
Abstract
Analyzing statements of facts and claims in online discourse is subject of a multitude of research areas. Methods from natural language processing and computational linguistics help investigate issues such as the spread of biased narratives and falsehoods on the Web. Related tasks include fact-checking, stance detection and argumentation mining. Knowledge-based approaches, in particular works in knowledge base construction and augmentation, are concerned with mining, verifying and representing factual knowledge. While all these fields are concerned with strongly related notions, such as claims, facts and evidence, terminology and conceptualisations used across and within communities vary heavily, making it hard to assess commonalities and relations of related works and how research in one field may contribute to address problems in another. We survey the state-of-the-art from a range of fields in this interdisciplinary area across a range of research tasks. We assess varying definitions and propose a conceptual model – Open Claims – for claims and related notions that takes into consideration their inherent complexity, distinguishing between their meaning, linguistic representation and context. We also introduce an implementation of this model by using established vocabularies and discuss applications across various tasks related to online discourse analysis.
Introduction
The Web has evolved into an ubiquitous platform where many people have the opportunity to be publishers, to express opinions and to interact with others. It has been widely explored as a source to mine and understand online discourse or to extract knowledge.
On the one hand, understanding and analyzing societal discourse on the Web are becoming increasingly important issues involving computational methods in natural language processing (NLP) or computational linguistics. Related tasks include fact or claim verification, discourse modeling, stance detection or argumentation mining. In this context, a wide range of interdisciplinary research directions have emerged involving a variety of scientific disciplines including investigations into the spreading patterns of false claims on Twitter [197], pipelines for discovering and finding the stance of claim-relevant Web documents [20,70,203], approaches for classifying sources of news, such as Web pages, pay-level domains, users or posts [143], or research into fake news detection [190] and automatic fact-checking [75]. In addition, understanding discourse in scholarly and scientific works has been a long-standing research problem throughout the past years [1,57,58,61,64–66,79,83,87,94,95,120].
On the other hand, knowledge-based approaches, in particular works in knowledge base (KB) construction and augmentation, often are concerned with mining, verifying and representing factual knowledge from the Web. Research in such areas often deploys methods and conceptualisations strongly related to some of the aforementioned computational methods related to claims, e.g. when aiming to verify facts from the Web for augmenting KBs [37,214]. Whereas the focus in knowledge base augmentation is on extracting and formally representing trust-worthy factual statements as an atomic assertion in the first-order-logic sense, research focused on interpreting claims expressed in natural language tends to put stronger emphasis on understanding the context of a claim, e.g. its source, timing, location or its role as an argument as part of (online) discourse. Capturing the meaning of claims requires both to preserve the actual claim utterances as natural language texts as well as structured knowledge about the claims. Utterances often carry a range of assertions and sentiments embedded in complex sentence structures, which are easy to process by humans but are hard to interpret by machines. Preserving structured knowledge about claims, including their contexts and constituents, enables machine-interpretation, discoverability and reuse of claims, for instance, to facilitate research in the aforementioned areas.
Despite these differences, methods in various disparate fields, such as claim/fact verification or fact-checking as well as KB augmentation, tend to be based on similar intuitions and heuristics and are concerned with similar and related notions from different perspectives. Hence, achieving a shared understanding and terminology has become a crucial challenge.
However, both the used terminology and the underlying conceptual models are still strongly diverging, within and across the academic literature and the involved applications [35,186]. For example, “Animals should have lawful rights” is considered a claim in Chen et al. [29] and according to many definitions from the argumentation mining community which define claims as the conclusive parts of an argument. It does not constitute a claim according to the guidelines of the FEVER fact-checking challenge [184] where claims are defined as factoid statements. This claim would also not be eligible for inclusion in a fact-checking portal as it does not contain factual content that can be checked and does not seem check-worthy (although this would depend on the context, such as who uttered the statement and when). The claim might be contained in the ground truth of a topic-independent claim extraction approach, but might only be used to evaluate a topic-dependent approach when it is connected to a given topic (more details in Section 3).
This heterogeneity poses challenges for the understanding of related works and data by both humans as well as machines and hinders the cross-fertilisation of research across various distinct, yet related fields. Thus, our work aims at facilitating a shared understanding of claims and related terminology across diverse communities as well as the representation of semi-structured knowledge about claims and their context, which is a crucial requirement for advancing, replicating, and validating research in the aforementioned fields.
In order to address the aforementioned problems, this paper makes the following main contributions:
Note that while an earlier version of the conceptual model has been presented in Boland et al. [23], the novel contributions of this work include the actual survey of related works in the context of online discourse, a critical review of related tasks, as well as improvements to the model and its implementation facilitated by the substantial survey provided here.
This work is meant to facilitate a shared representation of claims across various communities, as is required for inter-disciplinary research. This includes works aimed at detecting and representing the inherent relations of uttered claims among each other or with represented factual knowledge and other resources, such as web pages or social media posts, e.g., as part of stance detection tasks. Assessing and modeling the similarity of claims, for example, is a challenging task. When two claims are similar to each other, what precisely does this mean? Do they have the same topic but have been uttered to express a different stance? Are they expressing a shared viewpoint but have been uttered by different agents? Do they talk about similar topics but with diverging specificity, i.e. the topic of one claim is a single aspect of the more broad topic of the other one? Or is one claim a part of a more complex claim that includes multiple assertions? Even claims deemed equal with regard to their content may have to be differentiated: they may, for example, be repeated utterances with the same content by the same agent (but at different times), paraphrases (same content but different utterances, also at different times, maybe by different agents) or just duplicates in the respective database. A fine-grained model that allows relating claims and individual claim components allows specifying different dimensions of relatedness and similarity. This also enables more formal and clear definitions for tasks related to detection of claim similarity and relatedness. Use cases involve research into the detection of viewpoints and communities sharing related narratives and viewpoints on the Web [172], the analysis of quotation patterns involving varied sources and media types or profiling of sources and references used in news media [126], and fact-checking applications, e.g. linking claims to previously fact-checked claims [109,162].
Methodology of the survey
In this section, we describe the publication selection and review process employed in this survey. An overview of the workflow is given in Fig. 1.
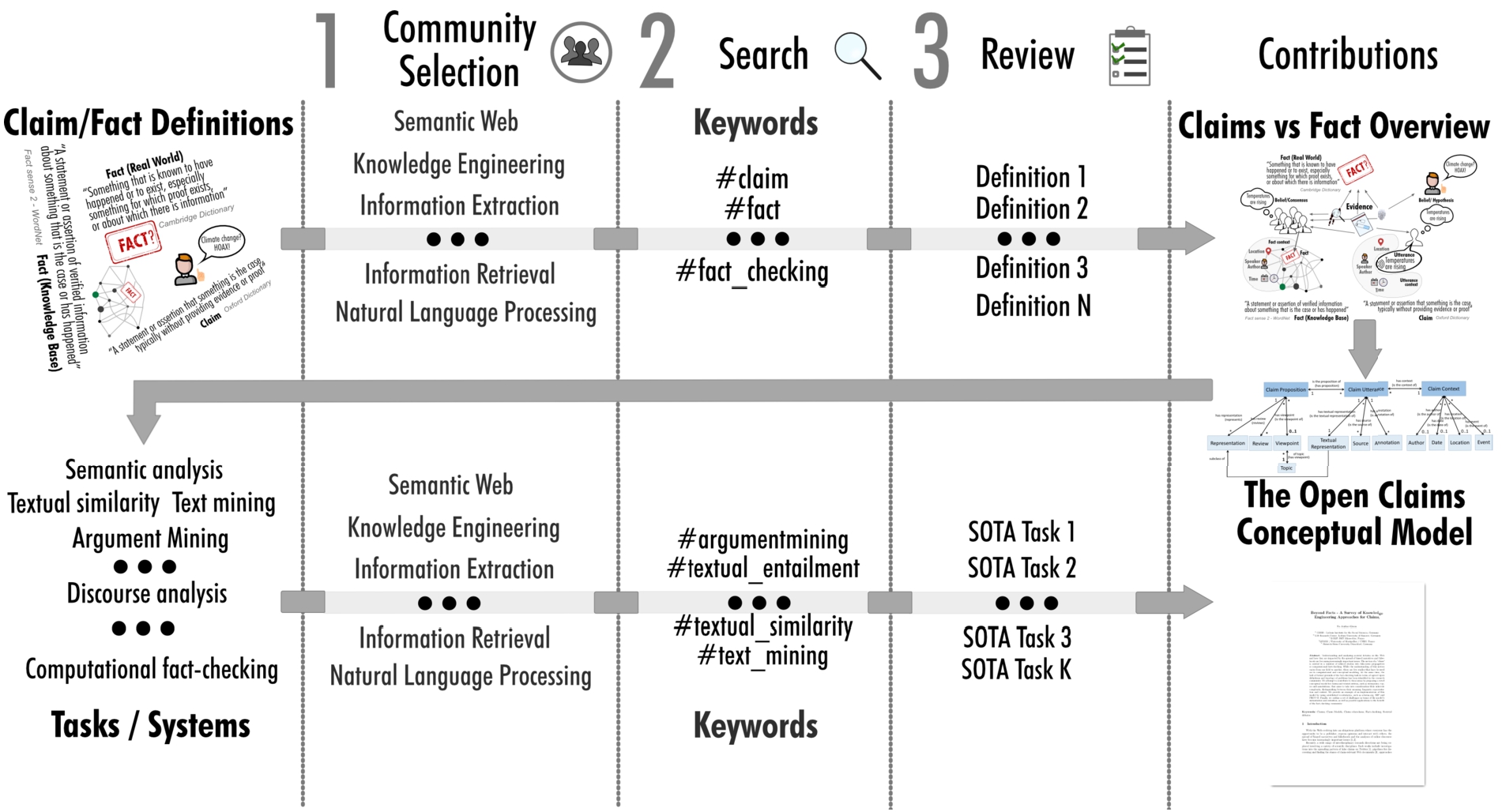
Publication selection and review workflow.
