
Abstract
Over the last decade, extensive research has been done on automatic construction of knowledge graphs from Web resources, resulting in a number of large-scale knowledge graphs such as YAGO, DBpedia, BabelNet, and Wikidata. Despite that some of these knowledge graphs are multilingual, they contain few or no linked data in Persian, and do not support tools for extracting knowledge from Persian information sources. FarsBase (available at
Introduction
Construction of knowledge graphs (KGs) from open-access data such as Wikipedia has revolutionized the semantic capabilities of information retrieval systems, including search engines and personal assistants like Siri, Google Assistant, Alexa, and Cortana. Users mostly prefer to find the exact answer instead of scrolling down through a list of results and then finding the answer in a Web page. For example, the desired response for “How many children does the Queen have?” is simply “Four”. Such a response requires a credible and up-to-date knowledge graph with comprehensive information for answering semantic user queries. In fact, most of the challenges in information acquisition that were traditionally handled by the search engine’s users – such as credibility analysis of the information sources (“should I trust this website?”), conflict resolution, and fact-checking – should now be handled by knowledge graph systems.
The past decade has witnessed ambitious research in knowledge graph construction. This includes knowledge graphs constructed from Wikipedia such as DBpedia [39]; systems that extract knowledge raw text, e.g. NELL [52]; as well as the hybrid systems that exploit multiple types of information sources, including YAGO [47].
In this paper, we present FarsBase, a Persian knowledge graph constructed from various information sources, including Wikipedia, Web tables and raw text. FarsBase is specifically designed to fit the requirements of structural query answering in Persian search engines. Our contributions are as follows:
We provide a hybrid architecture for knowledge graph construction from multiple sources that leverage both top-down and bottom-up approaches.
Contrary to other knowledge graphs, FarsBase is specifically constructed for Persian search engines. In that respect, the query log plays a key role in minimizing the human effort for knowledge graph construction and semantic search.
FarsBase supports rule-based methods that enable flexibility for data extraction and manipulation in several components of our architecture.
FarsBase supports efficient human labeling for managing and cleansing data from different sources and in multiple versions. The knowledge extractors extract multiple features that facilitate prioritizing and grouping the entities for cost-effective batch verification of triples by human experts.
We provide a mechanism for integrating data from heterogeneous knowledge extractors. Our mechanism handles different versions from data sources with minimum expert intervention. To the best of our knowledge, FarsBase is the only multi-source knowledge graph that supports timeliness [28] by handling different versions of data from multiple sources.
The remainder of this paper is organized as follows. The preliminaries and motivation are briefly introduced in Section 2. Section 3 describes a cost-based solution to select knowledge sources for FarsBase. We give an overview of FarsBase architecture in Section 4. Section 5 explicates knowledge extraction from different sources, including Wikipedia, Web table and raw text. In Sections 6, 7, we describe how extracted triple are mapped and integrated into a unified knowledge graph. Evaluation and statistics about FarsBase are reported in Section 8. Section 9 describes related work in knowledge graph construction, quality assessment, mapping, relation extraction from raw texts, never-ending paradigms and knowledge augmentation. Finally, Section 10 concludes the paper with directions for future work.
Preliminaries and motivation
In this section, we briefly introduce the basics of knowledge graph construction and representation. Also, we explain challenges for constructing a multi-domain Persian knowledge graph.
Knowledge base and knowledge graph
A knowledge base contains a set of facts, assumptions, and rules that allows storing knowledge in a computer system. Knowledge bases can be specific to certain domains, e.g. a medical knowledge base containing facts about medical drugs (such as their properties and interactions). Also, knowledge from multiple domains can be integrated to build a general-domain knowledge base. For example, DBpedia [39] is a multi-domain knowledge base that is semi-automatically constructed from Wikipedia articles. Knowledge bases require a data model to organize the facts. A typical approach is to define an ontology, where data instances (a.k.a. entities) are assigned to classes. Each class can be a subclass of another class, which results in a hierarchy known as the ontology tree. The facts of a knowledge base are commonly represented using a knowledge representation format. Modern multi-domain knowledge bases use the Resource Description Framework (RDF) for knowledge representation. RDF is primarily designed to represent resources on the Web, but it can also be used for knowledge management and supports essential features for constructing a knowledge base, such as Is-A relations and object properties.
In Semantic Web and linked data, there are different definitions of knowledge graph (KG); Ehrlinger et al. tried to clarify the term in [24]. They mentioned 5 selected definitions of knowledge graph and presented an architecture for it. They assumed a knowledge graph is somehow superior and more complex than a knowledge base because it contains a reasoning engine and also integrates knowledge from one or more sources.
Resource description framework
RDF is a standard for conceptualizing structural data. In this model, data is represented as a set of triples consisting of a subject, a predicate, and an object. A set of triples forms an RDF graph.
The RDF format enables knowledge representation using Web resources, where each resource has a Unique Resource Identifier (URI). In RDF, subjects and predicates are URIs, and objects can be either URIs or literal values. RDF data is serialized and stored using different textual syntaxes, e.g. Turtle and NTriples. For example, the fact that “Einstein knows Niels Bohr” can be represented in Turtle syntax as follows:

RDF can be easily used for knowledge graphs derived from non-English data. String literals can have a language tag, which is very useful for building multilingual knowledge graphs. For example, Albert Einstein can be represented as “Albert_Einstein”@en or “ ”@fa.
”@fa.
FarsBase: A Persian knowledge graph
Constructing a multi-domain and comprehensive knowledge graph from unstructured and semi-structured Web contents has been of interest for a while. The DBpedia project was initiated a decade ago to construct a knowledge graph from Wikipedia. Further works like YAGO [47] and BabelNet [61] integrated other sources, e.g. WordNet and GeoNames [86], in order to construct a more-enriched knowledge graph. Raw text data collected from Web can also be used to supplement knowledge graphs [53].
Thanks to tons of research in knowledge graph construction techniques, multi-domain knowledge graphs such as DBpedia and YAGO have a comprehensive set of facts extracted from English and other European languages. However, these knowledge graphs do not contain enough facts from a low-resource and challenging language [77], such as Persian. This is mostly due to the fact that tools required for automatic knowledge graph construction are not mature enough to be used in multilingual knowledge extraction engines. Also, Persian NLP toolsets suffer lower accuracies due to the small size of the Persian corpora. We tackled these challenges by various techniques that boost the accuracy of knowledge graph construction in Persian. The main challenges for FarsBase construction are summarized as follows:
Knowledge graph construction engines use numerous NLP tools for knowledge extraction. The errors caused by each of the tools are propagated throughout the system and result in low-precision outputs. Whenever the accuracy of an NLP toolset is too low, the toolset should be either enhanced or replaced with alternative approaches.
Knowledge graph construction requires human supervision as a part of the process, e.g. in the mapping phase (explained later in Section 6). Major knowledge bases such as DBpedia mostly focused on English and other widespread languages and did not put effort into mapping and cleaning Persian data. We argue that human supervision for yet-another language is non-trivial.
FarsBase is primarily constructed to be used as a backbone for semantic search in Persian Search Engines, it should be accurate for frequent user queries. Also, since a significant number of user queries target recent knowledge (e.g. details about a new celebrity or a recent event), the knowledge construction mechanism should be specifically eager to extract knowledge from the trending entities and relationships. To the best of our knowledge, none of the accessible knowledge graphs are optimized with respect to the user search query log.
FarsBase is designed to be specifically precise on parts of the knowledge graph that are frequently searched. Aside from having precise knowledge for frequent queries, a significant share of structural queries in a search engine correspond to recent content, such as queries about new celebrities and recent events. Therefore, our knowledge construction engine extracts new entities and relationships that are recently introduced in Persian Web sources.
Sources used in famous knowledge graphs
Sources used in famous knowledge graphs
FarsBase is automatically constructed from the Persian (Farsi) section of Wikipedia and is expanded by other data sources such as text and Web tables. Despite the fact that FarsBase is connected to various multi-lingual knowledge graphs, the main focus of FarsBase is on extracting knowledge from Persian sources. In fact, some multilingual information extraction tools already support Persian, but their accuracy on Persian sources is very low. In DBpedia, for example, the knowledge extraction engine is entirely run on Persian Wikipedia but very few triples are extracted. However, FarsBase is primarily constructed to extract Knowledge from Persian sources on the Web.
