
Abstract
Mobile hardware has advanced to a point where apps may consume the Semantic Web of Data, as exemplified in domains such as mobile context-awareness, m-Health, m-Tourism and augmented reality. However, recent work shows that the performance of ontology-based reasoning, an essential Semantic Web building block, still leaves much to be desired on mobile platforms. This presents a clear need to provide developers with the ability to benchmark mobile reasoning performance, based on their particular application scenarios, i.e., including reasoning tasks, process flows and datasets, to establish the feasibility of mobile deployment. In this regard, we present a mobile benchmark framework called MobiBench to help developers to benchmark semantic reasoners on mobile platforms. To realize efficient mobile, ontology-based reasoning, OWL2 RL is a promising solution since it (a) trades expressivity for scalability, which is important on resource-constrained platforms; and (b) provides unique opportunities for optimization due to its rule-based axiomatization. In this vein, we propose selections of OWL2 RL rule subsets for optimization purposes, based on several orthogonal dimensions. We extended MobiBench to support OWL2 RL and the proposed ruleset selections, and benchmarked multiple OWL2 RL-enabled rule engines and OWL reasoners on a mobile platform. Our results show significant performance improvements by applying OWL2 RL rule subsets, allowing performant reasoning for small datasets on mobile systems.
Introduction
Advances in mobile technologies have enabled mobile applications to consume semantic data, with the goal of e.g., collecting context – [63,71] and location-related data [10,68], achieving augmented reality [52,70], performing recommendations [72], accessing linked biomedical data (m-Health) [48] and enabling mobile tourism [33]. Automated reasoning, an essential Semantic Web pillar, involves the inference of useful information based on the semantics of ontology constructs, domain-specific if-then rules, or both. Giving the availability of advanced mobile technology and large volumes of mobile-accessible semantic data, we hence consider it opportune to investigate the potential of semantic reasoning on mobile, resource-constrained platforms. In light of recent empirical work [15,31], which indicates that mobile reasoning performance still leaves much to be desired, we choose to focus on benchmarking and optimizing mobile semantic reasoning. In particular, we discern a clear need for benchmarking specific application scenarios, including reasoning task (e.g., ontology or rule-based reasoning), process flow (e.g., frequent vs. incremental reasoning) and rule- and datasets, as it will allow mobile developers to make more informed decisions – for instance, in case of poor performance of their particular application scenario, they may choose hybrid solutions that combine mobile- and server-deployed reasoning [2,65].
In traditional Semantic Web reasoning applications, OWL2 DL is the most popular representation and reasoning approach. Regarding resource-constrained systems however, it has been observed that OWL2 DL is too complex and resource-intensive to achieve scalability [15,31]. Reflecting this, most mobile semantic reasoners i.e., tailored to resource-constrained systems, instead focus on rule-based OWL axiomatizations, such as custom entailment rulesets [1,34] or OWL2 RL rulesets [43,58]. Indeed, OWL2 RL is an OWL2 profile with a stated goal of scalability, partially axiomatizing the OWL2 RDF-based semantics as a set of rule axioms. Further, a rule-based axiomatization allows easily adjusting reasoning complexity to the application scenario [58] or avoiding resource-heavy inferences [12,54], by applying subsets of rule axioms. In contrast, transformation rules used in tableau-based DL reasoning are often hardcoded, making it hard to de-select them at runtime [58]. Also, most classic DL optimizations improve performance at the cost of memory [15], which is limited in mobile devices. At the same time, as only a partial axiomatization, OWL2 RL does not guarantee completeness for TBox reasoning [43]; and places syntactic restrictions on ontologies to ensure all correct inferences. Nevertheless, we find this expressivity trade-off acceptable in case it would render semantic reasoning feasible on resource-constrained platforms.
In this regard, our objective is three-fold:
developing a mobile reasoning benchmark framework (called MobiBench) that allows developers to evaluate the performance of reasoning on mobile platforms (reasoning times, memory usage), for specific scenarios and using standards-based rule- and datasets. Key features of MobiBench include a uniform, standards-based rule and data interface across reasoning engines, as well as its extensibility and cross-platform nature, allowing benchmarks to be applied across multiple platforms;
optimizing semantic reasoning on mobile platforms, by studying the following three OWL2 RL rule subset selections: (i) Equivalent OWL2 RL rule subset, which leaves out logically equivalent rules; i.e., rules of which the results are covered by other rules; (ii) Purpose and reference-based subsets, which divides rule subsets based on their purpose and referenced data; and (iii) Removal of resource-heavy rules that have a large performance impact – although this will result in missing certain inferences, we feel that developers should be able to weigh their utility vs. computational cost; and
performing mobile reasoning benchmarks, which measure the performance of the materialization of ontology inferences, using the AndroJena and RDFStore-JS rule systems loaded with different OWL2 RL ruleset selections, as well as three OWL2 DL reasoners (HermiT, JFact and Pellet). We note that, although the proposed OWL2 RL subset selections were construed and evaluated in the context of resource-constrained platforms, they may be applied in any kind of computing environment.
This paper is built on previous work, which presented a clinical benchmark [62] and an initial version of the Mobile Benchmark Framework [61], which only supplied an API, restricted benchmarking to rule-based reasoning, and did not attempt optimizations or applications of OWL2 RL.
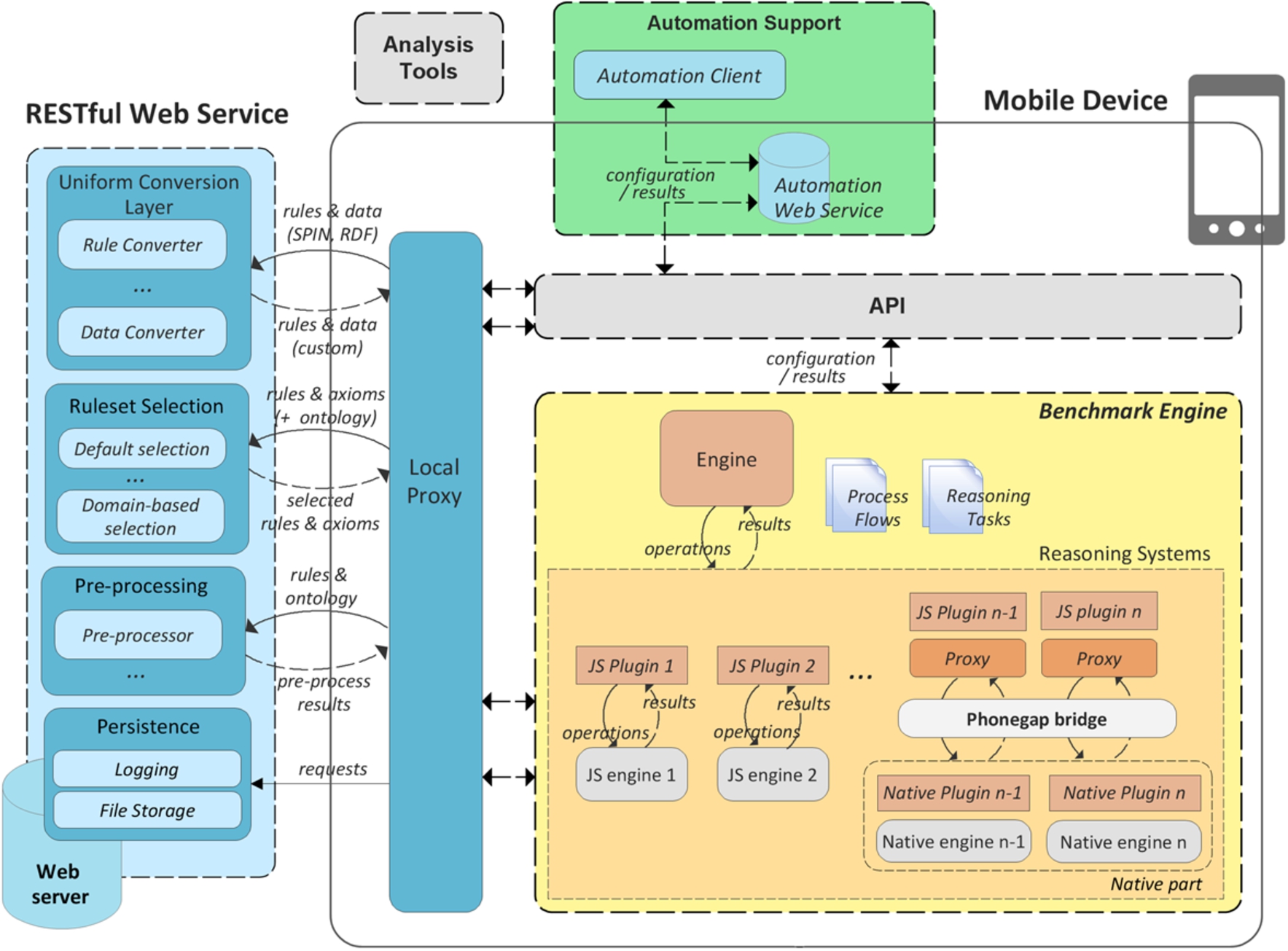
MobiBench framework architecture.
The paper is structured as follows. Section 2 introduces the MobiBench framework, presenting its architecture and main components, and Section 3 discusses how mobile developers can utilize MobiBench. In Section 4, we shortly discuss the OWL2 RL profile and our reasons for focusing on it, and detail its implementation as a ruleset. Section 5 elaborates on our selection of OWL2 RL rule subsets for optimization purposes. Section 6 presents and discusses the benchmarks we performed using MobiBench. We review related work in Section 7, and end with conclusions and future work in Section 8.
The goal of the MobiBench benchmark framework is to allow studying and comparing reasoning performance on mobile platforms, given particular application scenarios, including reasoning task, process flow and rule- and datasets. An important focus lies on extensibility, with clear extension points allowing different rule and data formats, tasks and flows to be plugged in. Moreover, given the multitude of mobile platforms currently in use (e.g., Android, iOS, Windows Phone, BlackBerry), MobiBench was implemented as a cross-platform system.
Figure 1 shows the architecture overview of the MobiBench framework. The
To support OWL2 RL, MobiBench was extended with the following services:
A remote RESTful Web Service, deployed on a server (e.g., the developer’s PC), comprises these services, and also hosts some utility services to persist benchmark output (
For portability across platforms, MobiBench was implemented in JavaScript (JS) and deployed using Apache Cordova [6] for mobile platforms and JDK8 Nashorn [44] for PC (this version is used for testing), which allows native, platform-specific parts to be plugged in. We note that this also allows MobiBench to easily benchmark JavaScript reasoners, which are usable in mobile websites or cross-platform, JavaScript-based apps (e.g., developed using Apache Cordova, Appcelerator Titanium [8]) with a write-once, deploy-everywhere philosophy. We currently rely on Android as the deployment platform, since most reasoners are either developed for Android or written in Java (which facilitates porting to Android), but MobiBench could be easily deployed on other platforms as well. The MobiBench framework can be found online [60].
In the subsections below, we elaborate on the main MobiBench components, namely the Uniform Conversion Layer (Section 2.1), Ruleset Selection Service (Section 2.2), Pre-Processing Service (Section 2.3) and Benchmark Engine (Section 2.4); and indicate extension points for each component (see parts on Extensibility). Section 3 shows how developers can utilize the benchmark framework.
Uniform conversion layer
The goal of the Uniform Conversion Layer is to handle the multitude of rule (and data) formats currently supported by rule-based reasoners. It supplies a uniform, standards-based resource interface across reasoning engines, which dynamically converts the input to their supported formats. The major benefit of this layer is that it allows developers to re-use a single rule- and dataset across different reasoners.
A range of semantic rule standards are currently in use, including the Semantic Web Rule Language (SWRL) [28], Web Rule Language (WRL) [4], Rule Markup Language (RuleML) [16], and SPARQL Inferencing Notation (SPIN) [37]. Some reasoners also introduce their own custom formats (e.g., Apache Jena) or rely on non-Semantic Web syntaxes (e.g., Datalog: IRIS, PocketKRHyper). When benchmarking multiple systems, this multitude of formats prevents direct re-use of a single rule- and dataset. We chose to support SPIN rules and RDF data as standard input formats; Section 2.1.1 shortly discusses SPIN and our reasons for choosing it.
Since the only available SPIN API is developed for the Java Development Kit (JDK) [36], conversion functions are deployed on an external Web service. To convert incoming SPIN rules, the SPIN API is utilized to generate an Abstract Syntax Tree (AST), which is then visited by a Rule Converter to convert the rule. Section 2.1.2 discusses our current converters, and how new converters can be plugged in. To convert incoming RDF data, a Data Converter can utilize Apache Jena [5] to query and manipulate the data.
SPIN
SPIN is a SPARQL-based rule and constraint language, which provides a natural, object-oriented way of dealing with constraints and rules associated with RDF(S)/OWL classes. In the object-oriented design paradigm, classes define the structure of objects (i.e., attributes) together with their behavior, which includes creating/changing objects (rules) and ensuring a consistent object state (constraints). Similarly, SPIN allows directly associating locally-scoped rules and constraints to their related RDF(S)/OWL classes, using properties such as spin:rule and spin:constraint.
To serialize rules and constraints, SPIN relies on SPARQL [67], a W3C standard with sufficient expressivity to represent both queries and general-purpose rules and constraints. SPARQL is supported by most Semantic Web systems, and is well known by Semantic Web developers. As such, this rule format is more likely to be easily comprehensible to developers. Further, relying on SPIN also simplifies support for our current rule engines (see below).
Rule and data conversion
Regarding rule-based reasoners, our choice for SPIN greatly reduces conversion effort for systems with built-in SPARQL support. RDFStore-JS supports INSERT queries from SPARQL 1.1/Update [67], which are easy to obtain from SPIN rules in their SPARQL query syntax. Both AndroJena and RDFQuery support a triple-pattern like syntax, which likewise makes conversion from SPIN straightforward. Other rule engines lack built-in Semantic Web support, and require more significant conversion effort. Two systems, namely PocketKrHyper and IRIS, accept Datalog rules and facts in a Prolog-style input syntax. For these cases, we utilize the same first-order representation as in the W3C OWL2 RL specification [17], namely
Currently, our converters support SPIN functions that represent primitive comparators (greater, equal, etc.) and logical connectors in FILTER clauses. Advanced SPARQL query constructs, such as (not-)exists, optional, minus and union, are not yet supported. None of the OWL reasoners (Section 2.4.1) required (data) conversion, since they can consume serializations of OWL in RDF out of the box.
Ruleset selection service
To optimize OWL2 RL reasoning on mobile platforms, the Ruleset Selection Service automatically applies the OWL2 RL ruleset selections presented in this paper (Section 5), given one or more selection criteria. Indeed, due to its rule-based axiomatization, the OWL2 RL profile greatly facilitates applying subsets of axioms. In Section 5, we discuss relevant selection criteria in detail, such as logical equivalence with other rules, and subsets based on purpose and reference. As before, since the only available API for SPIN (i.e., the input rule format) [36] is developed for Java, this component is deployed in the Web service.
The Default Selection function selects an OWL2 RL subset, given a list of selection criteria indicating rules and axioms to leave out, replace or add. The Domain-based Selection function leaves out rules that are not relevant to a given ontology – i.e., rules that will not yield any additional inferences (Section 5.2.2). Typically, a ruleset selection is performed once, before reasoning takes place; and in case of ontology updates that require re-executing the selection (e.g., schema updates; Section 5.2.1). Hence, the usefulness of selections will depend on whether the ontology is prone to frequent, relevant updates at runtime. This is especially true in our current setup, where this requires re-invoking the remote service at runtime, causing considerable overhead. By deploying the service directly on the mobile device, and even integrating it with the reasoner, this drawback could be mitigated (see future work).
Pre-processing service
The Pre-processing Service performs pre-processing of the ruleset and target ontology to support OWL2 RL-based reasoning, if required. In particular, the service implements 3 solutions to support n-ary rules (see Section 4.2.3): (1) instantiate the rules, based on schema assertions found in the ontology; (2) normalize (or “binarize”) the input ontology to only contain binary versions of the n-ary assertions, and apply binary versions of the rules; and (3) replace each rule
When applying solutions (1) and (2), pre-processing needs to occur initially and each time the ontology is updated. Solution (3) does not have this drawback, but infers
Benchmark engine
The Benchmark Engine performs benchmarks of reasoning engines, following a particular reasoning setup. A reasoning setup includes a reasoning task and process flow. By supporting different setups, and allowing new ones to be plugged in, benchmarks can be better aligned to real-world scenarios.
In Section 2.4.1, we elaborate on the currently supported reasoning engines. Next, we discuss the available reasoning tasks (Section 2.4.2) and process flows (Section 2.4.3), as well as the supported benchmark measurement criteria (Section 2.4.4).
Reasoning engines
Below, we categorize currently supported engines according to their reasoning support. The engines not indicated as Android systems, excluding the JavaScript (JS) engines, were manually ported to Android. In this categorization, we consider rule engines as any system that can calculate the deductive closure of a ruleset, i.e., execute a ruleset and output resulting inferences (not necessarily limited to this).
Rule-based systems AndroJena [3] is an Android-ported version of Apache Jena [5]. It supplies a rule-based reasoner, which supports both forward and backward chaining, respectively based on the RETE algorithm [22] and SLG resolution [19].
RDFQuery [49] is a JavaScript RDF store that performs queries using a RETE network, and implements a naïve reasoning algorithm.
RDFStore-JS [50] is a JavaScript RDF store, supporting SPARQL 1.0 and parts of SPARQL 1.1. We extended this system with naïve reasoning, accepting rules as SPARQL 1.1 INSERT queries.
IRIS (Integrated Rule Inference System) [13] is a Java Datalog engine meant for Semantic Web applications. The system relies on bottom-up evaluation combined with Magic Sets [11].
PocketKrHyper [55] is a J2ME first-order theorem prover based on a hyper tableaux calculus, and is meant to support mobile semantic apps. It supplies a DL interface that accepts DL expressions and transforms them into first-order logic.
OWL reasoners AndroJena supplies an OWL reasoner, which implements OWL Lite (incompletely) and supports full, mini and micro modes that indicate custom expressivities; and an RDFS reasoner, similarly with full, default and simple modes. For details, we refer to the Jena documentation [7].
The ELK reasoner [32] supports the OWL2 EL profile, and performs (incremental) ontology classification. Further, Kazakov et al. [31] has demonstrated that it can take advantage of multi-core CPUs of modern mobile devices.
HermiT [23] is an OWL2 DL reasoner based on a novel hypertableaux calculus, and is highly optimized for performing ontology classification.
JFact [29] is a Java port of the FaCT++ reasoner, which implements a tableau algorithm and supports OWL2 DL expressivity.
Pellet [56] is a DL reasoner with sound and complete support for OWL2 DL, featuring a tableaux reasoner. It also supports incremental classification.
In Section 6.3, we list the reasoning engines utilized in our benchmarks.
For native engines, the developer similarly implements a native plugin class, and supplies a skeleton JS plugin. The system wraps this skeleton plugin with a proxy object that delegates invocations to the native plugin over the Cordova bridge (see Fig. 1). In practice, native (Android) reasoners often have large amounts of dependencies, some of which may be conflicting (e.g., different versions of the same library). To circumvent this issue, we package each engine and its dependencies as jar-packaged.dex files, which are automatically loaded at runtime. For more details, we refer to our online documentation [60].
Reasoning tasks
Currently, we support three reasoning tasks. Figure 2 illustrates the dependencies between these tasks.
Reasoning types.
Regarding our choice for materializing inferences vs. reasoning per query (e.g., via resolution methods such as SLG [19]), we note that each have their advantages and drawbacks on mobile platforms. Prior to data access, the former involves an expensive pre-processing step that may significantly increase the dataset scale, which is problematic on mobile platforms, but then leaves query answering purely depending on speed of data access. In contrast, the latter incurs a reasoning overhead for each query that depends on dataset scale and complexity. Another materialization drawback is that inferences need to be (re-)computed whenever new data becomes available. For instance, Motik et al. [43] combine materialization with a novel incremental reasoning algorithm, to efficiently update previously drawn conclusions. To allow benchmarking such incremental methods, our framework supports an “incremental reasoning” process flow (Section 2.4.3). For the purposes of this paper, we chose to focus on a materialization approach, although supporting resolution-based reasoning is considered future work. We note that many Semantic Web rule-based reasoners, including DLEJena [42], SAOR [27], OwlOntDb [21] and RuQAR [9], also follow a materialization approach.
To better align benchmarks with real-world use cases, MobiBench supports several process flows, which dictate the times at which operations (e.g., load data, execute rules/perform reasoning) are performed. From previous work [61,62], and in line with our choice for materializing inferences, we identified two useful process flows:
Frequent reasoning: in this flow, the system stores all incoming facts directly in a data store (which possibly also includes an initial dataset). To generate new inferences, reasoning is periodically applied to the entire datastore. Concretely, this entails loading a reasoning engine with the entire datastore each time a certain timespan has elapsed, applying reasoning, and storing new inferences into the datastore.
Incremental reasoning: here, the system applies reasoning for each new fact (currently, MobiBench only supports monotonic reasoning, and thus does not deal with deletions). In this case, the reasoning engine is first loaded into memory (possibly with an initial dataset). Then, reasoning is (re-)applied for each incoming fact, whereby the new fact and possible inferences are added to the dataset. Some OWL reasoners directly support incremental reasoning, such as ELK and Pellet. As mentioned, Motik et al. [43] implemented an algorithm to optimize this kind of reasoning, initially presented by Gupta et al. [25].
Further, we note that each reasoner dictates a subflow, which imposes a further ordering on reasoning operations. In case of OWL inference (implemented via e.g., tableau reasoning), data is typically first loaded into the engine, and then an inference task is performed (LoadDataPerform-Inference). Similarly, RDFQuery, RDFStore-JS and AndroJena first load data and then execute rules. For the IRIS and PocketKrHyper engines, rules are first loaded (e.g., to build the Datalog KB), after which the dataset is loaded and reasoning is performed (LoadRulesDataExecute). For more details, we refer to previous work [61].
Measurement criteria
The Benchmark Engine allows studying and comparing the metrics listed below.
Reasoning times: time needed to infer new facts or check for entailment.
Memory consumption: total memory consumed by the engine after reasoning. Currently, it is not feasible to measure this criterium for non-native engines; we revisit this issue in Section 6.4.
Other related works focus on measuring the fine-grained performance of specific components [39], such as large joins, Datalog recursion and default negation. In contrast, MobiBench aims to find the most suitable reasoner on a mobile platform given an application scenario (e.g., reasoning setup, dataset). Our performance metrics support this objective.
We further note that the performance of the remotely deployed services, i.e., the Uniform Conversion Layer (Section 2.1), Ruleset Selection (Section 2.2) and Pre-Processing (Section 2.3) services are not measured. The Uniform Conversion Layer will not be included in actual reasoning deployments since it only aims to facilitate benchmarking; e.g., for production systems, rulesets can be converted a priori and then stored locally. Regarding the Ruleset Selection and Pre-Processing services, we note that these services are invoked once, before reasoning takes place; and then each time a relevant ontology update (e.g., schema update) occurs at runtime, i.e., which requires re-executing the operation. In scenarios where such updates may take place, we currently do not utilize selections or pre-processing options that would require re-invoking the service (see Section 5.2.1) at runtime. Therefore, and in light of future work to improve these services (e.g., by directly integrating them with the reasoner), we do not measure their performance.
Finally, we note that this paper focuses in particular on performance times and memory consumption on mobile platforms. Clearly, battery usage is an important aspect on mobile platforms as well. In the state of the art, a recent study [47] reported a near linear relation between consumed energy and OWL reasoning time, meaning that energy usage estimates, based on our captured performance times, could already be realistic. Nevertheless, future work involves supporting battery measurements as well.
Using MobiBench for benchmarking
While the previous section indicated how MobiBench can be extended by third-party developers, this section describes how developers can utilize MobiBench for benchmarking. Developers may run benchmarks programmatically (Section 3.1) or use the automation support (Section 3.2). To aggregate benchmark results into summary CSV files, developers can utilize the analysis tools (Section 3.3). For more detailed instructions, we refer to our online documentation [60].
Programmatic access
To execute benchmarks programmatically, developers call the MobiBench’s execBenchmark function with a configuration object, specifying options for reasoning and resources. We show an example (Code 1).

