
Abstract
Nowadays natural language generation (NLG) is used in everything from news reporting and chatbots to social media management. Recent advances in machine learning have made it possible to train NLG systems that seek to achieve human-level performance in text writing and summarisation. In this paper, we propose such a system in the context of Wikipedia and evaluate it with Wikipedia readers and editors. Our solution builds upon the ArticlePlaceholder, a tool used in 14 under-resourced Wikipedia language versions, which displays structured data from the Wikidata knowledge base on empty Wikipedia pages. We train a neural network to generate an introductory sentence from the Wikidata triples shown by the ArticlePlaceholder, and explore how Wikipedia users engage with it. The evaluation, which includes an automatic, a judgement-based, and a task-based component, shows that the summary sentences score well in terms of perceived fluency and appropriateness for Wikipedia, and can help editors bootstrap new articles. It also hints at several potential implications of using NLG solutions in Wikipedia at large, including content quality, trust in technology, and algorithmic transparency.
Introduction
Wikipedia is available in 301 languages, but its content is unevenly distributed [31]. Language versions with less coverage than e.g. English Wikipedia face multiple challenges: fewer editors means less quality control, making that particular Wikipedia less attractive for readers in that language, which in turn makes it more difficult to recruit new editors from among the readers.
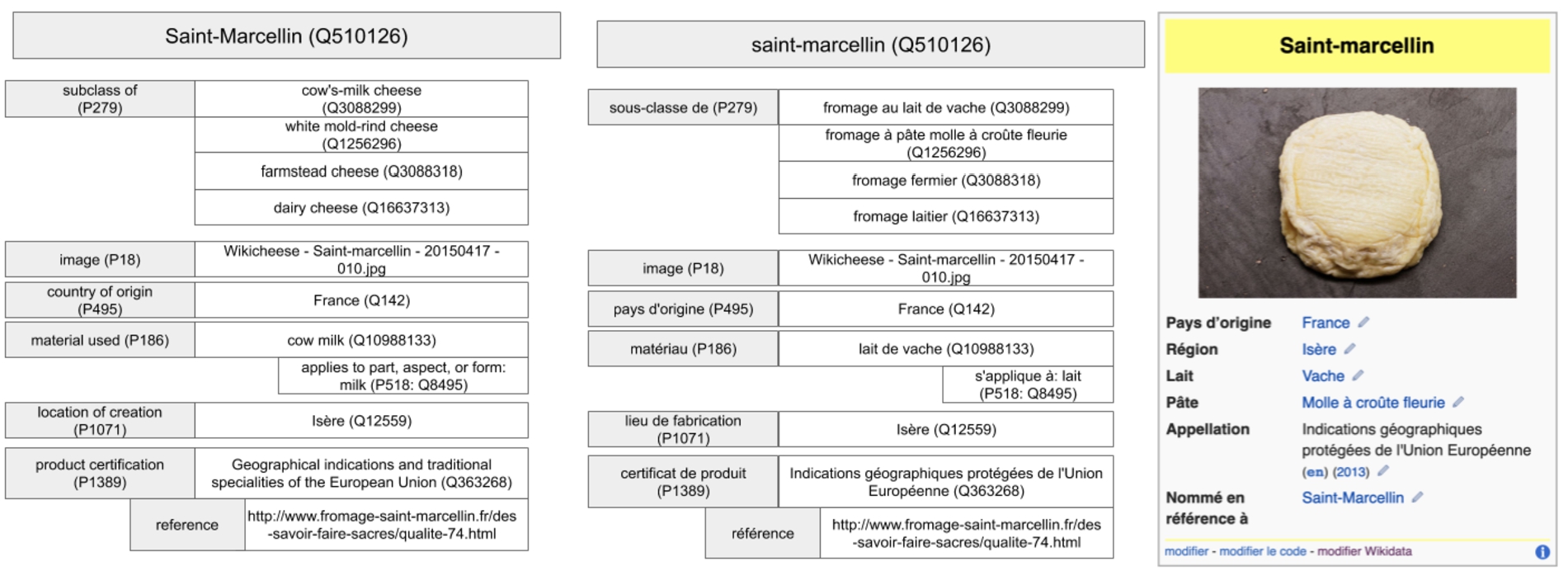
Representation of Wikidata statements and their inclusion in a Wikipedia infobox. Wikidata statements in French (middle, English translation to their left) are used to fill out the fields of the infobox in articles using the fromage infobox on the French Wikipedia.
Wikidata, the structured-data backbone of Wikipedia [86], offers some help. It contains information about more than 55 million entities, for example, people, places or events, edited by an active international community of volunteers [40]. More importantly, it is multilingual by design and each aspect of the data can be translated and rendered to the user in their preferred language [39]. This makes it the tool of choice for a variety of content integration affordances in Wikipedia, including links to articles in other languages and infoboxes. An example can be seen in Fig. 1: in the French Wikipedia, the infobox shown in the article about cheese (right) automatically draws in data from Wikidata (left) and displays it in French.
In previous work of ours, we proposed the ArticlePlaceholder, a tool that takes advantage of Wikidata’s multilingual capabilities to increase the coverage of under-resourced Wikipedias [41]. When someone looks for a topic that is not yet covered by Wikipedia in their language, the ArticlePlaceholder tries to match the topic with an entity in Wikidata. If successful, it then redirects the search to an automatically generated placeholder page that displays the relevant information, for example the name of the entity and its main properties, in their language. The ArticlePlaceholder is currently used in 14 Wikipedias (see Section 3.1).
In this paper, we propose an iteration of the ArticlePlaceholder to improve the representation of the data on the placeholder page. The original version of the tool pulled the raw data from Wikidata (available as triples with labels in different languages) and displayed it in tabular form (see Fig. 3 in Section 3). In the current version, we use Natural Language Generation (NLG) techniques to automatically produce a single summary sentence from the triples instead. Presenting structured data as text rather than tables helps people uninitiated with the involved technologies to make sense of it [84]. This is particularly useful in contexts where one cannot make any assumptions about the levels of data literacy of the audience, as is the case for a large share of the Wikipedia readers.
Our NLG solution builds upon the general encoder-decoder framework for neural networks, which is credited with promising results in similar text-centric tasks, such as machine translation [12,82] and question generation [16,19,78]. We extend this framework to meet the needs of different Wikipedia language communities in terms of text fluency, appropriateness to Wikipedia, and reuse during article editing. Given an entity that was matched by the ArticlePlaceholder, our system uses its triples to generate a Wikipedia-style summary sentence. Many existing NLG techniques produce sentences with limited usability in user-facing systems; one of the most common problems is their ability to handle rare words [15,58], which are words that the model does not meet frequently enough during training, such as localisations of names in different languages. We introduce a mechanism called property placeholder [36] to tackle this problem, learning multiple verbalisations of the same entity in the text [84].
