
Abstract
The process of gathering ground truth data through human annotation is a major bottleneck in the use of information extraction methods for populating the Semantic Web. Crowdsourcing-based approaches are gaining popularity in the attempt to solve the issues related to volume of data and lack of annotators. Typically these practices use inter-annotator agreement as a measure of quality. However, in many domains, such as event detection, there is ambiguity in the data, as well as a multitude of perspectives of the information examples. We present an empirically derived methodology for efficiently gathering of ground truth data in a diverse set of use cases covering a variety of domains and annotation tasks. Central to our approach is the use of CrowdTruth metrics that capture inter-annotator disagreement. We show that measuring disagreement is essential for acquiring a high quality ground truth. We achieve this by comparing the quality of the data aggregated with CrowdTruth metrics with majority vote, over a set of diverse crowdsourcing tasks: Medical Relation Extraction, Twitter Event Identification, News Event Extraction and Sound Interpretation. We also show that an increased number of crowd workers leads to growth and stabilization in the quality of annotations, going against the usual practice of employing a small number of annotators.
Keywords
Introduction
Knowledge base curation, or the task of populating knowledge bases, is one of the main research challenges of crowdsourcing the Semantic Web [47]. Knowledge base curation can be done either manually, by asking annotators to populate the knowledge graph by manually extracting triples from unstructured data, or automatically by using information extraction methods that are trained and evaluated on ground truth collected from human annotators. In both cases, the process of gathering the human annotations is the a bottleneck in the entire knowledge base population process. The traditional approach to gathering human annotation is to employ experts to perform annotation tasks [57], which is a costly and time consuming process. Additionally, in order to prevent high disagreement among expert annotators, strict annotation guidelines are designed for the experts to follow. On the one hand, creating such guidelines is a lengthy and tedious process, and on the other hand, the annotation task becomes rigid and not reproducible across domains. And, as a result, the entire process needs to be repeated over and over again in every domain and task. Finally, expert annotators are not always available for specific tasks such as open domain question-answering or news events, while many annotation tasks can require multiple interpretations that a single annotator cannot provide [3].
As a solution to those problems, crowdsourcing has become a mainstream approach. It has proved to provide good results in multiple domains: annotating cultural heritage prints [42], medical relation annotation [4], ontology evaluation [41]. Following the central feature of volunteer-based crowdsourcing introduced by [54] that majority voting and high inter-annotator agreement [12] can ensure truthfulness of resulting annotations, most of those approaches are assessing the quality of their crowdsourced data based on the hypothesis [40] that there is only one right answer to each question.
However, this assumption often creates issues in practice. Recent work in collecting annotations for text [16,44], sounds [22] and images [18,48] found that disagreement between annotators is not just a result of poor quality work, and can actually be an indicator for other properties of the data, such as ambiguity and uncertainty [2].
Previous experiments we performed [5] also identified issues with the assumption of the one truth: inter-annotator disagreement is usually never captured, either because the number of annotators is too small to capture the full diversity of opinion, or because the crowd data is aggregated with metrics that enforce consensus, such as majority vote. These practices create artificial data that is neither general nor reflects the ambiguity inherent in the data.
To address these issues, we proposed the
In this paper, we extend the definition of our ambiguity-aware methodology (CrowdTruth version 1.0 [25]) to work both with crowdsourcing tasks that are closed, i.e. the annotations that can occur in the data are already known, and the workers are asked to validate their existence (e.g. given a news event, decide whether it is expressed in a tweet), and tasks that are open, i.e. the annotation space is not known, and workers can freely select all the choices that apply (e.g. given a news piece, select all events that appear in the text). The code for the extended CrowdTruth version 1.1 methodology and metrics is available at:
We investigate tasks of text and sound annotation, in both domains that typically require expertise from annotators (e.g. medical) and those that don’t (open domain). In particular, we look at four crowdsourcing tasks: Medical Relation Extraction, Twitter Event Identification, News Event Extraction and Sound Interpretation. The aim is to investigate the role of inter-annotator disagreement as part of the crowdsourcing system by applying the CrowdTruth methodology to collect data over a set of diverse use cases.