First, we identified application areas and research fields involved with claims, facts or relevant concepts.
Application domains include, on the one hand, areas related to natural language claims, which are of concern in fact-checking portals, computational journalism or scientific discourse analysis, for instance, as part of scholarly publications, all involving claims of varying complexity. On the other hand, structured knowledge bases such as Wikidata are used in various applications such as Web search and involve factual statements bound to a predefined grammar relying on triples involving a subject (s), predicate (p) and object (o).
It becomes apparent that a more explicit and clear definition of the concepts of facts vs. claims is needed as both are relevant to this survey. Works focusing on claims made in the context of discourse can be found in argumentation mining, argumentation theory, discourse modeling, and pragmatics.
Facts are central for knowledge representation/augmentation works. With claims not only transporting beliefs or knowledge about factual information, but also conveying subjective information such as opinions, stances or viewpoints, relevant definitions and concepts can also be found in works targeting stance detection, viewpoint extraction and opinion mining/sentiment analysis. Rumours can be considered specific kinds of claims, thus we include definitions from the rumour detection field. Finally, retrieval of claims or respectively facts about specific entities is central to question answering and information retrieval in general, for instance, in the context of fact retrieval, entity summarisation or entity retrieval. Relevant works from these fields are also taken into account.
Search and review process
Works addressing the aforementioned fields and tasks can be found in a variety of different scientific communities, particularly NLP, Web Mining, Information Retrieval (IR), Knowledge-based Systems and Artificial Intelligence (AI). Based on an initial set of publications from these communities dealing with extraction, verification or linking of claims and facts, found using a keyword-based search, we selected venues from the most relevant papers for systematic screening. Table 1 gives an overview of the chosen core journals, conferences, workshops and events. For each of those, we screened the proceedings of the years 2015–2019 (incl. 2020 and 2021 to the extent possible at the time of writing and revision preparation) and widened the search beyond these venues using online search engines and databases, also considering pre-prints. Publications cited by relevant publications were also taken into account regardless of their venue. For each publication, we extracted formal and informal definitions and descriptions of the concepts of claims and facts which are the basis for the analysis in Section 3 and the development of the model introduced in Section 4. As part of the modeling process, we defined possible relations between the different classes and mapped the generation of information on classes and relations to knowledge engineering tasks (Section 5). We extended our search in the listed venues and beyond to also cover these tasks. The following set of keywords was used for both steps: fact-checking, fact checking, fake news, fact verification, argumentation, discourse, pragmatics, logic, knowledge representation, knowledge base augmentation, knowledge base construction, Knowledge-Base Augmentation, stance, viewpoint, claim, opinion mining, sentiment analysis, rumour detection, rumor detection, question answering, information extraction, relation extraction, ontology learning. This search procedure resulted in a set of 598 publications that we deemed potentially relevant for the topics. Distribution across venues and time periods are displayed in Figs 2 and 3. Note that not all of these publications contain relevant definitions or ended up being cited in this survey. To maintain readability, both figures only contain venues and years, for which we collected at least 10 publications.
Core venues analyzed systematically for the survey of fact and claim definitions and related concepts. Related events and workshops that were also considered: Workshop on Argument Mining (ArgMining), Fake News Challenge (FNC), CLEF Lab: CheckThat!, Fact Extraction and VERification (FEVER) Shared Task
Core venues analyzed systematically for the survey of fact and claim definitions and related concepts. Related events and workshops that were also considered: Workshop on Argument Mining (ArgMining), Fake News Challenge (FNC), CLEF Lab: CheckThat!, Fact Extraction and VERification (FEVER) Shared Task

Analyzed publications and distribution over venues for all venues with at least 10 publications.

Analyzed publications and distribution over years for all years with at least 10 publications.
While this is, to the best of our knowledge, the first extensive survey on the conceptualization of facts and claims, several works have looked into different aspects of the problem providing overviews of related work in specific areas related to these aspects.
Konstantinovskiy et al. [88] present a novel annotation schema and a benchmark for check-worthy claim detection, providing both an overview of claim definitions from other studies and a new definition of a claim that is constructed as a common denominator of existing ones. The novelty is that the definition is cast in the context of a claim being worthy of fact-checking – an important property of an utterance in view of verifying its veracity. The difficulty of identifying and defining fact-check worthiness of a claim is discussed with regard to the different perspectives that can be given to a single claim according to the human annotator’s background.
Daxenberger et al. [35] also take interest in the task of claim identification, but from an argumentation mining perspective, where this task is defined as recognizing argument components in argumentative discourse. The authors propose a qualitative analysis of claim conceptualization in argumentation mining data sets from six different domains (“different domains” here mean different data distributions). They show that the ways in which claims are conceptualized in each of these data sets are largely diverging and discuss and analyze the presumed harmful impact of these divergences on the task of cross-domain claim identification.
Thorne et al. [180] take a holistic stance on the problem and task of automated fact-checking. They provide an overview of approaches, data sets and methods covering the various steps of the process. This is the first paper of its kind that formulates the ambition to unify the often diverging definitions presented in related works from the fact-checking field by identifying shared concepts, data sets and models. A particularity of the survey is the fact that the authors consider both text-like and structured definitions of claims (e.g. in the form of triples), covering works on knowledge graph building and completion.
Fake news detection is related to fact-checking, but remains a distinct problem. Zhou et al. [222] provide a definition of fake news and present relevant fundamental theories in various disciplines on human cognition and behaviour that are assumed useful for understanding fake news propagation and detection. Their survey on fake news detection methods is built along four categories of methods: (i) Knowledge-based methods, which verify if the knowledge within the news content matches certified facts; (ii) Style-based methods that look into the form of fake news (e.g., expressing extreme emotions); (iii) Propagation-based methods that are based on online spreading patterns; and (iv) Source-based methods investigating the credibility of sources.
Rumours are often seen as a specific kind of fake news. Zubiaga et al. [224] provide a survey on rumour identification and resolution, where conflicting and diverging definitions of rumours from related works are discussed, but without making parallels to related notions such as fake news or biased discourse. The main motivations are the assumed impact of social media on rumour generation and spread. The survey focuses on datasets for rumour detection, as well as existing tools for accessing, collecting and annotating social media data for the purposes of automated rumour detection. The authors analyse generic rumour detection systems by breaking them down to their different components and subsequently discussing the related approaches to address the challenges related to each of those components. In that, the paper presents rumour tracking systems, rumour stance classification and veracity classification approaches.