Example benchmark configuration object.
This object specifies the unique engine id, the number of experiment runs, possibly including a “warmup” run (not included in the collected metrics), and whether memory usage should be measured (dumpHeap). The reasoning part indicates the high-level reasoning task (i.e., ontology_inference) and concrete mechanism (i.e., owl2rl), as well as details on dependency tasks (i.e., rule_inference), including its main and sub process flow.
The resources section lists the resources to be used in the benchmark; in this case, an ontology and OWL2 RL axioms and rules. Further, the section specifies that the inst-rules pre-processing method (i.e., instantiate rules; Section 4.2.3 (1)) should be applied, as well as selections inf-inst (i.e., inference-instance subset) and entailed (i.e., leaving out logically redundant rules) (Section 5). Both involve calling the respective services on the Web service. It may also indicate the path for storing inferences (outputInf); as well as the expected reasoning output (confPath), to allow for automatic conformance checking.
Due to the potential combinatorial explosion of configuration options, including engines and their possible settings, resources and OWL2RL subsets, manually writing configurations quickly becomes impractical. For that purpose, we implemented an Automation Support component.
This solution includes an Automation Client, deployed on a server or PC, which generates a set of benchmarks based on an automation configuration; and communicates these benchmarks over HTTP with the Automation Web Service on the mobile device, which locally invokes the MobiBench API and returns the benchmark results. In the Automation Client code, developers specify ranges of configuration options, whereby each possible combination will be used to run a benchmark. Code 2 shows (abbreviated) example code for running a set of OWL2 RL benchmarks.

