
Abstract
RDF data has been extensively deployed describing various types of resources in a structured way. Links between data elements described by RDF models stand for the core of Semantic Web. The rising amount of structured data published in public RDF repositories, also known as Linked Open Data, elucidates the success of the global and unified dataset proposed by the vision of the Semantic Web. Nowadays, semi-automatic algorithms build connections among these datasets by exploring a variety of methods. Interconnected open data demands automatic methods and tools to maintain their consistency over time. The update of linked data is considered as key process due to the evolutionary characteristic of such structured datasets. However, data changing operations might influence well-formed links, which turns difficult to maintain the consistencies of connections over time. In this article, we propose a thorough survey that provides a systematic review of the state of the art in link maintenance in linked open data evolution scenario. We conduct a detailed analysis of the literature for characterising and understanding methods and algorithms responsible for detecting, fixing and updating links between RDF data. Our investigation provides a categorisation of existing approaches as well as describes and discusses existing studies. The results reveal an absence of comprehensive solutions suited to fully detect, warn and automatically maintain the consistency of linked data over time.
Introduction
In recent years, a large number of knowledge bases interconnected on the Web have emerged describing various types of resources in a structured way. In particular, Linked Data (LD) refers to machine-readable data connecting datasets across the Web [44], by exploring Semantic Web technologies such as Resource Description Framework (RDF)1
Links between RDF descriptions are at the heart of the Web of Data. The growing number of structured data published as RDF repositories in the Web confirms the real potentiality of the global data space proposed by the Semantic Web vision. Indeed, connections between data elements described via RDF models are in the center of the Semantic Web [4]. The interconnection of RDF statements, via explicit links, plays a central role in this scenario to assure data linkage. The links allow previously isolated bases to be explored in combination.
RDF statements defining real-world resources are subject to change when the domain updates. This evolution comes from emerging number of contributions by governments, private institutions, Wiki databases (such as DBpedia)2
This scenario hampers data linkage consistency over time. The manual maintenance remains hardly accomplishable due to the overwhelming number of links available. Often external links disappear without notifying their dependants. Since links should not be recomputed each time a change occurs, novel methods are required to adequately consider the evolution. The evolution of the RDF datasets should be as much automated as possible, even though the possibility provided to users edit their content and validate changes should be assured [8]. This evolutionary characteristic of the LOD causes the link maintenance problem which is in the root of a research line known as the broken links.
The constant and evolving process of updating datasets demands the study and development of novel methods and software tools [35]. In general, RDF resources are linked by semi-automatic algorithms [24] [31] and these links are manually evaluated, which involves huge amount of labour cost and time. Usually RDF links between data sources are updated only sporadically, which leads to dead (broken) links pointing to URIs that are no longer maintained [4]. Currently, there is a huge mass of interconnected data that requires automatic methods and tools to deal with consistency aspects. In this context, Web dynamics tends to update data definitions on an isolated basis [1,23]. This aspect sets up a challenging research scenario to deal with the controlled evolution of interconnected datasets. The design and implementation of novel software tools must concern these factors and address them in various perspectives. These aspects represent serious obstacles towards a fully automatic solution, requiring a complete and exhaustive survey of existing approaches focused on addressing this issue.
With the advent of the LOD, researches emerged to study problems caused by its exponential expansion, ranging from scalability issues [20], URI synonymity [17] as well as dataset quality [45]. However, the literature has superficially studied the maintenance of linked datasets [30] and the mapping evolution phenomena between biomedical ontologies [9]. To the best of our knowledge, it lacks thorough investigations empirically grounded to unveil how links evolve in the context of linked datasets. In our previous work, we empirically analysed several cases of link modifications by studying the evolution of datasets in the domain of life sciences [33]. Our study investigated if there were correlations between changes in triples and changes in links by considering 12 scenarios involving addition, removal and modification of triples and links in the Agrovoc3
In this article, we provide a systematic literature survey to thoroughly understand existing contributions addressing link maintenance. In summary, we make the following contributions:
We formally define and illustrate the link maintenance problem, highlighting the complexity of the problem. We illustrate examples to clarify the involved issues and explore them throughout this article.
We systematically review the literature on the link maintenance problem, offering a comprehensive state-of-the-art by presenting, comparing and discussing existing proposals in several categories identified via our literature analysis.
We analyse lacks of existing approaches discussing open issues that the literature fails to address towards a fully automatic link maintenance. This allows us to underscore open research challenges.
In the view adopted in this paper, a systematic literature review identifies the extent and form the literature on a topic to obtain a broad review of key studies from a specific topic during the initial examination of a new domain. A literature review is valuable to gather existing information about a subject in a formal, complete, impartial and meticulous manner [5]. Our methodology was conducted based on a series of steps responsible for planning, retrieving and analysing the scientific papers selected on the search on huge scientific databases. The methodology involved defining research questions to be answered through this investigation, establishing the terms and in which databases the queries are performed. We defined inclusion and exclusion criteria for selecting the relevant retrieved papers. Our literature analysis provided an organisation of the papers based on distinct categories as approaches related to link maintenance problem.
The results achieved via a careful analysis of the literature indicate that there are solutions for detecting broken links – some of them with scalability issues given the size of the datasets. However, none of them are able to fix broken links of any kind, in the context of Linked Data, without the assistance of human throughout the process.
The remaining of this paper is organized as follows: Section 2 defines and formalizes the link maintenance problem; Section 3 describes in details the methodology conducted in our systematic literature review; Section 5 presents the obtained results indicating our literature analysis and explaining the categories of solutions found related to the problem; Section 6 carefully discusses our findings and reports on open challenges of different nature with unsolved research questions. Finally, in Section 7, we wrap up the article with concluding remarks and outline future work.
Before we formally define the link maintenance problem, we provide basic concepts referring to Linked Data and its essential elements.
