
Abstract
Storage and analysis of video surveillance data is a significant challenge, requiring video interpretation and event detection in the relevant context. To perform this task, the low-level features including shape, texture, and color information are extracted and represented in symbolic forms. In this work, a methodology is proposed, which extracts the salient features and properties using machine learning techniques and represent this information as Linked Data using a domain ontology that is explicitly tailored for detection of certain activities. An ontology is also developed to include concepts and properties which may be applicable in the domain of surveillance and its applications. The proposed approach is validated with actual implementation and is thus evaluated by recognizing suspicious activity in an open parking space. The suspicious activity detection is formalized through inference rules and SPARQL queries. Eventually, Semantic Web Technology has proven to be a remarkable toolchain to interpret videos, thus opening novel possibilities for video scene representation, and detection of complex events, without any human involvement. The proposed novel approach can thus have representation of frame-level information of a video in structured representation and perform event detection while reducing storage and enhancing semantically-aided retrieval of video data.
Keywords
Introduction
As surveillance systems are getting affordable, large-scale deployment of such systems are prevalent these days including in parking spaces. Thus, smart parking is becoming an integral part of smart city initiatives, deployment of surveillance systems in such places are resulting in the generation of massive surveillance video data. While, the most crucial task of surveillance systems is to identify unusual activities and events, the detection of these anomalous behavior poses a major challenge in the video data science research. Video data is considered as unstructured data: it is not quantitative but consist of information spread over highly correlated frames. It requires a concrete model to analyze and extract meaningful information. According to a survey [10], the video data being communicated on the global IP network per month is worth 5 million years of watch time. The survey estimates that video traffic will rise to 82% of total global data traffic by 2021 from 73% in 2016 and surveillance video traffic will increase by seven times of its current amount by 2021. These figures look imposing when we consider the fact that a majority of surveillance data is not shared over the Internet. Surveillance cameras are capturing an untold amount of video data that is merely stored in archives, remains unanalyzed and finally overwritten after a certain duration. Such waste has prompted an urgent requirement to develop technologies that are not only efficient in storage, retrieval, and processing of video data but are also able to draw meaningful information from the content. However, fetching meaningful knowledge from video data or automatic recognition of events happening in a video poses several technical and domain-specific challenges.
As humans can understand based on cognition, knowledge and experience, information present in a video needs to be extracted, transformed, and linked with domain knowledge to acquire interpretation capabilities through software agents [40]. This requires strong reasoning and analytical support to be able to detect an event, especially of anomalous nature and bridge the semantic gap between machine interpretation and human perception. Low-level features (such as shape, size, color, etc.) extracted using video processing are not enough to generate the information required for video scene understanding. Those complex events that are rare are hard to train using supervised machine learning due to lack of sufficient training examples and massive computational capability requirements. Formulating an event requires domain and context knowledge, however, most of the present techniques lack the ability to bridge the semantic gap between low-level and high-level features, do not support data integration as well. In such scenarios, machine learning algorithms may not be applicable due to the limited number of training examples and lack of formalism [32].
Semantic Web Technology, is, therefore leveraged to fill this gap by creating domain ontology, which is effective in representing high-level semantics present in the video. Semantic Web Technologies [6] facilitate data integration along with rule-based reasoning using Semantic Web Rule Language (SWRL) [25] and SPARQL, achieving widespread interoperability in a predefined domain by using same ontology. Ontology supports Description Logics (DL), which can be used to perform spatial and temporal reasoning [41]. The semantic information present in the video is represented in Resource Description Framework (RDF) [6] format, which is machine-readable triplet and describes the relational information in “subject-object-predicate” form. RDF statements are constructed using concepts defined in vocabularies written in Web Ontology Language (OWL) ontologies.
Our approach extracts the frame-level parameters using machine learning techniques to generate a higher-level semantics for detecting unusual and suspicious events from the surveillance video data. An ontology is developed which represents the object(s) and interactions between the object(s) present in video frame. The relationships between the objects in an image are generated by creating SWRL-based rules, and events are formulated using SPARQL queries. Our review of existing literature suggests that our approach, representing frame-level information of a video in the structured machine-interpretable format, while enabling event detection by means of Semantic Web Technology is not yet explored, and is thus proposed in this paper. The key contribution of our work are as follows:
Frame level representation of video scene in RDF, which saves a lot of storage space, facilitates reasoning and efficient information retrieval. Deriving relationships between the objects in an image using SWRL, i. e., reasoning over video. Activity detection using SPARQL: once all the information is represented in RDF graphs, activity / events can be recognised and retrieved by formulating SPARQL queries. Opens up new opportunities for video data analysis research, where training examples are fewer or resources are computationally costly. Accuracy (relationship detection) is very good and performance is high. A video dataset, which consists of six different trimmed localized activities in smart parking scenarios, totaling 92 videos. A novel approach for object tracking is also proposed here, based on SWRL and Description Logics.
The results obtained using the proposed approach are promising, as the proposed methodology efficiently represents the frame-level information in RDF, then performs SWRL reasoning to extract spatio-temporal relationships between objects. The represented semantic information is retrieved to identify various scenarios and use-cases (demonstrated by recognizing suspicious events in smart parking scenarios).
The remainder of this paper is organized as follows: Sect. 2 presents the related work. Section 3 demonstrates the proposed approach for representing the events in the smart parking domain. Section 4 shows the results of the proposed work, describing parameters for evaluation, and outlines current issues and limitations. Conclusions about the contribution of the work are drawn in Sect. 5 while Sect. 6 covers future work prospects.
Related work
In this section, we first review previous work on the extraction of high-level semantic information present in the video. We then briefly summarize the existing work on utilizing ontology-based approaches.
Non semantic approaches
The non-semantic approach predominantly includes machine learning and feature based methodologies. You et al. [50] proposed a semantic framework for video genre classification based on the Hidden Markov Model (HMM) and Gaussian mixture model. The framework utilized the visual features by generating a semantic feature computation approach along with analysis on the relationship between such features and video semantics. The approach was complex and depended highly on the way the video features are computed. Si et al. [38] proposed an unsupervised learning approach for event detection by using the predefined set of atomic actions and relations (a combination of atomic actions) like touch, bend, sit, etc. These successive events were modeled in the learned grammar and made context-sensitive. The learned grammar could be used to improve the noisy bottom-up detection of atomic actions. It was also proposed to be used to infer the semantics of the scene. Zhu et al. [52] analyzed that low-level features alone, often are less significant for naive users, preferred to recognize using high-level semantic information (concepts). The shot was segmented using a color histogram. The identification of textual data in the video was performed in two ways; the first one involved the extraction of embedded text in the video like scores and another was the detection of text, which was already present in the scene. Text regions are recognized using edge detection techniques. Camera motion was identified using the mutual relationship between motion vectors in the P frame. Furthermore, the audio level was used to detect events with high noise, such as whistling, etc. Data were transformed to fit for association rule mining in item-set and temporal distance between two item-set, i.e., the video event was calculated. A deep hierarchical context model for event recognition was proposed by Wang et al. [47] which is effective in low image resolution and intra-class variation. The model could simultaneously learn and integrate context at all three levels, thus utilizes the context information efficiently. Context features (neighborhood of the event) used in the model to generate mid-level representations, and then combine the context information for recognizing events. The approach was evaluated on benchmarks dataset (VIRAT 1.0 ground dataset and UT-Interaction dataset), performed excellently.
Patterns determined through the machine-learning techniques applied to various feature descriptors of the video are very crucial for event analysis. Xie et al. [48] proposed a method for event detection, defined event by their dissimilarity among the discovered patterns, event description, event-modeling components, and current event mining systems. They have defined an event identification framework by identifying five W’s and 1H (when, what, who, where, why, how). Also, they have classified metadata as intrinsic and extrinsic which contains event-related information. The segmentation involved identifying the part of the video where it happened (time, space, and duration), recognition involved identification of one or more W’s described earlier, verification required test of the specific property, annotation, and adding labels to the data. The task of discovery is about finding the event without having prior knowledge of semantics. Hamid et al. [22] proposed an unsupervised activity analysis using n-grams suffix trees to mine motion patterns at different temporal scales. Activities were represented in the form of suffix trees. The class of the action was identified by mapping it to the problem of finding a maximal clique in a graph. The event is detected automatically by extracting the interaction of a person with the object using the Gaussian Mixture Model. An anomaly was detected if an activity does not appear in any of the sub-sequence. Baradel et al. [3] proposed a method for human activity detection from RGB data, without relying on pose information. They have defined a glimpse as a group of interest points relevant to classified activities. Due to the high correlation of events, visual point tracking is required, resulting in the collection of glimpses. However, the tracks whose location is not continuous in the spatial and temporal domain can lead to a change in semantic information, being a significant challenge. This problem is solved by selecting a local as well as distributed representation of glimpse points based on the sequential attention model and tracking the set of glimpse points by integrating them in final recognition. Liao et al. [27] proposed a novel framework for analyzing the surveillance video and recognizing the event. In the first step, an object was detected using Convolution Neural Network (CNN), then the owners of the objects were identified and monitored in real-time. If any object was moved, it was verified whether the person who moved the object was the owner or not. In case the person who moved was not the owner, the scene is further analyzed to differentiate between the stealing and moving away. They have also proposed a dataset consisting of such scenarios to evaluate the proposed approach. The approach was compared with the state of the art results on existing benchmarks dataset related to luggage detection and management.
Snoek et al. [43] listed the issues and challenges in concept-based video retrieval. They have also emphasized the semantic-gap, thus come up with concept-based video search by primarily focusing on methods of information retrieval, machine learning, human computer interaction and computer vision. Also, they have explored the task of concept detection by fusing the feature and information from classifiers to model the relations along with tools and techniques for benchmarking as performed in the NIST TRECVID benchmark.
