
Abstract
Zero-shot learning (ZSL) which aims to deal with new classes that have never appeared in the training data (i.e., unseen classes) has attracted massive research interests recently. Transferring of deep features learned from training classes (i.e., seen classes) are often used, but most current methods are black-box models without any explanations, especially textual explanations that are more acceptable to not only machine learning specialists but also common people without artificial intelligence expertise. In this paper, we focus on explainable ZSL, and present a knowledge graph (KG) based framework that can explain the transferability of features in ZSL in a human understandable manner. The framework has two modules: an attentive ZSL learner and an explanation generator. The former utilizes an Attentive Graph Convolutional Network (AGCN) to match class knowledge from WordNet with deep features learned from CNNs (i.e., encode inter-class relationship to predict classifiers), in which the features of unseen classes are transferred from seen classes to predict the samples of unseen classes, with impressive (important) seen classes detected, while the latter generates human understandable explanations for the transferability of features with class knowledge that are enriched by external KGs, including a domain-specific Attribute Graph and DBpedia. We evaluate our method on two benchmarks of animal recognition. Augmented by class knowledge from KGs, our framework generates promising explanations for the transferability of features, and at the same time improves the recognition accuracy.
Keywords
Introduction
Recently, object recognition by deep learning which learns features from abundant samples has gained a lot of successes. For example, it even outperforms human beings on the ImageNet ILSVRC challenges [55]. However, it still suffers from challenges from data collection: when a new class emerges, hundreds of samples are needed for training while their labels are usually hard to acquire. This makes the recognition model less competitive. Therefore, the interest in zero-shot learning is growing rapidly. It focuses on developing deep learning models for those emerging classes without training samples.
Zero-shot learning (ZSL) is widely introduced in image classification tasks (e.g., [43]). It predicts the images of new classes (i.e., unseen classes) that do not exist in the training set by transferring features learned from the training classes (i.e., seen classes). The inspiration is that a human can recognize new objects through the class knowledge (e.g., description) itself, even without labeled samples. For example, considering the animal class “Serval”, even though a human has never seen its samples in the past, s/he would still be able to recognize it based on the description: “Serval, a kind of animal with a Cat-like face and a Cheetah-like body” (see Fig. 1). With previous recognition experience of Cat and Cheetah, s/he can easily infer the appearance of Serval and identify it correctly.
The general principle of most ZSL algorithms is to represent such class knowledge and utilize inter-class relationship to transfer model parameters such as neural network features from seen classes to unseen classes. Some works (e.g., [12,42]) leverage the word embeddings of class names learned from text corpora for transferring e.g., CNN features, while others (e.g., [23,59]) prefer more complex knowledge like class hierarchy and class attributes. These methods aim at learning and predicting for unseen classes [7,12,20,23,42,59], but are black-box models: the transferability of features between classes is uninterpretable. This not only limits human’s trust in prediction results of ZSL models, considering that ZSL is a method which recognizes the samples of new classes but has never been trained with their labeled samples, but also restricts the potential of improving ZSL models, for example, with explanations, machine learning specialists would master which classes whose features are transferable to learn the features of unseen classes and which are not so that optimizing the ZSL models by adding necessary features or removing inadequate features. Therefore, in this paper, we focus on explaining the transferability of features in ZSL and generating textual explanations which can be understood by not only specialists but also non-specialists.
There have been few works that explain ZSL with human understandable knowledge. As far as we know, the only work that is close to ours is by Selvaraju et al. [56]. They first learn the mapping between class attributes and individual neurons in deep networks, and then transfer neurons from seen classes to unseen classes, where class attributes are taken as textual explanations to justify the decisions made by unseen classifiers (cf. more in Section 2.3). Such work indicates that it is feasible to explain ZSL by class knowledge such as class attributes. However, it focuses on grounding the network neurons in interpretable semantics but ignores the feature transferability which is the core of ZSL. Also, its method is ad-hoc, only working for predefined class attributes, while ours supports not only attributes but also general knowledge in different formats, coming from external KGs like DBpedia.

An example of recognizing Serval (unseen class) with two seen classes (Cat and Cheetah). We focus on explainable ZSL, which extracts domain-specific attributes as well as general knowledge, such as sharp ear, face appearance, long leg, spotted coat and felidae ancestor, as evidence to generate textual explanations that are more understandable by humans.
In this paper, we propose a KG based framework to explain the transferability of features in ZSL. It first adopts a KG named WordNet and an Attentive Graph Convolutional Neural Network (AGCN) to model and encode inter-class relationship for ZSL, which is also known as an Attentive ZSL Learner (AZSL). Namely, a matching between inter-class relationship and CNN features is learned. It then uses an explanation generator to extract rich class knowledge from a domain-specific Attribute Graph and general external KGs (e.g., DBpedia) as evidence for ZSL explanation. For example, as shown in Fig. 1, the attribute knowledge of sharp ear and the DBpedia knowledge of felidae ancestor are used to illustrate the transferability of features from Cat and Cheetah to Serval. Finally, we propose multiple templates to generate human understandable explanations.
Briefly, our work contributes are as follows:
A KG-based explanation framework for zero-shot learning is proposed. It is among the first to explain the transferability of neural network features in ZSL.
A novel ZSL algorithm called AZSL is built upon WordNet and AGCN. It models the inter-class relationship and the transfer of CNN features from seen classes to unseen classes, which not only shows improvements over the state-of-the-art baselines, but also enables explaining the transferability of CNN features in ZSL.
An explanation generator is developed. It can generate explanations with class semantics from not only domain-specific KGs like Attribute Graph but also general KGs like DBpedia.
A series of templates are designed to organize these class semantics and generate human-consumable natural language explanations.
Lastly, experiments on two image classification benchmarks are conducted to evaluate the ZSL learner and the explanation generator.1
Code and the Attribute Graph are available at
The structure of this paper is as follows. In Section 2, we review the related work. In Section 3, we set up the background of our work. In Section 4, we introduce the details of our KG-based explanation framework, including the attentive ZSL learner in Section 4.2 and the explanation generator in Section 4.3. In Section 5, we report the evaluation results. Finally, we conclude the paper and discuss some future directions.
