
Abstract
Company data, ranging from basic company information such as company name(s) and incorporation date to complex balance sheets and personal data about directors and shareholders, are the foundation that many data value chains depend upon in various sectors (e.g., business information, marketing and sales, etc.). Company data becomes a valuable asset when data is collected and integrated from a variety of sources, both authoritative (e.g., national business registers) and non-authoritative (e.g., company websites). Company data integration is however a difficult task primarily due to the heterogeneity and complexity of company data, and the lack of generally agreed upon semantic descriptions of the concepts in this domain. In this article, we introduce the euBusinessGraph ontology as a lightweight mechanism for harmonising company data for the purpose of aggregating, linking, provisioning and analysing basic company data. The article provides an overview of the related work, ontology scope, ontology development process, explanations of core concepts and relationships, and the implementation of the ontology. Furthermore, we present scenarios where the ontology was used, among others, for publishing company data (business knowledge graph) and for comparing data from various company data providers. The euBusinessGraph ontology serves as an asset not only for enabling various tasks related to company data but also on which various extensions can be built upon.
Introduction
Corporate information, including basic company information (e.g., name(s), incorporation data, registered addresses, ownership and related entities, etc.), financials (e.g., balance sheets, ratings, etc.) as well as contextual data (e.g., cadastral data on corporate properties, geo data, personal data about directors and shareholders, public tenders data, etc.) are the foundation that many data value chains depend upon in different sectors. The most evident examples of sectors are the business information sector, the marketing and sales sector and the business publishing industry. At the same time, the use of company data is extremely significant in many other business sectors and societal activities including transparency and accountability [20].
Recently, a number of initiatives have been established to harmonise and increase the interoperability of corporate and financial data across national borders, including public initiatives such as the Global Legal Entity Identification System – GLEIS,1
Less than 1.6M companies worldwide were assigned a Legal Entity Identifier (LEI) number as of December 2019 (
As a result, collecting and aggregating information about a business entity from several public sources (official and non-official ones, such as public tender registries, press mentions of companies and related entities, cadastral records, etc.), and especially across borders and languages is a tedious and very expensive task which renders many potential business models non-feasible. As a step in addressing this challenge, governments and other public bodies are increasingly publishing open data about firmographics and contextual databases, which reference companies. For example, the UK, Norway, France, and Denmark make the public records about companies available as open data, and other countries have different degrees of openness for their company registries.8
In this article, we follow the established approach for harmonizing and integrating data based on ontologies (e.g., [5,16]). In particular, we develop an ontology – the euBusinessGraph ontology – for harmonising and integrating basic company information.12
By basic we mean company information that is usually covered in Trade Registers, but excluding change tracking (e.g., when a headquarters address changes) and documents (e.g., financial returns) due to the typical unavailability of such data. Examples of non-basic information can include transactions (investments, M&A, IPO), company relations (parent/subsidiary, branch, competitor, supplier/client, joint venture), etc.
The remainder of the article is organised as follows. Section 2 provides an overview of related work and ontologies relevant to company-related data. Section 3 describes the euBusinessGraph ontology development process, covering the scope, requirements, and the development approach. Section 4 gives an overview of the core concepts and relations in the euBusinessGraph ontology, together with details about the realization of the ontology. Section 5 provides examples of the usage of the ontology. Finally, Section 6 concludes this article and outlines possible future work.
Several ontologies and data models were described in the literature and have relevance to capturing the structure and complexity of company-related data. In what follows, we look specifically at works dealing with basic information about companies, covering organizational structures of companies, economic classifications of companies, company identification schemes, and locations of companies.13
An overview of all ontologies and vocabularies that were reused in the euBusinessGraph ontology (including those not specifically dealing with basic company information) are discussed in Section 4 (with a summary provided in Table 1).
The ontologies and vocabularies discussed in this section either insufficiently cover basic company information or are too complex due to many ontological commitments. Nevertheless, as we shall see below, relevant ontologies and data models were partly re-used and/or provided inspiration in the development of the euBusinessGraph ontology.
The W3C Organization Ontology (ORG) [29] is a W3C recommendation since 2014. It aims to capture information about organizations (companies and institutions), including governmental organizations. It primarily captures organizational structure (e.g., sub-organizations and classification), reporting structure (e.g., roles and posts), location information (e.g., sites and addresses), and organizational history (e.g., merger and renaming). ORG is highly generic and designed as a core ontology, capturing general concepts and encouraging extensions for specific domains. It has been reused by other ontologies such as PPROC [25] in the procurement domain.
The e-Government Core Vocabularies [32] were developed in order to provide a minimum level of semantic interoperability for e-Government systems as part of the SEMIC (Joinup) community14
The Popolo Project defines data interchange formats and data models in the context of the Open Government initiative.17
The Application Profile of the Organization Ontology (ORG-AP-OP) was developed by the Publications Office of the European Union and supports its Whoiswho service.18
The Schema.org initiative [17] is spearheaded by the big four search engines, Google, Yahoo, Bing and Yandex, and is a collaborative effort to create, maintain, and promote schemas for structured data on the Internet. It is highly reusable since it makes few ontological commitments in order to cater to a truly global audience of millions of Web sites. Schema.org considers schemas as a set of types arranged in a hierarchy and associated with a set of properties. The core vocabulary is currently composed of 614 types and 902 properties. The “Organization” concept is among one of the commonly used types (among with, e.g., person, product, event) and models businesses (e.g., type, contact, etc.) and marketing aspects (e.g., logo, social profile, etc.).
