
Abstract
One of the major barriers to the deployment of Linked Data is the difficulty that data publishers have in determining which vocabularies to use to describe the semantics of data. This systematic report describes Linked Open Vocabularies (LOV), a high-quality catalogue of reusable vocabularies for the description of data on the Web. The LOV initiative gathers and makes visible indicators such as the interconnections between vocabularies and each vocabulary’s version history, along with past and current editor (individual or organization). The report details the various components of the system along with some innovations, such as the introduction of a property-level boost in the vocabulary search scoring that takes into account the property’s type (e.g.,
Introduction
The last two decades have seen the emergence of a “Semantic Web” enabling humans and computer systems to exchange data with unambiguous, shared meaning. This vision has been supported by World Wide Web Consortium (W3C) Recommendations such as the Resource Description Framework (RDF), RDF-Schema and the Web Ontology Language (OWL). Thanks to a major effort in publishing data following Semantic Web and Linked Data principles [6], there are now tens of billions of facts spanning hundreds of linked datasets on the Web covering a wide range of topics. Access to the data is facilitated by portals (such as Datahub1
Despite the enormous volume of data now available on the Web, the Linked Data community has relatively little interest in vocabulary4
We use the terms “semantic vocabulary”, “vocabulary” and “ontology” interchangeably.
The Linked Open Vocabularies (LOV) initiative5
The purpose of LOV is to promote and facilitate the reuse of well documented vocabularies in the Linked Data ecosystem. In D’Aquin and Noy [12]’s categorisation of ontology libraries, LOV falls into the categories “curated ontology directory” and “application platform”. Specifically, LOV supports the following main activities for the design of ontologies and the publication of data on the Web [19,20,30,32]:
LOV enables searching for vocabulary terms (class, property, datatype) based on domain: vocabularies (and therefore vocabulary terms) are categorised according to the domain they address.
LOV provides a ranking (cf. Section 3.3.1 for each term retrieved by a keyword search to assist in ontology assessment.
LOV categorizes seven different types of relationships between ontologies: metadata, import, specialization, generalization, extension and equivalence (cf. Section 3.1.1). These relationships can be useful for finding alignments between ontologies.
This report is structured as follows: in the next section, we provide statistics on the usage of LOV. In Section 3, we describe the components and features of the system. Thereafter, in Section 4, we provide an overview of some applications and research projects based on and motivated by the LOV system. In Section 5, we report on related work. The limitations and further development of LOV are discussed in Section 6. We conclude in Section 7.

Evolution of the number of vocabularies in LOV from March 2011 to June 2015.
The LOV dataset consists of 527 vocabularies as of October 2015.6
However, the figures and evaluation used in this report are based on LOV catalogue with 511 vocabularies as of June 2015.
By observing the vocabularies contained in LOV as a whole, we can extract some information about Semantic Web adoption and dynamics. Figure 2 shows the distribution of LOV vocabularies by creation date. The distribution follows a bell curve with its peak in 2011. It is worth noting that a decrease in number of vocabulary creation does not necessarily mean a decrease in use of the technology but rather that the existing vocabularies now cover a large part of the semantic description needed. When looking at the last modified date of the same vocabularies (as illustrated in Fig. 3), we see that LOV vocabularies are part of a living ecosystem in constant evolution.

Distribution of LOV vocabularies by creation date. For indication, we use vertical red lines to mark the official release dates of the main Semantic Web languages (RDF, RDFS and OWL).
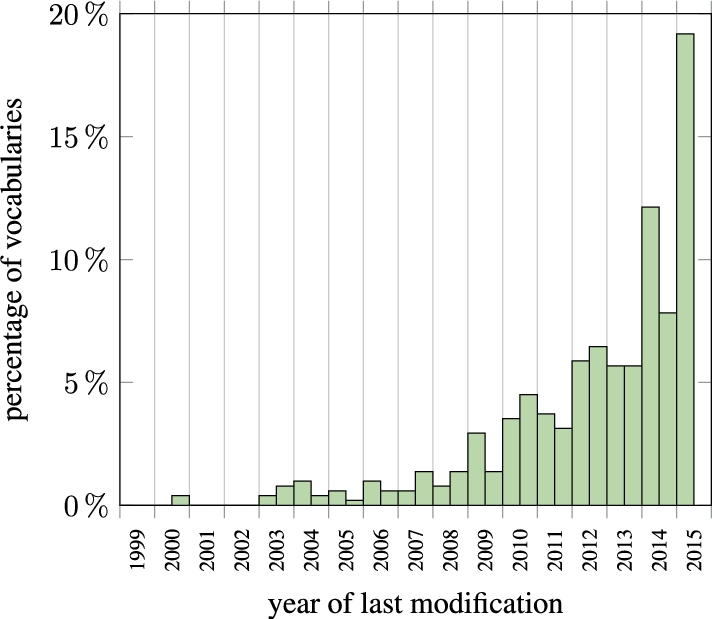
Distribution of LOV vocabularies by last modified date.