Zero-shot learning
Zero-shot learning (ZSL) has received a lot of attention in machine learning community. Some work by Larochelle et al. [25] has shown the ability to predict new (unseen) classes of digits that are omitted from the training set, with the features from training (seen) classes being transferred. In computer vision, techniques for utilizing knowledge of classes to realize the transfer of deep features from seen classes to unseen classes have been investigated [12,22,25,43,59].
Early algorithms focus on utilizing class attributes to model the semantic relationship of classes [3,11,23,39]. For instance, Lampert et al. [23] annotate each class with a set of attributes and propose two attribute-based classification methods, where the features are transferred between seen and unseen classes via attribute sharing. Recent methods prefer to utilize class embeddings (i.e., the word embeddings of class names) trained on classes’ textual descriptions to explore the class semantics [12,42,64,70]. For example, Frome et al. [12] present a visual-semantic embedding model, which linearly maps image (visual) features into the class embedding space to predict the labels of images. However, the state-of-the-art performance in zero-shot image classification is achieved by those who utilize KGs for class relationship [18,59,65]. For example, Wang et al. [59] use WordNet to model the semantic relationship of hierarchical classes and encode it using GCN to predict classifiers for unseen classes. Considering that graph convolutional operation in GCN only aggregates the features of first-order neighbors, the authors propose to stack multiple graph convolutional layers (e.g., 6) to propagate features towards distant nodes. While Kampffmeyer et al. [18] propose a dense connection scheme that connects distant nodes via additional links to optimize the propagation of features from distant nodes with only 2 convolutional layers. Following the above ideas, we combine class embeddings and class hierarchy as class knowledge to transfer features from seen classes to unseen classes. Unlike the above GCN-based encoder, we propose to utilize Attentive GCN to encode the inter-class relationship, which can assign different importance to different neighboring classes to augment the feature propagation between classes. Moreover, the learned attention weights indicate the most contributing seen classes in the feature transfer, enabling explaining the transferability of features.
There are also some ZSL methods for dealing with the training sample shortage problem in other domains, such as Natural Language Processing (NLP) including text classification [48,67,69], entity linking [33,53], relation extraction [29] and machine translation [17]. These methods also introduce high-level knowledge of labels to conduct feature transfer from seen labels to unseen labels. Notably, NLP data and labels are both symbol-based representation, which leads to benefits in feature transfer. In contrast, the feature transfer in our work is more challenging considering the gap between vision and symbol.
Explainable artificial intelligence
Explainable Artificial Intelligence (XAI), which aims to produce interpretable models or predictions, is becoming more and more popular nowadays [4,15,31]. Such methods enable humans to understand, trust, and effectively manage AI systems and their decisions. Some of the explainable works design white-box and inherently interpretable models like rule-based systems [54], while others try to justify the prediction of black-box models by for example approximating its behaviour locally with simple interpretable linear models [52], or quantifying the contribution of each single input variable [24].
Some explanations target humans with AI expertise. They can be used for system debug to manage and develop machine learning models efficiently [21,61]. While some explanations are for common people without AI expertise, for example, they help medical doctors to understand the decisions made by AI-based systems [6]. Most of these works prefer to generate textual explanations, which are more understandable by humans. For example, Biran et al. [5] introduce linguistic expressions from Wikipedia articles to explain the stock price prediction with natural language sentences. Li et al. [30] generate attributes and captions of images to verify whether the system really understands the image content when answering a visual question.
There are also a few works devoted to enriching the explanation with knowledge graphs (KGs), by utilizing human understandable background knowledge and common sense in these KGs, as well as their underlying semantics that can be inferred by reasoning [51,57]. For example, Tiddi et al. [57] exploit Linked Data as background knowledge to generate explanations for data clusters. Chen et al. [9] extract evidence from local domain ontologies and external KGs like DBpedia using Semantic Web techniques to explain the results of flight delay forecasting.
Another related direction is to utilize the attention mechanism to explain [50,66]. For example, Yang et al. [66] leverage attention layers to select words and sentences that have a decisive effect on document classification as explanations. Our work also utilizes such an attention technique but goes beyond it. It includes a general framework to incorporate class semantics from KGs and generate textual explanations for the core of ZSL – the transferability of deep features.
Transfer learning explanation
ZSL is often regarded as a branch of transfer learning which aims at utilizing samples, features or model parameters learned from one domain to guide the learning in another domain [44,60]. ZSL algorithms usually transfer features learned by deep neural networks from seen classes (domains with labeled training samples) to predict the testing samples of unseen classes (domains without labeled training samples).
Some works have been proposed to augment transfer learning as well as ZSL with KGs [9,26,27,71]. For example, in [26], prior knowledge about the prediction tasks and domains are expressed by ontologies and further utilized to analyze the transferability of features and samples to augment transfer learning. For another example, Zhang et al. [71] propose a transfer learning based algorithm for long-tail relation extraction, which incorporates data features from data-rich relations to tackle the prediction of data-poor relations. Knowledge of the relation, which comes from a KG, is investigated to enhance the feature learning of data-poor relations, using KG embeddings and relation hierarchy. In summary, these works indicate the feasibility of studying transfer learning tasks and domains by external knowledge from KGs. In our study, we not only utilize KGs for performance improvement (i.e., attentive ZSL learner based on KG and AGCN), but also for human understandable explanations.
Recent studies on transfer learning explanation focus on the analysis of feature transferability [9,14,32,68]. For example, Liu et al. [32] assume that the features are transferable from a source domain to a target domain if the source and target domains have similar feature structures. Chen et al. [9] extract knowledge (e.g., ontology axioms and DBpedia facts) that co-exist in the source and target domain to explain the transferability of features learned by deep neural networks. These works indicate that the transferability of features is highly related to the knowledge of the source and target domain. In this paper, we also focus on extracting domain knowledge (i.e., class knowledge) to generate explanations for feature transferability. Different from the above works, we on the one hand develop a general framework that generates explanations from different knowledge resources from multiple KGs such as Attribute Graph and DBpedia. On the other hand, we focus on KG-based ZSL – an essential and popular transfer learning branch whose current solutions are all black-box models without explanations.