Cheng et al. [9] conducted a study by using TRECVID 2015 dataset to understand the importance of features that are more relevant for video hyper-linking like meta-data, subtitle, content-based features including (audio and visual) along with the context of the video. However, the major improvements in search quality resulted from textual features rather than content-based features.
Shen et al. [37] proposed a method for event detection by using a subspace selection technique that can identify various classes, also preserve intramodal geometry of samples within a class. The approach was divided into two major tasks; the first one involved the extraction of video features from the video segments while in second task Modality Mixture Projections (MMP) were used to generate the signature of video. The MMP is a dimensionality reduction technique based on linear discriminant analysis which preserves the geometric projections. The approach was demonstrated on soccer video and TRECVID news dataset. Chen et. al. [8] presented an approach to generate captions of the video scene for video understanding. They have isolated two significant challenges for the task of video captioning (broad domain and multimodal information) as compared to video indexing and retrieval. Thus, they have divided the task of captioning in two tasks; the first task was the latent topic generation and the second one was topic-guided caption generation. The topic generation task predicts the topic of the video based on an unsupervised learning method built using video contents and captions in the video. This reduces the overall complexity by narrowing the topics and cover the various modalities by topics. They have also proposed a topic-guided ensemble framework by correlated the two tasks to generate more precise video captions. But their approach cannot be employed for video event detection, however useful for video understanding.
Deep learning can effectively model human cognition and behavior, thus lead to bridge the semantic gap between machine-level interpretation and human understanding. However, it requires massive labeled data and computationally expensive, often suffers due to lack of training data. Caruccio et al. [7] proposed a layered knowledge representation framework for automatic video detection consisting of environment layer (including capturing devices like camera and sensors), frame layer (analyzes frame sequences), elements of context representations, general context descriptors and action representations. The activity was detected in the framework by forming logic based visual representations of the scenarios while combining a set of small actions. The approach was complex and very specific to the use-case. It could not completely represent the information present in a scene. Gan et al. [19] proposed a CNN based approach named Deep Event Network (DevNet) for Event detection. DevNet took key frames of the video as input and construct a saliency map by pack-passing, which was used to find the key frames. Events were formulated as a semantic abstraction of video rather than just concepts. Event of “Town-hall-meeting” was formulated by combining objects, a scene, actions, and acoustics. The objects may include person, podium, scene of a conference room while actions include talking, meeting and speech, clapping as acoustic concepts. DevNet localized key shreds of evidence and detected high-level events as well. The approach was evaluated for event detection and evidence recounting on TRECVID 2014 and MEDTest dataset and achieved promising results. He et al. [24] proposed a multi-modal fusion model, which exploits spatial-temporal modeling for human activity recognition. The model named StNet (Spatial-temporal Network) based on ResNet for enhanced modeling of spatial and temporal characteristics leading to video understanding. Multi-modal information contained in the video was integrated using a temporal Xception network (iTXN). The other framework, such as Inception, Resnet-V2, ResNeXt and SENet, could also be used instead of ResNet based architecture. The results are promising due to the exploitation of multi-modal information. Furthermore, a model for spatio-temporal representation based on the residual network named pseudo-3D residual network (P3D) is proposed by Qui et al. [35]. As 3D ConvNet development from scratch requires a significant amount of computations. Various types of bottleneck building blocks were constructed in a residual simulating 3x3x3 convolutions from 1x3x3 convolutional filters equivalent to 2D-CNN and 3x1x1 convolution for creating temporal dimension on particular feature maps with time. A novel architecture named Pseudo-3D Residual Net (P3D ResNet) based on ResNet but having the different placement of blocks, having a philosophy that by increasing structural variation on the deeper layer will make the network more robust. P3D ResNet demonstrated to perform better by 5.3% and 1.8% on the classification of Sports-1M video dataset than 3D CNN and 2D CNN.
Semantic approaches
Features extracted from multimedia contents are represented in symbolic or numerical form. The knowledge inferred from these features, is represented in terms of concepts, properties, sub-concepts, and their respective relationships can be individually identified and described. This knowledge can be interlinked with the known concepts for data integration and thus facilitates multi-modal analysis. Ram et. al. [31] proposed the Video Event Representation Language (VERL), a formal language for describing an ontology of events using objects and state. They described an event as a change of state of an object. Events in a state may lead to other state, but the scope of the ontology was limited and cannot be applied to other domains and concepts. Moreover, it does not follow OWL-DL syntax. Juan et al. [18] presented an ontology which can represent high-level semantic features and knowledge using a hierarchical framework for video event and annotations. However, the ontology is not integrated with other standards like MPEG7 and does not include domain related concepts. Bermejo et al. [5] discussed an ontology-based approach which detects complex events and abnormal situation by integrating the sensor data (e.g. acceleration, speed, distance, lane change, etc.). The integrated information was used to aid decision support system for traffic management. Fan et al. [14] proposed to incorporate concept ontology for hierarchical video classification. More specific semantics were represented in the deeper layers of the hierarchy. Concept ontology provided contextual and logical relationships. As a single ontology may not meet all requirements, multiple concept ontologies for video concept organization were needed. The specific semantics were represented in deeper layers of the hierarchy. Duong et al.[12] proposed an ontology-based approach to describe the content and allow sharing with a consensus-based algorithm for reconciliation of conflicts. The visual features were extracted using MPEG7 visual descriptors, which were then used to generate video-level summary. It was, however, not suitable for representing the frame-level information. Elleuch et al. [13] proposed a fuzzy ontology to enhance concept detection by using context information about concepts based on visual modality. The context modeling was performed in three steps, i.e., semantic knowledge representation, semantic concept categorization, and refinement. A context ontology was constructed first to model the relationships between concepts and then a deductive engine was built on fuzzy rules and optimized based on genetic algorithms. Grassie et al. [21] proposed a semantic model which enables annotation to create structured knowledge at multiple levels of granularity and complexity. Ontologies were built to support linking to LOD cloud at data level. The high level interpretation of the video was limited to brief textual comments and tags explaining the whole video. In most of the cases, videos were not labeled or annotated to encode all relevant information with tags, as their interpretation were often confusing. One use case was used to demonstrate the applicability of semantic representation and linking it to DBpedia [2] resource by using annotation tools. Patricio et al. [20] proposed a framework to construct a symbolic model which exploited contextual information and tracking data in a scene. Knowledge representation and reasoning was performed using OWL and DL. An ontology was developed based on the DL, which defined the concepts, roles, and relations, giving the basic idea of the domain. The framework consisted of a general tracking layer which generated trajectory and context layer representing context and knowledge extracted from the scene. Domain ontologies had to be created manually or semi-automatically needing considerable effort and domain knowledge. Xu et al. [49] proposed a video structure description ontology, which parsed the video into text information using spatial and temporal segmentation, feature extraction, object recognition, and semantic web technologies. The extracted video content was represented in RDF using domain-specific ontology created for traffic domain surveillance videos. However, the data mining and inference rule generation for various events are still unexplored. Vallet et. al. [46] proposed a content retrieval method using ontological knowledge (a semantic distance of the concepts) considering user preferences. Ontologies provided a formal framework for representing semantic definition and facilitated the generation of new knowledge-base through inference rules. The model was deficient, in that it only captured long-term preferences, without considering short term preferences. Naphade et al. [30] constructed 834 semantic concepts based on the properties of multimedia content, but many terms were not suitable for automated tagging. LSCOM produced an ontology consisting 1000 concepts of broadcast news domain. Apart from ontology design, binary relations to hold higher relations (rule) by relating target concepts and also includes explicit rules were created. Hauptmann et al. [23] proposed high-level semantics by providing descriptors of visual content and experimentally demonstrated that video retrieval improves by increasing the number of semantic concepts, used concepts from MediaMill and LSCOM to evaluate TRECVID 2005 collection. Video retrieval efficiency was shown to be proportional to the relevance of concepts. Mutual information was used to determine the helpfulness of concepts. Mahmood et al. [28] proposed a method to extract the semantic content from the sports video. They highlighted the variety aspect of the data, which consisted of semi-structured and unstructured format. The proposed model was based on speech processing, Natural Language Processing (NLP), and Semantic Web Technologies to predict the best combination of players for next ‘n’ minutes. Text from the video was extracted and then converted to RDF using semantic web technologies and NLP. Best performance for the next few minutes was identified based on factors like weather and their past performance in a match but no details were provided on methodology and evaluation of the proposed approach. Tani et al. [44] proposed a rule based approach using SWRL for event detection, but handled only spatial events like walking and running. They could not detect temporal events which happened over the course of time. Additionally, the proposed methodology could not represent frame-level interactions between the objects.
According to Sikos [42], video contents are challenging to parse due to lack of semantics in software systems. Most of the annotation formats provide metadata about the title, creator, time, comments, and lyrics in XML format. However, this information is not machine interpretable, making it unsuitable for access, sharing and reuse. Existing vocabularies such as Dublin Core and Schema.org only provide de-facto standard for annotating video objects, while semantic interoperability requires explicit descriptors to represent information, should be unique and defined in entity. Sikos [41] proposed a DL based knowledge representation, which can be used for multimedia analysis, event detection, and interpretation of high-level media descriptors. High-level video-semantics requires comprehensive reasoning along with suitable ontologies. Most of the existing ontology do not supports all constructs of DL which could efficiently model complex reasoning using atomic concepts by implying assertion, conjunction, disjunction, etc. and follow SROIQ DL like role restrictions, concepts, etc. Sikos [39] demonstrated that ontologies for representing video events require spatial and temporal features including specific motion events in video scenes.
Smart parking is an integral part of smart city initiative. Denizens of the city face massive problem in finding a proper parking space. As surveillance systems are getting affordable, large-scale deployment of such systems in parking spaces is resulting in generation of massive surveillance video data. This data is beneficial in order to analyze the trajectory, driver behavior of the vehicles along with safety and security of the car [26]. Most of the work done in literature is focused towards assisting a driver to the parking system, i.e., identifying the nearest appropriate parking location. However, parking lot itself needs to be monitored to ensure the safety and security of the vehicle when parked inside the parking lot [45,51]. In this paper, we demonstrate the applicability of our methodology by identifying unusual activities to ensure safety of the parked vehicle.
Proposed work