Example automation configuration.
In this case, one subset leaves out entailed, logically redundant rules (entailed), and the second applies the inf-inst (i.e., inference-instance subset), entailed and domain-based (i.e., selecting a domain-based subset) selections. Both rulesets are applied on all benchmark ontologies, creating a total of 378 benchmarks.
To deal with large amounts of benchmark results, the MobiBench Analysis Tools assemble benchmark results into a CSV file. This file lists the performance results and memory usages per configuration; including process flow and reasoning task, rule subsets, engine-specific options, and datasets.
Further, the Analysis Tools include a utility function to easily compare performance times of two reasoning configurations (e.g., different OWL2 RL subsets), and output both the individual (i.e., per benchmark ontology) and total (i.e., aggregated) differences in performance. The Analysis Tools are available both as source code and a command line utility. See our online documentation [60] for more information.
OWL2 RL realization
We argue that OWL2 RL is a promising solution for ontology-based reasoning on resource-constrained devices, as it targets scalability at the expense of expressivity; while its rule-based axiomatization also provides unique opportunities for optimization, as discussed in Section 5. Although its reduced expressivity leads to a lack of completeness of TBox reasoning [43] and places syntactic restrictions on ontologies, we find this trade-off acceptable if it would lead to ontology-based reasoning becoming feasible on resource-constrained platforms.
In this section, we discuss our realization of the OWL2 RL profile. First, we shortly discuss the OWL2 RL profile (Section 4.1), and then elaborate on our practical implementation (Section 4.2).
OWL2 RL profile
The OWL2 Web Ontology Language Profiles document [17] introduces three OWL2 profiles, namely OWL2 EL, OWL2 QL and OWL2 RL. By restricting ontology syntax and reducing expressivity, these profiles can more efficiently handle specific application scenarios. The OWL2 RL profile is aimed at balancing expressivity with reasoning scalability, and presents a partial, rule-based axiomatization of OWL2 RDF-Based Semantics. Reasoning in OWL2 RL has been found to be decidable, in particular, PTIME-complete with regards to data and taxonomic complexity, and co-NP-complete (PTIME-complete for atomic class expressions) regarding combined complexity [18]. Using OWL2 RL, reasoning systems can be implemented using standard rule engines. The W3C specification [17] presents the OWL2 RL axiomatization as a set of universally quantified, first-order implications over a ternary predicate T, which stands for a generalization of RDF triples. In addition to regular inference rules, OWL2 RL includes rules that are always applicable (i.e., without antecedent), and consistency-checking rules (i.e., with consequent false). Below, we exemplify each type of rules (namespaces omitted for brevity) for later reference. Code 3 shows a “regular” inference rule that types resources based on the subClassOf construct:
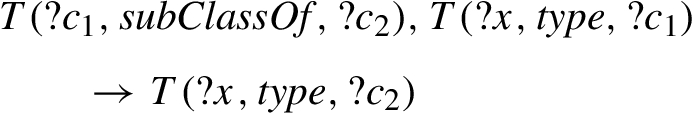
Rule classifying resources (#cax-sco).
The second type of rule lacks an antecedent and is thus always applicable. E.g., the rule in Code 4 indicates that each built-in OWL2 RL annotation property has the owl:AnnotationProperty type:
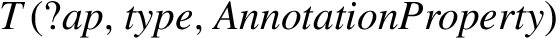
Rule typing annotation properties (#prp-ap).
Thirdly, the consistency-checking rule in Code 5 checks whether an instance of a restriction, indicating a maximum cardinality of 0 on a particular property, participates in said property. If so, the ontology is flagged as inconsistent:

Rule based on maxCardinality restriction to check consistency (#cls-maxc1).
To implement the OWL2 RL axiomatization for general-purpose rule engines, where no particular internal support can be assumed, three types of rules may pose problems: (1) rules that require internal datatype support; (2) rules that are always applicable; and (3) rules referring to lists of elements. Below, we present these issues and our solutions, and we end with a description of our final ruleset implementation.
Rules requiring datatype support
The datatype inference rule #dt-type2 (Code 6) requires literals with data values from a certain value space to be typed with the datatype of that value space (e.g., typing an integer “42” with xsd:int):
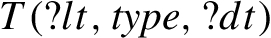
Rule typing each literal with its corresponding datatype (#dt-type2).
Similarly, a second rule (#dt-not-type) flags an inconsistency when a literal is typed with the wrong datatype. Two other datatype rules (#dt-eq and #dt-diff) indicate equality and inequality of literals based on their values; which requires differentiating literals from URIs, to avoid these rules to fire for URI resources as well. These four rules thus require built-in support for RDF datatypes and literals, meaning they cannot be consistently implemented across arbitrary rule engines. Therefore, we chose to leave these rules out of our OWL2 RL ruleset. Related work, including DLEJena [42], the SPIN OWL ruleset by Knublauch [35] and OWLIM OWL2 RL ruleset [12] also do not include datatype rules.
A number of OWL2 RL rules lack an antecedent, and are thus always applicable. One subset of these rules lack variables (e.g., specifying that owl:Thing has type owl:Class), and may thus be directly represented as axiomatic triples to accompany the OWL2 RL ruleset. A second subset comprises “quantified” variables in the consequent; e.g., stating that each annotation property has type owl:AnnotationProperty (Code 4). Likewise, these were implemented by axioms that properly type each annotation property (built-in for OWL2 [26]) and datatype property (supported by OWL2 RL [17]).
Rules referencing element lists
This set of rules includes so-called n-ary rules, which refer to a finite list of elements. A first subset (L1) of these rules lists restrictions on individual list elements (#eq-diff2, #eq-diff3, #prp-adp, #cax-adc, #cls-uni). For instance, rule #eq-diff2 flags an ontology inconsistency if two equivalent elements of an owl:AllDifferent construct are found.
In contrast, rules from the second subset (L2) include restrictions referring to all list elements (#prp-spo2, #prp-key, #cls-int1), and a third ruleset (L3) yields inferences for all list elements (#cls-int2, #cls-oo, #scm-int, #scm-uni). E.g., for (L2), rule #cls-int1 infers that y is an instance of an intersection in case it is typed by each intersection member class; for (L3), for any union, rule #scm-uni (Code 8) infers that each member class is a subclass of that union.
To support rulesets (L1) and (L3), we added two list-membership rules (Code 7) that recursively link each element to preceding list cells, eventually linking the first cell to all list elements:

Two rules for inferring list membership.
Using these rules, #scm-uni (L3) may be formulated as follows (Code 8):

Rule inferring subclasses based on union membership (#scm-uni).
Since the supporting rules (Code 7) eventually link all list elements to the first list cell (i.e.,
However, extra support is required for (L2). For these kinds of n-ary rules, we supply three solutions, each with their own advantages and drawbacks:
Instantiate the rules based on n-ary assertions found in the ontology. Per OWL2 RL rule, this generates a separate rule for each related n-ary assertion, by constructing a list of the found length and instantiating variables with concrete schema references. E.g., a property chain axiom P with properties Instantiated rule supporting a specific property chain axiom (#prp-spo2).
A drawback of this approach is that it requires pre-processing the ruleset for each ontology, and whenever it changes. Although our selections also include a pre-processing option (Section 5.2), this is only needed for optimization. Of course, the severity of this drawback depends on the frequency of ontology updates. In addition, it yields an extra rule for each relevant assertion, potentially inflating the ruleset. On the other hand, instantiated rules contain less variables, and may also reduce the need for joins, as for #prp-spo2 (see also [43]). Further, in case no related assertions are found, no rules will be added the ruleset. Future work includes studying the application of this approach to all rules (Section 8).
Normalize (or “binarize”) the input ontology to only contain binary versions of relevant n-ary assertions. E.g., an n-ary intersection can be converted to a set of binary intersections as follows (Code 10), with I representing the original, n-ary intersection; Binary version of an n-ary intersection. Binary version of rule #cls-int1. Inferences when applying binary #cls-int1.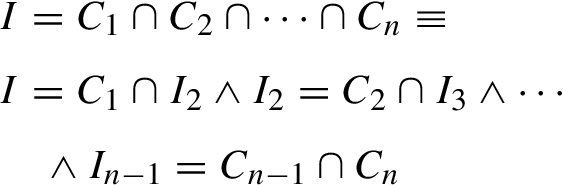


It is not hard to see how this approach only works for recursive rules. Rule #prp-key is not a recursive rule, since it infers equivalence between resources but does not refer to such relations. So, this approach only works for rules #prp-spo2 and #cls-int1 from (L2). Another drawback is that, similar to (1), it requires pre-processing for each ontology and its updates. In particular, each relevant n-ary assertion needs to be replaced by
Replace each rule from (L2) by 3 auxiliary rules. Bishop et al. [12] suggested this solution for OWLIM, based on a W3C note [51]. In this solution, a first auxiliary rule starts at the end of any list, and infers an intermediary assertion for the last element (cell n). Starting from the first inference, a second rule travels up the list structure by inferring the same kind of assertions for cells i (
A distinct advantage of this approach is that, in contrast to (1) and (2), it does not rely on pre-processing. However, each complete, single n-ary inference requires a total of
Based on all observations from Section 4, we collected an OWL2 RL ruleset implementation written in the SPARQL Inferencing Notation (SPIN), based on an initial ruleset created by Knublauch [35]. This initial ruleset relies on built-in Apache Jena functions to implement the rules from Section 4.2.3. Such built-in support cannot be assumed for arbitrary rule engines, which are targeted by our ruleset. Also, it does not specify axioms (Section 4.2.2). Our ruleset contains 69 rules and 13 supporting axioms, and can be found in Appendix A. This ruleset includes the two list-membership rules (Code 7) for n-ary rules from sets (L1) and (L3) (Section 4.2.3). To add support for a particular solution for (L2), our Web service needs to be contacted (Section 2.3) to pre-process the necessary rules or ontology, and/or add the rules (e.g., binary versions, auxiliary rules) to the ruleset. Note that our evaluation does not compare the performance of these n-ary rule solutions; this is future work.
In Section 5.4, we discuss options for checking conformance with OWL2 RL semantics.
OWL2 RL optimization
This section discusses OWL2 RL ruleset selections with the goal of optimizing ontology-based reasoning. We note that, while this solution was construed and evaluated for resource-constrained platforms, it may be applied in any kind of computing environment. We consider three selections: leaving out redundant rules (Section 5.1), dividing the ruleset based on rule purpose and references (Section 5.2), and removing resource-heavy rules (Section 5.3). We note that most1
Aside from the selection presented in Section 5.3, as it focuses in particular on leaving out resource-heavy rules.
For the purpose of these selections, we introduce the terms owl2rl-schema-completeness and owl2rl-instance-completeness, to indicate when a selection respectively derives all schema inferences and instance inferences covered by the OWL2 RL axiomatization. Although OWL2 RL reasoning infers all ABox inferences over OWL2 RL-compliant ontologies, it does not cover all TBox inferences dictated by the OWL 2 semantics [38,43], hence our introduction of these specialized terms. Further, we discuss conformance with the OWL2 RL W3C specification (Section 5.4).
As mentioned by the OWL2 RL specification [17], the presented ruleset is not minimal, as certain rules are implied by others. The stated goal of this redundancy is to make the semantic consequences of OWL2 constructs self-contained. Although this is appropriate from a conceptual standpoint, this redundancy is not useful when optimizing reasoning.
Aside from rules that are entailed by other rules (Section 5.1.1), opportunities also exist to leave out specialized rules by introducing extra axioms (Section 5.1.2) or replacement by generalized rules (Section 5.1.3). Some inference rules may also be considered redundant at the instance level, since they do not contribute to inferring instances (Section 5.1.4).
Entailments between OWL2 RL rules
A first set of rules is entailed by #cax-sco (see Code 3), each time combined with a second inference rule. For instance, #scm-uni (see Code 8) indicates that each class in a union is a subclass of that union. Together, these two rules entail the #cls-uni rule (Code 13). This rule infers that each instance of a union member is an instance of the union itself:

Rule that infers membership in OWL unions (#cls-uni).
Code 14 shows that the rule #cls-uni, for each instantiation of the input variables, is covered by #scm-uni + #cax-sco:

Entailment of #cls-uni by #scm-uni, #cax-sco.
Applying #scm-uni on two premises from #cls-uni returns inference (a). Then, #cax-sco is applied on the remaining premise, together with (a). This yields the inference in (b), which equals the #cls-uni consequent. As such, this rule may be left out without losing expressivity. Similarly, it can be shown that rules #cls-int2, #cax-eqc1 and #cax-eqc2 are entailed by #cax-sco, each time combined with a schema-based rule.
A second set of inference rules is entailed by the #prp-spo1 rule, each time combined with rules that indicate equivalence between owl:equivalent [Class|Property] and rdfs:sub[Class|Property]Of. Similar to #cax-sco, #prp-spo1 (Code 15) infers that resources related via a sub property are also related via its super property:
Rule that infers new resource relations (#prp-spo1).
E.g., the #scm-eqp1 (Code 16) rule indicates that two equivalent properties are also sub properties:

Rule inferring sub properties (#scm-eqp1).
These two rules collectively entail the rule #prp-eqp1 (Code 17). This rule infers that, for two equivalent properties, any resources related via the first property are also related via the second property:

Rule for property membership (#prp-eqp1).
This entailment is shown by Code 18:
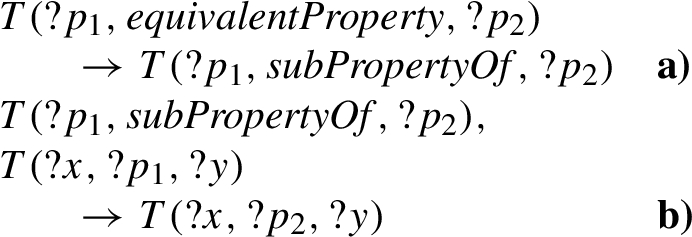
Entailment of #prp-eqp1 by #scm-eqp1, #prp-spo1.
By applying #scm-eqp1 on the first premise from #prp-eqp1, the inference from (a) is returned. Applying #prp-spo1 on this inference and the remaining premise yields (b), which equals the #prp-eqp1 consequent. This rule may thus be left out. Rule #prp-eqp2 is similarly equivalent to these two rules.
Other rules are covered by single rule. The #eq-trans rule (Code 19) indicates the transitivity of owl:sameAs:

Rule indicating transitivity of owl:sameAs (#eq-trans).
This rule is entailed by #eq-rep-o (Code 20), which indicates that, for any triple, subject resources are related to any resource equivalent to the object:

Rule inferring new relations via owl:sameAs (#eq-rep-o).
By partially materializing the premise of #eq-rep-o, Code 21 shows how this rule entails #eq-trans.
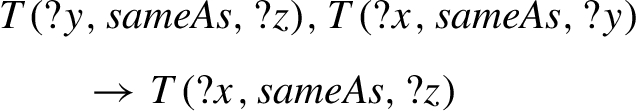
Entailment of #eq-trans by #eq-rep-o.
When executing the #eq-rep-o rule on suitable data, the
Finally, we note that some rules could potentially be removed, depending on type assertions found in the dataset. Rules #cls-maxqc4 & #cls-svf2 support restrictions that apply to owl:Thing, and thus do not require objects to be typed with the restriction class (since each resource is implicitly already an owl:Thing). Related rules #cls-maxqc3 & #cls-svf2 support restrictions that apply to a particular class, and thus require related objects to be typed with the restriction class. Since owl:Thing is the supertype of each class (#scm-cls rule), and each instance is typed by its class’s supertype (#cax-sco rule, Code 3), any instance will be typed as owl:Thing. Therefore, executing the second ruleset on restrictions relating to owl:Thing could produce the same inferences. However, #cax-sco requires each instance to be explicitly typed, which often is not the case in practice. Therefore, we opted to leave these rules in the ruleset.
We note that our online documentation [60] discusses all rule equivalences in detail. In total, this selection involved leaving out 7 redundant rules.
In other cases, extra axiomatic triples can be introduced to allow for entailment by existing rules. For instance, the rule #eq-sym (Code 22) explicitly encodes the symmetry of the owl:sameAs property:

Rule indicating owl:sameAs symmetry (#eq-sym).
By adding an axiom stating that owl:sameAs has type owl:SymmetricProperty, Code 23 shows that any inferences generated by the #eq-sym rule are covered by the #prp-symp rule:

Rule implementing property symmetry (#prp-symp) and supporting axiom.
Similarly, #prp-inv2 is entailed by #prp-symp with an extra axiom, together with the #prp-inv1 rule.
Rules #scm-spo and #scm-sco, implementing the transitivity of rdfs:subPropertyOf and rdfs:subClassOf, respectively, are entailed by #prp-trp with supporting axioms (Code 24):

Transitivity rule (#prp-trp) and supporting axioms.
In doing so, 4 rules can be left out, at the expense of adding 4 new supporting axioms.
Opportunities also exist to generalize multiple rules into a single rule, combined with supporting axioms. We observe that rules #eq-rep-p (Code 25) and #prp-spo1 (see Code 15) are structurally very similar:
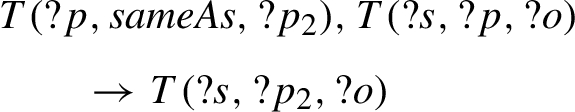
Rule inferring new relations via owl:sameAs (#eq-rep-p).
Therefore, both rules can be generalized into a single rule, with accompanying axioms (Code 26):

Rule covering #eq-rep-p and #prp-spo1 (#prp-sl) and supporting axioms.
In fact, several rules are structurally very similar, and may be pairwise generalized into a single rule with supporting axioms: rules #scm-hv and #scm-svf2; #scm-avf1 and #scm-svf1; #eq-diff2 and #eq-diff3; #prp-npa1 and #prp-npa2; and #cls-com and #cax-dw (see [60] for details). We note that the same solution could also be applied for rule #prp-eqp1 (Code 17) but this rule had already been removed (Code 18). In doing so, we left out 12 specialized rules while adding 6 general rules and 12 supporting axioms. After applying these selections, 52 rules remain and 16 axioms are added.
So-called “stand-alone” schema inferences, which extend the ontology but do not impact the set of instances, may also be considered redundant, at least at the instance level. E.g., #scm-dom1 (Code 27) infers that properties also have as domain the super types of their domains:
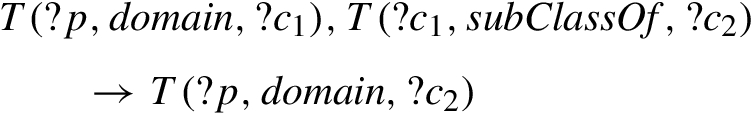
Rule inferring super class domains (#scm-dom1).
Although this information may be a useful addition to the ontology, the new schema element will not result in new instance inferences. Code 28 shows that its resulting instance inferences are already covered by rules #prp-dom (a) and #cax-sco (b):

