
Abstract
The Henri Poincaré correspondence is a corpus of letters sent and received by this mathematician. The edition of this correspondence is a long-term project begun during the 1990s. Since 1999, a website is devoted to publish online this correspondence with digitized letters. In 2017, it has been decided to reforge this website using Omeka S. This content management system offers useful services but some user needs have led to the development of an RDFS infrastructure associated to it. Approximate and explained searches are managed thanks to SPARQL query transformations. A prototype for efficient RDF annotation of this corpus (and similar corpora) has been designed and implemented. This article deals with these three research issues and how they are addressed.
Keywords
Introduction
Jules Henri Poincaré is a great name of the history of science. Born in Nancy (France) on April 29, 1854, he died in Paris on July 17, 1912.
His name is associated with discoveries or works of primary importance. He is responsible for, among other things, the discovery of Fuchsian functions in mathematics, an essential contribution to the resolution of the Three-Body problem in celestial mechanics, for which he won the Oscar II Prize, King of Sweden’s mathematical competition, in 1889, as well as the introduction in topology of the concepts of homotopy and homology. His theoretical research on new mechanics after 1900 prepared the discovery of the special theory of relativity by Albert Einstein in 1905.
Mathematician, physicist, astronomer, research administrator, Henri Poincaré was also very active in the field of philosophy as a regular contributor to the Revue de métaphysique et de morale. His philosophical books, such as La science et l’hypothèse [Science and Hypothesis] [26] contributed to the birth of French philosophy of sciences and gave him a great reputation in France and at international level. Although not very engaged on the political scene, he nevertheless played a significant role in the Dreyfus Affair through several mathematical expertises.
Henri Poincaré was elected in 1887 at the Académie des sciences of Paris, at the age of 33. Throughout his life he was also a member of the Bureau des longitudes (1893), of the Académie Française (1908) and of numerous foreign learned societies and academies.
In 1992, the laboratory of history of science and philosophy Archives Henri Poincaré was created to study Henri Poincaré’s manuscripts and to organize the publication of his scientific and private correspondence. For more than 25 years, this long-term project has produced four volumes of letters. The first one is devoted to the letters exchanged between Henri Poincaré and the Swedish mathematician Gösta Mittag-Leffler [23]. The second one concerns the correspondence with physicists, chemists and engineers [30]. The third volume gathers the correspondence with astronomers and, in particular, geodesists [31]. The fourth one deals with the Henri Poincaré’s youth correspondence [28]. Two other volumes are in preparation. The first one will be devoted to the letters from or of mathematicians. The second will contain Henri Poincaré’s administrative, academic and private correspondence.
The corpus1
The notion of corpus is in accordance with the terminology in history i.e. a collection of documents of a specific subject gathered and stored to be exploitable. In natural language processing, the appropriate term could be semantic digital library.
Due to copyright laws, some images of letters are not available online, though transcripts are.
Different projects exist that are devoted to scientific correspondences for example the CKCC project (

Plain text search engine exists for the letters that are already transcribed5
The search-engine Solr is installed in the platform.
This article is organized as follows. Section 2 presents the Henri Poincaré correspondence and how it was edited, annotated and published on the web of documents. It has appeared that principles and technologies of the Semantic Web should prove useful for the exploitation of this corpus, in particular, the RDF(S) technology that is briefly recalled in Section 3, with some examples related to the corpus. The remainder of the paper presents three main works related to Semantic Web for the Henri Poincaré correspondence. Section 4 explains how the RDF(S) infrastructure is added on the Henri Poincaré correspondence website, which involves some translation mechanisms. This makes possible the interrogation of this corpus by SPARQL queries. The need for more flexible querying is motivated in Section 5, together with a way of handling this flexibility. Finally, the prototype of a tool for efficient editing of RDF triples for the purpose of indexing the Henri Poincaré correspondence is described in Section 6.
From 1999 to 2015, the Henri Poincaré Papers website which was created and maintained by Scott Walter to highlight the Henri Poincaré correspondence knew several developments. The last version was a web application associated with the open source full text search engine Sphinx.6
OAI-PHM is a protocol developed by the Open Archives Initiative for harvesting metadata description of archives. It is mainly based on the Dublin Core model. See
In 2017, the Archives Henri Poincaré decided to reforge the website. In order to better structure the site and to benefit from semantic annotation, this new platform has been based on the content management system (CMS) Omeka S.8