Linked Data refers to “[…] a set of best practices for publishing and connecting structured data on the Web in a way that data is machine-readable, its meaning is explicitly defined, it is linked to other external datasets” [44]. The Linking Open Data initiative, known as LOD cloud, started its activity in 2007 with the premise of being a “grassroots community effort to bootstrap the Web of Data by interlinking open-license datasets” [44]. From that period, the LOD cloud has grown substantially. Nowadays, a huge quantity of RDF datasets has been published and present interconnections from one dataset with others.
A literal is a string combined with either a language identifier (plain literal) or a data-type (typed literal). Blank nodes are those nodes representing the resources for which a URI or literal are not given. As an example of triple considering the notation
dbr:Abraham_Lincoln dbo:birthDate “1809-02-12”ˆˆxsd:date;
dbo:birthPlace dbr:Hodgenville,_Kentucky.
From now on, we use the notation
The connection between nodes of a source and destination node can be broken by several reasons, which changes the state of the link to broken or invalid. According to Popitsch and Haslhofer, a link is broken when “[...] the representations of the target resource were updated in such a way that they underwent a change in meaning the link-creator had not in mind” [31].
Some authors categorize the broken links in two main groups. A link is structurally broken, as stated by Singh, Brennan and O’Sullivan, “if either source or target are no longer dereferenceable” [38]; and also by Popitsch and Haslhofer “if its target resource had representations that are not retrievable anymore” [30]. A link is semantically broken when the semantic of data in the target dataset is different from the semantic of the source [19]. Semantically broken links are harder to detect and fix [30].
When a broken link is found by someone in traditional hypermedia, the one who found it might search for alternative paths to the same or similar location, different from the machine-to-machine communication present in linked data [30]. Vesse et al. [42] divided the link integrity in two main categories: (1) the dangling link, where the destination node no longer exists and takes to nowhere; and (2) the editing problem, in which the destination node still exists, but the semantics of this node changed over time and the link does not provide any reliable information.
As an example of broken link, we found a real scenario at Agrovoc linked open data.6
Represented by the end of the URI,

Real-world example of broken link.
At this stage, we introduce the notion of time

Link maintenance problem.
An example of semantically broken link caused by the evolution of the dataset is the “London” example. In dataset A we have the resource with label “London”, as long as in dataset B. They are connected by a “sameAs” predicate, forming a link between the “London” resources. The maintainer of the ontology A decides to change the resource from “London” to “Greater London”. Now, “Greater London” from dataset A is linked to “London” in dataset B. London and Greater London are different in many aspects such as population number, area and climate. The link became semantically broken. It is not structurally broken because the resources still exist in the datasets.
The evolution of RDF datasets in terms of changes affecting its triples may invalidate previously determined links. Figure 3 presents the general scenario of investigation. Since we consider RDF datasets evolution, it is necessary to examine different versions of each dataset. A
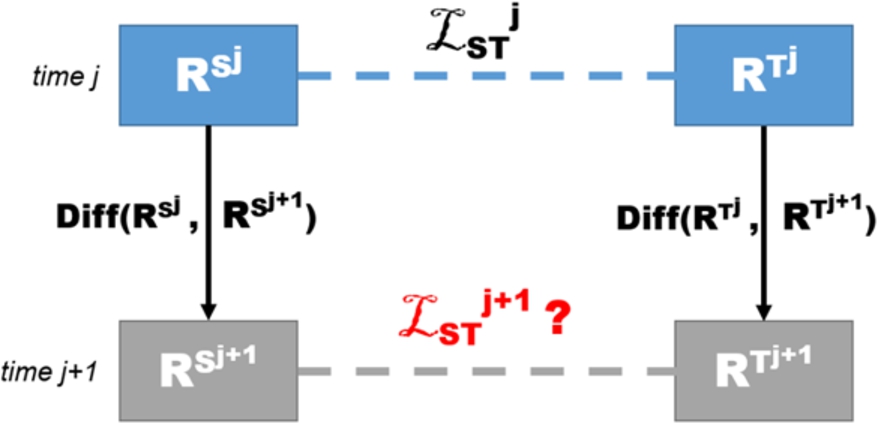
Problem modelling.
In order to maintain the consistency of the dataset, its links should remain in an integrity state, even with recurrent changes in the data. Popitsch and Haslhofer define link integrity as “[…] a qualitative property that is given when all links within and between a set of data sources are valid and deliver the result data intended by the link creator” [15].
In this investigation, we concern the research problem named link maintenance, whose aims are:
To provide innovative mechanisms to guarantee that there is a minimum occurrence of broken links;
To consider change operations from one dataset to another aiming to inform operations of update in links, based on information on how the nature of these changes is affecting the links;
To consider the history of changes to retrieve older links and maximize data reliability [32];
If unsolved occurrences of broken links remain, the responsible for maintaining data integrity should be notified.
This work investigates the research literature related to link integrity and maintenance. This review provides a key contribution to a better understanding and existing solutions on this topic. A complete investigation about the subject provides a concise understanding of common approaches and advancements in the scenario under investigation. Our study aims to guide researchers concerning the state-of-the-art status in addition to unveil the drawbacks and open issues in recent studies.
We adopted the guidelines proposed by Budgen and Brereton to perform the review [5]. Our methodology considers two key phases named planning and conduct. Figure 4 presents the steps in these two phases of the methodology.

Systematic literature review process.
Study definition
Research questions
The planning phase defines activities related to the review protocol, organising the steps of the literature research. The protocol defined for the literature search identifies the research questions and a establishes search strategy comprising inclusion, exclusion and quality criteria to evaluate the studies. The conduct phase executes the defined protocol via specific activities to retrieve, select and analyse the papers. Section 3.1 describes the steps involved in the planning phase, while Section 3.2 reports the activities in the conduct phase.