FarsBase has been designed to be a multi-source knowledge graph. Even though other knowledge graphs also use multiple sources, none of them is designed to be a knowledge graph which accepts structural data and raw texts concurrently. For example, DBpedia mainly extracts triples from Wikipedia (Some researches has been made to augment DBpedia from other sources e.g. [5,58,59]). Similarly, BabelNet is constructed with Wikipedia and WordNet only; and NELL has mainly focused on raw texts and extracts limited number of predicates. To our knowledge, YAGO is the only knowledge graph that supports multiple structural sources and can extract from raw text using an extension [37]. However, the libraries and architecture of YAGO requires language-specific libraries that are of very poor quality for Persian.
FarsBase is constructed by integrating data from different sources, including Wikipedia infoboxes, Tables extracted from Web pages, and raw text collected from various sources.
The information sources for building a knowledge graph should be rich and accurate. Different types of input sources may be considered for knowledge graph construction, including:
Existing knowledge graphs: Freebase, Wikidata.
Encyclopedias: Wikipedia, World Book Encyclopedia
Domain-specific databases: IMDb, BrainyQuote, TripAdvisor, etc.
Semi-structured Web sources: Web tables, infoboxes.
Unstructured (raw) text, collected from the Web and book texts.
Direct human input: collected by human experts or crowdsourcing.
Each of the existing knowledge graphs used one or a couple of the above sources that were accessible at the time of knowledge graph construction. Table 1, summarizes the input sources for common knowledge graphs.
Availability of sources in Persian
Sources for constructing Persian knowledge graphs are limited, both in terms of the number of available options, and their quantity and quality. Wikipedia, for example, contains over 5.6 million English articles, but only 0.6 million articles in Persian. Aside from Wikipedia and raw text, the other common data sources for knowledge graph construction, shown in Table 1, have no Persian alternative or are so small that are not worth extraction. For example, there are few Persian websites similar to the IMDB movie database, such as
Persian sources are sparse. In Wikipedia, for example, English articles usually contains more information than their Persian version. More specifically, Persian Wikipedia articles are less verbose, have fewer links and many of them have no infoboxes. This is mostly due to the smaller community of contributors for Persian, which also impacts the quality of the content. Other types of sources such as Web pages are even poorer in quality due to the massive amount of hoaxes and false information, that even appear on credible news sources.
Due to the numerous challenges associated with Persian sources, the first step for FarsBase construction is to select a set of sources that have comprehensive and accurate information.
Source selection: A cost-based approach
In order to use FarsBase for query answering in search engines, its primary application, it should contain a diverse and comprehensive set of facts from all domains to cover a large share of user queries. Such a large knowledge graph should be collected with an affordable effort, hence we should consider the cost of knowledge extraction from each source. Extracting information from texts, tables, and other sources on the Web is far more challenging and costly than the structured sources like Wikipedia, mainly due to the lack of structure and quality issues.
General cost measures The cost of exploiting a source can be defined as the human effort required for verifying its facts, e.g. in terms of “second per tuple”. Using an incredible data source might lead to false information and increase the demand for human verification. Errors generated by the knowledge extraction modules can also call for more verification.
Application-specific cost measures In most applications, facts of the knowledge graph are not of the same importance. In a search engine, for example, the importance of an entity or relationship is proportional to how frequently it appears in user queries. A false relationship about frequently-searched entities, e.g. “Barack Obama was born in Africa”, has a higher impact on users than the same false information on non-famous people. Moreover, the cost of extracting a false relationship is much higher than missing the relationships from a source, which should be considered when tuning the sensitivity of the extraction algorithms.
We considered the following criteria for selecting and prioritizing the sources
To achieve a good trade-off between the quality and quantity of the extracted knowledge, in the following we provide a brief cost analysis for each of the available sources for Persian knowledge extraction.
Wikipdia
Wikipedia is a rich knowledge resource developed by millions of contributors. Most of the multi-domain knowledge graphs such as DBpedia, YAGO, and BabelNet use Wikipedia as their primary knowledge source [28]. Although the Persian Wikipedia is smaller than the English version, it is still the most valuable and accurate Persian knowledge source in comparison with other sources. Many Wikipedia articles have one or more infoboxes. Knowledge graph construction from infoboxes is very cost-efficient because the human effort is mostly on the mapping and transformation (Section 6.1) and the extracted data are accurate enough such that no human verification is required on the extracted triples.
Aside from the structured data in Wikipedia (infoboxes, abstracts, categories, redirects, etc), the raw content of the articles is very rich and has the highest quality compared to other raw text sources. This is further discussed in Section 3.2.3.
Web tables
Web tables are also rich sources for batch triple extraction. One can easily extract a considerable number of entities and their relations. Due to the high variety of structures in Web tables, the cost of extracting information from tables is much higher than infoboxes because it needs entity linking [12] and special extraction approaches [72,73,90].
Raw text
Due to the limited size of Persian Wikipedia, it has to be supplemented with additional knowledge extracted from other sources, most notably the raw text and Web tables. Hence, it is very important that the knowledge source contains substantial amount of information with high quality and low complexity, e.g. not having complicated grammar or table structure, so that the available tools can extract the knowledge effectively.
Raw-text extraction can be applied on any type of raw text, including Web content, books, and OCR-extracted texts. However, raw text requires significant effort to extract and verify knowledge because each triple must be verified by human experts. To overcome the high cost of extraction, we should select the most informative texts that contain a high number of entities and relationships.
To select the most cost-effective sources as input for RTE, we investigated four types of raw-text data: Wikipedia article bodies, news articles, technical and personal blog posts. We picked a set of randomly selected articles from each source, and manually counted the number of triples that are suitable for the knowledge graph. The data from all sources is collected on November 1, 2016.
To investigate the difficulty of knowledge extraction from each raw text source, we investigate the impact of co-reference resolution for each data source. Co-reference resolution can help extractor to find out more triples from the raw texts, but the quality of state-of-the-art Persian NLP toolsets for co-reference resolution is not very high. In all of the experiments, experts have counted the number of triples with and without co-reference resolution.
We performed a few preprocessing steps on each data source to ensure a valid comparison:
 ).1
).1
Table 2 shows the average number of triples in each category of the raw text sources, measured by human experts with and without co-reference resolution. Results are normalized by length to represent the number of triples per 1000 words.
Number of triples per 1000 words for different raw text sources
Number of triples per 1000 words for different raw text sources
Table 3 summarizes different cost aspects of the available data sources for FarsBase, including the need for natural language processing (especially Co-reference resolution), the number of triples, quality of each triple, and the overall cost of extracting knowledge from the source. Considering all these parameters, we built FarsBase using structured parts of Persian Wikipedia (primarily infoboxes); along with a selection of Persian news websites to cover recent information. We also support a high-precision approach to extract data from Web tables, which requires explicit human supervision.
Cost of available sources for FarsBase

FarsBase architecture.
In more details, FarsBase is constructed from the following data sources: Wikipedia structured data (infoboxes, entity categories, ambiguities, external links, Web pages, images, connections between entities, and rewriting ids, etc.), tables (with explicit human labeling), Wikipedia article bodies, and news websites.
In this section, we present the FarsBase system architecture and illustrate how integrating the knowledge graph with a search engine – especially having access to a query log – can optimize both the knowledge construction and the knowledge-graph search systems.
FarsBase consists of a KG construction system for extracting knowledge, as well as a search system for answering KG-based user queries and suggesting similar entities in a search engine. Figure 1 shows an overview of the FarsBase architecture.
The construction and search systems benefit from shared components and data in a symbiotic manner: The construction system updates the knowledge graph with the most recent triples, and this helps the Resource Extractor to extract more entities and ontology predicates from the input sources to feed the construction system.
Knowledge graph construction
FarsBase extracts knowledge from various types of sources, including Wikipedia, semi-structured Web data (e.g. Web-tables) and raw texts. The extracted data is then cleaned and organized with partial supervision by the expert.
Extractors Each resource type requires a separate extractor to process its data format. The main three extractors are as follows:
Wikipedia Extractor (WKE): Extracts triples from Wikipedia dump, including the infoboxes, abstracts, categories, redirects, and ambiguities.
TaBle Extractor (TBE): Extracts from Web pages that contain tables with informational records. The schema of the table, i.e. the mapping to KG, is suggested by the system but needs to be verified by a human expert. The current version of TBE is mostly designed for parsing tables in Wikipedia, where the mapping is easier to infer.
