
Abstract
The W3C Generating RDF from Tabular Data on the Web Recommendation provides a mechanism for mapping CSV-formatted data to any RDF graph model. Since the Wikibase data model used by Wikidata can be expressed as RDF, this Recommendation can be used to document tabular snapshots of parts of the Wikidata knowledge graph in a simple form that is easy for humans and applications to read. Those snapshots can be used to document how subgraphs of Wikidata have changed over time and can be compared with the current state of Wikidata using its Query Service to detect vandalism and value added through community contributions.
Keywords
Introduction
Because of its availability and ease of use, Wikidata has become one of the widely used open knowledge graphs [21]. Its dedicated users and easy-to-use graphical interface promise value added through community contributions, and access through its API1
These advantages have generated a lot of interest among biodiversity informaticians [20], information specialists [15], and others in communities such as galleries, libraries, archives and museums (GLAM) [30], for using Wikidata as a place to expose and manage data about items of their concern, such as collections records, authors, and authority files. Because those data are exposed as RDF through the Wikidata Query Service,2
In this paper, we argue that Wikidata provides an opportunity for user groups and small institutions with limited technical expertise to participate in the LOD movement if simple systems are available for them to upload and monitor data about items in which they have a vested interest (referred to henceforth as “items of interest”). We also argue that for users at small GLAM institutions with limited IT resources, a system based on comma-separated tabular data (“CSV”) files is not only simple but is the most appropriate format given that community’s long-term interest in archival preservation of data. Although there are existing systems for writing tabular data to Wikidata, they do not fully document the semantics of the table columns in a manner that allows for easy reconstruction of RDF that fully describes the subgraph of Wikidata serialized in the table.
We describe a method for mapping specific Wikidata properties and the Wikibase model generally to flat CSV files using the Generating RDF from Tabular Data on the Web (CSV2RDF) W3C Recommendation (i.e. standard), making it possible for humans to interact more easily with the data locally using spreadsheet software. The method was developed as part of an ongoing project of the Vanderbilt University Jean and Alexander Heard Libraries known as VanderBot,4
The main novelty of this work is demonstrating a single system that simultaneously:
is extremely simple and easily used by those with a limited computer science background
maintains the ability to fully capture details of a subgraph of Wikidata in a form that is easily archived
can easily be ingested or output by scripts
can be used to track subgraph changes over time.
The simplicity of the system does come at some costs imposed by the limitations of the CSV2RDF specification itself, including the inability to express the language of literals as part of the data or to generate two triples from the same column of data (necessitating some post-processing). General limitations of “flat” tables also apply to this approach, such as complications when a property has multiple values for a single item. However, we believe that these shortcomings are outweighed by the benefits gained from the wide acceptance of CSV as an archival format and from allowing non-technical users to edit, copy, and paste data using familiar spreadsheet software, as well as scan columns for patterns and missing data.
This paper is organized as follows. The remainder of this introduction describes the key features of the Wikibase model and its Wikidata implementation. Section 2 reviews related work. Section 3 describes how the CSV2RDF Recommendation is applied to the Wikibase model. Section 4 explains how the method can be used to manage Wikidata items of interest. Section 5 describes how the method can satisfy three important use cases, and Section 6 concludes by discussing circumstances under which the method is likely to be most useful.

