
Abstract
Knowledge graphs are often constructed from heterogeneous data sources, using declarative rules that map them to a target ontology and materializing them into RDF. When these data sources are large, the materialization of the entire knowledge graph may be computationally expensive and not suitable for those cases where a rapid materialization is required. In this work, we propose an approach to overcome this limitation, based on the novel concept of mapping partitions. Mapping partitions are defined as groups of mapping rules that generate disjoint subsets of the knowledge graph. Each of these groups can be processed separately, reducing the total amount of memory and execution time required by the materialization process. We have included this optimization in our materialization engine Morph-KGC, and we have evaluated it over three different benchmarks. Our experimental results show that, compared with state-of-the-art techniques, the use of mapping partitions in Morph-KGC presents the following advantages: (i) it decreases significantly the time required for materialization, (ii) it reduces the maximum peak of memory used, and (iii) it scales to data sizes that other engines are not capable of processing currently.
Introduction
The amount of data that is being published in RDF has been steadily increasing in recent years. The generalized acceptance and use of knowledge graphs (KGs) [21] in a wide range of domains and organizations has contributed to this increase. Given that most of the data available inside organizations are structured in heterogeneous data formats, data integration techniques are often used in the data transformation and homogenization process required for knowledge graph construction (KGC).
KGC engines can be considered as data integration systems
There are many techniques and associated implementations that can be used to create knowledge graphs integrating heterogeneous data sources using declarative mapping rules [3,12,15,26,31,33,38,39]. In the specific case of materialization, different optimizations have been proposed to speed up the materialization process in complex data integration scenarios (e.g., high rate of duplicates, large data sources, or transformation functions). Approaches such as SDM-RDFizer [22], RMLStreamer [17] and FunMap [23] propose optimizations to enhance the performance of the materialization process. In our previous work [1], in which we analyzed several KGC engines, the experimental evaluation suggests that more efficient solutions are still needed, especially when the volume of data is large.
Problem and objectives We address the problem of scalability in knowledge graph construction from heterogeneous data sources using declarative mapping rules. Our main objective is to propose the theoretical background and a set of techniques that can enhance the process of KGC in complex data integration systems, increasing the performance in both time and memory consumption.
Proposed approach We present the novel concept of mapping partitions, which can be used to reduce the time required for the materialization of a knowledge graph and the peak amount of memory required in the process. Mapping partitions group rules in the input mapping documents ensuring the generation of disjoint sets of RDF triples by each of them. The experimental evaluation reveals that our proposal outperforms state-of-the-art engines significantly in terms of execution time and memory consumption, as well as our own implementation in the absence of this optimization.
Contributions (i) The novel concept of mapping partition, which allows the identification of rules that produce disjoint sets of RDF triples; (ii) algorithms to find a partition of a mapping document and to remove redundant self-joins within mapping documents; (iii) Morph-KGC, a scalable interpreter of R2RML and RML that implements mapping partition-based construction of the knowledge graph; (iv) an empirical evaluation of our approach and a comparison against four well-known KGC engines using three different benchmarks (GTFS-Madrid-Bench [6], SDM-Genomic-Datasets [22], and NPD [27]).
The remainder of the article is structured as follows. Section 2 introduces R2RML and RML, and presents a set of concepts, notations, and conventions that will be used throughout the rest of the paper. In Section 3 we delve into the foundations of mapping partitions. Section 4 presents the experimental evaluation comparing Morph-KGC with other R2RML and RML engines. Finally, Section 5 summarizes the related work and Section 6 wraps up and outlines future work.
Preliminaries
In this section, we first provide some background by introducing R2RML and RML, the mapping languages that this work focuses on. Then, we present some concepts, notations, and conventions that will be used in the following sections.
R2RML and RML
R2RML [9] is the W3C Recommendation declarative mapping language that links relational databases to the RDF data model. RML [14] is a well-known extension of R2RML that supports input data formats beyond RDBs (e.g., CSV, JSON, or XML). As RML is a superset of R2RML, in this section we present the main notions of these mapping languages focusing solely on RML.
