
Abstract
The correct functioning of Semantic Web applications requires that given RDF graphs adhere to an expected shape. This shape depends on the RDF graph and the application’s supported entailments of that graph. During validation, RDF graphs are assessed against sets of constraints, and found violations help refining the RDF graphs. However, existing validation approaches cannot always explain the root causes of violations (inhibiting refinement), and cannot fully match the entailments supported during validation with those supported by the application. These approaches cannot accurately validate RDF graphs, or combine multiple systems, deteriorating the validator’s performance. In this paper, we present an alternative validation approach using rule-based reasoning, capable of fully customizing the used inferencing steps. We compare to existing approaches, and present a formal ground and practical implementation “Validatrr”, based on N3Logic and the EYE reasoner. Our approach – supporting an equivalent number of constraint types compared to the state of the art – better explains the root cause of the violations due to the reasoner’s generated logical proof, and returns an accurate number of violations due to the customizable inferencing rule set. Performance evaluation shows that Validatrr is performant for smaller datasets, and scales linearly w.r.t. the RDF graph size. The detailed root cause explanations can guide future validation report description specifications, and the fine-grained level of configuration can be employed to support different constraint languages. This foundation allows further research into handling recursion, validating RDF graphs based on their generation description, and providing automatic refinement suggestions.
Introduction
Semantic Web data is represented using the Resource Description Framework (RDF), forming an RDF graph [25]. The quality of an RDF graph – its “fitness for use” [86] – heavily influences the results of a Semantic Web application [58]. An RDF graph’s fitness for use depends on its shape, i.e., the RDF graph itself and the application’s supported entailments of that RDF graph. For example, some applications support inferring
RDF graphs are validated by assessing their adherence to a set of constraints [57], and different applications (i.e., different use cases) specify different sets of constraints. Via validation, we discover (portions of) RDF graphs that do not conform to these constraints, i.e., the violations that occur. These violations guide the user to the resources and relationships related to the constraints. Refining these resources and relationships results in an RDF graph of higher quality [31], thus, RDF graph validation is an important element for the correct functioning of Semantic Web applications.
Validation problems
Let us consider the following example: an RDF graph containing people and their birthdates is validated. The use case dictates the set of constraints and the supported entailments. Specifically, we validate formula (1),1
For the remainder of the paper, empty prefixes denote the fictional schema
Problem 1 (P1): Finding the root causes of violations For example, a use case dictates that every resource should have either a firstname and lastname, or a nickname. This constraint,
For constraint types such as compound constraints, existing validation approaches typically return the resource that violates the constraint. More detailed descriptions are typically not provided, and manual inspection is needed to discover the root cause of a violation, i.e., why a resource violates a constraint. Without the root cause, it is hard to (automatically) refine the RDF graph and improve its quality.
Problem 2 (P2): The number of found violations depends on the supported entailments A mismatch between which entailments are supported during validation and which entailments are supported by the use case influences, e.g., whether formula (3) is inferred or not. Thus, either too many or too few violations can be returned [14]. This difference in number of found violations gives a biased idea of the real quality of the validated RDF graph.
Too many violations: formula (2) specifies the domain of
Too few violations: Let us validate that “every person in the RDF graph adheres to constraint
Customizing the set of inferencing steps during validation (e.g., whether
For a detailed example, please see
Problem 3 (P3): Combining validation with a reasoning preprocessing step decreases performance Entailments can be inferred by performing reasoning as a preprocessing step prior to validation [14], thus combining multiple systems. The resulting RDF graph then explicitly contains all supported entailments, given that the reasoner can be configured to only infer the entailments that are supported by the use case. The number of found violations is then accurate with respect to the use case (solving P2). However, this requires a sequence of independent systems. Thus, the preprocessing step possibly produces entailments not relevant for validation [14]. This independent generation of unnecessary entailments can decrease the performance compared to a single validation system. More, due to this sequence of independent systems, finding the root causes involves investigating the results of both systems: the validator who detects violations, and the reasoner who infers entailments.
To solve aforementioned observed validation problems, we pose following hypotheses.
Hypothesis 1 Root causes can be explained more accurately compared to existing validation approaches when using a logical framework that can be configured declaratively.
Hypothesis 2 A more accurate number of violations are found compared to existing validation approaches when supporting a custom set of inferencing steps.
Hypothesis 3 A validation approach supporting more accurate root cause explanations and a custom set of inferencing steps can support an equivalent number of constraint types compared to existing approaches.
Hypothesis 4 A validation approach supporting a custom set of inferencing steps is faster than an approach including the same inferencing as a preprocessing step.
Contributions
In this paper, we propose an approach for RDF graph validation that uses a rule-based reasoner as its underlying technology. Rule-based reasoners can generate a proof stating which rules were triggered for which returned violation. Thus, the root causes of violations can be accurately explained (solving P1).
A validation approach using rule-based reasoning natively support the inclusion of a custom set of inferencing steps by adding custom rules. The supported entailments during validation can thus be matched to the entailments supported by the use case, and the validation returns an accurate number of found violations (solving P2).
Moreover, rule-based reasoners only need a single language to declare both the constraints and the set of inferencing rules, and only a single system to execute the validation. Compared to a combination of a reasoner and a validation system, this approach does not lead to the generation of entailments unnecessary to the validation step, making it potentially faster than including an inferencing preprocessing step (solving P3).
Our contributions are as follows.
An analysis of existing validation approaches and comparison to a rule-based reasoning approach.
A formal ground for using rule-based reasoning for validation.
An application of that formal ground by providing an implementation using N3Logic [11] to define the inferencing and validation rules, executed using the EYE reasoner [84], supporting general constraint types as described by Hartmann et al. [41,43].
An evaluation of our approach, positioning it within the state of the art by functionally validating the hypotheses and comparing the validation speed.
We validated that (a) the formal logical proof explains the root cause of a violation more detailed than the state of the art; (b) an accurate number of violations is returned by using a custom set of inferencing rules up to at least OWL-RL complexity and expressiveness; (c) the number of supported constraint types is equivalent to existing validation approaches; and (d) our implementation is faster than a combined system, and faster than an existing validation approach when RDF graphs are smaller than one hundred thousand triples.
The remainder of the paper is organized as follows. We start by giving an overview of the state of the art (Section 2), after which we position and compare rule-based reasoning as validation approach (Section 3). Then, we discuss the logical requirements (Section 4) and apply them to achieve a practical implementation (Section 5). Finally, we evaluate our proposed approach (Section 6) and summarize our conclusions (Section 7).
State of the art
In this work, we propose an alternative validation approach using rule-based reasoning. We first provide a background on validation and reasoning in Section 2.1. Then, we give an overview of existing validation approaches in Section 2.2, and of related vocabularies and ontologies in Section 2.3. We conclude with an overview of general constraint types in Section 2.4, which allows us to functionally compare validation approaches. Our categorization is derived from the general quality surveys of Zaveri et al. [86], Ellefi et al. [34], and Tomaszuk [81], and from the “Validating RDF Data” book [58]. The related works are extended with recent works published in, among others, the major Semantic Web conferences (ESWC and ISWC), and the major Semantic Web journals (Journal of Web Semantics and Semantic Web Journal).
