
Abstract
The PAROLE/SIMPLE ‘lemon’ Ontology and Lexicon are the OWL/RDF version of the PAROLE/SIMPLE lexicons (defined during the PAROLE (LE2-4017) and SIMPLE (LE4-8346) IV FP EU projects) once mapped onto lemon model and LexInfo ontology. Original PAROLE/SIMPLE lexicons contain morphological, syntactic and semantic information, organized according to a common model and to common linguistic specifications for 12 European languages. The data set we describe includes the PAROLE/SIMPLE model mapped to lemon and LexInfo ontology and the Spanish & Catalan lexicons. All data are published in the Data Hub and are distributed under CC Attribution 3.0 Unported license. The Spanish lexicon contains 199466 triples and 7572 lexical entries fully annotated with syntactic and semantic information. The Catalan lexicon contains 343714 triples and 20545 lexical entries annotated with syntactic information half of which are also annotated with semantic information. In this paper we describe the resulting data, the mapping process and the benefits obtained. We demonstrate that the Linked Open Data principles prove essential for datasets such as original PAROLE/SIMPLE lexicons where harmonization and interoperability were crucial. The resulting data is lighter and better suited for exploitation. In addition, it facilitates further extensions and linking to external resources such as WordNet, lemonUby, DBpedia etc.
Introduction
The PAROLE/SIMPLE ‘lemon’ Ontology is the OWL/RDF version of the PAROLE & SIMPLE lexicon models (defined during the PAROLE LE2-4017 and SIMPLE LE4-8346 projects) once mapped to lemon1
The original PAROLE/SIMPLE3
Catalan, Danish, Dutch, English, Finnish, French, German, Greek, Italian, Portuguese, Spanish and Swedish.
The goal of SIMPLE project was to add semantic information to the set of harmonized multifunctional lexicons built for 12 European languages by the PAROLE consortium. All PAROLE/SIMPLE lexicons were defined against a common model defined in the DTD. Thus all PAROLE/SIMPLE lexicons are XML files valid against the same DTD.5
Original PAROLE/SIMPLE lexicons were in SGML so we previously converted them into XML.
LMF [6] (Lexical Markup Framework) is an ISO standard (ISO-24613:2008) for computational lexicons. LMF combines the best designs and methods from many existing NLP lexicons.6
Especially GENELEX, PAROLE and SIMPLE.
Lemon [4,7] (‘lexicon model for ontologies’ developed by the Monnet project http://www.monnet-project.eu/) is a model for modeling lexica in RDF. The lemon model consists of a core path defined as: OntologyEntity ↔ LexicalSense ↔ LexicalEntry → LexicalForm → WrittenRepresentation. Lemon is highly compliant with LMF.
LexInfo [3,5] is a model for the linguistic grounding of ontologies and as such allows for the association of linguistic information (such as part-of-speech, subcategorization frames etc.) with ontology elements (such as concepts, relations, individuals, etc.). LexInfo it is also highly compliant with LMF and the lemon model.
Mapping PAROLE/SIMPLE lexicons onto lemon/LexInfo involves three tasks. Firstly, the original PAROLE/SIMPLE model expressed in the DTD needs to be mapped onto the lemon model. This can be seen as the lexicon format mapping. Secondly, all descriptive elements defined by PAROLE/SIMPLE lexicons are mapped onto the LexInfo ontology. This includes language dependent descriptive elements and common elements.7
Note that, whereas PAROLE lexicons are structurally compatible, in certain aspects they are semantically idiosyncratic as each lexicon defines its own ‘descriptive’ elements. Thus for example, subcategorization frames are defined in each lexicon without any reference or relation to the others. In contrast, SIMPLE lexicons go one step further and define a set of shared descriptive elements.
The resulting dataset is organized into three files. One contains the PAROLE/SIMPLE Ontology which essentially imports lemon and LexInfo ontologies and adds ‘PAROLE elements’ (classes and/or properties) whenever these could not be mapped. The other two files collect the Spanish and Catalan lexical entries.
In the following sections we describe the clues of the mapping process and highlight some of the benefits obtained.
The strategy followed when mapping PAROLE/SIMPLE model onto lemon can be summarized as follows:
Elements from the DTD were mapped onto classes. Whenever possible, lemon (and LexInfo) classes were used. Otherwise, new classes were created. For example: PAROLE Description elements become lemon:Frames. In contrast, the parole:Connotation class was created as a subclass of parole:Element and lemon:PropertyValue as shown in Fig. 1. Note that many PAROLE/SIMPLE elements are not mapped and simply disappear in the target model. This is partially due to the fact that RDF allows a better modeling and they are no longer needed.
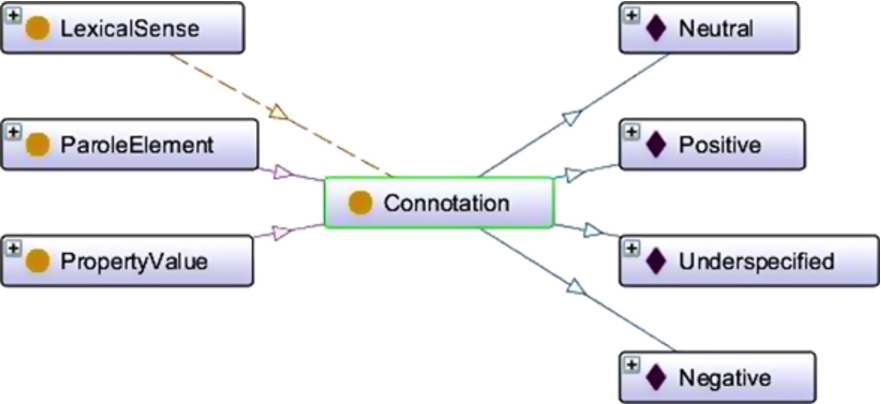
Adding classes.
Attributes from the DTD were mapped onto Properties. Again, whenever possible, lemon or LexInfo properties were used. For example: PAROLE MuS/@gramcat8
We use XPath expressions when referring to source data.
Values. When the PAROLE/SIMPLE DTD establishes the set of values for a given attribute, these values are mapped onto the corresponding LexInfo values. For example: the PAROLE pair: “NOUN” + “COMMON” simply translates as lexinfo:commonNoun as shown in Fig. 2.
Parent