An RML mapping is represented as an RDF graph. An RML mapping document is an RDF document that encodes an RML mapping, and it consists of one or more triples maps. A triples map has one logical source and contains the rules to generate the RDF triples. A triples map consists of one subject map and zero or more predicate-object maps. Each predicate-object map has in turn, one or more predicate maps and object maps. Subject, predicate, and object maps are term maps specifying how to generate the RDF terms in the homonymous positions of the triples. Term maps can be constant-valued (always generate the same value), reference-valued (the values are obtained directly from the logical source, e.g., a column in a table of an RDB), or template-valued (which generate RDF terms with some parts given by constants and others given by references). A template-valued term map comprises a string template, that defines how RDF terms are generated from one or more references (enclosed in curly braces) over the logical source. Constant shortcut properties are a compact method of expressing constant-valued term maps. A referencing object map allows to generate triples in which the object map is given by the subject map of another triples map, known as the parent triples map. A join condition is used when the logical sources of both triples maps are different. The evaluation of a triples map1
In our work, we rely on the normalization of mapping rules as defined in [36]. A normalized mapping does not contain shortcuts, it uses predicate-object maps to type resources, and all its triples maps contain a single predicate-object map with one predicate map and one object map. This is not restrictive as any R2RML or RML document can be normalized [36].
We target KGC where the resulting RDF graph does not contain duplicated triples, as assumed by most engines [3,12,22]. Given that an RDF graph is a set of triples [8], the presence of duplicated triples in the serialization of the RDF graph does not affect the final result. We add this restriction as it has an impact on memory and time consumption, as well as on the size of the resulting files.
We use [R2]RML to refer to R2RML and RML. Our proposal may be easily extended to other R2RML-based mapping languages. We refer to R2RML columns and RML references indistinctly as references. We refer to RDF triples and quads indistinctly. TM, SM, POM and OM denote triples map, subject map, predicate-object map and object map respectively.
Let
The Morph-KGC approach
In this section, we introduce the foundations of Morph-KGC, an [R2]RML engine for constructing knowledge graphs at scale. First, we introduce self-join elimination at the mapping level. Next, we formalize the novel concept of mapping partitions. After that, we propose two algorithms to generate mapping partitions of [R2]RML documents and tackle KGC based on them. Finally, we validate the feasibility of this approach over different benchmarks and real use cases.
Self-join elimination at the mapping level
Most virtualization engines in the state of the art (e.g., [3,35]) remove redundant self-joins in the SQL queries that they generate, with the objective of making query evaluation more efficient. However, most materialization engines do not address self-joins that can occur in a mapping, which in most cases are executed locally by the engine.
(Redundant self-join in an [R2]RML document).
A redundant self-join in an [R2]RML document appears when a referencing object map joins two triples maps with the same logical source and it has join conditions with the same unique references.
Redundant self-joins in an [R2]RML document can be removed by replacing the referencing object maps with object maps given by the subject map of the parent triples map, producing the same set of RDF triples.
Consider the R2RML mapping rules with a self-join taken from GTFS-Madrid-Bench [6]:
Both triples maps use the same database table, and the referencing object map uses the same unique column to join both triples maps. This can be transformed into an object map without a join condition (the second object map in the triples map #shapesTM).

As defined in the R2RML Recommendation [9], the effective SQL query of the referencing object map in the triples map #shapesTM of Example 1 is:

Removing this kind of SQL joins is widely studied in the literature, known as semantic query optimization [4,39]. Under the assumption that the join references in a mapping are unique, self-joins can be eliminated in mapping documents for any data format.