Background
Validation Data quality can be assessed by employing a set of data quality assessment metrics [12]. Quality assessment for the Semantic Web – and more specifically, for Linked Data – spans multiple dimensions, further categorized in accessibility, intrinsic, trust, dataset dynamicity, contextual, and representational dimensions [86]. Validating an RDF graph directly relates to intrinsic quality dimensions, as defined by Zaveri et al. [86]: (i) independent of the user’s context, and (ii) checking if information correctly and compactly represents the real world data and is logically consistent in itself, i.e., the graph’s adherence to a certain schema or shape. In this paper, we specifically focus on RDF graph validation, i.e., the intrinsic dimensions.
Validation of an RDF graph can be automated by using a set of test cases, each assessing a specific constraint [57]. Violations of those constraints are then indicated when a validation returns negative results. Validation is typically achieved following Closed World Assumption (CWA): what is not known to be true must be false. For example, a validation assesses for a specific RDF graph if all objects linked via the predicate
schema:birthdate
are a valid
xsd:date
, or if all subjects and objects linked via the predicate
foaf:knows
are explicitly listed to be of type
Reasoning Ontologies are prevalent in the Semantic Web community to represent the knowledge of a domain. Ontology languages are used to annotate asserted facts (axioms). Examples include RDF Schema (RDFS) [19] and the Web Ontology Language (OWL) [46]. Reasoning on top of these axioms is achieved, as the calculus of the used logic specifies a set of inferencing steps, inferring logical consequences (entailments) from these axioms [30]. Logics for the Semantic Web – given the open nature of the Web – typically follow the Open World Assumption (OWA): what is not known to be true is simply unknown.
Semantic Web reasoners are typically description logic-based reasoners supporting OWL-DL or subprofiles such as OWL-QL [61], or rule-based reasoners [66]. Description logic-based reasoners are typically optimized for specific description logics, such as KAON23
There is a clear distinction between ontologies and the constraint set for RDF graph validation: ontologies focus on the representation of a domain, whereas RDF graph validation checks whether the resources of that graph conform to a desired schema [58]. It is not required that the representation of a domain aligns with the schema for validation. However, they can complement each other. The usage of ontologies prescribes a set of inferencing steps, for example, the FOAF ontology declares the
In this section, we discuss RDF graph validation approaches. Tools and surveys that cover quality dimensions other than the intrinsic dimensions such as accessibility or representational dimensions are out of scope. We discuss the approaches roughly in chronological order: hard-coded, using integrity constraints, query-based, and using a high-level language. Except from hard-coded systems, these validation approaches propose or use some kind of declarative means to describe RDF graph constraints.
Hard-coded
Hard-coded systems are a black box where the business logic lies within the code base: the implementation embeds both description and validation of constraints. Hogan et al. analyzed common quality problems both for publishing and intrinsic quality dimensions [47], providing an initial set of best practices [48]. Efforts focus on a limited set of configurable settings (i.e., turning constraint rules on or off) [60].
Integrity constraints
For these validation approaches (so-called “logic-based approaches”), the axioms of vocabularies and ontologies used by the validated RDF graph are interpreted as integrity constraints [62,67,79]. For example, disjointness forces a description logic-based reasoner to throw an error, which is interpreted as a violation. To combine CWA typically assumed for validation with OWA assumed in ontology languages, alternative semantics for these ontology languages are proposed. The underlying technology used is a description logic-based reasoner or a SPARQL endpoint.
Description logic-based reasoner Motik et al. [62] propose semantic redefinitions, where a certain subset of axioms are designated as constraints. To know which alternative semantics for OWL apply, constraints have to be marked as such. They propose to integrate their implementation with KAON2. Furthermore, custom integrity constraints for Wordnet have been verified using Protégé [63] with FaCT++ [23].
SPARQL endpoint Tao et al. [79] propose using OWL expressions with Closed World assumption and a weak variant of Unique Name assumption to express integrity constraints. OWL semantics are redefined, without being explicitly stated as such during validation. They use SPARQL [1] for axioms described in RDF, RDFS, and OWL [79], e.g., using SPARQL property paths to simulate
Query-based
In query-based approaches, constraints are described and interpreted similar to SPARQL queries [43,68]: only RDF graphs whose structure is compatible with the defined structure are returned. These approaches use an embedded or external SPARQL endpoint as underlying technology.
CLAMS [35] is a system to discover and resolve Linked Data inconsistencies. They define a violation as a minimal set of triples that cannot coexist. The system identifies all violations by executing a SPARQL query set. Knublauch et al. propose the SPARQL Inference Notation (SPIN) [55]: a SPARQL-based rule and constraint language. The SPARQL query is described using RDF statements instead of using the original SPARQL syntax. Kontokostas et al. [57] propose Data Quality Test Patterns (DQTP): tuples of typed pattern variables and a SPARQL query template to declare test case patterns. The validation framework that validates these DQTPs is called RDFUnit. The DQTPs are transformed into SPARQL queries, where every SPARQL query is a test case. RDFUnit additionally allows automatically generated test cases, depending on the used schema.
RDFUnit is also used to validate Linked Data generation rules in the RDF Mapping Language (RML) [32], by manually defining different DQTPs to target the generation description instead of the generated RDF graph [31]. This means the RDF graph can be validated before any data is generated, as the generation description reflects how the RDF graph will be formed.
High-level language
These approaches use a terse high-level language specifically designed to describe constraints for validation [58]. These languages are independent of underlying technologies, and alternative implementation strategies can be devised. We first discuss initial high-level languages, after which we discuss high-level languages with wide adoption from the community: ShEx and SHACL.
Description Set Profiles (DSP) [64] define a set of constraints using Description Templates, targeted specifically to Dublin Core Application Profiles, and implemented using SPIN [16]. Other high-level languages to describe constraints include OSLC Resource Shapes [76] – part of IBM Resource Shapes – and RDF Data Descriptions [36]. Luzzu [28] uses a custom declarative constraint language (Luzzu Quality Metric Language, LQML). Any metric that can be expressed in a SPARQL query can be defined using LQML. Moreover, quality dimensions other than the intrinsic dimensions are also expressible using LQML. Luzzu supports basic metrics and custom JAVA code allowing users to implement custom metrics.
ShEx Shape Expressions (ShEx) [73,74] is a structural schema language which can be used for RDF graph validation. The grammar of ShEx is inspired by Turtle and RelaxNG, its semantics are well-founded, and its complexity and expressiveness are formalized [13,78]. ShEx provides an extension point to handle advanced constraints via Semantic Actions, which allows to evaluate a part of the validated RDF graph using a custom function.
SHACL The Shapes Constraint Language (SHACL) is the W3C Recommendation for validating RDF graphs against a set of constraints [56]. The core of SHACL is independent of SPARQL, which promotes the development of new algorithms and approaches to validate RDF graphs [59]. The original specification does not include a denotational semantics such as ShEx, however, the recent work of Corman et al. propose a concise formal semantics for SHACL’s core constraint components, and a way of handling recursion in combination with negation [24]. Advanced features of SHACL include SHACL Rules (to derive inferred triples from the validated RDF graph) and SHACL Functions (to evaluate a part of the validated RDF graph using a custom function) [54].
Validation reports
Validation reports handle identification of which data quality dimensions are assessed in general, and the representation of violations in particular.
To identify data quality dimensions, Radulvic et al. extended the Dataset Quality Ontology (daQ) [29] to include all data quality dimensions as identified by Zaveri et al. [86], leading to the Data Quality Vocabulary [75]. This allows the comparison of data quality dimension coverage of different frameworks.