Wikibase RDF model (from
Wikidata is built on a general model known as the Wikibase data model [31]. The Wikibase data model has an RDF export format [19] whose key components are shown in Fig. 1. The primary resource of interest in the model is some describable entity known as an item. One can describe an item directly using a “truthy” statement – an RDF triple where the predicate has the
Namespace abbreviations
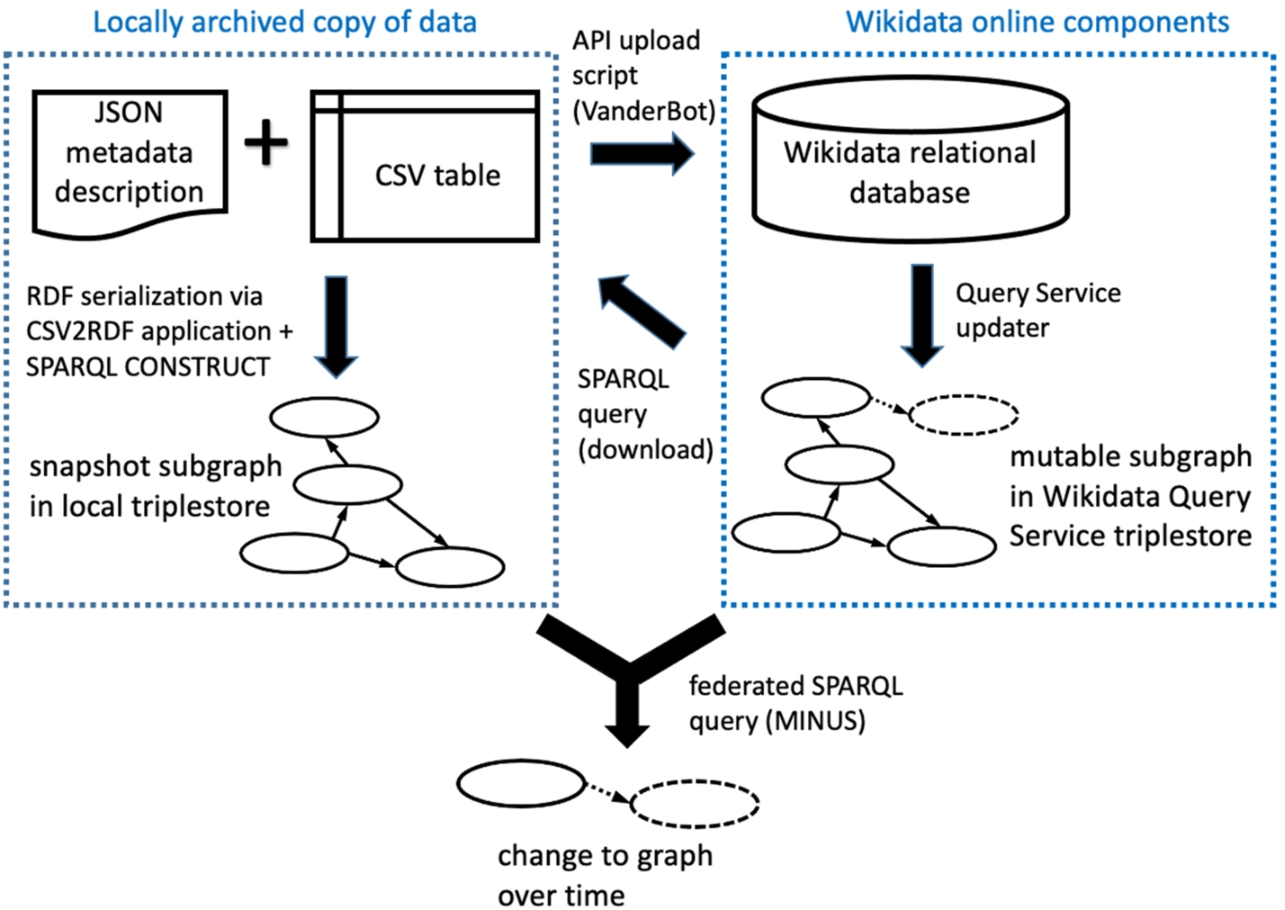
Key components and interactions described in this paper. The Wikimedia Foundation hosts the online components with data maintained by the user community. Users may keep a local set of data in order to upload new data to Wikidata via the API, or as downloaded archival subgraph snapshots generated using the Query Service. A federated SPARQL query can be used to compare online and local subgraphs.