In building the system we aimed to pursue the following research questions:
The evaluation helps us build a better understandings of the tools and experience we need to help nurture under-served Wikipedias. Our quantitative analysis of the reading experience showed that participants rank the summary sentences close to the expected quality standards in Wikipedia, and are likely to consider them as part of Wikipedia. This was confirmed by the interviews with editors, which suggested that people believe the summaries to come from a Wikimedia-internal source. According to the editors, the new format of the ArticlePlaceholder enhances the reading experience: people tend to look for specific bits of information when accessing a Wikipedia page and the compact nature of the generated text supports that. In addition, the text seems to be a useful starting point for further editing and editors reuse a large portion of it even when it includes
We believe the two studies could also help advance the state of the art in two other areas: together, they propose a user-centred methodology to evaluate NLG, which complements automatic approaches based on standard metrics and baselines, which are the norm in most papers; at the same time, they also shed light on the emerging area of human-AI interaction in the context of NLG. While the editors worked their way around the
Structure of the paper The remainder of the paper is organised as follows. We start with some background for our work and related papers in Section 2. Next, we introduce our approach to bootstrapping empty Wikipedia articles, which includes the ArticlePlaceholder tool and its NLG extension (Section 3). In Section 4 we provide details on the evaluation methodology, whose findings we present in Section 5. We then discuss the main themes emerging from the findings and their implications and the limitations of our work in Section 6 and 7, before concluding with a summary of contributions and planned future work in Section 8.
Previous submissions A preliminary version of this work was published in [36,37]. In the current paper, we have carried out a comprehensive evaluation of the approach, including a new qualitative study and a task-based evaluation with editors from six language communities. By comparison, the previous publications covered only a metric-based corpus evaluation which was complemented by a small quantitative study of text fluency and appropriateness in the second one. The neural network architecture has been presented in detail in [36].
We divide this section into three areas. First we provide some background on Wikipedia and Wikidata, with a focus on multilingual aspects. Then we summarise the literature on text generation and conclude with methodologies to evaluate NLG systems.
Multilingual Wikipedia and Wikidata
Wikipedia is a community-built encyclopedia and one of the most visited websites in the world. There are currently 301 language versions of Wikipedia, though coverage is unevenly distributed. Previous studies have discussed several biases, including gender of the editors [14], and topics, for instance a general lack of information on the Global South [24].
Language coverage tells a similar story. [67] noted that only
Our work is motivated and complements previous studies and frameworks that argue that the language of global projects such as Wikipedia [32] should express cultural reality [46]. Instead of using content from one Wikipedia version to bootstrap another, we take structured data labelled in the relevant language and create a more accessible representation of it as text, keeping those cultural expressions unimpaired in terms of language composition compared to machine translation.
To do so, we leverage Wikidata [86]. Wikidata was originally created to support Wikipedia’s language connections, for instance links to articles in other languages or infoboxes, see example from Section 1); however, it soon evolved into becoming a critical source of data for many other applications.
Wikidata contains statements on general knowledge, e.g. about people, places, events and other entities of interest. The knowledge base is created and maintained collaboratively by a community of editors, assisted by automated tools called bots [38,80]. Bots take on repetitive tasks such as ingesting data from a different source, or simple quality checks.
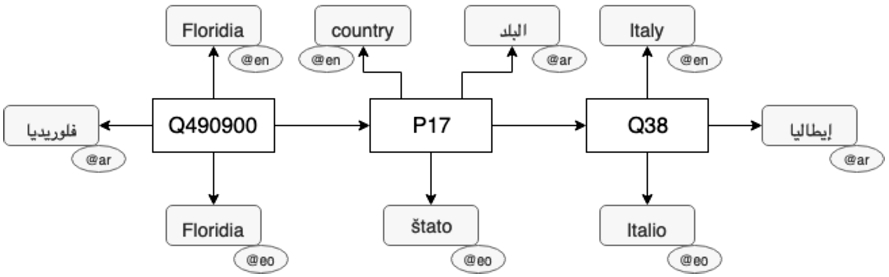
Example of labeling in Wikidata. Each entity can be labeled in multiple languages using the labeling property
The basic building blocks of Wikidata are items and properties. Both have identifiers, which are language-independent, and labels in one or more languages. They form triples, which link items to their attributes, or to other items. Figure 2 shows a triple linking a place to its country, where both items and the property between them have labels in three languages.
We analysed the distribution of label languages in Wikidata in [39] and noted that while there is a bias to English, the language distribution is more balanced than on the web at large. This was the starting point for our work on the ArticlePlaceholder (see Section 3), which leverages the multilingual support of Wikidata to bootstrap empty articles in less-resourced Wikipedias.
Our works builds on top of prior research that looked at generating texts, without intermediate Machine Translation stages, preserving the cultural characteristics of the target languages [7,29,42,47]. In our task, we focus on generating sentences from triples expressed as Resource Description Framework (RDF) or similar. Many of the related approaches rely on templates, which are either based on linguistic features e.g., grammatical rules [87] or are hand-crafted [20]. An example is Reasonator, a tool for lexicalising Wikidata triples with templates translated by users.1
To tackle this limitation, Duma et al. [17] and Ell et al. [18] introduced a distant-supervised method to verbalise triples, which learns templates from existing Wikipedia articles. While this makes the approach more suitable for language-independent tasks, templates assume that entities will always have the relevant triples to fill in the slots. This assumption is not always true. In our work, we propose a template-learning baseline and show that adapting to the varying triples available can achieve better performance.
Sauper and Barzilay [76] and Pochampally et al. [69] generate Wikipedia summaries by harvesting sentences from the Internet. Wikipedia articles are used to automatically derive templates for the topic structure of the summaries and the templates are afterward filled using web content. Both systems work best on specific domains and for languages like English, for which suitable web content is readily available [53].
There is a large body of work that uses the encoder-decoder framework from machine translation [12,82] for NLG [11,21,22,51,55,59,79,84,90,91]. Adaptations of this framework have shown great potential at tackling various aspects of triples-to-text tasks ranging from microplanning by Gardent et al. [21] to generation of paraphrases by Sleimi and Gardent [79]. Mei et al. [59] sought to generate textual descriptions from datasets related to weather forecasts and RoboCup football matches. Wiseman et al. [90] used pointer-generator networks [77] to generate descriptions of basketball games, while Gehrmann et al. [22] did the same for restaurant descriptions.
A different line of research aims to explore knowledge bases as a resource for NLG [10,11,17,51,55,84,91]. In all these examples, linguistic information from the knowledge base is used to build a parallel corpus containing triples and equivalent text sentences from Wikipedia, which is then used to train the NLG algorithm. Directly relevant to the model we propose are the proposals by Lebret et al. [51], Chisholm et al. [11], Liu et al. [55], Yeh et al. [91] and Vougiouklis et al. [84,85], which extend the general encoder-decoder neural network framework from [12,82] to generate short summaries in English. The original of English biographies generation was introduced by Lebret et al. [51] who used feed-forward language model with slot-value templates to generate the first sentence of a Wikipedia summary from its corresponding infobox. Incremental upgrades of the original architecture on the same task include the introduction of an auto-encoding pipeline based on an attentive encoder-decoder architecture using GRUs [11], a novel double-attention mechanism over the input infoboxes’ fields and their values [55], and adaptations of pointer-generator mechanisms [85,91] over the input triples.
All these approaches use structured data from Freebase, Wikidata and DBpedia as input and generate summaries consisting either by one or two sentences that match the style of the English Wikipedia in a single domain [11,51,55,84,91] or more recently in more open-domain scenarios [85]. While this is a rather narrow task compared to other generative tasks such as translation, Chisholm et al. [11] discuss its challenges in detail and show that it is far from being solved. Compared to these previous works, the NLG algorithm presented in this paper is for open-domain tasks and multiple languages.
Related literature suggests three ways of determining how well an NLG system achieves its goals. The first, which is commonly referred to as metric-based corpus evaluation [72], use text-similarity metrics such as BLEU [66], ROUGE [54] and METEOR [50]. These metrics essentially compare how similar the generated texts are to texts from the corpus. The other two involve people and are either task-based or judgement/rating-based [72]. Task-based evaluations aim to assess how an NLG solution assists participants in undertaking a particular task, for instance learning about a topic or writing a text. judgement-based evaluations rely on a set of criteria against which participants are asked to rate the quality of the automatically generated text [72].