Few works have been found to explain ZSL with human understandable knowledge. The only work we know is by Selvaraju et al. [56]. It first learns a mapping between class attributes and individual neurons in a network, and then predicts unseen neurons based on the attributes of unseen classes to optimize the learning of unseen classifiers. It also generates textual explanations by inversely mapping the predicted neurons to class attributes to validate the decisions made by unseen classifiers. The authors focus on grounding the transferred neurons in interpretable semantics, however, ignore the transferability of features between classes in ZSL. By contrast, the explainable ZSL proposed in our work pays attention to the transferability of deep features, which is more important for analyzing the nature of ZSL. Also, in [56], the generation of explanations relies on the input class attributes, while our method can access external resources and generate explanations involving not only domain-specific attributes but also general knowledge, which are more expressive in comparison with the ad-hoc attributes. Besides, the input class attributes also have an impact on the prediction of the ZSL model, that is to say, any changes for improving the diversity or quality of explanations (i.e., improving the input attributes) may hurt the classification performance. In contrast, the generation of explanations in our method is relatively independent of the classification model, which is more flexible than other explainable methods that need to make a tradeoff between accuracy and interpretability.
Preliminaries
Zero-shot learning
In zero-shot learning, the training set is denoted as
There are usually two prediction settings in ZSL: the standard ZSL and the generalized ZSL [65]. The former is to predict the labels of testing samples in
Class knowledge
In our study, we introduce three kinds of Knowledge Graphs (KGs) to describe the class knowledge, which depicts the semantic relationship between classes. These KGs are used for transferring features in ZSL model as well as generating explanations for the feature transferability. We briefly introduce them below.

An example of our two introduced KG resources for animal class Seabird. [Left] is the domain-specific Attribute Graph with corresponding entity Seabird; [Right] is the general DBpedia with aligned entity dbr:Seabird.
In order to provide an overall explanation for ZSL in animal recognition task, we take Attribute Graph as well as DBpedia as external KGs to extract visual knowledge like “red leg color” as well as general knowledge like descendants of “Seabird” in biology.
Framework overview
In this paper, we present a KG-based framework to explain the transferability of features in ZSL in a human understandable manner, including an Attentive ZSL learner (AZSL) and an explanation generator, as shown in Fig. 3. AZSL first models the hierarchical relationship of seen classes, unseen classes as well as their ancestor and descendant classes using WordNet, and then matches this class knowledge with deep features extracted from CNNs, which pursue class discrimination and are the core components of a classifier. Specifically, we utilize AGCN to encode the inter-class relationship and then predict a CNN classifier for each class, in which the unseen classifiers are learned by transferring features from seen classifiers. Considering that different seen classes have different contributions in the feature transfer, we introduce an additional attention layer in AGCN to learn the attention weights of seen classes. In this way, we select the most contributing seen classes for unseen classes as well as master the transfer of features from seen classes to unseen classes. Next, given unseen classes and their contributing seen classes, the explanation generator extracts richer class knowledge from external KGs, such as class attributes, semantic relations between classes and textual descriptions of classes, as evidence to justify why these seen classes transfer their features to the unseen ones (i.e., the transferability of deep features from seen classes to unseen classes). The generator also generates natural language explanations with these evidence using some hand-crafted templates.

Our proposed KG-based explainable ZSL framework.

Overview of attentive ZSL learner. During training, AZSL encodes class knowledge to predict classifiers with multiple graph convolutional layers and an attention layer; during testing, predicted classifiers are used to conduct nearest neighbor search to classify the testing images.
AZSL utilizes the class knowledge from WordNet and an Attentive Graph Convolutional Network (AGCN) to predict classifiers for unseen classes. As Fig. 4 shows, It first pre-trains a discriminative CNN classifier for each seen class (Fig. 4 [Right]), and then encodes class knowledge to predict classifiers for classes especially for unseen classes (Fig. 4 [Left]).
CNN classifier
Consider Convolutional Neural Network (CNN), a frequently used network for feature extraction in object recognition, where significant features of images are extracted to make predictions. Given an object class, when we use its images to train a CNN, the second to the last layer of the network will output a set of class-specific parameters. These parameters constitute a real-valued vector representing the discriminative visual features of this class, which can be used to classify new images of this class. Therefore, in this paper, we take this vector as a classifier and use it to classify the testing images by performing nearest neighbor search (more prediction details are in Section 4.2.3).
As a result, in AZSL, we hope to leverage AGCN to predict such a classifier for each class especially for each unseen class. In particular, as seen classes have enough training samples to learn their classifiers, we pre-train a set of seen classifiers with samples from
Predicting classifiers
AGCN is used to encode the graph-structured inter-class relationship and predict a classifier for each class node. It includes multiple graph convolutional layers and an attention layer.
Stacking the convolutional layer one after another, we can output the feature of class i at last layer:
Specifically, for each neighboring class of class i, its attention weight is computed by the similarity between its feature vector and
It is noted that we stack the attention layer after multiple graph convolutional layers, as Fig. 4 shows. We have attempted to add an attention layer after each convolutional layer in the preliminary experiments, however, we found the model is hard to converge. It may be because (i) the dimension of hidden features in our model (e.g., 2,048) is large compared with that in other graph attention networks (e.g., 8 in [58]), or (ii) our model is a regression model, whose training is often more difficult than other graph attention networks that are classification models (e.g., [58]).
Obviously, the model is trained in a semi-supervised manner. For unseen classes, their classifiers can be inferred (learned) by aggregating visual features from their neighboring seen classes.