Through the use of CrowdTruth aggregation metrics, the interpretations collected from the crowd are transformed into explicit semantics for the various tasks presented in this paper – i.e. relations expressed in sentences, topics/events expressed in tweets and news articles, words describing sounds – thus enabling knowledge base curation for these specific tasks. Furthermore, we prove that capturing disagreement is essential for acquiring high quality semantics. We achieve this by comparing the quality of the data aggregated with CrowdTruth metrics with majority vote, a method which enforces consensus among annotators. By applying our analysis over a set of diverse tasks we show that, even though ambiguity manifests differently depending on the task (e.g. each task has an optimal number of workers necessary to capture the full spectrum of opinions), our theory of inter-annotator disagreement as a property of ambiguity is generalizable for any semantic annotation crowdsourcing task.
The paper makes the following contributions:
CrowdTruth methodology
In this section, we describe the CrowdTruth methodology version 1.1, for aggregating crowdsourcing data, which offers methods to aggregate both closed an open-ended tasks. Version 1.1 presented in this paper is a generalization of the initial version 1.0 of CrowdTruth [25].
In Section 4 we use a number of annotation tasks in different domains to illustrate its use and gather experimental data to prove the main claim of this research – CrowdTruth methodology provides a viable alternative to traditional consensus-based majority vote crowdsourcing and expert-based ground truth collection. The elements of the CrowdTruth methodology are:
annotation modeling with the triangle of disagreement;
quality metrics for media units (input data), annotations and crowd workers;
identification of workers with low quality annotations.
Each of these elements is applicable across a variety of domains, content modalities, e.g., text, sounds, images and videos and annotation tasks, e.g., closed and open-ended annotations. The following sub-sections briefly introduce the overview of the methodology elements.
CrowdTruth quality metrics
Measuring quality in CrowdTruth is done with the triangle of disagreement model (based on the triangle reference [30]), which links together media units, workers, and annotations, as seen in Fig. 1. It allows us to assess the quality of each worker, the clarity of each media unit, and the ambiguity, similarity and frequency of each annotation. This model makes it possible to express how the ambiguity in any of the corners disseminates and influences the other components of the triangle. For example, an unclear sentence or an ambiguous annotation scheme would cause more disagreement between workers [6], and thus, both need to be accounted for when measuring the quality of the workers.

Triangle of disagreement.
The CrowdTruth quality metrics [6] are designed to capture inter-annotator disagreement in crowdsourcing. The metrics were introduced for closed tasks, i.e. multiple choice tasks, where the annotation set is known before running the crowdsourcing task. In this paper, we present an extended version of these metrics (version 1.1), that can be used for both closed tasks as well as open-ended tasks (i.e. the annotation set is not known beforehand, and the workers can freely select all the choices that apply). The code for the CrowdTruth version 1.1 metrics is available at:
The quality of the crowdsourced data is measured using a
While for closed tasks the number of elements in the annotation vector is known in advance, for open-ended tasks the number of elements in the annotation vector can only be determined when all the judgments for a media unit have been gathered. An example of such a task can be highlighting words or word phrases in a sentence, or as an input text field where the workers can introduce keywords. In this case the answer space is composed of all the unique keywords from all the workers that solved that media unit. As a consequence, all the media units in a closed task have the same answer space, while for open-ended tasks the answer space is different across all the media units.
Although the answer space for open-ended tasks is not known from the beginning, it is still possible to deduce a finite answer space. To achieve this, we added an answer space dimensionality reduction step to the methodology for open-ended tasks. Additional goals of this step are to reduce redundancy in the answer space through similarity clustering (e.g. by making sure that synonymous words do not count as disagreement between annotators), and to keep the vector space representation small enough so that the CrowdTruth quality metrics still produce meaningful values. The method for performing dimensionality reduction is dependent on the annotation task itself.
In the annotation vector, each answer option is a boolean value, showing whether the worker annotated that answer or not. This allows the annotations of each worker on a given media unit to be aggregated, resulting in a
Three core
Two
After collecting the crowd annotations, but before the evaluation of the data, we perform spam removal. The purpose of this step is to identify the adversarial and low quality workers – e.g. those workers that always pick the same annotations, regardless of the unit. Once identified, the spam workers are removed from the dataset, and their annotations are not used in the evaluation. The methodology for spam removal is based on our previous work in [51], extended in this paper to work also for open-ended tasks.