Raw-Text Extractor (RTE) consists of four extractor modules, namely the rule-based, distant supervision, dependency pattern, and unsupervised modules. RTE continually extracts new triples for the KG. To prioritize the input sources, KG prioritizes input sources (websites) based on the facts that are under-demand. To provide raw-text data for RTE, some crawled sources by a search engine has been fed it. RTE consumes and archives fed raw texts.
Each extraction module preserves a variety of metadata, including the version and URL of the source that the triple is extracted from. For example, when WKE reads a new dump to generate triples, the version of the dump is stored along with all the extracted triples.
Source selector RTE is fed by the crawler of the search engine, although it can use an independent crawler such as Heritrix or Apache Nutch. The Source Selector module prioritizes Web pages based on the cost-efficiency of the sources, as discussed in Section 3.2. The module also exploits the query-log of the search engine to prioritize Web pages based on the frequency that they appear in search results and the click-through rates.
Experts The extracted predicates must be mapped to a unified ontology. The mapping table is incrementally constructed by the human experts and stored in Candidate Fact and Metadata Store (CFM-Store). The experts are also used for various verification tasks, most importantly for verifying the mapping schemata for TBE and all the triples extracted by RTE.
Mapper The Mapper integrates triples generated by all extractors and converts them into mapped triples. The mapped triples and their corresponding metadata are written to the CFM-Store. The metadata of triples includes document URLs, the module that extracted the triples, version information, date of extraction, source texts (if available), expert votes and notes.
Candidate fact and metadata store (CFM-store) CFM-Store stores all triples and their metadata. FarsBase supports versioning, i.e. the CFM-Store contains multiple versions of each triple. The latest version of triples, after expert approval, is updated/filtered periodically at specified intervals (currently once a day) to the Belief-Store without any metadata.
Filtering/updating triples When transferring the triples to Belief-Store, the Update Handler re-builds the Belief-Store using the latest version of the mapped triples. Therefore, if a relation is removed from the input sources, it is no longer written in Belief-Store.
Resource extractor Resource Extractor is used by both the extraction engine (specifically for RTE), and the search system. It extracts all possible entities and relationships from a given text in a brute-force manner. Resource extractor does not apply any filtering or disambiguation on the extracted entities. Rather, it extracts all combinations of resources (i.e. entities and relationships) that might even overlap with each other and further computes several features for each resource such as its position in the sentence and the class of the resource. These features are very helpful for filtering out irrelevant resources in the consecutive components, e.g. for disambiguation.
Note that the RTE relies on the resource extractor, which in turn is backed by the Belief-Store. Therefore, the Belief-Store should be initially filled with data from Wikipedia and Web-tables, and then the resource extractor can be used to run RTE.
The search system
FarsBase is designed to respond to unstructured queries with structured output (entities) as the result. While the details of the search system are beyond the scope of this paper, we briefly explain the main components.
Searcher
Much of the attempt to search over knowledge graphs is on question answering systems, where the goal is to retrieve snippets of the documents that are related to the question and contain the answer [57]. However, we aim to design a system that answers specific questions with highly-reliable results instead of returning snippets.
An important requirement in a KB-based search in search engines is that wrong results are intolerable, such that a single wrong result by the KG-based search system for “President of the US” could be regarded as a disaster for the entire search business. As a result, the KG search system is admissible only if the precision is very close to 1. With this in mind, we follow a template-based approach which is similar to TBSL [85], where text queries are mapped to structural SPARQL queries according to a set of templates. Unlike [1,85], we do not directly allow auto-generated templates to be fed into the searcher. Instead, we first generate a set of templates, and then each template is verified by human experts to ensure that the precision of FarsBase for the query is satisfactory. To handle the very large number of generated templates, we exploit the query log to rank templates based on how frequently they are triggered, and then the most frequent templates are verified by the experts.
Related entity recommender
Entity recommendation, i.e. suggesting related entities for a given entity, is an interesting service for search engines. FarsBase exploits relevance propagation through heterogeneous paths in the knowledge graph to estimate the relevance between entities. The training is done using an active learning approach.
Extraction
FarsBase extract knowledge from three types of data sources, namely Wikipedia, Web-tables, and raw text. We briefly explain each extractor and the specific information that can be extracted from each source.
Wikipedia extraction
The Wikipedia extractor in FarsBase is similar to DBpedia [40] and YAGO [47]. The most important data types extracted from Wikipedia are as follows:
Infobox data Infoboxes contain a list of attribute and values. Note that an attribute might contain more than one value, e.g. “occupation: [job1, job2, …]”. A value can be a string literal, an image, a link to other Wikipedia articles, an external link, or a combination of these types. The values can also be objects that contain a list of key-values.
Abstracts and body of articles The body and abstracts of Wikipedia articles contain internal links, which are valuable sources for raw-text and table extractors. In particular, internal links are used to automatically extract high-confidence patterns for extracting facts from raw-texts.
Redirects Entities may have multiple titles. For example, “ ” (Saadi Shirazi, a Persian poet) has multiple alternative titles that refer to him in Persian Wikipedia, such as “
” (Saadi Shirazi, a Persian poet) has multiple alternative titles that refer to him in Persian Wikipedia, such as “ ” (The Master of Speech) and “
” (The Master of Speech) and “ ” (The Most Eloquent Speaker).
” (The Most Eloquent Speaker).
Disambiguation pages Different entities might have a common title, such as people with the same name. For each ambiguous term, there is a disambiguation page that specifies all entities that might refer to it. Disambiguations and redirects of Wikipedia are specifically helpful for accurate entity resolution in other extractors.
Categories Each Wikipedia article has one or more categories, e.g. “Saadi Shirazi” belongs to several categories such as “Persian poets of the 13th century” and “Persian Poets”. Despite the fact that categories have some sort of hierarchy, e.g. might have sub-categories, the categories are not well-structured and can be treated as a set of tags assigned by different people to each entity. Nevertheless, data analytic applications such as related-entity recommendation or KG search can leverage these labels. Moreover, various enhancements can be applied to improve the quality of category labels [83].
Images The images of entities can be used for constructing the image-based FarsBase. The details of such a system do not fall in the scope of this paper.
Inter-language and inter-KG links Articles belonging to the same entity in different languages are linked to each other in Wikipedia. Also, other knowledge graphs and ontologies might have links to Wikipedia articles. Entity linking is further done in the mapping stage to integrate all records from different sources that belong to the same entity.
Tables
Information extraction from tables is a challenging task, specifically because the schema of Web tables is very flexible. Indeed, Web tables are primarily designed for viewing purposes, not to store a collection of data, such that many tables have split and merged cells. In most long tables, the subjects of the underlying triples are in a specific column of the table, albeit the subjects might also be in a specific row. More importantly, it is not trivial to recognize if a table contains significant information to be extracted. Despite these challenges, some research has been done to automatically extract entities or triples from tables [12,43,90].
Raw text
The Raw Text Extractor (RTE) extract triples from unstructured text based on the current knowledge of the KG. Even though FarsBase’s RTE engine shares some aspects with never-ending learning (NELL), it is primarily designed to supplement the KB with information that is missing from Wikipedia. The triples supplied by the RTE should be almost of the same accuracy as the information extracted from Wikipedia, in order not to degrade the quality of the KG for semantic search. Therefore, RTE mostly adopts methods that maintain a high-precision, such as rule-based approaches, even though it can sacrifice the recall. Note that while all triples extracted by RTE are verified by the experts, evaluating highly-accurate results requires much less effort because the triples can be grouped and verified in batches.
In the following, we briefly describe the preprocessing steps for raw text extraction. we then describe our entity linking system that detects the entities from the text, followed by the four RTE modules that extract triples from the raw text. FarsBase has four modules for raw-text triple extraction, namely rule-based extraction, distant supervision, dependency patterns, and unsupervised extraction.
Preprocessing
Before extracting the triples from the raw text, some preprocessing steps must be applied on the text, including sentence boundary detection, word tokenization, part of speech (POS) tagging, base phrase chunking, dependency parsing, co-reference resolution, and entity linking.
Even for the basic NLP tasks, such as NER, the available tools for Persian are not mature enough [19,51,55]. The errors of the Persian NLP tools are propagated through the triple extraction process, which can result in poor extraction quality.