Although the data in Wikidata are available in the form of RDF via a SPARQL endpoint, they are actually managed in a relational database, with periodic exports by a Query Service updater to the triplestore (i.e. specialized RDF graph database) behind the endpoint (Fig. 2, right side). However, because the JSON that is used to interact with the database via the API is structured based on the same abstract data model as the triplestore (i.e. the Wikibase data model), a client that can use that model to interpret data acquired from the triplestore through SPARQL queries can also be designed to construct and parse the JSON necessary for API uploads involving similarly structured data.
The design of the Wikibase RDF model makes it simpler in some ways than generic LOD. The Wikibase model does not include the notion of classes as distinct entities as introduced in the RDF Schema (RDFS) model [8]. Instead, in Wikidata items that are values of the property P31 (“instance of”) fill the role of classes. Thus, the class proxies are simply part of the data rather than being defined as part of an independent ontology. Similarly, properties are also part of the community-curated data rather than being defined in a separate ontology, so terminological changes over time could be documented simultaneously with changes in assertions without the need to monitor an external ontology.
Wikidata deals with the issue of tracking sources by including the notion of a statement instance (Fig. 1) as part of its data model rather than depending on special mechanisms such as reification or named graphs to generate nodes to which provenance data can be attached. Again, this simplifies the system since properties and values of qualifiers and references that are linked to statement instances are managed using the same system as properties and items used to make statements.
Wikidata also differs from traditional LOD in that it is centrally managed rather than distributed. That makes it possible to detect changes in the knowledge graph over time without needing to access multiple endpoints or dereference IRIs. Although anyone can edit items, changes to properties can only be made through community consensus, adding a degree of stability and transparency that would not be ensured if external ontologies were used.
Subgraphs of the Wikidata knowledge graph can be exported in one of the RDF serializations [32] or explored via the Wikidata Query Service SPARQL endpoint.7
In contrast, our system of storing a subgraph as a CSV file coupled with a JSON metadata description file makes it easy to review data and store it by traditional means. The combination of CSV + metadata description effectively serves as an RDF serialization since it is interconvertible with other more typical serializations that could be loaded into a triplestore if desired (Fig. 2, left side).
Small institutions like museums, galleries, and libraries and user groups focused on relatively narrow topics are an important part of the Wikidata contributor community.8
The case of the technical architecture of Biodiversity Information Standards (TDWG)9
Based on a query of occurrence records performed on 2021-06-01.
Within the library community, there is wide recognition that deploying generic LOD applications is a complex task restricted primarily “to large, well-resourced institutions, often with external financial support” [3]. However, there is significant interest within the GLAM community for exploring Wikidata, evidenced by the large number of Wikidata WikiProjects in the GLAM category.12
QuickStatements accepts plain text files as input using either an idiosyncratic “command sequence” syntax or CSV files having a particular structure. Interpretation of the CSV syntax depends on a header row that must conform to a very specific set of alphanumeric codes applied in a specified sequence. Because its input format is well-defined, QuickStatements input files can be created as the output of other scripts. This allows developers to create tools such as Author Disambiguator15
The ability to use QuickStatements with CSV files provides the benefits of easy review and editing with a spreadsheet program. However, the restrictions placed on column headers do not permit the use of easy-to-understand column names. A QuickStatements CSV file also cannot be converted directly to a well-known RDF serialization without an application designed specifically to interpret the coded column headers. These characteristics make QuickStatements CSV files difficult to use for archival purposes if it is considered important to be able to reconstruct the RDF subgraph that the CSV represents.
OpenRefine is a free, well-known tool for cleaning tabular data. Its Wikidata extension16
Tables as edited within OpenRefine can be more complex than simple CSVs, with multiple rows being considered as part of a single record. CSV is available as a lossy export format, but as with QuickStatements, if these CSVs were archived they could not directly be translated into a common RDF serialization.
In the case of both QuickStatements and OpenRefine, the format of their associated CSV files does not have a mechanism for preserving the statement and reference node identifiers necessary to fully document the subgraphs they represent.