The search terms were built upon strings related to the link maintenance problem. Approaches to maintain links matter for this work (e.g., create new links, reconstruct erased ones, modify semantically wrong links or even detect and notify about them). Table 3 presents the defined search queries.
Search queries
Search queries
We clarify that the order of the search terms and the search logic connectors used in the entire process of search, such as double quotes and connectors like AND/OR/+/−, are relevant to retrieve the exact papers referred to in this survey. We set parameters at the research according to database specificities (defined in the next step). In particular, we considered 100 as the maximum number of retrieved results in Google Scholar.
Exclusion criteria
Inclusion rules
The motivation for the exclusion criteria was based on the necessity to retrieve a well-defined set of papers, meeting a quality and content criteria. We understand that the defined exclusion criteria help obtain high quality papers in the literature considering: papers that are not too old (EC-01), papers noncompliant with academic best-practices (EC-02 and EC-03); and articles whose addressed problem does not contribute to the understanding of the link maintenance challenges (EC-04).
Categories of approaches
This initial selection considered finding key terms in the title and abstract, based on the keywords in Table 3. For instance, “Repairing Broken RDF Links in the Web of Data” and “An Approach for Discovering and Maintaining Links in RDF Linked Data”, which present terms such as “broken rdf links” and “maintaining links in rdf”.
Those papers meeting all the inclusion criteria and not fitting the exclusion criteria were retrieved in our selection. For a given paper, whether one of the inclusion criteria had not been met or one exclusion criteria had been met, then such paper was discarded. The selection was made after the common agreement of the researchers. The Appendix presents details regarding the returned results for each query in the research sources.
In addition to the retrieval based on the defined queries, we performed an additional manual step in retrieving and selecting relevant articles, respecting the inclusion and exclusion criteria. In this step, we searched for additional articles in Google scholar, specific conferences and workshops whose papers are not indexed in the considered databases. Our goal in this step was to obtain and analyse articles not retrieved from the chosen sources of information. We consider this step relevant to evaluate additional investigations that can contribute to improve this survey. Additionally, we considered the selection of key correlated surveys connected to our topic of interest. The collected and presented surveys can help in clarifying the open challenges and organizing existing outcomes.
Section 5 presents the description of the articles obtained in each category. We clustered them depending on how they propose a solution based on the research questions presented in Table 2.
Publication analysis
This section presents a numeric publication analysis of the papers in our survey.
Our selection and analysis led to a total of 28 papers by considering the defined inclusion and exclusion criteria. Regarding the year of publication, the oldest article was published in 2006 whereas the newest one was published in 2018. This indicates that the problem investigated in this survey and the literature around it is mature, but there are still researchers seeking to solve open issues.
Table 7 shows the articles retrieved from each of the main scientific databases. The others refer to Google Scholar and ArXiv.
Results by scientific database
Results by scientific database
Table 8 summarises the number of articles for the different types of publication. Most of them are book chapters and full papers in conferences. Only one thesis was found in the survey.
Types of publication
Table 9 summarises the number of papers retrieved by each query string. The line identified by the word “reference” is related to the papers that were found at the section of references of the retrieved papers.
Results by query string
In this section, we describe and analyse the studies obtained in each of the categories.
Change detection
The act of identifying, storing and retrieving different versions of linked datasets is used in the process of defining which resources were modified. In this scope, we discuss solutions for computing and representing change detections in RDF datasets. We understand that for addressing link maintenance issues, studies concerning the detection of modifications in RDF datasets are very relevant. This is justified by the fact that changes affecting resources in the dataset can be a source for recognizing and fixing broken links. Via the comparison of different versions of the same dataset, a broken link can be potentially identified and fixed.
Change detection approaches are intrinsically related to the area of ontology evolution, resulting in researches to compare versions of the same ontology to detect the differences between different versions (releases) [1]. Our survey focused on studies reporting on techniques for addressing change detection on RDF datasets.
In this category, Powl [1] refers to a versioning framework aiming to detect and store atomic changes performed in ontologies, joining them and creating hierarchic and compound changes. This framework assists the process of ontology validation after several changes after a certain elapsed time. The storing of changes is performed via atomic changes. Compound changes combine distinct atomic changes to improve the readability of the changes for humans [1]. Figure 5 presents the user interface of the Powl framework for the management of RDF versioning. It presents the versioning tab with a table containing examples of changes at a given date and in the last column the possibility to rollback to a specific version.

Versions and reviews in the Powl framework [1].
Category: change detection
Category: metadata storage
In the context of versioning and ontology evolution, a delta expresses the difference between two versions of the same dataset. One of the limitations found in the versioning context is the size of deltas files created to map the differences between two versions of a dataset. Lee, Im and Won [20] proposed an algorithm to decrease the number and size of deltas produced by state-of-the-art similarities algorithms, using MapReduce as a framework for distributed and parallel computing. Table 10 presents a summary of the articles selected in this category.
Category: high-level modifications
In the context of this study, the concept of metadata is related to custom data stored with the nodes of the dataset to help detecting and fixing broken links. Some of the implementations of metadata store the current state of the link, for example “created”, “changed” or “removed”. Other metadata tag the resources with semantic descriptive tags, such as “Sherlock Holmes” > “Watson” and “IBM” > “Watson”. Table 11 presents a summary of the articles selected in this category.
Zuiderwijk, Jeffery and Janssen [46] argue about the relevance of using metadata for finding, storing, analysing, visualising and other advantages of data manipulation in LOD. The authors conducted a literature review of metadata used in LOD research. They listed eighteen directives for a concise metadata structure and validated these directives.
Kovilakath and Kumar suggested an approach to detect semantically broken links based on stamping hierarchic tags on the resource. When the resource changes, a publish/subscribe module stores and signals that some resource may be broken. The use of metadata plays a key role for their semi-automatic method, which detects semantically broken links. Although their approach enables identifying the broken links, it cannot fix the links [19].