Two rules yielding same instances as #scm-dom1.
Thus, any variable
In this section, we discuss selections based on purpose and reference. We differentiate between selections independent of the domain (Section 5.2.1) and that leverage domain knowledge (Section 5.2.2).
Domain-independent ruleset selection
Many (e.g., context-aware [43]) scenarios only involve adding or updating ABox (instance) statements at runtime, meaning that TBox reasoning may be restricted to design/startup time and whenever the ontology changes, with ABox reasoning being re-applied when new instances are added. Reflecting this, most OWL2 RL reasoners focus on separating TBox from ABox reasoning [9,21,27,42,43]. Further, data generated by the system may have a smaller likelihood of being inconsistent, thus reducing (or even removing) the need for continuous consistency checking as well.
Consequently, an opportunity exists to divide our OWL2 RL ruleset into 2 major subsets according to purpose; (1) inference ruleset, comprising inference rules (53 rules), and (2) consistency-checking ruleset, containing rules for checking consistency (18 rules2
These rule subsets both include the two membership rules (Section 4.2.3), making them cumulatively larger.
In this approach, inference-schema is applied on the ontology, initially and whenever the ontology changes, to materialize all schema inferences. When new instances are added, only inference-instance is applied on the instance assertions and materialized schema. As shown in our evaluation (Section 6), executing only inference-instance has the potential to improve performance. Below, we show that this process still produces a complete materialization.
We define S as the set of all schema assertions (i.e., TBox) and I the set of all instance assertions (i.e., ABox) with
The deductive closure of IR on the union of any ontology schema O (
It is easy to see why this equivalence holds. Compared to the left operand, the set of assertions on which ruleset α is applied no longer includes inferences from β (since its deductive closure is now calculated separately), nor assertions from D. But this does not affect the deductive closure of α, since α only matches assertions from S with
In the same vein, the consistency-checking ruleset needs to be applied on a dataset with all inferences materialized using the inference ruleset. It can be similarly shown that applying only consistency-checking on such a dataset will not result in losing any consistency errors. We note that related work often uses a separate OWL reasoner for materializing the schema [9,21,42]. Although this is a viable approach, we argue that this is not optimal for mobile platforms as it requires deploying two resource-heavy components (i.e., an OWL reasoner and rule engine).
At the same time, it is clear that the utility of separately applying these subsets depends on the frequency of ontology (schema) updates, since each update requires re-materializing the (schema) inferences. Although ontology changes are typically infrequent compared to instance data, this depends on the concrete scenario. In general, we define an ontology as
By leveraging domain (i.e., ontology) knowledge, rules that do not reference the ontology and will thus not yield any inferences, may be left out as well, yielding a domain-based rule subset.
Manually determining such a domain-based ruleset is quite cumbersome and error-prone. Firstly, one can clearly not just check whether constructs referenced by the rule are present; e.g., the ontology may contain owl:subClassOf constructs, but the premise of #scm-eqc2 requires two classes to be subclasses of each other, which is less likely. Secondly, some rules may be indirectly triggered by other rules, meaning that checking inferences per individual rule is insufficient.
Consequently, Tai et al. [58] describe a “selective rule loading” algorithm to determine this ruleset. As a type of naïve forward-chaining algorithm, it executes each rule sequentially on the initial dataset, adding any inferences. In case a rule yields results, it is added to the selective ruleset. This process continues until no more inferences are generated. We implemented this algorithm in the MobiBench framework (Section 2.2). Similar to before, the applicability of this ruleset selection depends on the “stability” of the ontology. In this case, relevant changes not only include schema updates but also insertions of certain data patterns, i.e., sets of instance assertions (e.g., reciprocal owl:subClassOf relations would make the #scm-eqc2 rule relevant); these will require re-calculating the ruleset (with its associated overhead) at runtime.
Removal of inefficient rules
Rule #eq-ref (Code 29), inferring that each resource is equivalent to itself, greatly bloats the dataset:
Rule inferring that each unique resource is equivalent to itself (#eq-ref).
For each unique resource, this rule creates a new statement indicating the resource’s equivalence to itself. Consequently, 3 new triples are generated for each triple with unique resources, resulting in a worst-case 4× increase in dataset size (!). One could argue that there is limited practical use in materializing these statements; and it is unlikely that their absence will affect other inferences (there is one case where this may happen; see [60]). If needed, the system could e.g., be adapted to support them virtually. Therefore, we feel that developers should at least be allowed to weigh the utility of this rule versus its computational cost. We note that some production-strength OWL reasoners, such as SwiftOWLIM, have configuration options available to disable such rules as well [30].
After applying all selections cumulatively (aside from purpose- and reference-based subsets), this leaves a ruleset of 51 rules; 18 rules less than the original ruleset. Our evaluation (Section 6) studies the performance of separately and cumulatively applying these selections.
To check the conformance of our original OWL2 RL ruleset and its subset selections (Sections 5.1–5.3), standard OWL2 RL conformance tests should be applied. However, many test cases listed on the W3C OWL2 Web Ontology Language Conformance page for the OWL2 RL profile [57] are not actually covered by OWL2 RL (as confirmed by one of its major contributors on the W3C mailing list [66]). Therefore, we used the OWL2 RL conformance test suite presented by Schneider et al. [53]. We note that some of these tests had to be left out, either due to the limitations of the original OWL2 RL ruleset (Section 4.2; e.g., lack of datatype support), or due to difficulties testing conformance. We detail these cases in our online documentation [60].
The original OWL2 RL ruleset (Section 4.2), as well as its conformant subsets (Sections 5.1.1–5.1.3), pass this conformance test suite. In addition, we confirmed that the selections presented in Section 5.1.4 (Equivalence with instance-based rules) loses owl2rl-schema-completeness, and Section 5.3 (Removal of inefficient rules) fully breaks conformance with the test suite. We note that conformance of the domain-based ruleset selection (Section 5.2.2) cannot be checked using this test suite, since this subset only includes rules specific to the domain ontology (while the test suite clearly checks all OWL2 RL rules). Instead, conformance of this rule subset was tested by collecting the inferences of the full ruleset (when applied on our evaluation ontologies; Section 6), and comparing them to the output of the domain-based rule subset.
Mobile reasoning benchmark results
This section presents the benchmark results for materializing ontology inferences on mobile platforms, obtained using MobiBench.
Reasoning task
Our benchmarks cover OWL2 materializing inference. We note that, although rule-based reasoning is not benchmarked separately, it is used to implement this task (Section 2.4.2). Our goals include:
Measuring the performance impact of our OWL2 RL subset selections (Section 5). To that end, we utilize two rule-based systems (Section 6.3).
Using the best performing OWL2 RL rulesets, benchmarking the best-effort performance of the two rule-based systems under different orthogonal cases: “stable” vs. “volatile” ontologies (Section 5.2); and OWL2 RL-conformant vs. non-conformant rulesets. In addition, we benchmark three OWL2 DL reasoners (Section 6.3) and compare the benchmark results.
Currently, we chose to only apply the Frequent Reasoning process flow; since most systems either support incremental reasoning only partially (e.g., Pellet: only incremental classification), or not at all. This means they will have virtually identical performance for incremental reasoning steps.
Benchmark resources
To benchmark our reasoning task, we rely on the validated resources listed below (available for download at our online documentation [60]), including OWL ontologies (Section 6.2.1) and rulesets for OWL2 RL reasoning (Section 6.2.2).
OWL2 ontologies
To suit the constrained resources of mobile platforms, we extracted ontologies with 500 statements or less from this corpus, resulting in 189 benchmark ontologies (total size: ca. 9 Mb). By focusing on OWL2 RL ontologies, all ontology constructs are supported by all evaluated reasoners, i.e., OWL2 RL and DL.
In Section 6.6, benchmark ontologies are ordered 0–188, with an ontology’s cardinal number indicating its relative OWL2 RL reasoning performance.
OWL2 RL rulesets
To study the effects of OWL2 RL subset selections on performance (Section 5), we created multiple benchmark rulesets using our Ruleset Selection Service (Section 2.2). We summarize each selection below, and indicate their label used in the benchmark results. Note that, when discussing the benchmark results, the “+” symbol indicates applying one or more selections on the OWL2 RL ruleset.
All selections from (1) guarantee OWL2 RL conformance, i.e., they are complete under the OWL2 RL semantics (Section 5.4); whereas the inst-ent selection from (2) still guarantees owl2rl-instance-completeness (Section 5.1.4), i.e., ensuring all instances are inferred under the OWL2 RL semantics.
entailed: leave out logically redundant rules (Section 5.1.1);
extra-axioms: add extra supporting axioms, which allows leaving out specific rules (Section 5.1.2);
gener-rules: add generalized rules, each replacing two or more specialized rules (Section 5.1.3);
inf-inst: retain inference rules referring to both instance and schema elements (Section 5.2.1);
inf-schema: retain inference rules referring only to schema elements (Section 5.2.1);
consist: retain only consistency-checking rules (Section 5.2.1);
domain-based: leave out rules not referenced by the ontology (Section 5.2.2).
To support n-ary rules from (L2) (Section 4.2.3) we chose to only apply solution (1), i.e., instantiating the ruleset. This was done for all benchmarks, i.e., all benchmark results were obtained with a ruleset that can deal with any n-ary rule. Since the benchmark ontology corpus (Section 6.2.1) only contains 18 intersections in total (with no property-chain or has-key assertions), we chose a solution that leaves out these rules in case no related n-ary assertions are found. Due to the low number of relevant assertions in this corpus, comparing the performance impact of different solutions would not make much sense (this is future work). We also note that ontologies with intersections were manually extended with relevant instance assertions, so inferences would be made based on the (instantiated) #cls-int1 rule.
Benchmarked systems
In order to focus on our main goals (Section 6.1), namely studying the performance impact of the proposed OWL2 RL rule subsets and best-effort performances in light of the proposed optimizations, we limit ourselves to benchmarking only two rule-based systems (AndroJena, RDFStore-JS). An exhaustive comparison of all systems would warrant its own paper and is thus considered out of scope. For this purpose, we chose the best-performing native Android system (AndroJena) and JavaScript system (RDFStore-JS). Our reason for including a JavaScript system is because they are interesting from a development perspective; i.e., they can be directly used by cross-platform, JavaScript-based mobile apps (e.g., deployed using Apache Cordova). We put these results side-by-side with performance results for Hermit, JFact, and Pellet, the only three OWL2 DL reasoners currently supported by our framework.
Benchmark measurements
Benchmarks capture the metrics discussed in Section 2.4.4, including loading and reasoning times and memory consumption. Regarding memory, Android Java heap dumps are used to accurately obtain memory usage of native Android engines. However, regarding JavaScript engines, heap dumps can only capture the entire memory size of the native WebView (used by Apache Cordova to run JavaScript on native platforms), not individual components. Although Chrome DevTools [20] is more fine-grained, it only records memory inside the mobile Chrome browser. Therefore, memory measurements were only possible for native Android reasoners.
Benchmark hardware
To perform the benchmarks, we used an LG Nexus 5 (model LG-D820), with a 2.26 GHz Quad-Core Processor and 2 Gb RAM. This device runs Android 6, which grants Android apps 192 Mb of heap space. During the experiments, the device was connected to a power supply.
Benchmarking results and discussion
This section presents and discusses the benchmarks for OWL materializing inference. We show the results for individually benchmarking OWL2 RL ruleset selections for AndroJena (Section 6.6.1) and RDFStore-JS (Section 6.6.2), and summarize these results in Section 6.6.3. In Section 6.6.4, we present the best performing OWL2 RL rule subsets, given different requirements and scenarios, and set them side by side with benchmarks of OWL2 DL reasoners (HermiT, JFact and Pellet). Unless indicated otherwise, result times include ontology loading, reasoning, and inference collection.
AndroJena benchmarking results
Figures 3–5 show the performance of OWL2 RL ruleset selections for AndroJena. Figure 3 shows that leaving out logically redundant rules (+entailed, i.e., applying the entailed selection) has a slight positive impact on performance (avg. ca. −180 ms), whereas also replacing specific rules by extra axioms and general rules (+ entailed, extra-axioms, gener-rules) performs slightly worse (avg. ca. +180 ms). This was a possibility, since this selection introduces more general, i.e., less constrained, rules (e.g., less able to leverage internal data indices). Applying a domain-specific ruleset (+ entailed, domain-based) supplies a much larger performance gain (avg. ca. −0.78 s). The inf-inst selection improves performance even more (avg. ca. −1 s). The ineff selection loses completeness but shows the highest cumulative gain (avg. ca. −1.3 s).
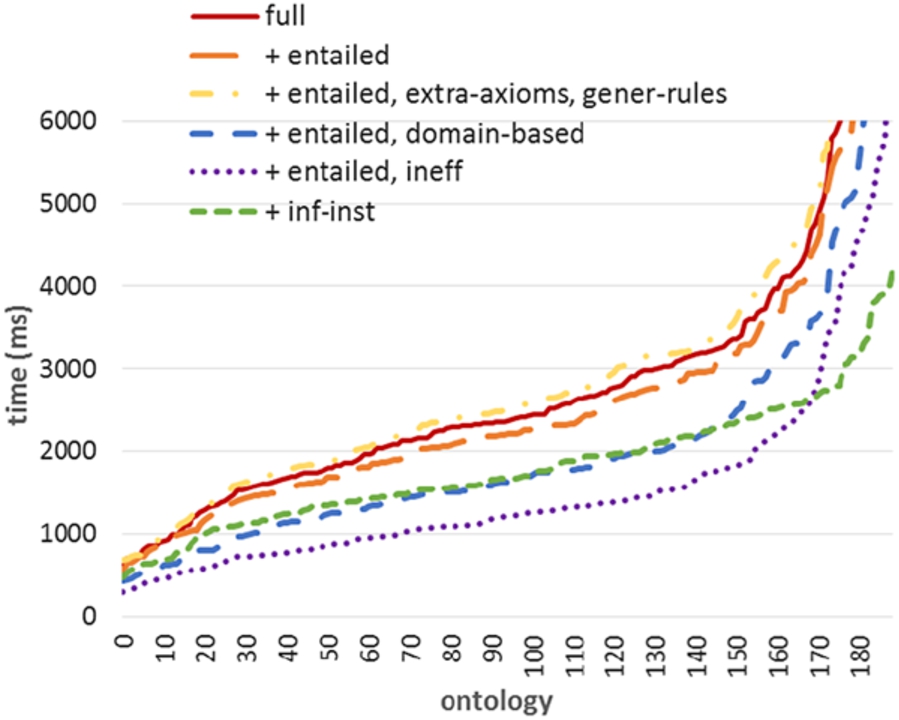
AndroJena: OWL2 RL selections (full).3
AndroJena: OWL2 RL selections (inf-schema).
Although the inf-inst selection shows promise, it requires materializing schema inferences using the inf-schema subset, initially and in case of ontology updates. Also, when consistency needs to be checked, the consist ruleset needs to be separately executed. Next, we discuss the performance of inf-schema and consist, and the effect of ruleset selections on inf-inst.
Some figures chop off peaks to avoid skewing the graph. The full average results can be found at [60].
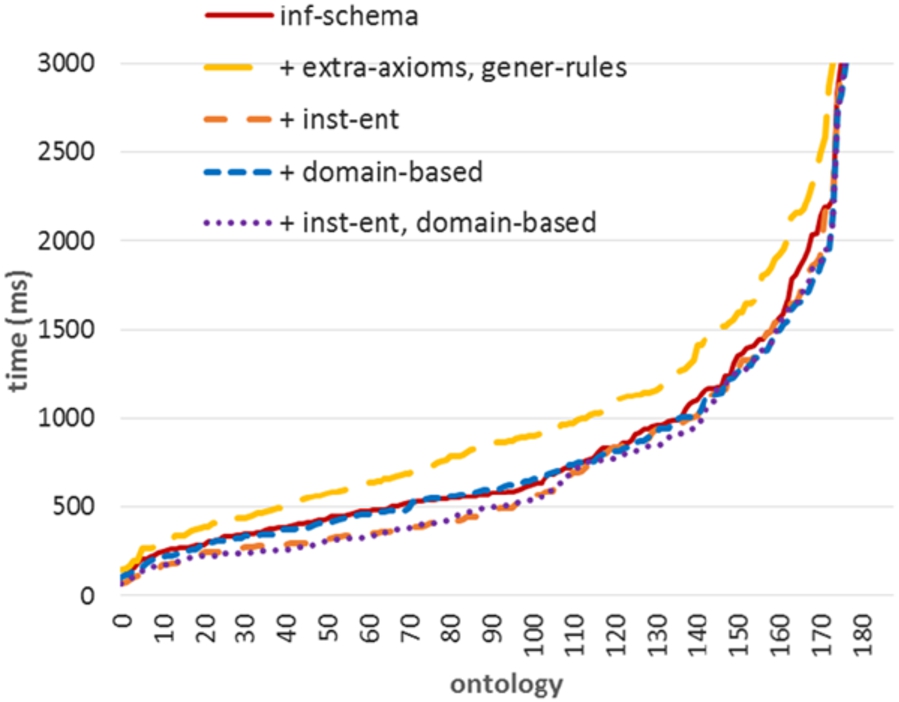
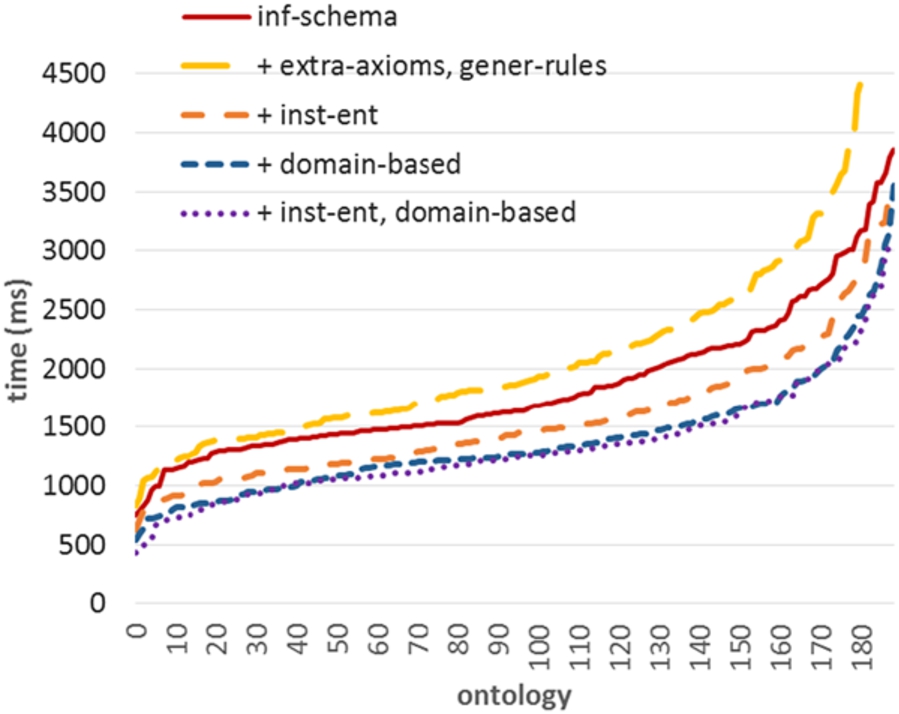
Figure 4 shows the performance of materializing schema inferences (inf-schema). As was the case before, ruleset selections may be applied on this subset. Similar to the full case, replacing specific rules with extra axioms and general rules (+ extra-axioms, gener-rules) reduces performance (avg. ca. +250 ms, compared to inf-schema). For inf-schema, a non-conformant selection is leaving out rules inferring schema inferences that do not yield extra instances (inst-ent, Section 5.1.4), which slightly improves performance (avg. ca. −80 ms). Since entailed and ineff do not include schema-only rules, they cannot be applied here. Applying domain-based, alone and when combined with inst-ent (+ inst-ent, domain-based), similarly improves performance slightly (avg. ca. −50 ms and −100 ms, respectively).
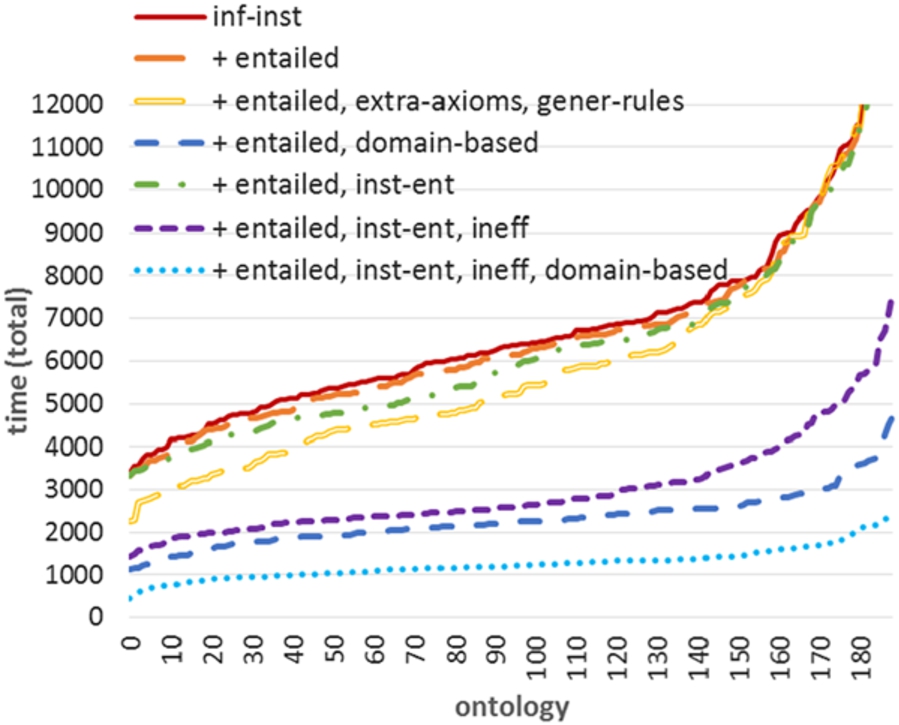
AndroJena: OWL2 RL selections (inf-inst).
However, we note that when applying domain-based on the inf-schema subset, the domain-based selection would need to reconstruct the inf-schema ruleset for each ontology update; and the ruleset is then utilized only once,4
Except for scenarios where e.g., the ontology needs to be re-materialized at each startup.
Future work involves studying mobile deployment, see Section 8.
After materializing the ontology with schema inferences, instance-related rules (inf-inst) are applied whenever new instances are added. When consistency needs to be checked, the consist ruleset selection is applied on a materialized set of schema and instance assertions (avg. ca. 420 ms). We note that the only applicable selection for consist, i.e., gener-rules, results in very similar performance (avg. ca. 430 ms).
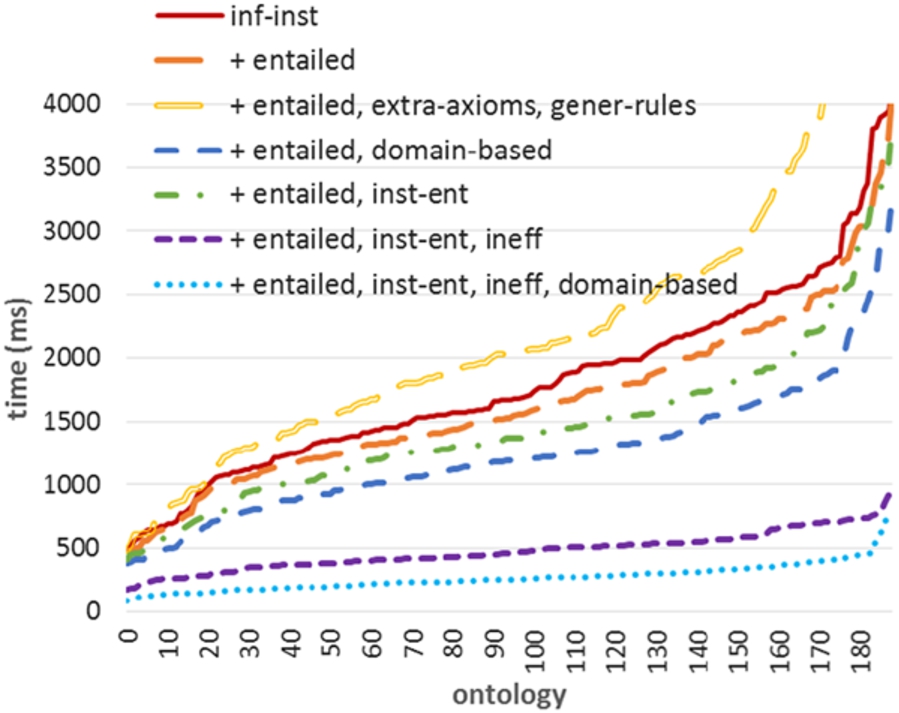
Figure 5 shows that, similar to the full case, leaving out redundant rules (+ entailed) results in small improvements (avg. ca. −145 ms, compared to inf-inst). Additionally replacing specific rules by extra axioms and general rules (+ entailed, extra-axioms, gener-rules) similarly leads to performance loss (avg. ca. +0.5 s), while selecting a domain-based subset (+ entailed, domain-based) results in gains (avg. ca. −0.5 s). Regarding non-conformant cases, a first option is to execute the rule subset when the ontology schema is instead materialized by inst-ent, which is smaller since it lacks some schema elements (i.e., not yielding extra instances). This scenario (+ entailed, inst-ent) improves performance by avg. ca. −340 ms. Also removing inefficient rules (+ entailed, inst-ent, ineff) increases performance by avg. ca. −1.3 s. Combining all selections yields reductions of avg. ca. −1.5 s.
Figures 6–8 show OWL2 RL subset performances for RDFStore-JS. Figure 6 shows that, similar to AndroJena, entailed yields only slightly better performance (avg. ca. −100 ms), whereas entailed, extra-axioms and gener-rules collectively result in worse performance (avg. ca. +0.85 s). At the same time, compared to AndroJena, also applying domain-based yields much higher performance gains (avg. ca. −5.8 s), while inf-inst (avg. ca. −1.3 s) and ineff (avg. ca. −1.9 s) have a smaller comparative impact.