Both the lack of and necessity for shared understanding and conceptualization of claims surfaces from all of the above studies, which is underlined as their main motivation. However, the fact that some of these surveys discuss the same notions and refer to the overlapping sets of related work but by using different terminology (like e.g. [224]) comes to show that these works do not fully contribute to closing the terminological and conceptual gap that exists within and across fields as these studies discuss more narrow concepts of claims/facts used in specific domains rather than aiming at providing a shared view on the overlap and differences between used terminology.
Facts and claims – a multidisciplinary survey of definitions

An overview of definitions and relations between facts and claims.
While the analysis of facts and claims plays a crucial role for a number of fields, the definitions of these concepts vary and are often left to the intuition of the reader. Existing definitions vary considerably not only across different fields but also within a single community. At the same time, different communities use the same terminology to refer to different concepts. In this section, we expatiate on different concepts for facts and claims, explain commonalities and differences and introduce a selected vocabulary to refer to these and related concepts throughout this paper. An overview is given in Fig. 4.
A fact in the everyday use of the term (depicted on the top of Fig. 4) refers to “A thing that is known or proved to be true”,1
Oxford Dictionary;
Merriam-Webster Dictionary;
Cambridge Dictionary;
Dictionary.com;
WordNet;
WordNet;
In the semantic web community and the fields of knowledge representation and knowledge base construction/augmentation, facts are seen as the knowledge that is represented in KGs or KBs [6,9,12,28,31,46,47,50,110,110,115,131,153,165,189,193,196,200,216,223]. More precisely, items in KGs or KBs are coined statements of facts or assertions or triples encoding/representing facts [28,31,115,165,193], with the facts being assumed to be true, can be proven to be true or are likely to hold [31,131,142]. However, the use of terminology is not consistent: fact is often used as synonym for RDF triple [50,82,131,218,223] or for the representation of a fact, respectively assertion, but there is often no distinction made between “fact” and “statement of a fact” [46,110,115,153]. The interchangeable use of “statement of fact” and “fact” leads to a widespread terminology of “checking whether facts are true” [175], implying that facts may not be true. Depending on the precise definition of fact, this might be an oxymoron, i.e. when defining a fact as something that is known to be true. Having the task of fact-prediction as background, some works coin the relations between entities or the paths in a knowledge base as facts [131,196]. As Gerber et al. [50] note, facts have a scope, e.g. a temporal one, that determines the context that has to be taken into account in order to judge their validity.
Types of facts
Several more fine-grained distinctions of different types of facts can be found in the literature. Facts can refer to relations or attributes [218], or can be attributes of other facts [196]. They can pertain to numerical properties, quotes or other object properties [82]. They can be assessed according to their “check-worthiness” [82] or importance for the containing KB [196]. Another interesting distinction is made by Tsurel et al. [191] who aim at identifying facts that are suitable to be used as interesting trivia by developing a measure for trivia-worthiness that relies on surprise and cohesiveness of the contained information.
Throughout this paper, we will use the term fact referring to knowledge that is generally accepted to be true and refer to items in knowledge bases as statements of facts.
Facts vs. evidence
Related to the notion of fact is the notion of evidence. Evidence is seen as something to support or contradict a claim [3,150,171]. Some works give a more narrow definition relating to their specific use cases, e.g. Zhan et al. [216, p. 1] define evidence as “text, e.g. web-pages and documents, that can be used to prove if news content is or is not true”. As Stahlhut [171] notes, the task of evidence detection is similar to premise detection in argumentation mining. A premise in argumentation mining is, as Stab et al. [169, p. 1] put it, “a reason given by an author for persuading the readers of the claim”. Evidence and premise directly correspond to each other, as both terms are often used interchangeably [101,166,188].
Evidence can be categorized into many different types, such as expert opinion, anecdote, or study data [171], or, with slightly different wording, study, expert or anecdotal [3]. Walker et al. [199] distinguish lay testimony, medical records, performance evaluations, other service records, other expert opinions, other records. Niculae et al. [125] include references such as URLs or citations as pointers to evidence. Premises can refer to logos, pathos or ethos [80]. For scientific articles, Mayer et al. [112] distinguish the classes comparative, significance, side-effect, other.
While some works refer to knowledge found in texts or other resources as evidence for a fact [9,46,127,153] and call it fact only after the truthfulness has been determined and that knowledge is entered into a knowledge base, other works assume the truthfulness of the mentions and refer to them or the knowledge they represent as facts directly [32,71]. Very related is the task of Truth Discovery. “Truth Discovery aims at identifying facts (true claims) when conflicting claims are made by several sources” [18]. In this domain, the terms data items and truths are used to refer to invalidated mentions of knowledge and the true values respectively [202,209].
Claims
A claim is commonly seen as “a statement or assertion that something is the case, typically without providing evidence or proof”.7
In line with this definition, works in argumentation mining and argumentation theory focus on claims as the key components of arguments [35], as statements that are made to convince others or express someone’s views, evaluations or interpretations [80,102,107,152].
Claims denominate the conclusion of an argument, the assertion the argument aims to prove or the thesis to be justified [19,97,100–102,133,169]. Claims correspond to propositions in argumentation models and both terms are often used interchangeably, “The claim is a proposition, an idea which is either true or false, put forward by somebody as true” [133]. As Daxenberger et al. [35] point out, the exact definition of a claim, even inside the field of argumentation mining, depends on the domain or task and is somewhat arbitrary. Also, as Torsi et al. [186] show, related annotation categories are often not well defined.
With the use case of scientific articles in mind, Mayer et al. [111] define a claim as a concluding statement made by the author about the outcome of the study. Focusing on debates, Aharoni et al. [3, 2], but also Rinott et al. [150, 1], define a claim as a “general, concise statement that directly supports or contests the topic”. A topic here is defined as “a short, usually controversial statement that defines the subject of interest” or “a short phrase that frames the discussion” respectively. Examples for such topics are “Use of performance enhancing drugs (PEDs) in professional sports” with a claim being “PEDs can be harmful to athletes health” [150, p. 2] or “The sale of violent video games to minors should be banned” with a claim being “Violent video games can increase children’s aggression”[3, p. 3]. Note that these definitions diverge from the common definition of a topic as the underlying semantic theme of a document with a topic being a probability distribution over terms in a vocabulary [22] as used in topic modelling and document classification. There, a topic may be represented by terms on a coarse-grained level such as Health or Computers & Internet [211]. This concept of a topic is also used by Chen et al. [29] in their work about discovering perspectives about claims. Also, the second example of a topic can be seen as a claim or stance itself. Durmus et al. [40] represent topics by tags of pre-defined categories similar to the above described semantic themes plus what they call a thesis, corresponding to Aharoni et al. [3]’s claim-like topics, e.g. “free Press is necessary to democracy.”, “All drugs should be legalised.”.
In the following, topic will be used to refer to the frame of the discussion, as defined by Rinott et al. [150] while the underlying semantic theme will be referred to as the subject.
Types of claims
According to Lippi et al. [102], there are three different types of claims: 1) epistemic, i.e., claims about knowledge or beliefs, 2) practical, i.e., claims about actions, alternatives and consequences, and 3) moral, i.e., claims about values or preferences. For example, “our survival rate for cancer that used to be some of the worse in Europe now actually is one of the best in Europe, we are changing the NHS and we are improving it” [sic] is an epistemic, “cuts will have to come, but we can do it in a balanced way, we can do it in a fair way” a practical and “I don’t want Rebecca, I don’t want my own kids, I don’t want any of our children to pay the price for this generation’s mistake” a moral claim [102].
Similarly, Schiappa et al. [45,157] differentiate claims of fact, value and policy. Claims of fact state that something is true, i.e. they express a belief about a fact. This corresponds to the epistemic claims according to Lippi et al. [102]’s taxonomy with claims of value and policy corresponding to moral and practical claims, respectively. Epistemic claims are also referred to as factoid claims [183,184] or, more commonly, factual claims, e.g. [51,52,75,76,88,97,117,130]. However, assessing the factuality of a claim may refer to assessing a claim’s veracity [74] rather than assessing whether it is a factual or non-factual claim. Note that all types of claims can be used to express a stance in discourse but not all of them are verifiable.