Attribute mapping.
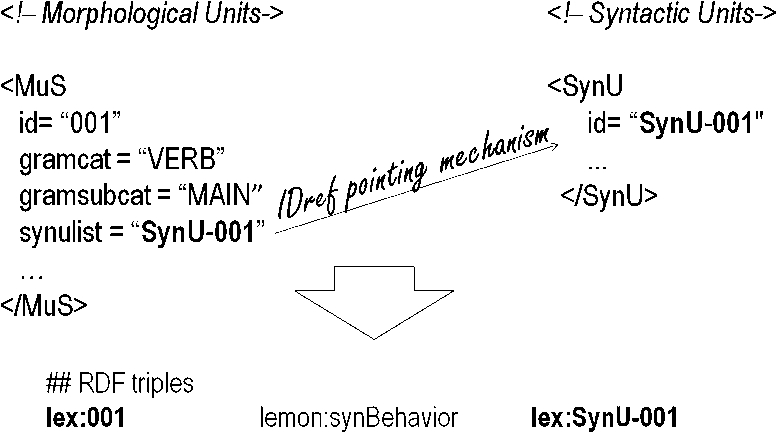
Mapping the IDREF pointing mechanism.
IDREFs pointing mechanisms between elements in the DTD became properties. For example: the relation between PAROLE morphological and syntactic units (MuS & SynUs) is expressed by means of the lemon:synBehaviour property as shown in Fig. 3.
Though the mapping process implied a considerable effort we think the task was worth it. The source model (DTD) and common descriptive elements are already mapped and can be reused by other languages. This process involved two main aspects: a change of model (both conceptuall9
Notice that we moved from a layered model onto an ‘integrated’ one and from an ER model formalized as a DTD into an ontology.
Finding the right correspondences between PAROLE/LexInfo ‘vacabularies’ was rather tough and not always easy due to the lack of documentation in the original lexicons. Note for instance that the LexInfo model includes up to 319 morphosyntactic features.
Notice that PAROLE model allowed for both coarse-grained and fine-grained descriptions.
Our lexicons include lots of pronominal and sentential frames (used to distinguish between indicative and subjunctive complements) that were not listed in the LexInfo ontology.
Note for instance that getting all transitive verbs in the original PAROLE lexicons meant searching for each and every transitive frame.
In any case, conversion tasks can benefit from already defined conversion templates which can be reused when mapping lexical entries from different languages and sources. Figure 4 shows part of the XSL template used to map PAROLE features to LexInfo ontology.
The Lemon model simplifies the original PAROLE/SIMPLE model in a good number of aspects. This is partly due to the use of RDF which allows for a more compact and efficient representation. The case of syntax/semantic mappings is particularly interesting. The original PAROLE/SIMPLE data include a complex machinery to define syntactic subcategorization frames and semantic argument structures. In the former case, we have to deal with a large set of related elements: SynU, Description, Construction, Self , InstantiatedPositionC, PositionC, SyntagmaNT, etc. The relation among these elements is established by means of the parent/child relation mechanism or ID/IDREF pointing mechanism as exemplified in Fig. 5.