Predicting testing samples
With predicted classifiers, we perform nearest neighbor search to predict labels for testing samples. Specifically, at test time, when a testing image arrives, AZSL first extracts its features using pre-trained CNN, and then multiplies the image features with these classifiers to produce some similarity scores. The class corresponding to the most similar classifier (i.e., the nearest one) is the predicted label. Regarding different prediction settings in ZSL, the candidate classifiers involve unseen classifiers (i.e.,
Meanwhile, we can learn contributing seen classes for each unseen class from attention layer. These seen classes have high attention weights and each of them is believed to be important in transferring features to the unseen class. We name them as
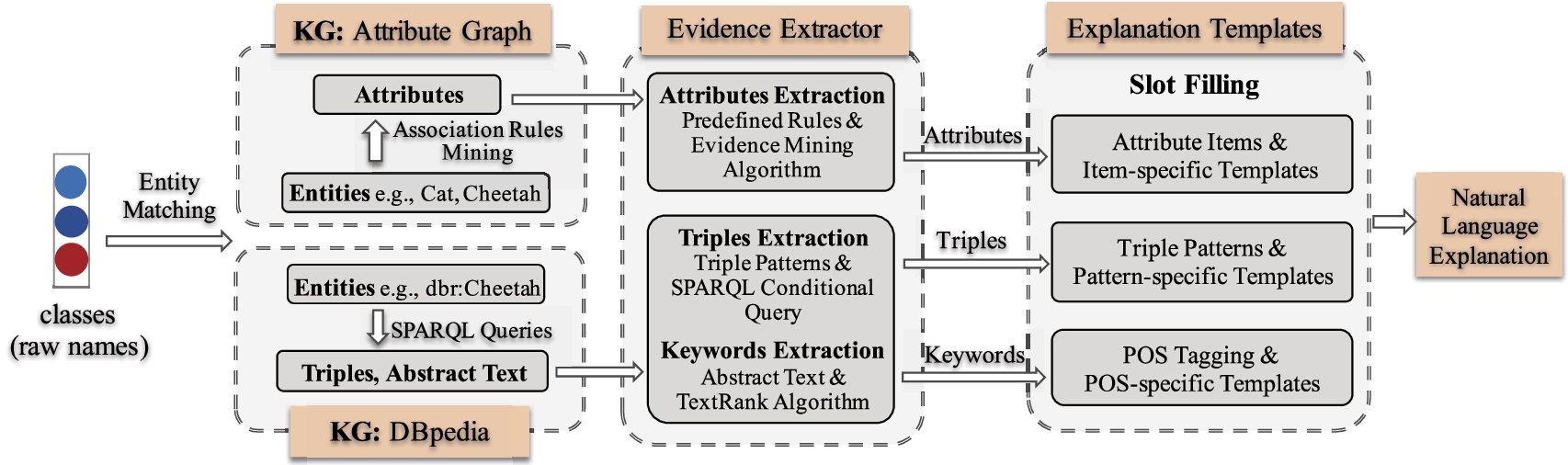
Illustrating for generating natural language explanation from external Attribute Graph and DBpedia.
Given unseen classes and their impressive seen classes, we introduce two external knowledge graphs, the domain-specific Attribute Graph and the general DBpedia, to extract reliable evidence and generate human understandable explanations to justify the feature transferability between seen and unseen classes.
The explanation generation procedure is illustrated in Fig. 5. Briefly, we (i) match raw class names with entities of external KGs; (ii) adopt different strategies to extract supported evidence from different external KGs; and (iii) generate natural language explanations with some templates.
Domain-specific KG: Attribute Graph
Considering that ZSL classes are naturally matched with entities in Attribute Graph, we first begin by extracting evidence. In Attribute Graph, the evidence refers to the common attributes shared by unseen classes and their impressive seen classes. However, the searching space is often large for finding the common attribute set, especially when multiple impressive seen classes exist. To this end, we develop a rule-mining based method to find out the common attributes by mining the association rules of classes, with an algorithm named EvidenceMining proposed. The mined rules illustrate the semantic association between seen and unseen classes, and the supporting set of a rule is a set of common attributes shared by these classes, which are desired evidence to explain the feature transferability from seen classes to unseen classes.
Association rule mining is widely used in Data Mining. It was first proposed for mining the association rules of shopping items from a list of customer transactions [1]. Each transaction consists of a set of items purchased by a customer in a visit. An association rule of items is like
Let
Example of mining association rules of classes Polar bear, Raccoon and Grizzly bear
Example of mining association rules of classes Polar bear, Raccoon and Grizzly bear

Evidence Mining
Take unseen class Grizzly bear and its impressive seen classes Polar bear and Raccoon as an example. Let
Algorithm 1 illustrates the pseudocode of mining rules and common attributes. Given an unseen class and its impressive seen classes, we first extract attributes of each class from Attribute Graph
In this way, we not only mine the association rules of seen and unseen classes with some measurements produced, e.g., support value and confidence value, but also extract common attributes from Attribute Graph as evidence to explain the transferability of features from seen classes to unseen classes.
dbr, dbo, etc. are URI prefixes in DBpedia. Please see
One challenge of class to entity matching is that only a part of ZSL classes have entity correspondences. On the one hand, the entity corresponding to a class may not exist in the KG. For example, DBpedia only contains an entity for Chicken but no Cock and Hen. The latter two however have totally different appearances. On the other hand, some classes are wrongly matched with DBpedia entities. For example, Red fox is incorrectly matched with entity dbr:Fox, while the correct matching should be dbr:Red_fox. To ensure the correctness of class to entity matching, we manually check the matching results and remove the incorrect ones. There are also some algorithms developed to automatically evaluate the entity matching results, for example, the string similarity based methods [41,47] and the embedding based methods [63,72] in entity alignment tasks. However, considering that these methods have some limitations and errors in real-world applications (i.e., relying on well-designed matching patterns or labeled entity pairs), and our work focuses on studying the interpretability in ZSL, we decide to manually check all matching results. It is expected that some methods can be developed to release the pressure of manual verification in the future.