Some works propose a more fine-grained differentiation of claims according to their use cases, e.g. Lauscher et al. [95] distinguish Own Claims vs. Background Claims vs. references to Data for argumentation mining of scientific texts. Hassan et al. [77] distinguish between the classes Non-statistical (e.g. quotes), Statistical, Media (e.g., photo or video), and Other, Zhang et al. [217] between categorical vs. numerical claims. Park et al. [136] categorize claims according to their verifiablity and distinguish between unverifiable, verifiable nonexperiential, verifiable experiential claims with experiential referring to whether the claim refers to the writer’s personal state or experience or not. Another notion that can be seen as a specific type of claim is a rumour. In an attempt to unify various definitions found in works addressing the identification and veracity assessment of rumours, Zubiaga et al. [224, p. 1] define rumours as “items of information that are unverified at the time of posting”. The authors further distinguish between different types of rumours, with respect to their currentness (emerging vs. longstanding rumours).
Claims vs. stances vs. viewpoints
Habernal et al. [68] explain that the term claim in the context of argumentation theory is a synonym for standpoint or point of view referring to what is being argued about, i.e. the topic. This is in line with Liebeck et al’s [98] and Aharoni et al’s [3] debate-oriented definition and with Hidey et al’s [80, p. 4] definition of claims as “proposition that expresses the speaker’s stance on a certain matter”. Standpoint, point of view and stance in these definitions do not mean the content of the claim has to be of an unverifiable or of a purely opinionated nature. Stab et al. [170] see a stance as an attribute of a claim.
Stances are usually defined as text fragments representing opinions, perspectives, points of views or attitudes with respect to a target [52,53,70,89,221]. They can be expressed explicitly or implicitly [146]. Fragments can be messages such as tweets or posts [55,86], paragraphs [144] or complete articles [70]. Joseph et al. [86] see stances as latent properties of users rather than text fragments. Text fragments can however reveal a user’s stance. As Joseph et al. [86] point out, stance and sentiment are related, but not the same: a negative sentiment of a text can be paired with a positive stance towards a particular target and vice versa. Also the tasks of aspect-based sentiment analysis and stance detection differ, even though both aim at detecting opinions towards a target. For example, a piece of text may express a positive sentiment towards a specific aspect of a person, e.g. their personality, but still argue against this person’s claim.
Stance detection has been used to determine opinions on the veracity of claims [43,108]. Stances in these works are similar to what is coined evidence in fact-checking works, as described above, although they do not necessarily contain factual information that can be used to verify information. Note that this may be the case for evidence as well, depending on the precise definition. The fact that a claim is supported by another entity than the source can be seen as evidence for the claim’s truthfulness in itself (cf. expert-type evidence).
Stances have been classified into different categories such as for, against and observing [43], pro and con [14] and none [185], agree, disagree, discuss, or unrelated [118]. There is also a hierarchical model that classifies the stance of web documents in three levels: first as related or unrelated, the related ones as taking a stance or being neutral, and those taking a stance as agree or disagree [154]. Another fine-grained distinction can be found in Hidey et al., [80] who distinguish interpretations, rational evaluations, emotional evaluations, agreement and disagreement. As Kotonya et al. [89] note, the task of stance classification is closely related to relation-based argumentation mining that determines attack and support relations between argumentative units.
Another related task is that of viewpoint discovery. Thonet et al. [177] define a viewpoint as “the standpoint of one or several authors on a set of topics”. A viewpoint goes beyond a person’s stance on a specific subject and represents their global standpoint or side they are taking. As Thonet et al. [177] explain, a viewpoint in a debate about the building of Israeli communities on disputed lands can for example be summarized as “pro-Palestine” or “pro-Israel”. Consequently, Viewpoint Discovery is considered a sub-task of Opinion Mining [145,177].
Another closely related, but different notion is that of a perspective which Chen et al. describe as an argument that constitutes a particular attitude towards a given claim, an opinion in support of a given claim or against it [29]. For example, for a claim “Animals should have lawful rights” a perspective would be “Animals are equal to human beings”, which would express support for the claim. A perspective corresponds to an opinion on a specific aspect in a viewpoint. Perspectives can be supported by evidence, connected to claims by supports or attacks relations and can be seen as a specific type of claims that are connected to what Chen et al. coin argue-worthy claims.
Claims in journalism and fact-checking
Works outside of the area of argumentation focus less on the role of the claim in the context of the discourse and more on the content of the claims.
A very general definition is given by Zhang et al. [217, p. 2] for their truth discovery approach: “A claim is defined as a piece of information provided by a source towards an entity”.
From a journalistic fact-checking perspective, dedicated platforms focus on statements supported by (a group of) people or organizations that appear news-worthy, check-worthy, significant and verifiable (cf. definitions from, e.g., politifact.com,8
For other use cases, different definitions or restrictions of what is considered a claim are employed.
Automatic fact-checking often constrains the problem by limiting the kinds of claims being checked to focusing on simple declarative statements (short factoid sentences [181]) or claims about statistical properties [62,179,195]. For the Fast & Furious Fact-Check Challenge, four primary types of claims were distinguished and further differentiated into more fine-grained sub-categories:11
In the area of Information Retrieval and Question Answering, several works focus on retrieving scientific claims and claims in digital libraries. Here, a claim is defined as a statement formulating a problem together with a concrete solution [56] or a sentence in a scientific document that relates two entities given in a query [57,58]. More generally, from a database-centric perspective, Wu et al. [207,208] represent a claim as a “parametrized query over a database”. This allows to computationally study the impact of modifying a claim (i.e. its parameters) on the result of the query and to thus identify claim properties, such as claim robustness which may serve as evidence to detect potential misleadingness i.e. due to cherry-picking. A related perspective has been proposed by Cohen et al. [33] in the field of Computational Journalism.
Discussion and concluding remarks
In summary, works focusing on the argumentation domain investigate claims in the context of a discourse, i.e. taking their pragmatic role into account. Claims are uttered by the author or speaker to achieve an aim through a speech act [159]. In order to recognize the meaning of an utterance and draw conclusions about the intention of the author, the pragmatic context has to be taken into account. A claim often carries a variety of intentional or unintended meanings, where subtle changes in the wording or context can have significant effects on its validity [62]. Works in other areas, such as Knowledge Bases and Fact-checking, typically focus on the content of epistemic claims, i.e. rather than trying to analyze intended meanings or messages, they try to find and check evidence for assertions and find facts vs. false claims of fact. Works in the area of information retrieval focus more on the surface of claims, trying to retrieve relevant texts without necessarily analyzing their content or contexts. These differences are reflected in the claim definitions found in the respective works.
Note that due to these different foci, there is a difference in what is referred to as claim in argumentation mining vs. in the automatic fact-checking community: what is used as premise or evidence in an argument is often selected as check-worthy claim by fact-checking sites, not the evaluative component of the argument that is coined claim in argumentation mining. Generally, the distinction of argumentative units such as claims and evidence in argumentation mining is based on the statement’s usage or its relations in an argument, while fact-checking classifies statements into claims, stances and other categories considering features inherent to the statement itself (such as their subjectivity), regardless of their connection to the discourse. Thus, what is identified as claim in works of one research field or labelled claim in a ground truth corpus may or may not be called claim in the other, depending on the specific use case and context.
Likewise, some works focus on identifying claims (or other argumentative components) that belong to a pre-defined topic (called corpus wide topic-dependent [166], context-dependent [3], or the information-seeking perspective [188]), while others aim at extracting any units that act as claims for any topic (closed-domain discourse-level [188] or context/topic-independent). Using topic-dependent annotations as ground truth for topic-independent extraction approaches leads to impaired precision values [103].
Lastly, another difference between statements of fact in knowledge bases and claims is that for the former, a certain level of consensus at least in the respective community can be assumed, while claims may only represent the beliefs of one person or be uttered by them to achieve a certain goal such as spreading disinformation. Thus, it makes sense to model truth values for claims while statements in knowledge bases are assumed to be true. There may be errors in knowledge bases, however. Thus, modeling uncertainty or confidence values is applicable for them.