The Financial Industry Business Ontology (FIBO) [7] is a joint effort of the Enterprise Data Management Council (EDMC) and the Object Management Group (OMG), aiming to go beyond a mere dictionary and capture the semantics of the business domain from a financial perspective. FIBO formalizes entities such as companies, directors, ownership and control relations, business registers, monetary amounts, debts, obligations, contracts, and financial instruments. It is composed of a large number of smaller ontologies, with a modular perspective, each of which models a specific financial area [24]. The result is a large and very complex set of ontologies for the financial industry consisting of 11 core domains and 49 modules made available in more than 400 ontology files.
There are a number of classification vocabularies to specify the kind of economic activity such as International Standard Industrial Classification of All Economic Activities (ISIC) [11], which is a United Nations industry classification system, and European Commission’s NACE [14], which is preferred in the context of European interoperability.
The Entity Legal Forms Code List19
The Global Legal Entity Identifier Foundation (GLEI) established a registration structure to issue Legal Entity Identifiers (LEI) to legal entities participating in financial transactions. The LEI structure is standardized as ISO 17442 [19]. LEI includes two code lists that are relevant in the context of basic company information, that is registration authorities list including 651 national official registers with their descriptions such as authority code, jurisdiction, and website; and, entity legal form code resolving variant names for each valid legal form within a jurisdiction to a single code per legal form.
The Business Registers Interconnection System (BRIS) interconnects business registers across Europe and provides a single (though limited) company search form.21
With respect to capturing various forms of locations for companies, several initiatives are relevant. Eurostat has established a unified hierarchy of regions across the EU, EFTA and Candidate Countries. It consists of a nomenclature of Territorial Units for Statistics (NUTS) [15] and Local Administrative Units (LAU).22
The EU ISA2 Location Core Vocabulary [13] aims at describing any place in terms of its name, address or geometry through a minimum set of classes and properties. It integrates with the Business (i.e., RegOrg) and Person Core Vocabularies of ISA2.
Finally, GeoNames24
In addition to well known initiatives such as FOAF,25
ADMS ontology [10] describes various interoperability assets, including XML schemas, generic data models, code lists, taxonomies, dictionaries, vocabularies. ADMS is relevant in our context since we aggregate free company datasets from various company data providers.
Vocabulary of Interlinked Datasets (VoID) [1] provides terms and patterns for describing RDF datasets and could be used in a variety of situations such as data discovery, cataloging and archiving of datasets.
Simple Knowledge Organization System (SKOS) [4] offers a vocabulary for expressing the basic structure and content of concept schemes. This is essential for example for company classification (e.g., type and status).
The IANA language code registry28
Person Core Vocabulary30
The Simple Event Model ontology (SEM) [41] is created for modelling events in a variety of domains and it is relevant for capturing different events in the lifetime of a company.
In order to design the euBusinessGraph ontology, we applied common techniques recommended by well established ontology development methods [8,26]. We used a bottom-up approach by identifying the scope and user group of the ontology, requirements, and ontological and non-ontological resources (some of which are referred to in Section 2).
One of the main resources used during the ontology development was company data that was provided by four company data providers and that needed to be harmonized before further processing. The data providers were OpenCorporates,31
OpenCorporates provides core company data on over 180 million entities, obtained from more than 130 company registers around the world. The data is sourced only from official public sources and full provenance is provided. The depth of data varies from jurisdiction to jurisdiction, sometimes including officers, industry codes, even occasionally shareholders and ultimate beneficial owners.
SpazioDati integrates detailed up-to-date company and contact information on legal entities in Italy and the United Kingdom. Their dataset contains basic firmographics about more than 11 million business entities in both jurisdictions and information about 13 million directors and managers. Data comes from both authoritative sources (e.g., Registro imprese, the Italian Register of Companies and all the regional chambers of commerce) and non-authoritative sources (e.g., company websites, social media accounts, and business-centric news websites).
Brønnøysund Register Centre (Brønnøysundregistrene) maintains the Norwegian Central Coordinating Register for Legal Entities (Enhetsregisteret)35
Ontotext extracted data from the Bulgarian Trade Register. This register provides a centralized database whose purpose is to facilitate the start-up of businesses in Bulgaria, as well as to curb corruption practices.
These data sources were analyzed to determine the scope and requirements of the ontology. They cover official company information in Bulgaria, Norway, Italy and the United Kingdom, with additional unofficial information for the later two jurisdictions.
After an analysis of the data provided by the different providers and the information available therein, we identified the major concerns that the ontology should address. Figure 1 provides an overview of the different types of information found during the data analysis, organized according to the type of entity being described (Registered Organization and Officer). In addition, the ontology needed to cover the description of dataset offerings by individual data providers (Dataset) and the description of identifier systems used to uniquely identify companies (Identifier System).

Overview of the scope of the euBusinessGraph ontology.
We identified target domains for our ontology, which primarily map to the business information sector, the marketing and sales sector, and the business publishing industry interested in new innovative data-driven products and services. Users working with data in these domains will benefit from a common representation that covers the types of information contributed by the different data providers. This common representation will also ease the task of data providers and aggregators who need to validate, transform and clean the data by providing a single ontology to target. The fact that there is a single ontology that provides a common representation will also benefit service developers who need to reference company information to implement their services. To this end, the ontology has to capture the properties of the different identifiers that can be used to link the different entities being represented, providing machine readable descriptions for the identifier systems in use, including support for describing rules for validation and normalization of company and company-related identifiers.