While English RTE engines enjoy numerous tools for text preprocessing, FarsBase can only use the very few tools available for Persian, and in some cases, we developed our own tools specifically built for RTE. For example, there are no high-precision co-reference resolution and entity linking modules for Persian, so we developed these libraries with only the required functionalities for RTE. Moreover, a base phrase chunker (BPC) could be very useful for relation extraction, but there is no reliable library for BPC in Persian, thus we did not use BPC for preprocessing the RTE input. For other preprocessing tasks, we used the JHazm2
Pronoun resolution As shown in Table 2, co-reference resolution increases the recall of triple extraction up to 46%. To have a basic co-reference resolution, we used a baseline algorithm for pronoun resolution [54]. In our baseline, for each pronoun in the text, we choose the closest entity that is before the pronoun as the co-reference.
To detect the gender of person entities, we used a gazetteer (originally developed for a named entity recognizer) that contains a list of male and female first names in Persian, Arabic, Turkish, English and French languages.3
The first step for extracting triples from raw text is to detect the entities. This enables the RTE modules to extract relations between the detected entities. Entity linking is the task of linking the entities mentioned in the raw text to their corresponding KG URIs. It is a very essential task for triple extraction because the subject of a triple must be linked to an entity URI. Once the URI of an entity in the text is known, we can leverage its type (ontology class) for further post-processing and filtering.
Entity linking in RTE uses the resource extractor module, which finds the links of all resources in a given input text. More specifically, the entity linker identifies the entities, categories and ontology predicates in the text, based on the known labels in the KG. Each resource may have more than one label, and a single word in the text may be shared between more than one resource.
The resource extractor does not perform any disambiguation analysis and merely finds the labels of all candidate resources. For example, a phrase may be linked to more than one entity, or even some verbs and adverbs may be mistakenly detected as entities. This is mainly because the modules that use the resource extractor, such as the search system and RTE, have different requirements and thresholds for disambiguation.
RTE has a separate module, named entity linker, which takes as input the extracted URIs and disambiguates the entities in the sentence, such that each word is linked to one and only one entity. The entity linker removes other types of resources including the predicate and category links. The entity linker uses the following heuristics for disambiguation:
Filtering by POS tags The POS tag of each entity is determined by the POS tagger. If a link contains just one word with certain POS tags, it is eliminated. The set of POS tags consists of P, Pe, CONJ, POSTP, PUNC, DET, NUM, V, PRO, and ADV. Labels of many entities in FarsBase are homographs with verbs or prepositions, e.g. “ ” can refer to a village (
” can refer to a village ( ) or it can be the present continuous form of the verb “Go”. Similarly, “
) or it can be the present continuous form of the verb “Go”. Similarly, “  ” can refer to a preposition or a fruit (
” can refer to a preposition or a fruit (  ).
).
Handling homographs Homographs are words that are written the same but have different meanings. For example, even though the word “very” is a common modifier in English, in a few portions of texts it may refer to other entities such as the “Very” company. State-of-the-art NLP methods are still not very reliable for disambiguating such rare homographs [44]. Therefore, specific and rare entities are ignored using a manually-created list.
Class-specific filters Some entities have a very generic name that may cause a high level of ambiguity for RTE. For instance, “ ” (“At the age of 40”) is a famous Persian movie, although it can be a part of a sentence, e.g. “Alex died at the age of 40”. Such entities are very common in special classes, like movies (movie names), books, and artworks. To alleviate the ambiguity issue, if the detected entity belongs to certain classes, such as Movies, we look for more evidence in the surrounding context using a reference list. For example, if a sentence contains “At the age of 40” (as a movie name), we require that the surrounding context also contains phrases such as “movie”, “channel”, “video”, etc.; otherwise, the linking is ignored.
” (“At the age of 40”) is a famous Persian movie, although it can be a part of a sentence, e.g. “Alex died at the age of 40”. Such entities are very common in special classes, like movies (movie names), books, and artworks. To alleviate the ambiguity issue, if the detected entity belongs to certain classes, such as Movies, we look for more evidence in the surrounding context using a reference list. For example, if a sentence contains “At the age of 40” (as a movie name), we require that the surrounding context also contains phrases such as “movie”, “channel”, “video”, etc.; otherwise, the linking is ignored.
Context-based disambiguation This type of disambiguation is based on the context of the words. If a word is linked to more than one entity, its context is compared with the body of the corresponding Wikipedia articles of each entity. The cosine similarity between the context of the word and the body of the Wikipedia article is used as the measure to sort the entities.
Graph-based disambiguation This heuristic leverages the hyperlinks between the Wikipedia articles. If a word is linked to more than one entity, we consider the Wikipedia pages of the entities and score the ambiguous entities based on the number of hyperlinks between each entity and the Wikipedia pages of the surrounding words.
Combining graph- and context-based disambiguations We use the weighted sum approach to combine our graph- and context-based disambiguation heuristics. The score of each ambiguous entity is computed as
The precision of FarsBase entity linker, evaluated by human experts on 30000 words, was 67.8%.
Rule-based RTE
The rule-based RTE is a high-confidence extractor, which is based on Stanford TokensRegex4
 (capital)” followed by an entity of type “Country” (say
(capital)” followed by an entity of type “Country” (say  (city)” and another entity of type “Settlement” (say
(city)” and another entity of type “Settlement” (say 
Distant supervision is a semi-supervised approach for information extraction from raw-text [5,50]. It is based on the intuition that the facts in the knowledge graph already have instances mentioned in the raw text sources. By aligning known facts, i.e. triples, with the corresponding sentences, we can automatically create a training set, so that a classifier can be trained to extract more facts with similar patterns from the raw text.
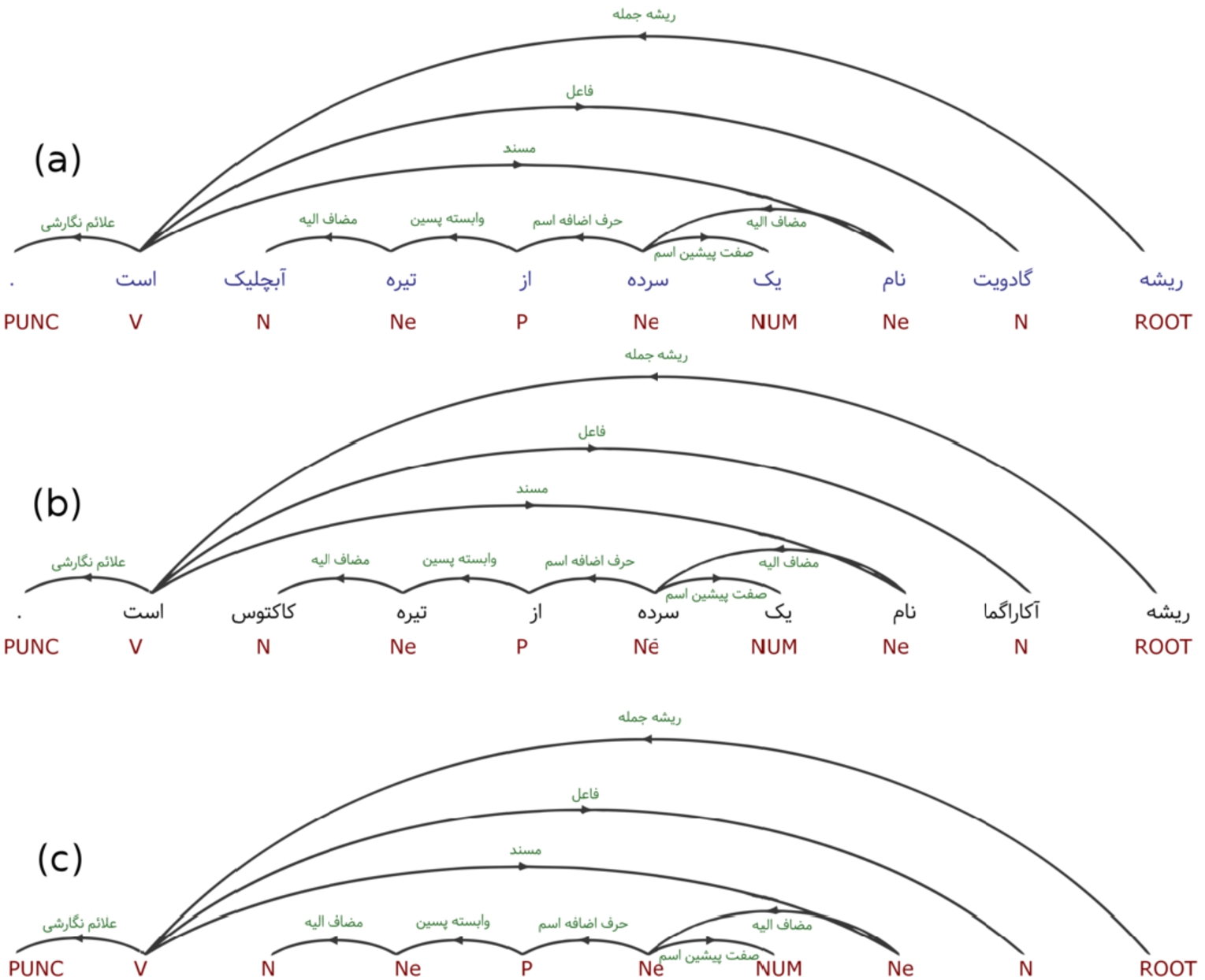
Two sentences (a, b) with the same dependency pattern (c).