Workflow and framework of the approach.
In this paper, we propose a method to detect suspicious events occurring inside the parking lot to monitor the safety of parked vehicles. The description logic expressivity of this ontology is ALHI+(D). Inference rules are created to perform the reasoning over the video data. We then formulate the SPARQL and DL queries to extract high-level semantic information. This formulation further requires the extraction of low-level features and representation using video ontology to create high-level semantics, matching human-level perception. The overall workflow is shown in Fig. 1. The workflow contains three processing layers: Video Preprocessing Layer, Semantic Processing Layer and Semantic Extraction Layer. The video preprocessing layer performs the feature extraction through a series of steps involving low-level features extraction, motion information, spatial features, and contextual information. These features are then passed onto the semantic processing layer. The semantic processing layer then generates the structured semantic information by processing the video which is represented in machine-readable format after performing ontology engineering, data integration, concept identification, and rule-based reasoning. Finally, the semantic extraction layer transforms the processed semantic information for various use-cases.
A set of terms are defined which are found in literature and used in a standard context:
Events and concepts

Detailed workflow of the proposed approach.
Concepts and sub-events are formulated to represent the information present in a video scene. Events that need to be detected are characterized by combining sub-events, properties, and relations among them. Frame-level information is used to construct the sub-events having a temporal attribute, which in turn is used to identify complex events. The scene is represented by developing an ontology that represents an object along with its position in every frame. For each frame, a date and timestamp attribute is associated with every identified object.
Low-level features are extracted using edge detection, color detection, hough line detection, contour detection. Since a frame consists of multiple objects, the properties of these objects such as length, width, dominant color, type, location, and time-stamp in a video are also considered as low-level features. We used YOLO [36] for extracting type and location of the object. It returns a bounding box of the object with which the size and location of the object can also be calculated. Mid-level features consist of class hierarchy of the objects and relationships between the objects. Since not every feature is relevant to every event scenario, the low-level features are further picked on the basis of ontology and domain. A detailed workflow is shown in Fig. 2 wherein part (a), depicts the extraction of low-level features, ontology development, and frame representation, while part (b) shows the generation of relationship and detection of an activity. The constructed ontology represents the spatio-temporal relations between objects in a video scene. The features of a frame are represented using ontology as data properties. In contrast to data properties, the object properties are referred to as mid-level features. As shown in Fig. 2 (a), each object of the frame is represented as an individual. In Fig. 2 (b), the mid-level features, i.e., the relations between the objects present in same frame and temporal frames are inferred using SWRL rules between the individuals. Relation between objects isInTheVicinityOf is shown using same color line. The green-colored connecting line shows the existence of overlaps relation between Car-1 and Car-2. The isInTheVicinityOf relation exists between Person-1 and Person-2 shown by blue-colored connecting lines while the same relation between Person-1 and Car-1 is shown through orange-colored connecting lines. In final step, abnormal events are formulated by reasoning over the behavior (reason for suspicion) and using SPARQL from RDF database.
Parking lot ontology
We develop an ontology that includes the concepts and parameters of the parking domain. The extracted data from the video is represented in the RDF format using proposed domain ontology. The ontology1
follows OWL 2 DL constructs. OWL 2 adds new functionality with respect to OWL 1. Some of the new features are syntactic (e.g., disjoint union of classes) while others offer new expressibility, including richer datatypes, data ranges, qualified cardinality restrictions, asymmetric, reflexive, and disjoint properties along with enhanced annotation capabilities. The pellet incremental reasoner is used to test the consistency of the proposed ontology. The ontology contains classes to represent frame level information in a video scene. Figure 3 shows an ontograph of the video frames represented in RDF format using constructed ontology. The proposed work is carried out in protege tool [29].The top four boxes in Fig. 3 represents the classes (thing, scene, frame, and object) followed by different boxes representing individuals of the class object. The relationships between classes, subclasses, individuals, and object properties are represented using respective colored arcs. Each individual represents one unique object in a frame number. Individual name Person 1-1 is first object (type person) of first frame of a video scene. Green-colored arcs represent the hasIndividual relationship between class and the individual. Arcs with blue color represent the hasSubclass relationship between a class and a subclass. Red-colored arc represents object property isInTheVicinityOf between two individuals. Black-colored arcs represent object property sameObject between two individuals. However, owl:sameAs essentially means that two individual have same properties and instance, but in this case data properties and object properties of the individual are different, also the object belong to different frame. Therefore, sameObject is defined in our ontology to be used instead of owl:sameAs.

