
Abstract
VocBench is an open source web platform for the collaborative development of datasets complying with Semantic Web standards. Since its public release – five years ago – as an open source platform, VocBench has attracted a growing user community consisting of public organizations, companies and independent users looking for open source solutions for maintaining their thesauri, code lists and authority resources. The focus on collaboration, the differentiation of user roles and the workflow management for content validation and publication have been the strengths of the platform, especially for those organizations requiring a distributed, yet centrally controlled, publication environment. In 2017, a new, completely reengineered, version of the system has been released, broadening the scope of the platform: funded by the ISA2 programme of the European Commission, VocBench 3 offers a general-purpose collaborative environment for development of any kind of RDF dataset (with dedicated facilities for ontologies, thesauri and lexicons), improving the editing capabilities of its predecessor, while still maintaining the peculiar aspects that determined its success. In this article, we review the requirements and the new objectives set for version 3, and then introduce the new characteristics that were implemented for this new incarnation of the platform
Introduction
In 2008 the group for Agriculture Information Management Standards (AIMS) of the Food and Agriculture Organization of the United Nations1
Rebranded as VocBench (VB), to suggest a more general environment for thesaurus management, the platform was later strongly reengineered in the context of a collaboration between FAO and the ART2
The strengths of the platform included the possibility for project administrators to define roles with very specific capabilities and to assign them to different users according to their proficiencies and authorizations, together with the publication workflow where dedicated users could supervise the work of others and accept their modifications. They were appreciated especially by those organizations requiring a collaborative yet centrally controlled publication environment. Unfortunately, this controlled approach was realized on a rigid model comprising a few first-class resources (e.g. concepts, concept schemes, etc.) and predefined operations on them. Consequently, some other users felt more freedom on data modeling was missing from the system, desiring unrestricted capabilities for editing data at its very core, as in triple-oriented RDF editing environments. The increased freedom would also reflect in the possibility to customize the models, going beyond plain SKOS/SKOS-XL modeling, which is sometimes a must for users dealing with complex, yet still KOS-like, resources.
VocBench 3 (or, simply, VB3) was planned to overcome the above limitations, while broadening the original scope of the platform to a general-purpose collaborative environment for development of SKOS thesauri, OWL ontologies and RDF datasets in general. The VocBench 3 project is funded by Action 1.1 of the ISA2 Programme of the European Commission for “Interoperability solutions for public administrations, businesses and citizens”.3
VocBench 3 was released to the public on September 2017, under a BSD 3-clause license.5
VB3 adopts Semantic Versioning (
In this article, we review the original requirements that drove the development of the platform and introduce the new objectives set for VB3. We then describe and discuss the new features and architectural improvements that have been implemented to meet the goals for this next iteration of the platform. Our aim is thus to highlight the improvements over VB2, while we refer the reader to [56] for a general introduction to the system and for a comparative analysis of VB with related works. This article is a revised and expanded version of a previous work [57], in which we previewed VB3 just before the completion of its first development iteration. Improvements over that work include:
discussion of related systems, discussion of additional features (e.g. extended input/output, integration of collaboration platforms), a more thoroughly analysis of the (meanwhile improved) support for OntoLex-Lemon, an example about XKOS showing the ability to support extensions to the core SKOS model, description of the system architecture, impact assessment.
We list here the requirements that drove the development of VB3, including those originally put together for the development of the original VocBench platform and of its successor VocBench 2 (R1–R7 in the list below). The original requirements have been reassessed and reformulated, accounting for the widened scope of the platform and its improved editing capabilities, while new ones (R8–R15) have been added to complete the target objectives for the platform. The set of revisions and new requirements has been collected following proposals by the VocBench developing team and requests performed by stakeholders through several means: dedicated stakeholder meetings held at the Publications Office, ISA2 programme, pro-active feedback on the support mailing lists of the platform. The input from these different sources all contributed to lay down the program for the development of VocBench 3, revised by the Publications Office and finally validated and approved by the ISA2 committee.
R1. Multilingualism. Properly characterizing knowledge resources in different (natural) languages is fundamental. This especially holds for thesauri, due to their use in information retrieval, though the overall importance of elaborated lexicalizations is progressively gaining momentum, thanks to data publication initiatives such as the Linguistic Linked Open Data8
R2. Controlled Collaboration. One of the keystones of the system is to enable collaboration on a large scale: several, distributed users have to be able to collaborate remotely on a same project. Opening up to communities is important, though the development of authoritative resources demands for the presence of some control to be exerted over the resource lifecycle: for this reason, users must be granted different access levels, and some of them should be allowed to validate other users’ work before it is committed to the dataset.
R3. Data Interoperability and Integrity. Interoperability critically depends on data integrity and conformance to representation standards. However, flexible models such as SKOS translate to underspecified possibilities on the one hand, and formal constraints beyond the expressiveness of OWL on the other one. Additionally, the increase in the offer of – often overlapping – standards in the family of RDF languages resulted in the necessity for systems to be flexible enough to properly read and manage all of them. It is thus important that VocBench enforces a consistent use of these models, by preventing the editors from generating invalid data, and by providing “fixing facilities” for spurious data acquired from external sources. Finally, support for alignment to other datasets is also an interoperability must for the Linked Data World.
R4. Software Interoperability/Extensibility. The system should be able to interact with (possibly interchangeable) standard technologies in the RDF/Linked Data world, with the possibility to surf linked open data on the Web, accessing SPARQL endpoints, resolving RDF descriptions through HTTP URIs, etc. as well to import/export data through standard Graph Store APIs and the like. The system should support extensions (sometimes called plugins), which can provide additional capabilities, often bound to predefined extension points: for example, enable to export data to a new type of destination (e.g. an SFTP server), or introduce a further serialization format (e.g. Zthes10
R5. Data Scalability. The system must deal with (relatively) large amount of data, while still offering a friendly environment. This holds for some thesauri as well as for most lexicons. The user interface should appropriately subdivide data loading into subsequent requests and implement solutions for large results.
R6. Under-the-hood data access/modification. While a friendly user interface for content managers/domain experts is important, knowledge engineers need to access raw data beyond the usual front ends, as well as to benefit from mass editing/refactoring.
R7. Adaptive Context and Ease-of-use. Expanding a requirement on its predecessor, VB3 should provide an even smoother experience, with very low installation requirements and an as-short-as-possible time-to-use. Whether (and proportionally if) the user is an administrator configuring the system, a project manager configuring a project, a user requesting registration and connection to a given project, or a new user willing to test the system as a desktop tool without settings and configuration hassle, VB3 should adapt to their needs.
R8. RDF Languages Support. In contrast to its predecessors, dealing with thesauri only, VB3 has to support SKOS (/SKOS-XL) thesauri, OWL ontologies, and RDF datasets in general. Support for OntoLex-Lemon lexicons and for ontology-lexicon interfaces was introduced later as a further requirement [26,27]
R9. Maintainability (Architecture and Code Scalability). In particular, the ability to meet new requirements, cope with changed environments and make future maintenance easier. A weak spot of VB2, VB3 aims to achieve high levels of architecture/code scalability. In VB3 it is mandatory to be able to add new services, functionalities, plugins, etc. without the fabric of the system being altered or too much effort being required to align these new elements with all the characteristics of the system, such as validation, history management, roles and capabilities.
R10. Full Editing Capability (RDF Observability and Reachability). Any complex RDF construct should always be inspectable and modifiable by users (providing they have the proper authorization) even in its finer details. While the platform can provide high-level operations for conveniently creating/modifying complex descriptions of resources according to predefined modeling design patterns, the user should never be prevented from inspecting/altering these elements.
R11. Provenance. Actions in VB3 should be handled as first-class citizens themselves, being identified and qualified by proper metadata, logged in a history with information about which user performed an action, when they did it, which parameters have influenced its performance, etc. Metadata answering to the five “Ws” (with the possible exception of the “why”) should provide all information for tracking the origin of an action.