Triple patterns and corresponding SPARQL query items, where s, u represent entity patterns corresponding to seen and unseen classes respectively, ∧ represents the joint operator of patterns
Different from the attribute annotations in Attribute Graph, the knowledge in DBpedia is massive and diverse. Therefore, with matched entities, we utilize SPARQL queries4
To this end, we design some triple patterns, as shown in Table 2. Based on these patterns, SPARQL queries are developed to retrieve triples, from which the relations or entities that associate seen and unseen entities (classes), and the common properties shared by seen and unseen entities (classes) are extracted. Consider the example in Fig. 1, where Cat and Serval share the same ancestors Felidae. The fact can be verified by triples (dbr:Cat, hypernym, dbr:Felidae) and (dbr:Serval, hypernym, dbr:Felidae), which are extracted according to the pattern
Therefore, we adopt TextRank [35], an unsupervised automatic summarization algorithm, to extract keywords from abstract text. The extracted words and phrases are core and descriptive to represent the class-specific properties so that illustrating the knowledge shared between entities. For example, the extracted keyword Africa in Fig. 1 illustrates the same living environment of Cheetah and Serval.
Aforementioned extracted items, including attributes from Attribute Graph, as well as triples and keywords from DBpedia, constitute fine-grained class knowledge which can be taken as evidence to explain the transferability of features from seen classes to unseen classes. To make these evidence more understandable, we organize them with some hand-crafted templates.
Inspired by Slot Filling, a popular method of completing sentence in dialogue system, we design templates with classes, entities, attributes, relations, properties and keywords as slots, and take extracted items as values to fill in. We design three different kinds of templates, as shown in Table 3, for structured triples, unstructured attributes and keywords respectively.
Templates for generating natural language explanations. An overall illustration is first provided.
,
,
,
,
,
, ADJ , etc. are slots in templates to be filled. The left of table is for attributes, where part of attribute items are listed. The center is for structured triples. The right is for textual keywords, where all Parts-of-Speech (POSs) of keywords (e.g., adjective (ADJ) and noun (NOUN)) and types of named entities (e.g., LOC) used are listed. Notably, the POS tags attached to the attribute items (e.g., coat (ADJ)) mean the attribute values with different POSs
Templates for generating natural language explanations. An overall illustration is first provided.
Attributes are domain-specific descriptions used for annotating objects. The attribute values of the same attribute item describe the same aspects of objects. For example, attributes like head, tail, claws and leg describe the body parts of animals, which both belong to the attribute item body part, while attributes like red, green and blue describe the appearance colors of animals, which belong to the attribute item color. Considering that the attributes belonging to the same attribute item can be expressed in a similar way, we design templates based on attribute items. For example, the common attribute sharp ear of Cat and Serval, which belongs to the attribute item body part, can be expressed with the sentence: “They both have sharp ears”. Table 3 lists some attribute items and their corresponding templates. Notably, the number of extracted common attributes varies a lot. In order to restrict the length of generated sentences and avoid excessively repetitive expressions, we randomly select 10 attributes to represent the knowledge between seen and unseen classes when the number of common attributes exceeds 10.
Structured triples have fixed formats, especially those extracted using the same triple patterns. Thus, we design templates to textualize triples according to the triple patterns as shown in the center of Table 3. The entities, properties and relations in extracted triples are taken as values to fill the corresponding slots in templates. For triples (dbr:Cat, hypernym, dbr:Felinae) and (dbr:Serval, hypernym, dbr:Felinae) extracted by pattern “
Keywords extracted from abstract text are natural expressions consisting of adjectives, nouns, their combinations and so on. One example is spotted coat. Therefore, we design templates based on the parts-of-speech (POSs) of keywords and utilize POS Tagging to generate natural language sentences. Specifically, each keyword is first labeled with a POS tag, and then filled into the template with the same POS slot. For the keyword spotted coat labeled with an ADJ-NOUN tag, we can use the template with ADJ-NOUN slot to generate the sentence: “They are similar in spotted coat”. Additionally, some nouns have special meanings, for example, Africa describing the habitat of Serval is a location noun. To express them better, we further use Named Entity Recognition (NER) [40] to identify the named entities among these nouns and classify them into different types, and then design different templates regarding different types. The right of Table 3 lists the types we adopt and their corresponding templates. In our experiments, we utilize SpaCy,5
We conduct experiments on an image classification task and evaluate our framework regarding the following aspects: (1) accuracy of our attentive ZSL learner (AZSL) in the standard ZSL and generalized ZSL setting in comparison with the state-of-the-art ZSL baselines; (2) illustration of the feature transfer from seen classes to unseen classes; (3) evaluation on the generated explanations, including human scoring, qualitative analysis and case studies. Based on the generated explanations, we also discuss the transfer of deep features in ZSL.
Experiment setting
Datasets
Two widely used image sets are adopted: Animals with Attributes (AwA) [23] and ImageNet [10]. AwA is a coarse-grained dataset, while ImageNet is diverse in terms of granularity, i.e., it contains a collection of fine-grained datasets, e.g., different vehicle types, as well as coarse-grained datasets. Each AwA class or ImageNet class corresponds to an entity of WordNet. For each dataset, we split the classes into two disjointed parts – seen classes and unseen classes as in [65]. The former have training images while the latter do not but are semantically related to the former. Specifically, in ImageNet, 398 animal classes are used as seen classes, each of them contains about 1,000 images, while the classes that are one-hop away from the seen ones in WordNet are taken as unseen classes. In AwA, 40 classes are used as seen classes and 10 as unseen classes. It is noted that we only consider the “one-hop” unseen classes in ImageNet, although those more hops away can also be taken as unseen classes. It is because ZSL algorithms often perform worse when the unseen classes are far from the seen ones [12,42,59]. In order to investigate the explainable ZSL problem better, we focus on these one-hop classes which are visually and semantically similar with the seen classes.