Inspired by Aprosio et al. [5], we developed a training dataset by automatically aligning FarsBase known facts with Persian Wikipedia’s text. Out of 2.5 Million sentences from Persian Wikipedia articles, 172,368 sentences were mapped to the facts in FarsBase. The mapped sentences were evaluated by human experts, and 16,745 sentences were verified and added to the RTE engine. To improve the accuracy, we added a number of negative examples, i.e. sentences without any relationship between their entities.
We used LibSVM5
The precision of the classifier was 54% on the gold data. To increase the precision, we used a type-checking algorithm, which eliminates triples that are not compliant with the domain and range constraints of their predicates. For example, the subject of a nationalTeam must be a Person, and its object must be a Team. Therefore, if the extracted rule is “Iran nationalTeam Africa”, it is eliminated due to in compliance with the domain constraints. Using this module, we extracted 203441 triples (confidence > 0.9) from Wikipedia articles.
Dependency patterns is a novel method for RTE which attempts to extract triples using “unique dependence trees”. By definition, two dependency parse trees have the same dependency pattern if replacing each word with its corresponding POS tag, generates two identical trees. Figure 2 shows two sentences with the same dependency pattern.
Triple extraction with dependency patterns is based on the intuition that if a sentence contains a triple, other sentences with the same structure also contain similar triples. In such cases, the subject, object, and predicate can be extracted from the words with the same position indexes in all sentences.
Note that the triples extracted by this method are not linked to the entities. Instead, a mapping module must link the subject and predicate to the KG resources.
RTE with dependency patterns is a supervised method, and human experts must define the position of the subject, predicate, and object in the sentences. Currently, 2000 most frequent dependency patterns are extracted automatically from Wikipedia texts and are annotated by the experts. Using these patterns, we extracted 240320 triples from Wikipedia articles.
Unsupervised RTE
We introduce an unsupervised method for triple extraction, which is based on dependency parsing and constituency tree. Unfortunately, there are no accurate libraries for constituency parsing in Persian. Our unsupervised method takes the main phrases of a sentence as input and uses the dependency parse tree to detect the main phrases. Using this module, we extracted 178240 triples (confidence > 0.9) from Wikipedia articles.

The dependency parse tree and main phrases of a sample Persian sentence.
We explain our unsupervised RTE by an example. Consider the sentence shown in Fig. 3. Given the dependency parse tree and the constituency tree, consider the following definitions:
Verb Phrase (VP): A phrase that contains at least one verb.
Ignored Phrase (IP): A phrase in which the head of the phrase is not connected to the verb in the dependency parse tree. IPs are not to be involved in the extraction process.
Linked Phrase (LP): A phrase that all of its words are linked to one and only one entity.
Candidate Phrase (CP): A phrase that includes at least one verb or noun. Phrases that do not include any name or verb is not be ignored in triple extraction.
In our unsupervised RTE, triples are extracted based on the following criteria:
Sentences with no VP are ignored.
If the sentence has one VP and two LPs, the triple (
If the sentence has one VP, one LP and more than one CPs (
The precision of our unsupervised RTE is 67%, evaluated in 600 sentences. To facilitate the verification by human experts, we assign confidence values to each of the extracted triples with a method similar to [25].
The triples are extracted from multiple heterogeneous sources. As a result, semantically equivalent predicates may be extracted in different lexical forms. For example, “ ”, “place of birth” and “birthplace” have the same meaning but are extracted from different sources. Therefore, it is essential to have a homogenization process on the predicates to map the equivalent lexical forms into a common IRI. Mapping is originally suggested by DBpedia [39] to map Wikipedia infoboxes to the ontology classes and properties.
”, “place of birth” and “birthplace” have the same meaning but are extracted from different sources. Therefore, it is essential to have a homogenization process on the predicates to map the equivalent lexical forms into a common IRI. Mapping is originally suggested by DBpedia [39] to map Wikipedia infoboxes to the ontology classes and properties.
Mapping Wikipedia infoboxes
Wikipedia infoboxes contain predicates in different syntactic shapes and different languages. While DBpedia uses a markup language for mapping, FarsBases uses mapping tables which are easier to maintain by the human experts. In the following, we describe the two approaches.
The DBpedia approach
Lehmann et al. [40] proposed an approach to map Wikipedia infobox data to the triples based on a markup language that specifies the mapping. DBpedia mappings consist of 1. the mapping of infoboxes to the ontology classes and 2. the mapping of the attributes in the infoboxes to the ontology predicates.6
New classes added to the original DBpedia ontology based on Persian language and culture
Mapping tables The main difference between FarsBase and DBpedia approaches is on their mapping representation. While the markup language in DBpedia is more flexible than the table-based scheme in FarsBase, we observed that it is hard for the human experts to define, read and maintain the markup entries. More importantly, working with markups takes more time and drastically increases the cost of KG construction. FarsBase provides a user interface that is more friendly to the experts who are not familiar with markup languages.
Mapping suggestion In Persian Wikipedia, some of the infobox types and their attributes are written in English but are displayed in Persian in the user interface. Since the English types and attributes are mostly found in the DBpedia mappings, we transfer these mappings to the FarsBase mapping tables. For those types and attributes that are written in Persian, we use machine translation. By looking at the Persian attributes, the system automatically translates them into English and looks for their equivalence in English DBpedia. Finally, human experts need to confirm the suggested mappings. Therefore, this process is semi-automatic.
Transformers FarsBase uses a novel technique called the transformer functions to map complex strings in infobox attributes to multiple pairs of values and RDF types. Transformer functions automate data cleansing and normalization and require minimal effort by the experts. The technique is described in Section 6.2.
Mapping for raw text extraction We propose an ontology-aware method for mapping RTE triples in Section 6.3. In this method, the mapping entries that are originated from Wikipedia infoboxes are also used to map RTE-generated triples.
Ontology construction
Ontology is one of the most important parts of any knowledge graph. In FarsBase, each entity is an instance of one of the classes. The FarsBase ontology is a tree of the classes, each of which has only one parent.
For Example 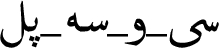 (Si-o-se-pol) is a Bridge, ArchitecturalStructure, Infrastructure, RouteOfTransportation, Place and Thing. The main class of each entity (i.e. the deepest class in the tree) is defined by an fbo:instanceOf predicate.
(Si-o-se-pol) is a Bridge, ArchitecturalStructure, Infrastructure, RouteOfTransportation, Place and Thing. The main class of each entity (i.e. the deepest class in the tree) is defined by an fbo:instanceOf predicate.

Note that fbr is the prefix for the “

The ontology of FarsBase consists of 767 classes. The main body of the ontology is derived from DBpedia. Classes with no entities in Persian Wikipedia, most of which are not extensively used in Persian language and culture, are removed from the ontology. Also, some new classes were found in Persian Wikipedia, which is added to the ontology. The new classes are listed in Table 4.
Mapping rules for Wikipedia templates
Mapping rules for Wikipedia templates
Experts added some valuable information to this ontology, e.g. different labels for classes, predicates, ranges, and domains. FarsBase automatically estimates the range and domain of each property and stores them in the KG as triples of type fbo:autoRange and fbo:autoDomain.
In Wikipedia templates and infoboxes, the values are written in different formats. Interpreting each format requires implementing a small logic. Consider the following examples:
If the infobox type of an article is “Iranian village”, the type of entity is fbo:Village. Moreover, it can be concluded from the infobox type that the village is located in fbr:Iran.
If the value of “years of activity” in infobox is “1357–1366”, this string value should be parsed and converted to two numerical values as the start and end years of the activity.