R12. Versioning Support. Besides history and validation, providing triple-grained information about actions enriched with provenance metadata, it should be possible to take static, periodic, snapshots of datasets.
R13. Dataset-level Metadata Descriptions. For the Semantic Web to fully achieve its vision, linked open data has to speak about itself [39]. This means not only having data modeled according to well-known shared vocabularies, but to be able to grasp meaningful information about a dataset without having to dig into its content. Edited datasets should be coupled with resuming information about their characteristics, that can be published together with them.
R14. Customizable User Interface. User interfaces merely based on ontology description are limited to the analysis of the axiomatic description of the resources they show and of their types, ignoring possible desiderata of the user. VB3 should allow users to represent the information that they want to specify at resource creation, per resource type, so that it will be prompted to the user. Connected technical aspects, such as proper transformation of the user input into serializable RDF content, should also be covered.
R15. Everything’s RDF. VB2 used a relational database to store user and project management information as well as history and validation information. Conversely, VB3 should follow a more uniform approach, adopting RDF for virtually any storage need.
VB3 is based on a classical three-tier architecture (Fig. 1), structured through a presentation layer, a service layer and a data layer. The web application (developed using Angular11
VB3 does not feature the RDF abstraction layer – a middleware allowing for different RDF technologies to be interchanged in the lower tier – that characterized its earlier incarnations. This neat drift in the architecture is due to the acknowledgement that, at least with the current technologies and specifications, it is utopic to expect two API implementations to be practically swapped under the same functional layers. While the first VocBench largely adopted triple-oriented API to access the data and the second introduced SPARQL queries, VB3 is completely based on SPARQL, which is the weak point where technology interchangeability fails. By first, standards compliancy is not to be taken for granted when non-common characteristics of the language (e.g. bindings) are being used, as different triple stores might miss to implement (or partially implement) them. Second, and most important, the SPARQL specifications do not constrain the order in which the various clauses of a query should be resolved: the strategies of SPARQL query resolvers and optimizers may vary dramatically across diverse triple stores, making it difficult to express a certain information need as a SPARQL query that will behave as expected under all conditions. Additionally, there are critical differences in the way stores organize content (e.g. where the inferred triples are stored and how they can be retrieved). Fighting these idiosyncrasies is not an easy war, especially in an editor that must guarantee flexibility and that cannot perform any content-oriented optimization (as the datasets it manages are not know a priori).

VocBench 3 architecture.
With the advent of RDF4J12
The adoption of OSGi (formerly Open Service Gateway initiative)13
While there is currently no native extension mechanism for web interfaces built through Angular, the user interface of VB is informed by the extension point mechanism and supports extensions with automatically built forms for configuration of settings, selectors for choosing the implementation to choose, etc.
Currently, numerous extension points have been included in the system, in order to make extensible the user-visible features of VB3 (see Section 4). Hereafter, we will describe three extension points that are not covered elsewhere in paper, because they are related to lower level aspects of the system.
RepositoryImplConfigurer: this consists in configuration templates for different triple stores. Currently, there are implementations for the storage solutions of RDF4J and for Ontotext GraphDB14
Dynamic dialog for the configuration of a repository based on some store solution (in this case, the RDF4J Native Store).
SearchStrategy: a search component that can use non-standard, triple store specific text-search capabilities. Indeed, SPARQL only supports FILTER with some string matching functions. However, as FILTERs are often applied to discard solutions rather than find them, their use as a search mechanism is quite inefficient if the number of candidates is very high (e.g. tens of thousands). In contrast, a dedicated SearchStrategy can take advantage of the efficient fulltext capabilities provided by GraphDB.
URIGenerator: a pluggable component for the automatic generation of URIs. Indeed, there are many strategies to mint URIs, based on technical and political arguments. Ontologies often use human-friendly but language-specific identifiers based on a label (e.g.
As anticipated in the description of the architecture, project and user management have been completely rewritten as part of the Semantic Turkey framework. The system offers an abstract representation of the core entities managed: users, projects, system properties, etc. and API for storing/retrieving them, so that different implementations can be provided.

VocBench UI showing EuroVoc (
The default implementation represents another aspect which is streamlined with respect to VB3’s predecessors: it is completely file-based. Consequently, the relational DB previously used for system administration (and for metadata representation, which is now completely represented in RDF, see Section 4.3) is no more necessary. The use of the filesystem is not just a choice to get rid of the relational DB. An accurate organization in the distribution of the descriptors for users, projects, configurations, settings, plugins (these last three can in turn be also scoped differently) and their relationships enables an easy porting of data across different distributions: it is thus possible to easily transfer all data to another installation of Semantic Turkey, or to separately move users, projects, deciding whether to copy or not their settings etc.
CODA15
In this section we list features, functionalities and visual changes that are more evident to the user than the description provided in the architecture. Conformance to and satisfaction of the requirements expressed in Section 2 is reported case by case.
User interface (UI)
The overall data view (Fig. 3) preserved its overall organization, with data browsing views on the left and the description of the selected resource on the right. However, there are notable changes on both sides.
Browsing data structures
VB only provided a concept tree to browse the content of the dataset, supposed to be a SKOS(-XL) thesaurus. In line with its wider scope, VB3 now offers different data structures in different tabs, depending on the modeling vocabulary. OWL offers three tabs with a class tree and instance list, a property tree and a datatype list respectively, while SKOS adds to them a concept tree, a list of schemes and a collection tree (showing the containment between collections). OntoLex-Lemon adds tabs for lexicons and lexical entries.
The resource-view
The several tabs of VB2 (which inherited and extended the tab-based model of VocBench 1) that populated the “concept details” panel have been replaced with a single component, called resource-view.

Visualization of specialized hierarchical relationships between SKOS concepts.
In contrast to both VB1 and VB2, there are no first-class citizen resources, such as SKOS concepts and SKOS-XL labels; in fact, all resources now can be viewed and edited through the resource-view. This capability supports generic RDF development (requirement R8) and marks a profound departure from previous versions of the system, which had dedicated panels for certain types of resources that occur in thesauri (e.g. concepts and reified labels). The general applicability of the resource-view and the possibility to edit any of their details also contribute to satisfy requirement R10.
The resource-view adapts to the inspected resource: a few sections are shared among all resources, such as types, listing the rdf:types for the resource, lexicalizations, listing the available lexicalizations and properties, listing properties not addressed by other sections, while others are specific to the inspected resource. While the mapping of these sections to properties of the core modeling vocabularies is trivial (e.g. types to rdf:type), the sections are however presented with a predicate-object style in order to qualify the predicate, as they might include user-defined or domain-specific subproperties of the above ones. For example, see Fig. 4, instead of saying generically that “car” is “broader” than “steering wheel”, we can we can use XKOS [11] to state that the latter is a meronym of the former. Indeed, a subproperty of skos:broader can be indicated (optionally) both in the dialog for the creation of a new concept (when creating it as narrower of an existing concept, thus refining the relation among them) and in the dialog for the addition of a broader concept. The previous example shows the ability of the user interface to handle extensions (e.g. XKOS) of the core modeling vocabularies (e.g. SKOS), contributing to fulfill requirement R8.

Visualization of WordNet’s lexical entries in OntoLex views. In fact, the system is managing the whole collection of 34 wordnets collected by Open Multilingual WordNet [7].
