfies both thresholds, all its ancestors can be pruned (to avoid redundancies). This pruned tree can then be directly converted into a logical expression which will translate the conditions into a single SHACL constraint. Each literal
Figure 7 shows an example of how the pruning process works. The decision tree is learned on the example relation
A confidence value of 1 means that only pure nodes containing exclusively negative examples can be selected. It also means that if the learned constraints are to be applied on the original data, no existing errors can be detected. In order to enable detection of preexisting errors, the confidence threshold of less than 1 is necessary. We can use different confidence thresholds to define different SHACL constraints with different severity levels. Constraints with lower confidence may be used as warnings, while higher confidence values close to 1 maybe used as violations.
Since PaTyBRED relies on path and type features, all conditions in the decision tree nodes will be of the following kinds: subject type, object type and path.
The decision tree’s logical expression can be directly translated to SHACL Core using
The main problem with SHACL Core is when translating path features. In the decision trees we consider pairs of subject and object as examples, however SHACL validation is performed on single nodes basis. Its vocabulary provides the components for property pair constraints
PaTyBRED features translation into SHACL
PaTyBRED features translation into SHACL
This can be illustrated with Example 1. If we want to validate the relation

A similar problem happens if we try to use the negation of
In SHACL-SPARQL path features can be correctly translated in a more intuitive way, since it is possible to work directly with subject-object pairs. Moreover, it has the advantage of using a well-established and widely used language instead of requiring the learning of a whole new vocabulary. The template for a SHACL-SPARQL relation constraint is shown below. The SPARQL constraint is defined with the
The relation constraints expression is represented by
For the earlier
It is important to note that the number of variables and the length of the expression will depend on the number of features selected defined by PaTyBRED. It also depends on the decision tree settings, such as the maximum depth, maximum number of leaf nodes, minimum samples on leaf and on split.
To evaluate the learning of relation constraints, we compare the constraints learned with our approach with domain and range restriction axioms learned with statistical schema induction (SSI). We conduct experiments on two large-scale knowledge graphs, i.e., DBpedia and YAGO. These experiments address research question RQ2.
As discussed above, approaches learning explicit interpretable and executable models for identifying errors in knowledge graphs are scarce, since most approaches are rather focused towards scoring individual triples. However, a feasible way of combining error detection in knowledge graph with learning explicit models is first to enrich the underlying schema or ontology by additional axioms, and then to use the axioms to detect errors in the knowledge graph [63]. We use an approach called Statistical Schema Induction (SSI) first introduced in [66], which uses association rule mining to learn domain and range restrictions in a schema. SSI [66] uses association rule mining to induce domain and range restrictions the data. In order to learn such restrictions, it generates transaction tables where transactions correspond to relation assertions and items correspond to relation and subject types, for domain learning, or relation and object types, for range learning. Then rules of the forms
The reasons why we choose SSI as a comparison is two-fold: first, it scales well to an entire knowledge graph such as DBpedia. Second, our approach can, as discussed in the introduction, learn more complex patterns for errors which go beyond simple domain and range restrictions. Hence, the comparison will also reveal whether this theoretical capability is also exploited in practice, or whether our approach falls back to learn simple domain and range restrictions, which are only expressed by more complex SHACL constraints.
We run both methods with minimum confidence of 0.95 and minimum support of 50 instances. For SSI, we use the most specific domain and range axioms that satisfy the minimum confidence and support thresholds. Every constraint and axiom preserves its original confidence value, and for every fact violating the constraints we assign the confidence of its original axiom.
We rank the detected errors by the scores, and select the top-10,000 (top-10k) errors with each method (less than 1% of the total amount of relation assertions). Since many of triples are in the top-10k of both methods, we manually evaluate only those triples which are selected by one method and not the other.
We decided to evaluate the compared approaches based on their ability to detect existing errors. Evaluating the quality of the generated constraints by themselves, without considering their ability to detect errors, would be subjective. Since both methods induce the constraints from the ABox and the detection of errors is their main application, we think it is fair to evaluate the approaches by how accurately they can detect errors in an incorrect dataset like DBpedia.
The learned SHACL constraints are translated from PaTyBRED decision trees learned with
Figure 8 shows the results of our manual evaluation on DBpedia.18
The manual annotations can be accessed in
In the manual evaluation we classify the triples detected as errors into four categories.