Example of transcription and metadata from a letter.
Omeka S allows semantic annotations. In the backoffice, several vocabularies are already available: Dublin Core Terms, Friend of a Friend, and Bibliographic Ontology. Adding other vocabularies is possible, like the Archives Henri Poincaré Ontology.9
For now, this ontology is rather basic. It still requires an epistemological investigation which will rely on other ontologies in digital humanities such as the CIDOC-CRM ontology (
For all letters, there are two types of indexing. The first one is a physical description (type of letter – telegram, autograph letter, minutes, etc. –, number of pages, location of the letter within the archive, sender, recipient, date and place of expedition, etc.). Some pieces of information are missing. For example, there are letters for which the exact sending date is unknown, but for which the year and the month are known from the context and associated to the letter.
The second type of indexing relates to the content of the letters; all relevant information can be indexed (see Fig. 2 for an example). These data are relevant from the viewpoint of historians. For instance, people or publication quoted, mathematical theories or formulae, philosophical concepts are taken into account.
This section makes a presentation of RDF, RDFS and SPARQL that is simplified for the needs of this article, and exemplified in the domain of the correspondence of Henri Poincaré.
The atoms of RDF are resources and literals. A resource is either anonymous or named. An anonymous resource (aka blank node) is an existentially quantified variable; by convention its identifier starts with a question mark (e.g.,
An RDF triple is a triple

Examples of indexation by RDF triples.

An RDF graph
RDFS is a logic whose language is RDF and inference relation ⊢ is defined by a set of inference rules, that are based on some given resources:
Let p, q and r be properties, x and y be resources, and C, D, E and R be classes. The inference rules considered in this paper are
SPARQL is a query language for RDF. In this article, SPARQL querying is assumed to be performed by an engine using RDFS entailment, meaning that querying an RDF graph