If the area_km2 value in an infobox is “1897”, the string value should be parsed as a number, and the property is “area”. Also, the unit should be set as a square kilometre (
The ”lat“ (latitude) value for geographical entities can be either in degrees-minutes-seconds format (e.g. 35 41′ 36″) or in numerical signed degrees format like 35.69333333. We have to unify the formats.
To efficiently handle the logic required to handle the values, the experts create a table containing the mapping rules for each template. Each row in the mapping rules table (Table 5) is a rule that defines what should be done for each of the attributes of a template. For example, a mapping table for the template “a city of Iran” is defined in Table 5.
As an example, suppose that the mapper is given all triples extracted from an article with “a city in the Iran” template. The rules with empty attribute fields are executed at first. Therefore, two triples are generated for type (fbo:City) and location (fbr:Iran). Note that a rule with an empty attribute must have a constant value. In the next step, the mapper checks the infobox attribute in all triples and looks for the corresponding rule in the mapping rules table. For example, if the infobox attribute is “mayor”, it is mapped to “fbo:mayor”. Also, wheat_production matches with two rules in the rule set. As a result, several triples corresponding to such attribute are generated.
The transformer functions are defined to handle complex value types. The input of a transformer is a string, and the output can be a string, a numerical value, or a date. For example, the minMaxRangeToMin function receives an interval string (minimum and maximum) and returns the minimum value (Input: “12–13”, output: 12). Similarly, the latLong function receives a string corresponding to latitude or longitude, detects its format, and generates a decimal value in signed degrees format (Input: “35 41′ 36″”, output: 35.69333333).
For some attributes in Wikipedia infoboxes, FarsBase maps the attribute to NULL, meaning that the key will be ignored in the mapping phase and its information will not be stored in the knowledge graph. For example, the size of an image in a Wikipedia article is not valuable and is ignored.
Storing mapping data in the rule sets makes it easier to represent and maintain the mapping system. Manipulating the mapping rules is easy for the experts and provides enough flexibility to handle all complicated cases.
Mapping triples from raw texts
The Wikipedia mapping system discussed in 6.1 is only applicable to Wikipedia infoboxes. However, if we identify the IRI of the entities, we can also apply the mapping rules on triples extracted from raw text. The module that identifies the entities from the triples generated by RTE and TBE is described in Section 5.3.2.
Obviously, identifying the entities and predicates is very challenging due to the ambiguities in triple extraction. To overcome this problem, if the entity has an infobox in Wikipedia, the extracted predicate is matched with an attribute in the infobox according to the mappings of that template. If the attribute is found in the infobox, the triple is mapped according to the Wikipedia mapping. Otherwise, we look for any rules in the mapping-rule tables of all templates that contain the extracted predicate.
To ensure that the information extracted from raw-text have an adequate quality, all RTE-generated triples must be approved by experts before they can be stored in the Belief-Store.
Integration
Once the triples are extracted, they need to be integrated with the KG. This requires different post-processing steps in the integration phase, including the following tasks:
Mapping Wikipedia infoboxes to the ontology (discussed in Section 6)
Handling N-ary relations
Versioning and updating the KG
Human supervision, used for batch verification of the candidate triples
Linking entities to external datasets
Our integration system is designed such that it can be continuously updated to handle very recent informational queries in the search engine. Moreover, it uses several heuristics for low-cost (batch) verification of the triples in which we have low confidence.
In this section, we explain the mapping process and our initial mapping phase for data triples. Then we show how FarsBase integrates mapped data from multiple sources, how candidate facts are updated and in which process they are promoted to the beliefs.
N-ary relations
Most knowledge graphs, FarsBase included, represent data in subject-predicate-object (SPO) format defined by the RDF model. This representation is suitable for relations involving two entities, but it is not straightforward to represent n-ary relations in the SPO format.
Wikipedia infoboxes support n-ary relations by defining an order for attribute-values. Figure 4 shows a sample of n-ary relations in the Wikipedia infobox of a football player. In such cases, all related attributes end by a digit, e.g. years4, caps4, and goals4. Rouces et al. [76] reviewed some modeling patterns for the representation of n-ary relations: The basic-triple pattern, triple-reification, singleton-property pattern, specific-role-neo-davidsonia, general-role-neo-davidsonian and Role-class pattern. FarsBase uses triple-reification for handling n-ary relations. For the infobox shown in Fig. 4, a sample of the extracted triples is as follows:

Note that 

N-ary relations in a Wikipedia infoboxe.
The Mapper system stores all the data generated by the various extraction modules in the CFM-Store. The update system is triggered whenever a new set of triples is generated, either by WKE, RTE or TBE. In each update, the generated files, along with general extraction information (start and end time of the extraction and the extractor module), are stored in the system. The Mapper continuously traverses the arriving updates in short intervals and runs the mapping process. Note that some of the mapped triples might need to be validated before transferring to the final data. The Update Handler transfers the mapped triples to the final repository when the data is validated by experts, or when their confidence is above a pre-defined threshold.
Triples that no longer exist in a new Wikipedia dump is deleted from the final data (Belief-Store). FarsBase stores the version number along with the triples so that it can handle the changes in the values of the triples. After finding new triples from a module, the mapper uses a version number generated by the CFM-Store and stores all triples with the assigned version to the CFM-Store. The final (validated) data is stored in Belief Store in specific periods (currently every 24 hours).
Human supervision
Automatic approaches for knowledge graph construction, such as NELL [52], have recently reached considerably high accuracy, but to construct a high-quality KG, NELL uses crowdsourcing to verify the extracted facts. Therefore, human supervision is still essential to ensure the correctness, consistency, and completeness of the data.
In FarsBase, Human experts are used in four tasks: triple approval, ontology construction, mapping, and evaluation (e.g. to create gold data for evaluating the distant supervision module).
Triples with the confident higher than a threshold are automatically transferred to the Belief-Store. Other triples must be verified by a majority vote of three experts.
Since FarsBase is used in a search engine, the cost of a wrong triple is proportional to its popularity in user queries, i.e. its frequency in the user query logs. To minimize this cost, entities are prioritized by their expected query frequency, which is estimated by a probabilistic model.
Frequency of entities in each classes
Frequency of entities in each classes
Frequency of triples in each classes
DBpedia is already linked to 36 other datasets. Therefore, we can easily link FarsBase to other datasets if we correctly match the FarsBase entities with DBpedia. Most Persian Wikipedia articles have inter-language links with an English article, and the majority of English articles are mapped to DBpedia. By following the connections, FarsBase is connected to DBpedia using the owl:sameAs predicate. 439,445 of FarsBase entities have at least one link to external datasets. FarsBase totally has 5,582,589 links to external datasets.
Evaluation and statistics
We evaluated FarsBase from different aspects, including the size, precision, mapping quality, coverage, and freshness (timeliness), and the number of links to other datasets.
Size
Tables 6 and 7 show the frequencies of entities and triples for the most frequent classes in FarsBase. The Settlement and Village classes contain the largest number of entities (69317 and 49512).
The frequency of entities and triples of the first level of the ontology
The frequency of entities and triples of the first level of the ontology
In general, more than 190,000 entities are instances of the Place class. The frequency of entities and triples of the first level of the ontology are shown in Table 8.
There are 1712 unique templates in Persian Wikipedia, out of which 683 templates are mapped to FarsBase ontology classes. Also, Persian Wikipedia infoboxes have 25032 unique attributes, and 7808 attributes are mapped to the FarsBase ontology. Table 9, illustrates the number of mapped templates, attributes, and Wikipedia infobox triples. While we have only mapped 40% of the templates and 31% of the attributes, the mapping covers 90% of the triples because the unmapped templates and frequencies have a quite lower frequency in the triples.
Coverage of entities
We adopted several measures to evaluate the coverage of entities in FarsBase. The coverage is evaluated using two test sets: Wikipedia articles, entities from a gazetteer, and the information need of search engine based on a query log.
Gazetteer named entities We aim to measure how much of the named entities that appear in raw texts are available in FarsBase. We used three gazetteers for named entity recognizer (NER) in Persian developed by Iran Telecommunication Research Center (ITRC). We measured how many of the gazetteer entities are available in FarsBase. Table 10 shows the results for the person, location and organization classes. Results show that FarsBase has a wider coverage for famous persons compared to other named entities.
Query log entities When a KG is used for semantic search, entities that appear in frequent queries are more important. We used 321 popular queries from a search engine log. Human experts chose the main query for each entity and checked whether the entity exists in FarsBase. FarsBase covered 91.85% of the frequent entities.