We identify the low quality workers by applying the core CrowdTruth worker metrics, the worker-worker agreement (
In open-ended tasks we apply the same approach. However, we need to acknowledge the fact that open-ended tasks are more prone to disagreement due to the large answer space and thus, the overall agreement between the workers can occur with lower values. Thus, we do not have predefined values for identifying the low-quality workers, but for every task or job we use the following main heuristic: given worker w, if the agreement
Based on the specificity of each task, closed or open-ended, the effort required to pick different annotations might vary. For instance, when no good annotation exists in the media unit, the time to complete the annotation is considerably reduced. This can bias the workers towards selecting the option that requires the least work. In order to prevent this, we introduce in-task effort consistency checks. Such annotations do not count towards building the ground truth, and are used to reduce the bias from picking the quickest option. For instance, when stating that no annotation is possible in the media unit, the workers also have to write an explanation in a text box for why no annotation were provided.
Experimental setup
The aim of the crowdsourcing experiments described and analyzed in this paper is to show that the CrowdTruth ambiguity-aware crowdsourcing approach produces data with a higher quality than the traditional majority vote where consensus among annotators is enforced. In order to show this, we perform an experiment over a set of four diverse crowdsourcing tasks:
two closed tasks, i.e. Medical Relation Extraction, Twitter Event Identification,
two open-ended tasks, i.e. News Event Extraction and Sound Interpretation.
Crowdsourcing task details
Crowdsourcing task details
Crowdsourcing task data
These tasks were picked from diverse domains (medical, sound, open), to aid in the generalization of our results. To evaluate the quality of the crowdsourcing data, we constructed a trusted judgments set by combining expert and crowd annotations. The rest of this section describes the details of the crowdsourcing tasks, trusted judgments acquisition process, as well as the evaluation methodology we employed.
Tables 1 and 2 present an overview of the crowdsourcing tasks, as well as the datasets used. The results of the crowdsourcing tasks were processed with the use of CrowdTruth metrics (Section 2.1), and we removed consistently low quality workers based on the spam removal procedure (Section 2.2). The tasks were implemented and ran on Figure Eight1
Tasks marked with ∗:
The payment per judgment was determined through a series of pilot runs of the tasks where we started with a $0.01 cost per judgment, and then gradually increased the payment until a majority of Figure Eight workers rated our tasks as having fair payments. As a result, we were able to get a constant stream of workers to participate in the tasks. The values shown in Table 2 show the final cost per judgment we reached after the pilot runs. Since crowd pay has a complex effect on the quality of the annotation [35], and in order to remove confounding factors, judgments collected with costs lower than those in Table 2 were left out of this evaluation. In total, it took two months to perform the pilot runs and then collect the judgments for all of the tasks.