Overall, the LOV dataset contains 20,000 classes and almost 30,000 properties. The median is 9 classes and 17 properties per vocabulary. Table 1 presents a breakdown of LOV content by vocabulary element type. In this Table, the Classes type refers to any instance of
LOV vocabulary element types statistics
Top five languages detected in the LOV catalogue, showing numbers and percentages of vocabularies using them. A vocabulary can make use of multiple languages

Distribution of LOV vocabularies by number of languages explicitly mentioned using language tag. “Zero” means that there is no explicit language tag declared (i.e. no literal value of the vocabulary has a language tag).
Type of elements searched from January to June 2015 by users in LOV for all searches and those with keyword
Out of 511 vocabularies, 66.14% explicitly use the English language for labels/comments, i.e. containing
From January to June 2015, more than 1.4 million searches were conducted on LOV.7
This figure includes searches from the API and UI as well as searches with and without keywords such as “all agents that participated in vocabulary design and publication in the geo-location domain”.
Top 10 terms searched from January to June 2015 by users in LOV

Evolution of the number of searches through UI and API methods from January to June 2015. Note that the y axis has a logarithmic scale.
Since 2011, the Linked Open Vocabularies initiative has gathered a community of about 480 people interested in various domains, including ontology engineering and data publication. The LOV Google+ community8
The LOV architecture is composed of four main components (cf. Fig. 6): 1) Tracking and Analysis. Checks for any vocabulary version update and analyses vocabularies’ specific features. 2) Curation. Ensures the high quality of the LOV dataset by enabling the community to suggest vocabularies or edit the catalogue. 3) Data Access. Provides access to the data through a large range of methods and protocols to facilitate the use of LOV dataset and 4) Data Storage. Offers a reliable and efficient method for storing and querying the data. Each component provides a set of features detailed in the following subsections.

Overview of the Linked Open Vocabularies Architecture.
The Tracking and Analysis component dereferences9
A URI is looked up over HTTP to return content in a processable format such as XML/RDF, Notation 3 or Turtle.
At the vocabulary level, the system extracts three types of information for each vocabulary version (Fig. 7):
The metadata associated to the vocabulary. This information is explicitly defined within the vocabulary to provide context and useful data about the vocabulary. Some high level vocabularies can be reused for that purpose, such as Dublin Core10
Inlinks/incoming vocabularies, making explicit the
Outlinks/outgoing vocabularies, making explicit the

Metadata type, vocabulary inlinks and outlinks of DCAT vocabulary.
Two vocabularies can be interlinked in many different ways. Consider two vocabularies
Some terms from
Some terms from

Examples of Inter-vocabulary relationships.
These relationships, with the exception of Import which is represented by
The SPARQL Queries are described in the VOAF vocabulary.
Inter-vocabulary relationship types and their number of occurrences in LOV
At the vocabulary term level, the system extracts two types of information:
term type (class, property, datatype or instance defined in the namespace of the vocabulary) indexed by the system’s search engine so it can be used to filter a search.
term natural language annotations (RDF literals) with their predicate and language (e.g.
The information concerning the usage of a vocabulary term in Linked Open Data, also called “popularity”, is used in LOV search results scoring as explained in Section 3.3.1. This information is not natively present in the vocabularies and can not be inferred from the LOV dataset. We make use of the LODStats project which gathers comprehensive statistics about RDF datasets [3]. LOV regularly fetches LODStats raw data14
We retrieve the statistics available at:
The vocabulary collection is maintained by curators who are responsible for validating metadata information, inserting a vocabulary in the LOV ecosystem, and assigning a review on the suggested vocabulary.