WT-CC: wrong triple with correct types;
WT-WC: wrong triple with wrong types;
CT-WC: correct triple with wrong types;
CT-CC: correct triple with correct types.
We consider a fact to have wrong type (WC), if either the subject or the object in the triple has wrong or missing triple assertions. That includes instances which are untyped, has too general types, or has wrong type assertions. A relation assertion is considered correct (CT) if the pair of subject and object entities is correct, independent of their types.
The results from Fig. 5 show that the SHACL constraints are better at detecting wrong triples, with a higher number of wrong triples with correct types (WT-CC), which are more difficult to detect. Also, the number of correct triples with wrong types (CT-WC) is reduced, showing that the more flexible SHACL constraints are better at modeling noisy and incomplete relations. We suppose that on datasets where path features are more relevant, our learned SPARQL constraints would have a greater advantage when compared to SSI, since the latter only exploits subject and object types.
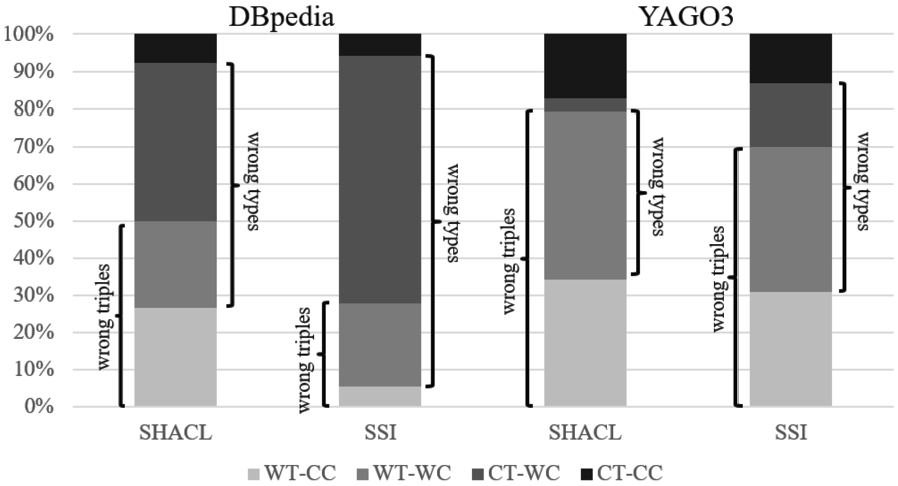
Manual evaluation on DBpedia and YAGO.
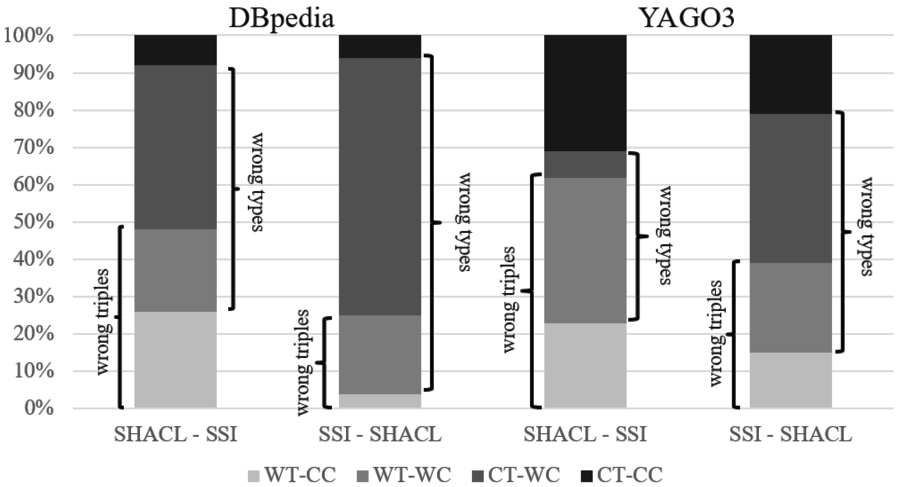
Manual evaluation of the differences between SHACL and SSS on DBpedia and YAGO.