The number of workers per media unit was determined experimentally with the goal of capturing all possible results from the crowd and stabilizing the quality of the annotations; this process is explained at length further on in Section 4, with the results of the experiment shown in Fig. 4.
The
The medical relation extraction task (see Fig. 2a) is a closed task. The crowd is given a medical sentence with the two highlighted terms collected with distant supervision, and is then asked to select from a list all relations that are expressed between the two terms in the sentence. The relation list contains eight UMLS4
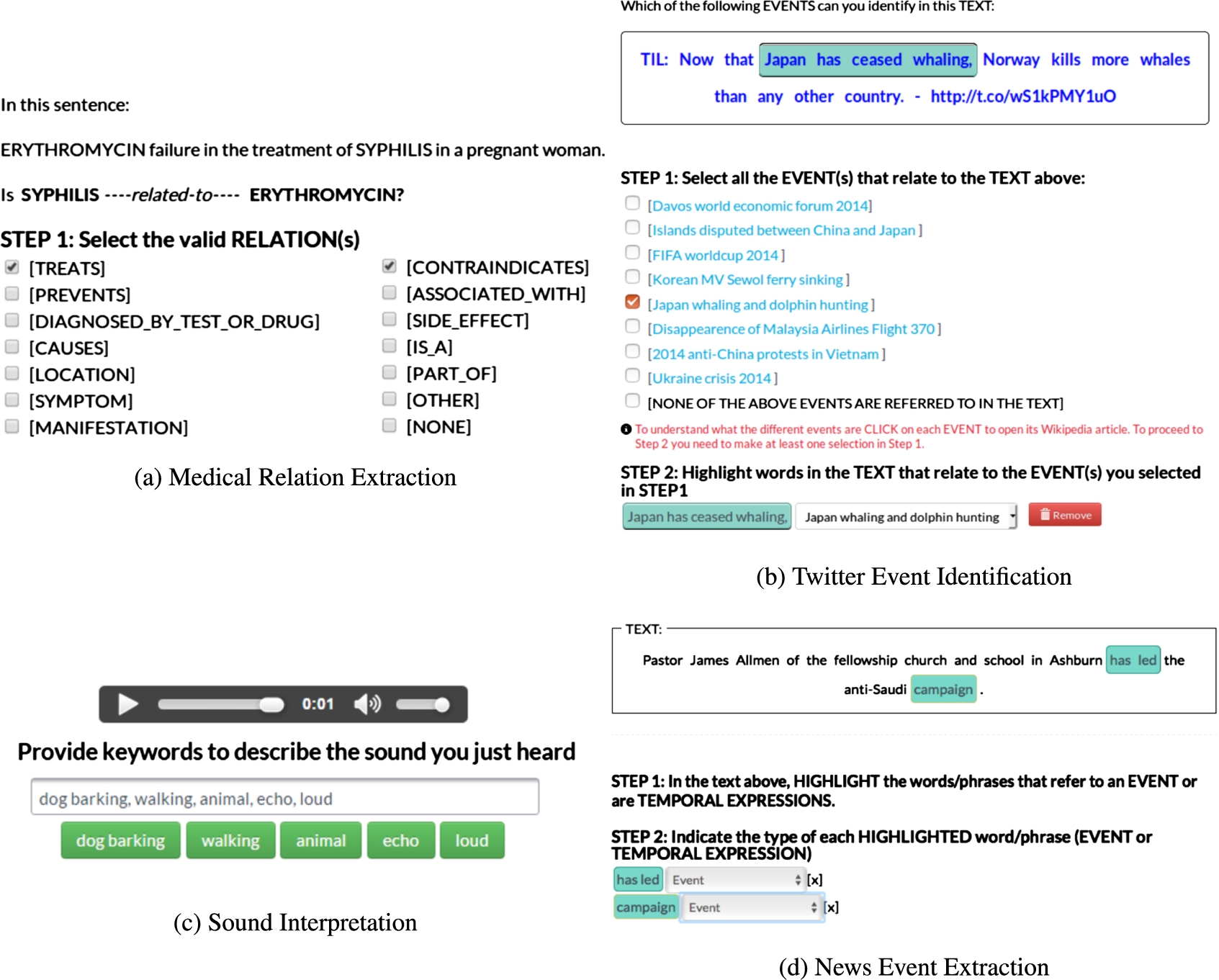
Templates of the crowdsourcing tasks.
The
The
The
The purpose of the evaluation is to determine the quality of the annotations generated with CrowdTruth ambiguity-aware aggregating metrics. To this end, we label each media unit and annotation pair with its media unit-annotation score (see Section 2.1), and compare it with three other methods for labeling the data, as described below:
Consider an open-ended sound annotation task where 10 workers have to describe a given sound with keywords. The media unit for this task is a sound, the annotation set contains all the keywords workers provide for a sound. The table shows the media unit metrics, as well as the majority vote score for the media unit
Consider an open-ended sound annotation task where 10 workers have to describe a given sound with keywords. The media unit for this task is a sound, the annotation set contains all the keywords workers provide for a sound. The table shows the media unit metrics, as well as the majority vote score for the media unit
The evaluation of the quality of the CrowdTruth method was done by computing the micro-F1 score over each task. The micro-F1 score was used in order to treat each case equally, without giving advantage to annotations that appear less frequently in our datasets. Using the trusted judgments collected according to Section 3.3, we evaluate each media unit – annotation pair as either a true positive, false positive etc. We compute the value of the micro-F1 score using the following formulas for the micro precision (Equation (1)) and micro recall (Equation (2)):
An important variable in the evaluation is the media unit-annotation score (UAS) threshold for differentiating between a negative and a positive classification. Traditional crowdsourcing aims at reducing disagreement, and therefore corresponds to high values for this threshold. Lower values means accepting more disagreement in the classification of positive answers by the crowd. In our experiments, we tried a range of threshold values for each task, to investigate with which one we achieve the best results. The UAS threshold was also used in gathering the set of trusted judgments for the evaluation (Section 3.3). All the data used in this paper can be found in our data repository.7
To perform the evaluation, a set of trusted judgments is necessary to assess the correctness of crowd annotations. For each dataset, we manually evaluated the correctness of all the media unit annotations that were generated by the crowd and the experts. Depending on the task, the number of media unit-annotation pairs can become quite high, so we explored methods to make the manual evaluation more efficient.