Statistics about mapped templates, attributes and triples
Statistics about mapped templates, attributes and triples
Coverage of the gazetteer named entities
Application-specific coverage The search system and its evaluation is beyond the scope of this paper. Nonetheless, it is important how FarsBase covers the triples that are required to answer KG-based semantic queries. Evaluating application-specific triple coverage is very challenging because it depends on the application (KG search engine) on how many triples it needs to have for answering to each query. For example, consider the query  (“Bridges in Isfahan”). For any of the results of this query, such as the Si-o-se-pol bridge, at least two triples must be available in the KG so that the result can be retrieved, namely “result rdf:type fbo:Bridge” and “result fbo:locatedInArea Isfahan”. From the application’s perspective, if any of the two triples are not in the KG, the cost is the same as not having both of the triples. Therefore, we use an evaluation measure in the application’s domain, such as precision, which indirectly measures the triple coverage.
(“Bridges in Isfahan”). For any of the results of this query, such as the Si-o-se-pol bridge, at least two triples must be available in the KG so that the result can be retrieved, namely “result rdf:type fbo:Bridge” and “result fbo:locatedInArea Isfahan”. From the application’s perspective, if any of the two triples are not in the KG, the cost is the same as not having both of the triples. Therefore, we use an evaluation measure in the application’s domain, such as precision, which indirectly measures the triple coverage.
Eliminating application-specific errors To have a precise estimate of the triple coverage, we try to eliminate the aspects of the application (i.e. semantic search engine) that are irrelevant to triple coverage. A KG-based semantic search engine can fail to retrieve a result for four reasons:
The query is not KG-compatible, e.g. “What to do in case of fire?”
The query is not supported by the KG. Note that semantic search engines, like Google knowledge graph, do not try to support all KG-compatible queries because this reduces the precision. Similarly, the FarsBase query engine only answers a query if it matches one of the pre-defined query templates.
The query is not correctly understood by the engine, e.g. it fails to detect entities from the query or to disambiguate the detected entities.
Any of the triples required to retrieve the result are not in the KG or are wrong.
To measure the application-specific triple coverage, we have to eliminate the effect of the first three issues. Therefore, the experts carefully revised the query set and chose the KG-compatible queries that are already supported and processed correctly by the query engine.
Query set Three experts evaluated the responses by the semantic search module for each query.
The query set is built from three different sources:
Expert queries: 62 queries were proposed by three experts.
Search engine log: 63 queries were selected randomly from the end user query log. If the answer of a query was not in the knowledge graph (checked by human experts), the query was replaced by another query.
Class-centric queries: 253 queries were selected based on the ontology class of the main entity that appears in the query. For example, in “Bridges in Isfahan”, the main entity is “Isfahan” and it belongs to the fbo:City class. These queries were constructed automatically from the triples of each entity.
R-precision for different query sets
R-precision for different query sets
Results We used r-precision to measure the application-specific triple coverage. For each query, r-precision is the number of correct results among the first R results, where R is the number of relevant results. For examples, since there are 6 bridges in Isfahan, if the query engine returns only 5 correct results, its r-precision is
Freshness measures the effectiveness of the update process. To evaluate the freshness of data in FarsBase, a list of famous recent events was collected in a time interval. The list was extracted automatically from “Portal:Current_events” and “Deaths_in_2018” pages in Wikipedia. After checking 100 entities from the list, all the entities and 91.02% of their attributes existed in FarsBase.
Linked data
A total of 558,2589 FarsBase resources has been linked to 33 external datasets. In total, 439,445 of the 541,927 FarsBase entities (81.09%) were connected to at least one other datasets. Table 12 shows the number of links to each of the linked datasets.
Datasets linked to FarsBase
Datasets linked to FarsBase
Knowledge graph construction
FreeBase Developed by Metaweb, Freebase was a publicly available knowledge graph launched in early 2007. It contained more than 125,000,000 tuples, 4,000+ types, and 7,000+ properties [14]. Freebase data was harvested from multiple sources including Wikipedia and was available using Metaweb Query Language (MQL).
YAGO Suchanek et al. [82] presented YAGO as a lightweight, high-quality and extensible ontology.
YAGO combined Wikipedia infoboxes and WordNet taxonomic relations using several heuristics and a quality control system. Facts are extracted by applying different heuristics on infoboxes, types, words, and categories. YAGO2 added temporal and spatial aspects to the knowledge graph. To provide geographical information, YAGO2 included the GeoNames database [34] YAGO3 is built using multilingual information extraction techniques and supports 10 languages [47,71].
DBpedia DBpedia converted Wikipedia contents into a large multi-domain RDF dataset. It is interlinked to other open data sources including FOAF, GeoNames, Dublin Core Berlin, World Factbook, and Music Brainz. The DBpedia community also developed a series of modules which makes DBpedia accessible via Web services [6]. DBpedia has been further developed into a multilingual knowledge graph and aims to completely support all languages in Wikipedia. The DBpedia extraction framework contains four extraction modules: Mapping-Based Infobox Extraction, Raw Infobox Extraction, Feature (e.g. geographic coordinates) Extraction, Statistical Extraction. Using the mapping-based infobox extraction system [39,49].
BabelNet BabelNet integrated lexicographic and encyclopedic knowledge across multiple languages and presented a lightweight method to map Wikipedia articles to WordNet senses. For resource-poor languages, they used human-edited and statistical machine translations of Wikipedia articles in the other languages. BabelNet also integrated a multilingual word-sense disambiguation system with its knowledge graph [61].
Wikidata The goal of Wikidata (Wikipedia for data) is managing the factual information of Wikipedia. Wikidata uses facts instead of triples and users enter facts directly to the database. Each entity has an ID (not a URI). There is no extraction process on Wikidata and each fact is entered by the users. Each entity has multiple “statements” instead of “triples”. Each statement has one or more references and one claim [36,88].
Other knowledge graphs Wang et al. [89] proposed an automatic knowledge graph construction using statistical text over database systems (MADDEN), deductive reasoning system (PROBKB) and human feedback (CAMEL).
Knowledge Vault introduces a probabilistic knowledge graph that mixes information extraction from Web content with prior knowledge derived from existing KGs. This knowledge graph uses a supervised machine learning method to fuse these information sources. Knowledge Vault has three main components: triple extractors (text documents, HTML trees, HTML tables, and Human annotated pages). Graph-based priors, and knowledge fusion. Triple extractors may extract unreliable and noisy knowledge. Prior knowledge is used to reduce the noise from the extracted data [23].
DeepDive cleans and integrates data from multiple sources like text documents, PDFs and structured databases. Statistical inference and machine learning is used to extract tuples and defines a probability score for each of tuple [31,91].
Nguyen et al. [62] argued that most of the knowledge graphs are not extracted based on the information needs of the end users and fail to cover many relevant predicates. They suggested QKBfly, an approach to construct an on-the-fly knowledge graph from user’s queries a question answering system.
FrameBase [76] proposed a KG schema which uses FrameNet [10] to store and query n-ary relations (facts with more than two entities or literals) from heterogeneous sources which combine efficiency and expressiveness. The article investigated different triple representations for n-ary relations and used NLP frames to handle these relations on other knowledge graphs.
Comparative survey Farber et al. defined 35 aspects in seven categories, including general information, format and representation, genesis and usage, entities, relations, schema, and particularities. for a comparative study on knowledge graphs, they provide a thorough comparison of these aspects in DBpedia, Freebase, OpenCyc, Wikidata, and YAGO [29].
KG construction for other low-resource languages Persian is originated from the ancient Middle-Persian language and has an extensive vocabulary derived from the Classic Arabic language. Persian and Arabic come from different roots (i.e., Indo-European and Semitic), but the Persian script is an adaption of Arabic script with a few modifications.
Currently, DBpedia has an Arabic chapter7
Paulheim et al. [65] provided a survey on knowledge graph refinement approaches (completion vs. error detection, the target of refinement, and internal vs. external methods) and evaluation methodologies (partial gold standards, knowledge graph as silver standards, retrospective evaluation, and computational performance). They evaluated Cyc [41] and OpenCyc, Freebase, DBpedia, YAGO, NELL and Knowledge Vault. They also presented some statistics about Wikidata, Google’s Knowledge Graph, Yahoo!’s Knowledge Graph [13], Microsoft’s Satori and Facebook Entity Graph.