Taking into account the needs of the intended users of the ontology and after the analysis of the data provided, we elicited the ontology requirements following the Neon methodology [39] for requirements specification, and considering two kinds of requirements.
Firstly, we consider functional requirements dealing with the scope of data and groups of competency questions that the data should be able to answer. The functional requirements include:
Capture the concept of a company, representing the different types or legal forms that companies can take, their jurisdictions and registration information, legal and alternative names, official and secondary locations, prevalent economic activity, web keywords and social media accounts, among others;
Capture the concept of company officers, their roles and officerships, including temporal information to be able to represent these officerships through time;
Provide machine-readable descriptions of the properties of the different systems of identifiers available to external applications and services, so that algorithms can be developed to select and prioritise the most suitable identifiers for a task (this includes provisioning of validation and cleaning rules for identifiers to help their usage); and
Provide data advertising and extensibility features, including description of additional properties of company and company-related entities that are not covered by the model but are available from company data providers as unique or differentiating features.

Phases of the euBusinessGraph ontology development process.
Examples of groups of competency questions that the data should be able to answer include:
What companies are relevant to the search keyword “Opel”?
What are the jurisdictions and legal types of companies matching that search keyword?
What companies match an industry classification such as “Automotive companies”?
What are alternative names for the company “Opel Group GmbH”?
What jurisdiction does the company “Opel Group GmbH” belong to?
What is the official address of “Opel Group GmbH”?
Does the company “Opel Group GmbH” have other locations (additional addresses)?
What companies are located in “Rüsselsheim am Mein”?
What are the economic activities registered for the company “Opel Group GmbH”?
Is the company “Opel Group GmbH” publicly traded? Is it a startup? Is it government-owned?
How many companies in a given industry classification are available in each country, NUTS statistical region, province, county, and city?
What are the points of contact (phone, email) of “Opel Group GmbH”?
What is the online presence (web, email, blog) of “Opel Group GmbH”?
What is the Wikipedia page of the company “Opel Group GmbH”?
Who are the officers of “Opel Group GmbH” (including historical timeline)?
What is the legal company type of “Opel Group GmbH”?
What is the current status of “Opel Group GmbH”?
Which jurisdictions are covered by which data provider datasets?
What is the number of companies and persons in each data provider dataset?
What additional properties are available for “Opel Group GmbH” from different data providers?
What additional properties are available from different data providers, and what is their coverage across companies?
Secondly, we consider non-functional requirements dealing with the general requirements or aspects that the ontology should fulfill. Foremost amongst these is
Six of the nine scenarios in the “Neon Book” Chapter 2.3 (Nine Scenarios for Building Ontology Networks) revolve around reuse.
Reuse existing ontologies as often as possible, in order to reduce effort and promote the use of the integrated data;
Make the developed ontology as easy to reuse as possible;
Use simple and pragmatic mechanisms with low “ontological commitment” rather than complex ontological mechanisms (see Section 3.3); and
Support the integration of all company data provided by at least one data provider, spanning authoritative and non-authoritative sources and modelled in different ways under a single representation schema.
The ontology development process was guided by the need to harmonize and integrate datasets with different sets of attributes, different representations for the same entity and in some cases close but not entirely similar semantics. Figure 2 depicts the four phases of the ontology development process in which we (a) gathered data from all company data providers that include natural language descriptions and example instances of each data attribute they provided, (b) analyzed attribute descriptions, refining them with additional notes describing their scope and using this information to group similar attributes, (c) analyzed identifiers and their identifier systems to produce machine readable descriptions of their properties, and (d) carried out manual reconciliation with the aim to reuse existing vocabularies.
There are differences in the types of information available from source to source (e.g., one dataset contains only official information from the national registers, while another integrates contact information parsed from company websites), differences in the way the same bit of information is represented by each provider (e.g., addresses as strings or as complex objects with separate attributes for street number, name and municipality) and differences in semantics for closely related concepts that may appear to be the same (e.g., information about officerships and their durations that contain references to possibly ambiguous officer names versus log entries that link person identification numbers to roles in different companies through time).
In the first phase of the ontology development process, as shown in Fig. 2(a), each data provider provided a description of the dataset they shared. This data analysis focused on identifying the different attributes present and the way in which they were represented. Each attribute was described, adding notes and example uses that clarified the semantics as deemed appropriate. In this phase we already identified similar or even same-as candidates (e.g., company_number, base.ukCompanyNumber, organisasjonsNummer in Fig. 2(a)). Moreover, each provider specified to which extent a particular attribute was shared, in one of three modalities: (i) fully available, (ii) fully available to perform entity matching, but not available in any other case, and (iii) fully available for matching but available in reduced form for other purposes (e.g., address information without street numbers). Analyzing the descriptions provided in the previous phase, we identified a common subset shared by all contributed datasets. This common subset contained attributes that represented the same or very similar concepts in all datasets, which allowed us to group attributes from different providers accordingly (see similar attributes grouped under the legalName label across different providers in Fig. 2(b)).