For the datasets that contain expert annotation, we calculated the thresholds which yielded the maximum agreement in number of annotations between the crowd and expert annotations. These annotations were then added to the trusted judgments collection, as the judgment in this case is unambiguous. The interesting cases appear when crowd and expert disagree. Previous work we performed in crowdsourcing Medical Relation Extraction [7] has indicated that experts might not always provide better annotations than crowd workers. Additionally, for the Sound Interpretation task we noticed that experts provided considerably fewer tags than the crowd, and there was a large discrepancy between annotations of crowds and experts, with a very small overlap between their annotations. Therefore, instead of simply relying on expert judgment, the annotations where crowd and expert disagree were manually relabeled by exactly one of the authors, and then added to the trusted judgments set, which is also published in our data repository. In the Appendix we present a selection of examples where the expert judgment is different from the trusted judgment. While these cases might call into question the level of expertise of the domain experts, inconsistencies and disagreement in expert annotation are regularly reported in various annotation tasks [17,24,36]. Furthermore, in Section 4 we will show that using the trusted judgments for evaluation still results in the expert performing the best for 2 out of 3 tasks. The only task where the expert underperforms is Sound Interpretation, where the set of annotations provided by the expert is much smaller than the one provided by the crowd.
We collected expert annotations for the Medical Relation Extraction data by employing medical students. Each sentence was annotated by exactly one person. The annotation task consisted of deciding whether or not the UMLS seed relation discovered by distant supervision is present in the sentence for the two selected terms.

CrowdTruth F1 scores for all crowdsourcing tasks.
For the Sound Interpretation task, each sound in the dataset contains a description and a set of keywords that were provided by the authors of the sounds. We consider the keywords provided by the sounds’ authors as trusted judgments given by domain experts.
The news event extraction data was annotated with events by various linguistic experts. In total, 5 people annotated each sentence but we only have access to the final annotations, a consensus among the annotators. In the annotation guidelines described in [46], events are defined as situations that happen or occur, but are not generic situations. In contrast to the crowdsourcing task, where the workers had very loose instructions, the experts had very strict rules for identifying events, strictly based on linguistic features: (i) tensed verbs: has called, will leave, was captured, (ii) stative adjectives: sunken, stalled, on board and (iii) event nominals: merger, Military Operation, Gulf War.
The only task without expert annotation is Twitter Event Identification – as it is in the open domain, no experts exist for this type of data.
CrowdTruth evaluation results, given the highest F1 media unit-annotation score (UAS) threshold
p-values for McNemar’s test of statistical significance in the CrowdTruth classification, compared with the others
We begin by evaluating
Across all four tasks, the CrowdTruth method performs better than both majority vote and the single annotator dataset. While majority vote unsurprisingly performs the best on precision, as a consequence of its lower rate of positive labels, CrowdTruth consistently scores the best for both recall, F1 score and accuracy. These differences in classification are statistically significant, as shown in Table 5 – this was calculated using McNemar’s test [37] over paired nominal data.

The effect of the number of workers per unit on the F1 score, calculated at the best UAS threshold (Table 4). For every point, the F1 is calculated with at most the given number of workers. The number of units used in the calculation of the F1 is shown in the y-axis on the right.
The evaluation of CrowdTruth compared with the expert is more nuanced. For the Medical Relation Extraction and news event extraction tasks, CrowdTruth performs as well as the expert annotators, with p-values indicating there is no statistically significant difference in the classifications. In contrast, for the task of Sound Interpretation, CrowdTruth performs better than the expert by a large margin.
The second evaluation shows the
The effects of the number of workers on the CrowdTruth F1 is clear – more workers invariably leads to a higher F1 score. For the tasks of Medical Relation Extraction, Twitter Event Identification and News Event Extraction, the CrowdTruth F1 grows into a straight line, showing that the opinions of the crowd stabilize after enough workers. For the Sound Interpretation task, the CrowdTruth F1 score is still on an upwards trend after 10 workers, possibly indicating that more workers are necessary to get the full spectrum of annotations.
Figure 4 also shows that CrowdTruth performs better than majority vote regardless of the number of workers per task. For closed tasks, increasing the number of workers has a positive impact on the majority vote F1 score. For open tasks, adding more workers has less of an effect – more workers increase the size of the annotation set for a unit, which is typically larger than for closed tasks, but the agreement is low because opinions are split between possible annotations.

CrowdTruth F1 score evaluation, using expert annotation as ground truth.