More generally, the execution of a SPARQL query Q on an RDF graph

The Henri Poincaré website is hosted and managed using a Huma-Num service. Huma-Num is a French infrastructure dedicated to Digital Humanities [17]. A system, branded “Huma-Num Box”, has been developed to address several issues related to the treatment of data for Humanities (scalability, volume, accessibility, security, etc.). Using such a service enhances the development of standards when dealing with Digital Humanities. The Omeka S instance (vocabularies, content, website modules, etc.) has been installed on a shared server.
Omeka S comes with a search engine called Solr,10
Solr is an open source search platform built on Apache Lucene.
An automatic script retrieves data from Omeka S to update this RDFS base on a daily basis.11
However, although Omeka S allows export to different data formats, Turtle is not part of it. The script exports Omeka S data in JSON-LD format, and then converts it to Turtle before updating the RDFS base.
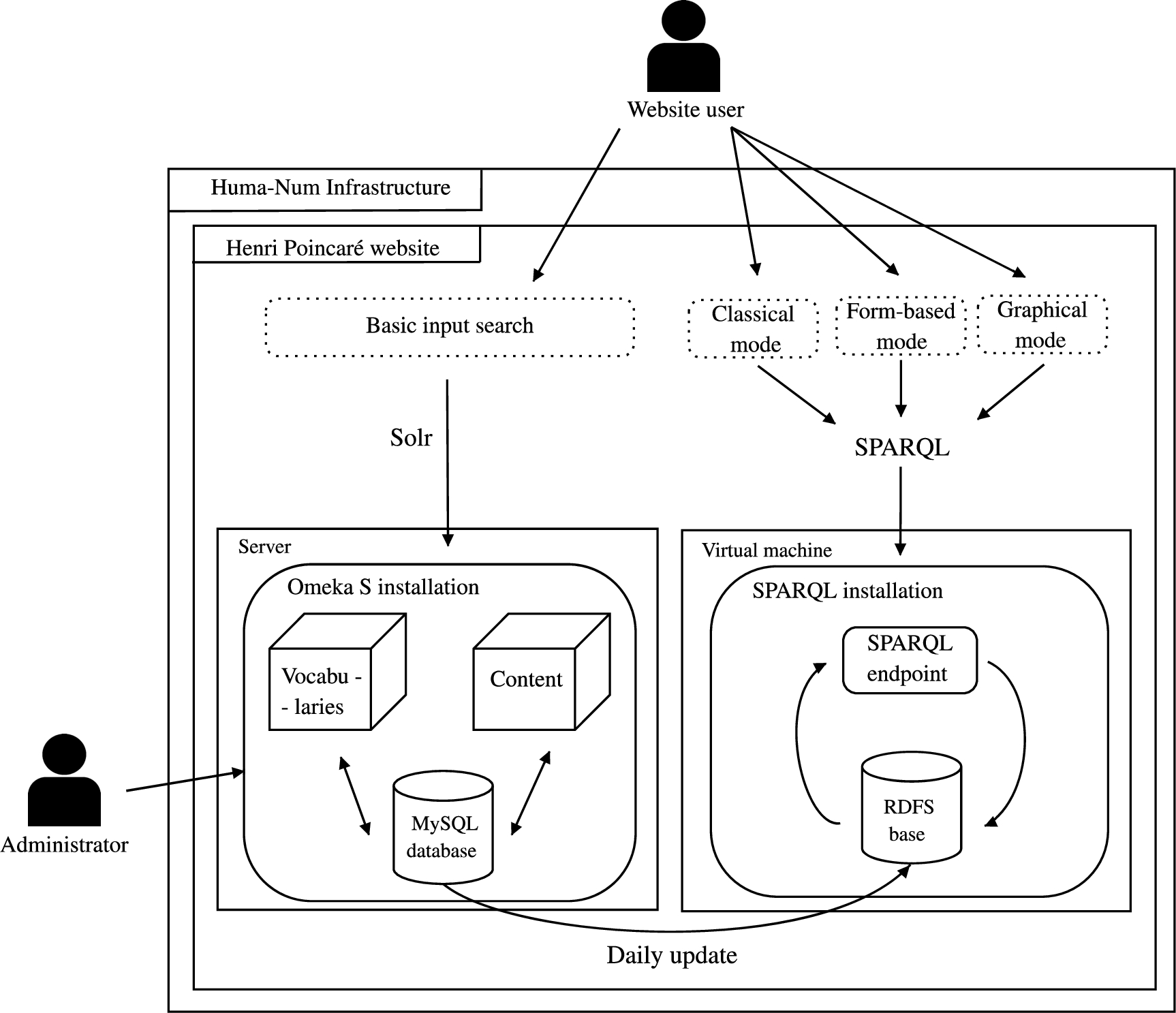
The architecture of the Henri Poincaré website.
On the website, a user can choose between using the basic input search and creating more complex queries with SPARQL. Three SPARQL query editing modes are proposed:
The user can directly write SPARQL queries, within a text area, to access the RDFS database It allows creating complex queries by taking advantage of the expressiveness of the SPARQL language. But this requires a good understanding of SPARQL syntax which is not well suited for historians of science and people that are not familiar with the Semantic Web technologies.
A form containing a set of inputs is proposed to the user to help him/her building the query. This is a mode suitable for all users, as it does not require any specific knowledge.
A graphical interface is presented to let the user construct a graph corresponding to an inference graph. This mode can be a good compromise because it is not too difficult to apprehend, but also keeps a certain expressiveness when formulating queries. The interface has been created using D3.js library, which is adapted for manipulating documents based on data [3].
It is important to mention that the different blocks shaping the website are invisible for users. They can easily retrieve data they are interested in by choosing the appropriate search engine. In practice, for the daily use, historians and experts of the domain tend to use the form-based and graphical modes. Figure 4 illustrates the website architecture presented above. For the historians, Omeka S grant access to a specific back interface to visualize and update data (collections, vocabularies and content). As the data transfer from Omeka S to the RDFS base is automatic, they do not need to manage this particular task.
Consider a user who wants to express the following informal query using SPARQL:
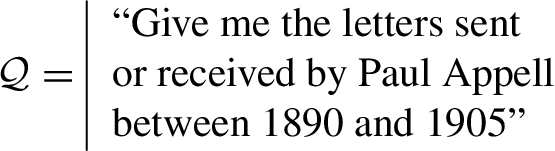
He/she can use any of the three modes to express the SPARQL query and to find the corresponding letters. Figure 5 shows the edition of this query in the three modes.