The task of assessing the correctness of a statement of fact is called fact validation. The task of assessing the veracity of a claim is called fact-checking. Fact-checking has also been modeled as a specific stance detection task where the stance of a source or evidence unit towards an epistemic claim is used to assess the claim’s veracity. Finding the true values in case of conflicting evidence is the aim of truth discovery.
Naming conventions
To arrive at a more precise usage of terminology, we will, throughout this paper, refer to items in knowledge bases as statements of facts, while other mentions or assertions of knowledge, will be referred to as claims about a fact that can act as evidence about some information being true and its content being a fact. An index of all naming conventions followed in this work is given in Table 2.
Index of main notions and definitions as discussed in this paper
Index of main notions and definitions as discussed in this paper
In this section, we propose a conceptual model for representing claims and related data as well as an example of an implementation of this model in RDF using established vocabularies.
The conceptual model was informed through the survey described in the previous section. In order to derive a conceptual model, we followed the following steps: 1) identification of key concepts to be reflected in the model (e.g. claim proposition, claim utterance), 2) deriving definitions of these concepts by considering established definitions from the literature, 3) excluding definitions that are inconsistent with each other or not reflecting the required granularity (e.g. we argue that a distinction between proposition and utterance is important for many NLP and knowledge engineering tasks), and 4) identifying relations between all concepts which are consistent with and/or implied by our definitions. Through this process, we arrive at a conceptual model containing key concepts, relations and definitions which is then implemented in OWL as well as through a dedicated RDF/S data model. We start by giving an overview of the key terminology.
Key terminology – from pragmatics to fact-checking
For our conceptual model, we follow notions from pragmatics to allow modeling not only a claim in isolation, but also its meaning in a given discourse and its role in communication.
As Green (1996) puts it, “(...) communication is not accomplished by the exchange of symbolic expressions. Communication is, rather, the successful interpretation by an addressee of a speaker’s intent in performing a linguistic act.”[63, p. 1] “Minimally the context required for the interpretation (...) includes the time, place, speaker, and topic of the utterance.” [63, p. 2] While this quote refers to the interpretation of indexical expressions (i.e. words like “here” and “now”), the same holds true for the interpretation of the meaning of an utterance in general.
A linguistic act, or speech act following Searle [159], includes an utterance, a proposition, an illocution and a perlocution. An utterance is a grammatically and syntactically meaningful statement. A proposition is the semantic content, i.e. meaning. An illocution is the intended effect, e.g. persuading the addressee or requesting a service, while a perlocution is the achieved effect.
For example, referring to the topic “Brexit”, i) British journalist David Dimbleby said during a topical debate in Dover “We are going to be paying until 2064, apparently”,12
https://www.independent.co.uk/news/uk/politics/uk-brexit-divorce-bill-taxpayers-deadline-treasury-obr-office-budget-responsibility-a8253751.html.
This can only be recognized when taking the context into account which is why we argue that the context should be modeled along with the claim utterance. The importance of contextual information has also been recognized for the task of fact-checking: “Who makes a claim, when they say it, where they say it, and who they say it to, can all affect the conclusion a fact-checker could reach. Whether it’s true to say unemployment is what country or which part of a country a speaker is referring to, and when the speaker makes the claim. An open format for recording public debate should support metadata, including at least the time, the place, the venue or publication, and the speaker.” [11].
As outlined in the previous section, we see a fact as a conceptual object which represents the current consensual knowledge in a given community about something or someone. While this knowledge is relatively stable, a change of its truth value is possible, for example when flaws in scientific studies are discovered and findings have to be corrected [149].
Any verified information about a claim, like who uttered it, when and where, can be considered a fact. Facts explicitly uttered by an agent can be modeled as (factual) claims. Facts extracted from a knowledge base can be represented using the same model: provenance information about the knowledge base can be represented as source, that is, as part of the utterance. The statement of a fact is typically not embedded in a discourse. Thus, certain attributes of the context, like the topic of the discourse and the agent, would remain undefined. Likewise, non-factual claims (e.g. “animals should have lawful rights”) do not have universally accepted truth values, i.e. they are unverifiable, and hence, verdict would remain undefined for the respective proposition. Therefore, we argue that facts, factual claims and non-factual claims can be represented using the same model.
In line with the rationale outlined above, we introduce the Open Claims conceptual model, which distinguishes three main components of a claim represented by three central classes: (1) claim proposition, (2) claim utterance, and (3) claim context (Fig. 5).
A claim proposition is the meaning of a statement or assertion. In the context of fact-checking and argumentation mining, it is usually related to a controversial topic and is supported by one person or a group of people. A claim proposition can have been expressed in many different ways and in different contexts, thus it has one or more claim utterances. For example, it might have been expressed in different languages, using different words in the same language, or uttered by different persons and/or in different points in time.
In contrast, a specific claim utterance is typically associated with only one claim proposition, i.e., it has a single meaning. However, the claim proposition can be represented in different ways, for example, by selecting a representative utterance with its context, or through a more formal model. Each claim utterance is related to a specific claim context, which includes the person who uttered the claim, the time point at which the claim was uttered, the location or the event of the utterance and the topic of the enclosing discourse. The claim context provides information to interpret the claim utterance and thus understand its proposition.
Since explicit information about the perlocution (achieved effect) and illocution (intended effect) of utterances is usually unavailable, we do not consider them in this model. They can, however, easily be added to the model as an extension.
Below, we provide details and the main properties of each of the three main classes (Claim Proposition, Claim Utterance, Claim Context).
An OWL implementation of the Open Claims model is available online.16

The open claims conceptual model.
A claim proposition is the meaning of one or more claim utterances in their respective contexts. A claim proposition is associated with i) zero, one or more representations, ii) zero, one or more reviews, iii) zero, one or more attitudes, and iv) zero, one or more other claim propositions.
A representation can have the form of free text, e.g. a sentence that describes the proposition as precisely as possible, or be more formal, e.g. a first-order logic model, or the URI of a named graph pointing to a set of RDF statements.
A review is a resource (e.g. a document) that analyzes one or more check-worthy claim propositions and provides a verdict about their veracity or trustworthiness. An example of such a review is an article published by a fact-checking organization. Note here that not all factual claims have a clear verdict. For instance, the claim “the presence of a gun makes a conflict more likely to become violent” represents hypothesis which can be linked to both supporting and contradicting evidence and is thus difficult to be associated with a single overall correctness score. If a claim is associated to a review which gives a true verdict about its veracity, then the claim can be considered a fact (it represents the current knowledge about something). Non-factual claims are not linked to any reviews and have no verdicts.
An attitude is the general opinion (standpoint, support) on a given topic (e.g. a viewpoint), which often underlies a set of specific values, beliefs or principles. For instance, pro-Brexit and anti-Brexit are two different viewpoints for the Brexit topic. A claim proposition can be associated with several attitudes for different topics. For example, the proposition linked to the claim “immigrants are taking our jobs” can support both the against immigration (for the Immigration topic) and the pro-Brexit attitude (for the Brexit topic).
A claim proposition can also be associated with other claim propositions through some type of relation, e.g. same-as, opposite, part-of, etc.
Claim utterance
A claim utterance is the expression of a claim in a specific natural language and form, like text or speech. Among other things, it can be something said by a politician during an interview, a text within a news article written by a journalist, or a tweet posted by a celebrity about a controversial topic. It is associated with i) one or more linguistic representations (subclass of representation), ii) one or more sources, and iii) zero, one or more other claim utterances (through relations such as same-as, paraphrase, etc.).
A linguistic representation can be, for example, a text in a specific language that best imprints the claim as it was said/appeared, or a sound excerpt from someone’s speech.
A source provides evidence of the claim’s existence. For instance, it can be the URL of an interview video, a news article, or a tweet, i.e. source here means the medium reporting the utterance, not the originating agent (speaker or author which is part of the context). For this distinction, see also Newel [122]. A linguistic representation can have one or more linguistic annotations which provide formal linguistic characteristics. For instance, it can be an entity or date mentioned in the text of the claim utterance, the sentiment of the text (e.g. positive, negative, neutral), or the linguistic tone of a speech (like irony). These annotations can enable advanced exploration of the claims (e.g. based on mentioned entities) and can be manually provided by a domain expert or automatically produced using a NLP or speech processing tool (like an entity linking [164] tool for the case of entity annotations in text).