Finally, Fig. 5 shows an evaluation of CrowdTruth using only the expert annotations as ground truth (the Twitter Event Identification task does not have experts, so it could not be evaluated). The F1 scores are lower than in the evaluation over the trusted judgments collection. For the Medical Relation Extraction Task, majority vote performs essentially the same as CrowdTruth, whereas for the open-ended tasks, CrowdTruth still performs better. However, as we have shown in the Appendix, the expert annotations contain errors and are sometimes incomplete, particularly in the case of open-ended tasks. The evaluation using expert ground truth was done to show that the trusted judgments set is not biased in favor of CrowdTruth.
The first goal in this paper was to show that the
The gap in performance between CrowdTruth and majority vote is the most striking for open tasks (News Event Extraction and Sound Interpretation). These tasks also require the lowest agreement threshold for achieving the best performance with CrowdTruth. During the trusted judgments collection process, we observed how these tasks are prone to a wide range of opinions – for instance, in the case of Sound Interpretation, there are frequent examples of labels that are semantically dissimilar, but could reasonably be applied to the same sound (e.g. the same sound was annotated with the tag
Our evaluation also shows that processing crowd data with ambiguity-aware metrics performs at least as well as expert annotators, which is not the case for majority vote. Crowdsourcing annotation is significantly cheaper in cost than experts – e.g. even with 15 workers per unit, crowdsourcing for the task of Medical Relation Extraction cost
The variation in the optimal media unit-annotation score (UAS) thresholds across the tasks shows that the level of ambiguity is dependent on the crowdsourcing task, thus supporting our triangle of disagreement model (Section 2.1). It is not surprising that the task with the highest agreement threshold (Medical Relation Extraction) also has the most exact definition of a correct answer (i.e. whether a medical relation is expressed or not in a given sentence). The definition of a medical relation is fairly clear; in contrast, the definition of an event is more subjective, therefore workers were able to come up with a wider range of correct annotations.
The experimental setup provides an empirical method for selecting the optimal threshold for UAS. However, if performing an evaluation with trusted judgments is not possible, selecting the optimal threshold becomes more difficult. For open-ended tasks, the experiments indicate that almost all opinions matter, and the agreement threshold should be as low as possible. In these cases, spam workers can be successfully eliminated by in-task effort consistency checks, and there is no need to enforce agreement beyond that. In contrast, the experiments for closed tasks show higher agreement thresholds tend to work better. The difficulty as well as the subjectivity of the domain also appear to have an impact. The threshold should grow together with the difficulty, and inversely with subjectivity. However, both difficulty and subjectivity might be difficult to measure in practice. In the end, the tuning of the threshold should be regarded similarly to a precision-recall trade-off analysis, where the optimal value depends on the requirements of the ground truth (high precision but many false negative crowd labels, or high recall but more false positives). The high variability for optimal threshold values also shows the limitations of traditional evaluation metrics like precision and recall that rely on discrete labels. CrowdTruth metrics were constructed to measure ambiguity on a continuous scale, but the use of standard metrics resulted in losing this information by forcing the conversion to either positive or negative. Ultimately, our goal is to move away from a binary ground truth that needs to be calculated using a fixed threshold, and instead to use the CrowdTruth metrics to express ambiguity on a continuous scale.
The second goal of the experiment was to show
The stabilization of the F1 score for Medical Relation Extraction, Twitter Event Identification and News Event Extraction is an indication that we have indeed managed to collect the entire set of opinions for these tasks. The fact that the scores all stabilize at different points in the graph (around 8 workers for Medical Relation Extraction, 5 for Twitter Event Identification, and 10 for News Event Extraction) indicates that the optimal number of workers is dependent on the task type, thus also confirming our hypothesis that more workers than what is typically being considered in crowdsourcing studies are necessary for acquiring a high quality ground truth.
There exists a trade-off between cost and quality of annotations that should also be considered when optimizing the number of workers. The higher cost was justified for these tasks, as the expert annotation was three times more expensive than the crowdsourced annotations at expert quality level.
An interesting observation is that the optimal number of workers per task does not seem to influence the optimal UAS threshold for the task. The News Event Extraction requires a high number of workers, but the optimal UAS threshold is low, while the Twitter Event Identification requires a low number of workers, and also a low UAS threshold, at least compared to Medical Relation Extraction.