Mapping features.

Subcategorization information.
Similarly, argument structure representation is also complex and, again, we find a good number of elements involved: PredicativeRepresentation, Predicate, Argument, InfArg, SemanticRole, etc.
Syntax semantic linking in the PAROLE/SIMPLE model is even more complex and, in most cases, useless. Syntactic frame descriptions and semantic predicate descriptions are completely separated. The former involve syntactic arguments whereas the latter involve semantic arguments with no relation at all between them. Syntax/semantic relations are expressed by means of additional elements: the Correspondence element and its ‘descendants’. Correspondence are global elements that point to SimpleCorrespArgPos elements which are the eventual holders of the syn/sem argument linking. Since SimpleCorrespArgPos elements are global, the linking is defined not in terms of arguments IDs but in terms of the position they occupy in the syntactic frame and the semantic predicate. Note in addition (see Fig. 6) that neither the syntactic frame nor the predicate involved are at hand.
The lemon model allows defining all these things in a much easier way, essentially:
Description, Construction & Self elements are mapped to lemon:Frame class and related onto the relevant entry by means of the lemon:synBehaviour property.
InstantiatedPositionC, Position & Syntagmas are mapped onto lemon:Argument class and related to the relevant lemon:Frame via some lemon:synArg relation.
PredicativeRepresentation & Predicate are also mapped onto lemon:Frame.
Argument, SemanticRole & InfArg become lemon:Argument class and link to relevant lemon:Frame via some lemon:semArg relation.

Syn/sem linking in PAROLE/SIMPLE.
A simplified entry for the English verb ‘write’ can be found in Fig. 7. Figure 8 gives a partial graphical representation. There we can see that both the syntactic frame and the lexical sense point to ARG0 and ARG1 instances. In the former case, the frame links to its arguments by means of subject and object properties. In the latter case, the lexical sense links to its arguments by means of agent and patient properties. Finally, arguments are also specified for a semantic template (Human & SemioticArtifact respectively) and syntactic realization (NP in both cases).

A simplified entry for the English verb write.
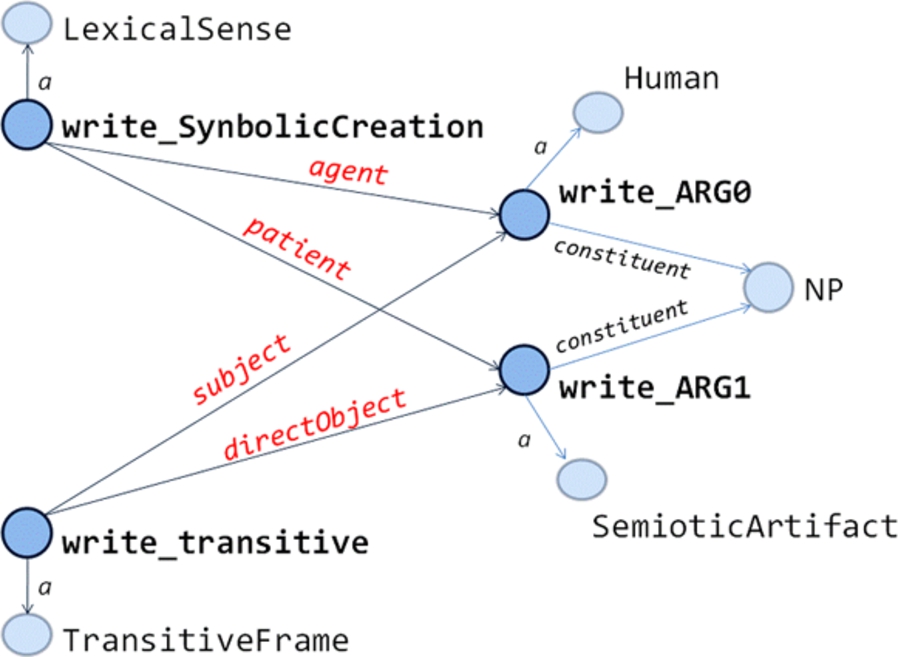
Simplified Syn/Sem linking.
Each original PAROLE lexicon defines the set of subcategorization frames for a particular language. Contrary to semantic descriptions, syntactic descriptions are essentially language dependent. Thus whereas all lexicons share the same set of semantic descriptive elements (domain, semantic class, semantic relations, etc.) such homogeneity was not defined in the syntactic layer. This means that subcategorization information cannot be easily shared among the lexicons. Basically, this is due to the fact that PAROLE aimed at being a flexible model to accommodate different approaches. This might be welcome but proves problematic when addressing interoperability among resources and prevented us from providing a general frame ontology14
As an extension of the LexInfo one.
Differences between lexicons are important. For example, in the Spanish lexicon optionality of arguments is dealt at the argument level (optional complements are marked as optional) whereas in the Catalan lexicon optionality of an argument generates two distinct frames; Spanish frames include passive constructions whereas Catalan frames do not; etc.
LexInfo defines the subcategorization ontology as the instantiation the lemon classes. As we saw, lemon includes the notion of Frame. Frames are indicated with the synBehaviour property and their arguments with the property synArg. LexInfo defines subproperties of synArg to represent the syntactic functions of arguments and organizes frames into subclasses. Our mapping to LexInfo implied mapping PAROLE subcategorization frames onto this model (Description elements and their ‘descendants’). The mapping process was done in two steps. First, we defined a style sheet converter that reads our PAROLE XML lexicon and for each Description element generates a new Frame. Consequently, all newly created frames were treated as subclasses of the general lemon:Frame. Second, we collapsed some frames into one single class,16
For example, the original Spanish lexicon includes 12 intransitive prepositional Descriptions, one for each bounded preposition. All these frames are mapped to IntransitivePP Frame as the information about the preposition is encoded by means of a property attached to the PP argument.
SPARQL query to retrieve verbs with a sentential argument (with inference):SELECT DISTINCT ?label
WHERE { ?entry lemon:synBehavior ?frame; rdfs:label ?label.
?frame lemon:synArg ?arg.
?arg lemon:constituent parole:Clause.}
The most difficult problem of the original PAROLE/SIMPLE lexicons is exploitation and management. When moving from the original PAROLE/SIMPLE model to a relational database, we end up with a complex database with a huge number of related tables.18
Our PAROLE/SIMPLE database included 223 tables.