High-level modifications
High-level changes aim to represent what has changed in the dataset in a non-atomic way. This facilitates the understanding of new, updated or deleted information over time. The so-called low-level changes are the atomic changes that add and delete nodes, links and triples in the dataset. High-level changes aggregate the atomic changes via functions, which creates a more semantic-based change definition, intuitively describing what the intention of the user who performed the action in the ontology was. For example, an addition of an employee to a given ontology can be expressed as a group of triples that sets the employee’s name, salary and skills. This group of triples is an example of a high-level and complex change, representing the set of triples in a single change of employee’s addition. Table 12 presents a summary of the articles selected in this category.
Category: ontology-driven change representation
Category: ontology-driven change representation
Category: hypermedia-based approaches
According to Galani et al. [11], the identification and versioning of simple events in the dataset cannot express the semantic of the change. These authors proposed a language to manage and define complex changes in RDF datasets. The concept of complex changes is analogous to the high-level change described by Roussakis et al. [35]: changes easy to be deduced and produced by users. The authors emphasized the relevance of complex changes, since the detection and versioning of simple changes are not suited to explain how and why the RDF data changed. In addition, simple changes cannot express with precision the semantics of the change [11]. The authors applied both proposed language and algorithm in biology datasets, which benefits from the versioning method because the evolution of these datasets is an important requirement for their consistency.
According to Papavasileiou et al. [28], the use of high-level changes originates an increase in the complexity to detect the changes. The increase in the amount of these types of changes and in complexity causes an increase in the level of abstraction. The authors proposed a language that creates and uses small and intuitive deltas without losing the expressiveness of the changes. The work presented by Papavasileiou et al. [27] is an extension of Papavasileiou et al. [28].
Ontologies can be usable to represent changes in RDF datasets. The adequate change representation is assumed in this category as essential to facilitate so ontology experts verify ontology evolution to accept changes and better understand their effects. Table 13 presents a summary of the articles selected in this category.
Pernelle et al. [29] defined an approach that detects and semantically represents high-level changes of a given dataset. As a result, the authors proposed an ontology for representing the changes.
Kondylakis et al. [18] presented a framework that uses provenance queries to identify changes in the ontologies. The framework enables queries to inform when a resource is changed and which operation caused this change. The framework takes log files containing change operations and generates the corresponding instances after the change in a visual manner. This helps ontology experts visualize ontology evolution.
Pourzaferani and Nematbakhsh [32] proposed a tool that detects broken link based on the source node of the link, instead of the destination node. In addition, they defined two auxiliary ontologies: one, named superior, which presents all the subjects and objects of the main ontology; and the inferior ontology, where the subjects of the first ontology become objects and the objects become subjects. These ontologies support the finding of possible resource similarities and new resources to be connected after the discovery of broken links. This technique was proven to get more effective results in fixing links. Using datasets from the domain of “person”, the proposed solution repaired more than 90 percent of the broken links. However, this tool cannot repair semantically broken links.
Category: link management mechanisms
Category: link management mechanisms
Link integrity in hypermedia received attention in the late 1980s and early 1990s primarily from researchers in the open hypermedia community [43]. In the traditional Web, most of the traffic runs over the HTTP protocol, where the link integrity problem is present. In our survey, the adaptation of solutions implemented in traditional Web, which might be used in the Web of Data, is discussed by a series of researches. Table 14 presents a summary of the articles selected in the hypermedia-based category.
Vesse, Hall and Carr [42] presented a web interface and service called All About That (AAT), which tracks changes in a dataset and stores it. The AAT uses a concept called URI Profiling, which is related to the storage of old data of a given URI; thus, if an URI is removed, a profile of this URI – including triples, metadata, links – can be retrieved. The linked data is stored in SQL databases. In synthesis, AAT is concerned with data preservation.
Continuing the work in Vesse, Hall and Carr [43], in 2010 an Expansion Algorithm was included into AAT. This algorithm can discover new URIs to links. Given the URI, the algorithm returns similar URIs in the form of sameAs links, acting as a crawler. A new feature – called Default Profile – aimed to provide three big data-sources – DBpedia, Sindice Cache9
Based on the work of Vesse, Hall and Carr, Vesse [41] designed an algorithm for retrieving linked data about the broken URI, which uses links with predicates such as “same as” and “see also”. This process is based on link maintenance from the traditional hypermedia. These contributions resulted in a doctoral thesis that proposes a framework for handling broken links based on two solutions for structural broken links implemented in hypermedia.
Another inspiration from the “traditional web” used by linked data is the backlinks, which are registers in databases that points to all places that mentioned a given URL in their web pages. Stefanidakis and Papadakis [39] described and developed a framework to store links and backlinks – in a bidirectional way. The solution provided a consistent way to handle broken links in connected LOD datasets. The proposal helps a given LOD dataset to summarize which datasets are referencing it and being referenced by it.
Category: hybrid solutions
This category is related to contributions exploring similarity techniques to create links among resources from various types of datasets ranging from multipurpose domains. Some studies described in this category name the linkage of resources in different datasets as “duplicate records detection” or even “record linkage” and “instance linking”. The link discovery task can be used as a potential procedure for addressing link maintenance. One of the key steps after the detection of a broken link is to choose what action is to be taken, for instance, exclusion of the link, modification of one of the involved resources or re-connection. In the last case, link discovery techniques can be used to find adequate substitutes. Table 15 summarizes the articles in the link management mechanisms category.
The MeLinDa framework [36] is based on DSNotify [15] and refers to an interlinking framework aiming to map and apply existing tools to interconnect ontological datasets, based on their URIs and underlying ontologies. A total of six link building tools – proposed in other investigations – is used to optimize the achieved results. The authors compared the level of automation, domain specificity (some of them tend to work better in certain domains) and types of similarity techniques explored in each of the used tools.