Links between utterances can be also used to explicate their role in discourse, e.g. by using relations such as used-as-evidence-for or used-as-evidence-against to model premises, evidence, conclusions and other components and relations in argumentation. Likewise, supports and attacks relations may hold between utterances to connect stances and their targets. With this, we follow Carstens and Toni [25] and the discussion in Section 3 with the notion that whether a statement is of type evidence or another type and whether it was uttered to express a stance depends on its usage in the context of a discourse, e.g. its relations, rather than being an inherent property of the statement in isolation.
Claim context
The claim context provides background information about the claim utterance. It is associated with metadata information about the claim utterance and, together with the linguistic representation of the claim utterance, can provide an answer to the Five W’s: i) what was said (linguistic representation of claim utterance), ii) who said it (agent; person, group, organisation, etc., making the claim), iii) when it was said (date/time the claim was uttered), iv) where it was said (location where claim was uttered), and v) why it was said (event or activity in the context of which the claim was uttered, and/or the topic of the underlying discourse). The claim context provides the necessary information for interpreting the claim utterance (and thus understanding its proposition).
Instantiation example
Figure 6 depicts an instantiation example of the proposed conceptual model. The example shows information for two claim utterances (in pink background, in the centre of Fig. 6): i) the one by David Dimbleby (“We are going to be paying until 2064, apparently”), and ii) the one by The Independent (“UK will be paying Brexit “divorce bill” until 2064”). Both utterances correspond to the same claim proposition (in green background, left part of Fig. 6) and each one has its own context information (in yellow background, right parts of Fig. 6). The linguistic representation of the first claim utterance has been annotated with one date annotation (2064) and that of the second claim utterance with one entity annotation (United Kingdom).
The claim proposition has two representations, a textual one (“Britain will be paying its Brexit bill for 45 years after leaving the EU”) and a formal one (“cost = {of = ‘Brexit’, for = ‘UK’ amount = ?, until = 2064}”), and supports the against-Brexit viewpoint of the Brexit topic. In addition, there is a review of this claim proposition with verdict “true”, published by Full Fact (UK’s independent fact-checking organisation). Moreover, we can see the URL of the review article as well as a reference to a document file which provides evidence for its correctness.
The context of each claim utterance provides additional metadata information about the claim. For example, we see that the first utterance was said by David Dimbleby on 15.03.2018, in the context of a debate about Brexit which took place in Dover. For the second claim utterance, the example only represents its agent (UK Office of Budget Responsibility) and date (13.03.2018).

Instantiation example of the conceptual model.
In order to facilitate the use and operationalisation of our Open Claims Conceptual Model, we provide an RDF/S implementation using established vocabularies, depicted in Fig. 7. Vocabulary selection followed three directives: i) relying on stable term identifiers and persistent hosting, ii) being supported by a community, iii) being extensible.
As our base schema, we propose to use schema.org.17
More details about the RDF/S implementation of the proposed conceptual model can be found in our previous work [23].

RDF/S implementation of the open claims conceptual model.
In this section, we review different knowledge engineering and information extraction tasks pertaining to claim related data, like utterances, claim verification scores, claim context information (e.g. who uttered the claim, when and where) and other claim metadata that is described in our Open Claims model. Figure 8 depicts how the below discussed knowledge engineering tasks are mapped to the Open Claims model.

The open claims model annotated with related knowledge engineering tasks.
We identify three main (sometimes overlapping) categories of tasks: extraction, verification, interlinking and position them within the context of our conceptual model. Note that we do not aim to provide an exhaustive overview of those tasks, but rather introduce examples of works of different relevant areas and show how they are positioned with respect to extracting or generating the information and relations suggested by our model. Extraction pertains to detecting statements, utterances and other components and attributes in a corpus of (mainly) textual modality. Verification pertains to the assignment of truth ratings or credibility scores to claims or other related components such as information sources. Interlinking, finally, includes a range of tasks that aim at detecting various relations between claims or related components thereof, such as same-as relations, stances or topic-relatedness.
Given the complexity and varying definitions of what is or what constitutes a claim, a number of different knowledge extraction approaches can be associated to the tasks in each of the three groups outlined above. We will follow the definition of a claim and its components as given by our model (Section 4) in order to review the existing techniques for knowledge extraction pertaining to each of these components and attributes. In parallel, we identify challenging problems that are underrepresented in the literature.
Extracting claim propositions
The task of extracting a claim proposition can be reformulated as assigning an identifier to a group of statements that are assumed to be semantically equivalent. Our model suggests that the meaning of a claim can be captured both by the means of natural language as well as formal knowledge representation frameworks, e.g. description logics.
Extracting formally represented claim propositions at different levels of formality is of main interest in the field of knowledge extraction, both from unstructured (web pages, social networks) or semi-structured (Wikipedia) sources. Populating and building KBs and thus providing structured knowledge on the Web has been of central interest in the NLP, web, data mining and the semantic web communities over the past decades, focusing on a variety of tasks such as named entity recognition, entity linking, relation extraction or word sense disambiguation. The extensive research in this field has led to a very broad range of works. A comparison of generic information extraction tools and systems is provided by Gangemi et al. [49], while Martinez-Rodriguez et al. [110] and Ristoski and Plaulheim [151] focus on semantic web approaches (aiming at the provision of structured knowledge for populating ontologies, linked data and knowledge graphs). The reader may also turn to the book on NLP methods for building the semantic web [113] as well as a recent survey on fact extraction from the web [204].
Relation extraction and ontology learning from text are overviewed by Kumar [92] and Wong et al. [206], respectively, while Atefeh and Khreich [8] dedicate their survey to the task of extracting event-related knowledge. Uren et al. [192] consider methods that take the inverse approach of annotating documents with entities or statements of facts based on existing knowledge bases. Very closely related to this work is a recent work by Al-Khatib et al. [7] who extract knowledge encapsulated in arguments to inform a knowledge graph encoding positive and negative effects between concept instances and classifying the consequences as good or bad. For instance, from the claim “Nuclear energy leads to emission decline”, a positive effect of nuclear energy on emission decline would be extracted and the consequence, emission decline, rated as good. The proposed extraction framework uses a combination of supervised learning and pattern-based approaches.
If we look at textual representations of a claim, the task can be approached by first extracting textual utterances (see below), then grouping them together according to their meaning by the help of textual similarity methods (some of them described in 5.3.2) and then identifying in a cluster of semantically equivalent utterances one that will serve as an identifier for the meaning of the claim. A formal approach to the assignment of textual identifiers to a set of equivalent claims has not been discussed in the literature, to the best of our knowledge, but the task relates closely to the text summarization task, which is surveyed by Lin and Ng [99].
Extracting viewpoints and stances Existing computational models [137] describe viewpoints via a summarization framework, able to find phrases that best reflect them. In Thonet et al. [177,178], unsupervised topic models are proposed to jointly discover viewpoints, aspects and opinions in text and social media. An unsupervised model for viewpoint detection in online debate forums, proposed in Trabelsi and Zaiane [187], favors “heterophily” over “homophily” when encoding the nature of the authors’ interactions in online debates. With respect to viewpoint detection in social media, the model by Barberá [15] groups Twitter users along a common ideological dimension based on who they follow. A graph partitioning method that exploits social interactions for the discovery of different user groups (representing distinct viewpoints) discussing about a controversial topic in a social network is proposed in Quraishi et al. [145], also providing a method to explain the discovered viewpoints by detecting descriptive terms that characterize them.
Our model suggests, in line with the current research, that viewpoints with respect to topics take the form of polarized opinions. Given a controversial topic, for example an issue like climate change, viewpoint discovery aims at finding the general viewpoint expressed in a piece of text or supported by a user. This task can indeed be considered a sub-task of opinion mining, which aims to analyze opinionated documents and to infer properties such as subjectivity or polarity. The survey in Pang and Lee [134] provides a general review of the opinion mining and sentiment analysis tasks. However, for some topics, there may be more than two viewpoints. As of yet, there is limited research that studies these cases.