Comparing the prominent validation approaches with rule-based reasoning, using factors explanation, time, customization, inferencing steps, and reasoning preprocessing. The time row indicates which approaches’ execution time is influenced due to the reasoning preprocessing using an asterisk. The asterisk in the inferencing steps row indicates that approaches based on integrity constraints cannot combine with a custom set of inferencing steps that overlaps with the integrity constraints, as their semantics are redefined

Comparing the prominent validation approaches with rule-based reasoning, using factors explanation, time, customization, inferencing steps, and reasoning preprocessing. The time row indicates which approaches’ execution time is influenced due to the reasoning preprocessing using an asterisk. The asterisk in the inferencing steps row indicates that approaches based on integrity constraints cannot combine with a custom set of inferencing steps that overlaps with the integrity constraints, as their semantics are redefined
The violations report itself allows to distribute and compare the violations found in an RDF graph, and can refer to the dimension specifications using aforementioned general vocabularies. For example, the Quality Problem Report Ontology assembles detailed quality reports for all data quality dimensions [28]. The Reasoning Violations Ontology (RVO) is used to represent integrity constraint violations [18], and Kontokostas et al. [57] use the RDF Logging Ontology6
Hartmann né Bosch et al. identify eighty-one general constraint types [17,43]. These constraint types are an abstraction of specific constraints, independent of the constraint language used to describe them. A constraint type can be defined in different ways. For example, the property domain constraint type specifies that resources that use a specific property should be classified via a specific class, e.g., all resources using the
Moreover, Hartmann et al. provide a logical underpinning stating the requirements for a validation approach to support all constraint types [14]. For thirty-five out of eighty-one constraints types (
Comparative analysis
Different types of validation approaches are proposed in the state of the art. The most prominent approaches are hard-coded, based on integrity constraints, query-based, and using high-level languages. In this section, we compare them with our proposed rule-based reasoning approach. Our analysis is summarized in Table 1.
We adapt the framework presented by Pauwels et al. [70], which introduces comparative factors of key implementation strategies for compliance checking applications. We adjust these factors with respect to the validation problems identified in Section 1.1. We generalize the factors time, customization, and inferencing steps, and introduce explanation and reasoning preprocessing as validation-specific factors.
Explanation The explanation as to why a certain violation occurs (i.e., the root cause). The more specific a validator can explain, the easier it is to (automatically) refine the RDF graph and improve its quality. Existing approaches typically have the means to explain violations up to the level of which resource violates which constraint. Explanations of hard-coded approaches either need to be explicitly implemented, or are provided by inspecting the code base. When using integrity constraints, approaches exist for resolving inconsistencies. These approaches perform some sort of root cause analysis, but are usually targeted at refining the axioms of the ontologies themselves [39]. It is not a standard feature to produce proofs of the results of description logic-based reasoners [65]. In a query-based approach, the used SPARQL endpoint returns bindings [1]. In the case of validation, it returns the violating resources, without additional explanation. High-level languages can have mechanisms to additionally include the violating resources in the validation report. For example, ShEx and SHACL provide ShapeMaps [73] and Focus nodes [56], respectively. SHACL’s Focus nodes can further specify which predicate and object cause the violation, except for, e.g., compound constraints. Using rule-based reasoning allows the generation of a logical proof, as rule-based reasoning relies on a general “implies” construct to describe rules, and rule-based reasoners typically do not contain description logic optimizations. Such a logical proof declares which rules were triggered to arrive at a certain conclusion, giving a precise explanation for the root causes of constraint violations. Where existing approaches typically have the means to explain violations up to the level of which resource violates which shape, a logical proof can provide a more detailed explanation.
Time The time needed to execute the validation: short versus long. Typically, specialized approaches allow for optimizations, making them faster than general approaches. Hard-coded is usually the fastest and needs the shortest processing time, followed by systems that use high-level languages: both can be optimized for validation tasks. The other approaches (using integrity constraints, query-based, and rule-based reasoning) are typically built using an underlying existing technology (description logic-based reasoners, SPARQL endpoints, and rule-based reasoners, respectively). They are not built (or optimized) for validation tasks. This makes them independent of the constraint language, but can also slow down the validation. The total execution time of validation approaches depends on whether a reasoning preprocessing step to include additional inferencing steps is required or not. Using rule-based reasoning is thus potentially slower than existing approaches, however, it does not require inclusion of reasoning preprocessing.
Customization The extent of customization each type of approach enables. Typically, ease of customization is improved by using a declarative language. Customization of a hard-coded system requires development effort, as the business logic is embedded within the code. Other approaches rely on declarations to customize the validation. Declarations are decoupled, i.e., independent of the tool’s implementation. Thus, they can be shared and easier customized to a certain use case. Description logic-based reasoners used to identify integrity constraints are typically optimized for description logics such as OWL-QL and OWL-DL. Customization is limited to the description logic that the reasoner is optimized for. Query-based approaches allow customization by defining additional SPARQL queries and registering custom functions [40]. Systems using high-level languages are customized using the declarations as specified by the used language. The adoption of ShEx and SHACL shows that these languages provide sufficient customization. The extension mechanisms of these languages such as Semantic Actions [73] and SHACL Advanced Features [54], respectively, allow to customize the validation even further. Using rule-based reasoning allows customization by adding and removing rules. As opposed to existing approaches, users can customize both the constraint types and the set of inferencing steps within the same declarative language.
Inferencing steps Whether the validation approach supports a (custom) set of inferencing steps. Hard-coded systems can support a fixed set of inferencing steps, but this set cannot be inspected or altered without investigating the code base. Approaches that use integrity constraints for validation propose alternative semantics of commonly agreed upon ontology languages to include, among others, some form of CWA [62,79]. This leads to ambiguity in the Semantic Web as an existing, globally agreed upon logic, is changed [4]. It is not possible to combine such validation with a (custom) set of inferencing steps within a description logic: the same inferencing step has different semantics whether it is used for validation or for inferring new statements. SPARQL endpoints used for query-based approaches can support up to OWL-RL reasoning [53], or support up to RDF and RDFS entailment via translation of the SPARQL queries using property paths [79]. High-level languages such as SHACL allow specifying the entailment regime used [38]: SHACL validators may operate on RDF graphs that include entailments using the
Reasoning preprocessing Existing approaches have no support for including a custom set of inferencing steps, propose alternative semantics, or allow a specific entailment regime. By including a reasoning step as preprocessing step to these approaches (see Fig. 1.1), the entailments valid during validation can be matched with the entailments valid for the use case, even when that use cases requires a custom set of inferencing steps [14]. First, a reasoner – optionally, hence the dashed line – infers all valid entailments of the original RDF graph (Fig. 1.1, Reasoner), taking into account the axioms of the relevant ontologies and vocabularies (Axioms). Then, the newly generated RDF graph (RDF graph*) is validated with respect to the specified constraints (Fig. 1.1, Validator).