Statistics of the image sets. “#Train/Val/Test” denotes the number of images for training/validation/testing. “Test(Seen/Unseen)” means the testing images of seen or unseen classes in the generalized ZSL setting. Notably, we only test on AwA and ImageNet in the generalized ZSL
Statistics of the image sets. “#Train/Val/Test” denotes the number of images for training/validation/testing. “Test(Seen/Unseen)” means the testing images of seen or unseen classes in the generalized ZSL setting. Notably, we only test on AwA and ImageNet in the generalized ZSL
We leverage WordNet to build the hierarchical graph of classes in our datasets. Specifically, we first make an alignment between ZSL classes and WordNet entities. And then, these classes are connected with each other via “subClassOf” relation edge, in our experiments, we adopt two strategies to construct the edge. One is to look up the hypernyms of classes using WordNet interface in NLTK toolkit.6
Especially, as ImageNet contains not only coarse-grained subsets but also fine-grained subsets, the density of the connection between seen classes and unseen classes varies a lot: some seen (unseen) classes whose first-order neighbors contain multiple (e.g., 5) unseen (seen) classes (i.e., dense connection), while some seen (unseen) classes whose first-order neighbors are very few (e.g., 1) (i.e., sparse connection). Regarding different connection density, we extract a subset
Additionally, in our experiments, we take partial samples of seen classes as the validation set. Specifically, the images of each seen class are split into 2 parts –
The following ZSL methods are used as baselines:
In our AZSL, we leverage Attentive GCN to optimize the encoding of class knowledge so as to learn more effective unseen classifiers. To demonstrate the effectiveness of the attention layer in AGCN, we implement graph convolutional layers with the graph convolutional operations proposed in GCNZ and DGP. The model referring to GCNZ is denoted as
Besides, NIWT, which was proposed by Selvaraju et al. [56], is a work for explaining ZSL. However, in our paper, we do not make a comparison with it. It is because that NIWT focuses on justifying the predictions made by unseen classifiers and grounding the transferred neurons in interpretable semantics, while our work focuses on explaining the transferability of features from seen classes to unseen classes.
Model configuration and evaluation metrics
We adopt ResNet50 – a successful CNN architecture to extract the features of images [16]. For ResNet50, the output parameter vector of the second to the last layer has 2,048 dimensions, therefore, the dimensionality of the classifier in our paper is also set to 2,048. Following GCNZ and DGP, we adopt 6 convolutional layers for AZSL-G and 2 convolutional layers for AZSL-D. Both of them contain one attention layer with an attention weight threshold
We evaluate the ZSL model with
Performance (%) of AZSL-G, AZSL-D and baselines on AwA, ImageNet and
in the standard ZSL setting.
indicates the results come from the original paper. “–” means the method cannot be applied to the dataset. “±” represents the variation range of results in the repeated experiments
Performance (%) of AZSL-G, AZSL-D and baselines on AwA, ImageNet and
Standard ZSL setting
We first report the results under the standard ZSL setting in Table 5. It can be seen that the performance of KG-based methods, including GCNZ [59], DGP [18] and our AZSL, is much higher than that of traditional methods, especially on ImageNet. This verifies that class semantics extracted from a KG are more effective in modeling the inter-class relationship and can significantly improve the ZSL performance. It is as expected, because the semantics of class names and attributes used by traditional methods is not as rich as that of KG.
Compared with GCNZ and DGP – the state-of-the-art methods utilizing KG semantics, our AZSL-G and AZSL-D perform better in most settings. This indicates the effectiveness of our Attentive GCN architecture in dealing with the ZSL problem. Considering the main goal of AZSL is to provide explanations for ZSL and it is widely believed that there is a compromise between a machine learning model’s interpretation and accuracy [45], the performance improvement of AZSL over GCNZ and DGP is still very promising.
We also evaluate KG-based methods on
Generalized ZSL setting
From the above results, we observe that the KG-based ZSL methods perform better than other traditional methods, therefore, in this subsection, we mainly report the prediction results of KG-based methods, as Table 6 shows. We find that the performance of all methods dramatically drops when predicting unseen testing samples (i.e.,
Performance (%) of AZSL-G, AZSL-D and KG-based baselines on AwA, ImageNet in the generalized ZSL setting
Performance (%) of AZSL-G, AZSL-D and KG-based baselines on AwA, ImageNet in the generalized ZSL setting
Error analysis of DGP and AZSL-D on AwA in the generalized ZSL setting. “from Seen/Unseen” means the wrongly predicted labels are from seen class set or unseen class set
To validate our assumption, we conduct error analysis on those wrongly classified unseen testing samples. As Table 7 shows, we count the distribution of predicted labels of these misclassified testing samples. Taking the prediction results of DGP on AwA as examples,
We also find that our models perform not well when predicting seen testing samples (i.e.,
In this subsection, we illustrate the transfer of deep features from seen classes to unseen classes with the learned impressive seen classes (IMSCs), including an intuitive visualization and some quantitative analyses.