Metric-based corpus evaluations are widely used as they offer an affordable, reproducible way to automatically assess the linguistic quality of the generated texts [4,11,36,45,51,72]. However, they do not always correlate with manually curated quality ratings [72].
Task-based studies are considered most useful, as they allow system designers to explore the impact of the NLG solution to end-users [60,72]. However, they can be resource-intensive – previous studies [73,88] cite five figure sums, including data analysis and planning [71]. The system in [88] was evaluated for the accuracy of the generated literacy and numeracy assessments by a sample of 230 participants, which cost as much as 25 thousand UK pounds. Reiter et al. [73] described a clinical trial with over 2000 smokers costing 75 thousand pounds, assumed to be the most costly NLG evaluation at this point. All of the smokers completed a smoking questionnaire in the first stage of the experiment, in order to find what portion of those who received the automatically generated letters from STOP had managed to quit.
Given these challenges, most research systems tend to use judgement-based rather than task-based evaluations [4,11,17,18,45,64,72,81]. Besides their limited scope, most studies in this category do not recruit from the relevant user population, relying on more accessible options such as online crowdsourcing. Sauper and Barzilay [76] is a rare exception. In their paper, the authors describe the generation of Wikipedia articles using a content-selection algorithm that extracts information from online sources. They test the results by publishing 15 articles about diseases on Wikipedia and measuring how the articles change (including links, formatting and grammar). Their evaluation approach is not easy to replicate, as the Wikipedia community tends to disagree with conducting research on their platform.2
The methodology we follow draws from all these three areas: we start with an automatic, metric-based corpus evaluation to get a basic understanding of the quality of the text the system produces and compare it with relevant baselines. We then use quantitative analysis based on human judgements to assess how useful the summary sentences are for core tasks such as reading and editing. To add context to these figures, we run a mixed-methods study with an interview and a task-based component, where we learn more about the user experience with NLG and measure the extent to which NLG text is reused by editors, using a metric inspired from journalism [13] and plagiarism detection [70].
The overall aim of our system is to give editors access to information that is not yet covered in Wikipedia, but is available, in the relevant language, in Wikidata. The system is built on the ArticlePlaceholder that displays Wikidata triples dynamically on different language Wikipedias. In this paper, we extend the ArticlePlacehoder with an NLG component that generates an introductory sentence on each ArticlePlaceholder page in the target language from Wikidata triples.

Example page of the ArticlePlaceholder as deployed now on 14 Wikipedias. This example contains information from Wikidata on Triceratops in Haitian-Creole.

Representation of the neural network architecture. The triple encoder computes a vector representation for each one of the three input triples from the ArticlePlaceholder,
As discussed earlier, some Wikipedias suffer from a lack of content, which means fewer readers, and in turn, fewer potential editors. The idea of the ArticlePlaceholder is to use Wikidata, which contains information about 55 million entities (by comparison, the English Wikipedia covers around 5 million topics), often in different languages, to bootstrap articles in language versions lacking content. An initial version of this tool was presented in [41].
ArticlePlaceholders are pages on Wikipedia that are dynamically drawn from Wikidata triples. When the information in Wikidata changes, the ArticlePlaceholder pages are automatically updated. In the original release, the pages display the triples in a tabular way, purposely not reusing the design of a standard Wikipedia page to make the reader aware that the page was automatically generated and requires further attention. An example of the interface can be seen in Fig. 3.
The Article Placeholder is deployed on 14 Wikipedias with a median of 69,623.5 articles, between 253,539 (Esperanto) and 7,464 (Northern Sami).
Text generation
We use a data-driven approach that allows us to extend the ArticlePlaceholder pages with a short description of the article’s topic.
Neural architecture
We reuse the encoder-decoder architecture introduced in previous work of ours in Vougiouklis et al. [84], which was focused on a closed-domain text generative task for English. The model consists of a feed-forward architecture, the triple encoder, which encodes an input set of triples into a vector of fixed dimensionality, and a Recurrent Neural Network (RNN) based on Gated Recurrent Units (GRUs) [12], which generates a sentence by conditioning the output on the encoded vector.
The model is displayed in Fig. 4. The ArticlePlaceholder provides a set of triples about the Wikidata item of Nigragorĝa (i.e.,
Such triple-level vector representations help compute a vector representation for the whole input set
Surface form tuples A summary such as “Nigragorĝa estas rimarkinda …” consists of regular words (e.g. “estas” and “rimarkinda”) and mentions of entities in the text (“
The ArticlePlaceholder provides our system with a set of triples about Floridia, whose either subject or object is related to the item of Floridia. Subsequently, our system summarizes the input set of triples as text. We train our model using the summary with the extended vocabulary (i.e. “Summary w/ Property placeholders”)
The ArticlePlaceholder provides our system with a set of triples about Floridia, whose either subject or object is related to the item of Floridia. Subsequently, our system summarizes the input set of triples as text. We train our model using the summary with the extended vocabulary (i.e. “Summary w/ Property placeholders”)
Property placeholders The model by Vougiouklis et al. [84], which was the starting point for the component presented here, leverages instance-type-related information from DBpedia in order to generate text that covers rare or unseen entities. We broadened its scope and adapted it to Wikidata without using external information from other knowledge bases. Some of the surface form tuple correspond to a rare entity, i.e., entities less frequently used and therefore potential out of vocabulary words in training. Given such a surface form tuple that is part of a triple matched to a sentence, we can leverage the relationship (or property) of this triple to use it as a special token to replace the rare surface form. The surface form tuple is replaced by the token of the property that matches the relationship. We refer to those placeholder tokens [15,78] as property placeholders. These tokens are appended to the target dictionary of the generated summaries. We used the distant-supervision assumption for relation extraction [61] for the property placeholders. After identifying the rare entities that participate in relations with the main entity of the article, they are replaced from the introductory sentence with their corresponding property placeholder tag (e.g.
Page statistics and number of unique words (vocabulary size) of Esperanto, Arabic and English Wikipedias in comparison with Wikidata. Retrieved 27 September 2017. Active users are registered users that have performed an action in the last 30 days
In order to train and evaluate our system, we created a dataset for text generation from knowledge base triples in two languages. We used two language versions of Wikipedia (we provide further details about how we prepared the summaries for the rest of the languages in Section 4.3) which differ in terms of size (see Table 2) and language support in Wikidata [39]. The dataset aligns Wikidata triples about an item with the first sentence of the Wikipedia article about that entity.
For each Wikipedia article, we extracted and tokenized the first sentence using a multilingual Regex tokenizer from the NLTK toolkit [8]. Afterwards, we retrieved the corresponding Wikidata item to the article and queried all triples where the item appeared as a subject or an object in the Wikidata truthy dump.3
To map the triples to the extracted Wikipedia sentence, we relied on keyword matching against labels from Wikidata from the corresponding language, due to the lack of reliable entity linking tools for lesser resourced languages. For example, in the Esperanto sentence “Floridia estas komunumo de Italio.” (English: “Floridia is a municipality of Italy.”) for the Wikipedia article of Floridia, we extract all triples which have the Wikidata entity of Floridia as either subject or object. Then, we match “Floridia” in the sentence to the Wikidata entity Floridia (Q490900)4
We use property placeholders (as described in the previous section) to avoid the lack of vocabulary typical for under-resourced languages. An example of a summary which is used for the training of the neural architecture is: “Floridia estas komunumo de
We followed a mixed-methods approach to investigate the three questions discussed in the introduction (Table 3). To answer
The raw data of the quantitative evaluation experiments can be found here:
Evaluation methodology
We evaluated the generated summaries against two baselines on their original counterparts from Wikipedia. We used a set of evaluation metrics for text generation BLEU 2, BLEU 3, BLEU 4, METEOR and ROUGEL. BLEU calculates n-gram precision multiplied by a brevity penalty, which penalizes short sentences to account for word recall. METEOR is based on the combination of uni-gram precision and recall, with recall weighted over precision. It extends BLEU by including stemming, synonyms and paraphrasing. ROUGEL is a recall-based metric which calculates the length of the most common subsequence between the generated summary and the reference.