Video information extracted and represented in RDF using ontology.
The data properties used are
ObjectLocationLT – Coordinate of the center of the object along x axis. ObjectLocationYC – Coordinate of the center of the object along y axis. ObjectType – Type of the object like car, person. ObjectWidth – Width of the object. ObjectLength – Length of the object. hasTime – Date Time Stamp upto milliseconds of a video frame. hasSceneNumber – Scene number of the video. Frame-Number – Frame number of the scene. vicinityDuration – Duration for which two objects are in vicinity.
The object properties used are
isInTheVicinityOf – This relation holds between two objects when they are nearby.
sameObject – holds when two objects are same in different frame.
moving – holds when object is moving.
notMoving – holds when object in not moving.
overlaps – holds when two objects overlaps.
We perform reasoning and scene interpretation using inference rules. Based on domain knowledge, the rules are formulated using DL to detect suspicious activity near a parked car in a parking lot using SWRL [25]. The rules are described with car as a reference, modified accordingly for other type of vehicles. SWRL supports new inferences based on the reasoning over existing classes, objects, and data properties. SWRL is expressed in the form of an implication between an antecedent (body) and consequent (head). The intended meaning can be read as: whenever the conditions specified in the antecedent hold, then the conditions specified in the consequent must also hold. All the statements on the left side of the implication operator (⇒) are known as antecedent (body) and on the right side are known as consequent. Antecedent consists of statements connected through conjunction operator (∧). Antecedent can also include built-in’s for e.g. swrlb:add(), swrlb:subtract() etc., for mathematical operation. Variables used in the rules are described in Table 1. The threshold values for yaTh, ysTh, xaTh and xsTh are obtained using several independent experiments and were found to be most suitable for the task. In this work, yaTh, ysTh, xaTh and xsTh were set to 100, 170, 215 and 100 respectively.
Description of the variables
Description of the variables
Rule 1 sets the object property isInTheVicinityOf between two individuals if they are nearby each other.