The impact of redundant self-joins in materialization engines has been previously reported by us in [1]. We propose to remove redundant self-joins within the mapping documents to improve the performance of KGC engines without the need to modify their current materialization procedures. In this way, an [R2]RML document without redundant self-joins does not contain referencing object maps involving two triples maps with the same logical source and with the same unique references in the join conditions. This redundant self-join elimination approach is independent from the underlying data format, as opposed to the previous techniques (e.g., [3,35] address RDBs only).
A canonical [R2]RML document is a normalized [R2]RML document without redundant self-joins.
An [R2]RML document and its canonicalization are equivalent, this entails that any transformation of a mapping document comprised in Definition 2 (i.e., normalization and redundant self-join elimination) also generates an equivalent mapping document. Algorithm 1 obtains the canonicalization of any mapping document. First, it normalizes the document (see [36]). Next, it discards referencing object maps with different logical sources in the triples map and the parent triples map (lines 4–6). After that, the algorithm checks that the fields in all join conditions match (lines 7–11). When that happens, the self-join can be removed, and the object map is replaced by the subject map of the parent triples map (lines 12–13).

Canonicalization of an [R2]RML document,
Given an initial set of mapping rules, we aim at identifying those that produce disjoint sets of triples, i.e., the initial mapping rules will be grouped so that those in different groups generate sets of RDF triples that do not overlap. In the following, when we refer to the sets of generated triples, we consider them to be composed of all the triples that a mapping rule, group of mappings rules, or mapping document generate given a data source.
(Mapping Partition of an [R2]RML document)
Multiple mapping partitions can exist for
Consider the mapping rules (taken from [9]):
Both mapping rules can be assigned to different mapping groups as they do not generate common triples, given that the predicates are constants and that they are different. Nonetheless, the mapping rule in #TM2 is dependent on #TM1, since the object map of the former is given by the subject map of the latter, and this results in a join dependency between those mapping groups. This prevents both mapping groups from becoming independent mapping documents.

Figure 1 depicts an example of mapping partitioning that involves three initial mapping documents with eleven normalized mapping rules in total. Six mapping groups are formed, which have between one and three mapping rules. As can be seen, there are join dependencies between different groups of mappings, nonetheless, they are still disjoint in terms of the set of triples that they generate.

We now delve into the rationale to obtain partitions of a mapping document
We define the prefix of a template as the constant (or immutable) part of its string template preceding the first reference in it. If a template starts with a reference, then its prefix is empty (∅). Note that this is different to the notion of prefix declaration in RDF documents.
Consider the following string templates along with their prefixes: 
The prefixes are obtained by eliminating the first reference and what follows. The beginning of the latter string template is data source-dependent and therefore its prefix is ∅.
The invariant If If If
(Invariants).
For simplicity and clarity, we define the following notation for invariants:
Consider the three templates in Example
3
and their invariants
Let
Disjointness of term maps depends on:
(Disjoint Mapping Rules).
Two mapping rules
For two mapping rules to be disjoint, it is required that at least two position-wise term maps are disjoint. This is true because once two triples have a different subject, predicate, object or graph then the triples are immediately distinct. Abusing of notation, given two mapping rules
(Disjoint Mapping Groups of an [R2]RML document).
Two mapping groups
(Maximal Mapping Partition of an [R2]RML document).
The maximal mapping partition of
Given a mapping document, its maximal mapping partition is not necessarily unique, i.e., there may be several maximal mapping partitions for the original mapping document. When all the mapping rules in a mapping document are disjoint, each mapping group in
Mapping partition-based knowledge graph construction
Knowledge graph construction can leverage mapping partitions to reduce execution time and memory consumption. Before this, a partition of the mapping needs to be performed. We propose Algorithm 2, which generates partial mapping partitions by

Partial-Aggregations Partitioning of an [R2]RML document,
The outer for-loop (line 3) of Algorithm 2 iterates four times to retrieve partial mapping partitions by subject, predicate, object and graph. The normalized mappings are sorted lexicographically by the
The time complexity of Algorithm 2 is

Maximal Partitioning of an [R2]RML document,
We also propose Algorithm 3 which generates the maximal mapping partition of an [R2]RML document, i.e., it solves the problem of finding
The time complexity of Algorithm 3 is upper bounded by

The construction of a knowledge graph based on a mapping partition can be done in two different ways. The first one (Fig. 2a) processes each mapping group sequentially. Hence, only the triples of a single mapping group are kept in memory simultaneously to remove duplicated triples. Memory usage is bounded by the largest group of mappings (in terms of the number of triples that it generates). The second one (Fig. 2b) processes each group of mappings in parallel. As a consequence, the execution time is reduced at the cost of increasing the maximum memory required, as multiple triple sets of different groups of mappings are maintained in memory at the same time.