Viewpoint extraction is closely connected to the stance detection problem, a supervised classification problem in NLP where the stance of a piece of text towards a particular target is explored. Stance detection has been applied in different contexts, including social media (stance of a tweet towards an entity or topic) [10,38,41,93,116,174,210], online debates (stance of a user post or argument/claim towards a controversial topic or statement) [13,67,167,198], and news media (stance of an article towards a claim) [20,70,141,203,216]. A recent work by Schiller et al. [158] details the different and varying task definitions found in previous works, diverging not only with regard to domains, but also classes and number and type of inputs, and introduce a benchmark for stance detection that allows the comparison of models against a variety of heterogeneous datasets. In contrast to the works on viewpoint extraction described previously, works on stance detection focus more on supervised models and textual features (like the sentiment expressed in the text, or the use of polarised words), and less on the structure of the underlying network of users or documents, which can be exploited by unsupervised approaches. For two recent surveys of stance detection works, we refer to Küçük and Can [91] and Ghosh et al. [54].
In recent work, Sen et al. [160] compare untargeted and targeted opinion mining methods (sentiment analysis, aspect-based sentiment analysis, stance detection) to infer approval of political actors in tweets. They show that the compared targeted approaches have low generalizability on unseen and unfamiliar targets and that indirectly expressed stances are hard to detect, and thus identify the need for further research in this area.
Chen et al. [29] propose the task of substantiated perspective discovery where the goal is to discover a set of perspectives and supporting evidence paragraphs that take a stance to a given input claim, and release a first dataset for this task.
Extracting claim utterances
Textual utterance extraction In this survey, we focus on methods for extracting information from language rather than other modalities such as speech or video. The methods discussed in the literature, with few exceptions, are tailored towards a particular context, topic or type of targeted utterances, usually referred to as claims in these works.
Identifying and extracting argumentative components such as claims (also called propositions in these works) or evidence units (also called premises) is a central task in the argumentation mining field [35,96]. The first survey on the topic by Peldszus and Stede [139] assumes the availability of an argumentative text and focuses on the problem of analyzing the underlying structure of the presented argument from two perspectives: (1) argument annotation schemes drawing from works in the classical AI field of argumentation and (2) automatic argumentation mining, discussing the first approaches that enhance the historical field with data-centered machine learning approaches. A more recent survey by Lippi and Torroni [104] provides a structured view on the existing models, methods, and applications in argumentation mining attempting to draw a single unifying view over a plethora of related sub-tasks and dispersed efforts. The authors define the argumentation mining problem as a pipeline consisting of the detection of argument components in raw text and predicting the structure (or relations) between these components, where the former is of particular interest to the task that we consider in this section. Building on and completing these surveys, Cabrio and Villata [24] adopt a data-driven perspective of the existing work in argumentation mining with a focus on applications, algorithms, features, and resources for evaluation of state of the art systems. Taking also a data-driven perspective, the difficulty of devising cross-domain claim identification approaches has been discussed and analyzed in Daxenberger et al. [35] by using multiple domain-specific data sets. In that, the authors address the analysis of the generalization properties of systems and features across heterogeneous domains and study their robustness across the underlying fields. Shnarch et al. [166] propose a methodology to combine smaller amounts of high quality labeled data with noisy weakly labeled data to train neural networks for extracting evidence units for given topics.
The extraction of a claim is the first step in a computational fact-checking pipeline, where it is common to see fact verification as a three-step process: (i) detecting/extracting a check-worthy claim, (ii) reviewing the claim with respect to its veracity and (iii) publishing the reviewed claim [78,180].22
Annotating utterances In our model, we discuss an annotation of utterances based on (1) entities (such as names, dates, locations, etc.) and (2) lower-level linguistic features extracted from the text that can be useful for a number of tasks, such as bias detection or fake-news analysis, as discussed in Rashkin et al. [147]. For (1), one can turn to the literature surrounding (end-to-end) Entity Linking,23
Claim utterance source extraction Sources are identified as the media that publishes a claim. Their extraction can be straightforward in many cases (e.g. when the utterance itself is extracted directly from its source). In certain cases identifying the original source may be more challenging and would require tracking down the claim to its original publication by, e.g. following cascades of retweets or identifying and analysing quotations [121,126,173,197].
This group of approaches deals with annotating a claim with contextual information that helps reply to the questions who uttered the claim when and where. In order to extract a date or a location one can rely on Entity Linking (EL) or Named Entity Recognition (NER) techniques outlined in the previous section. We focus in more detail on the tasks of event detection, topic detection, and author identification and attribution.
Event detection The event in which a claim was uttered is an important component from the context that defines a claim. An event can be seen as a complex entity defined by a set of attributes, such as a date, persons involved and a location. Following this definition, one can apply the methods described in the previous paragraph in order to extract independently these components to populate an event. However, recent approaches consider an event as an atomic entity that can be detected from web corpora (often social networks) [30,73].
Topic detection Detecting what claims are about is a challenging issue. If available, context such as the source articles the claim was extracted from, a claim review article, or the discourse the utterance was embedded in, e.g. the given subject in a debating portal, can be considered for claim topic detection. Here standard NLP methods of topic extraction, modeling or detection from text can be employed [110]. However, detecting the topic when only the textual content of a claim utterance can be considered, or when the textual context is sparse, is challenging.
Approaches developed for extracting topics from short text (like tweets and micro-blogs) can be adapted for claim topic modeling [168]. However, the complex structure and positioning in a context of elements (such as sources, authors and other entities) has to be taken into consideration when predicting topics of claims. Topics can be seen as groups of equivalent claims (e.g. all claims pertaining to “US immigration policies”) situated in a network of contextual entities (e.g. a knowledge graph such as the one given in our model implementation example in Fig. 7). Therefore, link prediction methods on knowledge graphs may be used, where a recent work by Beretta et al. [17] studies the effectiveness of neural graph embedding features for claim topic prediction as well as their complementary with text embeddings. The authors show, however, that state-of-the-art link prediction models fail to capture equivalence structures and transfer poorly to downstream tasks such as claim topic prediction, which may, however, also be connected to the lack of sufficiently large and reliable ground truth data (topic-labeled claims) that would allow to train neural embedding models. This calls for the development of novel methods that surpass the state-of-the-art graph embedding model’s reliance on a local link prediction objective, which likely limits the ability of these models to capture more complex relationships (e.g. equivalence cliques between claims, keywords and topic concepts) and the generation of suitable ground truth data.
Author identification and extraction Identifying the author of an utterance is not trivial [11] yet authorship is crucial for interpreting its meaning. Moreover, claims are often quoted by distant sources, e.g. in news articles or other media. The attribution of content to an author25
Coined “source” in the respective works; in order to not confuse different terminologies, we are referring to these entities as “authors” in the following text although this diverges from the naming used in the literature in this field.
A number of terms, such as fact-checking, truth discovery, claim or fact verification pertain to a large degree to the process of the automatic assignment of a veracity score to a statement uttered by a particular person or a group of people [180]. Note that the analysis of false or mis-information spread, or fake-news detection,26
“False and often sensational information disseminated under the guise of news reporting”, according to Collins English Dictionary.
Claim truthfulness verification is reviewed in Cazalens et al. and Thorne et al. [26,180], where [180] in particular propose to unify diverging definitions of the task and its components from various disciplines, such as NLP, machine learning, knowledge representation, databases, and journalism. Indeed, most of the existing techniques rely on background knowledge sources (e.g. encyclopedic knowledge graphs, such as DBpedia or Freebase) that provide a “truthfulness context” [78,179] and a combination of various computational methods in order to infer the veracity scores of a claim either from those background knowledge sources or, more rarely, in a self-dependent manner. In addition, versatile features pertaining to all three main components of our model (meaning, utterance and context) are often considered in a combined manner, making it difficult to break down claim verification approaches along each of these three axes independently.
In certain cases, claims are given a structured form (e.g. triples or database queries), which allows for the verification of entity-centric information by calling on machine learning techniques [214]. In that, fact verification can be seen as a particular kind of a link prediction or knowledge base augmentation task [31,165]. In contrast, certain methods apply symbolic inference approaches on KGs in order to infer the truth value of a statement [18], or to identify potential errors [48]. A multitude of features, machine learning models and inference techniques are combined together in the KB construction approach presented in [37].