RDFStore-JS: OWL2 RL selections (full).
RDFStore-JS: OWL2 RL selections (inf-schema).
RDFStore-JS: OWL2 RL selections (inf-inst).
Figure 7 shows the performance of materializing schema inferences (inf-schema). As for AndroJena, replacing specific rules (+ extra-axioms, gener-rules) reduces performance (avg. ca. +380 ms, compared to inf-schema), while leaving out “instance-redundant” rules (inst-ent) improves performance to a larger extent (avg. ca. −270 ms). As before, we note that entailed and ineff are not applicable here. Utilizing domain-based, individually and combined with inst-ent (+ inst-ent, domain-based) results in the largest improvements in performance (avg. ca. −0.46 s and −0.5 s, respectively), although, as mentioned, the suitability of domain-based could be questioned here.
Figure 8 shows the results of the inf-inst rule subsets, applied on an ontology materialized with schema inferences. In contrast to AndroJena and the full case for RDFStore-JS, collectively applying entailed, extra-axioms and gener-rules improves performance (avg. ca. −0.8 s), and thus exceeds the performance gained by only + entailed (avg. ca. −180 ms). Similar to full (Fig. 6), the domain-based selection (+ entailed, domain-based) performs much better (avg. ca. −4.5 s).
Best overall performances (avg) (ms)