The performance of partition-based KGC strongly depends on the ability to partition mapping documents. If the conditions required to generate mapping partitions are not generally met, then mapping partitioning would not be feasible in practice (for instance,
We have compiled information on mapping partitioning for several well-known benchmarks (namely, NPD [27], BSBM [2], GTFS-Madrid-Bench [6] and LSLOD [18]), the DevOps ICT knowledge graph [7], and other real uses cases from the KGC W3C Community Group2
Mapping partitioning of benchmarks and real use cases
In this section, we experimentally evaluate our proposal. The research questions that we aim to answer are:
Benchmarks We evaluate our proposal on three different testbeds. First, we use GTFS-Madrid-Bench [6], a benchmark in the transport domain, for testing the performance and scalability of our proposal over different tabular data formats and sizes. After that, we use the SDM-Genomic-Datasets [22] from the biomedical domain to evaluate our proposal over different mapping configurations. Finally, we use the Norwegian Petroleum Directorate (NPD) benchmark [27], from the energy domain, to compare different configurations of Morph-KGC. We have used MySQL 8.0 as DBMS for RDB. The NPD benchmark provides the mappings in R2RML, the SDM-Genomic-Datasets in RML, and GTFS-Madrid-Bench provides the mappings in both languages.
Engines We use Morph-KGC v1.1.03