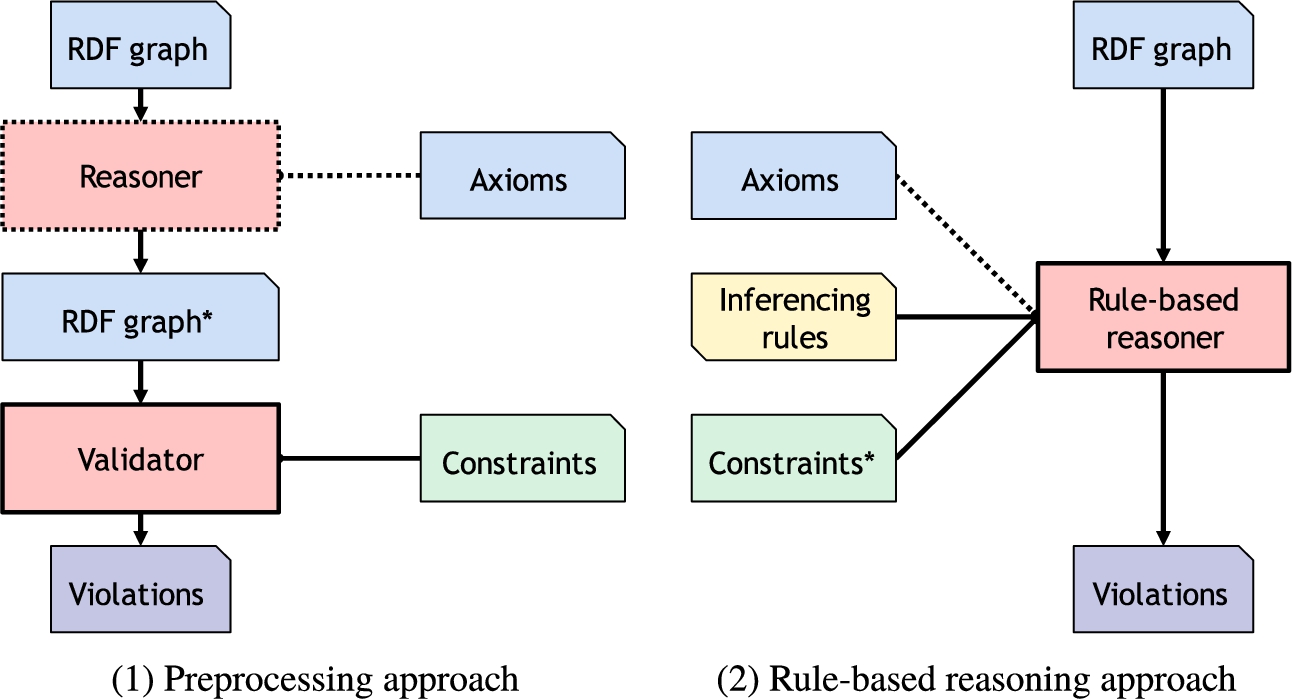
The preprocessing approach: first (optionally, hence the dashed line), a reasoner is used to generate intermediate data (RDF graph*). That intermediate data is then the input data for the Validator. Using a rule-based reasoner only needs a single system and language to combine reasoning and validation.
By using a preprocessed inferred RDF graph, multiple systems (i.e., the reasoner and the validator) need to be combined, configured, and maintained. This separates concerns, however, this also means that different languages may need to be learned and combined for specifying the inferencing steps and constraints. As these multiple systems are not aligned, the reasoner could infer a large number of new triples that are irrelevant to the defined constraints, which could lead to bad scaling (Fig. 1.1, RDF graph*). Also, explaining the violation is hindered. Even when the reasoner can differentiate between the original triples and the inferred triples, finding the root causes involves investigating the output of both systems: the validator detecting the violations, and the reasoner inferring the supported entailments.
Reasoning preprocessing is not required when using rule-based reasoning. The set of inferencing steps and the set of constraints can be defined using the same declaration (Fig. 1.2, Inferencing rules and Constraints*), and executed simultaneously on the RDF graph and the axioms. Which statements need to be inferred can be optimized guided by the set of constraints, and only the output of a single system needs to be investigated to explain the found violations.
In this section, we discuss the logical requirements needed for RDF graph validation, and argue for using a rule-based logic.
Constraint languages need to cope with different constraint types depending on users’ needs. Each constraint type implies logical requirements. The constraint types and the requirements they entail are investigated by Hartmann et al., claiming that Closed World Assumption (CWA) and Unique Name Assumption (UNA) are crucial for validation [14]. These requirements typically do not apply to logics for the Semantic Web, as data on the Web is decentralized, information is spread (“anyone can say anything about anything” [25]), and single resources can have multiple URIs. Instead, relevant logics such as OWL-DL assume OWA and in general non-Unique Name Assumption [61]. Hartmann et al. emphasize the difference between reasoning and validation, and favor query-based approaches for validation. When needed, query-based approaches can be combined with reasoning (e.g., OWL-DL or OWL-QL) as a preprocessing step.
However, in this section, we show how rule-based reasoning can be used for validation in a Semantic Web context, even though this reasoning typically does not follow CWA and UNA. Specifically, we state that the requirements for using rule-based reasoning are (i) supporting Scoped Negation as Failure (SNAF) [26,51,72] instead of CWA (Section 4.1), (ii) containing predicates to compare URIs and literals instead of supporting UNA (Section 4.2), and (iii) supporting expressive built-ins, as validation often deals with, e.g., string comparison and mathematical calculations (Section 4.3).
Scoped negation as failure
Existing works claim that CWA is needed to perform validation [14,67,79]. Given that most Web logics assume OWA, this would require semantic redefinitions to include inferencing during validation [62], which leads to ambiguity. However, as validation copes with the local knowledge base, and not the entire Web, we claim Scoped Negation as Failure (SNAF) is sufficient. This is an interpretation of logical negation: instead of stating that ρ does not hold (i.e.,
To understand the idea behind Scoped Negation as Failure, let us validate following RDF graph:
This changes if we take into account SNAF. Suppose that
Predicates for name comparison
UNA is deemed required for validation [14], i.e., every resource taken into account can only have one single name (a single URI in our case) [52]. UNA is in general difficult to obtain for the Semantic Web and Web logics due to its distributed nature: different RDF graphs can – and actually do – use different names for the same individual or concept. For instance, the URI
dbpedia:London
refers to the same place in Britain as, e.g.,
dbpedia-nl:London
. That fact is even stated in the corresponding datasets using the predicate
owl:sameAs
. The usage of
Let us look into the following example. We assume
The related constraint – defined as

Components view of our approach. All double-snipped rectangles are rule sets, the single-snipped rectangles are RDF graphs or constraint declarations. The large overlapping rectangle is the rule-based reasoner. By taking all rule sets into account, the rule-based validator is formed. Four parts can be identified within the validation execution: (i) possibly guided by provided Axioms, all supported entailments of the given RDF graph can be generated using the Inferencing rules, resulting in RDF graph*; (ii) the general Constraints* are inferred from the given Constraints using a set of rules for Constraint translation; (iii) the rules for Validation generate Violations; and (iv) the returned Violations* are structured given a set of rules that specify the Report format.
Validation often deals with, e.g., string comparison and mathematic calculations. These functionalities are widely spread in rule-based logics using built-in functions. While it typically depends on the designers of a logic which features are supported, there are also common standards. One of them is the Rule Interchange Format (RIF), whose aim is to provide a formalism to exchange rules in the Web [50]. Being the result of a W3C working group consisting of developers and users of different rule based languages, RIF can also be understood as a reference for the most common features rule based logics might have.
Let us take a closer look to the comparison of URIs from the previous section.