In other cases, statements are taken in their textual form [143,201], while again largely machine learning techniques are applied in order to assess their veracity. Training data in the form of examples of true and false claims come either from archives of fact-checked statements [16,194,201] or from manually labelled (often crowdsourced) collections of claims [59,114,182]. Statistical (topic) models as well as standard NLP filters are used in order to construct a feature space. Note that the majority of approaches based on machine learning rely primarily on highly contextualized features on document/text level, such as words, n-grams, salient entities and topics [75]. Additional context- and aspect-related features such as provenance, time and sources are considered in Popat et al. and Vlachos and Riedel [143,194]. An analysis of news corpora is provided by Rashkin et al. [147] in an attempt to identify linguistic and stylistic cues that help discriminate facts from false information. In addition, certain approaches, like [212], look at how a claim spreads through a crowd or how sources and claims are connected, exploiting social/community-related features.
There exist a variety of types of relations between claims and in particular between their components as introduced in our conceptual model. We consider that the problem of claim relatedness depends on the particular perspective and application context – for example, two claims can be considered contextually similar because they have been uttered at the same event by the same person, but still differ in their meaning and textual expression. Following the main building components of our model, we identify a number of dimensions on which this problem can be studied. One could be interested in relating instances of propositions, utterances or contexts within each of these three groups. These are the kind of relations that will be discussed in this section. Else, one can look into cross-class relations (e.g. establishing the association between an utterance and its author or viewpoint). Such relations result from knowledge extraction processes already discussed in Section 5.1. Although most of these problems can be considered as challenging with little existing work that approach them directly, we will outline below relevant works.
Relating propositions
According to our model, the proposition, or meaning, of a claim is materialized via a particular representation (e.g. a natural language or a logical expression) and is further described by its topics to which we associate viewpoints. As discussed in Section 5.1, different extraction methods can be applied in order to derive those representations. Independently from the particular representation type, we outline three general types of relations that we can establish between proposition instances: equivalence (same-as), similarity and relatedness.
Same-as. The equivalence or identity relation binds together claims that have the exact same meaning. In the case of textual expression of the meaning of a claim, when two propositions are expressed differently although they convey the same message (have the same meaning), we talk of a relation of paraphrase. Paraphrasing detection allows to discover equivalent text fragments that differ (to a given extent), where neural language models are currently largely applied to the task [106,220]. In the case of a symbolic or formal expression of a claim (or a fact), we outline works on relation alignment, such as Pereira et al. [140].
Similar. Two propositions can be similar to a given degree on a scale between “identical” (represented by the same-as relation) and “dissimilar”. This notion relates to that of semantic similarity discussed, for example, in Gracia and Mena [60] and tackled in the Semantic Textual Similarity task [2,27]. A first systematic study on finding similar claims is proposed by Dumani and Schenkel [39].
Related. Relatedness, as opposed to similarity, covers “any kind of lexical or functional association” [60] and is, hence, a more general concept than semantic similarity. Relatedness encloses various relationships, such as meronymy (a relation of composition (part-of) that is such that the meaning of a complex expression relates and can be expressed by the meanings of the parts from which it is constructed), antonymy (opposite meanings, including conflicting/contradicting claims), logical or textual entailment [34], same topic, or any kind of functional relationships or relationships or frequent association. A survey of semantic relatedness methods, evaluation and datasets is given by Zhang et al. [219] and Hadj-Taieb et al. [69]. As opposed to logical entailment, textual entailment is understood as a relationship between pairs of text fragments where one entails the other if a human reading the former would be able to infer that the latter holds.
Relating utterances
Several works address finding equivalent claims in the context of claim verification [76,78,109], where a claim matcher (or linker) is a component of a fact-checking system matching new claims to claims that have already been checked. Shaar et al. [162] recently proposed the task of detecting previously fact-checked claims defined as ranking a set of verified claims according to their potential to help verify an input claim. They propose a learning-to-rank approach and release a first dataset for the task. Clustering similar arguments is at the core of the work by Reimers et al. [148] who use contextualized word embeddings to classify arguments as pro or con and identify arguments that address the same aspect of a topic.
Concerning the matching of text fragments more generally, recent advances in neural NLP and the advent of deep contextualized language models for language understanding, have allowed a renewal state-of-the-art techniques for matching text fragments through the pooling or aggregation of classical [132] and contextualized word-embeddings [81,105] into phrase, sentence or document embeddings [4,5] and the computation of distance metrics to find the closest matching utterances.
In the context of the Open Claims model, relations between utterances can further be derived from the relations between their constituents. For example, an utterance is a repetition of another utterance when all constituents are equal except for at least one attribute of the context such as the author or the date. An utterance is a paraphrase of another utterance when the propositions are equal but the (linguistic) representations differ. Deriving relations when some of the constituents are similar or related, rather than equal, remains a question for further research.
Other types of relations comprise support/attack relations or pro/con stances. Many works treat this as an extraction and classification task, e.g. classifying an argumentative unit as evidence (see Section 5.1), while others treat this as an argumentative relation extraction task, e.g. relating two units with a supports or attacks relation [25,124,129].
Relating contexts
A context is broken down to its constituents: events, entities, dates, etc. Establishing links among contexts comes down to linking their respective components. For that purpose, one may call upon state-of-the-art approaches to data linking, where, following years of research and practice, a wealth of methodological approaches and tools are currently out there [119]. Among those, property-centric approaches (e.g. [84,123]) can be of particular interest in order to establish relations (like identity or overlap) between different contexts, comparing their elements individually by the help of well-suited similarity measures (e.g. measures of similarity between proper names or dates).
Conclusion
This paper bridges the gap between various disciplines involved with online discourse analysis from a range of perspectives by (a) surveying definitions of claims, facts and related concepts across different research areas and communities, (b) establishing a shared conceptualisation and vocabulary in this context and (c) discussing a range of tasks involved with such notions, for instance, for extracting or interlinking related concepts through NLP techniques. We contribute to a shared understanding of a wide range of disparate yet strongly related research areas, facilitating a deeper understanding of shared methods, approaches and concepts and the potential for reuse and cross-fertilisation across communities. Below, we highlight under-researched areas and potential future directions.
Currently, a framework for claim relatedness and similarity is missing. Several works from different fields appear to deal with the problem from different perspectives, but an approach that takes into consideration the various aspects of a claim, as well as its various representations, as defined in our Open Claims model in order to discover claim relatedness or similarity of different kinds is yet to be proposed. While there are works addressing the extraction of structured information from claims [85], allowing for example the detection of nested claims, current fact-checking methods and sites largely ignore such issues. For instance, a complex claim can have different (or no) truth rating as compared to its constituents. For instance, “Colin Kaepernick says Winston Churchill said, “A lie gets halfway around the world before the truth has a chance to get its pants on.””27
Given the subtle differences between claims, where meaning often derives from subtext and context, disambiguating claim representations, e.g. when mapping novel claims to knowledge bases of fact-checked claims, appears challenging. Even for humans, deciding on the type of relationship of two claims is a non-trivial task. For example, the claim “Interest on the debt will exceed defense spending by 2022” provides an exact date, while “Interest on debt will exceed security spending” does not provide a date. Can these two claims be considered the same, and, if not, what is their relation? Using the proposed model, such subtle differences can be made explicit. In addition, automated fact-checking has the potential to elevate the problem given its lack of maturity at different steps, where for instance, the classification of half-correct or poorly disambiguated claims as correct may introduce further false claims into the wild.
Similarly, the process of stance detection is challenging as it has been shown to not work well for the minority class, i.e. documents disagreeing with the claim [70,154], and for unseen targets [160]. Little research in viewpoint discovery deals with extracting viewpoints for more than two polarized positions, a topic that could be worthwhile researching for the analysis of debates.
Detecting claim topics and linking those to a specific commonly shared vocabulary or thesaurus of topics (like, e.g., the TheSoZ [215] or the Unesco28
Generally speaking, considering the wide variety of methods and datasets involving claims and related notions, adopting a shared and well-defined vocabulary has the potential to significantly increase impact and reuse of research methods and data.