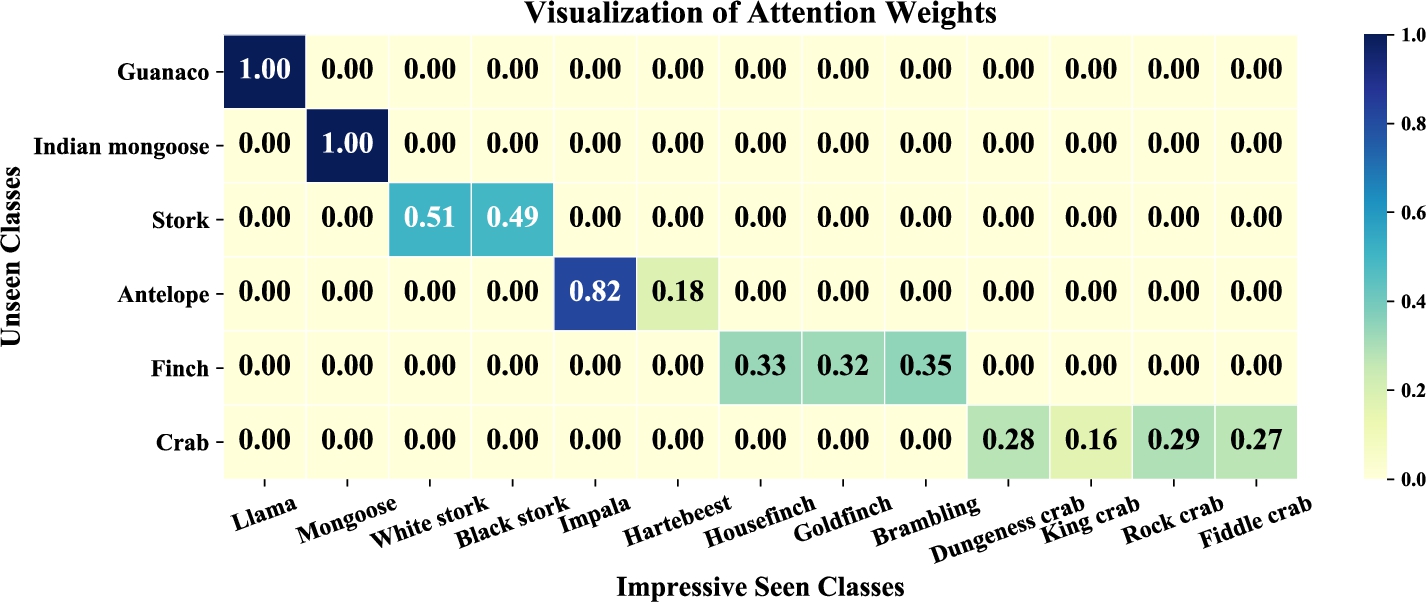
Impressive seen classes (IMSCs) as well as their normalized attention weights of 6 randomly selected unseen classes. 0.00 here means a weight value below a threshold (very close to zero).
Firstly, Fig. 6 visualizes some unseen classes and their IMSCs, showing that these impressive seen classes transfer their deep features to the corresponding unseen classes. The presented examples in Fig. 6 are mostly consistent with our common sense about animals, for example, in our impression, Guanaco and Llama are two animals that are similar in appearance. We also evaluate the impact of IMSCs by analyzing the performance drop when some IMSCs are removed, as shown in Fig. 7. Taking the prediction results of AZSL-G as examples, the performance decreases in all cases when some IMSCs are removed, in comparison with NO removing. Specially, it drops to 0 in most cases when all IMSCs are removed. According to these observations, we can conclude that our AZSL is capable of learning reasonable IMSCs for unseen classes and these IMSCs play a key role in transferring their features to unseen classes. They can be used to generate explanations to analyze the transferability of features from seen classes to unseen classes.

Hit@2 of AZSL-G when one IMSC is removed, all IMSCs are removed and NO IMSCs are removed.
We also observe that the number of IMSCs of different unseen classes varies dramatically. For example, Indian mongoose and Guanaco have only one IMSC, while Finch and Crab have 3 and 4 respectively. We further count the distribution of IMSC size in Table 8. An interesting finding is that most unseen classes have only one IMSC (
We also note that some unseen classes (around
In this subsection, we demonstrate how human beings are satisfied with the generated textual explanations. We also compare the impact of different external KGs, and present some case studies.
The distribution of impressive seen classes (IMSCs)
The distribution of impressive seen classes (IMSCs)
For human evaluation, we invite 25 volunteers without AI expertise to score the generated explanations. The first language of volunteers is Chinese, they are all undergraduate students who are fluent in reading English. We divide all unseen classes into 5 parts. Each one contains about 100 unseen classes and corresponding explanations. Each explanation is scored by 5 volunteers, the final decision is made by majority voting.
We defined two metrics – readability and rationality for evaluation. “G” (Good), “M” (Median) or “B” (Bad) are scored for each metric.
These two metrics are scored independently. To help volunteers deal with the evaluation better, we prepare some guidelines and examples for them before scoring to make sure they are familiar with the scoring procedure. Besides, we also provide some images and textual illustrations of classes as references as well as some notes of generated explanations during scoring. It is allowed that volunteers can skip the scoring item if they are not sure about their judgment.
Table 9 presents the human evaluation results. We can find that the explanations of most unseen classes are satisfactory, especially on the rationality, and only a very small ratio of explanations get “Bad” on readability and rationality. It can also be seen that
Results of human evaluation on the generated explanations
Results of human evaluation on the generated explanations

The explanations for unseen classes: Horse, Rat, Dolphin and Stork. In each case, images of the unseen class and its impressive seen classes (IMSCs), their matched DBpedia entities, the extracted attributes, triples and keywords are displayed. The association rules of seen and unseen classes from EvidenceMining algorithm are listed with their measurements (“sup.”: the support value, “con.”: the confidence value). “(w:∗)” behind IMSC denotes the attention weights. The textual explanations as well as the evaluation results from volunteers are also displayed. The sentences in italic are explanations generated with knowledge from Attribute Graph (i.e., attributes), while those marked with underline are generated with knowledge from DBpedia (i.e., triples and keywords).
We present some examples of the generated explanations in Fig. 8, with the evidence extracted from Attribute Graph and DBpedia. For the unseen class Horse, whose features are transferred from seen class Zebra, our explanation generator extracts attribute evidence such as hooves, longneck, chewteech, tail from Attribute Graph to illustrate the common attributes between Horse and Zebra, and mine the association rule: “
We find that the evidence from different external KGs have different characteristics. Taking Rat in Fig. 8 as an example, the evidence from Attribute Graph are more likely to generate explanations in vision, such as body parts (quadrupedal, paws) and coat appearances (furry), while the evidence from DBpedia usually generate more general explanations, including not only visual descriptions such as incisors, but also general descriptions such as rodent ancestor and invasive mammal in biology. We also have similar observations in other examples, this is due to the nature of these two KGs – Attribute Graph is a domain-specific knowledge graph while DBpedia is a general one.