Application
In this section, we present our approach that uses rule-based reasoning for validation. We discuss the different components and the workflow in Section 5.1, the underlying technologies in Section 5.2, and implementation in Section 5.3. We end with an example using rules in Section 5.4.
Customizable validation
Our validator consists of multiple components that can be configured by adjusting the different rule sets (Fig. 2). The execution is primarily handled using the rule-based reasoner as underlying technology.
The set of Inferencing rules specifies the supported entailments during validation. This set can either be a predefined set to support, e.g., RDFS entailment [19], or can be fully customized. Optionally, the relevant axioms are provided during validation. As such, the entailments supported by the use case can be matched during validation.
The set of rules forming the Constraint translation allows our validator to infer the general constraint types – common across existing constraint languages [17,43] – from specific constraint descriptions. It can thus infer these types from the constraints described in a specific language such as SHACL [56]. The general constraint types are described using RDF-CV, which generalizes the constraint types into a coherent structure [17]. The purpose of RDF-CV is not to invent a new constraint language: it is a concise ontology which is deemed universal enough to describe constraints expressible by other constraint languages such as SHACL.7
For a detailed description of RDF-CV, we refer to the original papers [15,17], or the source:
The set of rules forming the Validation allows our validator to infer violations on the RDF graph with all supported entailments, based on the general constraint types. This set of rules specifies how to detect each constraint type.
The set of rules forming the Report allows our validator to infer the resulting violations in the required format. This set can be adapted to, e.g., the SHACL report format [56].
As a result, this declarative approach is decoupled from ontology language, constraint language, and report format. When no additional rule sets are included (i.e., only the Validation rule set is used), this validator does not infer any entailments, only validates constraints described using RDF-CV, and returns a report in a format based on RDF-CV.
All rule sets and input data are taken into account during a single reasoner execution. As opposed to using a reasoning preprocessing step, the inferred entailments can be geared towards the specified constraints (when making use of a backward chaining reasoner), and no unnecessary entailments are produced. For example, when an axiom specifies the range of a certain path, but no constraints are related to that path, this range might not need to be inferred. Moreover, as you only have a single system, finding the root cause does not require investigation of multiple systems: the logical proof contains the complete overview of which rules were used to generate which entailments and which violations.
The most important technological considerations are the rule-based web logic and reasoner in accordance with that logic.
Rule-based web logic Rule-based web logics include the Semantic Web Rule Language (SWRL) [49], the Datalog+/− framework [22] and N3Logic [11].8
For a more thorough discussion of relevant rule languages, we refer to Section 3.2 of [83].
We follow the formalized semantics of N3Logic [83] as implemented in the EYE reasoner [5]: a clear formal definition of Notation3’s semantics was missing from its initial proposal [11]. Verborgh et al. formalised the basics of the model theory of a logic with similar properties to N3Logic, excluding the constructs which lead to different interpretations (mainly nested implicit quantification) [83]. This work also proves the correctness of the calculus N3 reasoners use. Thus: the results of the reasoners are correct if the defined model theory is followed. Arndt et al. expanded on this work, specifically investigating the excluded constructs, and defined two different mappings from N3 syntax to core logic syntax covering two possible interpretations of N3Logic [5]. Even though this work defines two possible semantics, the difference between these two semantics does not influence the use of N3 in our paper since the semantic differences are only relevant for deeply nested formulas, our formulas are not of that nature (see Listing 3).
More, N3Logic supports at least OWL-RL inferencing [2,3], which can be included during validation: the rules for OWL-RL are specified11
and are supported by every rule language that is at least as expressive as Datalog. This includes N3Logic: the concrete realisation of these rules in N3 can be found online.12
N3Logic, among others, covers existential rules, thus typically rendering the logic undecidable. This brings three trade-offs. First, we note that decidability does not imply that reasoning times are acceptable: even decidable logics can result in reasoner time-outs. Second, we expect the validation rules to be used in a distributed context (the Web). Thus, even though relevant research investigates the maximal subset of existential rules which are still decidable [6,21,80], we have no control over all potential rules used together with our validation rules, and cannot use these well-studied mechanisms ensuring a set of existential rules to be decidable. These mechanisms need to consider all rules together. Third, for example, the logic framework Prolog is a widely used Turing complete programming language. Even though this is a desirable property for a programming language, making it very expressive, checking properties over a Turing complete language is undecidable. Prolog remains a popular choice: we can conclude that using this undecidable logic allows for expressiveness, without necessarily introducing a performance bottleneck.
The rule language introduced together with N3Logic is N3 [10,11]. Everything covered by RDF 1.1 Semantics [44] is covered in N3. Syntactically, it is a superset of Turtle [7]. N3 allows declaring inferencing rules, axioms, and constraints in the same language. As in RDF, blank nodes are understood as existentially quantified variables and the co-occurrence of two triples as in the RDF graph of formulas (9) and (10) is understood as their conjunction. More, N3 supports universally quantified variables, indicated by a leading question mark
Reasoner Reasoners that support N3Logic include FuXi, cwm, and EYE. FuXi13
We choose the EYE reasoner as it fulfills the requirements as presented in Section 4. Furthermore, its ability to combine forward and backward chaining proves especially useful since constraint types are mostly localized to single relationships [14]. This means backward chaining has a potentially large impact on the performance: reasoning during validation can be very targeted, and in most cases, only facts that are relevant to the defined constraints are inferred.
Our implementation is dubbed “Validatrr”: a validator using rule-based reasoning. A Node.js JavaScript framework was created to discover and retrieve the vocabularies and ontologies as required by the use case, manage the commandline arguments, etc. The implementation is available at https://github.com/IDLabResearch/validatrr, and the set of validation rules (Fig. 2, center) is available at
Execution example
As example, we validate an RDF graph with a custom set of inferencing steps using SHACL constraints. We take into account the example of the introduction (formula (1)), but the case where

Person shape in SHACL
To make sure
To make sure SHACL constraints are correctly interpreted, SHACL translation rules need to be included during validation (Constraint translation). The general “Exact Qualified Cardinality Restrictions” RDF-CV constraint is inferred from the SHACL constraint of Listing 1, using the rules of Listing 2 (Constraints*).

Translate the SHACL shape to a general constraint type
Validation makes use of general rules, i.e., Listing 3 (Validation). Lines 11–14 define how to find a violation, relying on built-ins: gather a set of resources in a list (

Validate using general constraint types
The general violations are translated into a report format (Fig. 2, Violations*), e.g., using the SHACL Validation Report [56] (see Listing 4). The result is a set of triples using the exact same input and output as a SHACL processor. However, the RDF graph’s supported entailments can be matched to the use case, and the process is a single reasoning execution with transparent rule sets.

Translate the general violations to the SHACL validation report
Moreover, different constraint descriptions are easily supported via the general constraint types. Given the OWL restriction of Listing 5: using a different set of rules, we can translate this restriction into the same constraint type (Listing 6). The validation process continues exactly the same.

An OWL restriction

Translate the OWL restriction to the general constraint type
To validate the hypotheses of Section 1.2, we compare Validatrr to different validation approaches. We show that Validatrr (i) accurately explains the root cause of why a violation occurs in more cases than specified in SHACL, given the SHACL core constraint components (accepting Hypothesis 1, see Section 6.1); (ii) returns an accurate number of validation results with respect to the used set of inferencing steps, compared to an integrity constraints validator with a fixed set of inferencing steps using RDFUnit (accepting Hypothesis 2, see Section 6.2); and (iii) supports an equivalent number of constraint types than existing approaches (accepting Hypothesis 3, see Section 6.3). The performance evaluation shows that our implementation is faster than the state of the art when combining inferencing and validation for commonly published datasets (accepting Hypothesis 4, see Section 6.4).