While four tasks is a small sample to draw conclusions from, our findings seem to indicate that ambiguity in the crowdsourcing system has an impact on both the optimal number of workers per task, as well as the clarity of the media units. These observations will form the basis for our future research in modeling crowd disagreement.
Finally, it is worth discussing the outlier characteristics of the Sound Interpretation task. It is the only task that does not achieve a stable F1 curve (Fig. 4) possibly due to insufficient workers assigned to it. It is also unique in its lack of false positive examples – precision is 1 for the optimal UAS threshold (Table 4), meaning that all labels collected from the crowd were accepted as part of the trusted judgments. Sound Interpretation is also the only task for which the expert annotator performed comparatively poor, with a statistically significant difference from CrowdTruth. As mentioned in the beginning of this section, after collecting the trusted judgments for this task, it became clear that the main challenge for the Sound Interpretation task is not to achieve consensus between annotators, but to collect the entire spectrum of annotations that describe a sound, given that this spectrum is so large (e.g. the tags
Related work
Crowdsourcing ground truth
Crowdsourcing has grown into a viable alternative to expert ground truth collection, as crowdsourcing tends to be both cheaper and more readily available than domain experts. Experiments have been carried out in a variety of tasks and domains: medical entity extraction [21,53,60], medical relation extraction [28,53], open-domain relation extraction [31], clustering and disambiguation [33], ontology evaluation [41], web resource classification [14] and taxonomy creation [11]. [50] have shown that aggregating the answers of an increasing number of unskilled crowd workers with majority vote can lead to high quality NLP training data. The typical approach in these works is to assume the existence of a universal ground truth. Therefore, disagreement between annotators is considered an undesirable feature, and is usually discarded by using either of the following methods: restricting annotator guidelines, picking one answer that reflects some consensus usually through majority voting, or using a small number of annotators.
Disagreement and ambiguity in crowdsourcing
Besides CrowdTruth, there exists some research on how disagreement in crowdsourcing should be interpreted and handled. In assessing the OAEI benchmark, [17] found that disagreement between annotators (both crowd and expert) is an indicator for inherent uncertainty in the domain knowledge, and that current benchmarks in ontology alignment and evaluation are not designed to model this uncertainty. [43] found similar results for the task of crowdsourced part-of-speech tagging – most inter-annotator disagreement was indicative of debatable cases in linguistic theory, rather than faulty annotation. [8] also investigate the role of inter-annotator disagreement as a possible indicator of ambiguity inherent in natural language. [32] propose a method for crowdsourcing ambiguity in the grammatical correctness of text by giving workers the possibility to pick various degrees of correctness, but inter-annotator disagreement is not discussed as a factor in measuring this ambiguity. [48] propose a framework for dealing with uncertainty in ground truth that acknowledges the notion of ambiguity, and uses disagreement in crowdsourcing for modeling this ambiguity. For the task of word sense disambiguation, [27] show that, in modeling ambiguity, the crowd was able to achieve expert-level quality of annotations. [15] implemented a workflow of tasks for collecting and correcting labels for text and images, and found that ambiguous cases cannot simply be resolved by better annotation guidelines or through worker quality control. Finally, [34] shows that often, machine learning classifiers can achieve a higher accuracy when trained with noisy crowdsourcing data. To our knowledge, our paper presents the first experiment across several tasks and domains that explores ambiguity as a property of crowdsourcing systems, and how it can be interpreted to improve the quality of ground truth data.
Crowdsourcing aggregation beyond majority vote
The literature on alternative crowdsourcing aggregation metrics typically focuses on analyzing worker performance – identifying spam workers [10,26,29], and analyzing workers’ performance for quality control and optimization of the crowdsourcing processes [49]. [59] and [56] have used a latent variable model for task difficulty, as well as latent variables to measure the skill of each annotator, to optimize crowdsourcing for image labels. [58] use on-the-job learning with Bayesian decision theory to assign the most appropriate workers for each task, for both text and image annotation. Finally, [45] show that the surprisingly popular crowd choice (i.e. the answer that most workers thought would not be picked by other workers, even though it is correct) gave better results than the majority vote for a variety of tasks with unambiguous ground truths (state capitals, trivia questions and price of artworks).