The lexicalizations section abstracts different properties and modeling patterns for lexicalizations, as it offers specific resolution of their shape, always showing the form of the lexicalization, i.e. merely the label for rdfs:label and for SKOS terminological labels, the skosxl:literalForm for SKOS-XL labels and the ontolex:writtenRep of the canonical form associated with the lexical entry lexicalizing the resource in OntoLex-Lemon. In VB3, the concept of lexical model has been introduced (and separated from the knowledge model, e.g. OWL or SKOS) so that, for instance, it is possible to select SKOS-XL as a lexical model for both OWL ontologies and SKOS thesauri. In OntoLex-Lemon, the indirection is perhaps the most evident as one possible path from the lexicalized resource to the shown lexicalization is:
ontolex:isReferenceOf → <ontolex:Sense> → ontolex:isSenseOf → <ontolex:LexicalEntry> → ontolex:canonicalForm → <ontolex:Form> → ontolex:writtenRep → <shown lexicalization>
Many other paths are considered, due to shortcuts on property chains and inverse properties. So, the written representation is shown, but the user can click on it and inspect the full series of linked RDF terms.
This revised model greatly improves requirement R1 by covering not only diverse natural languages, but the different formal languages (and thus, R8 as well) in which the lexical information can be encoded.
Custom form for a relational noun in the OntoLex-Lemon model.
The support for lexicons required, even more than with thesauri, a data-scalable user interface (see Fig. 5). Modern thesauri are (usually) organized around a hierarchy of concepts that can be easily browsed by progressively expanding the explored branches of the tree. Conversely, lexicons have huge flat lists of entries that are difficult to represent. Additionally, the OntoLex-Lemon model introduces the notion of ontolex:LexicalConcept, corresponding to the notion of synset in lexical databases following the model of WordNet18
VB1 and 2 showed concepts through their labels in all the selected languages for visualization. In VB3, an option allows for toggling between the URIs/qnames19
A qualified name (qname) is formed by a prefix, followed by a colon, and then a local name (e.g.
An important new aspect of the user interface is offered by custom forms, a flexible data-driven form definition mechanism that we devised for VB, allowing users to perform a declarative specification of the key elements that concur to the creation of a complex RDF resource (satisfying req. R14).
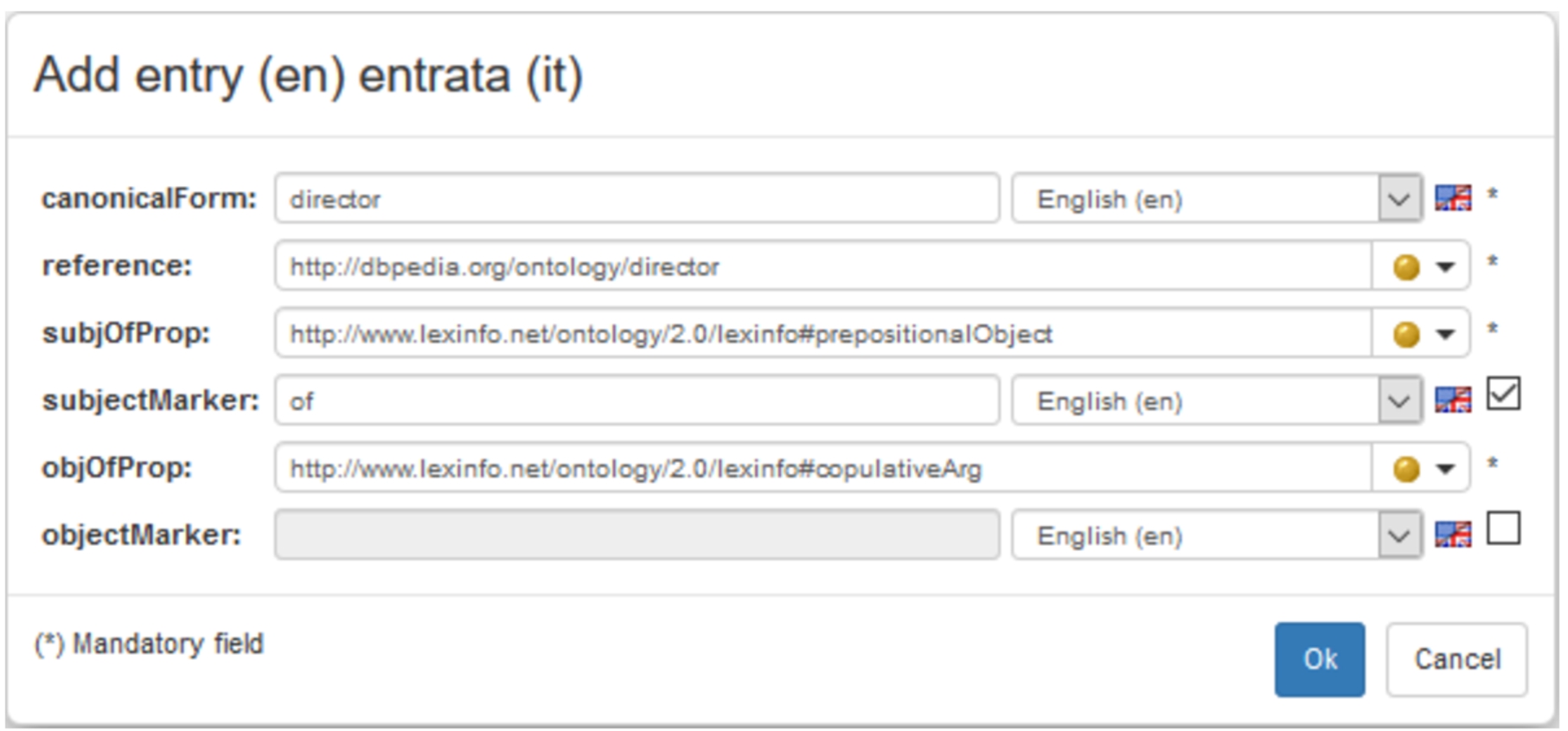
Custom forms have been described more in details in [17], which analyzed and evaluated their expressive power by applying them to the use case of representing lexical entries using the OntoLex-Lemon vocabulary. In that work, a subset of the lemon Design Pattern Library [46] was implemented as custom forms: VB exploits them to generate a form-based interface for the creation as well as the visualization of diverse lexical entries. Figure 6 reports a form filled with information regarding the entry “director”, which is said to denote the property dbo:director in the DBpedia ontology. Furthermore, the syntax-semantics interface is defined by establishing the correspondence between the atom x dbo:director y and the stereotypical verbalization y is the director of x.

Editing a capability for a role in VocBench.
A single installation of VB can handle multiple projects, which can also be interlinked for mutual data access (e.g. for purpose of alignment). VB promotes the separation of responsibilities through a role-based access control mechanism, checking user privileges for requested functionalities through the role they assume (req. R2). While VB2 had hard-wired and scarcely configurable roles, which do not easily scale-up to possible extensions of the system (req. R9), in VB3 we have created a dedicated language for specifying capabilities in terms of area, subjects and scopes. E.g. the expression:
auth(rdf(datatypeProperty, taxonomy), ‘R’)
corresponds to the requested authorization for being able to read taxonomical information about datatype properties. The ‘R’ stands for READ (or, equivalently, RETRIEVE), as in the CRUD paradigm, rdf is the area of the requested capability while datatypeProperty and taxonomy define the subject and scope respectively of the capability. We recall that “CRUD is […] the most common acronym for the four basic functions of persistent storage: create, retrieve, update and delete” [34]. Our language supports all these functions, which are identified by their initial letter. Actually, we extended CRUD with a fifth letter ‘V’ standing for VALIDATE: this permission grants the right to validate other users’ work (see Section 4.4).