SPARQL query editing modes available on Henri Poincaré website (
To be exploitable, the Henri Poincaré correspondence has to be queried. SPARQL querying, with adequate user interfaces, serves this purpose. However, more flexible searches can be useful, which is explained in Section 5.1. The way flexible searches are managed is based on SPARQL query transformations, as explained in Section 5.2. These transformations are based on rules, and a tool for expressing and managing these rules is briefly presented in Section 5.3. This work is implemented and works well, but can be improved: some future improvements are described in Section 5.4.
Motivating approximate and explained searches
Two reasons why flexible search is useful in the context of the correspondence of Henri Poincaré are presented below and exemplified.
Taking into account vagueness Consider the following informal query:
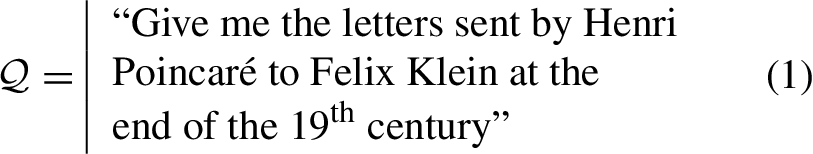
The time period “end of the
Some historians of science state that the end of the
One way to handle these kinds of informal queries, where boundaries of notions are imprecise, consists in using the tools of fuzzy set theory: a fuzzy query with a kernel corresponding to the years
Finding related results Now, consider a historian of science querying the corpus about the query

The execution of this query gives a set of letters that match exactly the formulated query
The set of results is empty or, at least, too small (for the historian accessing the corpus): the historian may desire that the system provides more letters associated to explanations pointing out the mismatch between these letters and the query, something like “This is not a letter about complex analysis but it is about analysis.”
The corpus is incomplete: there exist letters sent or received by Henri Poincaré that do not exist anymore and also, there probably exist such letters that are not yet discovered. However, there may be a letter
Different tools and methods have been proposed to deal with the notion of approximation when using SPARQL querying. The f-SPARQL engine [7] is a flexible extension of SPARQL which introduces the use of fuzzy set theory. Several new terms and operators (
Query transformations can be useful for taking into account vagueness and for finding results that are related to the query but do not match it exactly. A method proposes a framework to relax query by analysing the failing causes of the initial query [11].
Another line of work related to this issue is the approach of case retrieval in case-based reasoning based on query transformations that has been applied in various application domains with various query languages (e.g., in machine translation [29], organic chemistry synthesis [18] and cooking [9]).
An approach based on the use of transformations rules is explained in the next section.
Consider first the informal query