Vocabulary insertion
Compared to other vocabulary catalogues (cf. Section 5), LOV relies on a semi-automated process for vocabulary insertion. Whereas an automated process focuses only on volume, in our process, we focus on the quality of each vocabulary and therefore the quality of the overall LOV ecosystem. Suggestions come from the community and from inter-vocabulary reference links. Our system provides a feature to suggest16
a vocabulary should be written in RDF and be dereferenceable;
a vocabulary should be parsable without error (warnings are tolerated);
all vocabulary terms (classes, properties and datatypes) in a vocabulary should have an
a vocabulary should refer to and reuse relevant existing ones; and
a vocabulary should provide some metadata about the vocabulary itself (at least a title).
When automatic extraction of metadata fails, LOV curators enhance the description available in the system and notify the vocabulary authors of the pitfalls’ report. This manual task usually consists in checking for any additional information present in the HTML documentation (targeted for humans) and not reflected in the RDF description. The documentation provided by the LOV system assists users in understanding the semantics of each vocabulary term and therefore of any data using the term. For instance, information about the creator and publisher is a key indication for a vocabulary user in case help or clarification is required from the author, or to assess the stability of that artifact. About 55% of the vocabularies specify at least one creator, contributor or editor. We augment this information using manually gathered information, leading to the inclusion of data about the creator in over 85% of the vocabularies in LOV. The database stores every version of a vocabulary since its first issue. For each version, a user can access the file (particularly useful when the original online file is no longer available). A script automatically checks for vocabulary updates on a daily basis. When a new version is detected, it is stored locally, and the statistics about that vocabulary are recomputed. Similarly we ensure that curated review for each vocabulary is less than one year old by sending curators a notification when a vocabulary review is older than eleven months. In both cases, curators update the vocabulary review accordingly.
Data access
The LOV system (code and data) is published under a Creative Commons 4.0 license17
Query the LOV search engine to find the most relevant vocabulary terms, vocabularies or agents matching keywords and/or filters;
Download data dumps of the LOV catalogue in RDF Notation 3 format or the LOV catalogue and the latest version of each vocabulary in RDF N-quads format;
Run SPARQL queries on the LOV SPARQL Endpoint; and
Use the LOV API which provides a full access to LOV data for software applications.
In [9], Butt et al. compare eight different ranking methods grouped in two categories for querying vocabulary terms:
Content-based Ranking Models: tf-idf, BM25, Vector Space Model and Class Match Measure. Graph-based Ranking Models: PageRank, Density Measure, Semantic Similarity Measure and Betweenness Measure.
Based on their findings, we defined a new ranking method adapting term frequency inverse document frequency (tf-idf) to the graph-structure of vocabularies. Compared to the other methods, tf-idf takes into account the relevance and importance of a resource to the query when assigning a weight to a particular vocabulary for a given query term. We reuse the augmented frequency variation of term frequency formula to prevent a bias towards longer vocabularies. Because of the inherent graph structure of vocabularies, tf-idf needs to be tailored so that the basic unit is not a word, but rather a vocabulary term t in a vocabulary V. Equation (1) presents the adaptation of tf-idf to vocabularies (a definition of the variables used in this paper’s equations is provided in Table 6).
Definition of the variables used in the equations
Definition of the variables used in the equations
As highlighted in [9] and [26], the notion of the vocabulary term’s popularity across the LOD datasets set
RDF datasets have a consensual and stable structure, which arises from the best practices of vocabulary publication. It then becomes intuitive to assign more importance to a vocabulary term matching a query on the value of the property Local name (URI without the namespace). While a URI is not supposed to carry any meaning, it is a convention to use a compressed form of a term label to construct the local name. The local name therefore becomes an important artifact for term matching for which the highest score will be assigned. An example of local name matching the term “person” is Primary labels. The highest score will also be assigned for matches on the Secondary labels. We define as secondary label the following properties: Tertiary labels. Finally all properties not falling in the previous categories are considered as tertiary labels for which a low score is assigned. An example of tertiary label matching the term “person” is
For every vocabulary in LOV, terms (classes, properties, datatypes, instances) are indexed and a full text search feature is offered.18

The LOV catalogue RDF schema model, in a UML class diagram representation.