All of these approaches show promising improvements over the use of majority vote as an aggregating method. These methods were developed only for closed tasks, primarily dealing with classification. However, the novel approach of CrowdTruth allows to explore both closed and open-ended tasks. Furthermore, our focus is on modeling ambiguity as a latent variable in the crowdsourcing system, as well as its role in generating inter-annotator disagreement, which these approaches currently do not take into account. We believe an optimal crowdsourcing approach would combine both ambiguity modeling, as well as specialized task assignment to workers. For instance, [20] developed a generative model to aggregate crowd scores that incorporates features of the data (e.g. number of words), although they do not evaluate the performance of specific features. Ambiguity as measured with CrowdTruth, like the media unit-annotation score, could be used as a data feature in such a system.
Conclusions
Gathering human annotation is a major bottleneck in the process of knowledge base curation. Crowdsourcing-based approaches are gaining popularity in the attempt to solve the issues related to volume of data and lack of annotators. Typically these practices use inter-annotator agreement as a measure of quality. However, by ignoring inter-annotator disagreement, these practices tend to create artificial data that is neither general nor reflects the ambiguity inherent in the source.
In this paper we presented an empirically derived methodology for efficiently gathering of human annotation by aggregating crowdsourcing data with CrowdTruth metrics, which harness the inter-annotator disagreement. We applied this methodology over a set of diverse crowdsourcing tasks: closed tasks (Medical Relation Extraction, Twitter Event Identification), and open-ended tasks (News Event Extraction and Sound Interpretation). Our results showed that the ambiguity-aware CrowdTruth approach allows us to collect richer data, which enables reasoning about the ambiguity of the content being annotated. This is intrinsically relevant to the Semantic Web community, i.e. to identify the semantics of ambiguity across all modalities, e.g. text, images, videos and sounds. Our results also showed that, in all the tasks we considered, such ambiguity-aware quality scores provide better ground truth data than the traditional majority vote. Moreover, we have shown that CrowdTruth annotations have at least the same quality, even better in the case of Sound Interpretation, as expert annotations. Finally, we showed that, contrary to the common crowdsourcing practice of employing a small number of annotators, adding more crowd workers actually can lead to significantly better annotation quality.
In the future, we plan to expand our methodology to more complex annotation tasks, that require multiple or combined types of input beyond the closed/open-ended categorization we presented in this paper. We are also working on expanding the CrowdTruth metrics for ambiguity to incorporate the state-of-the art in modeling crowd worker and data features [20]. Finally, we want to use the CrowdTruth data in practice for training and evaluating information extraction models used to populate the Semantic Web.
Footnotes
Acknowledgements
We would like to thank Emiel van Miltenburg for assisting with the exploration of feature analysis of sounds, Chang Wang and Anthony Levas for providing and assisting with the medical data, Zhaochun Ren for the help in gathering the Twitter dataset, Tommaso Caselli for providing the news dataset, and the anonymous crowd workers for their contributions to our crowdsourcing tasks.
Example media units where the expert judgment is different from the trusted judgment
Example sentences from the medical relation extraction task where the expert judgment is different from the trusted judgment. The pair of terms that express the medical relation are shown in italic font in the media unit
Media unit
Annotation
Expert judgment
Crowd score
Trusted judgment
The epidermal nevus syndrome is a neurocutaneous disorder characterized by distinctive skin lesions and often serious somatic and central nervous system (CNS) abnormalities.
cause
no
0.98
yes
For empiric treatment of epididymitis, especially when gonococcal or chlamydial infection is likely Ofloxacin or levofloxacin should be used only if epididymitis is not caused by gonorrhea.
treat
no
0.966
yes
In contrast, we did not find a definite increase in the LGL percentage within 6 months postpartum in patients with Graves’ disease who relapsed into Graves’ thyrotoxicosis.
cause
no
0.738
yes
The 1 placebo controlled trial that found black cohosh to be effective for hot flashes did not find estrogen to be effective, which casts doubt on the study’s validity.
treat
no
0.73
yes
Multicentric reticulohistiocytosis (MR) is a systemic disease of unknown cause characterized by the presence of a heavy macrophage infiltrate in skin and synovial tissues and the development of an erosive polyarthritis.
cause
yes
0.697
no
Urokise versus tissue plasminogen activator in pulmonary embolism.
treat
yes
0.365
no
The principal differences between these vaccines are the transmission of live vaccine viruses from recipients to their contacts and the occurrence of occasional cases of paralytic poliomyelitis associated with use of live poliovirus vaccine
treat
yes
0.1
no
These cases highlight the importance of considering PTLD in the differential diagnosis of lymphadenopathy.
cause
yes
0.09
no