Let
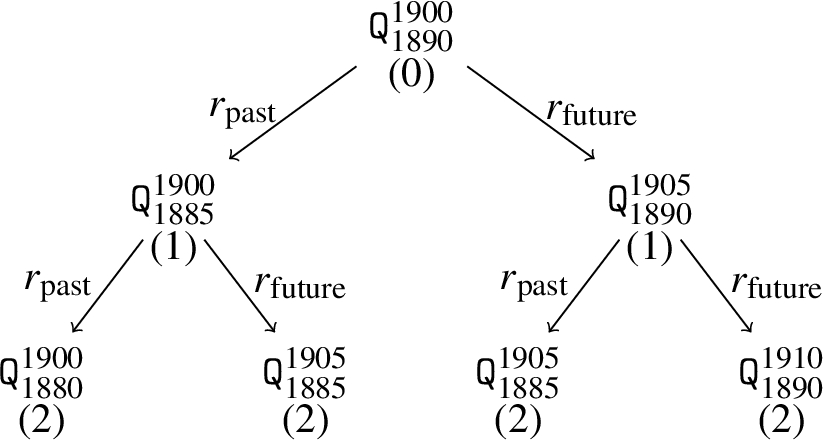
A search tree (truncated at depth 2) for an informal query related to the end of the
To implement this idea, the notion of SPARQL query transformation rules is considered. Let
Thus, the informal query
For the example of the query Substitution of the predicate p of a triple by a superproperty q of p (i.e., Substitution of the object o of a triple If the body of a query If the body of a query
A generalization rule is a rule r such that if
SQTRL (SPARQL Query Transformation Rule Language) is a language associated with a tool designed for handling SPARQL query transformations. This tool has been used in various application contexts [4].
An SQTRL transformation rule r is characterized by the following fields:
The RDFS triples of such a rule appear in SPARQL syntax.
Given an RDFS graph
For example, consider first the query transformation rule
The rule
An XML syntax has been chosen to properly define a transformation rule. As an example, Fig. 7 illustrates the XML syntax associated with the rule

An example of SQTRL rule in XML syntax.
The SQTRL tool internally reuses the Corese engine [8]. Such an engine enables to query Semantic Web data, stored as RDF(S) files.
The current version of SQTRL has some limitations that require to be overcome. This section lists some of them and points out future studies for addressing them.
The first limitation is related to the costs associated to a rule: such a cost is a constant, whereas it is sometimes more relevant to have costs that depend on the bindings of anonymous resources occurring in the rule (in the fields
The second limitation is linked with the unnecessary applications of some rules given the rules already applied in the same branch of the search tree. For example, it is not necessary to apply sequentially twice the rule
The third limitation is related to the filter statements of the SPARQL queries. Currently, only filter statements representing intervals (e.g.,
The fourth limitation is more domain-dependent since it is related to the notion of time in history. For example, the rules
In particular data for history,
Currently, the Henri Poincaré correspondence is indexed in a satisfying way by RDFS files. However, new properties may emerge from research in history that would require additional annotation work and, more importantly, new correspondence corpora exist that are not yet annotated and that are of interest for nearby colleagues in history of science. This justifies the development of an editing tool of RDF triples for the purpose of corpus annotation. The RDF graph
RDFWebEditor4Humanities: An editor for indexing corpora

A screenshot of RDFWebEditor4Humanities.
The indexing work done by historians of science for the Henri Poincaré correspondence was mainly done using the user interface of Omeka S: the RDF files are generated by translating the information edited via Omeka S (in a SQL server) to RDF, as described before, in Fig. 4. It was decided to implement an RDF triple editor prototype for the new annotation tool in order to benefit from the RDF(S) infrastructure.
Several tools and methods have been proposed to assist users in RDF data editing. Protégé [24] is one frequently used tool which benefits from an user friendly interface but lacks of real assistance to find resources and to edit new triples. Several methods use language processing to let users edit RDF databases in a simpler way. For example, the GINO editing tool [2] introduces a guided and controlled natural language to define statements. Another example is the CLOnE language [12] which provides a method for editing data without any knowledge about Semantic Web standards.
Figure 8 presents a screenshot of the developed interface. An autocomplete mechanism has been implemented which assists users in writing triples values. Applying such a filter is particularly relevant when working with a base containing a large number of triples. The set of potential values for a field are ranked according to the alphabetical order.
The editor also displays the context of the edition. For the edition of a correspondence, the context is a letter and the already edited triples about this letter. If the current letter is
When editing a state for which only one of the three values is missing, the tool avoids giving to the user a value that forms a triple already known. For example, when the subject s and the predicate p are already edited, the values o resulting from the query
Figure 8 example displays the context of the letter which is currently being edited. This letter is identified as item no9866 of the Henri Poincaré database and its context contains four triples.
Consider an expert indexing the Henri Poincaré correspondence:
For example, consider the editing question Either Or