Object (?o1) – Represents a variable o1 which is of type Object(Class in the ontology, it can be of type individual, class, data property or an object property).
Frame-number (?o1,?v1) – Evaluates to true whenever the data property value (Frame- Number) of object o1 is stored in variable v1.
swrlb:equal (?v1,?v2), swrlb:notEqual (?v1,?v2) – SWRL built-in function to compare values if they are equal or unequal.
swrlb:add(?v1,?v2,?v3), swrlb:subtract(?v1,?v2, ?v3) – SWRL built-in function to perform mathematical operation and store the result in v1.
swrlb:greaterThan (?y2,?ys), swrlb:lessThan (?y2, ?ys)- Compares to values y2 and ys and returns true when y2 satisfies the condition.
objectLocationYC (?o1,?y1), objectLocationLT (?o1,?x1) – sets the y coordinate and x coordinate of object o1 in variable y1 and x1.
ObjectType (?o1,?t1) – Sets the class of the object o1 in t1.
isInTheVicinityOf (?o1,?o2) – Sets the isInTheVicinityOf property between object o1 and o2, states objects are in vicinity of each other when antecedent on left side of the above rule evaluates to true.
sameObject
Rule 2 sets the object property sameObject. Two objects are said to be sameObject when objects present in subsequent frames have the same shape, size, same dominant color, and are locationally nearby. However, they have been identified to be two different individuals belonging to the same object class (e.g. two persons or two cars).

sameObject (?o1,?o2) – Sets the sameObject relation between object o1 and o2, states that both object are same when antecedent on left side of the above rule evaluates to true.
Rest of the antecedents used, are already defined earlier in Section 3.5.1.
Moving
Rule 3 sets the object property moving when object present in subsequent frames have the same shape, size, same dominant color, and are locationally nearby, but is continuously changing over the certain number of frames. However, they have been identified to be two different individuals belonging to the same object class (e.g. two persons or two cars).

moving (?o1,?o2) – Sets the moving relation between object o1 and o2, states that both object are moving when antecedent on left side of the above rule evaluates to true.
Rest of the antecedents used, are already defined earlier in Section 3.5.1.
notMoving
Rule 4 sets the object property notMoving when object present in subsequent frames have the same shape, size, same dominant color, and are locationally same, but location is fixed over certain frames. However, they have been identified to be two different individuals belonging to the same object class (e.g. two persons or two cars).

notMoving (?o1, ?o2) – Sets the notMoving relation between object o1 and o2, states that both object are notMoving when antecedent on left side of the above rule evaluates to true.
Rest of the antecedents used, are already defined earlier in Section 3.5.1.
Overlaps
Rule 5 sets the object property overlaps when the boundaries (bounding box of object) of the two different object are overlapping in current frame.