The authorization policy is implemented as a series of facts in Prolog [8], whose resolution mechanism provides a principled mechanism for authorization decisions. Indeed, the same set of expressions is manipulated and validated on both the server and the client, by using different technologies, respectively, tuProlog20
New roles can be easily created, and existing ones can be modified, through a dedicated rbac editing wizard (Fig. 7). The default policy recognizes typical roles and their acknowledged responsibilities:
Administrator: the sole inter-project role (i.e. the role exists a-priori from projects). The administrator has, by definition, full access to the system. Project Managers: project-local administrators who can do everything within the boundaries of the project(s) they have been assigned to with that role. Specific project-local roles: ontology editors (allowed to make changes at the axiomatic level), thesaurus editors (allowed to work on thesauri without OWL editing actions), terminologists/lexicographers (allowed to edit lexicalizations, can be limited to certain languages), mappers (allowed to perform alignments only), validators (allowed to validate others’ actions, see Section 4.4) and finally lurkers, that can read everything in a project but have no editing authorization
In VB2, the change tracking mechanism that powered history and validation was based on a predefined set of recognized operations, severely limiting maintainability (req. R9) and the possibility to perform (req. R6) under-the-hood changes (e.g. through SPARQL) while keeping a complete history of the dataset. In VB3, we implemented a completely new track-change mechanism working at triple-level. For any action, triple additions and removals are intercepted and stored into a separate RDF repository (the support repository) (req. R15) together with metadata about the action (req. R11). This design was guided by an analysis [21,24] in which we discussed the nature and the representation of change, reviewed relevant version control systems for RDF, and delved into the challenges posed by validation.

Proposed concept “Canyon” shown in the concept tree, as well as in the resource-view.
VB2 had a 5-step publication workflow, clocked by the property “status” (with values: proposed, validated, published, deprecated and proposed_deprecated) and, redundantly, with information stored in the DB about the status of operations to be validated. Also, in VB2, the concepts of resource and action were mixed up in the validation procedure, with the status of a resource being affected by the validation (e.g. moving from “proposed” to “validated”), while single changed triples had no trace of their validation status.
This follows from the fact that it is not possible to attach a status to a triple in RDF, if not by reifying the triple. An in-depth discussion of different reification mechanisms can be found in [35]. Some mechanisms deeply affect how data is represented (e.g. singleton properties [49], or even standard reification), while named graphs [10] would be sufficiently lightweight, if VB did not already use them to differentiate between local and imported triples. Nonetheless, as discussed below, VB3 eventually adopted named graphs for the representation of proposed triples.
Benefiting from the new change tracking system, we have made things clearer and easier: there is no “status” property anymore, as the workflow is implicitly expressed by the validation mechanism coded into graphs. The added/removed triples are stored in the support repository as described in the previous section, while non-reified “previews” of them are available in separate graphs (staging-add-graph and staging-delete-graph) in the main repository, while the system presents them appropriately to the user. In this way, the main graph (i.e. the graph where managed information is stored) represents stable information, which does not need to be tagged as “validated”. The distinction between “validated” and “published” has been removed as it has never been put in place in any known user workflow. Finally, the status of deprecation has been represented through the official owl:deprecated property. The status of “proposed deprecated” is also intuitively represented by the need to validate the action for setting the owl:deprecated property to “true”.

Accepting the creation of a concept to move it from “proposed” to “validated”.

Resource-view of the class
In Fig. 8, we show the concept “Canyon” that was created in a project with validation.
The triples describing this concept are asserted in the staging-add-graph (instead of the project main graph): the resource-view shows them with a combination of green color and italic font, while triples in the main graph (none in this example) are displayed in black with a normal font. Since the assertion of the characterizing type (skos:Concept) is also staged for addition, the concept itself is considered proposed, and thus displayed in the concept tree differently from other (already validated) concepts. Figure 9 shows the creation of the concept in the list of operations pending for validation: a user with suitable rights (see Section 4.2) can decide to either accept or reject these operations. Accepting an operation makes its effects permanent (i.e. updating the main graph), while rejecting an operation undoes its effects (i.e. remove the previewed triples in the staging graphs). In the latter case, no trace of the operation remains, nor is the operation logged in the history: rejecting an operation should be like the operation was never performed. Future directions for the system foresee the possibility to store (in a logically-separated space) rejected actions so that, should they be re-proposed in the future, the user can be informed and discouraged from submitting them for validation again.
VB2 had already an advanced support for multiple SKOS schemes. We have improved the management by allowing users to select more schemes for browsing the concept tree and by adopting a combination of conventions and editing capabilities for quickly associating the proper schemes to newly created concepts and collections. Support for SKOS collections and ordered collections has been introduced in the system with dedicated UI views and editing facilities.
OWL support
VB already allowed for importing ontology vocabularies for modeling thesauri. Now VB also supports ontology development (requirement R8) with an almost complete coverage of OWL2 and using the Manchester syntax for both editing and visualization of class expressions (see Fig. 10). VocBench delegates reasoning to the triple store that manages the ontology and its data (see Section 3). Nonetheless, VB differentiates between explicit and inferred statements: they are rendered differently in the user interface, and users may toggle their inclusion in the resource-view (see Fig. 10). Currently, VB does not present justifications of the inferences, because RDF4J (see Section 3.1) lacks any mechanism to obtain them.
Export data.
Triple stores usually do rule-based reasoning with a total materialization strategy: the entailment closure of the ontology is computed in advance by the iterative application of the rules defining the semantics of the ontology modeling language. In the rest of the section, we provide more details about the triple stores commonly used with VB highlighting differences in flexibility, expressiveness and suitability to workloads.
RDF4J used to ship a reasoner with hard-coded rules for RDFS. Moreover, when knowledge is retracted from the ontology, this reasoner computes the entailment closure from scratch, since it cannot determine which entailments are no longer supported. This approach is clearly inefficient when the workload includes many deletions that affect the entailment closure slightly, e.g. the deletion of a fact assertion is usually less impactful than a deletion at the schema level. An alternative “schema caching” reasoner is not rule-based, since it gathers schema-level assertions and creates a data structure to quickly determine inferred statements. This reasoner better handles deletions that do not affect the schema, while being more performant (up to 80× faster) and more complete (but still bound to RDFS). For these reasons, the forward-chaining reasoner was superseded by this new one in RDF4J 2.5.