A screenshot of RDFWebEditor4Humanities using RDFS deduction to rank the set of potential values.
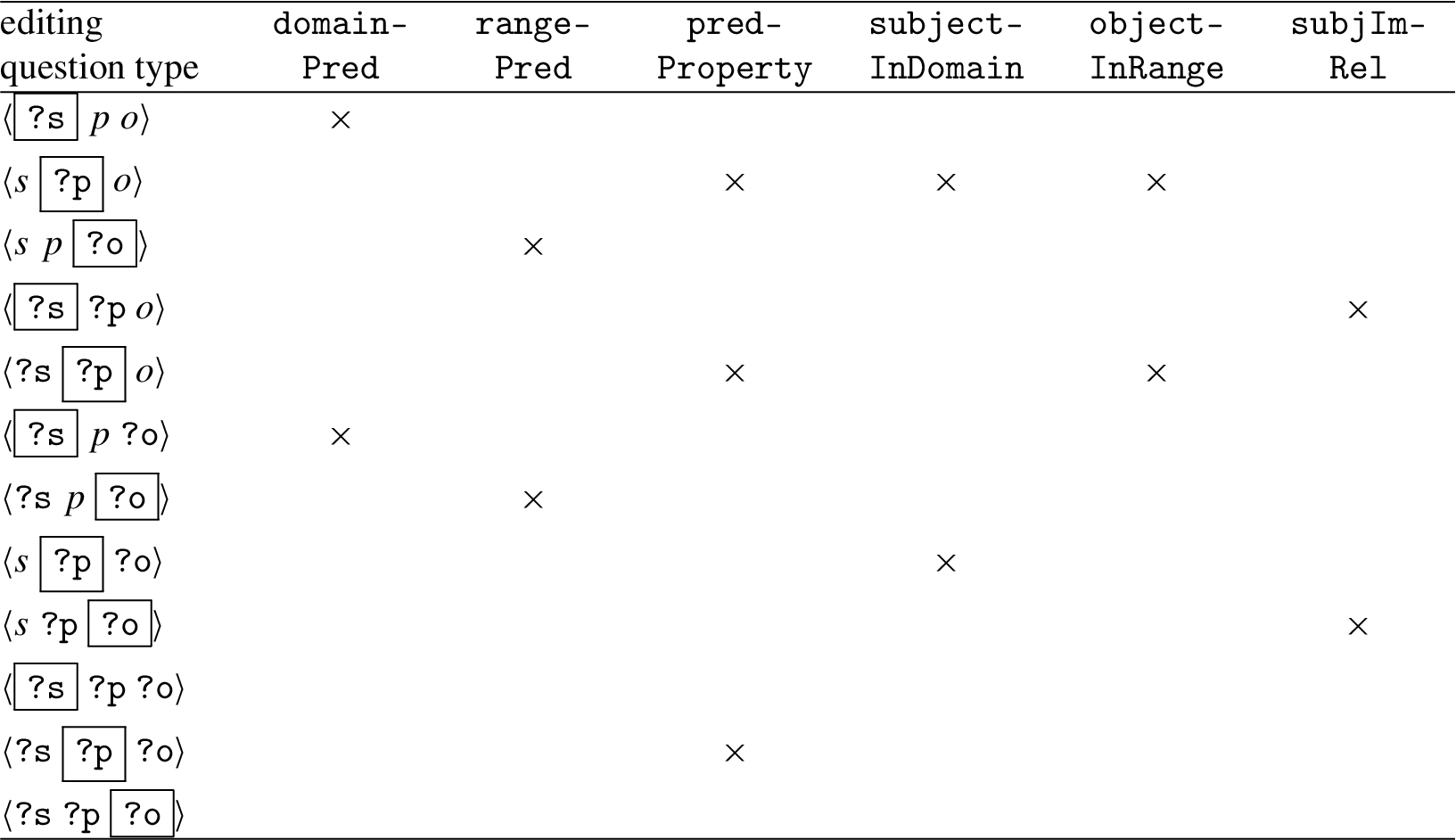
Editing question types and associated features of candidate values.
This editing question is of the type
Consider an editing question of the type
For the editing questions of the type