A less well-known tool, Wikibase_Universal_Bot,17
Archival preservation of data is a major concern of the GLAM community. Best practices for preservation of digital data have a long history in the archival preservation community. ISO 14721 describes a reference model for an open archival information system (OAIS) for digital data [23]. This standard describes many aspects of data preservation, but the part of the model most relevant to this paper is the Information Package definition (Section 2.2.2). It differentiates between the Content Information (the information to be preserved) and the Preservation Description Information (PDI). The PDI includes a description of how the Content Information relates to information outside the Information Package, i.e. the context that makes the Content Information understandable to the user community. Section 3.2.4 describes the requirement that the Information Package must be understandable not only to the original data producers, but also to the Designated Community, which must be able to understand the information over the Long Term without the help of the experts who generated the information.
Since the development of the original OAIS model in 2003, data preservation specialists in the GLAM community have sought to understand how the model might apply in the context of LOD. Bartoli et al. [5] provided an analysis of strategies for ensuring long-term preservation of LOD. Although much of their paper focused on how standardized vocabularies can be used to describe LOD datasets, their review of the state of the art identified a key point related to preservation of the data itself: the set of tools needed to understand a dataset are different from those needed to use and query it. That is, software necessary for installing a triplestore and querying it may be more complex and difficult to preserve than the RDF that constitutes the dataset. Thus an archiving system that makes the data directly available in a form that does not require complex software for its interpretation has an advantage from a preservation perspective. The system described in this paper is such a system because archived CSV files can be examined without specialized software that would need to be archived and documented alongside the data files.
The PRELIDA project [1] examined the gaps between the Linked Data and Digital Preservation communities to describe steps towards efficient digital preservation of linked data. They made a distinction between RDF serialized and stored across the web and RDF stored in a triplestore. Differences between these “online” and “offline” data sources result in important differences in strategies to preserve them. It is easier to preserve “snapshots” of offline data sources since obtaining those versions does not depend on dereferencing IRIs that may have suffered “link rot”. In their gap analysis (their Section 4), they identified several challenges for preserving Linked Data.
However, several of these challenges do not apply to Wikidata. Since the Linked Data representation of Wikidata is accessed exclusively from sources internal to the Wikidata system, the problem of dependence on web infrastructure is largely absent. Formal knowledge problems associated with dependence on external ontologies are largely missing since the semantics of Wikidata are described almost entirely by the Wikibase ontology and graph model, and by properties whose definitions are included as part of the data within Wikidata itself. Complications involving preservation of provenance metadata associated with links are reduced by the Wikibase model, which has built-in link (i.e. statement) instantiation, allowing for reference and qualifier data to be associated with links as part of the dataset itself.
The PRELIDA project also raised several issues that can be examined in the specific context of Wikidata. One identified preservation risk was failure to preserve the ontologies that provide classes and properties that express the data. That risk was also identified in Best Practice 28 for data preservation in Data on the Web Best Practices [18]. In Wikidata, this risk is avoided because the Wikibase model does not rely upon classes as they are defined in RDFS, and because properties are defined as part of the data.
The PRELIDA project raised the question of who is responsible for “community” data. On the surface, in the case of Wikidata the responsible party would seem to be the Wikimedia Foundation, which operates Wikidata. But because anyone can edit Wikidata, GLAM institutions can take responsibility for adding and curating data in Wikidata about items of their concern. This effectively places them in the roles of both data producer and Designated Community in the OAIS sense, and it enables them to have a role in ensuring that the data they care about remain accurate and available.
Finally, the PRELIDA project considered the question of durability of the format of the data. Since RDF is based on open standards and can be serialized as plain text, it can be considered very durable. Wikidata also maintains its own permanent, unique IRI identifiers for items and properties, reducing problems related to IRI maintenance and dereferencing.