We illustrate the results obtained with our method showing two examples of SHACL constraints learned on DBpedia learned for the relations
The
The
This case illustrate the importance of having readable constraints, which can be understood and improved by specialists. The constraint could be easily fixed by adding the path
One of the limitations of our approach is the cost of considering paths of length
Another limitation is that in its current implementation, PaTyBRED generates negative examples by substituting the subject or object by a randomly selected entity. Since the distribution of instances over classes on most KGs is highly skewed, with some classes being much more likely to be sampled than others. That means the generation of potentially relevant negative examples with instances of infrequent classes is unlikely, which may make it difficult to learn constraints with such infrequent classes.
In order to compensate for this effect, we would need to introduce a bias to selection of entities on the generation of negative examples. A possible solution is to make it more likely to generate instances of the same or sibling classes, making it more likely to select entities of classes that are more closely related to the class of the original entity. That is an interesting problem, however it requires extensive research in order to verify its effectiveness on mitigating the issue.
Conclusion and future work
In this paper, we have investigated three research questions: error detection in knowledge graphs (RQ1), developing a method for sustaining the results of error detection and abstract from individual errors detected to patterns of such errors (RQ2), and automatic correction of such errors (RQ3).
We have shown that although the error detection problem is similar to knowledge completion, methods which perform well in knowledge completion might not necessarily be appropriate for error detection. To address RQ1, we have proposed PaTyBRED, a robust supervised error detection method which relies on type and path features, and compare it with state-of-the-art error detection and knowledge graph completion methods. We demonstrate the importance of combining those path and type features together, and we also perform a manual evaluation of our approach on DBpedia and NELL.
The experiments in our paper show that path features are particularly helpful when detecting the less obvious kinds of errors, e.g., when two entities of the same type are confused. At the same time, the search space for optimal path features is very large, so that a big potential of improvement lies in the development of efficient searching and pruning strategies. For example, in our paper, we have imposed a fixed number of paths of each length to inspect and to create longer paths from, while a flexible approach which always inspects a different fraction of paths of each length might yield better results.
To address RQ3, we have presented CoCKG, an approach for correcting erroneous facts originated from entity confusions in knowledge graphs. The experiments show that CoCKG is capable of correcting wrong triples with confused instances, with estimated precision of 21% of the produced corrections in DBpedia and 14% in NELL. The low precision values obtained do not allow this process, as of now, to be used for fully automatic KG enrichment. Nevertheless, it works as a proof of concept and can be useful, e.g., as suggestions from which a user would ultimately decide whether to execute. Moreover, fusing multiple external signals (e.g., confidence scores of link prediction approaches, external evidence from texts [23,24], other knowledge graphs [7] or fact validation engines [29]) to achieve better scores for the substitution candidates might be a way to improve the performance of CoCKG.
We have observed that there are quite a few characteristic patterns of confusion in knowledge graphs (e.g., artists and albums with the same name, a city and a sports club located in that city, etc.). Similar to learning patterns for typical shapes in a knowledge graph, it might be interesting to learn typical shapes for confusions. Those may serve as good starting points for semi-automatically curating editing guidelines with common mistakes and how to avoid them.
To address RQ2, we have furthermore proposed a method for learning SHACL-SPARQL constraints for relations which is based on the relation assertion error detection method PaTyBRED. We compare the learned SHACL constraints with RDFS domain and range restriction learned with statistical schema induction. We performed a manual comparison of the two approaches on DBpedia, and we show that our SHACL constraints are better at detecting wrong relation assertions while being more robust when handling noise and incompleteness of subject and object type assertions. The SHACL constraints learned are available online19
In the future we plan to investigate the creation of SHACL constraints for numerical and textual data. For numerical data constraints we can extend previous works [16,42] on the area to derive intervals which can be used as constraints. It would also be interesting to adapt CoCKG to support active learning. Since guaranteeing the quality of the newly generated facts is crucial, having input from the user to clarify borderline cases and improve the overall results would be highly valuable. Furthermore, using an ensemble of different KG models with different characteristics, e.g. KG embeddings, instead of a single model may potentially increase the robustness of the system. Finally, it would be worth adding textual features from entities descriptions to help determine if a pair of entities is related or not.
Footnotes
Acknowledgements
The work presented in this paper has been partly supported by the Ministry of Science, Research and the Arts Baden-Württemberg in the project SyKo2W2 (Synthesis of Completion and Correction of Knowledge Graphs on the Web).