For the editing questions of the type
For editing questions of the type
For the other possibilities no re-ranking is provided in the current version of the tool.
Figure 9 illustrates the use of RDFS deduction in the edition tool. The editing question is the same as the one presented in Fig. 8. This is a question of the type
As the class
The work presented in this section is freely inspired from the research on the UTILIS system that assists users in RDFS graph updating [15] and on the case-based reasoning methodology.
Case-based reasoning (CBR [27]) aims at solving problems with the help of a case base, where a case is a representation of a problem-solving episode. The target problem is the problem currently under resolution. A source case is an element of the case base. The reasoning process is usually composed of several steps: (1) retrieval chooses one or several source cases judged similar to the target problem, (2) adaptation modifies, if necessary, the retrieved case, (3) storage adds the newly formed case, possibly after a correction from the user. In this ongoing work, only retrieval is considered (adaptation is currently a mere copy and storage is quite straightforward).
In this application framework, a problem is an editing problem, defined by an editing question (as in the previous section), and the context of the problem (as defined in Section 6.1). For example, consider the following target problem for the running example developed below:

A solution is a plausible value for the highlighted field in the editing question of the problem. The set of edited data,
The retrieval step aims at extracting cases from
So, the question is how to assess the similarity between a letter and the target problem. The answer proposed for the UTILIS system cited above is based on query relaxation. For RDFWebEditor4Humanities, this idea is reused, and query relaxation is replaced with SQTRL query transformation (cf. Section 5). More precisely, the target problem

Then retrieval amounts to an approximate search, as described in Section 5, taking
With the running example, consider only the SQTRL rules

The execution of

The execution of
Finally, the transformation cost for obtaining
This work and its combination with the work of Section 6.2 are still in their early stages, so it is not evaluated yet and thus, not considered in the next section.
A first evaluation
A first evaluation has been carried out that is fully automated, though it is acknowledged that a complete evaluation of an editing tool has to involve human editors.
For this evaluation, the baseline is the editor tool using only alphabetical order to rank the values (cf. Section 6.1) and it is compared to the editing prototype using RDFS entailment (cf. Section 6.2). The autocomplete mechanism has been disabled for the automatic evaluation.
Given an editing question
The test set is built on the basis of the current RDF graph
Initially,
For each triple
For each of the 3 fields subject, predicate and object, considered in a random order,
Let
Let
Add
Add
At the end
The results are presented in Fig. 11.