In considering the relative durability of data formats, the Library of Congress recommended formats for datasets [16] is instructive. Preferred formats are platform-independent and character-based. They are also well-developed, widely adopted and are de facto marketplace standards. Examples include line-oriented formats like CSV and formats using well-known schemas with public validation tools. With respect to RDF serializations, JSON-LD and RDF/XML would fall in the latter category. However, although JSON and XML are well-known data transfer formats, their use as RDF serializations is not familiar to most archivists and they are not readily interpretable without software specially designed to consume them. In contrast, CSV files are widely accepted and understood in the archival community and can be easily interpreted using widely available software. For these reasons, we argue that CSV should be considered a preferred format for archiving RDF data.
Vandalism has been a longstanding concern in the Wikidata community, and a number of tools have been developed to counter it.20
These tools are generally focused on detecting Wikidata-wide vandalism. However, GLAM institutions are likely to be more focused on detecting both vandalism and value added to their items of interest rather than on the scale of all of Wikidata. Thus, methods optimized to make it easy for them to track changes over time for a specified set of items are likely to be more useful to them than Wikidata-wide tools, which incur more complexity because of their broad scope.
Generating RDF from Tabular Data on the Web (CSV2RDF) [26] is a W3C Recommendation that specifies how tabular data should be processed to emit RDF triples. It is part of a broader W3C specification that defines a tabular data model [28]. The Recommendation prescribes how to construct a JSON metadata description file that maps the columns of a tabular data file (e.g. CSV) to RDF triples. A conformant processor operating in “minimal mode” will convert data from the cells of the table into RDF triples based on the metadata description mappings.
Since the general Wikibase model can be expressed as RDF, the CSV2RDF Recommendation makes it possible to unambiguously describe how the contents of a simple CSV file are related to statements, qualifiers, and references in Wikidata. Thus, a CSV data file coupled with a JSON metadata description file can represent a snapshot of some subgraph of the Wikidata knowledge graph at a particular moment in time. If those snapshots were managed using version control, it would be possible to record the history of some subgraph of Wikidata as it develops over time.
Because data in Wikidata form a graph with no limit to the number of edges arising from a node, they cannot reasonably be represented as a single flat table without placing restrictions on the properties included, the number of allowed values, and the number and properties of references and qualifiers associated with the statements. Nevertheless, communities that want to monitor the state of certain types of items will generally be able to restrict the scope of the statements, references, and qualifiers to a small number that they are interested in tracking.

The column description part of the metadata description describes how these two columns are used to generate triples. (See Appendix A for examples of the full JSON metadata description files.)

The description of the first column, whose header is
If the CSV table were processed using the JSON metadata description file, the following graph (serialized as RDF Turtle) would result:

Wikidata descriptions are handled similarly to labels in the description file except that the property
Example 1 in Appendix A illustrates how RDF for a Wikidata statement can be generated from CSV data using a JSON metadata description file. In the CSV table, the second column contains the UUID identifier assigned to the statement instance and the third column contains the QID for the item that is the simple value of the statement (where
Processing the CSV file using these column descriptions emits four triples: one for each of the two data columns in each of the two rows. The predicates
Qualifiers are a feature of the Wikibase model that provide additional context to a statement, such as indicating the time over which the statement was valid. Since qualifier properties link statement instances to values, CSV columns containing qualifier values will be described similarly to the third column in Example 1, with the difference being that the qualifier properties will have the namespace
One deficiency of the CSV2RDF Recommendation is that it does not allow a column of a table to be used to generate the object of two triples. Because of that restriction, it is not possible to directly generate all possible edges defined in the Wikibase model. In Example 1, it is assumed that the truthy statement triple that directly links the subject item

the third column value can’t also be used to generate the truthy statement triple. Fortunately, shorter paths that are assumed to exist based on the Wikidata model can be constructed from longer paths using SPARQL Query [13]
One complication of this process is that not every statement instance has a corresponding truthy statement triple. Statements with the rank “deprecated”, and statements with a “normal” rank but where other values for that property have a “preferred” rank do not have corresponding truthy statement triples.23
Thanks to Andra Waagmeester for pointing out this complication.