In the next phase, exemplified in Fig. 2(c), we performed a different analysis to assess the suitability of each attribute to work as an identifier of the instance it described. The analysis contained a heterogeneous group of attributes with identifying characteristics: identifiers for geographical entities, legal entities, company headquarters and secondary sites, company websites, among others. Within the provided data, we found several ways to identify an instance in a group of similar instances (e.g., registration numbers and legal names are two different and useful ways to identify a company). Some identifiers are ambiguous in nature, such as company names, while others can be used to uniquely refer to a company, as is often the case with company registration numbers. The expectation is that the former will often be found in unstructured texts while the latter will be useful to annotate those unstructured texts to link to the corresponding instance being referred to. Some identifiers belong to official registers while others are self-issued and not centralized (e.g., websites). Some identifiers are subject to particular geographic jurisdictions (e.g., company registrations in local trade registers), or belong to special registers that attest that companies belong to a certain class (e.g., register of startup companies). In other cases, identifiers simply indicate the database in which the company information can be found (e.g., identification codes issued by data providers such as OpenCorporates, codes issued by other companies that aggregate company data such as Dun & Bradstreet), the website of a company or the various associated social network identifiers (e.g., a company’s Facebook page or Twitter handle).
In light of the varied nature of the identifiers available, it was determined that the semantic model should also represent key aspects of the different identifier systems in use. These key aspects should encode expectations of the identifiers issued under each system and provide readily available rules to aid in validation and transformation of these identifiers. The expectations should help to determine the suitability of a particular indicator for common use cases that included publishing, reconciliation and matching within unstructured text. Additionally, the semantic model should provide links to information about issuing authorities and maintainers, revisions, databases and other resources.
In the last phase of the development process, as exemplified in Fig. 2, we searched within existing vocabularies for all the concepts identified in the common subset aiming to reuse whenever possible. Examples of reuse from appropriate ontologies include W3C Org, RegOrg, Location, Person (not W3C), Schema.org and ADMS datasets and identifiers.
Differences in the ways each provider decided to share the various attributes present in their datasets made it necessary to understand the scope of the ontology as early in the process as possible. In this way, it was possible to determine what to cover while having a clear path for extensibility.
Reuse approach
One reuse approach is to create own terms (classes and properties), and tie them to existing ontologies using semantic mapping properties (e.g.,
Furthermore, we want our own terms to be easily reusable. This is facilitated when terms do not carry a lot of “ontological baggage”, such as deep class hierarchies or strong bindings of properties to classes. RDFS defines the properties
Schema.org describes many real-world entities, is applicable in a wide variety of domains, and integrates data from a huge number of providers and domains. The Web Data Commons crawl from 2019-1237
See
This approach has much lower “ontological commitment” and we find that it enables more flexible reuse and combination of different ontologies, so it is appropriate in the company data domain, where data comes from a large variety of providers. Rather than using complicated OWL mechanisms, we prefer to use RDF Shapes to validate incoming data from data providers.
Prefixes, namespaces, and count of classes and properties used in the euBusinessGraph ontology
The euBusinessGraph ontology is composed of 20 classes, 33 object properties, and 57 data properties (see Table 1) that make it possible to represent basic company-related data. Figure 3 gives an overview of the ontology, depicting the main classes and their relationships (i.e., object properties). The ontology covers the following areas:
Note: We use
Further details about the
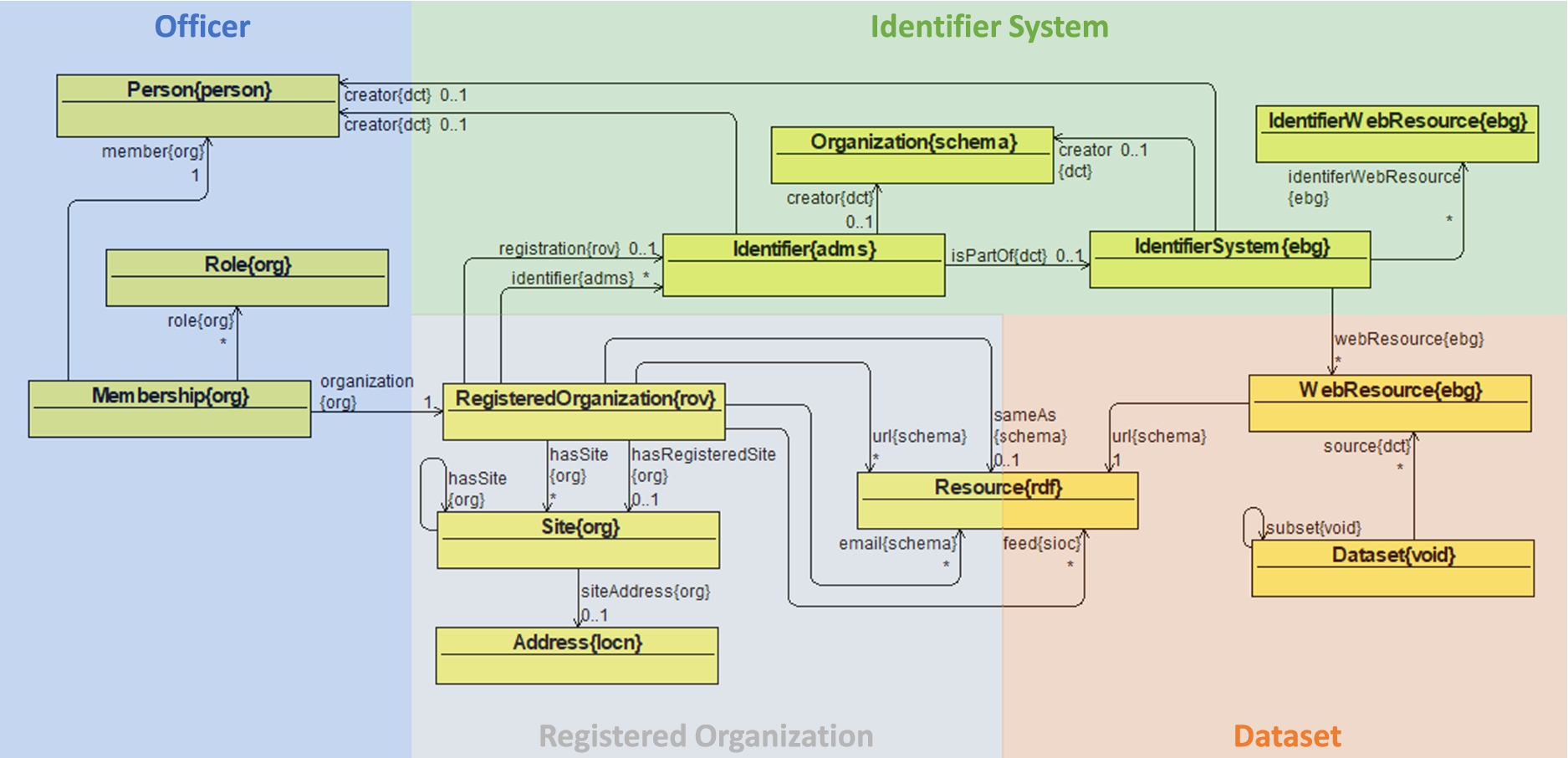
euBusinessGraph ontology overview: main classes and their relationships.