Ontotext GraphDB implements reasoning using a rule-engine that can execute arbitrary rules written in a proprietary rule-language. GraphDB provides optimized rulesets for RDFS, OWL2-RL and OWL2-QL semantics. When statements are retracted, GraphDB first determines (by forward-chaining) their logical consequences, and then removes only those inferred statements for which it is not possible to determine (by backward-chaining) any derivation not including the knowledge being retracted. GraphDB can also perform consistency checking and prevent modifications that would produce inconsistent knowledge. GraphDB features a non-rule implementation of
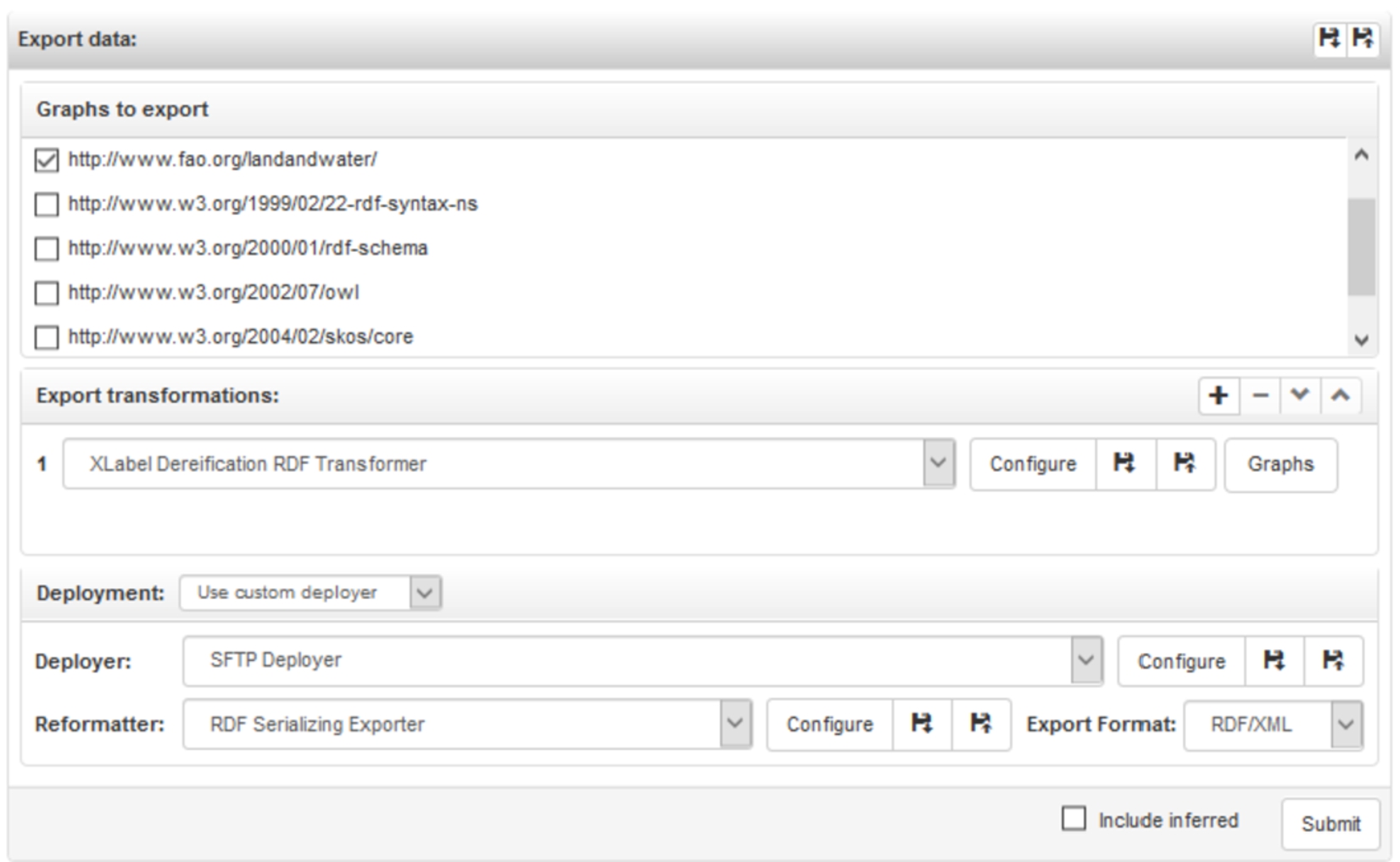
VB3 features completely redesigned data load and export capabilities. Since they are somehow specular, we will focus hereafter on the export procedure, using the example in Fig. 11 dealing with export of a SKOS-XL thesaurus.

Time-traveling across different versions of a resource.
In the example, we accepted the default option to export the main graph (the data edited by the users).
In some circumstances, the triples in the chosen graphs can’t be exported as they are. VB2 partially satisfied this need with the ability to export a cut of a thesaurus. VB3 clearly required a more general solution: the extension point rdf transformer (see Section 3.2) has been added, and data being exported can be processed by a chain of rdf transformers, each performing a destructive transformation (on a temporary copy of the data. In our example, we turned SKOS-XL reified labels into plain SKOS labels.
The RDF data being exported, optionally processed by a chain of transformers can be placed to a file, a triple store or a custom destination (the last two options associated with the extension point Deployer, see Section 3.2). The first two options require an RDF reformatting exporter, the extension point (see Section 3.2) for supplying serializers of the data into a byte sequence. In the example, we chose to deploy an RDF/XML serialization of the transformed data to an SFTP server.
It is worthy of note that these complex export chains can be saved and reused (even across projects). Furthermore, the configurations of each of the individual components (transformers, reformatters and deployers) can be saved and reused in different export chains.
Listing issues in JIRA associated to concepts in a thesaurus, opening one of these concepts and checking other collaboration options.
A new SPARQL UI, based on YASGUI [41], has been included in VB3, featuring the same feeding-from-live-data mechanism present in VB2.
VB3 also introduced the possibility to store queries (at different scopes described in Section 3.2) and share them with other users, even across projects. This capability is useful in different cases: (i) a complex query can be reused, (ii) a user writes a query for other users less proficient (or no proficient at all) with SPARQL, (iii) periodic execution of a query (e.g. for analytics).
VB3 offers several options for downloading the results of a query, including various tabular formats for tuple queries, and RDF serializations for graph queries. Following the observation that the latter case is not much different from a data export, we supported a customizable chain of transformers as we did in the export. For instance, a general SPARQL query could extract all alignments available in a dataset, while a chained RDF transformer could filter only those alignments referring to DBpedia [6]. The alignment export query can thus be reused across different cases.
Versioned datasets and metadata
In VB3, users can create snapshots of a repository (req. R12) and tag them with a version identifier (and other metadata, such as the time of creation of the snapshot). Users can travel across the different points in time identified by these versions, and thus analyze the evolution of browsed resources. The time travel can be performed both globally, by switching version so that everything in the UI refers to the selected version, and locally, by inspecting different versions of a resource in the resource-view (Fig. 12) or different versions of a tree (of classes, concepts, etc.)
Alignment
VB3 provides the same inter-project alignment support of VB2, allowing users to browse other projects and supporting semi-automatic label-based searches over them to provide candidate resources for alignments. In addition to this on-the-fly generation of mappings, VB3 introduces a tool for loading and validating alignments following the model of the INRIA Alignment API [12]. Validated alignments can then be projected over standard RDFS/OWL or SKOS mapping properties, depending on the validated relation and the involved entities. E.g. two classes mapped through an inria:EquivRelation will be mapped through the property owl:equivalentClass while two SKOS concepts will be proposed to be aligned with a skos:exactMatch or a skos:closeMatch.