Färber et al. proposed 34 metrics for knowledge graph quality assessments and analyzed on the DBpedia, Freebase, OpenCyc, Wikidata, and YAGO [28]. The metrics categorized on Intrinsic (accuracy, trustworthiness, and consistency), Contextual (relevancy, completeness, timeliness), Representational Data Quality (ease of understanding and interoperability) and Accessibility (accessibility, license, interlinking) metrics.
Rashid et al. [69] also proposed 4 quality assessments (Persistency, Historical Persistency, Consistency, and Completeness) and assessed these metrics on 11 release of DBpedia and 8 release of 3cixty [74].
Mapping
Dimou, et al. [21] proposed a uniform assessment approach using the RML (a mapping language) and RDFUnit (a test-driven approach for every vocabulary, ontology or dataset). They also applied this validation on DBpedia [20].
Ahmeti, et al. [2] proposed using the DBpedia mapping infrastructure to enhance Wikipedia content using an Ontology-Based Data Management (OBDM) approach, for example, using conflict resolution policies to ensure the consistency of updates on Wikipedia infoboxes.
Relation extraction from raw texts
Entity extraction and entity linking Many researchers have worked on triple and relation extraction from raw texts. In knowledge graph construction, we have to use triple extraction and each entity must be linked to our knowledge graph. Thus entity linking is an essential task in triple extraction.
Han et al. [32] introduced collective entity linking which works based on jointing name mentions in the same document by a representation called Referent Graph.
Exner et al. [26 ,27] proposed an entity extraction pipeline which includes a semantic parser and coreference resolver and worked based on coreference chains. This approach extracted more than 1 million triples from 114000 Wikipedia articles. Oramas et al. [64] presented a rule-based approach for extracting knowledge from the songfacts.com website. The extraction pipeline includes Babelfy [56] as a state-of-the-art entity linker with the highest precision on musical entities. Nguyen et al. [63] presented J-REED as a joint approach for entity linking based on graphical models.
Finally, Röder et al. [75] proposed a GERBIL including an evaluation algorithm for entity linking to compare two entity URIs without being bound to a specific knowledge graph.
Triple and relation extraction Bach et al. [8] presented a review on the most important supervised and semi-supervised relation extraction prior to 2007. Kasneci et al. [37] proposed YAGO NAGA which extracts candidate facts from raw text and integrates them to YAGO. NAGA also employs a consistency checking approach to control the quality of generated facts. Wanderlust [3] is an approach to extract semantic relations from raw texts unsupervised dependency grammar approach.
Nakashole [60] presented automatic extraction of a web-scale knowledge graph. He proposed a robust method to extract high-quality facts from noisy text sources. He also proposed a method to handle new entities in dynamic web sources.
TokenRegex [16] which was proposed by Stanford Natural Language Processing Group, facilitate rule-based approaches for relation extraction by implementing a framework for cascading regular expressions over sequences of tokens. Madaan et al. [46] proposed a relation extractor for numerical data (e.g. atomic number like “Aluminium, 13” or inflation rate like “India, 10.9%”) which tries to handle units with minimal human supervision.
Presutti et al. [66] proposed Legalo, an unsupervised open-domain knowledge extractor. Legalo is based on the hypothesis that hyperlinks between two entities provide semantic relations between them.
Speer et al. [80] proposed ConceptNet, a knowledge graph extracted from many sources including Open Mind Common Sense (OMCS) [79], Wiktionary, purposeful games, WordNet, JMDict [15] (a Japanese-multilingual dictionary), OpenCyc, and a subset of DBpedia.
Vo et al. [87] described the second generation of OIE which is able to extract relations between Noun and Pre, Verb and Prep using deep linguistic analysis. Stanovsky et al. [81] presented a supervised sequence tagging approach to OIE which is aimed by Semantic Role Labeling models. To provide training data, they automatically converted a question answering dataset to an open IE corpus.
Distant supervision Distant supervision (DS) was first introduced by Mintz et al. [50]. They examined DS on Freebase and the model extracted 10,000 instances and 102 relations with a precision of 67.6%. Aprosio et al. [5] used DS for extracting missing values from Wikipedia articles to enrich the DBpedia knowledge graph. Augenstein et al. [7] use DS on Web sources with data sparsity, noise, and lexical ambiguity. To handle such data, they used an entity recognition tool and an unsupervised co-reference resolver. They also presented several methods for information integration to aggregate extracted knowledge to the main KG. Heist et al. [33] proposed a language-independent approach based on distant supervision and extracted 1.6 million triples with 95% precision from the abstract of 21 Wikipedia language editions.
Knowledge graph augmentation
FACT EXTRACTOR [30] is an n-ary relation extractor which uses FrameNet and populates the KG with supervised NLP layers and tried to reduce the supervision costs by crowdsourcing. Chen et al. [17] proposed a parallel first-order rule mining method (Path-finding algorithm) and a pruning system to augment Freebase and mined 36625 rules and 0.9 billion new facts from Freebase.
Using web tables for knowledge augmentation
Limaye et al. [43] proposed machine learning techniques to find entities and type of entities in Web tables and extract relation type from the tables.
InfoGather [90] is an entity augmentation which works on entity-attribute tables. This information gathering system works based on three core operations: Augmentation by attribute name, Augmentation by example, and Attribute discovery. InfoGather crawls, extracts and identifies relational tables from the Web and builds a table graph from them.
TabEL [12] is an entity linking tool specially designed for Web tables. Assuming that a set of entities or relations in a table are in a particular type, TabEL assigns higher likelihood to entities with a higher co-occurrence in Wikipedia articles.
Ritze et al. worked on Web table matching to find missing triples on the knowledge graphs. They proposed T2K Match framework [72] to match triples in Web Tables Corpus (147 million tables) with a knowledge graph, and used this matching tables to augment DBpedia as a cross-domain knowledge graph [73].
Conclusion and future work
In this paper, We presented FarsBase, a multi-source knowledge graph that is specifically designed to provide linked data for answering semantic queries in Persian search engines. It leverages multiple engines for extracting knowledge from different types of data sources such as Wikipedia, Web-tables and unstructured texts. The extracted triples are then mapped to the ontology and integrated with the main Belief-Store. We adopted two policies for designing FarsBase. First, the extracted information should be up-to-date to cover queries about recent facts, hence FarsBase several different heuristics to automate the updates. Second, the triples must have enough accuracy to prevent returning wrong results, specifically for the frequent queries in semantic search engine. This is addressed by leveraging the query log and various cost models. Our approach also helps to maintain an affordable cost for human supervision, e.g. using rule-based methods for information extraction, and batch-verification of triples by human experts.
We identified several ideas for improving FarsBase. Future work includes the following:
Linking to FarsNet FarsNet [78] is a valuable lexical dataset in Persian. It provides a clean and carefully handcrafted hierarchy of concepts. Despite that we have already linked parts of FarsBase with FarsNet, a complete linking between the two sources can increase the extendability of both datasets and benefits certain applications for the Persian language. Interestingly, many of the FarsNet entities and predicates are already mapped to WordNet synsets, which could pave the path for designing multi-lingual applications.
Integrating with other Persian sources Using structural datasets such as Persian wikis, theses, academic information, and books, can help to further augment the FarsBase data.
OWL reasoning Reasoning is an effective methods for augmentation on FarsBase [11,18,67,68]. OWL supports standard reasoning capabilities, including symmetric, inverse, transitive, and functional properties. Triples produced by reasoning can be verified by the experts.
Deep learning for raw texts The idea of applying deep learning for information extraction is becoming popular. Deep learning can be applied as an independent extraction tool or can be integrated with the current stack using frameworks like Snorkel [70] and DeepDive [91].
Temporal and spatial aspects FarsBase currently extracts temporal information from the infoboxes and exploits them to model n-ary relations. However, temporal information can also be extracted and enhanced using other sources such as Wikipedia categories. Similarly, Integrating the spatial information and geographical location of the entities to FarsBase can benefit location-based applications.
Codes and data
All source codes are available at
Footnotes
Acknowledgements
This research is funded by the Iran Telecommunication Research Center (ITRC). We thank all FarsBase contributors, including Mohammad-Bagher Sajadi, Hossein Khademi-Khaledi, Mostafa Mahdavi, Abolfazl Mahdizadeh, Nasim Damirchi, Leila Oskooei, Ensieh Hemmatan, Morteza Khaleghi, Razieh FarjamFard, Mohammad Abdous, Mohsen Rahimi, Ehsan Shahshahani, Yousef Alizadeh, and Dr. Samad Paydar. We also thank the editors and the reviewers for their valuable comments.