The final score of t for a query Q (Eq. (4)) is a combination of the tf-idf, the importance of label properties of t on which query terms matched, and the popularity of that term in the LOD dataset. While the factorisation of the tf-idf and field normalisation factor is common for search engine ranking,19
See elasticsearch documentation:
The system provides two data dumps, one containing the LOV vocabulary catalogue only in RDF Notation 3 format20
The LOV SPARQL endpoint22

List of APIs to access LOV data.
LOV APIs give a remote access to the many functions of LOV through a set of RESTful services.23
Vocabulary terms (classes, properties, datatypes and instances). With these functions, a software application can query the LOV search engine, ask for auto-completion or a suggestion for misspelled terms.
Vocabularies. A client can get access to the current list of vocabularies contained in the LOV catalogue; search for vocabularies, get auto-completion or obtain all details about a vocabulary.
Agents. This provides a software agent with a list of all agent references in the LOV catalogue, a means to search for an agent, get auto-completion and details about an agent.
The LOV Website offers intuitive navigation within the vocabularies catalogue. It allows users to explore vocabularies, vocabulary terms, agents and languages, and to see the connections between these entities. For instance, a user can use the agent search to look for experts in geography and geometry domains.24
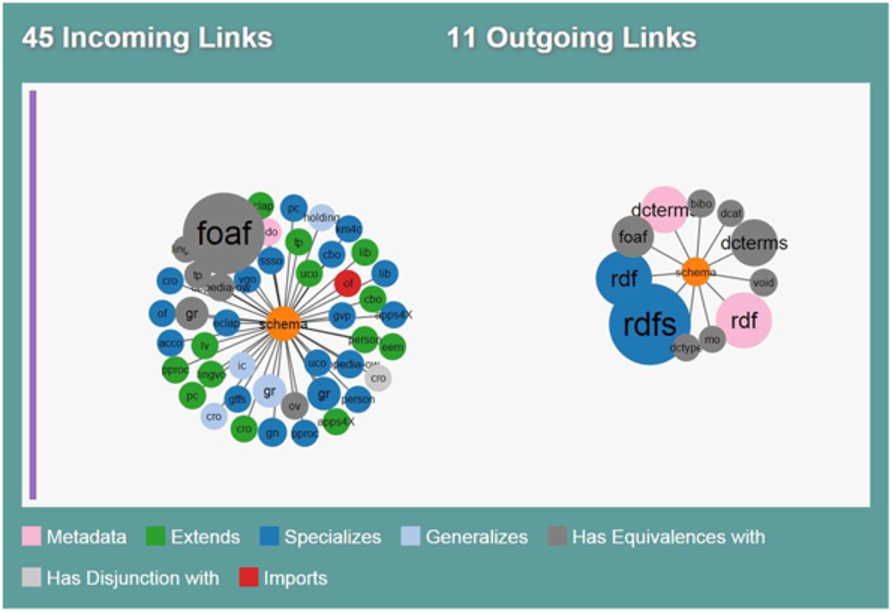
A graphical representation of the incoming and outgoing links for the Schema.org vocabulary as displayed in the UI.
To support the features presented above, we make use of specific storage technologies. The LOV catalogue is stored in MongoDB®, a document-based schema-less data store that scales and allows for dynamic changes in the data schema.26
LOV, with its various data access methods, supports the emergence of a rich application ecosystem. Below we list some tools using our system as part of their service and project.
Derived tools and applications
In [18], Maguire et al. use the LOV search API to implement OntoMaton,29
YASGUI (Yet Another SPARQL Query GUI)30
Data2Ontology maps data objects and properties to ontology classes and predicates available in the LOV catalogue. Data2Ontology is part of the Datalift32
OntoWiki33
Furthermore, we can mention the ProtégéLOV,34
LOV has served as the object of studies in [21] where Poveda-Villalón et al. analysed trends in ontology reuse methods. In addition, the LOV dataset has been used to analyse the occurrence of good and bad practices in vocabularies [22].
Prefixes in the LOV dataset are regularly mapped with namespaces in the prefix.cc service. In [2], the authors perform alignments of Qnames of vocabularies in both services and provide different solutions to handle clashes and disagreements between preferred namespaces. Both LOV and prefix.cc provide associations between prefixes and namespaces but follow a different logic. The prefix.cc service supports polysemy and synonymy, and has a very loose control on its crowd-sourced information. In contrast, LOV has a much more strict policy forbidding polysemy and synonymy ensuring that each vocabulary in the LOV database is uniquely identified by a unique prefix identification allowing the usage of prefixes in various LOV publication URIs.