Silk [44] refers to a framework responsible for keeping alive links between two active datasets, as both evolve. Silk generates links between two datasets, evaluates them and track future links that have to be created based on the changes on these datasets.
The link discovery module of Silk [44] was enhanced and new links were created by the framework using genetic programming [16]. The genetic programming applied in linkage rules chooses the candidates of links based on a fitness measure. The authors experimented over geographic datasets, interlinking DBpedia and LinkedGeoData. They also tested the algorithm in complex linkage rules over drugs’ data in DBpedia and Drugbank. The complex linkage rules were tested to match two drugs based not only on their names, but on their synonyms and international identifiers. The evaluations and the algorithm required a set of reference links as an entry point [16]. The study concluded that genetic algorithms can be used as a tool for link discovery and management, since they outperform results obtained by other approaches, such as SVM (Support Vector Machine). For example, MARLIN (Multiply Adaptive Record Linkage with Induction) framework [2] uses SVM to obtain the degree of similarity between records in databases, but without focusing on LOD or Semantic Web datasets.
PARIS (Probabilistic Alignment of Relations, Instances, and Schema) [26] is a framework used to align two ontologies [40]. The difference from the other frameworks is that PARIS creates links between instances and mappings between concepts at the ontology level. Instead of using SVM or genetic algorithms, it uses a probabilistic model to map matching instances in two distinct ontologies. The framework requires no training data, differently from SVM and genetic algorithms. PARIS is not suited to deal with huge structural differences, such entities that are treated as string in one ontology and as resources in another ontology [40]. The use of probabilistic model to discover new links and the avoidance of training data can be inspirational to frameworks that deal with maintenance action, given that it is solely applied to creation new links
The last approach worth mentioning is COLIBRI [26]. It is a link discovery tool that uses unsupervised machine learning algorithms to find resources candidate to be the object of the link. To the best of our knowledge, this is the only tool that discovers links in multiple datasets at the same time. Differently from the other approaches, it does not focus only on owl:sameAs links [26].
Category: survey papers
Category: survey papers
This category includes contributions that present more than one of the characteristics defined in this survey to address link maintenance. This concerns, for example, user notification, versioning of changes, metadata storage or the use of auxiliary ontologies. Table 16 summarizes the articles in the hybrid solutions category.
One of the first efforts to avoid broken links in the Linked Data context is the act of sending notifications to the maintainer, administrator of the ontology or the responsible for editing the current node, triple or links. These notifications are triggered by event detection mechanisms, representing what, when and why the resource has changed.
DSNotify [15] refers to an event detection framework, which aims to preserve link integrity with the aid of notifications. Based on detected events, this framework notifies the maintainer of the dataset about changes in its structure. Its core is organised by three modules: the first is responsible for storing the content of the items and their metadata reached by a certain URI in a vector structure, named Feature Vector; the second is responsible for storing the vectors in three distinct types of index: the item index (when a new resource is created in the dataset), the removed item index (when DSNotify computes that a certain resource is unreachable) and the archived index (when there is a new location to the resource); and, the third is responsible for notifying the application that something in the dataset has changed [15].
DSNotify can fix structurally broken links with the need of human review and analysis. The authors discussed strategies that could be employed to maintain link integrity, such as deleting all the statements that contain the target resource that was deleted. One of the limitations regarding the methodology used in DSNotify is the periodicity to check if there are changes in the dataset, which can be an obstacle to the adoption of the framework by real-time applications that cannot wait and require knowing about the changes when they occur. In addition, the approach may have scalability issues, if the number of notifications sent increases [30].
The Delta LD framework [38] aims to classify the changes detected between versions of the same dataset. The framework organizes the changes based on structural and semantic approaches for storing/representing them in a triple-centric way. The proposed framework can fix broken links caused by the updating of the resources, properties and triples of a dataset. Firstly, it detects and classifies changes in “removed”, “moved” and “renewed” groups of changes. Then, based on these groups, a repairing action is performed using SPARQL to deal with structurally broken links found using SPARQL templates. If the change is categorized as a “removed”, then the broken link is deleted. If there was a “moved” or “renewed”, the framework deletes the old link and adds a new link using the URI of the updated resource. By evaluating the framework with the use of Delta LD the authors showed evidence that the precision and recall obtained better results on detecting and classifying both types of changes, compared with other solutions in the literature [38].
The study conducted by Liu and Li [21] was based on the DSNotify framework [15]. Their proposal was the use of metadata to detect and notify real-time changes in the dataset, without need to scan the entire dataset periodically. Their investigation defined an automatic method for synchronisation and propagation of changes, without the need to periodically sweep the dataset looking for changes. Another difference is related to the way that notifications are communicated: if something changes in the dataset, the user receives the event only in the next time (s)he views the resources that have undergone the change. This decision was taken to avoid an overwhelming number of changes notified to the user. In this sense, the authors implemented a tool using this approach, which avoids monitoring all linked data in the dataset and update the consumers in a more controlled way.
An alternative approach was proposed by Meehan et al. [22], named as the SUMMR methodology. Their work based on metadata explores SPARQL query templates to store and select mappings (inserted using metadata) that may have become invalid. In such work, the term “mapping” refers to external links, such as the 27 million links connecting DBpedia to 36 external datasets, in one of the DBpedia releases. SUMMR is concerned about both reuse and repair of mappings between datasets.
Roussakis et al. [35] proposed a framework for joining links and detecting complex changes by storing detection queries of change events in order to retrieve events occurred in the past. The work reports “high-level changes” as the aggregation of simple changes (additions or exclusion of triples) resulting in human-understandable changes. The authors proposed providing a way to easily navigate between two different dataset releases seeking for changes, known as cross-snapshot query. The authors argue this solution facilitates the access to the changes in a queryable way.
Surveys
This category comprises the presentation of retrieved surveys concerning research issues relevant for link maintenance. Table 17 summarizes the articles in the survey category.