SPARQL sample query.

Query results.
The Ontology and both the Spanish and Catalan lexicons are distributed under CC Attribution 3.0 Unported license. These datasets are published in the Data Hub (http://datahub.io/dataset/parole-simple-lexinfo-ontology-lexicons) and can be downloaded in both XML RDF format and RDF Turtle format.
The Spanish lexicon contains 199,466 triples with 7,572 lexical entries fully annotated with syntactic and semantic information distributed as follows: 5,659 common nouns, 729 proper nouns, 859 adjectives and 325 verbs. The lexicon contains 11,430 LexicalSenses.
The Catalan lexicon contains 343,714 triples and 20,545 lexical entries annotated with syntactic information half of which are also annotated with semantic information. Lexical entries include 3,064 verbs, 13,206 common nous, 247 proper nous, 3,101 adjectives and 511 adverbs. The rest belong to closed categories. The lexicon contains 11,813 LexicalSenses.
Table 1 lists the properties assigned to LexicalSenses19
Semantic relations and semantic roles are grouped. The object of ‘semantic relation’ triples is always another LexicalSense.
Triples assigned to LexicalSense
The dataset described here is the result of mapping PAROLE/SIMPLE Spanish and Catalan lexicons onto the lemon model following the LexInfo ontology. The mapping implied three main tasks: the lexicon format mapping (from DTD to lemon model), the ontology mapping (from ‘descriptive’ elements to LexInfo ontology) and the mapping of lexical entries.
This work may help and encourage other PAROLE/SIMPLE lexicons to take the same way.20
Most PAROLE/SIMPLE lexicons have been maintained and enlarged since their creation and are available at the META-SHARE nodes (i.e.
The resulting lexicons benefit from standardization and Linked Open Data principles. The fact that source data categories are mapped onto the LexInfo ontology which in turn is linked to ISOcat21
From our experience we conclude that XML (essentially DTDs) is not well suited for modeling purposes as it allows for a number of syntactic alternatives and conveys semantic ambiguity. In addition, XML proves inefficient when relating resources. This is crucial in a scenario where references to external resources are essential to guarantee interoperability. RDF overcomes some of the problems met with XML. The use of RDF (especially URIs) proves essential for datasets such as original PAROLE/SIMPLE lexicons where interoperability was crucial. The resulting data is lighter and better suited for exploitation. In addition, it easies further extensions and links with external resources such as WordNet, lemonUby, DBpedia etc.
Acknowledgements
The resources reported in this paper were developed with the support of METANET4U: Enhancing the European Linguistic Infrastructure, (2011–2013), funded by UNER – Competitiveness and Innovation Framework Program, (CIP-PSP-270893).
We thank the Institut d’Estudis Catalans and the GilcUB from the University of Barcelona as the creators of the original Catalan and Spanish lexicons.
Finally, we also want to thank the reviewers of this paper for their valuable comments and suggestions.