The IRI identifier for the reference node is formed from a hash generated from the data describing the reference. Thus, any references having an identical set of property/value pairs will share the same IRI. Reference IRIs are not unique to a particular statement in the way that statements are unique to a particular item – the same reference may serve as a source of many statements.
Example 2 in Appendix A shows how triples describing a reference for a statement would be generated from CSV tabular data.
The emitted graph consists of only three distinct triples even though there are four data cells in the CSV table. Because both statements are derived from the same source, they share the same reference instance and only a single triple describing the reference is emitted.
Unlike general properties that are defined independently in each Wikibase instance (e.g.
Complex value nodes may be the objects of triples describing statements, references, or qualifiers (Fig. 1). The only difference is the namespace of the property serving as the predicate in the triple.
Example 3 in Appendix A illustrates a complex date value serving as the value for a “start time” (
The output graph for the example shows that the path from the statement to the time value traverses two edges (statement node to anonymous value node to time value literal). The Wikibase model implies that for qualifiers there is a direct link from the statement node to a simple value via a triple having a predicate in the
Using the CSV2RDF Recommendation to map CSV tables to the Wikibase model makes it possible for a community to implement a relatively simple system to write, document, version, and monitor changes to parts of the Wikidata knowledge graph (Fig. 2).
See Appendix B for a screenshot, a link to the code, and a link to an operational web page.
If all of the items of interest are known to not exist in Wikidata, then the columns in the CSV can simply be filled in using an appropriate data source. However, more commonly, some of the items may already exist. In that case a disambiguation step should be performed to ensure that duplicate item records are not created.
Once existing items are identified, the Wikidata Query Service SPARQL endpoint can be used to download the existing statements and references for those items and save them in a CSV file whose headers correspond to the column names in the JSON metadata description file.26
A Python script to download existing data for items based on a list of QIDs or screening query is available at
After the existing data are recorded in the table, available data sources can be used to supply data for parts of the table that are missing in existing items and all of the data for new items. A script can know that these data are new because they do not yet have assigned identifiers in the table.
A Python script known as VanderBot27
At any time, the archived CSVs can be transformed by a CSV2RDF-compliant application into an RDF serialization using the JSON metadata description file (Fig. 2, left side). One such application that is freely available is the Ruby application rdf-tabular.28
The output file can be loaded into a triplestore using the SPARQL Update [11]

To insert the constructed triples directly into a graph in a triplestore, the SPARQL Update
A simple but powerful type of analysis that can be done using this workflow is to compare the state of a snapshot subgraph with the current state of Wikidata. Using a triplestore and SPARQL query interface like Apache Jena Fuseki29
For example, the following query will determine labels of Bluffton University presidents that were added to Wikidata by other users after uploading data into the graph

In this query, the item QIDs were determined by triple patterns limiting the bindings to chancellors (

In this example, the direction of the
Some typical kinds of data to be compared are labels, values for statements involving particular properties, and reference instances.
Because the format of a federated query to a remote endpoint is very similar to the format of a query limited to a particular graph in the local triplestore, thesame approach using
We noted previously that constructing truthy statement triples for every statement instance without first considering the rank of the statement can introduce artificial differences between subgraphs generated from CSVs and their corresponding subgraphs in Wikidata. This possibility must be considered for MINUS comparisons that include truthy edges in the graph patterns used to bind solutions. To avoid this problem, it is best whenever possible to use graph patterns whose path passes through the statement nodes (e.g. example Query 2) rather than directly through truthy edges.
Conversion data for datasets of varying sizes
The datasets span a range of sizes that might be typical for projects taken on by a small organization. The
The key point of these data is that converting the CSV files into RDF can take a substantial amount of time, even for relatively small datasets under a million triples. In these trials, the conversion rate was roughly 500 triples per second. Although that rate would probably increase if the conversion were done on a more powerful computer, it is clear that the conversion time would become very limiting if graph size reached millions of triples. It is also possible that the conversion time could be reduced if it were done using a more efficient application than rdf-tabular.