Nentwig et al. [25] conducted a review of ten studies including tools and frameworks for discovering candidates for possible links between datasets. This work summarized relevant aspects of having an interconnected dataset in LOD. It highlighted that 44% of LOD datasets do not create links to other datasets, which does not follow the LOD best practices. The authors proceed on the evaluation of existing tools by comparing their effectiveness (assessment regarding the generation of high-quality links), their degree of automation, diversity of links, and computation efficiency other aspects.
The survey carried out by Nentwig et al. [25] concluded that most of the techniques used for link discovery rely basically on the analysis of the resource itself, not on the neighbourhood or the ontology context [37]; the adoption of genetic programming proved to be an important strategy; and the use of existing links and background knowledge to create new links is not widely adopted.
Dos Reis et al. [34] conducted a literature survey on mapping maintenance techniques for KOS (Knowledge Organization Systems). KOS comprise ontologies, thesauri and other structures to represent knowledge. Ontology mappings connect concepts that are semantically related between distinct ontologies. The semantic update of a given concept can invalidate an existing mapping. The authors proposed a definition of the mapping maintenance task and explained the importance of maintaining mappings up to date. Then, they categorized existing studies into four categories: mapping revision, calculation, adaptation, and representation.
The mapping revision category concerned identification and fixing of invalid mappings. The mapping calculation category addressed a fully or partial re-connection of mappings. The mapping adaptation category described a collection of strategies to re-organize affected mappings such as: composition of mappings, merging various mappings and transforming them into a single mapping; rewriting, to store the mappings in databases schemas; and synchronisation, to generate and maintain mappings between different types of KOS. The last category included studies concerning the construction of user interfaces for handling mapping maintenance.
Dos Reis et al. [34] described challenging aspects related to the mapping maintenance task. Most of the existing techniques (at the time of the survey) relied on logical inferences, which only benefit KOS possessing “high level of formalization”, such as ontologies [34]. The authors stated that the proposal of using partial re-calculation of mappings tends to reduce time cost. However, this is preventive for huge KOS.
Groß et al. [13] surveyed approaches to ontology and mapping evolution in the biomedical area. This area contains several huge ontologies (e.g., SNOMEDCT [6]), that are updated constantly and with overlapping information. The non-static behaviour of biomedical ontologies result in the creation of new mappings, as long as existing ones can be invalidated. The survey identified key aspects of mapping maintenance and how the existing literature addresses them.
Groß et al. [13] described techniques that help in the task of mapping adaptation, including: detection, visualisation and the prediction of changes at the concept level (ontologies). In order to compare the adaptation of ontology-based mappings, the authors enumerated a series of requirements to compare five novel algorithms and frameworks. For example, evaluation of the mappings’ quality, ontology size, user interaction and calculus of semantic mappings. Two studied cases use more complex diff operations to identify changes in mappings, such as merge operations. Non-equality mappings, such as “part-of” and “is involved in”, were also compared. Most of the studied cases only use equality mappings. None of the cases provides visualisation to aid ontology maintainers to check the life cycle of mappings. Scalability issues were not compared among the studies investigated [13].
The survey reported by Groß et al. [13] indicated future directions in mapping evolution research. Focusing on semantic mappings is challenging according to them. Each domain-specific mapping has its own semantics and, maintaining them at different ontology versions demands further investigations. The use of machine learning to predict and recommend mapping candidates is also a challenge. The maintenance of mappings in multilingual ontology environments requires research to fulfil the requirements of developing a robust mapping evolution algorithm [13].
Discussion and research challenges
The explicit connection between resources belonging to distinct datasets plays a central role in the interconnection between repositories in the LOD. Linked Data sources are subject to changes, since data regarding new entities are added as well as outdated data are modified or removed. The update of data repositories leads to the link maintenance problem. The maintenance of links among the linked data cloud is hard and expensive.
This systematic literature review is relevant to understand the frontiers of the link integrity and link maintenance problem. Our investigation aimed to gather and organise the existing literature on the problem to provide a complete survey to pave the way for further research and guide future researches to overcome the drawbacks and limitations of recent studies. Our literature review indicated that there is no evidence of a survey related to the state of the art in broken link diagnosis or even a method that can accurately and automatically maintain the links in a unbroken state or, given the broken state, fix them.
Our literature analysis indicated that state-of-the-art techniques do not fully address the complexity of the chain of events involved between the period of the occurrence of a change and the automatic fixing. Some approaches explore the notification solution, which might have their usability reduced due to the huge amount of triples stored. The manual checking of links to certify real broken links – i.e., whether it is a false positive or not – becomes impossible with the existing amount of data.
The significant number of changes affecting datasets might considered in link maintenance solutions. We understand that although the use of notifications to solve the broken link problem presents its limitations, the combination with other methods considering the way the datasets were changed can be relevant to advance the problem resolution and decrease the human burden.
Copying or being inspired by existing techniques from the traditional Web based on documents can benefit the handling of link maintenance in the Semantic Web data. However, the context and impact of a dead link in linked data is more problematic. In traditional Web, when the final user hits a dead link, (s)he can go back to the last page and search for another link that points to the same resource or to a similar one. In Semantic Web, applications seeking for information need to deal with dead links differently. Existing investigations point out the use of backlinks stored in a database to know where the dead link comes from, and where it is heading. In our understanding, it is not enough to provide dataset link-error proof.