Statistics of the two corpora. Average parameters are shown with standard deviations in brackets
Statistics of the two corpora. Average parameters are shown with standard deviations in brackets
Both the Arabic and Esperanto corpus are split into training, validation and test, with respective portions of
We replaced any rare entities in the text that participate in relations in the aligned triple set with the corresponding property placeholder of the upheld relations. We include all property placeholders that occur at least 20 times in each training dataset. Subsequently, the dictionaries of the Esperanto and Arabic summaries are expanded by 80 and 113 property placeholders respectively. In case the rare entity is not matched to any subject or object of the set of corresponding triples, it is replaced by the special
Baselines
Due to the variety of approaches for text generation, we demonstrate the effectiveness of our system by comparing it against two baselines of different nature.
RQ1 – Judgement-based evaluation
We defined quality in terms of text fluency and appropriateness, where fluency refers to how understandable and grammatically correct a text is, and appropriateness captures how well the text ‘feels like’ Wikipedia content. We asked two sets of participants from two different language Wikipedias to assess the same summary sentences on a scale according to these two metrics.
Participants were asked to fill out a survey combining fluency and appropriateness questions. An example for a question can be found in Fig. 5.

Example of a question to the editors about quality and appropriateness for Wikipedia of the generated summaries in Arabic. They see this page after the instructions are displayed. First, the user is asked to evaluate the quality from 0 to 6 (Question 69), then they are asked whether the sentence could be part of Wikipedia (Question 70). Translation (Question 69): Please evaluate the text quality (0–6). (The sentence to evaluate has a grey background.) How well written is this sentence? Translation (Question 69): Please evaluate whether you think this could be a sentence from Wikipedia. Do not use any external tools (e.g. Google or Wikipedia) to answer this question. (The sentence to evaluate has a grey background.) Could the previous sentence be part of Wikipedia?
Judgement-based evaluation: total number of participants (P), total number of sentences (S), number of participants who evaluated at least
Our study targets any speaker of Arabic and Esperanto who reads that particular Wikipedia, independent of their contributions to Wikipedia. We wanted to reach fluent speakers of each language who use Wikipedia and are familiar with it even if they do not edit it frequently. For Arabic, we reached out to Arabic speaking researchers from research groups working on Wikipedia-related topics. For Esperanto, as there are fewer speakers and they are harder to reach, we promoted the study on social media such as Twitter and Reddit6
We recruited a total of 54 participants (see Table 5). Coincidentally, 27 of them were from each language community.
Ethics
The research was approved by the Ethics Committee of the University of Southampton under ERGO Number 30452.

Screenshot of the reading task. The page is stored as a subpage of the author’s userpage on Wikidata, therefore the layout copies the original layout of any Wikipedia. The layout of the information displayed mirrors the ArticlePlaceholder setup. The participants sees the sentence to evaluate alongside information included from the Wikidata triples (such as the image and statements) in their native language (Arabic in this example).
For both languages, we created a corpus consisting of 60 summaries of which 30 are generated through our approach, 15 are from news, and 15 from Wikipedia sentences used to train the neural network model. For news in Esperanto, we chose introductory sentences of articles in the Esperanto version of Le Monde Diplomatique.8
Each participant was asked to assess the fluency of 60 sentences on a scale from 0 to 6 as follows:
No grammatical flaws and the content can be understood with ease
Comprehensible and grammatically correct summary that reads a bit artificial
Comprehensible summary with minor grammatical errors
Understandable, but has grammatical issues
Barely understandable summary with significant grammatical errors
Incomprehensible summary, but a general theme can be understood
Incomprehensible summary
For each sentence, we calculated the mean fluency given by all participants and then averaging over all summaries of each category.
To assess the appropriateness, participants were asked to assess whether the displayed sentence could be part of a Wikipedia article. We tested whether a reader can tell the difference from just one sentence whether a text is appropriate for Wikipedia, using the news sentences as a baseline. This gave us an insight into whether the text produced by the neural network “feels” like Wikipedia text. Participants were asked not to use any external tools for this task and had to give a binary answer. Similarly to fluency, average appropriateness is calculated by averaging the corresponding scores of each summary across all annotators.

Screenshot of the reading task as in Fig. 6, translated to English.
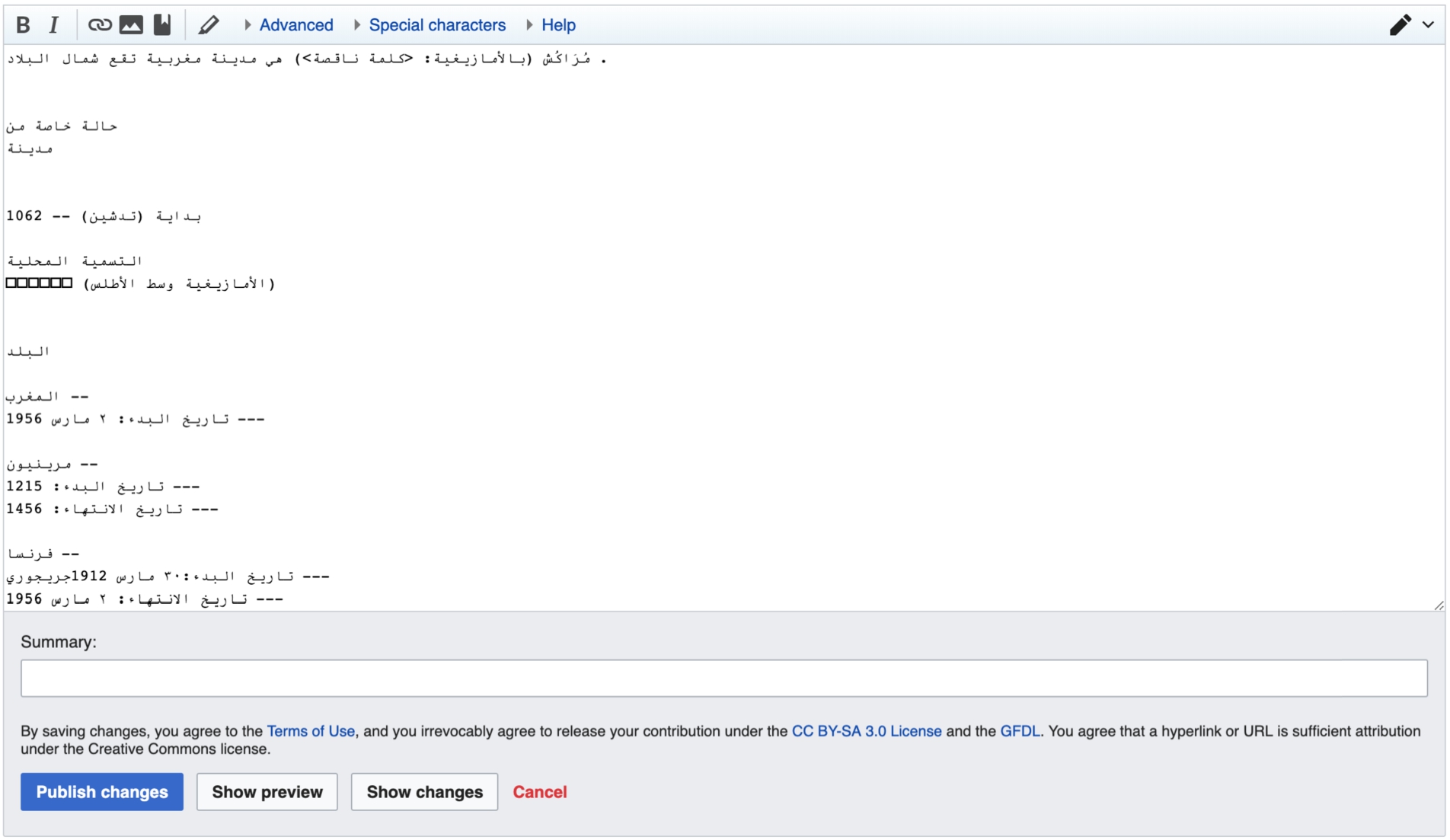
Screenshot of the editing task. The page is stored on a subpage of the author’s userpage on Wikidata, therefore the layout is equivalent as the current MediaWiki installations on Wikipedia. The participants sees the sentence, that they saw before in the reading task and the triples from Wikidata in their native language (Arabic in this example). The triples are manually added to the page by the researchers for easier interaction with the data by the editor. The data is the same data as in the reading task (Fig. 6).