Metrics Execution time: Elapsed time spent by an engine to complete the construction of a KG; it is measured as the absolute wall-clock system time as reported by the time command of the Linux operating system. Memory consumption: The memory used by an engine to construct the KG measured in time slots of 0.1 seconds. In addition, we have verified that the generated RDF are the same for all engines in terms of the number of triples and its correctness. All experiments were executed three times and the average execution time and memory consumption are reported. A timeout of 24 hours is used. The experiments are run on a CPU Intel(R) Xeon(R) Silver 4216 CPU @ 2.10GHz, 20 cores, 128 GB RAM, and a SSD SAS Read-Intensive 12 GB/s. The absolute values obtained for these metrics are available online4
We consider two distributions of the GTFS-Madrid-Bench based on the data format:
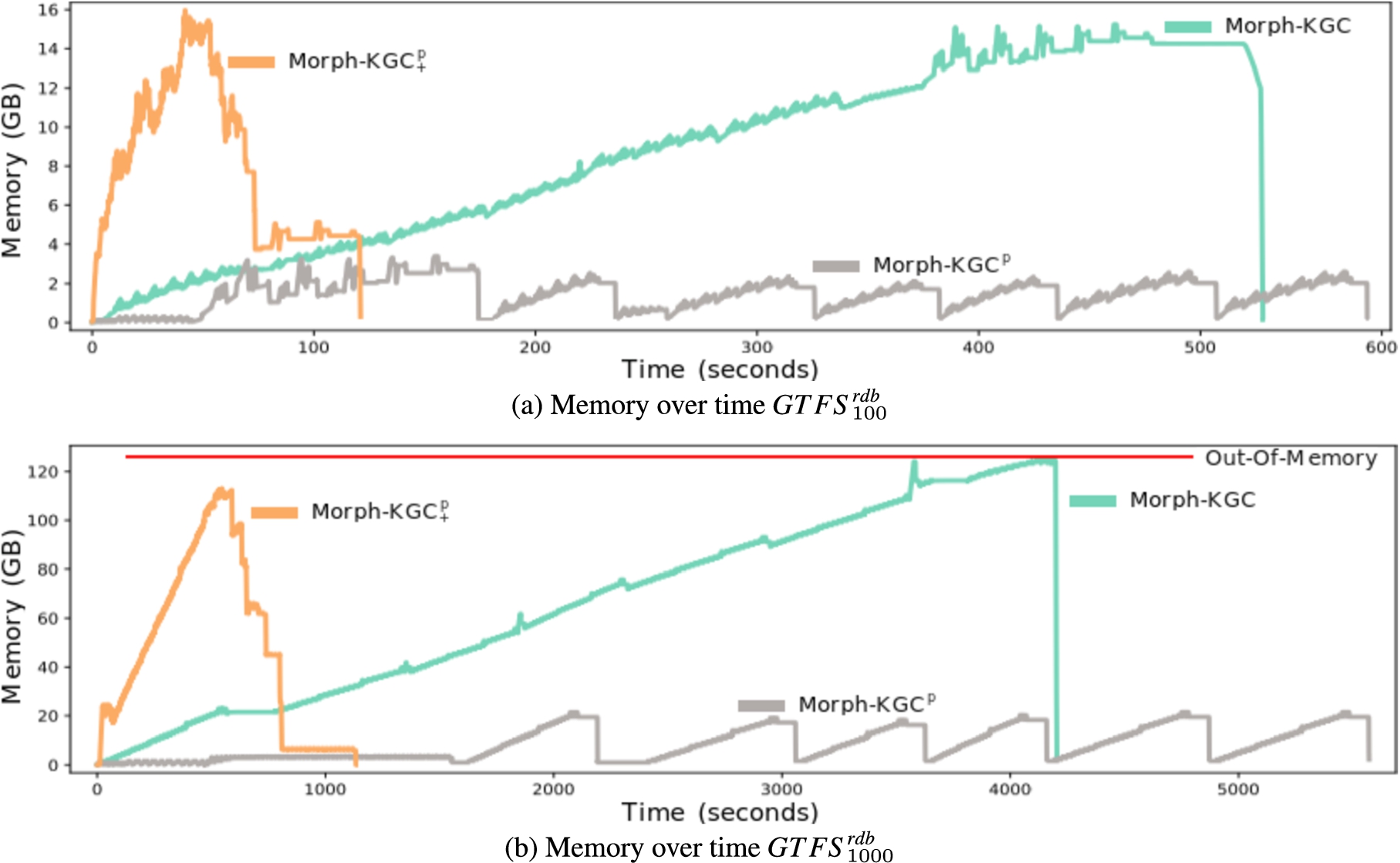
The impact of mapping partitions on the materialization of large input data sources can be observed in Fig. 3. Regarding memory consumption, we can observe that the baseline, Morph-KGC, follows a growing trend over time. The reason is that it keeps the entire KG in memory to avoid the generation of duplicate triples. Indeed, Fig. 3b shows that this approach produces an out-of-memory issue due to the size of the final KG. In the case of

Figure 4a shows the total execution time of Morph-KGC compared to the rest of the selected engines.