We also find and compare some limitations of these two KGs. Due to the great cost on attribute annotations, the scale of Attribute Graph is limited, and a considerable portion of classes (about
In summary, the evidence from Attribute Graph is more applicable to generate explanations for specific domain such as vision, especially when the attribute annotations are sufficient, while the evidence from DBpedia are more general and accessible: it can deal with large scale ZSL problems with a number of classes and can also be applied to different ZSL applications such as text classification. However, the evidence from Attribute Graph and DBpedia are compatible with each other, and can be combined.
The evaluation results of explanations with different numbers of common attributes
The evaluation results of explanations with different numbers of common attributes
From Fig. 8, we observe that the number of attributes extracted for different classes from Attribute Graph varies a lot. For example, Horse, Dolphin and Rat both have 10 common attributes while Stork only has 5. In our statistics,
In all explanations with more than 10 common attributes,
As for the quality in readability, we find that there is a slip when packing too many attributes. It might be because there are many repetitive expressions in the generated sentences. It is believed that randomly taking 10 attributes to generate is a good choice when the number of attributes is more than 10, however, some representative attributes may be lost as we mentioned above. Therefore, we look forward to adopting some strategies to improve the selection of attributes in the future, for example, evaluating the relevancy between classes and attributes to select the most relevant ones.
Generally speaking, the high coverage of attributes has a positive effect on generating higher quality explanations, especially in terms of rationality. However, it is better to combine the knowledge from Attribute Graph and DBpedia to complement each other.
Discussion on feature transfer in ZSL
In this subsection, we analyze the transfer of deep features in ZSL according to our generated explanations. We take the prediction results of AZSL-G in the standard ZSL setting as examples.
Successful and failed transfer
In ZSL, the samples of unseen classes are predicted by transferring features from seen classes. However, we find a case where some unseen classes have no features transferred from seen classes, and the prediction results on Hit@1 and Hit@2 are both 0. Such a case is viewed as a failed transfer (FT). In contrast, the case where some unseen classes have features transferred from seen classes is a successful transfer (SF). For example, the Hit@1 and Hit@2 of unseen class Eared seal are both 0 and its feature transfer is failed, while another class Frog whose features are transferred from seen classes Tree frog and Tailed frog achieves
Those explanations scored with “Good” on rationality illustrate the transferability of features from seen classes to unseen classes well, and are regarded as good explanations, while others are not. We find that
Performance of AZSL-G with different types of transferability
Performance of AZSL-G with different types of transferability
From the generated explanations, we also find that the transfer of features between seen classes and unseen classes have different types. For example, some features are transferred between two sibling classes, while some features are transferred from one class to its children or parents. Given a successful transfer between a seen class and an unseen class, we divide it into four types: (i) ancestor which refers to the case where the seen class is the ancestor of the unseen class or vice versa (e.g., unseen class Stork is the ancestor of seen classes White stork in Fig. 8); (ii) sibling which refers to the case where the seen class and the unseen class are siblings (e.g., unseen class Horse and seen class Zebra in Fig. 8 are both the children of Equus); (iii) ancestor-sibling which refers to the case where the type of the feature transfer between seen and unseen classes includes both ancestor and sibling; (iv) other which refers to the case where there are no ancestor or sibling relationship between seen and unseen classes.
We count all successful transfers in ImageNet according to the different types of feature transfer. As shown in Table 11,
Conclusion and outlook
In this study, we investigate explainable ZSL with (1) a new ZSL learner which utilizes the inter-class relationships extracted from WordNet as well as the Attentive Graph Convolutional Network to predict classifiers for unseen classes, and (2) an explanation generator which generates human understandable explanations with external Attribute Graph and DBpedia to justify the transferability of features in ZSL. The study is evaluated with two image sets. We not only achieve higher classification performance than the state-of-the-art baselines, but also generate promising explanations which make the transferability of features in ZSL more explainable. With the generated explanations, we also analyze the transfer of features from seen classes to unseen classes, which shows the potential of further improving the performance of ZSL algorithms.
In our work, we extract class knowledge e.g., attributes, triples and keywords from Attribute Graph and DBpedia as evidence to illustrate the transferability of features from seen classes to unseen classes. From another point of view, these evidence also build detailed semantic relationships between classes, which may be helpful for the feature transfer in ZSL. Therefore, in the future work, we can integrate these common attributes, keywords and triples into the hierarchical graph of classes to enrich the class semantics and improve the performance of ZSL models [8,13].
We also consider further improving the quality of explanations by making full use of the knowledge in external KGs. For example, we can use Semantic Web techniques such as ontology that involves the domain and range of properties to assist the knowledge extraction from Attribute Graph and DBpedia. Note that the ontology of DBpedia is ready-made, while the ontology of Attribute Graph may need to be designed manually considering it is collected from attribute annotations. We will explore this direction in the future.
Our work currently focuses on the image classification tasks, we also look forward to applying it in other domains like KG construction and natural language processing. For example, it can be applied for long-tail relation extraction [71] and zero-shot knowledge graph completion [49]. The models proposed in these tasks usually utilize label knowledge to transfer data features from seen (or data-rich) labels to unseen (or data-poor) labels, we can also introduce attention mechanism or other strategies into these models to attentively select the seen (or data-rich) labels which are contributing to the feature learning of unseen (or data-poor) labels. With learned contributing seen labels, the explanations of the feature transferability can be made by accessing the knowledge from external KGs as our work does. It is noted that the external KGs such as DBpedia can still be utilized to generate explanations for these tasks, while Attribute Graph is specific to image classification. If necessary, we can explore other external KGs for new applications or introduce other domain-specific knowledge from domain experts or public resources.
Footnotes
Acknowledgements
This work is funded by national key research program 2018YFB1402800, NSFC91846204/U19B2027, and supported by Alibaba-ZJU Frontier Technology Research Center. Jiaoyan Chen’s contribution is supported by the AIDA project (Alan Turing Institute), the SIRIUS Centre for Scalable Data Access (Research Council of Norway), Samsung Research UK, Siemens AG, and the EPSRC projects AnaLOG (EP/P025943/1), OASIS (EP/S032347/1) and UK FIRES (EP/S019111/1).