We ran a series of semi-structured interviews with editors of six Wikipedias to get an in-depth understanding of their experience with reading and using the automatically generated text. Each interview started with general questions about the experience of the participant with Wikipedia and Wikidata, and their understanding of different aspects of these projects. The participants were then asked to open and read an ArticlePlaceholder page including text generated through the NLG algorithm as shown in Fig. 6, translated to English in Fig. 7. Finally, participants were asked to edit the content of a page, which contained the same information as the one they had to read earlier, but was displayed as plain text in the Wikipedia edit field. The editing field can be seen in Fig. 8.
Recruitment
The goal was to recruit a set of editors from different language backgrounds to have a comprehensive understanding of different language communities. We reached out to editors of different Wikipedia editor mailinglists10
Mailinglists contacted: wikiar-l@lists.wikimedia.org (Arabic), wikieo-l@lists.wikimedia.org (Esperanto), wikifa-l@lists.wikimedia.org (Persian), Wikidata mailinglist, Wikimedia Research Mailinglist.
We were in contact with 18 editors from different Wikipedia communities. We allowed all editors to participate but had to exclude editors who edit only on English Wikipedia (as it is outside our use-case) and editors who did not speak a sufficient level of English, which made conducting the interview impossible.
Our sample consists of 10 Wikipedia editors of different lesser resourced languages (measured in their number of articles compared to English Wikipedia). We originally conducted interviews with 11 editors from seven different language communities, but had to remove one interview with an editor of the Breton Wikipedia, as we were not able to generate the text for the reading and editing tasks because of a lack of training data.
Among the participants, 4 were from the Arabic Wikipedia and participated in the judgement-based evaluation from
While Swedish is officially the third largest Wikipedia in terms of number of articles,12
Number of Wikipedia articles, active editors on Wikipedia (editors that performed at least one edit in the last 30 days), and number of native speakers in million
The participants were experienced Wikipedia editors, with average tenures of 9.3 years in Wikipedia (between 3 and 14 years, median 10). All of them have contributed to at least one language besides their main language, and to the English Wikipedia. Further, 4 editors worked in at least two other languages beside their main language, while 2 editors were active in as many as 4 other languages. All participants knew about Wikidata, but had varying levels of experience with the project. 4 participants have been active on Wikidata for over 3 years (with 2 editors being involved since the start of the project in 2013), 5 editors had some experience with editing Wikidata and one editor had never edited Wikidata, but knew the project.
Overview of sentences and number of participants in each language

Table 7 displays the sentence used for the interviews in different languages. The Arabic sentence is generated by the network based on Wikidata triples, while the other sentences are synthetically created as described below.
The research was approved by the Ethics Committee of the University of Southampton under ERGO Number 44971 and written consent was obtained from each participant ahead of the interviews.
Data
For Arabic, we reused a summary sentence from the
We collected the introductory sentences for Marrakesh in the editors’ languages from Wikipedia. Those are the sentences the network would be trained on and tries to reproduce. We ran the keyword matcher that was used for the preparation of the dataset on the original Wikipedia sentences. It marked the words the network would pick up or would be replaced by property placeholders. Therefore, these words could not be removed.
As we were particularly interested in how editors would interact with the missing word tokens, the network can produce, we removed up to two words in each sentence: the word for the concept in its native language (e.g. Morocco in Arabic for non-Arabic sentences), as we saw that the network does the same, and the word for a concept that is not connected to the main entity of the sentence on Wikidata (e.g. Atlas Mountains, which is not linked to Marrakesh). An overview of all sentences used in the interviews can be found in Table 7.
Task
The interview started with an opening, explaining that the researcher will observe the reading and editing of the participant in their language Wikipedia. Until both reading and editing were finished, the participant did not know about the provenance of the text. To start the interview, we asked demographic questions about the participants’ contributions to Wikipedia and Wikidata, and to test their knowledge on the existing ArticlePlaceholder. Before reading, they were introduced to the idea of displaying content from Wikidata on Wikipedia. Then, they saw the mocked page of the ArticlePlaceholder as can be seen in Fig. 6 in Arabic. Each participant saw the page in their respective language. As the interviews were remote, the interviewer asked them to share the screen so they could point out details with the mouse cursor. Questions were asked to let them describe their impression of the page while they were looking at the page. Then, they were asked to open a new page, which can be seen in Fig. 8. Again, this page would contain information in their language. They were asked to edit the page and describe what they are doing at the same time freely. We asked them to not edit a whole page but only write two to three sentences as the introduction to a Wikipedia article on the topic with as much of the information given as needed. After the editing was finished, they were asked questions about their experience. (For the interview guideline, see Appendix A.) The interview followed the methodology of a semi-structured interview in which all participants were asked the same questions. Only then, the provenance of the sentences was revealed. Given this new information, we asked them about the predicted impact on their editing experience. Finally, we left them time to discuss open questions of the participants. The interviews were scheduled to last between 20 minutes to one hour.
Analysing the interviews
We interviewed a total of 11 editors of seven different language Wikipedias. The interviews took place in September 2018. We used thematic analysis to evaluate the results of the interviews. The interviews were coded by two researchers independently, in the form of inductive coding based on the research questions. After comparing and merging all themes, both researchers independently applied these common themes on the text again.
Editors’ reuse metric
Editors were asked to complete a writing task. We assessed how they used the automatically generated summary sentences in their work by measuring the amount of text reuse. We based the assessment on the editors’ resultant summaries after the interviews were finished.
To quantify the amount of reuse in text we use the Greedy String-Tiling (GST) algorithm [89]. GST is a substring matching algorithm that computes the degree of reuse or copy from a source text and a dependent one. GST is able to deal with cases when a whole block is transposed, unlike other algorithms such as the Levenshtein distance, which calculates it as a sequence of single insertions or deletions rather than a single block move. Adler and de Alfaro [2] introduce the concept of Edit Distance in the context of vandalism detection on Wikipedia. They measure the trustworthiness of a piece of text by measuring how much it has been changed over time. However, their algorithm punishes the copy of the text, as they measure every edit to the original text. In comparison, we want to measure how much of the text is reused, therefore GST is appropriate for the task at hand.