The LOV query log covering the period between 2012-01-06 and 2014-04-16 has been used in [9] to build a benchmark suite for ontology search and ranking. The CBRBench35
In [16], the authors provide a 5 star rating for RDF vocabulary publication to boost interoperability, query federation and better interpretation of data on the Web similar to the 5 stars rating for Linked Open Data. Based on LOV’s best practices criteria, all vocabularies must be 5 stars using this ranking and must provide further quality attributes imposed by LOV to facilitate vocabulary reuse.
RDFUnit36
Finally, Governatori et al. [15] analyse the current use of licenses in vocabularies on the Web based on the LOV catalogue in order to propose a framework to detect incompatibilities between datasets and vocabularies.
Comparison of LOV with respect to Swoogle, Watson, Falcons and Vocab.cc; adapted from the framework presented by d’Aquin and Noy [12]. SWD stands for Semantic Web Document
Reusing vocabularies requires searching for terms in existing specialised vocabulary catalogues or search engines on the Web. While we refer the reader to [12] for a systematic survey of ontology repositories, below we list some existing catalogues relevant for finding vocabularies:
Catalogues of generic vocabularies/schemas similar to LOV catalogue. Example of catalogues falling in this category are vocab.org,37
Catalogues of ontologies for a specific domain such as biomedicine with the BioPortal [33], geospatial ontologies with SOCoP+OOR,39
Catalogues of ontology Design Patterns (ODP) focus on reusable patterns in ontology engineering [23]. The submitted patterns are small pieces of vocabularies that can further be integrated or linked with other vocabularies. ODP does not provide a search function for specific terms as is the case with some of these other catalogues.
Search Engines of ontology terms. Among ontology search engines, we can cite: Swoogle [13], Watson [11], FalconS [10] and Vocab.cc [29]. These search engines crawl for data schema from RDF documents on the Web. They offer filtering based on ontology type (Class, Property) and a ranking based on the popularity. They don’t look for ontology relations nor do they check if the definition of the ontology is available (usually known as dereferenciation). While in Swoogle the ranking score is displayed, Watson shows the language of the resource and the size. However, none of these services provide any relationship between the related ontologies, or any domain classification of the vocabularies. Table 7 presents a summary of key features of LOV with respect to Swoogle, Watson, Falcons and Vocab.cc.
Datasets and Vocabularies statistics. In this category we can mention LODStats [3] and the vocabularies derived from the LOD Cloud. LODStats makes a bridge between datasets and vocabularies gathering up to 32 different statistical criteria based on a statement-stream-based approach for RDF datasets in Datahub.41
While most of the related work focuses on automatic techniques to gather as many ontologies as possible, LOV focuses on maintaining a high quality collection of vocabularies that data publishers can reuse to describe their own data. To ensure the high quality of LOV data, we set up some stringent requirements for vocabularies to be inserted (cf. Section 3.2.1) such as the fact that a vocabulary URI must be dereferenceable. These kinds of requirements are not always taken into account in the aforementioned work: for instance, the authors in [28] define the notion of partly dereferenceable for vocabularies. As a consequence, anyone using a vocabulary referenced in LOV is ensured to get access to the vocabulary metadata but most importantly to its formal definition and preservation by accessing to various versions.
As part of our system evaluation we have compared the list of vocabularies in LOV with the ones in external services (LODStats and the empirical survey of Schmachtenberg et al. [28]) so as to understand the discrepancy.
LODStats contains 2,940 vocabularies extracted from datasets listed in Datahub.io. This list contains in fact a large number (2,596) of invalid vocabulary URIs and resource URIs that do not refer to a vocabulary (e.g.
Recently, an updated comprehensive empirical survey of Linked Data conformance has been presented by Schmachtenberg et al. [28]. Their survey is based on a large-scale Linked Data crawl from March 2014 to analyse the differences of best practices adoption in different domains. Their results concerning the most used accessible vocabularies and the adoption of well-known vocabularies are inline with the findings of this paper. However, comparing the vocabularies in the LOD cloud with the LOV catalogue needs some alignments. From the 638 mentioned by Schmachtenberg et al., we removed invalid URIs such as domain names such as “umbel.org”. Additionally we removed misspelled URIs and incomplete URIs. As a result, 270 candidate URIs (42.31%) can be compared with LOV vocabularies. Based on this analysis, we found that 102 vocabularies in the LOD cloud are already in the LOV catalogue, representing 38% of the 270 candidates. The general difference of our work with the one presented by Schmachtenberg et al. is that our approach applies strict criteria to include a vocabulary while their approach is dataset driven.