Root cause explanation of constraint violations
Using the logical proof, we increase the explanation’s accuracy compared to what is currently expected of a validation approach. SHACL is a W3C Recommendation standardizing the description of constraints and violation reports for RDF graph validation. We show that the logical proof produced by the rule-based reasoning execution provides more detailed root cause explanations of constraint violations, compared to SHACL’s violation report description.
The SHACL recommendation provides a set of test cases, enabling implementations to prove compliance.17
The validation report denotes the violating resources viaThis example is similar to the following SHACL test case: https://github.com/w3c/data-shapes/blob/gh-pages/data-shapes-test-suite/tests/core/node/or-001.ttl.

Validation report of an OR constraint
The rule-based reasoning execution of Validatrr can generate a proof, showing the rules used to reach a conclusion. This logical proof allows to determine, for each violation, which part of the RDF graph is the root cause of the violation, and which axiom of the used ontology triggered an inference causing the violation. Listing 8 shows the part of the proof which contains the rules deriving the violation. For

Validation proof of an OR constraint
Due to this proof, Validatrr can provide detailed explanations for the root causes of violations for all SHACL core constraint components, compared to 46%–75% of SHACL-conforming implementations. Analysis of the SHACL specification shows that, out of the 28 core constraint components, 13 (46%) provide a full explanation of the root cause (summarized in Table 2). For eight of the remaining components (an additional 29%), the validation report returns which resource violates which constraint, but does not return a detailed explanation. For example, a
Analysis of root cause explanation of violations for SHACL core constraint components. Validatrr can provide more detailed explanations for up to 56% of the components compared to SHACL-conforming implementations
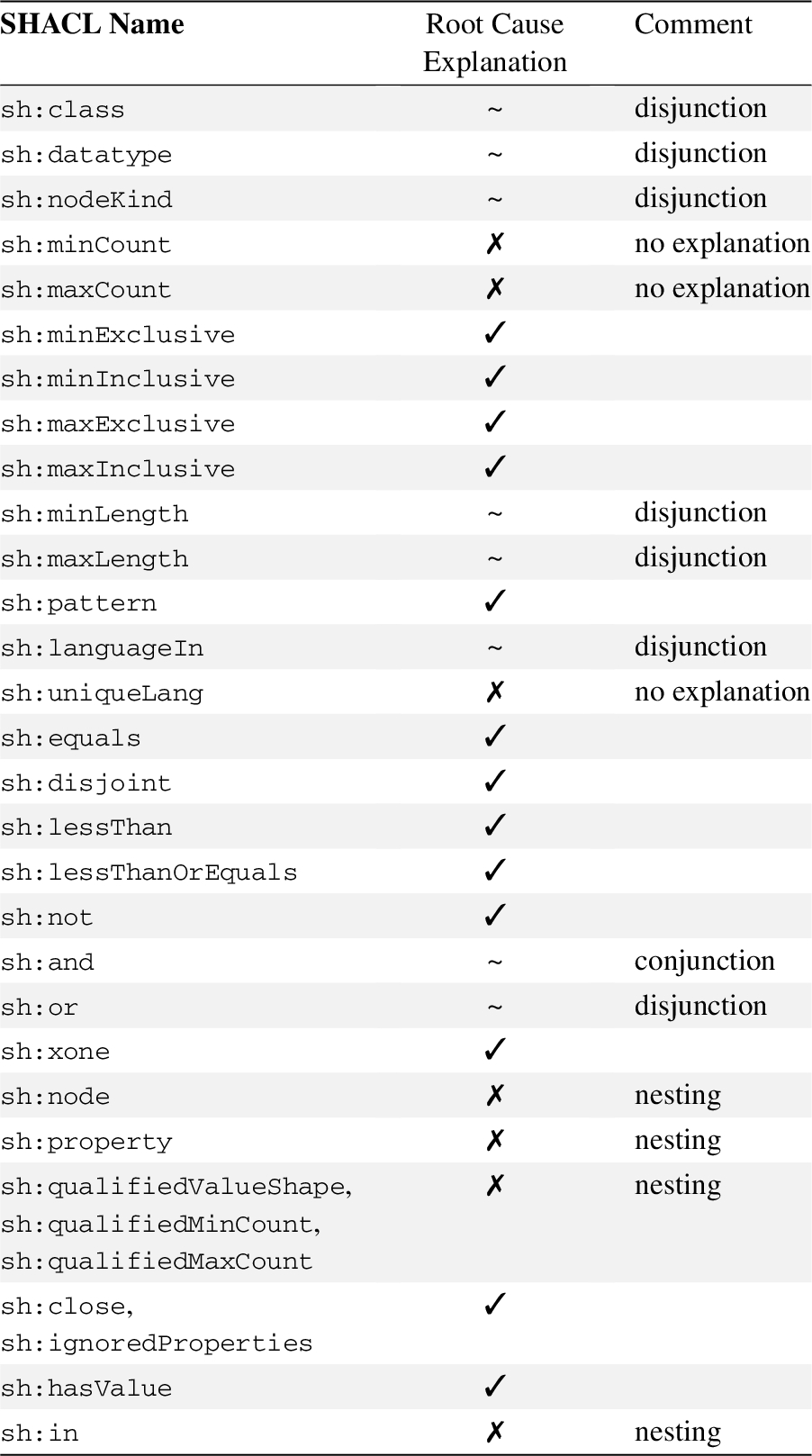
Compared to SHACL-conforming implementations, Validatrr supports, among others, explanation of disjunction and nested shapes. Our approach provides detailed explanations for all core components of W3C’s recommended high-level language to describe constraints. We thus accept Hypothesis 1.
Validatrr finds a more accurate number of violations compared to the state of the art. To prove this, we first compare Validatrr with the state of the art functionally, and then include a set of inferencing steps to clarify the difference.
Specifically, we compare with RDFUnit [57]. Hartmann et. al explicitly proposed using query-based approaches for validation [15], and RDFUnit is such a query-based approach, relying on a SPARQL endpoint, and describing the constrains using SPARQL templates named Data Quality Test Patterns (DQTP). As such, RDFUnit is highly configurable and one of the implementations that supports SHACL.20
Functional comparison We compare with the original pattern library of RDFUnit [57]. This pattern library is the closest to the constraint types as introduced by Hartmann et al. [17,43]: the mapping between those two is presented in previous work [4]. We test all unit tests defined by RDFUnit21
The validation results depend on the used set of inferencing steps. RDFUnit implicitly takes “every resource is an
Table 3 summarizes the results. For each constraint, we mention the test case’s name, the number of violations that RDFUnit detects, and the number of violations that Validatrr detects using the different sets of inferencing steps. The table shows the impact of using different sets of inferencing steps: depending on the set, Validatrr finds a different number of violations. More, Validatrr detects more violations using the same set of inferencing steps: there is a higher number of found violations for Validatrr under υ compared to RDFUnit.