The average and the standard deviation of the values
Although the evaluation has been carried out on a subset of the Henri Poincaré Correspondence, this was constructed in order to be representative of the whole correspondence. What emerges of these results is that the use of RDFS deduction brings a better general ranking and thus could effectively assist historians during the indexing work.
It is noteworthy that the tool presented here is still a prototype needing some technical and ergonomic improvements that are necessary before carrying out the complete evaluation involving human users.
The CBR approach presented in Section 6.3 is not fully implemented (and not evaluated) and this constitutes the first future work.
The combination of the deductive and CBR approaches for editing also has to be investigated. In particular, the following hypothesis is made: the editing improvements of these methods are largely independent one from the other, so a well-designed combination of them should give interesting results. One promising way to do such a combination is to apply one of these methods and then, to decide between the ties using the other method. More sophisticated combination techniques can also be investigated.
Another future work is related to the deductive approach and can be illustrated by the example of the editing question
A last potential future work would be to integrate this work in an existing RDF editing tool such as Neologism [1], Protégé [24] and Vitro [19].
Conclusion and future work
The Henri Poincaré correspondence is a corpus gathering letters received and sent by this famous scientist. This article has presented the application of Semantic Web technologies on this corpus. Before these technologies were used on this corpus, letters were digitized, transcribed in plain text and associated to metadata, within the content management system Omeka S.
Then, a translation script of these pieces of information into RDFS has been implemented, which has made possible the access to the corpus via an RDF endpoint using the vocabularies of standard ontologies and also the ontology developed for the purpose of this corpus. Therefore, the SPARQL querying became possible, and three user interfaces were developed for this purpose: a classical interface with the whole SPARQL querying, a form-based interface more suited to the habits of the users and an interface using a graphical view.
Now, SPARQL querying is sometimes insufficient, when approximate searches are needed. This is the case when vague notions have to be taken into account in the query (e.g., “the end of the
Currently, the indexing of the corpus is done via Omeka S. It is planned to do it directly in RDFS and an editing tool is currently under study. A prototype has been developed in which the user edits each element of a triple by selecting a resource in a list (or creating a new resource or a literal). This prototype has been improved by the use of RDFS entailment in order to propose most promising values first. Another (potential) improvement of this prototype using case-based reasoning principles has been presented and is an ongoing work.
These contributions have different degrees of maturity and have been presented from the more mature one (that is currently in use) to the less mature one (that is an ongoing work). To the best of our knowledge, there exists no other work that uses the methods presented in this article in the context of cultural heritage. Future works have been planned for approximate and explained search and for assisted indexing of triples (cf. Sections 5.4 and 6.5) and are not recalled here. Therefore, the first ongoing work consists in putting all these contributions in practice so that they are all as routine uses.
Another future work will aim at dealing with uncertainty and imprecision of some information about the letters, and, more specifically, about the dates. When the date is written in the preamble of a letter, it is reasonable to consider it as its writing date, but in many letters this information is missing. However, an imprecise date can be given, e.g., because it relates to an event (a historical event or a relation to another letter that is well-dated). In such situations, the precise date is often difficult to know, thus an imprecise date (e.g., giving only the month and the year) is associated to the letter. Sometimes, a precise yet hypothetical date can be inferred by historians, e.g., when the letter refers to something that is interpreted by a historical event. Dealing with imprecise and/or uncertain dates is a challenging issue that requires both a careful ontology modeling and inference mechanisms. Another challenge related to the ontology is the representation within it of mathematical formulae. Historians of science would benefit from the implementation of a search engine for mathematical content. Different methods have already been investigated [10] and should be considered in order to propose an integration in the framework of this research.
In this paper, the representation formalism for the ontologies and for the data does not go beyond RDFS. However, in order to carry out some of the future studies described in this conclusion as well as in other sections of the paper, the use of larger fragments of OWL is likely to be required. For instance, in Section 6.5, it was shown how the use of negation can improve the editor using entailment. It was also noted in this same section that the issue of computing time increasing potentially involved by a more expressive formalism can be harmful to the practical use of such a system. Some offline deductions may be used to alleviate the online computing burden.
Although this work has been carried out for the Henri Poincaré correspondence, it is planned to be applied to other correspondences of known scientists. More widely, it should be reusable for another history of science corpora.
Footnotes
Acknowledgements
This work was supported partly by the French PIA project “Lorraine Université d’Excellence”, reference ANR-15-IDEX-04-LUE. It was also supported by the CPER LCHN (Contrat de Plan État-Région Lorrain “Langues, Connaissances et Humanités Numériques”) that financed engineer Ismaël Bada who participated to this project.