The class diagrams (depicting the ontology classes, object properties and data properties) and the object diagrams (depicting instances of the ontology classes and properties) in this section were created using the Graphical Ontology Editor (OWLGrEd).40
We reused classes and properties from existing ontologies and nomenclatures where appropriate in order to build the ontology. Table 1 lists the prefixes, namespaces, and count of classes, object and data properties used in the euBusinessGraph ontology, including those reused from the other ontologies. Looking at the count of classes and properties per ontology, it can be seen that the euBusinessGraph ontology adds relatively few, which are mostly terms around describing identifier systems. The novelty of the proposed lightweight semantic model lies in the careful combination and reuse of terms from existing ontologies, and its expression as a detailed model or application profile and RDF Shapes.

Registered organization: main classes and properties.
The ontology is released under the Open Data Commons Attribution License (ODC-By).
Registered organizations are the main entities for which information is captured in the euBusinessGraph ontology. The ontology is not concerned with unregistered informal groups. Registered organizations gain legal entity status by the act of registration and are distinct from the broader concept of organizations, groups or, in some jurisdictions, sole traders. Figure 4 shows the classes and properties for representing core data about a registered organization. The class
Names and other basic information
The ontology adopts two different name types for a registered organization, namely formal legal names and informal alternative names, e.g., a trading name. In addition we code a single name as the preferred name of the organization. The
The ontology defines the following data properties for capturing additional basic information about an organization:
Classifications
Three types of classifications are defined in the ontology for representing the company type, status and economic activity of a
The nomenclature value (SKOS concept) is used in faceting and semantic search. The free-text value is used to provide additional detail and facilitate full-text search. Many IT systems include such redundant info: both nomenclature (codified) fields and free-text fields with additional detail or nuance. E.g., in the museum data domain, CDWA51
We represent commonly used electronic resources and channels (website, Wikipedia, email, news feed) as specific object properties of a company pointing to a
Sites and addresses
Physical presence of companies is defined via addresses. We model address in a structured way using a set of attributes such as country, macroregion, province, etc. Addresses may have geographic locations specified with a different resolution level. Least precise geographic location are resolved at the level of a country, while most precise are geographical points that specify location up to a street and house number. We also enable data providers to provide full addresses in the form of a free text, which is essentially a string that combines all attributes together into a human-readable format. To provide RDF binding for the attributes, we considered two ontologies. From the ISA Programme Location Core Vocabulary we reused structured attributes such as
We distinguish between registered, and other kinds of addresses. Many jurisdictions have the concept of registered address, i.e., the legal address where summons, subpoenas and other legal documents can be sent. An address is modelled using the

Example of company representation for SpazioDati.
The class
NUTS values are assigned using the EU NUTS classification as Linked Data (NUTS-RDF) datasets.53
Figure 5 is an object diagram depicting how the ontology is used to represent company data about the legal entity SpazioDati. Each object (depicted as a green rectangle) is an instance of a class defined in the ontology. The objects have data properties according to the class definitions. The data properties are assigned values depicted using the notation
Identifier system
Mechanisms to identify companies in various data sources are essential in integration of data about companies across data sources. A proper understanding of what kind of systems of identifiers can be used for companies is thus necessary in this context. We analyzed various types of identifiers commonly used for companies and collected various properties of the systems they are part of. We modelled identifiers and identifier systems explicitly in the ontology as shown in Fig. 6.