Comparing RDFUnit to Validatrr using different sets of inferencing steps (∅, υ, and ρ). Validatrr finds more violations given the same set of inferencing steps, and the set of inferencing steps used impacts the result. Test cases where Validatrr outperforms RDFUnit are starred. Rows where Validatrr and RDFUnit differ are marked gray
Validatrr finds more violations and supports more constraint types than RDFUnit, denoted as starred test cases
Impact of including sets of inferencing steps during validation Running Validatrr using different sets of inferencing steps impacts the number of found violations. Validatrr is designed to easily configure this set using inferencing rules (Fig. 2, top-left). The results are found in Table 3, comparing the different Validatrr columns. On the one hand, certain violations are not found without entailment (∅), as is the case for
Compared to existing validation approaches, our approach allows including custom sets of inferencing steps during validation. The inferencing provenance is retained in the proof, as all inferencing occurs during a single reasoning execution. The logical proof can thus distinguish between violations that are caused due to constraint violations in the original RDF graph, or due to entailment during validation. We thus accept Hypothesis 2.
Validatrr can support an equivalent number of constraint types compared to existing validation approaches such as RDFUnit and SHACL. In the previous section, we showed we functionally outperform the original pattern library of RDFUnit whilst including a custom set of inferencing steps during validation. In this section, we compare our number of supported constraint types to that of SHACL [56].
We test Validatrr against general constraint types [42,43], to show that the number of supported constraint types is equivalent to SHACL. We do not test specifically against SHACL’s test cases, as Validatrr is independent of the constraint language. We provide a set of test cases, used to test these different constraint types.22
Hartmann et al. investigated the constraint type support of SHACL, and stated that its coverage is 52% [42]. We updated the coverage report as presented by Hartmann et al. to take the latest SHACL specification and advanced features into account [54,56]. The relevant data is available at Section x, and online.23
Validatrr can cover up to 94% of all constraint types – given the current expressive support for built-ins – and has been tested to cover a similar number of constraint types as SHACL.24
The test report is available at
Achieving 100% coverage (i.e., the remaining five constraint types) requires additional development on the reasoner to support specific built-ins. “Whitespace Handling” and “HTML Handling” require parsing built-ins, and “Valid Identifiers” requires a built-in to test URIs’ dereferencability. The remaining two types (“Structure” and “Data Model Consistency”) are general constraint types, defined by Hartmann et al., requiring SPARQL support. Supporting these constraint types requires a translation from SPARQL queries to N3 rules, for which we refer to related work [77].
A validation approach that supports a custom set of inferencing steps is faster than a validation system that includes a reasoning preprocessing step. We first compare the performance of Validatrr to that of RDFUnit, both without and with a custom set of inferencing steps.
For these performance evaluations, we used 300 data sets with sizes ranging from ten to one million triples, and an executing machine consisting of 24 cores (Intel Xeon CPU E5-2620 v3 @ 2.40 GHz) and 128 GB RAM. All evaluations were performed using untampered docker images for both approaches to maintain reproducibility, the different tests were orchestrated using custom scripts. All timings include the docker images’ initialization time. The data is available online.25
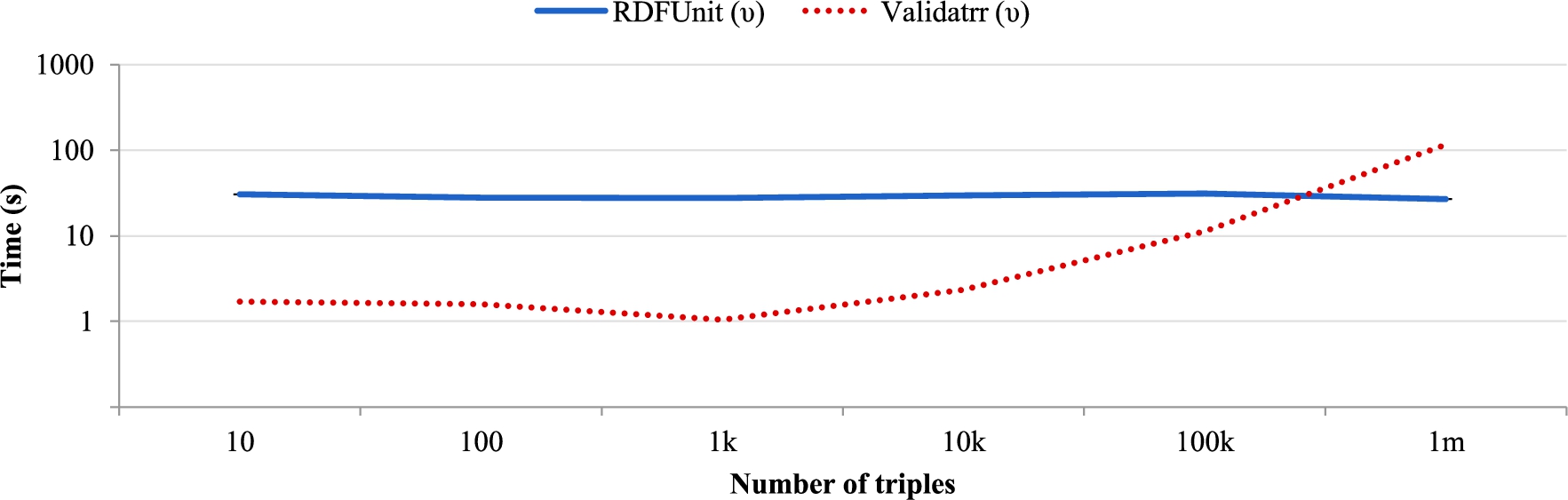
Validatrr’s execution speed (dotted line) is up to an order of magnitude faster than RDFUnits’s (solid line) when the number of triples per RDF graph is below 100,000 triples.
Performance comparison We compare the execution time of Validatrr to RDFUnit, following RDFUnit’s original evaluation method. We use a default set of constraints for a fixed set of schemas, as defined by Kontokostas et al. [57]. We consider six commonly used schemas: FOAF, GeoSPARQL, OWL, DC terms, SKOS, and Prov-O. For each schema, we use RDF graphs of varying size. The validated RDF graphs’ size range from ten triples to one million triples, in logarithmic steps of base ten. At most ten different RDF graphs – per schema, per RDF graph size – were downloaded, by querying LODLaundromat’s SPARQL endpoint [8].
We validate the different RDF graphs against their respective schema using the default set of constraints and set of inferencing steps (υ) of RDFUnit, and measure total execution time of Validatrr and RDFUnit. The median execution time across all schemas is plotted against RDF graph size per approach in a log-log scale (see Fig. 3). To make sure we can combine execution times across schemas, we tested the null hypothesis that no significant difference in execution time was found between schemas, by performing an ANOVA statistical test with single factor “used schema” for measurement variable “execution time per triple”, executed pairwise for all used schemas. The null hypothesis with
Validatrr’s execution time is highly correlated with the number of triples of the validated RDF graph. Regression analysis shows an R square value of 0.9998, the null hypothesis with
Without customizing the set of inferencing steps and docker images, Validatrr is faster for small RDF graphs. Validatrr is about an order of magnitude faster until 10,000 triples, namely, 1–2 s per RDF graph compared to 30 s per RDF graph for RDFUnit. After 100,000 triples, Validatrr is slower than RDFUnit, as Validatrr’s linearly growing execution time surpasses RDFUnit’s execution time.