ObjectWidth (?o1,?w1) – Evaluates to true whenever the data property value (ObjetWidth) of object o1 is not null.
ObjectLength (?o1,?l1) – Evaluates to true when data property value (ObjetLength) of object o1 is not null.
overlaps (?o1,?o2) – Sets the overlaps relation between object o1 and o2, states that both object are overlaps when antecedent on left side of the above rule evaluates to true.
Rest of the antecedents used, are already defined earlier in Section 3.5.1.
Suspicious activity detection around a parkied car using SPARQL query
SPARQL query is used to identify suspicious activities. It queries the RDF data using existing object properties and data properties. It can match against graph patterns and has a rich set of operators and functions on numbers, strings, date/time, and terms. A SPARQL query is triggered to extract meaningful information about occurrence of the event with time. A SPARQL query is created on the basis of logical description used to define an event. The queries are described with car as a reference, modified accordingly for other type of vehicles. For example, the activity of loitering around a parked car can be suspected by identifying the presence of a person in the vicinity of a car for more than certain duration. Figure 4 provides the complete SPARQL query created to identify loitering around the vehicle.
In the first part of the query given in Fig. 4, prefixes are defined. Prefix owl defines the schema of the OWL-DL construct. The rdfs define the resource description format schema, xsd defines the XML schema. The time defines the time ontology. The date defines the schema of date type and built-in’s. The select statement in the query returns four distinct instances of type object at two specified intervals. Instances inst1, inst3 are returned at time instant t1, and instances inst2, inst4 are returned at time instant t2, such that inst1 isInTheVicinityOf inst3 and inst2 isInTheVicinityOf inst4 as shown in lines 9 and 10 of Fig. 4. inst1 is sameObject with inst2, and inst3 is sameObject with inst4 as shown in lines 8 and 11 in Fig. 4. The relation isInTheVicinityOf describes the spatial relationship while the relation sameObject establishes the temporal relationship over different frames, resulting in representation and retrieval of spatio-temporal information present in the video scene.
Similarly, other activities such as “a person touching the car”, “a person looking inside the car” etc., have also been defined with a suitable logical description and their respective SPARQL queries are created. There are seven unusual or abnormal activities identified for this study. These are: –
General Loitering
Person walking around the car
Person touching the car
Person looking inside the car
Person attempting to damage the car
Group of people passing nearby car
Trying to open the door of the car
The above activities are formulated to test the applicability of the proposed approach and identified using SPARQL queries. Similarly, many more activities can be identified by defining more object properties, relations, and reasoning over those object properties.
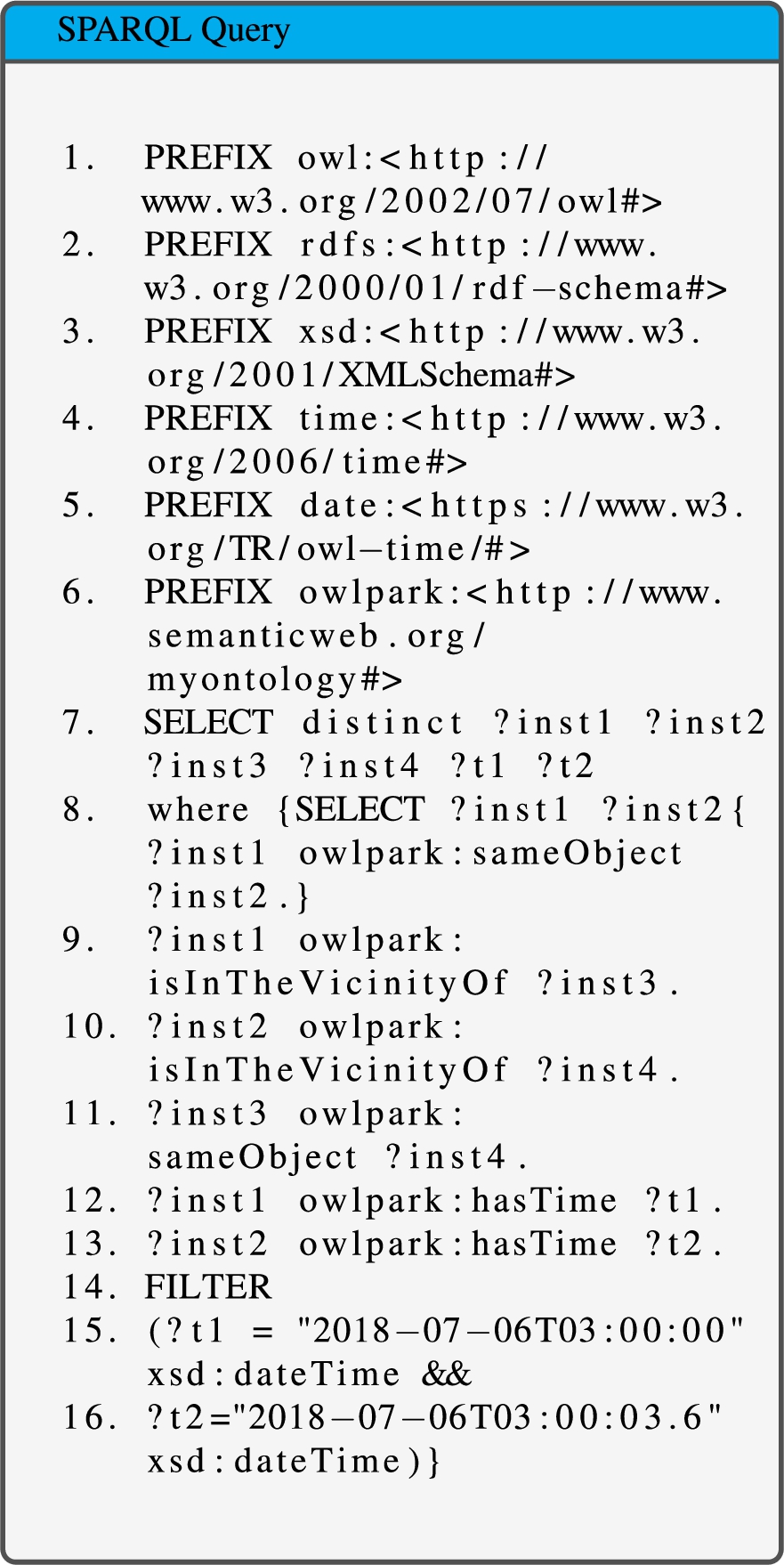
SPARQL query for moving around the car.
Object property sameObject established between two objects (one object of the current frame another of the subsequent frame) by comparing it with the all the objects in next frame. This sameObject property is extended over entire scene by applying transitive property on all the objects. If an object is same in first and second frame, and same in second, third frame, then the object is also same is first and third frame using transitive property as shown in Fig. 5. The tracking results are listed in Table 5 as relation sameObject.