Collaboration environments
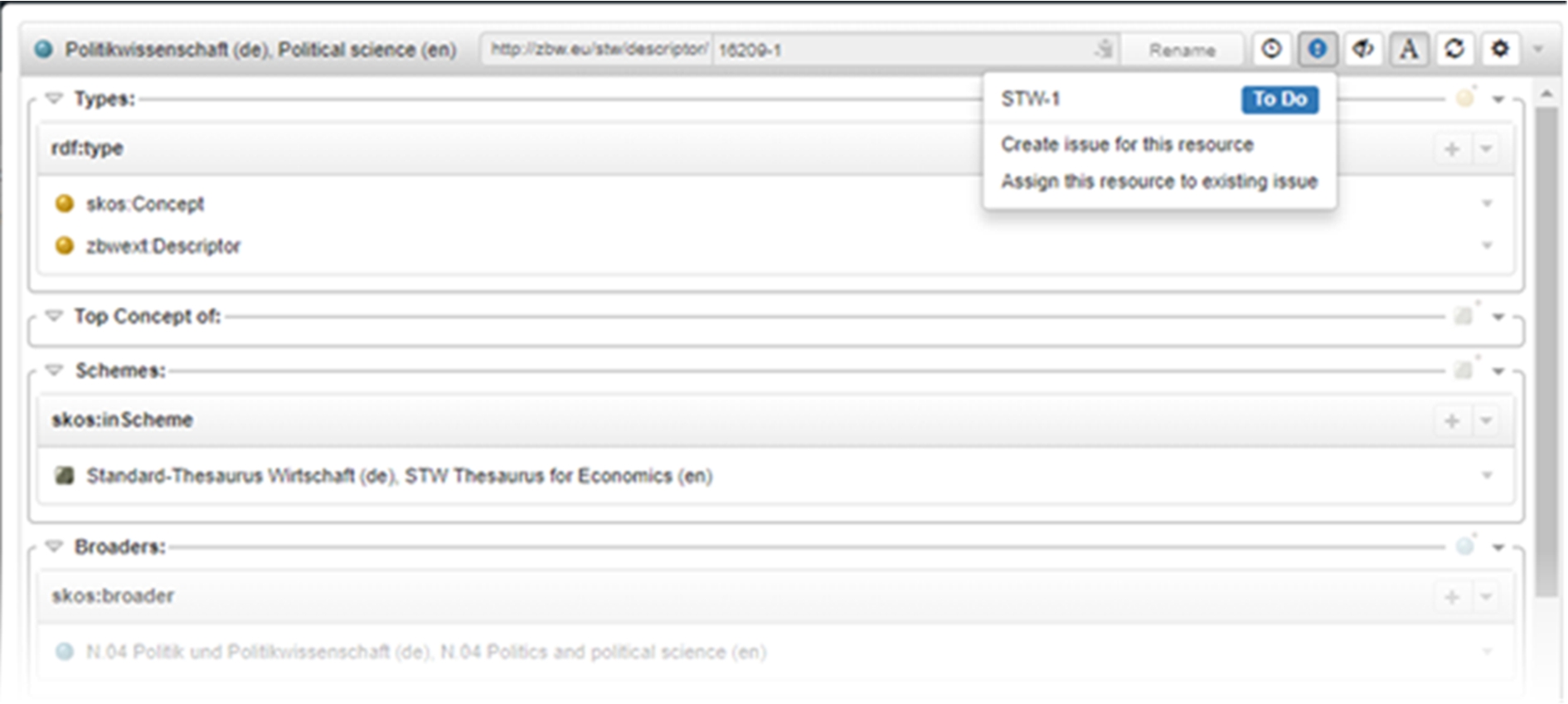
The extension point collaboration backend (see Section 3.2) has been added to the platform to enable the use of diverse collaboration environments with a predefined implementation for JIRA,22
The “metrics” section of VB2 has been replaced with a page for editing and exporting metadata (R13) modeled after several existing metadata vocabularies: the Data Catalog Vocabulary (DCAT) [62], the Asset Description Metadata Schema (ADMS) [13], The Vocabulary of Interlinked Datasets (VoID) [1] and the Linguistic Metadata vocabulary (LIME) [28] (a lexical extension to VoID). While DCAT and ADMS mostly deal with static metadata, VoID and LIME offer statistical information about the dataset and its lexical information. The information of VoID and LIME is being computed through the LIME API [22]. This metadata build and export functionality is implemented as an extension point of the platform, so that new vocabularies can be dynamically added to the platform through the extension point Dataset Metadata Exporter (see Section 3.2). For instance, an application profile for DCAT thought for European public sector data portals (DCAT-AP23
A section dedicated to Integrity Constraint Validation (ICV) allows the user to inspect possible anomalies. These include violations of formal constraints (e.g. thesauri constraints on existence and uniqueness of preferred labels, disjointness between taxonomy and relatedness, etc.) or problematic (though not necessarily illegal) patterns (e.g. a skos:Concept having a broader concept and being the top concept of a same scheme). Interactive fixes are provided (req. R3) for each discovered integrity break.
Desktop tool and collaborative web platform
As of requirement R7, the system offers a very lightweight installation (i.e. unzip and click-to-run) which, followed by default configuration options for both system and project creation, makes VB3 a good choice for users looking for a simple and easy-to-use desktop tool. Other more complex settings are still possible, satisfying different needs for distributed installation (separation of data servers, UI servers), better performance, etc.
Declarative service implementation
The VB framework provides Java annotations for specifying diverse characteristics of a service: the need for read/write access to the data, the capabilities the user must have, the prerequisites on the input parameters (e.g. an RDF resource must be declared in the dataset), etc. Service development becomes easier, less prone to errors and the produced code is more readable, as developers can focus on what the service does.

Download statistics for VocBench 2 (on the left) and VocBench 3 (on the right) as of 8 February 2019.
A heterogeneous user community24
Some of these long-lasting users still adopt VB2, but there are compelling reasons for which they will migrate to VB3: (i) VB2 is no longer supported in terms of updates (ii) the feature set of VB3 subsumes the one of VB2, (iii) some features of VB2 have been substantially improved when migrated to VB3 (e.g. search, history/validation, etc.). Additionally, we should mention that VB3 has already relevant users.25
The list expressed in the following paragraph has been gathered through a mix of direct interaction with known partners/users and data harvested from a questionnaire advertised on the VB mailing list. In both cases, explicit consent has been given to the authors for disclosing the information they have reported. This list is obviously limited to our most close interactions and, among those, only those with provable facts or a clear migration plan/expressed intention. It does not include other relevant organizations which are evaluating the system and the many occasional users whom we are not in contact with.
FAO, which was the steward of VB2, migrated to VB3 for the maintenance of their thesaurus Agrovoc in August 2018 and has recently started adopting it for classification systems used in statistics. INRA, the French “Institut national de la recherche agronomique”26
The Senate of the Italian Republic is also migrating management of its thesaurus Teseo from VB2 to VB3. There are also newcomers who are already adopting the platform and started directly with version 3, such as GelbeSeiten,31
Furthermore, VB3 acquired much more visibility and potential for adoption with respect to its predecessors, since it became the reference platform of the EU,33
To improve our understanding of the uptake of VocBench, we collected some statistics from the download pages of VB234
The most downaloded version of VB2 is the 2.3 with 395 downloads. The lower statistics associated with subsequent releases can be explained by the fact they were released one after the other with only a few months in between. These more frequent releases allowed us to deliver new features and (important) fixes to users; however, not every user had the same incentives to keep update with this faster release candence. The last release of VB2 2.4.4 (available since 8 March 2017) registered 295 downloads.
On the download page of VB2, there are also the documentations of VB 2.3 and VB 2.1 in PDF format, which have in total 959 downloads. A related obseravation is that the two versions of a simple thesaurus used in the getting started documentation were downloaded 491 times. Perhaps more important is the fact that a patch for a problem with the validation in VB 2.3 was downloaded 149 times: this figures tells us about users who considered the information they were validating valuable enough to warrant the application of the patch.
On the right side of Fig. 14, we report analogous statistics for VB3. The first stable release (version 1.0) has 138 downloads, while the subsequent version 2.0 was downloaded 498 times (more than the most downloaded version of VB2). Version 3.0.1 (released five days after 3.0.0) has 438 downloads, while version 4.0.2 (released three days after 4.0.0) has 637 downloads being the most downloaded so far. These high figures are associated with relatively frequent releases (every few months), and thus support two (non-mutually exclusive) hypotheses: existing users are willing to test/use new versions as they bring substantial new features, or there is a sufficiently large supply of new users. The typical slowness of large organizations (which are typical adopters of VocBench) in reacting to changes (confirmed by the feedback we have gathered, where most of them declared to have “intention to move” or “being in the process of migrating” though still with an unclear schedule) suggests that the second hypothesis covers at least a non-trivial part of the phenomenon.
The user community’s main point of interaction and support is the VocBench discussion group.36
User questionnaires are occasionally sent to the mailing list of VocBench in order to gather feedback from users about satisfaction and ideas for new directions for the system. A recent investigation held in March, 2018, based on a questionnaire diffused on the mailing list revealed that roughly 50% of the respondents already adopted VocBench 3 in production, 22% were in the process of adopting it, 17% were already using VocBench 2 in production and were considering moving to VocBench 3 while 11% was shared by users adopting VB2 and still not sure whether to move to the new platform and newcomers evaluating the VB3 platform. Adoption of VocBench 3 is still mainly focused on thesaurus development: among those adopting VB3 in production, 89% of the respondents are using it for developing thesauri while 33% is adopting it for OWL ontology development. We do not have figures for OntoLex development as at the time of the investigation the OntoLex editor in VB had not yet been released.