Whilst providing access to high quality vocabularies, LOV system presents several limitations. As described in the last section, LOV system could benefit from an automatic discovery process to suggest vocabulary candidates. We could for instance extract vocabularies from the latest version of the Billion Triple Challenge or the Web Data Commons42
Currently, LOV’s scope focuses on vocabularies for the description of RDF data and does not include any Value Vocabularies such as SKOS thesauri. By making the code of LOV system open source, we encourage anyone to set up an instance of the system to target such artifacts.
LOV relies on external projects such as LODStats to get the valuable information of vocabulary usage in published datasets. At the moment, the popularity information coming from LODStats does not take into account the most recent interest in publishing RDF data using markup language (e.g.
From the study of LOV as a dynamic ecosystem we can draw two main lessons learned: the need for more multilingual vocabularies on the Web and the importance of long term preservation of vocabularies.
Labels are the main entry point to a vocabulary and their associated language is the key. Only 15% of LOV vocabularies make use of more than one language. Multilingualism is important at least for two reasons: 1) the most obvious one is allowing users to search, query and navigate vocabularies in their native language; and 2) translation is a process through which the quality of a vocabulary can only improve. Looking at a vocabulary through the eyes of other languages and identifying the difficulties of translation helps to better outline the initial concepts and if necessary refine or revise them. Hence multilingualism and translation should be native, built-in features of any vocabulary construction, not a marginal task.
Currently there is no solution for long-term vocabulary preservation on the Web [5]. This is a particularly important problem in a distributed and uncontrolled environment where any individual can create and publish a vocabulary. Third parties can reuse such vocabularies and therefore create a dependency on the original vocabulary availability as it retains the semantics of the data. This issue weakens the Semantic Web foundations.
In this system report we presented an overview of the Linked Open Vocabularies initiative, a high quality catalogue of reusable vocabularies for the description of data on the Web. The importance of this work is motivated by the difficulty that data publishers have in determining which vocabularies to use to describe their data. The key innovations described in this article include: 1) the availability of a high quality dataset of vocabularies available through multiple access methods 2) the curation by experts, making explicit for the first time the relationships between vocabularies and their version history; and 3) the consideration of property semantics in term search relevance scoring.
In the future, the LOV initiative could evolve in several ways. First, an area that is still largely unexplored is multi-term vocabulary search. During the ontology design process, it is common to have more than 20 concepts represented using existing vocabularies or a new one in case there is no corresponding artifact. While we are able to search for relevant terms in LOV it is still the responsibility of the ontology designer to understand the complex relationships between all these terms and come up with a coherent ontology. We could use the network of vocabularies defined in LOV to suggest not only a list of terms but graphs to represent several concepts together.
Second, we would like to provide more vocabulary based services such as vocabulary matching to help authors add more relationships to other vocabularies. Vocabulary checking is another service the community is asking for. We could integrate useful applications directly into LOV, such as Vapour,43
Another research direction is SPARQL query extension and rewriting based on Linked Vocabularies. Using the inter-vocabulary relationships we could transform a query to use the same semantics (same vocabulary terms) as the data source(s) being queried.
Finally, we plan to provide a user study and publish the results on the different usage of LOV by end users. In addition, we plan to include the vocabularies from LODStats and LOD Cloud that are suitable for inclusion in the LOV catalogue.
The adoption and integration of the LOV catalogue in applications for vocabulary engineering, reuse and data quality are significant. LOV has a central role in vocabulary life-cycle on the Web of data as highlighted by the W3C:46
Footnotes
Acknowledgements
This work has been partially supported by the French National Research Agency (ANR) within the Datalift Project, under grant number ANR-10-CORD-009; the Spanish project BabelData (TIN2010-17550) and Fujitsu Laboratories Limited. The Linked Open Vocabularies initiative is graciously hosted by the Open Knowledge Foundation. We would like to thank all the members of LOV community and all the editors and publishers of vocabularies who trust in LOV catalogue. A special thank to Phil Archer, Julia Bosque Gil and Jodi Schneider for their valuable feedback and comments on this paper.