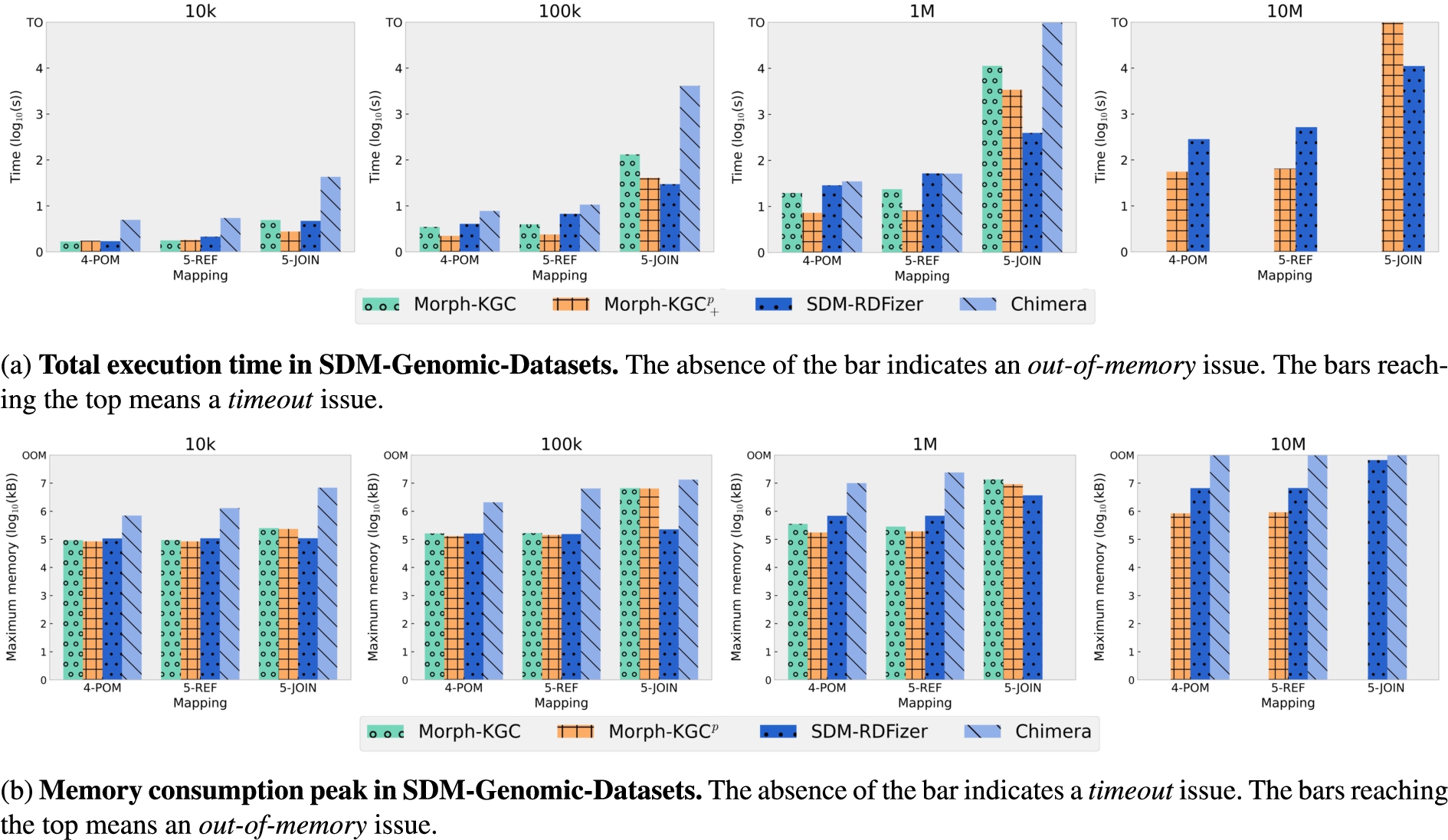
The SDM-Genomic-Datasets5
The total execution times for SDM-Genomic-Datasets are reported in Fig. 5a. As
The NPD benchmark [27] presents a comprehensive evaluation system for virtual KGC engines. It provides a set of SPARQL queries, a scalable instance of an RDB from the energy domain, and the corresponding mapping rules in R2RML. Although it has not been previously used for testing the performance of materialization engines, we notice that it is the only benchmark among those considered in Table 1 in which the difference in the number of mapping groups obtained by the partial-aggregations and the maximal partitioning algorithms is significant. This will allow us to compare the impact of maximal partitioning when it achieves a mapping partition with more groups than partial-aggregations. To further evaluate mapping partitions with different number of groups, we also include the configurations

The results obtained are shown in Fig. 6. We observe that the best performance regarding execution time is obtained by
The experiments with SDM-Genomic-Datasets show that redundant self-join elimination is an effective technique and that it reduces the execution time of materialization. The same behaviour was also reported by us in [1] for GTFS-Madrid-Bench. Since our technique applies directly to mappings, it is engine independent and can also be applied to any data format, as opposed to other proposals such as [3], that only work for RDBs. Any engine can benefit from this technique by preprocessing the mapping rules using Algorithm 1. However, this only applies to redundant self-joins, and the experiments with SDM-Genomics-Datasets also show that Morph-KGC is outperformed by SDM-RDFizer in complex joins, given that it implements the Predicate Join Tuple Table. Morph-KGC could implement this data structure to speed up other kinds of joins. The impact of high join selectivity in KG materialization has been shown in [5].