Custom inferencing steps’ performance impact We compare the execution time of Validatrr to RDFUnit when using a custom set of inferencing steps. We use RDFS entailment (ρ): it is commonly used, and the evaluation of Section 6.2 showed it affects the number of violations found. For Validatrr, we include the RDFS rules during validation. For RDFUnit, we include an RDFS entailment preprocessing step, as RDFUnit’s docker image does not allow configuration to use a SPARQL engine that has inferencing capabilities. However, even if it would be possible to use a different SPARQL engine, a reasoning preprocessing step would still be needed for use cases that require support for a specific set of inferencing steps, not covered by typical entailment regimes [1].
To keep the measures comparable, we use the EYE reasoner as used in Validatrr with the same RDFS entailment rule set to execute the reasoning preprocessing step. This also precludes the need to compare with other sets of inferencing steps than RDFS entailment: the conclusions will be similar due to the usage of the same reasoner. Figure 4 depicts the timings of RDFUnit and Validatrr. For RDFUnit, it depicts the combined timings of RDFS entailment as preprocessing step and validation on the newly inferred RDF graph (RDFUnit (ρ)), and it depicts solely the validation timings on the newly inferred graph (RDFUnit). For Validatrr, it depicts the timings of the validation with the two sets of inferencing rules (Validatrr (ρ) and Validatrr (υ), respectively).

Validatrr’s performance is not affected when including the RDFS inferencing rules (dotted line, compared to the lighter dotted line), whereas the reasoning preprocessing time deteriorated RDFUnit’s performance (solid line, compared to the lighter solid line).
Validatrr’s performance is not affected by using a different set of inferencing steps, whereas the preprocessing step deteriorates RDFUnit’s performance. This effect is noticable starting from RDF graphs of 10,000 triples. For RDF graphs of one million triples, compared to the previous evaluation, median execution time rises from 27 s to 210 s for RDFUnit, largely due to the reasoning preprocessing step.
The number of found violations inversely affects the validation execution speed. Most original violations handle missing domain and range classes, which is inferred in RDFS entailment. Statistical analysis does not allow us to accept the null hypothesis that the number of violations found is inversely correlated to the execution time. However, we notice increased performance for both approaches when less violations need to be handled. Compared to previous evaluation, for one million triples, execution time (without reasoning preprocessing) drops from 27 s to 21 s for RDFUnit, and from 116 s to 80 s for Validatrr.
The performance evaluations show that the execution time of Validatrr outperforms RDFUnit for small RDF graphs up to 100,000 triples, and its linear scaling behavior is not affected by including RDFS entailment during validation. Validatrr outperforms RDFUnit when reasoning preprocessing is needed, i.e., when the used SPARQL endpoint does not support inferencing up to the needed expressiveness, or cannot be sufficiently customized to the use case. Where RDFUnit first needs to infer all implicit data before validation, Validatrr can infer this data during validation, and thus performs better. We thus accept Hypothesis 4.
In this section, we discuss our proposed rule-based reasoning validation approach and introduced implementation. We provide concluding remarks and guide towards future work with respect to (i) the detailed root cause explanations, (ii) the fine-grained level of configuration, (iii) the number of constraint types supported by our approach, and (iv) the scaling behavior of Validatrr’s performance. We close by providing some further research perspectives.
The logical proof of a validation execution, generated by the rule-based reasoner, provides a more detailed root cause explanation of why a violation occurs than the state of the art. Our evaluation does not imply that existing approaches and implementations are not capable of providing a similar level of detail. However, it does show the feasibility of more detailed explanations, and the capability of our approach to generate them. To improve the level of detail of explanations provided in the validation report, our work can guide future iterations of, e.g., SHACL’s validation report descriptions, and the algorithms that generate them.
Our approach is fully configurable by adjusting different rule sets: only a single declaration and single implementation is needed to support different constraint languages, sets of inferencing steps, and validation report descriptions. This level of control considerably increases expressiveness and complexity of the validator, and a small change in a rule set could have large effects on the validation results. However, such fine-grained configuration is not needed for every use case. Future work requires investigation into configuration defaults for, among others, ShEx and SHACL: to what extend can Validatrr be configured to function as a compliant ShEx or SHACL validator, and how will the combination of inferencing rule sets look like? A short-term goal is showing that Validatrr with the right configuration passes the core SHACL tests and is included as a compliant SHACL validator in the respective W3C documentation.26
Our approach supports an equivalent number of constraint types compared to the state of the art, with description logic-expressiveness up to at least OWL-RL. An important point of interest is handling recursion, one of the main differences between ShEx and SHACL. The semantics of ShEx are defined, also for recursion [13], and – as it is currently undefined in the SHACL specification [56] – current works are investigating recursion in combination with negation for SHACL [24]. Future work for our approach is investigating recursion, taking into account the conclusions and mentioned complexity issues of aforementioned works. Accepting that the general problem is NP-Hard, using rule-based reasoning gives us a strong tool to handle recursion. A rule-based reasoner such as the EYE reasoner has path detection: different validations calling each other can be handled, as path detection prevents the reasoner from applying the same rule to the same data twice. In this regard, we can further investigate whether the strategies of Answer Set Programming [33] help to solve related problems, taking into account their two kinds of negation (Negation as Failure and strong negation). After investigating which rules are needed to handle recursion, the user can choose whether or not recursion should be supported during validation, as these extra rules can be added or not.
The performance of Validatrr is up to an order of magnitude faster than RDFUnit for RDF graphs up to 100,000 triples, and scales linearly w.r.t. the number of triples in the RDF graph. However, it scales less than RDFUnit, making Validatrr less suitable for large RDF graphs. As such, a trade-off must be made: our approach, which performs better for smaller RDF graphs, allows fine-grained configuration and detailed explanation, whereas other approaches scale better but do not provide the same level of detail. For future work, further investigation into related works that aim to improve the performance of rule-based reasoners, such as the work of Arndt et al. [3], can be used to improve the current scaling behavior of Validatrr.
Further research perspectives include validation of RDF graph generation descriptions, and automatic graph refinement based on violation explanations. The combination reduces the effort required to provide high-quality RDF graph generation descriptions, and is being further investigated by Heyvaert et al. [45].
On the one hand, a declarative description for generating an RDF graph – e.g., using the RDF Mapping Language (RML) [32] – can be validated, to show whether that description produces a valid RDF graph [31]. Certain constraints that apply to the description can be inferred based on the constraints that apply to the RDF graph. By including a custom inferencing rule set that reflects such inferencing in Validatrr, the generation description can be validated based on the set of constraints that apply to the RDF graph. As such, only a single set of constraints needs to be maintained and understood. The requirements of this custom inferencing rule set, and which constraint types can be applied to generation descriptions, is future work.
On the other hand, rules that handle the accurate explanations of why a violation is returned, can provide suggestions to (automatically) resolve the violation. For example, the constraint specifying “every book should have either an ISSN or an ISBN number” is violated by a resource that has both numbers. Suggestions include removing the ISSN number and removing the ISBN number. Which types of suggestions can be provided, and in which order these should be applied, is future work.
Footnotes
Acknowledgements
The described research activities were funded by Ghent University, imec, Flanders Innovation & Entrepreneurship (VLAIO), and the European Union. Ruben Verborgh is a postdoctoral fellow of the Research Foundation – Flanders (FWO).