Given a generated summary
Results
RQ1 – Metric-based corpus evaluation
As noted earlier, the evaluation used standard metrics in this space and data from the Arabic and Esperanto Wikipedias. We compared against five baselines, one in machine translation (
Automatic evaluation of our model against all other baselines using BLEU 2–4, ROUGE and METEOR for both Arabic and Esperanto validation and test set
Automatic evaluation of our model against all other baselines using BLEU 2–4, ROUGE and METEOR for both Arabic and Esperanto validation and test set
The tests also hinted at the limitations of using machine translation for this task. We attributed this result to the different writing styles across language versions of Wikipedia. The data confirms that generating language from labels of conceptual structures such as Wikidata is a much more suitable approach.
Around
The introduction of the property placeholders to our encoder-decoder architecture enhances our performance further by 0.61–1.10 BLEU (using BLEU 4).
In general, our property placeholder mechanism benefits the performance of all the competitive systems.

A box plot showing the distribution of BLEU 4 scores of all systems for each category of generated summaries.
To investigate how well different models can generalise across multiple domains, we categorise each generated summary into one of 50 categories according to its main entity instance type (e.g. village, company, football player). We examine the distribution of BLEU-4 scores per category to measure how well the model generalises across domains (Fig. 9).
We show that i) the high performance of our system is not skewed towards some domains at the expense of others, and that ii) our model has a good generalisation across domains – better than any other baseline.
For instance, the over performance of TPext is limited to a small number of domains – plotted as the few outliers in Fig. 9 for TPext –, despite its performance being much lower on average for all the domains.
Despite the fact that TPext achieves the highest recorded performance in a few domains (i.e. TPext outliers in Fig. 9), its performance is much lower on average for all the domains. The valuable generalisation of our model across domains is mainly due to the language model in the decoder layer of our model, which is more flexible than rigid templates and can adapt easier to multiple domains. Despite the fact that the Kneser–Ney template-based baseline (KNext) has exhibited competitive performance in a single-domain context [51], it is failing to generalise in our multi-domain text generation scenario. Unlike our approach, KNext does not incorporate the input triples directly for generating the output summary, but rather only uses them to replace the special tokens after a summary has been generated. This might yield acceptable performance in a single domain, where most of the summaries share a very similar pattern. However, it struggles to generate a different pattern for each input set of triples in multiple domain summary generation.
Results for fluency and appropriateness
Fluency
As shown in Table 9, overall, the quality of the generated text is high (4.7 points out of 6 in average in Arabic and 4.5 in Esperanto). In Arabic,
Appropriateness
The results for appropriateness are summarised in Table 9. A majority of the snippets were considered to be part of Wikipedia (
Our model was able to generate text that is not only accurate from a writing point of view, but in a high number of cases, felt like Wikipedia and could blend in with other Wikipedia content.
RQ2 task-based evaluation
As part of our interview study, we asked editors to read an ArticlePlaceholder page with included NLG text and asked them to comment on a series of issues. We grouped their answers into several general themes around: their use of the snippets, their opinions on text provenance, the ideal length of the text, the importance of the text for the ArticlePlaceholder, and limitations of the algorithm.
Use The participants appreciated the summary sentences: “I think it would be a great opportunity for general Wikipedia readers to help improve their experience, while reading Wikipedia” (P7).
Some of them noted that the summary sentence on the ArticlePlaceholder page gave them a useful overview and quick introduction to the topic of the page, particularly for people trained in one language or non-English speakers: “I think that if I saw such an article in Ukrainian, I would probably then go to English anyway, because I know English, but I think it would be a huge help for those who don’t” (P10).
Provenance As part of the reading task, we asked the editors what they believed was the provenance of the information displayed on the page. This gave us more context to the promising fluency and appropriateness scores achieved in the quantitative study. The editors made general comments about the page and tended to assume that the generated sentence was from other Wikipedia language versions: [The generated sentence was] “taken from Wikipedia, from Wikipedia projects in different languages.” (P1)
Editors more familiar with Wikidata suggested the information might be derived from Wikidata’s descriptions: “it should be possible to be imported from Wikidata” (P9).
Only one editor could spot a difference in the generated sentence (text) and regular Wikidata triples: “I think it’s taken from the outside sources, the text, the first text here, anything else I don’t think it has been taken from anywhere else, as far as I can tell” (P2).
Overall, the answers supported our assumption that NLG, trained on Wikidata labelled triples, could be naturally added to Wikipedia pages without changing the reading experience. In the same time, the task revealed questions around algorithmic complexity and capturing provenance. Both are relevant to ensure transparency and accountability and help flag quality issues.
Length We were interested in understanding how we could iterate over the NLG capabilities of our system to produce text of appropriate length. While the model generated just one sentence, the editors thought it to be a helpful starting point: “Actually I would feel pretty good learning the basics. What I saw is the basic information of the city so it will be fine, almost like a stub” (P4).
While generating larger pieces of text could arguably be more useful, reducing the need for manual editing even further, the fact that the placeholder page contained just one sentence made it clear to the editors that the page still requires work. In this context, another editor referred to a ‘magic threshold’ for an automatically generated text to be useful (see also Section 5.4). Their expectations for an NLG output were clear: “So the definition has to be concise, a little bit not very long, very complex, to understand the topic, is it the right topic you’re looking for or”. (P1)
We noted that whatever the length of the snippet, it needs to match reading practice. Editors tend to skim articles rather than reading them in detail: “[…] most of the time I don’t read the whole article, it’s just some specific, for instance a news piece or some detail about I don’t know, a program in languages or something like that and after that, I just try to do something with the knowledge that I learned, in order for me to acquire it and remember it” (P6) “I’m getting more and more convinced that I just skim” (P1) “I should also mention that very often, I don’t read the whole article and very often I just search for a particular fact” (P3) “I can’t say that I read a lot or reading articles from the beginning to the end, mostly it’s getting, reading through the topic, “Oh, what this weird word means,” or something” (P10)
When engaging with content, people commonly go straight to the part of the page that contains what they need. If they are after an introduction to a topic, having a summary at the top of the page, for example in the form of an automatically generated summary sentence, could make a real difference in matching their information needs.
Importance When reading the ArticlePlaceholder page, people looked first at our text: “The introduction of this line, that’s the first thing I see” (P4).
This is their way to confirm that they landed on the right page and if the topic matches what they were looking for: “Yeah, it does help because that’s how you know if you’re on the right article and not a synonym or some other article” (P1).
This makes the text critical for the engagement with the ArticlePlaceholder page, where most of the information is expressed as Wikidata triples. Natural language can add context to structured data representations: “Well that first line was, it’s really important because I would say that it [the ArticlePlaceholder page] doesn’t really make a lot of sense [without it] … it’s just like a soup of words, like there should be one string of words next to each other so this all ties in the thing together. This is the most important thing I would say.” (P8)
“the language is specific, it says that this is a language that is spoken mainly in Morocco and Algeria, the language, I don’t even know the symbols for the alphabets […] I don’t know if this is correct, I don’t know the language itself so for me, it will go unnoticed. But if somebody from that area who knows anything about this language, I think they might think twice” (P8).