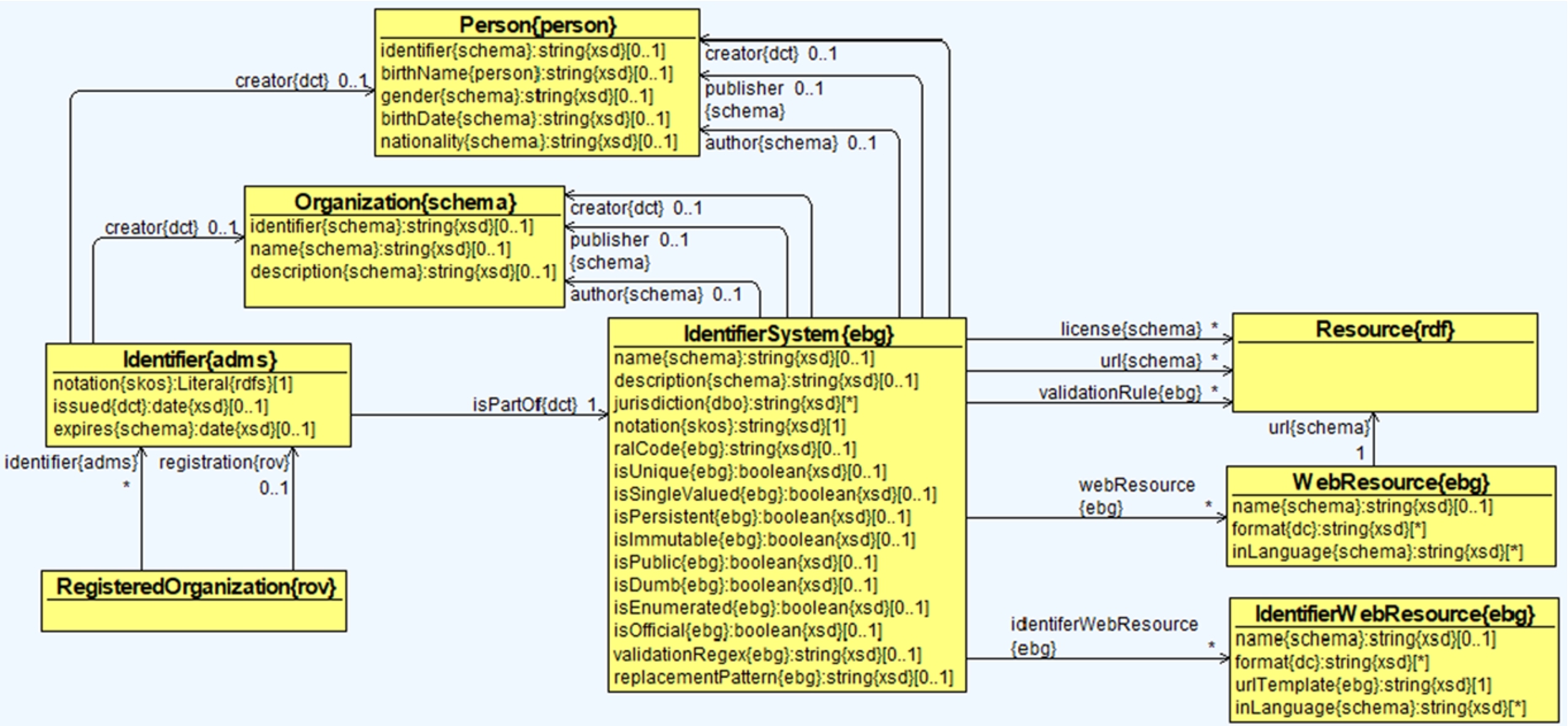
Classes, object properties and data properties for representing identifier systems and identifiers.
A
The
The
Identifier system properties and characteristics
Identifier systems have some basic properties:
Identifier systems have some boolean characteristics (flags) that represent expectations about their identifiers. Some systems have exceptions, i.e., identifiers that don’t satisfy the expectations. Each flag is set to “true” in the desirable (positive) case. We strive to provide all flags for each system, but in some cases the flag could be omitted (e.g., if there is not enough information):
Identifier systems are associated with some properties that can be useful for identifier validation:
Web resources
A Web resource is a URL complemented with a MIME type to specify what the URL is about. These web resources are used for identifier systems (e.g., to provide the search or download URL) and per-company, as a URL template in which to substitute the identifier value. There can be several MIME types because some URLs return various resource types using content negotiation. The class
The class If it has a placeholder If it has placeholders like
Agents
We represent an agent using either a
Example
An example of an identifier system is shown in Fig. 7, illustrating the OpenCorporates identifier system for which OpenCorporates is the publisher and the official UK identifier system for which Companies House is the publisher.

Example of representing the OpenCorporates identifier system and the Companies House official UK identifier system.