VB3 has dedicated facilities for a variety of core RDF knowledge models, and it can be used both as a desktop tool and as a web-based collaborative environment. The number of systems it could be compared against is consequently very large. Instead of attempting an exhaustive survey of these systems, we focused on selected systems, which are currently and widely recognized as references in their area of specialization.
Protégé
Protégé39
Originally based on a frame language (with a later extension for OWL), Protégé 4 switched to OWL-DL through the OWL API [38]. Protégé can thus benefit from DL reasoners, such as HermiT [30] which combines completeness, feature-richness and scalability.
DL semantics precluded most meta-modelling, which is supported by RDF systems (such as VB3), based on OWL Full semantics and rule-based reasoning. OWL2 closed this gap with the introduction of punning. Regarding the relative strengths of each approach, tableau-based (DL) reasoners are usually less scalable and efficient than lightweight rule-based reasoners, which, however, are less expressive [37].
One of the strengths of Protégé lies in its extensibility through plugins. At the time of writing, its plugin library40
Beyond single-user usage, Protégé supports a client-server mode (or multiuser model). Different instances of Protégé (clients) connect to a shared instance (server), enabling users to co-work on the same ontology (or SKOS dataset, in case of SKOSed). Client-server communication is based on Java RMI, while VB3 uses HTTP and JSON (popular in Web APIs).
The client-server mode greatly differs between Protégé 3 and Protégé 4: in Protégé 3 individual changes are sent to the server as they are made by clients, while in Protégé 4 changes are grouped together and only sent when the user commits them.41
Collaborative Protégé [58] is an extension for Protégé 3 that introduces several collaboration-oriented features beyond the multiuser model (client-server mode). Noteworthy features include the annotation of ontology components and changes, the management of a change history, inline discussions and a chat. In VB3, history is managed internally, while other capabilities are delegated to external (already appreciated) services (e.g. JIRA for issue management), through extensible connectors, while offering a smooth integration (e.g. showing issues for a resource inside its resource-view).
Version control systems for software development (e.g. GIT) are often considered inadequate for versioning of ontologies and RDF datasets: operating on a serialization of an ontology, they can be confused by semantically irrelevant operations (e.g. statement reordering, change of blank node identifiers).
Nonetheless, VoCol [2,33] demonstrated the viability of GIT42
WebProtégé was initially thought as a lightweight (open source) ontology editor, but it has grown over time reducing the functional gap with Protégé. Indeed, it supports class expressions in the Manchester syntax (as VB3) and editing of SWRL rules (absent in VB3).
WebProtégé reused and extended the functionalities of Collaborative Protégé for change tracking, notes, discussions and access control. In WebProtégé, users can also monitor (“watch”) individual resources or entire branches of the class tree: changes to these resources are listed in the user interface or sent via email notifications. This feature – not yet supported by VB3 – may speed up interactions between editors co-working on the same area of the ontology.
In addition to the change history of the ontology, WebProtégé enables to download the ontology in each state of its evolution. This is a rather unique feature, since other systems (VB3 included) only supports discrete snapshots of the edited data. A similar behavior may be found in VoCol, since in GIT it is possible to download any (previous) state of a repository.
WebProtégé supports the acquisition of instance data by means of customizable forms that effectively shield domain experts from the complexity of the underlying ontological modelling. This mechanism was borrowed from Protégé 3, and it is somewhat related to VB3 custom forms. Actually, VB3 custom forms are meant to enhance instance construction or property setting, without the aim to replace the editing panel (i.e. the resource-view) as a whole.
Currently, WebProtégé does not support plugins like its desktop counterpart;44
In line with its use in the life science domain, WebProtégé provides a dedicated facility for linking terms from BioPortal45
Currently, WebProtégé lacks dedicated facilities for SKOS, nor can third-party plugins like SKOSed fill this gap. Fortunately, there are numerous alternative SKOS editors, most of which – especially the most recent ones – are web-based collaborative editors. Mochón et al. surveyed [47] existing thesaurus managements tools from the perspective of LOD. They found that PoolParty46
PoolParty is a highly regarded suite of semantic technologies for different needs, including (i) thesaurus management, (ii) term and phrase extraction, entity linking and disambiguation, and (iii) semantic search and data mining. Different combinations of these proprietary technologies are available in different combinations as a one-time purchase or as a renewable subscription. We evaluated a demo instance of PoolParty Enterprise Server, which combines thesaurus management and term extraction, linking and disambiguation. The costlier PoolParty Semantic Integrator also includes semantic search & data mining capabilities and a wider spectrum of triple store backends. The latter is supported by VB3 by a dedicated extension point.
In PoolParty, the analogous of the resource-view for a concept consists of several tabs corresponding to various functionalities, such as detailed editing, notes, history, quality management, etc. The editing tab itself is subdivided into tabs, corresponding to different cohesive groups of properties. By default, it is possible to use the SKOS tab to edit the core description of a concept. However, additional tabs can be activated, by choosing an ontology or a custom scheme (a view on a subset of one or more ontologies developed for some purpose). Indeed, PoolParty treats ontologies as second-class citizens: while it has long been possible to edit them inside PoolParty, until version 7, editing of ontologies used a completely different, very constrained user interface. Indeed, only PoolParty 7 recently introduced a class tree for the class taxonomy.
PoolParty supports change tracking, while history can be browsed both globally and per resource. The approval workflow allows to exert some control on proposed changes: concepts transition to the draft state upon any change, and an explicit action is required to transition them again to the approved state. Upon unapproved changes, the concept can be assigned to a user for remedy. If the thesaurus is seriously compromised, it is possible to revert to a previously snapshotted state. VB3 also supports snapshots and quickly switching to a snapshot for visualization. However, reverting to a snapshotted state is – at the time of writing – not supported. PoolParty supports quality management through the integration of qSKOS48
PoolParty can leverage existing Linked Datasets, e.g. to populate a thesaurus or create mappings (e.g. to DBpedia). Similarly, VB3 supports browsing (via the resource-view) remote resources (accessed via HTTP or SPARQL) and creating mappings to remote datasets.
PoolParty supports (as VB3 does) the association of JIRA for task management.
Beyond thesaurus management in strict sense, interesting features of PoolParty (in some offerings) are the acquisition of concepts/terms from a corpus and the semantic annotation/classification of documents. Currently, VB3 lacks these capabilities. One may argue that they should be provided by external services that (right now) can interact with VB3 through its API or via a shared triple store. Indeed, there have already been some attempts to integrate knowledge acquisition from text in our platform [16,19] through CODA.
TopBraid EVN49
EVN has become part of TopBraid Enterprise Data Governance (EDG) as the package for Vocabulary Management (VM): https://www.topquadrant.com/products/topbraid-edg-vocabulary-management/.
TopBraid EVN implements change governance through working copies. Alike branches in GIT, working copies can be edited autonomously, and then merged to the production version of the asset, if the proposed changes are approved. The approval process is supported by a comparison report showing the difference between the copy and the production version in terms of property value changes of resources. The same type of report is available to editors, to understand how a resource has evolved, and in case undo a change. In addition to this resource-centric view, TopBraid EVN supports browsing and searching the history in terms of coarse-grained changes consisting of multiples triple additions/removals. Again, it is possible to revert individual changes. However, reverting a change in the middle of the history may create orphan resources. Validation in VB3 has the same problem. The behavior of TopBraid EVN differs from the validation in VB3 with respect to their interaction with the history. Reverting a change appends to the history another change that undoes the effects of the former. In VB3, a change pending for validation is – on purpose – not logged in the history, and if it is rejected, it is like the change had never happened. In TopBraid EVN, working copies enable a similar result. Archiving a working copy is alike snapshots in PoolParty and VB3.