Considering non-conformant selections, applying the rule subset when instead materializing the ontology schema using inst-ent (+ entailed, inst-ent) increases performance by avg. ca. −430 ms (compared to inf-inst). Also applying the ineff selection (+ entailed, inst-ent, ineff) significantly improves performance (avg. ca. −3.8 s). Combining all selections reduces reasoning times by avg. ca. −5.5 s. Finally, the consist ruleset yields a performance of avg. ca. 2.1 s, with + gener-rules (only applicable selection) performing slightly better (avg. ca. −160 ms).
Overall, we observe that the entailed selection has a relatively small performance impact, with reductions from −1.2% (rdfstore-js: full) to −8% (androjena: inf-inst). Utilizing extra-axioms and gener-rules typically results in (slightly) worse performance; which is not wholly unexpected, seeing how it replaces specific rules with more general ones (e.g., with more joins and less ability to leverage internal data indices). In some cases however, these selections perform better: i.e., when executing inf-inst (−21%) on RDFStore-JS.
In case of a stable ontology, additional conformant optimizations exist. Executing the inf-inst ruleset on a materialized ontology results in performance increases from −17% (rdfstore-js) to −36% (androjena) compared to the full ruleset. Here, applying the best-performing, conformant selection (i.e., inf-inst + entailed + domain-based) yields huge optimizations, up to −72% (rdfstore-js) compared to the non-selection case.
When dropping the conformance requirement, utilizing the inst-ent selection yields slight improvements in performance for inf-schema; 8% (androjena) and 15% (rdfstore). Re-using the smaller materialized ontology optimizes the inf-inst selection as well, up to −12% (androjena). Putting it all together, selection + inf-inst, entailed, inst-ent, domain-based, ineff yields dramatic improvements, as much as −90% (androjena) compared to the full case.
Best overall performance
Table 1 shows the best-effort performances of the rule engines: for the full, original OWL2 RL ruleset (original, for reference); when applying best-performing conformant (conformant) and non-conformant (non-conformant) rule subsets; and for cases where the domain ontology frequently faces changes (volatile ontology) that rule out certain selections, and cases where such changes are not likely to occur (stable ontology) (Section 5.2.1). For brevity, we only consider a single “volatile” case, i.e., where frequent ontology updates rule out both the domain-based selection and separation of inf-inst, inf-schema and consist selections. For the “stable” case, times for a priori materializing the schema (inf-schema), inferring new instances (inf-inst), and consistency checking times (consist) are shown. Based on results from the previous section, we chose the best-performing ruleset selections for each case (see table). Both total times and constituent loading and reasoning times are indicated. Further, the table sets these results side by side with the overall performance of HermiT, Pellet and JFact, well-known OWL2 DL reasoners. These systems perform reasoning with higher complexity (OWL2 DL), which yields extra schema (TBox) inferences not covered by the OWL2 RL rule axiomatization [38,43]. We confirmed that the OWL2 RL and OWL2 DL reasoners infer the same ABox inferences. Clearly, any comparison should take this schema incompleteness issue into account.
In line with expectations, the table shows that AndroJena, as a native Android system and featuring a non-naïve, RETE-based forward chainer, greatly outperforms RDFStore-JS, which we manually outfitted with naïve reasoning (Section 2.4.1). As shown before, the ruleset selection suiting volatile ontologies and guaranteeing conformance (entailed) performs only slightly better. However, if the ontology is considered stable, the conformant inf-inst selection supplies huge relative gains (avg. ca. 1.6 s (55%)–5.8 s (72%)) compared to the original case, respectively for AndroJena and RDFStore-JS (percentage indicates the proportion of time gained w.r.t. original). At the same time, inf-schema yields a comparatively lower, but certainly not negligible, overhead, which is incurred for each ontology update. As mentioned, since applying the domain-based selection on inf-schema would not be advantageous in most scenarios, it is not applied here. In contrast, the best-performing conformant inf-inst ruleset requires the domain-based ruleset selection, which needs to be re-calculated for each ontology update and thus adds an extra overhead (not included here). Hence, we only apply this configuration for stable ontologies, i.e., not faced by frequent updates that would require such re-calculations at runtime. Similarly, the cost of consist is not negligible; the frequency of applying the ruleset depends on the scenario.
When dropping conformance, we find significant performance improvements even for volatile ontologies (avg. ca. 1.3 s (45%)–1.9 s (24%)). For non-conformant reasoning in stable ontologies, the performance gain of inf-inst is tremendous (avg. ca. 2.5 s (90%)–6.9 s (85%)). Regarding OWL2 DL reasoners, Pellet and JFact have comparable performance (around avg. ca. 7 s) with HermiT being a clear outlier (avg. ca. 21 s).
Table 2 shows memory usage for each engine (aside from the JavaScript-based RDFStore-JS; see Section 6.4). JFact uses the least amount of memory, i.e., only 585 Kb, making it a suitable choice overall (see Table 1) for mobile platforms. Nevertheless, all memory usages appear acceptable (at least on Android), seeing how each Android app receives a 192 Mb max. heap.
Memory usage (Kb)
Memory usage (Kb)
In the state of the art on rule-based OWL reasoning, most works focus on separating TBox from ABox reasoning [9,21,27,42,43]. In most cases, a separate OWL reasoner is utilized to compute and materialize schema inferences [9,21,42]. However, this is inadvisable on mobile platforms, since it necessitates deploying two (resource-heavy) reasoner systems, i.e., an OWL reasoner and rule engine. After this separate schema reasoning step, some works [9,42,43] proceed with a rule-template approach; where OWL2 RL rules are instantiated based on the materialized input ontology. In particular, multiple instantiated rules are created for each rule, replacing schema variables by concrete schema references. We support a similar solution to support certain n-ary rules, and applied it in our benchmarks. Implementing and benchmarking this as an optimization for all rules is considered future work. Tai et al. [58] propose a selective rule loading algorithm, which composes an OWL2 RL ruleset depending on the input ontology. In our benchmarks, we found that this domain-based rule selection can significantly improve performance.
Bobed et al. [15] presented a set of comprehensive benchmarks on Android devices for a number of DL reasoners, focusing on classification and consistency checking in the OWL2 DL and OWL2 EL profiles. The authors manually ported the OWL reasoners to Android and detailed their porting efforts. It was found that reasoning on PC was between 1.5 and 150 times faster than on Android, with the number of out-of-memory errors increasing on Android as well. Similarly, Kazakov et al. [31] found orders of magnitude difference between PC and Android reasoning times. Nonetheless, Bobed et al. found some promising trends: reasoners on the new Android RunTime (ART), which features ahead-of-time compilation, can be around 2 times faster than in Dalvik. In prior work [69], the same team also found a performance increase of ca. 30% between Android devices only 1 year apart.
While the benchmarks presented by Bobed et al. are comprehensive and informative, our work goes beyond the benchmarking of existing reasoners by presenting (1) a freely available, cross-platform benchmark framework for evaluating mobile reasoner performance, so others may perform detailed benchmarks given their application scenarios; and (2) selections of OWL2 RL rule subsets to optimize mobile reasoning, accompanied by comprehensive benchmarks that show their performance effects.
As mentioned, Patton et al. [47] reported that due to the single-threaded nature of most reasoners, a near linear relation exists between energy usage and computing time for OWL inferences on mobile systems. As such, energy usage estimates, based on reasoning times, could be realistic. Regardless, future work involves measuring battery usage as well.
Conclusion and future work
This paper presented the following contributions:
Despite the presented work, as well as advancements reported in the state of the art, scalable mobile performance remains elusive. A huge gap still looms between PC and mobile reasoning times. Therefore, future work includes integrating additional optimization methods into MobiBench, such as utilizing rule templates for all rules. Optimizing and porting domain-specific rule selection to the mobile platform, in light of its positive impact on performance, is also an avenue of future work. Similarly, we aim to deploy pre-processing solutions for n-ary rules directly on the mobile device, and compare their performance on an ontology corpus featuring large amounts of n-ary assertions. Measuring energy consumption, an important aspect for mobile systems, is also part of future work.
Our major focus in this paper was on materializing ontology inferences. Reasoning per query (via e.g., SLG) may also have its merits on mobile platforms, since it does not require a priori materialization. Studying its performance on mobile systems is considered a major avenue of future work. We also aim to study the utility of semantically enhancing service matching, one of the supported reasoning tasks (Section 2.4.2), by weighting the extra found matches against the ensuing performance overhead. Finally, identifying additional OWL2 RL rule subsets for particular reasoning tasks (such as instance checking and realization) is also viewed as future work.