In general, our empirical evaluation shows that mapping partitioning is an effective technique for knowledge graph materialization that avoids the generation of duplicate triples. Concurrent processing of mapping partitions has achieved the best execution times in many of the evaluation configurations, except for those involving complex joins as previously mentioned. We have seen that in scenarios with several types of mappings (POM+REF+JOIN) (e.g., GTFS-Madrid-Bench or NPD),
We have seen in the experiment with NPD benchmark that the number of mapping groups in a partition has an impact on the performance of materialization. Regarding the execution time, a higher number of mapping groups entail a faster execution in parallel processing. However, once the maximum parallelization capacity of the machine is reached, a higher number of mapping groups does not reduce the execution time and can even slightly increase it. In respect to memory consumption, sequential processing bounds the maximum peak of memory to that of the largest mapping group. A higher number of groups only reduces this peak in the case that the largest mapping group has been further partitioned.
Related work
Ontology-based data integration [34,41] systems differentiate between the data layer, composed of the data sources, and the conceptual layer, in which an ontology or network of ontologies are used to abstract the heterogeneity of the former. Mappings are used to specify how to populate entities and relationships in the ontology with data from the underlying data sources, i.e., mappings are the link mechanism between both layers.
Several languages have been proposed to define mappings [16,19,29], but the one that stands out most notably is R2RML [9], the W3C Recommendation to map relational databases to RDF. However, R2RML does not generalize the underlying data model and cannot deal with heterogeneous data formats. RML [14] is a well-known superset of R2RML that removes specific references to the relational data model and enables data formats beyond RDBs. In addition, other R2RML-related proposals have addressed transformation functions [11,12], mixed content and RDF collections [33], usability [20] or scalability [40].
There are two approaches to process the mappings: virtualization (or query translation) and materialization (or data translation). Virtualization uses mappings to translate SPARQL queries into the native query languages of the underlying data sources. Research around this technique has focused primarily on relational databases and on efficiently processing the generated SQL queries. We refer the interested reader on virtualization to [3,15,35,39,42]. Materialization uses the mappings to transform all data in the underlying data sources to the corresponding RDF.
There are several solutions targeting the materialization of knowledge graphs [1]. For the specific case of RDBs, Ontop [3,43] leverages the fact that predicate maps are generally constant-valued. It generates one SPARQL query for each predicate with unbounded subject and object. These queries are then translated to SQL and optimized by applying a set of structural optimizations (e.g., subqueries elimination) and semantic query optimizations (e.g., redundant self-joins removal). It also avoids to retrieve large query result sets at once by doing it in chunks.