Analysis of surveyed papers on link maintenance tasks. The lines refer to each study analysed in this survey. Columns represent the distinct defined tasks related to link maintenance. The tasks are: (i) change detection; (ii) user notification; (iii) versioning; (iv) metadata storage; (v) broken link detection; (vi) fix of structurally broken links; (vii) automatic fix of structurally broken links; (viii) fix of semantically broken links; (ix) automatic fix of semantically broken links. The X sign indicates that such study (work) addressed the defined task somehow
Analysis of surveyed papers on link maintenance tasks. The lines refer to each study analysed in this survey. Columns represent the distinct defined tasks related to link maintenance. The tasks are: (i) change detection; (ii) user notification; (iii) versioning; (iv) metadata storage; (v) broken link detection; (vi) fix of structurally broken links; (vii) automatic fix of structurally broken links; (viii) fix of semantically broken links; (ix) automatic fix of semantically broken links. The X sign indicates that such study (work) addressed the defined task somehow
Our literature review emphasized the use of versioning systems, which create logs and show to the user when something changed in the dataset. The datasets that obtain most benefits with versioning are those with evolutionary characteristics, such as biologic datasets. The detection and understanding of changes in datasets, such as modification operations in a property and/or a statement, is valuable to the link maintenance problem. We advocate that detected changes must be explicitly used to help updating links. Thus, links in an invalid state can be modified or rollback the modifications to a valid state.
Our results showed that most of the existing approaches are suited to avoid creating broken links as well as to detect broken links. However, they still lack techniques to adequately fix them. The use of dataset changes could play a more prominent role in this task. Indeed, RDF versioning considers both atomic and compound changes. We argue that both types of changes should be further explored to support the discovery of link integrity issues and to provide information to support their update according to changes underwent in internal triples. Nevertheless, versioning with atomic and compound changes in both TBox (specification of concepts in a domain) and ABox (specification of individuals of concepts) are often used solely to document the ontology evolution, not to help fixing links. In this sense, approaches combining versioning and backlink techniques can be a great information source for link maintenance.
This subsection presents a comparative analysis among the retrieved studies in each category. Our comparison is based on characteristics summarised in Table 18 as well as on the analysis of implemented tools.
VERSIO-2 [20] (MRSimDiff) concerned performance issues to produce and store dataset versions. It uses the MapReduce framework [7] for distributed computing. In their approach, RDF triples are stored in an unordered way while not affecting their semantics to enable reducing the size of the stored versions.
Both studies HIGHLE-2 [28] and HIGHLE-3 [27] served as a basis to HIGHLE-1 [11] because they shared a similar hypothesis, i.e., develop a framework containing a specific language to produce concise deltas between dataset versions in a manner that changes are easily readable by humans.
HYPERM-2 [43] followed a similar proposal as that of HYPERM-1 [42] (All About That): data recovery instead of data monitoring, i.e., preventing errors in case of some failure, (e.g., a broken link). The study in HYPERM-2 [43] argued that monitoring links does not perform and scale well in the Web. HYPERM-2 [43] was an expanded version of HYPERM-1 [42].
HYPERM-4 [39] investigated a different approach to track links: the backlinks. This was inspired by traditional Web and proposed to store links pointing to and being pointed by a given resource, which might facilitate the task of broken link tracking.
Differently from LINKMA-1 [44] (Silk) and LINKMA-2 [36] (MeLinda), the other studies in this category do not rely on user-defined parameters. LINKMA-3 [16] used genetic programming and relies on training data to perform link discovery tasks. LINKMA-4 [40] (PARIS), on the other hand, does not require training data and uses probabilistic models to link resources. LINKMA-5 [26] (COLIBRI) is an approach using machine learning techniques to link resources in n datasets, where
HYBRID-3 [38] (Delta-LD) uses the broken link versioning and detection strategy to fix structurally broken links automatically. HYBRID-4 [21] argues that the solutions using notification, such as the one described in HYBRID-1 [15] and HYBRID-2 [30], are not efficient because it is unfeasible to report all cases and periodic monitoring may miss some of them. HYBRID-4 [21] advocates the use of notifications and metadata together for broken link detection task without fixing them.
HYBRID-5 [22] (SUMMR) investigated how enriched metadata can be useful for link maintenance. Differently from HYBRID-4 [21], HYBRID-5 uses SPARQL queries. HYBRID-5 [22] (SUMMR) stores metadata about changes and detects and fixes structurally broken links in an assisted way.
HYBRID-6 [35] describes a framework for both detection and analysis of changes in LOD datasets. It explored advanced versioning to detect broken links. To this end, HYBRID-6 combines querying versioned databases and change ontology to deal with the manipulation, organization and information on triple changes.
We defined a set of tasks related to link maintenance, which appeared in the analysed literature. The following tasks were used to analyse existing proposals in the literature surveyed in this work:
Tasks (i) to (v) represent the phases initially carried out to handle link maintenance, such as detecting a broken link. Tasks (vi) to (ix) emphasise how to fix the links.
Table 18 presents the analysed papers studied in this survey and shows which tasks related to link maintenance are supported/solved by the explored studies. The three survey articles summarized in Table 17 were not mentioned in Table 18, since we only compared characteristics of individual articles. Each column of the table refers to a task.
Results in Table 18 indicate that existing studies still do not support a fully automatic framework for handling link maintenance tasks. The human intervention is still relevant for the existing proposals. Whereas change detection has been widely studied the way of fixing semantically broken links is uncovered by the investigations:
20 of 25 studies present the ability to know that something has changed and they deal with this in their own way: 3 send messages to the user; 9 store the changes in versions; 3 attach metadata to it; and 8 are able to indicate that a link is correlated to the change;
Most investigations deal with the first tasks (i to iv), which indicates a trend in the literature of detecting instead of fixing;
5 studies were able to detect broken links and correct them manually, or suggest corrections to the user; 3 investigations described techniques to enable fixing links automatically. However, they only apply to structurally broken links;
The lack of solutions that automatically fix semantically broken links demonstrates that the link maintenance topic in linked data must be further investigated.
Most of the found solutions focus on handling the first part of the process to prevent broken links: i.e., the discovery. This part, which consists of data preservation and monitoring actions, such as change versioning and notification of changes, is only halfway of a full link maintenance process. To fulfil the process of maintaining a link up to date with no semantic or structural errors we should further advance in how to address the fixing part of the process.