Object tracking using transitive property.
Description of activity dataset
Description of activity dataset

Person walking around the car (Loitering).

Person touching the car.

Person looking inside the car.

Person attempting to damage the car.

A group passing by parking lot.

Person trying to open the door of the car.
Low-level features are extracted from each frame of the video. The extracted features are then populated using the ontology for scene interpretation. Relations between the objects are inferred using SWRL rules. The temporal relations are represented by comparing the information present in current frame with the next frame, and then the transitivity of object properties is applied to identify relationships over the entire scene thereby, reducing the computation and making the framework very agile and scalable as compared to other machine learning and video processing techniques. An activity dataset2
that contains six unusual activities, with a total of 92 videos is created. Details of the activity dataset is shown in Table 2. A person trying to open the car door or a person touching the car may not be suspicious in case the person is the owner or a genuine driver of the car. Therefore, a level of attention is assigned to each activity and classified as low, medium and high, as shown in Table 2. Experiments are performed for the activities listed in Table 2. The proposed approach is also applied to the crowd scene sequence dataset of the University of Florida (PNNL2) [11]. This dataset consists of a crowd movement near a parked car in an open parking space as shown in Fig. 12 along with objects with respective bounding boxes. Performance and accuracy measures of various steps are given in Tables 3, 4, 5, and 6.
Person walking around the vehicle in PNNL2 dataset [11].
The performance of the presented approach is tested on three different types of systems as shown in Table 3. The table lists execution time for processing ten frames in three environments. The first two systems are normal specification PC’s with easy to find system configuration. The third system is workstation with a relatively higher computing power consisting of Intel Xeon CPU, 64 GB RAM, and Nvidia 1080Ti GPU with 11 GB of dedicated graphics memory. Total execution time consists of two components, i.e., time for extraction of low-level features and time for inference rule generation. The results demonstrate that the low-level feature extraction is highly dependent on presence of GPU as in the absence of GPU, the performance of the system is substantially low. However, it is observed that the time taken for generation of inference and reasoning does not depend on the presence of GPU. The inference and reasoning part performs reasonably well even with 8 GB of RAM and Intel i7 processor. This is a prominent finding of this work which promises a possibility of implementing event detection using smart devices present on the edge of the surveillance systems with pre-trained deep-net models (to reduce the extraction of low-level features) and meaningful knowledge inference through semantic technologies. The presented framework is computationally efficient, and can be easily deployed in any of the listed system configurations.
Execution time of the framework in different environments
Execution time of the framework in different environments
The presented framework is computationally efficient, and can be easily deployed in any of the listed system configurations. There is no notable difference between the time taken by each rule as the time complexity depends on the number of atoms used in rules [40] shown in Table 4. Inference time for the relation
Relation wise execution time for different environment
Accuracy of inferring the relations in a video scene
Accuracy of the various activities by the framework
The proposed work is evaluated by measuring the accuracy of the inferred relations and activities. Accuracy of SPARQL query directly depends on inferred relationship as it extracts presence of relationship in the temporal domain. We measured the accuracy of inferred relations, on open parking dataset [11] and the accuracy of activities on our dataset shown in Table 2.
Relationship inference
The accuracy of the inferred relations is measured by calculating precision and recall of relations by forming a confusion matrix shown in Table 5. The matrix is calculated by considering relations among 7325 objects of open parking dataset [11]. Each frame has 14 objects on an average, and the number of frames per second (fps) of the video is 15. In total 70616 relations (overlaps, isInTheVicinityOf, sameObject, moving and notMoving) exists between the objects, of which the inferred sameObject relation has more number of false positives because of close objects and object occlusion. Thus, proposed framework performs quite well in inferring the complex spatio-temporal relations and interactions between the objects.
Comparison of the Loitering detection with the existing approach
Comparison of the Loitering detection with the existing approach
Activity recognition is performed by executing SPARQL queries tailored explicitly for a particular activity as listed in Table 2. The number of true alarm, false alarm and missed alarm are recorded to calculate the accuracy of the approach. The results are shown in Table 5.
As per Table 6, the following observation can be made for respective activities:
Activity: General loitering
The proposed methodology is utilized to identify the abnormal activity of loitering which is identified as one of the most common suspicious behaviors in the literature [4]. Loitering is defined as a person who enters the scene and remains within the scene for more than a certain duration. For reference, the duration of 60 seconds was mentioned in PETS2007[16]. The SPARQL query is formulated for defining loitering activity. It is said to be loitering when an individual is of type person and present in scene for more than t seconds. The ‘t’ here is kept 20 seconds. Our methodology performs significantly better in detecting loitering activity as compared to the previous approach [1] in literature as shown in Table 7. The performance of the approach is compared with the versatile loitering [1] on PETS 2006 and PETS 2016 datasets. Following sequences of PETS2006 [15] and PETS2016 [33] dataset are used:
Sequence S1-T1-C containing movement of a person with luggage in PETS2006 dataset. Sequence S2-T3-C containing the movement of a person with luggage in PETS2006 dataset. Sequence S3-T7-A containing the movement of a person with luggage in PETS2006 dataset. Sequence 03_06 TRK_RGB_1 containing the movement of person near parked truck in PETS2016 dataset. Sequence 03_06 TRK_RGB_2 containing loitering in PETS2016 dataset. Sequence 14_05 TRK_RGB_2 containing loitering in PETS2016 dataset.