RQ3 – Task-based evaluation
Our third research questions focused on how people work with automatically generated text. The overall aim of adding NLG to the ArticlePlaceholder is to help Wikipedia editors bootstrap missing articles without disrupting their editing practices.
As noted earlier, we carried out a task-based evaluation, in which the participants were presented with an ArticlePlaceholder page that included the summary sentence and triples from Wikidata relevant to the topic. We carried out a quantitative analysis of the editing activities via the GST score, as well as a qualitative, thematic analysis of the interviews, in which the participants explained how they changed the text. In the following we will first present the GST scores, and then discuss the themes that emerged from the interviews.
Number of snippets in each category of reuse. A generated snippet (top) and its edited version (bottom). Solid lines represent reused tiles, while dashed lines represent overlapping sub-sequences not contributing to the
. The first two examples are created in the studies, the last one (ND) is from a previous experiment. a list of all created sentences and their translations to English can be found in Appendix B

Number of snippets in each category of reuse. A generated snippet (top) and its edited version (bottom). Solid lines represent reused tiles, while dashed lines represent overlapping sub-sequences not contributing to the
Reusing the text As shown in Table 10, the snippets are heavily used and all participants reused them at least partially. 8 of them were wholly derived (
We manually inspected all edits and compared them to the ‘originals’ – as explained in Section 4, we had 10 participants from 6 language communities, who edited 6 language versions of the same article. In the 8 cases where editors reused more of the text, they tended to copy it with minimal modifications, as illustrated in sequences A and B in Table 10. Three editors did not change the summary sentence at all (including the special token), but only added to it based on the triples shown on the ArticlePlaceholder page.
One of the common things that hampers the full reusability are
Editing experience While GST scores gave us an idea about the extent to which the automatically generated text is reused by the participants, the interviews helped us understand how they experienced the text. Overall, the summary sentences were widely praised as helpful, especially for newcomers: “Especially for new editors, they can be a good starting help: “I think it would be good at least to make it easier for me as a reader to build on the page if I’m a new volunteer or a first time edit, it would make adding to the entry more appealing (…) I think adding a new article is a barrier. For me I started only very few articles, I always built on other contribution. So I think adding a new page is a barrier that Wikidata can remove. I think that would be the main difference.” (P4)
All participants were experienced editors. Just like in the reading task, they thought having a shorter text to start editing had advantages: “It wasn’t too distracting because this was so short. If it was longer, it would be (…) There is this magical threshold up to which you think that it would be easier to write from scratch, it wasn’t here there.” (P10)
The length of the text is also related to the ability of the editors to work around and fix errors, such as the “So I have this first sentence, which is a pretty good sentence and then this is missing in Hebrew and well, since it’s missing and I do have this name here, I guess I could quickly copy it here so now it’s not missing any longer.” (P3)
The same participant checked the Wikidata triples listed on the same ArticlePlaceholder page to find the missing information, which was not available there either, and then looked it up on a different language version of Wikipedia. They commented: “This first sentence at the top, was it was written, it was great except the pieces of information were missing, I could quite easily find them, I opened the different Wikipedia article and I pasted them, that was really nice” (P3).
Other participants mentioned a similar approach, though some decided to delete the entire snippet because of the “I know it, I have it here, I have the name in Arabic, so I can just copy and paste it here.” (P10) “[deleted the whole sentence] mainly because of the missing tokens, otherwise it would have been fine” (P5)
One participant commented at length on the presence of the tokens: “I didn’t know what rare [is], I thought it was some kind of tag used in machine learning because I’ve seen other tags before but it didn’t make any sense because I didn’t know what use I had, how can I use it, what’s the use of it and I would say it would be distracting, if it’s like in other parts of the page here. So that would require you to understand first what rare does there, what is it for and that would take away the interest I guess, or the attention span so it would be better just to, I don’t know if it’s for instance, if the word is not, it’s rare, this part right here which is, it shouldn’t be there, it should be more, it would be better if it’s like the input box or something”. (P1)
Overall, the editing task and the follow-up interviews showed that the summary sentences were a useful starting point for editing the page. Missing information, presented in the form of
Our first research question focuses on how well an NLG algorithm can generate summaries from the Wikipedia reader’s perspective. In most of the cases, the text is considered to be from the Wikimedia environment. Readers do not clearly differentiate between the generated summary sentence and an original Wikipedia sentence. While this indicates the high quality of the generated textual content, it is problematic with respect to trust in Wikipedia. Trust in Wikipedia and how humans evaluate trustworthiness of a certain article has been investigated using both quantitative and qualitative methods. Adler et al. [1] and Adler and de Alfaro [2] develop a quantitative framework based on Wikipedia’s history. Lucassen and Schraagen [56] use a qualitative methodology to code readers’ opinions on the aspects that indicate the trustworthiness of an article. However, none of these approaches take the automatic creation of text by non-human algorithms into account. A high quality Wikipedia summary, which is not distinguishable from a human-generated one, can be a double-edged sword. While conducting the interviews, we realized that the Arabic generated summary has a factual mistake. We could show in previous work [84] that those factual mistakes are relatively seldom, however they are a known drawback of neural text generation. In our case, the Arabic sentence stated that Marrakesh was located in the north, while it is actually in the center of the country. One of the participants lives in Marrakesh. Curiously, they did not realize this mistake, even while translating the sentence to the interviewee: “Yes, so I think, so we have here country, Moroccan city in the north, I would say established and in year (…)” (P1) “This sentence was so well written that I didn’t even bother to verify if it’s actually a desert city” (P3)
Supporting the previous results from the readers, editors have also a positive perception of the summaries. It is the first thing they read when they arrive at a page and it helps them to quickly verify that the page is about the topic they are looking for.
When creating the summaries, we assumed their relatively short length might be a point for improvement from an editors’ perspective. In particular, as research suggests that the length of an article indicates its quality – basically the longer, the better [9]. From the interviews with editors, we found that they mostly skim articles when reading them. This seems to be the more natural way of browsing the information on an article and is supported by the short summary, giving an overview on the topic.
All editors we worked with are part of the multilingual Wikipedia community, editing in at least two Wikipedias. Hale [26,27] highlight that users of this community are particularly active compared to their monolingual counterparts and confident in editing across different languages. However, taking potential newcomers into account, they suggest that the ArticlePlaceholder might be helpful to lower the barrier of starting to edit. Recruiting more editors has been a long-standing objective, with initiatives such as the Tea House [62] aiming at welcoming and comforting new editors; Wikipedia Adventure employs a similar approach using a tool with gamification features [63]. The ArticlePlaceholder, and in particular the provided summaries in natural language, can have an impact on how people start editing.
In comparison to Wikipedia Adventure, the readers are exposed to the ArticlePlaceholder pages and, thus, it could lower their reservation to edit by offering a more natural start of editing.
Lastly, we asked the research question how editors use the textual summaries in their workflow. Generally, we can show that the text is highly reused. One of the editors mentions a magic threshold, that makes the summary acceptable as a starting point for editing. This seems similar to post-editing in machine translation (or rather monolingual machine translation [33], where a user only speaks the target or source language). Translators have been found to oppose machine translation and post-editing as they perceive it as more time consuming and restricting with respect to their freedom in the translation (e.g. sentence structure) [49]. Nonetheless, it has been shown that a different interface can not only lead to reduced time and enhanced quality, but also convinces a user to believe in the improved quality of the machine translation [25]. This underlines the importance of the right integration with machine-generated sentences, as we aim for in the ArticlePlaceholder.