An officer is a natural person (as opposed to a legal person) that has a high-level management role in a company, e.g., executives and directors, and other important roles (e.g., secretary, legal council and treasurer). Officers have the authority to act on behalf of the corporation, including contract authority. Officers can also be shareholders. However, since few jurisdictions have rules for beneficial ownership reporting, and even those who do still have very little data about it,56
We use the membership model57
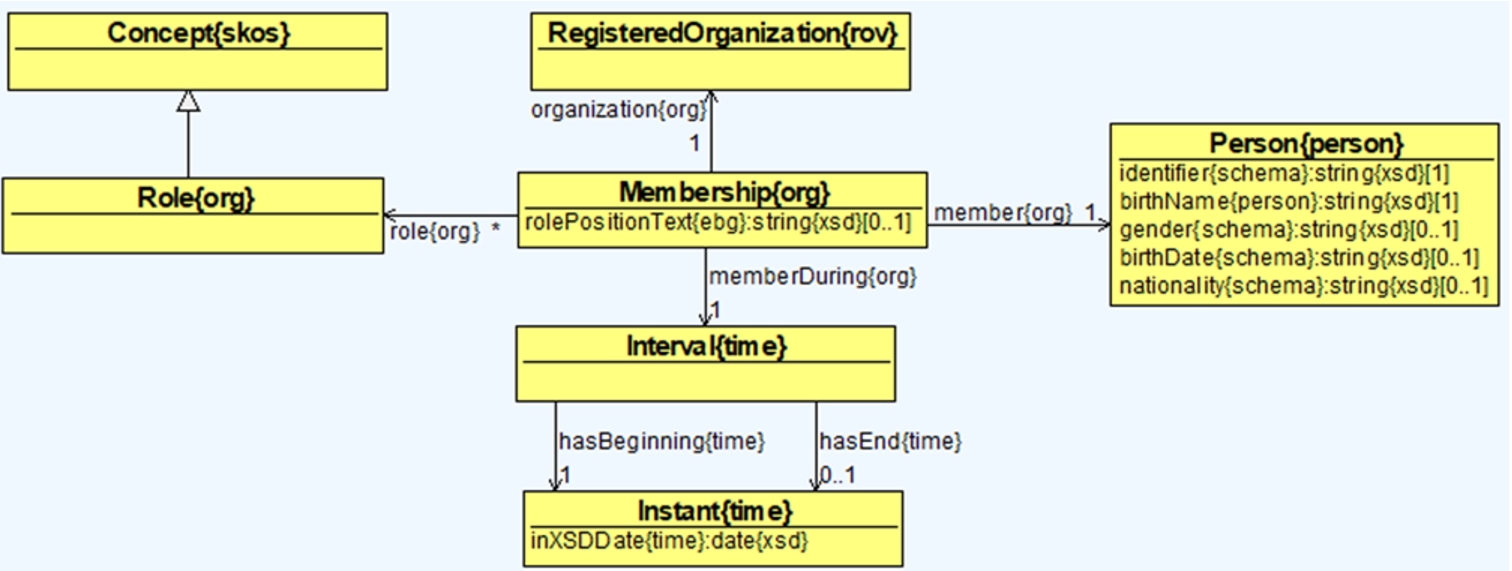
Classes, object properties and data properties for representing officers.

Example of officer representation for the company OpenCorporates.
A
The membership interval is defined by the
An example of officer roles using the free text data property
Dataset
Data consumers need to know how many companies are included in a data provider dataset, from which jurisdictions, and what depth of data is included (e.g., which properties, addresses with what geo resolution, etc.). We thus need to express both metadata about the dataset itself, and fine-grained statistics about the content of a dataset, e.g.,:
Publisher, source, last modified, license, home page, download distribution, etc.
Subsets of data by kind of entity (e.g., companies vs. addresses), field coverage (which fields are included in which subsets), and entity characteristics (e.g., Italian companies, startups, startups in Italy).
Count of entities in a dataset or subset.
After an analysis of various dataset description ontologies, we decided on using VOID with some extensions (see Fig. 10). VOID describes RDF datasets in terms of entities, classes, properties, triples, partitions (e.g., triples having a particular class), etc. A

Classes, object properties and data properties for representing datasets.
Figure 11 shows an example of the datasets provided by SpazioDati. The dataset

Example of datasets provided by SpazioDati.
In order to ensure that data can be correctly published according to the ontology, we devised a set of data validation rules that are associated with the ontology. The types of validations rules considered are as follows:

Example of SHACL shape used to validate EBG RDF company data.
There are several possible ways to describe data validation rules, ranging from an algorithmic style such as:
The ontology itself is not limited to European companies, but to ensure maximum compatibility across European data, our data provider rules and RDF Shapes choose specific EU-relevant thesauri. We use NACE for industrial classification (
Mapping parameters defined for each JSON data attribute
Helper functions used to create base URIs
We present examples of how the euBusinessGraph ontology was used. We will first describe the approach on how the ontology was used to harmonize and make available company data from various data providers, resulting in the development of a business knowledge graph (Section 5.1 and Section 5.2). We will then show how this knowledge graph was used in the euBusinessGraph marketplace for basic company data – a place where data consumers can search, analyse, and compare data from various providers (Section 5.3). Finally, we provide an example on how the ontology was used in the area of public procurement (Section 5.4), and how it was extended in the domain of financial transactions (Section 5.5).