The work presented in [25] exploits knowledge encoded in the mapping documents to project the attributes appearing in a triples map, reducing the size of the data sources that need to be processed. Similarly, to diminish the impact of duplicates in the evaluation of join conditions, it also pushes down projections into joins. SDM-RDFizer [22] proposes physical data structures to store the knowledge graph in memory in a way that allows to efficiently remove duplicates and avoid unnecessary operations. In particular, it uses one hash table for each predicate (called Predicate Tuple Table, where the hash key combines the subject and the object of the triple, and the value is the triple itself. It also proposes to speed up joins by creating the Predicate Join Tuple Table, a hash table using the values matching the join condition as the hash key, and being the values of the hash the set of the generated values by the parent triples map. These hash tables are checked every time a new triple is to be generated, in the case that the triple already exists, it is discarded, otherwise it is added to the knowledge graph, and the corresponding hash table is updated. Moreover, SDM-RDFizer considers data compression techniques that reduce the memory usage of the data structures that store intermediate results during materialization.
Recently, triples map planning has been proposed in [24]. Here a bushy tree plan is created specifying an optimized execution order for executing mapping assertions. These bushy tree plans are obtained heuristically by relying on a greedy algorithm. Operating system commands are obtained from these execution plans that allow to efficiently execute different knowledge graph materialization engines.
Karma [26] tackles the scalability of knowledge graph construction from large data sources using batch processing. Instead of loading all data into memory, when operating in batch mode, the engine continuously loads fractions of the data, transforming them to the nested relational model and then materializing the corresponding triples. In this manner, memory usage is reduced, as it is not required to maintain the entire knowledge graph in memory.
Parallelization has also been proposed to speed up the materialization process. The work presented in [17] divides this process in three tasks following the producer-consumer paradigm: ingestion of data from the sources, mapping to RDF, and combination of the RDF. Parallelization is done up to the data record level. Nevertheless, the proposed approach does not tackle duplicate elimination. [22,37] also parallelize at the triples map level.
Regarding the efficient processing of transformation functions, FunMap [23] addresses the materialization of these functions specified using FnO [10]. FunMap proposes a set of lossless rewriting rules so that the functions are executed in the initial steps of the KG materialization process. This approach generates a set of mapping rules that are function-free and that can be executed by any RML engine.
Mapping partitioning can be used together with existing techniques to further optimize the process of knowledge graph materialization. For instance, the Predicate Join Tuple Table could be implemented along with mapping partitioning to speed up joins in parallel and sequential processing. Moreover, redundant self-join elimination could be implemented as a preprocessing step (similarly to other techniques such as the rewriting of rules in FunMap) which generates mappings without redundant self-joins that can be executed by any engine.
Conclusions and future work
We address the problem of scalability in the materialization of knowledge graphs from heterogeneous data sources using declarative mapping rules. We present the novel concept of mapping partitions, which consists in grouping mapping rules that generate disjoints sets of RDF triples. Mapping partitions can be used to reduce memory consumption in KG materialization by processing each mapping group in a partition sequentially, or to decrease the execution time by processing multiple mapping groups in parallel. We implement this novel approach in an [R2]RML engine, Morph-KGC, and we empirically demonstrate that, in the general case, it outperforms state-of-the-art proposals in terms of the total execution time and the amount of memory required in the materialization process.
Our future lines of work include the extension of Morph-KGC and mapping partitions to RML-star [13], which poses the challenge of recursive and more complex mapping rules. We also plan to address the limitation of the current approach that prevents minimizing materialization time and memory consumption at the same time, by using standards such as MPI [32].
Footnotes
Acknowledgements
This work was funded partially by the project Knowledge Spaces: Técnicas y herramientas para la gestión de grafos de conocimientos para dar soporte a espacios de datos (Grant PID2020-118274RB-I00, funded by MCIN/AEI/ 10.13039/501100011033) and also received partial financial support in the frame of the Euratom Research and Training Programme 2019–2020 under grant agreement No 900018 (ENTENTE project). David Chaves-Fraga is supported by the Spanish Minister of Universities (Ministerio de Universidades) and by the NextGenerationEU funds through the Margarita Salas postdoctoral fellowship.