Suspicious activity of moving around the vehicle is evaluated on sequence of PETS2014 Arena dataset [34] containing the series of multiple camera recordings for understanding human behavior around the vehicle with the intention pro-actively identifying the potential threats. Therefore, we have evaluated accuracy of our framework on the various sequences of PETS2014 dataset. If the relationship isInTheVicinityOf holds between truck and person for 20 seconds then it is classified as suspicious activity of moving around the vehicle. Furthermore, the sequences are bifurcated to generate multiple scenarios for evaluating the robustness of the proposed approach:
Performance of framework in identifying potentially criminal activity of moving around the vehicle on PETS2014 dataset
Performance of framework in identifying potentially criminal activity of moving around the vehicle on PETS2014 dataset
Sequence 06_01 ENV_RGB_3 containing movement of person around the vehicle in PETS2014 dataset.
Sequence 06_04 ENV_RGB_3 containing the movement of person around the vehicle in PETS2014 dataset.
Sequence 10_03 ENV_RGB_3 containing the movement of person around the vehicle in PETS2014 dataset.
Sequence 10_04 ENV_RGB_3 containing the movement of person around the vehicle in PETS2014 dataset.
Sequence 10_05 ENV_RGB_3 containing movement of person around the vehicle in PETS2014 dataset.
The performance of the proposed approach is shown in Table 8 demonstrating the effectiveness to detect potential criminal scenario of unintentional movement around the parked vehicle on PETS 2014 dataset. However, in few scenario the activity could not be detected as the object (person) got occluded behind the bigger object (truck). Results demonstrate the accuracy of the proposed approach and create an exceptional foundation to categorize an event as suspicious or normal on top of which further decisions can be made. The proposed work can also be readily applied to several such scenarios for activity detection and scene representation.
In this paper, a novel approach of event detection and video analytics is presented, by creating a framework for event detection, and video understanding with high-level semantics. Firstly, frame-level features are extracted from the video. Secondly, an ontology is developed, which can represent the frame-level information of the use-case video data, i.e., parking lot footage. Selected frame-level information is mapped to data properties of the developed ontology. Relationships between objects in a video footage are identified using ad-hoc SWRL rules, including rules for object tracking. A labeled dataset of suspicious activities is created to test the applicability of the proposed approach. This dataset can be highly useful beyond the scope of this article, to aid developers in providing solutions to parking-related challenges, as there is no comparable preexisting dataset, to the best of our knowledge. As a use case, six suspicious events are identified in surveillance footage of a parking lot, thus filling a well-known semantic gap between low-level features of a video and high-level (hidden) semantics. Furthermore, the approach is also validated on the PETS2006, PETS2014 and PETS2016 datasets. Our approach can help in representing most of the spatial and temporal information present in the video, which could be useful for object tracking and generating high-level semantic information. Our work demonstrated the potential in leveraging semantic web technology for activity detection, especially useful in scenarios featuring lack of training data and limited computing resources. The proposed approach also covers extracting and representing salient information present in video frames in machine-readable and machine-interpretable format, which improves ease of retrieval, processing, and storage.
Future work
Video representation and event detection opens up a plethora of use-cases, and are applicable to various domains. In the future, an extensive comparison shall be done with other machine learning approaches. One of the vital requirements for smart city initiatives lies in the applicability of low-power edge devices having limited computing resources. Therefore, the ability of edge/fog computing devices to handle such workloads, deriving from the effectiveness of the current approach, will also be investigated. Most of the activities which can be categorized as alarming, also include some common activities like walking, running, standing, touching, sitting, opening the door, etc. These are sub-activities that do not require interactions among multiple objects in the time domain but focus only on a few objects. By detecting these sub-activities, more complex (and atypical) activities can be derived. Object tracking is one of the most challenging problems in the field of computer vision. The object tracking approach presented in this paper will be further explored to benchmark tracking and evaluate results. Another integral part of this approach is ontology engineering, which requires substantial manpower, skilled in domain-specific concepts. Although a significant amount of work in literature is available with regard to automatic concept detection from the perspective of ontology construction, most work still remains tedious, error-prone, and time-consuming. A video ontology may work well enough to represent all the interactions between objects, both spatially and temporally. An ontology thus built, can actually be used to represent a complete video in a RDF graph, for ease of storage, access, and retrieval. Therefore, methods and data-driven techniques to generate ontologies automatically will also be investigated.