Overview of data mapping approach
In order to develop the euBusinessGraph knowledge graph harmonizing data from various data providers, we devised a data mapping approach that was used to convert company data from CSV and JSON sources into RDF conforming to the ontology. In the following, we describe the mapping notation and provide specific examples showing how the mapping rules were used. Actual mappings for data are publicly available via the DataGraft platform60
The first step of the mapping process is to select attributes (e.g.,
Next, Table 3 defines a set of helper functions for a subset of base URIs that will be used to map JSON data to RDF. The helper functions improve readability of mapping rules by reducing the text needed to refer to a specific URI. As an example, the helper function
Mapping functions for a subset of company data attributes
A data provisioning infrastructure was developed to onboard data from various data providers. Using this approach, data source files from data providers were processed and mapped to the euBusinessGraph ontology using the mapping process discussed in the previous section. After transforming each dataset from a tabular format (i.e., CSV or JSON) to RDF, the resulting data was published to one named graph for each data provider jurisdiction in an enterprise semantic graph database, GraphDB,62
GraphDB is a service component on the Ontotext Platform.63
The core process of knowledge graph creation is executed by using the cloud-based data management platform DataGraft. Grafterizer64
The next section describes how the published knowledge graph was used to populate a marketplace for company data.
A main motivation behind the development of a data marketplace for basic company data is the democratisation of the company information market, currently dominated by a few large international players (e.g., Bisnode67
The ontology was used in the marketplace to realize functionality for a) full-text advanced search and detailed faceted search for exploration of the company knowledge graph, b) analytics services such as data aggregation and visualization (e.g., company activities per city), and c) search for company news articles, and search for company events.
Public procurement accounts for a substantial part of the public investment and global economy and therefore there is a need for better insight into, and management of government spending. In this respect, national, regional, local, and EU-wide public procurement portals were established to publish procurement notices regarding the purchase of work, goods or services from companies by public authorities in order to increase transparency, economic activity, and competitiveness [33]. However, the technical landscape is quite scattered and there are no common data formats and models used for exposing such data uniformly allowing advanced analytics and analysis, such as for fraud and trend detection. To this end, the euBusinessGraph ontology was used in the procurement domain, in the context of the project TheyBuyForYou (TBFY),70
The data integrated includes procurement data provided by OpenOpps,71
Company-related economic information is crucial to many business operations. It empowers customer relationship management, acquisition of new clients, marketing campaigns, supply chain management, market analysis, competitive intelligence, mergers and acquisitions, etc. In this respect, the euBusinessGraph ontology was used for matching and linking company-related economic information within the context of Ontotext’s Intelligent Matching and Linking of Company Data (CIMA) project.73
The analysis of existing initiatives in the area of interoperability of company-related data revealed the fact that harmonization of company data was far from a solved problem. Company data by different providers is very heterogeneous. We argued for the importance of harmonised basic company data as a key enabler for different value chains in various sectors that depend on company information.
In this article, we described the euBusinessGraph ontology for harmonizing basic company data as a lightweight mechanism for aggregating, linking, provisioning and analysing basic company data. It reuses numerous ontologies and adds extra properties and classes (e.g., IdentifierSystem) to describe the full scope of basic company information. The main challenge this paper addressed is related to finding the right balance between a semantic model for basic company information that is too complex and hard to understand (for an example of such model see FIBO) and a simplistic least common denominator model, while at the same time exploiting proper mechanisms to reuse numerous related ontologies.
The euBusinessGraph ontology was developed following standard practices in ontology development, identifying the scope and competency questions with different stakeholders, identifying and reusing existing ontologies, and publishing the ontology according to existing best practices for Linked Data vocabulary publishing. We provided an overview of the ontology scope, the ontology development process, explanations of core concepts and relationships, and the implementation of the ontology. Furthermore, we provided examples where the ontology was used, among others, for publishing company data and for comparing company data from various data providers.
An important aspect of our approach is the use of
The euBusinessGraph ontology serves now as an asset not only for enabling various tasks related to basic company data but also on top of which more specific extensions can be built upon. As an example of such an extension, initial efforts have been made to capture events that happen during the lifetime of a company [21] and for representing the French register data in RDF [12,21]. In addition to possible extensions of the ontology, other interesting directions for future work can be envisioned. For example, interlinking harmonized data from various data providers is an interesting topic for future work (preliminary work on interlinking company data harmonised using the euBusinessGraph ontology is reported in [23]). Extending the ontology with classification datasets for additional jurisdictions (e.g., Germany) will further increase the relevance of the business graph, and enable more precise queries to be executed on the harmonized data. This harmonization process includes describing supplementary identifier systems for company entities and officers for new data providers, as well as creating additional classification schemes for NACE, NUTS, LAU, organization types and organization status.
In the context of the TheyBuyForYou project, the ontology will be used as a core component of the proposed procurement knowledge graph and the ontology network. Currently, on the one hand, more data is being reconciled and ingested into the TBFY knowledge graph and on the other hand more research and development work is being undertaken in order to improve the reconciliation process matching supplier data against company data. Essentially, it will demonstrate how one can integrate disparate but relevant data sources, pose interesting queries that were otherwise not possible to answer, and create new business scenarios. In the CIMA (ONTO-CG) project, the euBusinessGraph semantic model is extended to cover financial transactions, and prototypes and exploitable systems are built using the Ontotext Platform to query RDF data integrated from numerous sources.
Footnotes
Acknowledgements
The work in this article was partly funded by the EC H2020 projects euBusinessGraph (grant 732003), EW-Shopp (grant 732590), TheyBuyForYou (780247), CIMA (grant BG16RFOP002-1.005-0168-C01), and further reused in InnoRate (821518). Special thanks to the members of the euBusinessGraph project consortium for stimulating discussions around various aspects of basic company information, especially to Tatiana Tarasova, Fredrik Seehusen, and David Norheim for their initial involvement in the development of the ontology.