The core of this work is to understand the perception of a community, such as Wikipedians, of the integration of a state-of-the-art machine learning technique for NLG in their platform. We can show that an integration can work and be supported. This finding aligns with other projects already deployed on Wikipedia. For instance, bots (short for robots) that monitor Wikipedia, have become a trusted tool for vandalism fighting [23]; so much that they can even revert edits made by humans if they believe them to be malicious. The cooperative work between humans and machines on Wikipedia has been also theorized in machine translation. Alegria et al. [3] argue for the integration of machine translation in Wikipedia, that learns from the post-editing of the editors. Such a human-in-the-loop approach is also applicable to our NLG work, where a algorithm could learn from the humans’ contributions.
There is a need of investigating this direction further, as NLG algorithms will not achieve the same quality as humans. Especially in a low resource setting, as the one observed in this work, human support is needed. However, automated tools can be a great way of allocating the limited human resources to the tasks that are mostly needed. Post-editing the summaries can serve a purely data-driven approach such as ours with additional data that can be used to further improve the quality of the automatically generated content. To make such an approach feasible for the ArticlePlaceholder, we need an interface that encourages the editing of the summaries. The less effort this editing requires, the more we can ensure an easy collaboration of human and machine.
Limitations
We interviewed ten editors having different levels of Wikipedia experience. As all editors are already Wikipedia editors, the conclusions we can draw for new editors are limited. We focus on experienced editors, as we expect them to be the first editors to adapt the ArticlePlaceholder in their workflow. Typically, new editors will follow the existing guidelines and standards of the experienced editors, therefore, the focus on experienced editors will give us an understanding of how the editors will accept and interact with the new tool. Further, it is difficult to sample from new editors, as there is a variety of factors that can make a contributor develop into a long-term editor or not [48].
The distribution of languages favours Arabic, as the community was most responsive. This is can be assumed to be due to previous collaborations. While we cover different languages, it is only a small part of the different language communities that Wikipedia covers in total. Most studies of Wikipedia editors currently focus on English Wikipedia [65]. Even the few studies that observe multiple language Wikipedia editors do not include the span of insights from different languages that we provide in this study. In our study we treat the different editors as members of a unified community of Wikipedia underserved languages. This is supported by the fact that their answers and themes were consistent across different languages. Therefore, adding more editors of the same languages would not have brought a benefit.
We aimed our evaluation at two populations: readers and editors. While the main focus was on the editors and their interaction with the new information, we wanted to include the readers’ perspective. In the readers evaluation we focus on the quality of text (in terms of fluency and appropriateness), as this will be the most influential factor for their experience on Wikipedia. Readers, while usually overseen, are an important part of the Wikipedia community [52]. Together, those two groups form the Wikipedia community as new editors are recruited from the existing pool of readers and readers contribute in essential ways to Wikipedia as shown by Antin and Cheshire [5].
The sentences the editors worked on are synthesized, i.e. not automatically generated but created by the authors of this study. An exception is the Arabic sentence, which was generated by the approach described in Section 4. While those synthesized sentences were not created by natural language generation, they were created and discussed with other researchers in the field. Our goal was to explore the usability and limitations of recent data-driven approaches w.r.t. Wikipedia’s editing community and the extent to which such approaches can effectively support their work. Limitations that currently prohibit the wide usability of these approaches are mostly associated with hallucinations and manifestation of rare tokens, and remain relevant to even the most recent systems. We therefore focused on the most common problem in text generative tasks similar to ours: the
Conclusion
We conducted a quantitative study with members of the Arabic and Esperanto Wikipedia community and semi-structured interviews with members of six different Wikipedia communities to understand the communities understanding and acceptance of generated text in Wikipedia. To understand the impact of automatically generated text for a community such as the Wikipedia editors, we surveyed their perception of generated summaries in terms of fluency and appropriatness. To deepen this understanding, we conducted 10 semi-structured interviews with experienced Wikipedia editors from 6 different language communities and measured their reuse of the original summaries.
The addition of the summaries seems to be natural for readers: We could show that Wikipedia editors rank our text close to the expected quality standards of Wikipedia, and are likely to consider the generated text as part of Wikipedia. The language the neural network produces integrates well with the existing content of Wikipedia, and readers appreciate the summary on the ArticlePlaceholder as it is the most helpful element on the page to them.
We could emphasize that editors would assume the text was part of Wikipedia and that the summary improves the ArticlePlaceholder page fundamentally. Particularly the summary being short supported the usual workflow of skimming the page for information needed. The missing word token, that we included to gain an understanding how users interact with faulty produced text, did not hinder the reading experience nor the editing experience. Editors are likely to reuse a large portion of the generated summaries. Additionally, participants mentioned that the summary can be a good starting point for new editors.
Footnotes
Acknowledgements
This research was supported by the EPSRC-funded project Data Stories under grant agreement number EP/P025676/1; and DSTL under grant number DSTLX-1000094186. We would like to express our gratitude to the Wikipedia communities involved in this study for embracing our research and particularly to the participants of the interviews. Hady Elsahar has been an essential part of this work, discussing the ideas with us from the beginning. We thank him for his support and collaboration on this and previous works on the topic of ArticlePlaceholder.
Guideline for the semi-structured interview
Opening/Introduction I am Lucie, a researcher at the University of Southampton and I work on this project as part of my PhD research, collaborating with Pavlos Vougiouklis and Elena Simperl. Before I start about the content, I want to ask for your consent to participate in this study, according to the Ethics Committee of the University of Southampton. We will treat your data confidentiality and it will only be stored on the password-protected computer of the researchers. You have the option to withdraw, but we will have to ask you to do that up to 2 weeks after today. We will use the results anonymized to provide insights into the editing of Wikipedia editors and publish the results of the study to a research venue. This experiment will observe your interaction with text and how you edit Wikipedia. Do you agree to participate in this study? Demographic Questions Do you read Wikipedia? In which language do you usually read Wikipedia? Do you search topics on Wikipedia or search engines (google)? If you can’t find a topic on Wikipedia, what do you do? Do you edit Wikipedia? What is your Wikimedia/Wikipedia username? Which Wikipedia do you mainly contribute to? How long have you contributed to Wikipedia? When you edit, what topics do you choose? Topics you are interested in or topics that you think that is needed? How do you decide, what is interesting/needed? How do you usually start editing? Where do you look up information? (for this topic specifically, in general) Do you draft points and then write text or write the text first? Have you heard of Wikidata? What is Wikidata? What is the relationship between Wikidata and Wikipedia? Have you edited it before? How long are you contributing to Wikidata? Description of AP This project is base on the ArticlePlaceholder. The idea is if there is no information about a topic, a user can search on Wikipedia and still get the information on the topic, that is available on Wikidata. We do not create stub articles, everything is displayed dynamically. Have you heard about the ArticlePlaceholder? Reading the layout of the AP Is the topic familiar to you? If so, how? If you look at the page, what information do you look at first? (If you want you can point it out with your mouse) What information do you look at after that? (In which order?) What part do you think is taken directly from Wikidata and what is from other sources? Which sources? What information is particularly helpful on this page? What do you think of the text in addition to the rest of the information? After editing sentence Where do you start in this case? What information do you miss when editing? Would you prefer to have more or less information given? What type of information? Would you prefer a longer text, even if it has a similar amount of missing information as this one? Closing Questions What we do in this project is to generate an introductory sentence from Wikidata triples. We train on this language Wikipedia. What impact do you think this project can have for you as a reader? Do you believe this project will have an impact on your editing? What does it change? Any questions from the interviewee?
Sentences created by the editors in the interviews and English translations