TopBraid EVN implements integrity checks via SPIN50
Like WebProtégé, TopBraid EVN allows to customize the form associated with a class. Internally represented in SWP51
TopBraid EVN supports the assignment of tasks to users at different levels (e.g. asset or individual resources). Additionally, TopBraid EVN supports comments on resources. Transitioning between a few statuses, comments also provide a simple task system.
In addition to these integrated facilities for collaboration, TopBraid EVN supports linking projects to JIRA: e.g. the editing view focused on a resource enables to see or create related issues on JIRA. As already stated, PoolParty and VB3 also offer this capability. Actually, VB3 defines an extension point that can be implemented for different collaboration platforms.
Like PoolParty, TopBraid EVN can manage document corpora, and supports both manual and automatic (document-level) semantic tagging of documents.
TemaTres is an open source web application for the management of thesauri, glossaries, controlled vocabularies, etc. TemaTres uses a term-based model in contrast to the concept-based model underpinning SKOS. Indeed, SKOS is only available as an import/export format, while data is stored in a relational DB using a dedicated schema. This schema is enough flexible to support custom relations; however, it doesn’t support the import of custom ontologies, and these customizations do not make it into the SKOS export anyway.
TemaTres supports multilingualism via interlinked monolingual vocabularies, either on the same TemaTres instance or accessed via a terminological web service, enabling the federation of TemaTres instances. Federation also benefits vocabulary mapping, allowing for term-lookup over remote vocabularies. VB3 achieves a similar goal through “assisted search”, enabling term lookup over the SPARQL endpoints of open online datasets. TemaTres supports bulk generation of mappings, by fetching and then reversing mappings contained in a federated vocabulary.
TemaTres has a workflow model like the one of VB3: concepts are created in a candidate state, and once accepted, they do not reenter the “modified” state after each modification. While TemaTres implements the state as an explicit metadata of the term (as in VB2), in VB3 the state is represented implicitly through the state of the triple asserting the characterizing class of the resource (when validation is enabled).
TemaTres has a very limited support for change history in the form of recent changes to a vocabulary (also available as an RSS feed).
TemaTres can be configured to enforce some integrity constraints (e.g. disallow polyhierarchy), while offering some quality assurance tools (e.g. terms without hierarchical relationships). The TemaTres Keyword Distiller uses terms extracted from text52
iQvoc53
Governance of change in iQvoc is based on the idea of differentiating the published version of a concept and its (unique) draft version created upon a change to that concept. Furthermore, locking the draft version prevents conflicts. Users with suitable rights can publish the draft version of a concept, making the changes persistent and visible. Before publishing, these users can request the evaluation of some integrity constraints, in order to avoid the corruption of the data being edited. In iQvoc, the granularity of validation coincides with individual concepts being edited, while VB3 records individual operations for validation. The approach of iQvoc enables to group together individual changes that are best vetted together. However, it is impossible to validate cross-concept changes.
iQvoc lacks a global history of changes; however, changes to individual resources can be described by attaching SKOS change notes to the affected resource (creator and date time are set automatically).
To our knowledge, VB3 is the first multi-model editor concerned with OntoLex-Lemon. In literature we could only find purpose-built systems that are tailored to a specific application of lemon (in broad sense, thus including the legacy Monnet lemon [44]). McCrae et al. argued [43] that generic data-driven editors are difficult to use with the lemon model: some model constructs are not properly displayed, and, moreover, there are constructs made of a few triples that logically should be manipulated as a single entity. McCrae et al. addressed these issues through the development of Lemon Source. Lemon Source also addresses collaboration, which was identified as a key requirement for lexicon development. The system thus incorporates change tracking, role-based access control, validation workflow, etc. Most of these items are generally useful features, already found in general-purpose collaborative editors such as VB3. Both Lemon Source and VB3 hide (most of) the complexity of the model, by prompting the user for essential information about a given construct (say the lemma of a lexical entry), which drives the generation of its complex RDF serialization. Lemon Source automates the construction of ontology lexicons a bit further: by means of a configurable NLP (Natural Language Processing) pipeline, it creates lexical entries from (RDFS) labels commonly found in ontologies, computing their tokenization, syntactic tree, and using (whenever possible) entries in already existing lexicons (e.g. Princeton WordNet). Unfortunately, Lemon Source is no longer publicly available.
Lemon Assistant [54] is another web-based editor for lemon, which is based on the design patterns for ontology lexicons [46]. Its motivation lies in the observation that the use of lemon is complex and error prone. In VB3, we implemented all the patterns supported by Lemon Assistant, but we complemented them with more general operations on lemon models, so that we are not constrained to ontology lexicons. Indeed, despite what the extended name (“lexicon model for ontologies”) of the model would suggest, lemon is largely used beyond its original scope, for example for the representation of language resources as Linked Data. However, VB3 does not support – at the moment – the generation of usages examples of lexical entries and some integrity (cross-language) checks. Lemon Assistant is currently available only as an online service,55
LexO [3 ,4] is the most recent lemon editor, grown in the area of Digital Humanities to support philologists, historical linguists and lexicographers. There are different versions of LexO that were developed in different projects to support different linguistic phenomena through a combination of extensions of the lemon model and customizations of the user interface: the notion of root for Arabic, transliteration and tone for Chinese, multiple alphabets, multi word expressions combining words in different languages and ancients forms without a canonical form (because were never attested) for Old-Occitan. Conversely, the demo56
In Monnet lemon, the representation of a wordnet was achieved as if it were a lexicalization of an ontology: synsets were usually represented as instances of an arbitrary class, while words were represented as lexical entries. Previous editors supported the editing of language resources with this mechanism. However, OntoLex-Lemon eventually differentiated between an ontology lexicon and a wordnet-like resource: the class lexical concept models synsets, while the attachment of lexical entries is achieved with a dedicated set of properties. Obviously, editors developed long before OntoLex-Lemon may not support all of this. Conversely, VB3 features an extensive support for lexical concepts, and it was tested with very large resources: for example, in Section 4.1.4 we cited the possibility to manage the collection of 34 wordnets collected in Open Multilingual Wordnet. Another recent innovation of the model not supported by previous editors is the LIME metadata module. VB3 supports the computation and the export of this kind of metadata. In the future, VB3 will benefit from this metadata to better orchestrate the alignment of different datasets: e.g. determine the overlap in the supported natural languages, or the identification of useful language resources.
In the last years, VocBench has addressed the needs of large organizations, companies and independent users needing an open source collaborative environment for editing thesauri, supporting a formalized editorial workflow. Continuous user feedback allowed us to spot bugs and to improve the usability of VocBench.
It is thanks to this community feedback, to the support of the ISA2 program and to our desire to reach new quality levels that we started this endeavor, by rethinking most of VocBench from scratch, still benefiting from the experiences we had with VB2.
The most important achievement of the new platform lies at its core: a fully-fledged RDF core framework, developed by further improving the Semantic Turkey framework with functionalities for user management, role-based access control, change tracking and collaboration and by providing it with a new user interface. With respect to VB2, we could say VB3 is a user interface (delivered as a web application) for the improved Semantic Turkey platform. A second major achievement is the broadened support for all major standards of the RDF family, going beyond SKOS thesauri and embracing OWL ontologies and OntoLex (both as a core model for developing lexicons and as a lexicalization model for all kind of RDF datasets) which makes of VB a unique, comprehensive offer in the scenario of RDF development platforms.
We hope that this evolution of the system will lay a solid foundation for the realization of a new range of services spacing from knowledge acquisition, evolution and management in Europe and worldwide.
Footnotes
Acknowledgements
This work has been funded by the European Commission ISA2 programme; the development of VocBench 3 (VB3) is managed by the Publications Office of the EU under contract 10632 (Infeurope S.A.)