Compared to the time required to convert the CSVs to Turtle, the time required for Fuseki to materialize the triples for the more direct paths in the Wikibase model was negligible. Those added triples increased the total number of triples in the graphs by about 35%, but even in the largest graph tested, it took only a few seconds for the SPARQL processor to construct them.
The ability to easily store a specific subset of Wikidata statements and references as a versioned snapshot, and to easily compare those snapshots to the current status of Wikidata makes it possible to satisfy several important use cases.
Conclusions
The W3C Generating RDF from Tabular Data on the Web Recommendation provides a mechanism for mapping CSV spreadsheets to the Wikibase model. When a CSV file is coupled with a JSON metadata description file that maps its columns to parts of the Wikibase model, it is a faithful representation of a subgraph of the Wikidata knowledge graph at a particular time. That same mapping file contains sufficient information for software to be able to upload new data in the CSV file to the Wikidata API.
A system based on CSV files makes it easy for non-technical users to view and edit data. It allows them to use familiar spreadsheet software to edit data using built-in tools such as copy-and-paste and find-and-replace. They can more easily scan for patterns and errors by examining columns of data than they could using other serialization formats like JSON or XML.
Our experience using the system confirms that it can be used successfully by persons with little technical expertise. Despite having a full-time staff of two and no dedicated IT staff, the Vanderbilt Fine Arts Gallery was able to create items in Wikidata for over 6000 works in its collection.30
The simplicity of CSV data coupled with a JSON metadata description file makes it straightforward to store versioned snapshots of small subgraphs of Wikidata using a standard archival format. At any time, those snapshots can be transformed into RDF and loaded into a triplestore. Then using a federated SPARQL query, that representation can be compared with the current state of Wikidata to detect both vandalism and value added by the community. Those queries on a restricted subgraph of Wikidata provide a simple alternative to schema- or machine learning-based alternatives for detecting vandalism.
Because of the simplicity and small size of CSV files, this system could be particularly useful for archiving numerous snapshots of relatively small graphs. However, because of the relatively long conversion time to RDF when CSV file sizes exceed 10 MB, the system would be less useful for datasets exceeding one million triples. The advantage of the CSV format in human readability and ease of editing would also be lost once table size exceeded what can reasonably be edited using typical spreadsheet software. Nevertheless, this system could be very useful for GLAM institutions and other communities that seek to manage data about Wikidata items on the order of a few thousand items and that do not have access to extensive technical infrastructure and expertise.
Footnotes
Acknowledgements
Gregg Kellogg provided valuable information about using the Generating RDF from Tabular Data on the Web Recommendation and implementation of the rdf-tabular application. Thanks to Mark Denning for assistance with the web tool for constructing JSON metadata description files. Jakub Klimek, John Samuel, Tom Baker, Andra Waagmeester, and Dimitris Kontokostas provided helpful comments and suggestions during the review process that significantly improved the paper.
Example listings
Files available at Generating RDF for a Wikidata statement using the W3C Generating RDF from Tabular Data on the Web Recommendation. For a more extensive example, see CSV table data (file name JSON metadata description file (filename Emitted graph (Turtle serialization, prefix declarations omitted for brevity): Generating RDF for a Wikidata reference. CSV table data (file name JSON metadata description file (filename Emitted graph (Turtle serialization, prefix declarations omitted for brevity): Generating RDF for a complex value of a Wikidata qualifier CSV table data (file name JSON metadata description file (filename Emitted graph (Turtle serialization, prefix declarations omitted for brevity): Python script to materialize triples for shorter alternate Wikibase paths
Web tool for constructing JSON metadata description files based on the Wikibase model
An operating version of the tool is available at
The tool can be operated offline by downloading the HTML file