Answers to the research questions
The conduct of our literature survey enables us to answer the defined research questions presented in Table 2. The posed research questions were answered based on the knowledge acquired from the 28 scientific articles selected. We considered successful our goal to uncover the unsolved open research questions and potential solutions presented in the literature on link integrity in LOD.
The benefits of having an RDF dataset with no or very few broken links include increased trust in dataset consistency. Unbroken links, or links that are in an integrity state, deliver the data that was intended by the link creator. A highly connected dataset cloud is beneficial for both maintainers and final users. Maintainers can keep focus on the core purpose of the dataset without worrying about lacking important information about related domains.
For example, the Geonames dataset has information about coordinates of a given country. DBpedia presents information about government hierarchy in a country. The Geonames maintainers do not have to worry about government information in their dataset, as long as it has a link to the same country in DBpedia, which contains information about government hierarchy. The absence of this kind of link would separate the datasets, turning them into several islands of knowledge. Without adequate links or with a large number of broken links, final users would not be able to reach a myriad of interconnected and rich information.
Surveyed studies consider broken links as structurally and semantically broken links. We found existing studies suited to address structurally broken links as they are easier to detect and be fixed by algorithms. For example, HYBRID-3 [38] and HYBRID-5 [22] (cf. Table 18) presented how they deal with the issue of fixing structurally broken links. On the other hand, semantically broken links are harder to detect and fix. To the best of our knowledge, our survey did not detect solutions able to automatically fix these links.
Our literature analysis found that the reported solutions for broken links outside the Semantic Web field are mainly based on hypermedia-based techniques [41], such as the use of backlinks [39]. Nevertheless, backlinks are only used to detect the presence of broken links, i.e., they are not used to fix them.
Another strategy used outside the LOD community is to profile all possible changes and store them in a database, as stated by HYPERM-1 [42] (cf. Table 18). Although this work concerned preservation of data and avoidance of broken links, it did not deal with their correction.
The most common solution used in LOD datasets is to ignore broken links and make them the responsibility of the application [15], which is not the best alternative.We organized the analyzed existing solutions into two groups: the first one includes solutions related to data preservation techniques, which is concerned with detection of possible broken links; and the second one includes solutions related to maintenance techniques, which is concerned with the fixing of broken links.
In the detection of broken links (first group), we found the following techniques:
Adopting a sub ontology (ONTOLO-1) [32] for change representation;
Visualising high-level changes (HIGHLE-2) [28];
Notifying Changes (HYBRID-2) [15];
Versioning deltas of computed changes (HYBRID-3) [38].
In the maintenance of broken links (second group), we found the following techniques:
Relying on Not Found HTTP response errors via active monitoring and changes notifications (HYBRID-1) [15] (HYBRID-2) [30];
Our results indicate that there is no evidence of a fully automated framework that can theoretically or in practice maintain all kinds of links up-to-date. All kinds of links refer to RQ-02, which categorises broken links as semantic and structural. We found approaches to fixing structural broken links using human intervention (cf. column vi of Table 18) as well as approaches without need of human intervention (cf. column vii of Table 18). However, none of them is able to fix semantically broken links, with or without human intervention (cf. columns viii and ix of Table 18).
We found approaches suited to discovering links. The frameworks that fall in this category present valuable ideas on how to seek for candidate links among datasets, which includes (un)supervised learning algorithms, genetic programming and probabilistic methods. These strategies can be used, for example, to identify broken links in future work, instead of just creating reliable new links automatically.
Open research challenges
Our thorough literature review and experience in the link maintenance problem helped to detect and categorise major research challenges that deserve further investigations. In the following section, we describe open problems closely related to link integrity in linked datasets:
Conclusion
The growing number of semantically-enhanced data published and consumed in RDF repositories in the Web confirms the real potentiality of the global data space proposed by the Semantic Web vision. Links between distinct resources in different datasets play a key role to interconnect RDF repositories. RDF statements defining real-world resources tends to change. These operations can affect established links turning them broken. This hampers data linkage integrity over time.
This article contributed with a systematic literature survey concerning link maintenance in LOD. We presented, discussed and compared existing approaches for tasks related to the maintenance of links. Our results indicated the need for improvements in this research field. Our results using a controlled process and a formal bibliographic research should benefit the research community, listing topics of interest and challenges demanding more investigation and knowledge deepening towards a fully automatic approach for link maintenance. We found that most of the existing investigations focus on the broken link detection phase whereas the fixing phase still involves several open research challenges. The findings obtained in this survey can be valuable for inspiring ideas and design solutions for novel software tools suited to deal with the full link maintenance process, including discovery and fixing of both structurally and semantically broken links.
Future work involves addressing the key research challenges. A new study could experimentally compare existing software tools shown in this survey by considering effectiveness measures such as precision, recall and accuracy, as this was not the focus of our survey. In addition, we plan to conduct extensive experiments to understand the evolution of links in the LOD to correlate changes in the semantic definition of data resources with modifications observed in predefined links. This must pave the way to the definition of an automatic and precise solution for link maintenance mechanism suited to deal with LOD dynamics and link integrity.
Footnotes
Acknowledgements
Appendix
Table 19 presents the number of papers retrieved by the queries run in each of the scientific databases. The first column shows the id of the query (cf. Table 3). The first number in each row represents the number of used papers from the query used in this survey, whereas the second number (between parentheses) represents the number of articles returned by the database search engine. For example, Q-06 identifies the query “broken links” + “web of data”, which retrieved seventeen results in Elsevier Science Direct database; one paper from it was used in this survey. The queries run resulted in the retrieval of fifty-two papers. Some of them were repeated among the databases. The sum of papers retrieved by the queries and considered relevant in this study totals twenty-two. They cover topics related to link maintenance tasks.